
应用n-LSTM的云平台任务CPU负载预测方法
2024-02-28 08:18谢同磊梁晨君
小型微型计算机系统 2024年1期
曹 振,邓 莉,谢同磊,梁晨君
(武汉科技大学 计算机科学与技术学院,武汉 430065) (智能信息处理与实时工业系统湖北省重点实验室,武汉 430065)
0 引 言
近年来,随着云计算技术的持续发展,云平台数据中心的用户规模一直处于稳定上升的趋势.然而研究表明,大多数云环境的资源利用率均处于较低水平[1,2],比如:阿里云平台中每台机器的平均CPU利用率都在40%以内[3],而Google云平台的CPU利用率则始终在10%~45%之间波动[4].数据中心的低效性会威胁到其盈利能力[5].云平台资源的有效管理,已成为当前数据中心所面临的主要挑战之一[6].有效地对云平台任务进行CPU负载预测可以促进主动的作业调度,更好地做出CPU负载均衡决策,提高CPU资源利用率,在保证作业性能的前提下降低云平台数据中心的运营成本.
研究人员已经进行了相关CPU负载预测工作.云平台中任务的CPU负载是一种特殊的时间序列,它兼具动态性、不确定性、突变性和时间依赖性等特点,这使得基于云平台任务的CPU负载预测工作变得更具有挑战性.为减轻数据中的噪声对CPU负载预测的负面影响,Deguang等人提出了一种将降噪和纠错相结合的云服务器CPU负载预测方法[7],一定程度上改善模型性能,但该方法忽略了时间序列缺失信号对预测的影响.为解决模型训练过程中的参数优化问题,Yiping等人提出了一种名为DP-CUPA的模型[8],结合深度置信网络(Deep Belief Network,DBN)和粒子群优化算法(Particle Swarm Optimization,PSO)来预测云数据中心中物理机的CPU利用率.得益于PSO对DBN的参数优化,该模型的预测结果要比原始模型EMDBN[9]的预测结果更为准确.但是利用PSO对DBN进行参数优化的过程中可能会陷入局部最优.
本文通过对阿里云平台数据集与Google云平台数据集的分析,发现它们分别记录了许多不同的特征,而这些不同特征与其待预测特征之间的相关性存在着较大差异.相比较于一般数据集,此类特征复杂多样的时间序列数据集在模型训练过程中的特征选取及特征学习更显重要.而现有的云平台任务预测模型在特征学习规划上都还存在不足,没有完全挖掘出多个不同时间序列变量之间存在的内在关系,从而影响目标变量预测值的准确性[10].本文提出基于多重长短期记忆n-LSTM(n-feature Long Short-Term Memory,n-LSTM)(https://blog.csdn.net/weixin_46649052/article/details/109693618)的CPU负载预测方法DPFE-n-LSTM(n-LSTM based on Data Preprocessing and Feature Extraction,DPFE-n-LSTM).数据预处理阶段利用热度图筛选出数据集的特征,并将其中的每一个特征对应独立的LSTM层.利用长短期记忆网络作为其基本单元来学习负载数据中各个特征的时间依赖关系,同时又考虑到多个特征之间的影响.这样,既可以避免由于模型深度增加而造成的梯度弥散和梯度爆炸现象,又可以在防止丢失部分特征的同时选择性地加强对某些相关性很高的特征的学习.
1 相关工作
随着云计算的兴起,数据中心变得越来越重要.数据中心主要服务于广泛的应用程序,比如:搜素引擎,视频处理,机器学习以及第三方云应用程序等[11].计算资源的有效使用是数据中心面临的主要挑战之一.准确的资源负载预测有助于计算资源的优化配置,从而大大降低数据中心的能耗.
CPU作为最重要的计算资源之一[8],其负载预测问题近些年来已经引起了相关研究人员的关注.2014年Yu等使用误差反向传播(Back Propagation,BP)模型对Google云平台任务的平均CPU 利用率进行了预测[12].但是,BP模型具有收敛速度缓慢和容易陷入局部最优值等缺点,同时目前云平台在线任务的资源配置是依据其最大资源使用量进行的[13].Duggan等在2017年使用循环神经网络对CPU使用率进行预测[14],该模型弥补了BP模型在时间序列的时间特征学习上的缺陷,但是它在学习长距离依赖方面依旧存在着不足.Song等在2018年利用LSTM模型对CPU 的平均负载和实际负载进行了预测[15].相比较于普通的RNN,LSTM模型在长时间序列的负载预测中具有更好的表现,并且能够解决长序列训练过程中的梯度消失和梯度爆炸问题,但是Song等人只提取出了CPU负载用于预测,没有考虑到其他特征对CPU负载预测的影响.而且在输入数据含有多个特征时,LSTM模型只能设置一个时间窗,会忽略不同特征之间的差异,从而影响最终的预测效果.2015年Xingjian等使用卷积长短期记忆神经网络(Convolutional Neural Network - Long Short-Terms Memory,CNN-LSTM)进行了预测[16].与LSTM模型相比较,CNN-LSTM在保留学习长期时序依赖信息的能力的同时,还拥有了自动特征提取以及学习空间依赖信息的能力,但是CNN-LSTM模型在特征提取过程中会丢失底层特征,导致特征学习的不充分,降低预测精度.
对于CPU负载的预测工作,大多数研究人员都过分关注于预测模型的设计,却忽略了数据的特征提取.在实际应用中,合适的数据预处理和特征提取对模型预测精度的提升有着重要的作用.本文基于对真实数据集的分析,提取多个特征,并采用n-LSTM模型学习这些特征而得到更为优良的预测效果.
2 预测方法DPFE-n-LSTM
本文所提出的基于多重长短期记忆的CPU负载预测方法DPFE-n-LSTM包括以下4个步骤:
步骤1.预处理有关CPU使用状态的历史时间序列数据,以生成长度相同的数组列表.数据预处理主要包括缺失值处理、数据标准化和步长选择等.
步骤2.利用热度图对任务负载的各特征进行特征分析,据此完成特征选择,并保留特征的相关性值,以供后续模型训练的参数设置.
步骤3.基于经由数据预处理得到的最新数据集以及特征提取后的特征分布情况,设计并训练n-LSTM模型.
步骤4.基于训练好的n-LSTM模型,对给定的输入数据,生成最终的预测结果.
图1描述了CPU负载预测方法DPFE-n-LSTM的具体实现流程.
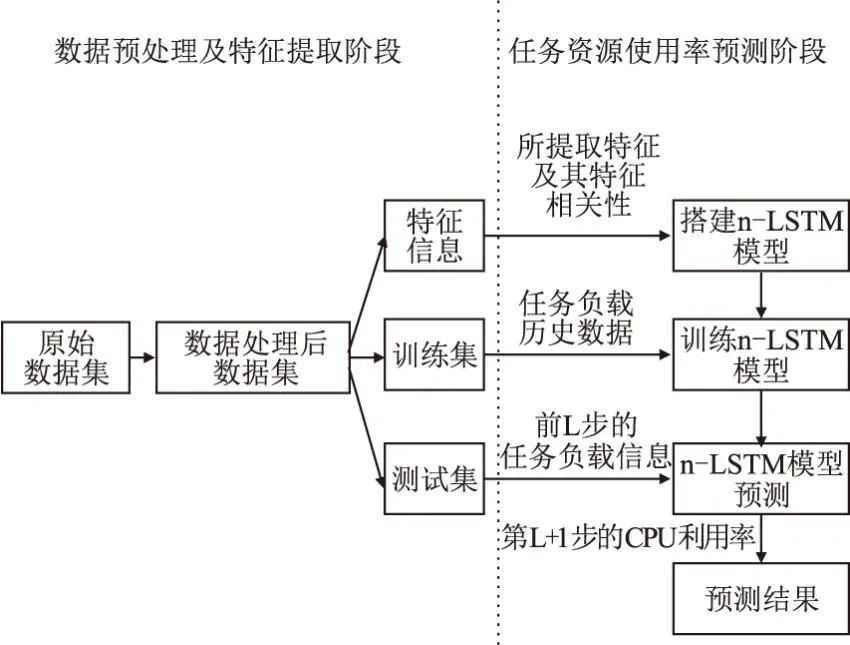
图1 云平台任务CPU负载预测方法DPFE-n-LSTM Fig.1 CPU load prediction method DPFE-n-LSTM of cloud tasks on cloud platform
如图1所示,首先基于云平台在连续时间内任务的资源使用数据,整理出任务在时间间隔T内的资源使用率信息,然后对数据集进行进一步数据处理,其中包括缺失值填充、特征分析及提取、数据标准化处理和输入数据步长选择等操作.最后再基于经过数据处理后的最新数据集,利用分析得出的特征信息来搭建n-LSTM模型,使用训练集中的任务负载历史数据以训练n-LSTM模型,提供测试集中的前L步任务负载信息以预测第L+1步的CPU利用率.
2.1 数据预处理及特征提取
云平台数据中心所提供的跟踪数据的主要来源是周期性的远程过程调用,而当监控系统或者主机发生超载现象时,有可能会丢失掉一些监测数据,因此需要对数据集中的缺失值进行填充操作,以避免遗漏掉某个缺失字段,从而影响后续的模型训练过程.本文采用的方法是先进行前向填充,再进行后向填充,这样能防止数据集中任意位置的缺失值填充遗漏.
缺失值填充能有效降低模型训练过程中意外事件发生的可能性.紧接着需要决定使用数据集中的哪些信息来进行模型训练,这会对预测结果产生很大的影响.特征选择(Feature Selection,FS)的过程还可以减少计算时间,降低数据存储需求,简化模型,规避维数爆炸,并增强泛化能力,避免过拟合[17].目前的特征选择技术主要是基于4个指标:特征方差,与目标的相关性,回归器之间的冗余度和特征重要性.
本文基于与目标特征的相关性来实现特征选择,使用热度图(heatmap)分别对阿里云trace和Google云trace进行特征相关性分析,从而决定用于CPU负载预测而保留的特征集合.图2分别展示了阿里云平台与Google云平台各自的特征的相关性分布.
从图2(a)可知,阿里数据集中的预测特征cpu_used(已使用的CPU所占百分比)与load1(以1分钟为一个单位的CPU平均负载)、load5(以5分钟为一个单位的CPU平均负载)、load15(以15分钟为一个单位的CPU平均负载)、avg_mpki(每1000条指令的平均的最后一级高速缓存未命中数)、max_cpi(最大指令周期)、max_mpki(每1000条指令的最大的最后一级高速缓存未命中数)以及其自身的相关性比较强,这些特征与cpu_used的特征相关性的值均大于0.5.需要注意的是,每个特征与其自身的特征相关性的值都为1.其中,load1、load5和load15两两之间的相关性又趋近于1,可以仅取其中与cpu_used的特征相关性最大的load15作为预测cpu_used的代表特征.而max_mpki、max_cpi以及avg_mpki两两间的相关性也很高,为避免后期模型训练过程的过拟合问题,则仅取max_mpki作为预测cpu_used的代表特征.因此,最终选择只保留阿里云trace中cpu_used,load15,max_mpki这3个特征,其中cpu_used同时也是目标特征.从图2(b)可知,在Google云trace中,目标特征maximum CPU usage(最大CPU利用率)与其他特征的相关性均较低且彼此相近,取值范围为0.01-0.13,且除去maximum CPU usage与自身的特征相关性以外,其余特征相关性绝对值的总和为0.94.根据以上分析可知,Google数据集中提供的特征与目标特征之间的关联性均较弱,如果选择的特征过少,则将有很大概率会导致欠拟合现象的发生.因此为避免丢失过多特征而影响预测精度,选择保留Google数据集中的所有可用特征.
通过热度图对两个数据集的特征分析,可以发现阿里云trace和Google云trace中的特征分布存在着很大的差异,这也在一定程度上说明了模型训练过程中的特征选择与特征学习的重要性,只有在合适的特征提取以及合理的特征学习的基础上才能有效地提高目标特征的预测精度.表1与表2分别列出从阿里云平台和Google云平台的任务数据集中提取到的全部特征及其含义.

表1 阿里云trace中提取的特征Table 1 Features extracted from Alibaba Cloud trace
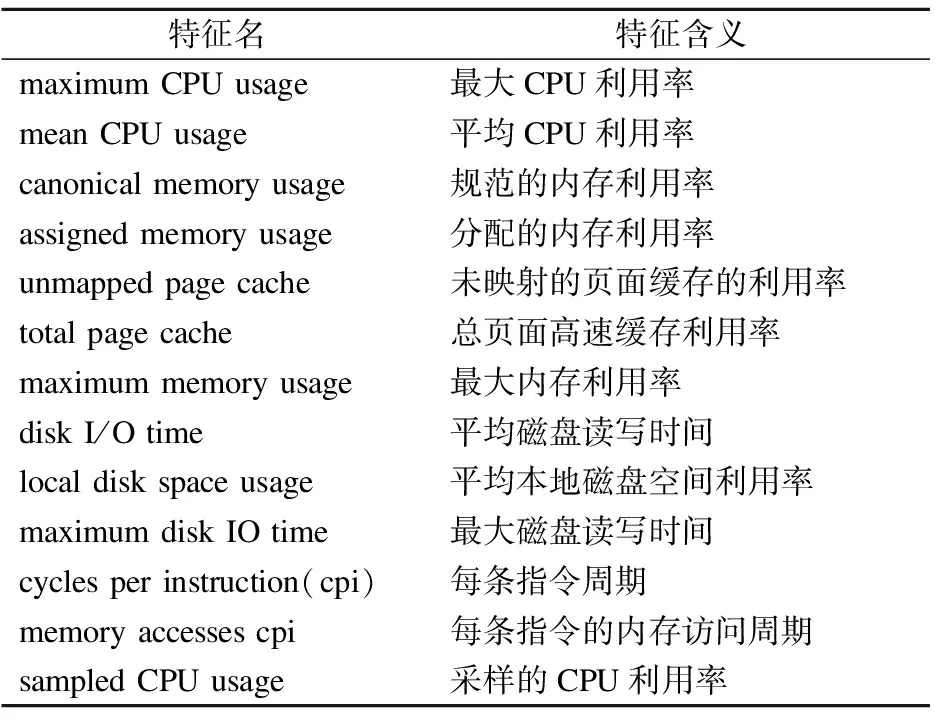
表2 Google云trace中提取的特征Table 2 Features extracted from Google Cloud trace
特征提取后,经观察发现不同特征之间的取值范围有较大差别.为了消除差别并使不同特征之间存在可比性,本文选择使用最大最小标准化方法对两个数据集中的每个特征依次进行处理,处理方式如公式(1)所示.
(1)
其中,MIN是某特征在所有样本中的最小值,MAX是某特征在所有样本中的最大值,x是某样本的原特征值,x′是该样本处理后的特征值.
数据经过标准化处理后既能在后续的模型训练过程中加快梯度下降求解最优值的速度,也能在一定程度上提高预测的精度.
图3描述了数据预处理的最后一步操作,是对已经按时间戳排好序的每组实例信息构造多个长度为L+1 的子序列,即将子序列的前L步视为输入,最后一步视为目标输出.即,本文模型训练的目标是通过前L步的任务资源负载信息预测下一步的CPU利用率.
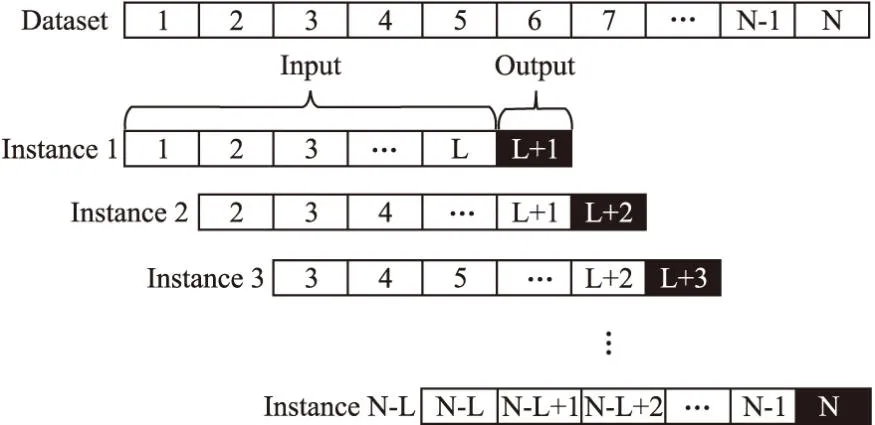
图3 时间序列中的步长设置Fig.3 Step size in time series
步长L值的确定,主要基于多次实验分析的经验.分别在阿里云trace和Google云trace中随机选定一个任务,对步长设置不同的值,使用LSTM模型进行预测,依据CPU负载预测的4个评价指标(均方误差、均方根误差、正规化均方根误差和平均绝对误差),确定最终的时间序列输入步长.
2.2 任务资源使用率预测模型
目前,用于云平台任务资源利用率的预测模型有BP模型[12]、LSTM模型[15]和CNN-LSTM模型[16]等.BP模型适用于任何非线性映射问题,具备着高度的并行性、良好的容错性与联想记忆功能,以及很强的自学习能力和对环境的自适应能力.但是它存在着3个问题:1)参数优化难度大,耗时耗力;2)学习速度慢;3)模型容易陷入局部最优解,从而导致学习不够充分.BP模型既不能实现特征维度上的灵活调节,也不能完成时间维度上的特征学习.LSTM模型是一种特殊的循环神经网络(Recurrent Neural Network,RNN)模型,主要是为了解决一般的RNN所存在的长期依赖问题.LSTM模型包含4个基本组件:单元、输入门、遗忘门和输出门,其中3个门跟踪并控制着单元中数据流的输入和输出.输入门决定当前输入数据中保留哪些信息,遗忘门决定要忘记之前没用的信息,输出门则确定当前时刻节点的输出.LSTM模型在特征学习的灵活性上有所欠缺,它没能在学习过程中将不同特征有效分隔开.CNN-LSTM模型会在输入数据通过CNN层时丢失掉底层特征,这将有一定概率使模型学习到的特征过少,而导致欠拟合现象的发生.
经观察发现,基于长期的复杂的多元数据进行预测时,包括LSTM在内的循环神经网络的性能均会有所下降.特别是在输入为多维的情况下,合理把握变量之间的关系对于预测更显得尤为重要[18].
考虑到多维特征,本文采用n-LSTM作为预测模型.不同于以往多层LSTM模型在纵向上的加深,n-LSTM模型是基于LSTM层和输入特征在横向上的扩展.其基本原理是根据各个特征与预测特征之间的相关性大小,对输入数据的每一个特征设计一个专门的LSTM层进行特征学习,每个LSTM层的输入特征的时间窗维度可以不同,因此输入数据的每个特征在n-LSTM模型中的学习程度也会不同,时间窗越大,对应特征通过LSTM层时被学习到的细节就越多.n-LSTM模型中的每一个LSTM层可以被看作是一个独立的特征提取器,这种针对不同特征进行不同分析的做法既能避免因丢弃掉过多特征而导致的模型欠拟合现象,又能防止保留过多嘈杂特征而引发的模型过拟合现象.根据特征相关性的大小决定不同特征提取器的提取力度,既可以减小对于保留下来的嘈杂特征的学习强度,又可以加大对于重要特征的学习强度.在各个特征分别经由其所对应的LSTM层同步学习以后,将所有LSTM的输出进行拼接,最后通过一个全连接层得出最终的预测结果.n-LSTM模型的实现框架如图4所示.
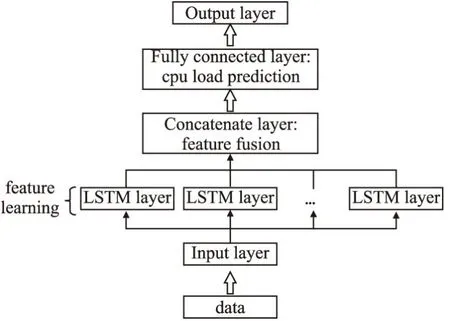
图4 n-LSTM模型实现框架Fig.4 Implementation framework of the n-LSTM model
n-LSTM模型在特征学习方面采取了分而治之的策略,即先将各个特征分开后借助LSTM层依次学习其时间依赖信息,然后借助全连接层学习各个特征之间的关系并实现信息的整合,这样便能很好的避免特征学习过程中的过拟合与欠拟合现象.相比较于BP模型、LSTM模型和CNN-LSTM模型,n-LSTM模型能合理利用数据预处理及特征提取阶段所获取到的特征信息,进而对云平台任务的资源使用特征进行更好的学习,从而产生更为准确的预测结果.
3 方法评估
本文选择使用阿里云trace以及Google云trace分别进行负载预测实验,评估本文所提出的云平台任务CPU负载预测方法DPFE-n-LSTM的性能,同时验证数据预处理及特征提取阶段对于最终预测性能提升的有效性.为多角度评估不同预测方法的性能,本文将采用4种不同的评估指标.
3.1 实验环境及数据集
实验在6核CPU(型号为AMD 锐龙 5 4600H)、16G DDR4内存、win10操作系统的环境中进行.
该实验采用了两个数据集,分别是2017年发布的阿里云平台跟踪数据集(https://github.com/alibaba/clusterdata/blob/master/cluster-trace-v2017/trace_201708.md)和2011年发布的Google云平台跟踪数据集(https://github.com/google/cluster-data/blob/master/ClusterData2011_2.md).
阿里云平台在2017年发布的跟踪数据集提供了连续24小时内对某生产集群的跟踪数据.数据包括机器的一部分工作负载和整个集群的工作负载.集群中的所有机器都能运行在线任务与批处理任务.数据集包含6类表格,分别是服务器事件表(server_event.csv)、服务器利用率表(server_usage.csv)、批处理任务表(batch_task.csv)、批处理实例表(batch_instance.csv)、在线任务事件表(container_event.csv)和在线任务利用率表(container_usage.csv).本文只使用了在线任务利用率表,并从中随机提取100个在线任务在24小时内保存下来的资源利用率数据.
Google云平台在2011年发布的跟踪数据集提供了自2011年5月开始的长达29天的跟踪数据,其生产集群包含了大约12.5千台计算机.Google云trace主要包含6类表格,其中,机器事件表(machine_events.csv)和机器属性表(machine_attributes.csv)共同描述了机器信息;作业事件表(job_events.csv)和任务事件表(task_events.csv)分别描述了作业信息、任务信息;任务约束表(task_constraints.csv)描述了任务放置的约束信息;任务资源使用情况表(task_resource_usage.csv)记录了集群中运行的任务的资源变化信息.本文只使用了该数据集中的任务资源使用情况表,并从中随机提取100个任务在29天时间里保存下来的资源利用率数据.
3.2 评价指标
为了评估不同模型对云平台任务CPU资源利用率预测的性能,本文选择使用均方误差(Mean Square Error,MSE)、均方根误差(Root Mean Square Error,RMSE)、正规化均方根误差(Normalized Root Mean Square Error,NRMSE)和平均绝对误差(Mean Absolute Error,MAE)这4个评价指标.
它们的定义公式如下所示.
(2)
(3)
(4)
(5)
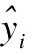
MSE作为最常用的回归损失函数,它可以评价数据的变化程度,MSE值越小,说明预测模型描述实验数据具有更好的精确度.RMSE是对MSE的开方,它可以解决MSE公式中改变量纲的问题,并且RMSE对一组预测结果中的特小误差反映更为敏感.NRMSE是将RMSE正规化后所得到的统计数值,它会将RMSE的值转换到(0,1)之间,当它的值较低时,代表着较少的残差变异.MAE同样是常用于回归模型的损失函数,它能避免误差相互抵消的问题,因而可以准确反映实际预测误差的大小.
3.3 阿里云平台资源使用情况预测
3.3.1 参数设置
基于不同步长,LSTM模型在阿里云数据集上进行CPU负载预测时得到的4个评价指标分别如表3所示.

表3 不同步长下的阿里云任务预测精度比较Table 3 Prediction accuracy comparison of Alibaba Cloud task with different step sizes
从表3可以观察到,当步长为5时,LSTM模型在4个评价指标上所展示出来的性能表现为最优.因此,在预测阿里云任务的CPU资源利用率时,将时间序列的步长L设置为5,即基于阿里云平台任务的前5步时间序列信息,预测下一步的CPU负载特征值.
基于阿里云数据集的负载预测实验中,经过多次模型优化测试,最终确定各个模型的重要参数.其中,BP模型的第1个全连接层的神经元数量设置为6,第2个全连接层的神经元数量设置为12,学习的周期数设置为160.LSTM模型的第1个LSTM层的神经元数量设置为8,第2个LSTM层的神经元数量设置为14,学习的周期数设置为150.CNN-LSTM模型的一维卷积层拥有32个大小为2的卷积核,该卷积层的步长设置为1,将它的一维最大池化层的池化窗口大小设置为2,其池化操作的移动步幅设置为1,将它的第1个LSTM层的神经元数量设置为8,第2个LSTM层的神经元数量设置为14,学习的周期数设置为120.n-LSTM模型的LSTM层的数量是由数据集的特征数所决定的,对于阿里云平台任务数据集,它拥有3个并行的LSTM层,LSTM层的神经元数量依次为20、17、12,神经元数量设置与该层所对应特征与预测特征的特征相关性大小有关,学习的周期数设置为130.
3.3.2 不同方法的性能对比
在本节实验中,将n-LSTM模型与已经提出的BP模型、LSTM模型和CNN-LSTM模型等3种模型进行比较,这些方法在云平台任务的CPU负载预测方面都已经体现出了优良的性能.
实验流程是:从前面已经进行了数据预处理的100个云平台任务的数据集中随机选取出50个云平台任务,并利用这50个任务各自80%的负载信息参与模型训练,20%参与模型预测.考虑到实际应用场景中除了参与模型训练的任务存在预测需求以外,还有部分任务需要直接依赖模型进行负载预测,本文选择保留剩余的50个云平台任务不参与模型训练,但同样需要利用其各自20%的负载信息参与模型预测.经过模型预测,针对每一个任务,每个模型均会得到4个评价指标.最后,基于这些评价指标的数据分别绘制累计分布图(Cumulative Distribution Function,CDF).图5分别描述了4种模型在MSE、RMSE、NRMSE和MAE四个评价指标上的性能比较.
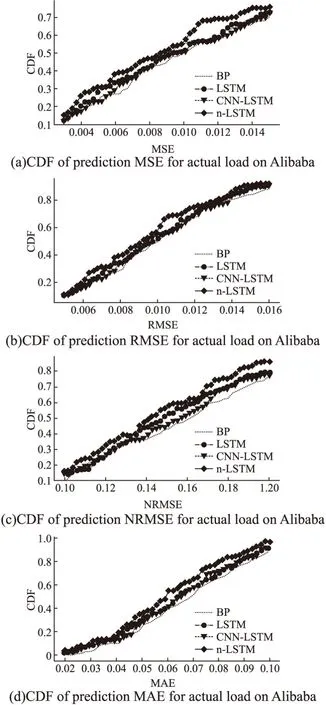
图5 基于不同模型的阿里云任务负载预测精度比较Fig.5 Prediction accuracy comparison of Alibaba Cloud task load based on different models
在图5(a)中,代表n-LSTM模型的曲线始终处于另外3条曲线的上方,而代表BP模型的曲线几乎一直处于最下方.在MSE取值为[0,0.008]或[0.010,0.015]时,LSTM模型的曲线整体上高于CNN-LSTM模型的曲线.在MSE取值为[0.008,0.010]时,LSTM的曲线整体上低于CNN-LSTM曲线.由此可知,n-LSTM模型在MSE上表现出的性能最优,BP模型的性能则会略差于另外3种模型,LSTM模型和CNN-LSTM模型的性能则处于居中位置,两者不相上下,时好时坏.例如,当MSE为0.012时,n-LSTM曲线的CDF为0.7,而LSTM曲线、CNN-LSTM曲线以及BP曲线的CDF分别为0.6、0.58和0.57,这表明,阿里数据集中的100个在线任务在分别经过4种模型的预测后,n-LSTM模型得到的MSE集合中有70%小于或等于0.012,而LSTM模型、CNN-LSTM模型和BP模型则分别有60%、58%以及57%的预测值的MSE小于或等于0.012.
与图5(a)相类似,图5(b)、图5(c)和图5(d)中,n-LSTM曲线始终位于最上侧而BP曲线位于最下侧.除了在图5(c)中LSTM曲线几乎一直位于CNN-LSTM曲线之上,另外三图中它们都是处于居中位置且会随着横坐标的变化而上下波动.综上所述,当对阿里云平台的在线任务进行CPU负载预测时,以4个不同的评价指标作为判别标准,n-LSTM模型都具有最好的预测效果.n-LSTM模型预测性能的提升主要是来源于其针对不同负载特征分而治之的思想和特殊的横向体系结构,这也是其他模型所欠缺的.
4个模型在阿里云平台的100个任务的预测实验中所得到的4个评价指标的平均值如表4所示.从表4可知,当将参与训练的任务与未参与训练的任务的预测结果统一分析时,n-LSTM模型在4个评价指标上的性能保持最优,拥有更高的预测精度.从MSE、RMSE和MAE这3个评价指标上来看,模型的预测性能由好到坏排序依次为:n-LSTM模型、LSTM模型、CNN-LSTM模型、BP模型.从NRMSE这个评价指标上来看,模型的预测性能由好到坏排序依次为:n-LSTM模型、CNN-LSTM模型、LSTM模型、BP模型.相比较次优模型,n-LSTM模型的MSE大约减少了8.35%,RMSE大约减少了5.24%,NRMSE大约减少了7.76%,MAE大约减少了7.92%.相比较最差模型,n-LSTM模型的MSE大约减少了13.56%,RMSE大约减少了8.21%,NRMSE大约减少了11.81%,MAE大约减少了13.04%.
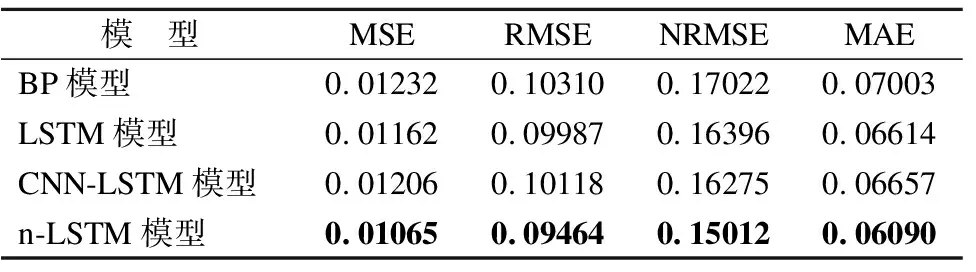
表4 基于不同模型的阿里云任务负载预测精度平均值Table 4 Average load prediction accuracy of Alibaba Cloud tasks based on different models
将阿里云任务分成参与训练的任务集合和未参与训练的任务集合,分别统计4个模型所得到的4个评价指标的平均值与最大值,结果如表5所示.从表5可知,无论任务是否参与模型训练,n-LSTM模型都能拥有最优预测性能,这正是源自于n-LSTM模型在特征学习上的优势.以4个评价指标的平均值作为模型性能的评判标准,n-LSTM相比较另外3个模型总能获得最小的预测误差,因此n-LSTM模型具有最好的整体预测性能.基于评价指标的最大值比较模型性能,n-LSTM模型同样能获得最小的预测误差,则在实际预测任务中n-LSTM模型相比较其他模型能在最大程度上尽量避免最坏预测结果的发生.
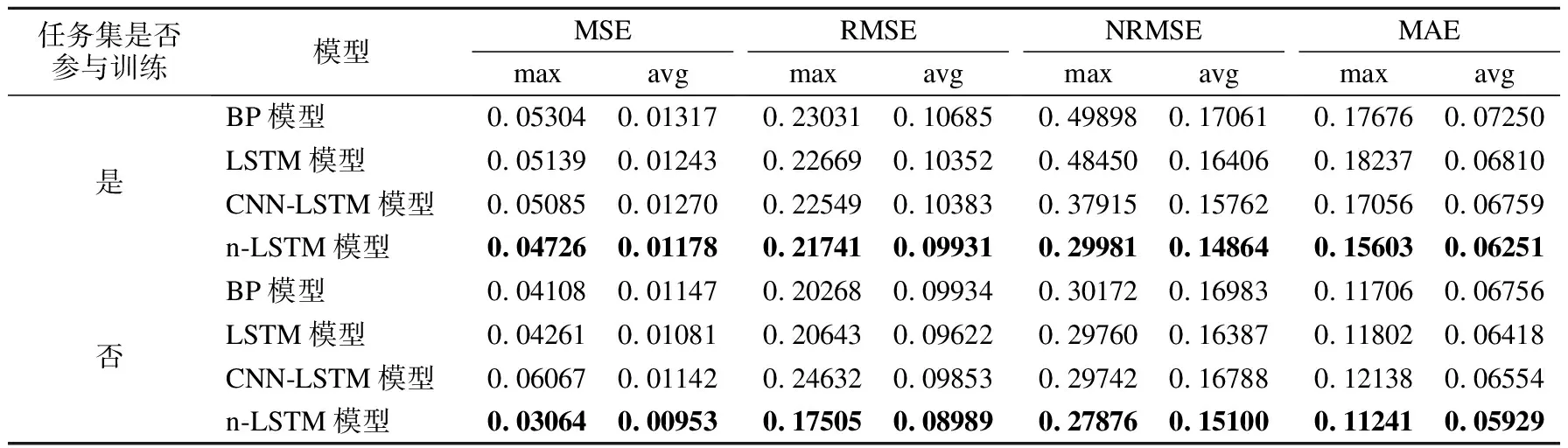
表5 基于不同模型的阿里云任务负载预测精度比较Table 5 Comparison of load prediction accuracy for Alibaba Cloud tasks based on different models
3.4 Google云平台任务资源使用情况预测
3.4.1 参数设置
基于不同步长,使用LSTM模型在Google数据集上进行CPU负载预测时得到的4个评价指标记录在表6中.
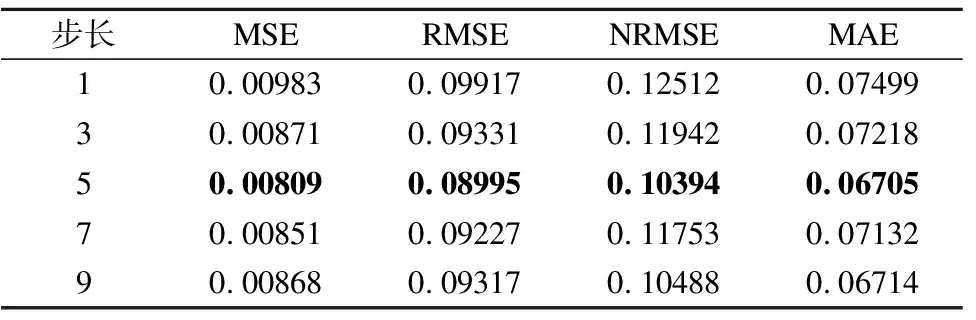
表6 不同步长下的Google云任务预测精度比较Table 6 Prediction accuracy comparison of Google Cloud task with different step sizes
从表6可知,步长为5时LSTM模型在4个评价指标上所展示出来的性能表现为最优.
因此,在预测Google云任务的CPU资源利用率时,将时间序列的步长L设置为5,即基于任务的前5步时间序列信息,预测下一步的CPU负载特征值.
在基于Google数据集的实验中,经过多次模型优化测试,最终确定各个模型的重要参数.与基于阿里云数据集的实验不同的是,BP模型学习的周期数设置为100,CNN-LSTM模型学习的周期数设置为100,n-LSTM模型学习的周期数设置为150.同时将CNN-LSTM的第1个LSTM层的神经元数量设置为6,第2个LSTM层的神经元数量设置为13.对于Google云平台任务数据集,为n-LSTM模型设置13个并行的LSTM层,这些LTSM层中包含的神经元的数量依次为12、1、1、1、1、1、1、1、1、1、1、1、1.
3.4.2 不同方法的性能对比
在本节实验中,将n-LSTM模型与BP模型、LSTM模型和CNN-LSTM模型进行了比较.实验流程是:从前面已经进行了数据预处理的100个任务中选取出50个云平台任务,并利用这50个任务各自80%的负载信息参与模型训练,20%参与模型预测.剩余的50个云平台任务不参与模型训练,但同样需要利用其各自20%的负载信息参与模型预测.经过模型预测,针对每一个任务,每个模型均会得到4个评价指标.针对这些评价指标分别绘制CDF图.图6分别描述了4种模型在MSE、RMSE、NRMSE和MAE4个评价指标上的性能比较.
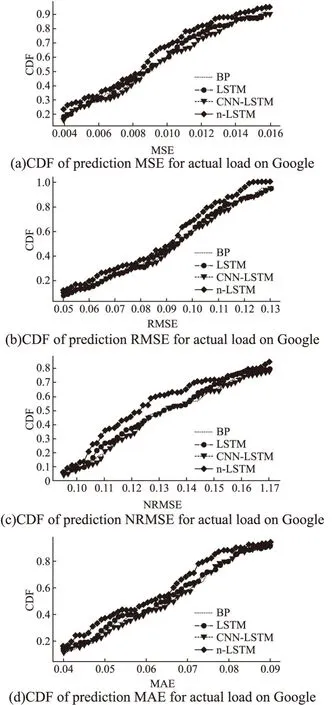
图6 基于不同模型的Google云任务负载预测精度比较Fig.6 Prediction accuracy comparison of Google Cloud task load based on different models
在图6(a)、图6(b)、图6(c)以及图6(d)中n-LSTM模型的曲线的位置明显高于另外3种曲线,而另外3种曲线的相对位置则会随着横坐标的变化而变化.由此可知,无论以哪个评价指标来比较模型的优劣,由于得益于对不同特征学习的合理把握,n-LSTM模型都始终具有最优性能,而另外3种模型的性能则相对不太稳定.
在图6(d)中,当横坐标取值为0.050时,n-LSTM曲线、LSTM曲线、CNN-LSTM曲线以及BP曲线在纵坐标上分别对应着0.37、0.30、0.28以及0.25,这表明Google数据集中的100个任务在分别经过4种模型的预测后,n-LSTM模型所得到的MAE集合中有37%的值小于或等于0.050,而LSTM模型、CNN-LSTM模型和BP模型则分别有30%、28%以及25%的MAE值小于或等于0.050.
上述实验中,4个评价指标的平均值分别如表7所示.
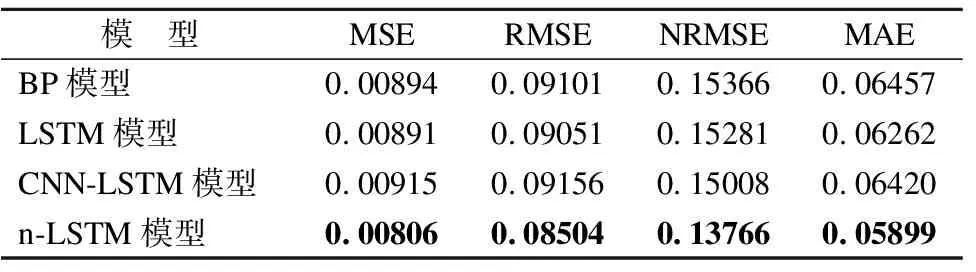
表7 基于不同模型的Google云任务负载预测精度平均值Table 7 Average load prediction accuracy of Google Cloud tasks based on different models
从表7可知,当将参与训练的任务与未参与训练的任务的预测结果统一分析时,n-LSTM模型在4个评价指标上的性能始终保持最优,即在Google云平台的任务CPU利用率预测上n-LSTM模型相比较其它3个模型整体上拥有更高的预测精度.从MSE和RMSE这2个评价指标上来看,模型的预测性能由好到坏排序依次为:n-LSTM模型、LSTM模型、BP模型、CNN-LSTM模型.以NRMSE为评价指标,模型的预测性能由好到坏排序依次为:n-LSTM模型、CNN-LSTM模型、LSTM模型、BP模型.以MAE为评价指标,模型的预测性能由好到坏排序依次为:n-LSTM模型、LSTM模型、CNN-LSTM模型、BP模型.相比较次优模型,n-LSTM模型的MSE大约减少了9.54%,RMSE大约减少了6.04%,NRMSE大约减少了8.28%,MAE大约减少了5.80%.相比较最差模型,n-LSTM模型的MSE大约减少了11.91%,RMSE大约减少了7.12%,NRMSE大约减少了10.41%,MAE大约减少了8.64%.
4个模型分别在Google云平台参与训练和未参与训练的任务集合的预测实验中所得到的4个评价指标的平均值与最大值如表8所示.

表8 基于不同模型的Google云任务负载预测精度比较Table 8 Comparison of load prediction accuracy for Google Cloud tasks based on different models
从表8可知,无论预测实验所用任务集是否参与模型训练,n-LSTM模型的预测结果在所有评价指标上的平均值以及最大值都保持最小,与阿里云任务负载预测实验相同,Google云任务负载预测实验中n-LSTM模型同样既能具备最优整体预测性能,也能最大程度提高预测精度的底线值.
4 总结与展望
现如今随着越来越多的企业实现了业务云端化,云计算已经逐渐迈开了从单一的互联网行业渗透到各个传统产业领域的步伐,这将使得云计算的发展更为迅速,与此同时云平台所承担的业务量也在不停增长.然而,随着各大云平台的运行成本稳定上升,其资源利用率却一直没能达到令人满意的程度.对云平台任务资源利用率的准确预测能在很大程度上改善整个云平台资源的有效使用.
本文专注于多元时间序列建模和预测单变量,旨在进一步提高云平台任务资源利用率的精度,为此提出基于n-LSTM模型的负载预测方法DPFE-n-LSTM,该方法在时间维度上的性能优势的基础上又增添了在特征维度上更为灵活准确的学习方式,它能在云平台任务的CPU负载方面表现出良好的性能.本文使用了Alibaba Trace和Google Trace两个真实负载跟踪数据集基于4个不同的评价指标来对模型进行评估.根据实验结果可知,n-LSTM模型具备着优异的自适应能力,在两个数据集上都是n-LSTM模型的性能最好.实验结果证明了n-LSTM模型在多元特征时间序列预测任务上的优异性能.但是,在某些现实情况下,可能会存在一些特征量较少的数据集.未来的工作将研究原始数据集特征数量的不足给模型预测精度带来的影响.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
炎黄地理(2021年1期)2021-06-08
疯狂英语·新策略(2019年10期)2019-12-13
小学生学习指导(低年级)(2019年11期)2019-11-25
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
中国科技信息(2015年21期)2015-11-07
