
一种基于ViT改进的轻量化恶意流量识别方法
2024-02-27 09:02张文波
小型微型计算机系统 2024年2期
刘 贺,张文波
(沈阳理工大学 信息科学与工程学院,沈阳 110159)
0 引 言
在过去几年里,IoT(Internet of Things,物联网)设备在多个领域的应用都出现了持续增长的趋势,如工业领域、医疗领域、自动化领域和教育、智能家居和智慧城市等领域.根据数据统计显示,2018年全世界物联网设备的总数量突破了200亿,预测该数量在2030年将超过500亿[1].
虽然物联网技术提出的万物互联能够推动经济的发展,但是该技术也带来了新的安全挑战,它并不像看上去的那么安全.事实上,物联网设备通常只会分配到有限的资源,例如空间较小的存储介质和计算能力较差的处理器.因此,物联网设备非常容易受到黑客攻击的威胁.这些限制阻碍了在这些设备上部署复杂的安全措施,并使黑客们有机会轻易地侵入物联网设备并执行一些非法活动,破坏网络的安全性和完整性.当物联网设备遭受到攻击时,僵尸网络是物联网受到的威胁中最常见的攻击类型.被入侵的物联网设备会成为僵尸网络的一部分,能够发起极具破坏性的DDoS(Distributed Denial of Service,拒绝服务)攻击.例如,在2016年10月,一个名为Mirai[2]的僵尸网络利用缺乏安全保护措施的物联网设备发起攻击,对Dyn等公司发起了历史上最大的DDoS攻击之一.该攻击在高峰时段使网络的最大吞吐量超过了1Tbps,并对包括Twitter、Netflix、亚马逊等许多大型网站造成了破坏.与由计算机组成的已知僵尸网络不同,受到Mirai僵尸网络影响的设备主要包括监控摄像头和DVR(Digital Video Recorder,硬盘录像机)等物联网设备[3].据调查,此次大规模DDoS攻击涉及超过40万台受感染的物联网设备,是造成半个美国互联网无法提供网络服务的罪魁祸首.目前,Mirai的变种Satori、Miori等僵尸网络还在肆虐网络,受害企业的相关系统收到的恶意流量也创下了新纪录.攻击者通常操控被控制的物联网设备发起恶意攻击.因此,如果能更快的识别出物联网设备接收的恶意流量,就可以显著地防止恶意攻击的入侵,降低网络受到攻击的影响.
随着人工智能技术的快速发展,深度学习已被引入恶意流量识别问题中.具有逐层对原始输入进行学习,自动获得分类任务的特征.与基于机器学习的方法相比,基于深度学习的恶意流量识别方法可以将特征提取和分类两个步骤整合到一个算法中,从而避免了人工设计特征的繁琐步骤,有效克服了人工设计的特征集不合理而导致的准确率低的问题.
基于深度学习的恶意流量识别方法需在原始流量输入深度学习模型之前,必须对其进行预处理,因为深度学习模型对输入数据的格式和大小有严格要求.然而,现有的基于深度学习的恶意流量识别方法在处理原始数据时没有考虑数据本身的特点.实际上,在训练深度学习模型时,糟糕的数据预处理方法可能会导致识别效果不佳.同时,较大的模型需要更高的计算和内存资源.虽然使用图形处理单元(GPU)可以提供充足的计算资源,但不能提供足够的内存资源.最近的大多数研究旨在提高识别性能,而没有考虑到大尺寸深度学习模型所带来的计算和内存需求.
为了填补上述空白,本文提出一种基于深度学习的轻量化恶意流量识别方法,该方法包括一种预处理方法和深度学习模型.本文的主要贡献如下:
1)针对恶意流量识别方法中深度学习模型输入的问题,本文提出一种基于会话中数据包的灰度图片转换方法(Packets in a Session to Grayscale Image,PS2GI).
2)针对恶意流量识别方法实现高精度、轻量化的问题,提出一种基于简化混合Vision Transformer模型(SHViT)注意力机制的方法.
1 相关工作
基于机器学习的恶意流量识别方法中最大的问题是需要设计一个能够从恶意流量中提供的信息中生成准确反映恶意流量特点的特征集合,这会影响到恶意流量的识别结果.虽然近年来许多研究者对这一问题进行了研究,但设计高精度的恶意流量特征集合是一个没有彻底解决的研究方向.基于深度学习的恶意流量识别方法解决了机器学习方法需要设计高精度的恶意流量特征集合问题,因为它可以直接从原始恶意流量数据中自动学习,避免设计恶意流量特征集合的问题.
基于深度学习的恶意流量识别方法已经在各种神经网络模型上进行训练,并取得了一些显著的成果.例如,Ferrag[4]等人在恶意流量的二分类和多分类问题上使用了7种深度学习模型,如CNN模型(Convolutional Neural Network,卷积神经网络)、RNN模型(Recurrent Neural Network,循环神经网络)等进行实验,并且与机器学习模型进行对比,实验结果表明分类的效果均比机器学习模型好.
在物联网环境下,基于深度学习的恶意流量识别方法也同样适用于识别物联网中的网络流量.例如,Susilo等人[5]提出了一种用于识别物联网中的DoS攻击的方法.他们得出的结论是深度学习模型可以显著提高准确性,是物联网中最有效的威胁预防方法,但是实验结果显示基于CNN模型的方法的准确率不高.
Dutta等人[6]使用了DSAE(Deep Sparse AutoEncoder,深度稀疏模式的自动编码)算法进行数据降维.分类模型采用的是DNN模型(Deep Neural Networks,深度神经网络),LSTM模型(Long Short-Term Memory,长短时记忆)和一个分类器(逻辑回归算法)堆叠而成的模型.该研究分别比较了RF(Random Forest,随机森林)算法,单独的DNN模型和LSTM模型在IoT-23[7]物联网流量数据集上的效果,实验结果表明堆叠后的模型的准确率得到了提升,是一种有效的恶意流量分类方法,但该方法只给出了二分类问题的结果,并没有给出多分类问题的结果.
Sahu等人[8]使用CNN模型提取原始恶意流量数据的特征表示,并通过LSTM模型对物联网中的恶意流量进行分类.该方法同时对恶意流量的二分类和多分类情况在IoT-23数据集上进行训练,实验结果表明,二分类情况的准确率没提升,但是多分类情况的准确率得到了提升.
Biswas等人[9]使用了ANN模型(Artificial Neural Network,人工神经网络)、LSTM模型和GRU模型(Gated Recurrent Unit,门控循环单元)来区分物联网中的恶意流量和良性流量,在数据预处理阶段对恶意流量数据集进行数据清洗,并对文件中的攻击类型使用独热编码进行区分.实验结果表明,GRU模型的准确率高于其它两个模型.
ULLAH等人[10]使用了基于RNN模型的LSTM模型、GRU模型和BiLSTM(Bidirectional Long Short Term Memory)模型解决物联网的异常流量识别问题.由于CNN模型可以在不丢失重要信息的情况下分析输入的特征,提出了一种基于CNN模型和RNN模型的混合深度学习模型用于解决恶意流量的多分类问题,使用基于RNN模型的深度学习模型用于解决恶意流量的二分类问题,分别在IoT-23数据集上取得了当前最好的结果.
Doriguzzi等人[11]提出了一种基于LUCID模型的DDoS攻击检测方法,该模型对CNN模型进行改进,在输入层提出了一个新的空间表示方法,使CNN模型能够学习同一流量的数据包之间的关联性,同时在池化层选择一维最大池化方法.该模型结构简单,准确率比同一数据集下的CNN模型和LSTM模型更高.
Wei等人[12]提出了一种基于ABL-TC(Attention-BasedLSTM-Traffic Classification)的网络流量分类方法,该方法对LSTM模型进行改进,增加了注意力机制,同时减少模型的参数量和计算量,是一种轻量化网络流量分类方法.该方法只与同一数据集下的CNN模型和LSTM模型进行对比,在提升准确率的前提下模型的参数量和计算量更低,但是并未与同一数据集的其它研究方法进行对比.
根据以上分析发现,当前基于深度学习模型的轻量化恶意流量识别方法准确率对比其它研究方法差距较大.本文提出一种基于SHViT模型的分类方法,该方法在实现轻量化恶意流量识别的同时,还保证了恶意流量识别的准确率.
虽然深度学习模型有很多,但比较成熟的模型像是CNN模型、RNN模型在深度学习中取得了比较大的成功.在物联网场景中,研究人员主要关注基于RNN的方法,恶意流量识别的准确率很高,但是基于CNN的方法恶意流量识别的准确率却比较差,其中的原因是CNN模型在图片分类任务中表现的很好,但是从流量中提取到的特征作为CNN模型的输入并不合适,如果是图片作为CNN模型的输入,会得到更好的结果.
Wang等人[13]利用原始流量文件中的每个字节都能用一个十进制的数字表示的特性,并且值在0~255之间,恰好与灰度图片的像素的值对应.将处理后的流量转换为灰度图片,然后使用CNN模型对处理后的流量进行分类,取得了很好的效果.该方法的问题是只对原始流量文件的长度进行分割,并没有关注数据包的情况.
Moreira等人[14]提出了一种数据包视觉的方法,用来解决网络流量分类问题.该方法使用流量捕获工具从网卡中获取原始流量,将原始流量中的数据包转换为十进制的格式,并且字节长度设置为8的倍数,长度不足就填充,然后进行图像转换,将十进制的数据转换为灰度图片,最后将图像统一设置为224×224的大小,将数据包转换后的图像分别作为AlexNet、ResNet和SqueezeNet模型的输入.该方法使用了自建的数据集,虽然实验结果表明取得了不错的效果,但是图像转换过程中将图像拉伸到224×224的过程损失了原图像的细节,降低分类的准确率.
Sun等人[15]提出了一种基于深度学习的异常流量识别方法.该方法对原始网络流量数据包的数量和长度进行限制,然后对这些数据包进行图像化的表示,最后放入深度学习模型进行分类.具体的处理方式为数据包的长度限制为60字节,数据包的数量为30秒内收到的前60个数据包,将这60个数据包组成一个60×60大小的灰度图片作为CNN模型的输入,最后得到分类结果.该方法也是使用了自建的数据集,从监控设备上收集了两周局域网的网络流量,该数据集正负样本不均衡,良性流量的样本数比恶意流量的样本数高了数十倍.该方法将数据包的长度限制在了60字节,这种方式舍弃掉数据包中的数据部分,只保留了包头信息,降低识别的准确率.
申利民等人[16]提出了一种基于网络流量灰度图片的Android恶意软件检测方法.首先,该方法对原始流量进行分割,对分割后的流量长度做出限制,不足784字节的需要填充,超过的部分丢弃.然后将16进制的流量数据转换为2进制.最后将所有二进制比特流映射为28×28的灰度图片.这种转换方式是为了让CNN模型获取到流量数据的空间特征,再结合LSTM模型具有时序性的特点,通过自注意力模型得出类别.虽然这种方法效果很好,但是LSTM模型无法实现并行处理.
根据以上分析发现,针对上述数据包图像化转换方法的不足,本文提出了一种基于PS2GI的方法,该方法使用完整的数据包首部和数据部分,并且选择对会话中指定长度内的数据包进行识别以提高恶意流量识别的准确率.
2 本文方法
2.1 恶意流量识别过程
本部分阐述了基于深度学习的恶意流量识别方法的过程,具体过程如图1所示.
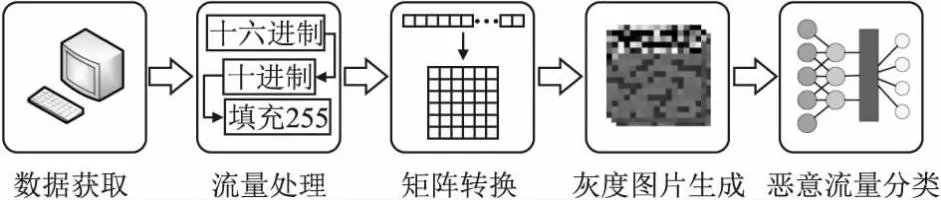
图1 恶意流量识别的过程Fig.1 Process of malicious traffic identification
第1步.数据获取.本文流量数据的来源是公开数据集(IoT-23数据集),是捕获自物联网设备的网络流量数据集.
第2步.流量处理.数据集中的原始流量文件并不能直接用于训练神经网络模型,需要先将原始流量文件按照五元组划分出单独的TCP流或UDP流,将原始流量文件中十六进制数据转换为十进制,并对每个数据包的长度进行限制,长度为256字节的倍数,不足的部分使用255填充.
第3步.矩阵转换.将十进制的数据按照本文提出的PS2GI方法转换为二维矩阵.
第4步.灰度图片生成.进行矩阵转换后,由于二维矩阵中的数值为十进制,恰好与灰度图片中每个像素的值对应,即可根据转换后的二维矩阵生成灰度图片.
第5步.恶意流量分类.将生成的灰度图片作为神经网络模型的输入,使用测试集验证恶意流量识别的准确率.
2.2 PS2GI方法描述及实现
PS2GI,即Packets in a Session to Grayscale Image,表示将会话中的数据包转换为灰度图片.该方法的思想是转换图像的过程中尽量不要截断数据包中的数据,而且图像的分辨率不宜过小,同时提升恶意流量识别的准确率.本部分给出了实现PS2GI方法的过程,如表1所示.

表1 实现PS2GI方法的过程Table 1 Process of implementing the PS2GI method
该方法的实现共有5个步骤:
1)限制会话的长度
PS2GI方法将会话的长度设置为50176字节,超出的部分将会舍弃,不足的部分进行填充,本文选择255(转换灰度图片后即白色)作为填充的值.在图像分类任务中,最常见的图片分辨率为224×224,很多基于CNN的神经网络模型的输入采用的都是这个分辨率,所以本文选择50176字节的长度就是为了将数据包转换成图片后的分辨率也是224×224,方便后续模型进行训练.相关研究中选择0作为填充值,即部分网络协议选择使用的填充值,本文选择255的目的是与这些填充值进行区分,有利于提升恶意流量识别的准确率.
2)规范会话中数据包的长度
PS2GI方法要求会话中的每个数据包的长度是256字节的倍数,不足256字节的部分进行填充,选择255作为填充的值.由上文可知,会话的长度是50176字节,本文将数据包的长度设置为256字节的倍数是受到ViT模型的启发,ViT模型将图片划分为14×14个patch,每个patch的大小恰好是16×16,恰好是256字节的倍数.更重要的是数据包内的数据是有顺序的,数据包与数据包之间也是有联系的.
3)矩阵转换
本文的矩阵转换简单示意图如图2所示.经过上面两步的处理后,会话的长度为50176字节,即大小为50176的一维矩阵,在转换成灰度图片之前需要先转换成二维矩阵.由上文可知,会话中的每个数据包的大小都是256字节的倍数,该方法需要在转换过程中按照一维矩阵的顺序先将前256字节转换到第一个16×16的patch中,依次每256字节转换为一个16×16的patch,总共有14×14个patch,最后形成224×224的二维矩阵.

图2 矩阵转换的简单示意图Fig.2 Simple schematic diagram of matrix transformation
4)在每个数据包前进行填充操作
上述3个步骤存在一个问题,只将一维矩阵转换为二维矩阵,并没有考虑到这种转换方式会截断协议首部的字段信息.例如,由TCP/IP体系结构下的各层协议的格式可知,使用TCP协议封装后的数据帧的首部长度为54(14+20+20=54)字节,使用UDP协议封装后的数据帧的首部长度为42(14+20+8)字节.按照第3步提到的将数据包转换为16×16的patch,TCP协议封装的数据帧的第16字节和第17字节、第32字节和第33字节、第48字节和第49字节的字段包含的信息会被截断,第32字节和第33字节涉及的恰好是IP协议的目的IP地址字段,该字段长度为4字节,不做处理直接转换会破坏字段包含的信息,无法提取到有用的信息.PS2GI方法的解决方式是在每个数据包前填充2个字节,选择255作为填充的值.
5)将二维矩阵输出为灰度图片
PS2GI方法调用opencv库的imwrite方法,将二维矩阵作为方法的参数输出到指定路径,图片类型为png.
2.3 基于ViT改进的轻量化恶意流量识别方法
受到Transformer模型[17]在NLP中可扩展性强的启发,为了将原始的Transformer模型直接应用在图像领域,并尽可能不做修改.为此,将图像分割为若干个patch,并把这些patch按照顺序排列好作为Transformer的输入.图像的patch与NLP领域中token的处理方式相同,并以有监督学习的方式训练图片分类的模型.
ViT模型[18]的架构如图3所示.首先,给定一张图片,把这张图片分割成n个patch,将这n个patch排成一个序列,通过一个线性投射层后得到一个特征,也就是图中的patch embedding.然后由于自注意力机制是所有的元素两两之间进行交互,需要添加一个位置编码(position embedding)方法,有了位置编码后,整体的token就既包含了图片的patch原本有的信息,又包含了图片的patch的位置信息.得到token后,就会与原始Transformer模型的输入结构保持一致,直接传送给Transformer Encoder模块并得到很多输出,ViT模型借鉴了BERT模型[19],在token中添加了一个分类token(

图3 ViT模型的架构Fig.3 Architecture of the ViT model
ViT模型相比基于CNN的模型缺少图像特有的归纳偏置.例如在CNN模型中,局部性和平移不变性是在每一层都有体现,这个先验知识相当于始终贯穿整个模型.但对于ViT模型来说,仅仅在MLP层是具有局部性和平移不变性的,自注意力层是全局的,ViT模型基本没有利用图片中的二维信息,也就在将图像切割成patch时,和进行位置编码时利用了图片的信息.位置编码也是随机初始化的,并没有携带任何二维的信息.所有关于图像patch之间的距离信息都需要重新学习.同时,由于多头自注意力机制要求序列中的每个token与其它token两两之间要进行计算.ViT模型中映射qkv使用的全连接层的维度和FFN的MLP模块隐藏层的维度非常大,即模型需要的参数量非常大.所以在物联网下的设备很难部署这样的模型.
针对上面提出的问题,现有的、最简单的方式就是采用CNN模型与ViT模型的混合架构,即HViT模型.CNN模型能够提供空间归纳偏置,而且加入CNN模型后能够加速网络的收敛,使神经网络训练过程更加的稳定.
本文使用了一种基于SHViT模型的恶意流量识别方法,该方法在HViT模型的基础上进行简化,HViT模型的参数量受到Transformer Encoder中映射qkv使用的全连接层的维度和FFN的MLP模块隐藏层的维度大小两方面的因素影响.经过研究后,为了尽可能不改变Transformer Encoder模块维度之间的倍数关系,两个维度的大小同时减少至原来的一半.HViT模型的计算量受到Transformer Encoder的输入大小影响,本文使用PS2GI方法将会话中的数据包转换成灰度图片,使用MobileNetV2模型进行下采样,生成大小为14×14的特征图,特征图的每个像素作为Transformer Encoder的输入.由于本文的灰度图片上下相邻的像素不像正常图片具有很强的关联性,左右相邻的像素具有一定相似性,所以在Transformer Encoder模块在计算注意力时无需计算相邻像素之间的值,即在对特征图进行展平成输入序列时,生成两个长度为特征图像素数量一半的输入序列,作为Transformer Encoder的输入.通过Transformer Encoder模块可知,输入序列长度减少一半,减少了多头自注意力机制的计算量,如公式(1)和公式(2)所示:
(1)
(2)
n代表Transformer Encoder输入序列的长度,k代表减少输入序列长度的倍数.
SHViTBlock的架构如图4所示.首先,输入维度为[H,W,C]的矩阵X,经过一个卷积核为1×3的卷积操作和一个卷积核为1×1的卷积操作改变通道数后,生成一个维度为[H,W,d]的矩阵,通过展开过程将该矩阵的维度转换为[H/h×W/w,h×w,d]作为Transformer Encoder的输入.然后,再经过Transformer Encoder后生成一个维度为[H/h×W/w,h×w,d]的矩阵,通过折叠过程将该矩阵的维度转换为[H,W,d],再经过1×1的卷积层对通道数进行改变,生成维度为[H,W,C]的矩阵.最后,将该矩阵和矩阵X通过残差连接后经过1×1的卷积层改变通道数后得到矩阵Y作为输出.
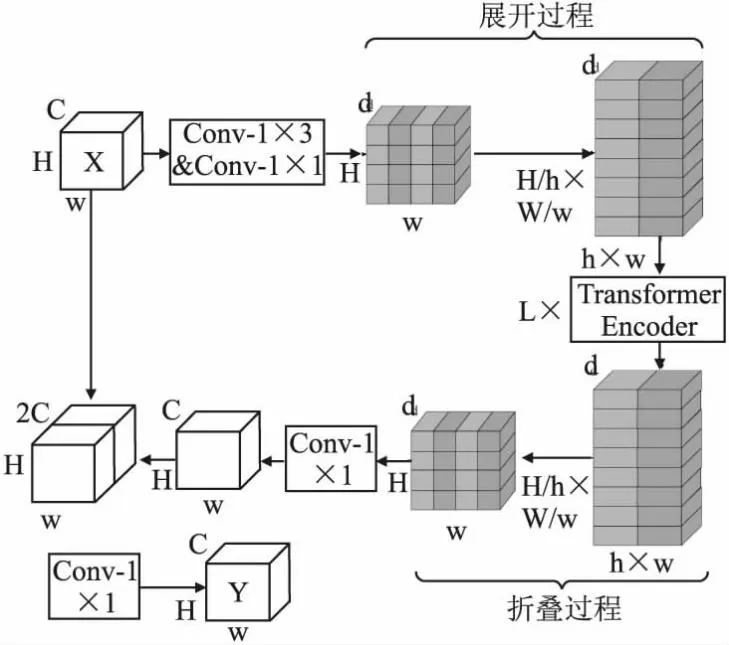
图4 SHViT Block的架构Fig.4 Architecture of the SHViT Block
SHViT模型的架构如图5所示.首先,经过一个步长为2,3×3的卷积层进行下采样,将矩阵的大小改变成112×112,再经过3个MobileNetV2块,进行3次下采样,矩阵的大小变为14×14.然后,该矩阵经过12个2×1的patch SHViT block后得到一个大小为14×14的特征,再经过1×1的卷积层对特征的通道数进行改变.最后,经过全局池化层后减少特征的大小,并通过线性层后得到分类的结果.

图5 SHViT模型的架构Fig.5 Architecture of the SHViT model
3 实验设计及结果分析
3.1 实验环境
本文实验环境使用的操作系统是windows11,CPU使用的是Intel Core第12代处理器i7-12700F,GPU使用的是Nvidia 3090Ti显卡,显存的大小为24G,内存的大小为32G.另外本文使用的编程语言是Python,版本为3.8,深度学习框架使用的是Pytorch[20],版本为1.12.0.
3.2 实验指标
本文实验的模型评价指标使用了accuracy(准确率)、precision(精确率)、recall(召回率)、F1-score 4个指标.这些指标的计算方式在公式(3)~公式(6)中给出:
(3)
(4)
(5)
(6)
TP代表被模型预测为正类的正样本,TN代表被模型预测为负类的负样本,FP代表被模型预测为正类的负样本,FN代表被模型预测为负类的正样本.
(7)
由于y是一个长度为q的独热编码向量,所以除了当前项j以外的所有项都消失了.由于所有yi都是预测的概率,所以它们的对数永远不会大于0.
为了体现模型具有轻量化的特点,选用了模型参数量、模型计算量和推理时间3个指标对模型进行评价.模型参数量和计算量是衡量深度学习模型的指标之一,参数量相当于是算法中的空间复杂度,计算量相当于是算法中的时间复杂度.在硬件层面上,参数量相当于是占用计算机存储资源的空间,计算量相当于是计算时间.计算量FLOPs并不是衡量网络效率的一个充分指标,因为它没有考虑与模型推理相关的因素,如设备的内存访问、并行度和特性.本文引入了一个新的指标,即模型的推理时间.首先,使用pytorch的torch.cuda.synchronize()函数,将异步模式转换成同步模式.然后,在当前轮次的GPU执行函数完成之后才停止计时.最后,使用torch.cuda.Event来跟踪GPU程序并更新模型的推理时间.模型参数量和计算量主要集中在卷积层和全连接层.
卷积层的参数量和计算量如公式(8)和公式(9)所示:
parameters=(kw×kh×Cin+1)×Cout
(8)
FLOPs=[(Cin×kw×kh)+(Cin×kw×kh-1)+1]×Cout×w×h
(9)
kw和kh分别代表卷积核的宽和高,Cin和Cout分别代表卷积层的输入通道数和输出通道数,w和h代表特征图的宽和高,公式中的1代表卷积层中的偏置.
全连接层的参数量和计算量如公式(10)和公式(11)所示:
parameters=(Nin+1)×Nout
(10)
FLOPs=[Nin+(Nin-1)+1]×Nout
(11)
Nin和Nout分别代表全连接层中的输入和输出维度的大小,公式中的1代表卷积层中的偏置.
3.3 实验数据集
IoT-23是捕获自物联网设备的一个新的网络流量数据集.该数据集于2020年1月首次发布,获取流量的时间从2018年持续到2019年.该物联网流量数据集的目标是为研究人员在开发机器学习算法时提供真实的和带标签的物联网恶意流量和良性流量的大型数据集.该数据集由23个不同的物联网场景捕获的网络流量组成.这些场景被分为20个来自感染恶意软件的物联网设备的网络流量捕获文件(Pcap文件)和3个真实物联网设备的Pcap文件.在每个恶意的场景中,一台树莓派会执行一个特定的恶意软件,该软件能够使用多种协议并执行不同的操作.
场景名称中的H代表CTU-Honeypot-Capture,M代表CTU-IoT-Malware-Capture.本文只挑选了其中的10个场景作为数据集,表2显示了物联网受到僵尸网络感染场景和良性场景的一些数据.该数据集通过捕获3种不同物联网设备(Philips HUE智能LED灯、Amazon Echo家庭智能助手和Somfy智能门锁)的网络流量,捕获了3种良性场景下的网络流量.这3种物联网设备都是真实的硬件,提供真实网络行为的数据.所有场景都运行在一个受控制的网络环境中,没有限制互联网连接,就像真实的物联网设备一样.在10个物联网场景中各种攻击类型的标签分布如表3所示.

表2 10个物联网场景中网络流量的汇总数据Table 2 Summary of network traffic in ten IoT scenarios

表3 10个物联网场景中各种攻击类型的标签分布Table 3 Iabels distribution of various attack types in ten IoT scenarios
3.4 实验设置及结果
本次实验使用SHViT模型的参数如表4所示.

表4 SHViT模型的参数设置Table 4 Parameters setting of SHViT model
SHViT模型在经过训练后的loss和准确率数据如表5所示.

表5 SHViT模型的loss和准确率Table 5 Loss and accuracy of SHViT model
SHViT模型在恶意流量的分类问题上的准确率如图6所示.

图6 使用SHViT模型进行恶意流量分类的准确率Fig.6 Accuracy of malicious traffic classification using SHViT model
3.5 实验结果分析与对比
在IoT-23数据集上,恶意流量二分类的SOTA方法是Ullah[10]等人提出的基于LSTM模型的方法,恶意流量多分类的SOTA方法是Ullah[10]等人提出的基于CNN-BiLSTM模型的方法.与本文使用的ViT模型实验结果对比如表6所示.

表6 ViT模型与SOTA模型的实验结果对比Table 6 Comparison of experimental results between ViT model and SOTA model
ViT模型引入了在自然语言处理领域中的Transformer架构,通过学习序列中的近距离和远距离依赖关系,可提升分类的准确率.而LSTM模型无法学习到序列中过长的依赖关系,在恶意流量识别问题上达到高精度的原因是设计了一种特殊的特征集,显著提升识别的准确率.而ViT模型使用的是本文提出的PS2GI方法处理后的灰度图片,排除了人为因素的影响,得到的实验结果更具代表性.由表6可知,ViT模型和LSTM模型在恶意流量二分类情况下的实验结果表明在准确率指标上没有差距.在F1-scorre指标的对比上,ViT模型比LSTM模型低0.08%左右.ViT模型和CNN-BiLSTM模型在恶意流量多分类情况下的实验结果表明ViT模型比CNN-BiLSTM模型在准确率指标上持平.本文首次将ViT模型应用在恶意流量识别问题上,具有创新性.
SHViT模型考虑到恶意流量数据集是灰度图片并且相邻像素块之间的关系,采用了一种基于简化后HViT模型的方法.该方法通过降低Transformer Encoder模块中全连接层的维度和MLP模块隐藏层的维度的方式减少参数量,通过简化Transformer Encoder模块中多头自注意力机制减少了计算量,并在SHViT Block前使用MobileNetV2模型进行下采样.ViT-B/16模型和SHViT模型在参数量上的对比如图7所示,本文提出的SHViT模型对比ViT模型,在二分类情况下的准确率指标降低了0.13%,在多分类情况下的准确率降低了0.17%.该模型在降低参数量和计算量的同时,还保证恶意流量识别的准确率.

图7 两种模型的参数量对比Fig.7 Comparison of number of parameters for two models
原始的ViT模型参数量巨大,达到86M,模型的输入是RGB图片,通道数为3,而本文的输入是单通道的灰度图片,并且将ViT模型中Transformer Encoder模块的全连接层的输入和输出维度的大小都设置为原来的1/3,ViT模型的参数量降低至1/9,仍然存在参数量过大的问题.本文提出的SHViT模型则是将HViT模型中的CNN模块部分替换为MobileNetV2模型,同时将Transformer Encoder模块的全连接层的输入和输出维度的大小设置为原来的1/2,在降低模型参数量的同时,也降低恶意流量识别的准确率.ViT-B/16模型和SHViT模型在计算量上的对比如图8所示.

图8 两种模型的计算量对比Fig.8 Comparison of computation amount for two models
ViT模型中Transformer Encoder模块的多头注意力机制和前馈神经网络的计算量十分巨大.SHViT模型将HViT模型的CNN模块替换为MobileNetV2模型,降低了计算量.将Transformer Encoder模块的输入使用一种忽略特征图像左右相邻像素的展开方法生成两个序列,将这两个序列放入Transformer Encoder模块后即可降低一半的计算量.ViT-B/16模型的计算量最大,需要进行3.74×109次浮点运算(Floating Point Operations,FLOPs).本文提出的SHViT模型该改变了HViT模型中输入序列的长度,减少了多头自注意力机制的计算量,所以SHViT模型只需要进行2.18×109次浮点运算.ViT-B/16模型和SHViT模型在推理时间上的对比如图9所示.

图9 4种模型的推理时间对比Fig.9 Comparison of the inference time for the two models
ViT-B/16模型的推理时间在二分类的情况下的推理时间达到4.67ms,在多分类情况下达到4.76ms,GPU对Transformer架构的优化正在进行中,推理时间会进一步缩短.本文提出的SHViT模型增加了一定的模型复杂度,在改变HViT模型中输入序列的长度时耗费了一些时间,其在二分类情况下所需的推理时间达到6.29ms,在多分类情况下达到6.37ms.
4 结 论
本文提出了一种新的数据包图像化的表示方法,即PS2GI方法.使用该方法将会话中的数据包转换成灰度图片,得到灰度图片后直接作为深度学习模型的输入进行训练.针对恶意流量识别方法实现高精度、轻量化的问题,提出一种基于简化HViT模型注意力机制的方法.SHViT模型使用MobileNetV2模型对灰度图片进行特征提取和下采样.此后,提出一种忽略特征图像左右相邻像素的展开方法以生成两个序列.将这两个序列经过降低维度的Transformer Encoder模块后转换为原始特征图像的形状,再通过全连接层后得到恶意流量识别的结果.通过实验结果表明,该方法虽然牺牲了一定的准确率,对比ViT模型增多了推理时间,但换来了需要更小的参数量和计算量.未来的研究方向是扩展到其它数据集上进行实验,包括加密流量数据集,同时与更多的其它方法进行对比,并且对自注意力机制进行改进,设计一种更适用于恶意流量识别的注意力计算方法,可进一步提升恶意流量识别的准确率.
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
销售与市场(营销版)(2021年10期)2021-11-21
高技术通讯(2021年3期)2021-06-09
销售与市场(营销版)(2019年6期)2019-06-21
网络安全和信息化(2018年4期)2018-11-09
网络安全技术与应用(2017年9期)2017-09-20
自动化学报(2017年5期)2017-05-14
光学精密工程(2016年1期)2016-11-07
深圳信息职业技术学院学报(2013年3期)2013-08-22
电子设计工程(2011年24期)2011-06-09
