
融合视觉信息的协同知识注意力网络推荐模型
2024-02-27 09:02:08黄贤英高钰澜
小型微型计算机系统 2024年2期
陶 佳,黄贤英,高钰澜
(重庆理工大学 计算机科学与工程学院,重庆 400054)
0 引 言
随着互联网中数据的快速增长,在众多的在线服务中推荐系统发挥了重要作用,如视频[1]、新闻[2]、电子商务[3]等.具体而言,推荐系统(Recommender Systems,RS)通过用户和物品的历史交互来推断用户兴趣,然后寻找一部分满足其兴趣的物品为用户提供个性化推荐.传统的基于协同过滤(Collaborative Filtering,CF)的推荐系统利用用户和物品的属性以及用户的历史行为进行推荐,具有广泛应用.但是基于协同过滤的推荐系统存在数据稀疏和冷启动问题.
为了解决传统推荐算法中存在的上述两种问题,研究者提出将知识图谱(Knowledge Graph,KG)作为辅助信息纳入推荐系统,通过在知识图谱中提取丰富的实体之间的关系信息缓解数据稀疏和冷启动问题.如图1所示是一个使用知识图谱进行电影推荐示例,图中电影、演员、导演作为实体,而类型、表演、导演是实体之间的关系,知识图谱通过将电影和用户以不同的潜在关系联系在一起进行推荐.将知识图谱引入推荐系统的另一个好处是为推荐系统带来可解释性[4].如图1所示,user A喜欢电影“Wall·E”,电影“Wall·E”和“The Terminator”的类型都是科幻,所以可以推断user A可能也喜欢电影“The Terminator”.
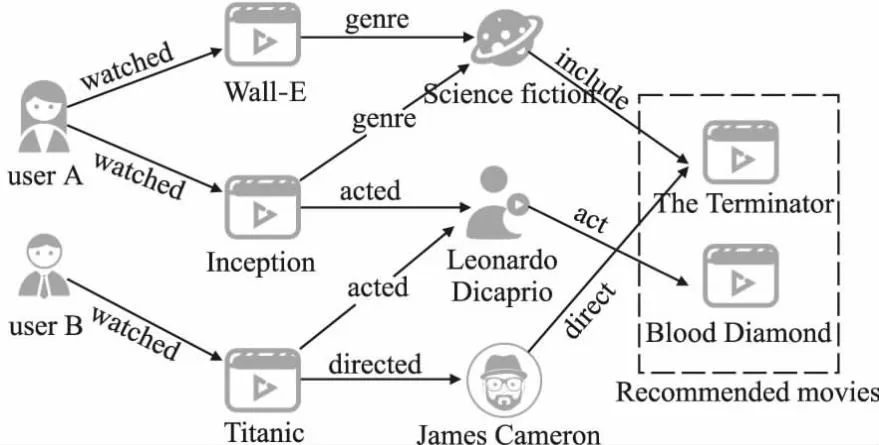
图1 电影推荐示例Fig.1 Example of a movie recommendation
推荐任务可以定义为,给定用户u和物品v,当前任务是预测用户u与物品v交互的概率.基于知识图谱的推荐系统将知识图谱作为辅助信息来丰富用户和物品的嵌入表示,进行预测.例如,Wang等人提出了KGCN[5]模型,将图卷积神经网络(Graph Convolutional Network,GCN)扩展到知识图谱中,有偏差地聚合邻域信息,得到物品的嵌入表示,提升了推荐准确率.KGNN-LS[6]考虑了不同用户对知识图谱中关系的偏好不同,将知识图谱转换为用户特定的权重图,使用图神经网络(Graph Neural Network,GNN)计算特定用户下,每一个物品的嵌入表示,在提升推荐性能的同时增强了模型的可解释性.上述工作都在一定程度上提升了推荐系统的性能表现,但是仍具有局限性:
一方面,现有的基于知识图谱的推荐模型[4-11],主要关注如何更有效地提取知识图谱信息,忽略了用户历史点击序列中不同物品对当前任务的重要性.用户的历史交互数据是丰富的,同时也是冗余的,在预测用户是否会喜欢某一物品时,往往只有部分的兴趣会影响用户的行为(点击/不点击).以电影推荐为例,用户喜欢电影“Avatar”,主要是因为他/她以前看过同为科幻类型的电影“Inception”,而不是他/她以前看过爱情片“Titanic”.所以,研究如何更有效地提取用户和物品历史交互数据中蕴含的信息,是非常有必要的.
另一方面,与物品相关的图像,如电影海报本身是对电影内容的介绍推广,蕴含了复杂内容的表达.与文字相比,图像能给用户直观的视觉冲击,留下深刻印象.现有的模型往往忽略了物品图像中蕴含的视觉信息对了解用户偏好以及物品的重要性.用户历史交互的物品都有其对应的图像,称其为用户的历史行为图像.这些图像是用户直接交互的对象,可以提供更多有关用户兴趣的视觉信息.如图2所示,观察user1历史观看的电影可以发现,user1观看的这几部电影的电影海报均以恐怖视觉效果呈现,表明用户可能会喜欢类似风格的电影.所以,可以为user1推荐相似风格的电影“Deadtime Stories”.物品的图像可以很好地帮助用户判断他/她是否对这个物品感兴趣.以电影推荐为例,一张生动的电影海报可以帮助用户判断他/她是否喜欢该电影,因为仅仅阅读电影的描述很难获得直观而深刻的印象[12].所以,从物品图像中提取视觉信息,可以利用它们更好地理解用户和物品.

图2 使用视觉信息推荐Fig.2 Use visual information recommendations
本文提出一种融合视觉信息的协同知识注意力网络推荐模型(Recommendation Model of Collaborative Knowledge Attention Network Fusing Visual Information,CKVI),该模型将协同信息和知识图谱信息视为两个不同空间中的信息,使用异构传播策略在用户-物品二部图和知识图谱中分别执行传播操作,同时使用注意力机制提取协同信息中的重要信息,得到协同信息和知识图谱信息.然后设计了一种聚合方法,学习不同条件下用户历史行为图像中不同图像的权重,了解用户的视觉偏好.综上所述,本文的贡献如下:
1)提出了一种新的推荐模型,称为CKVI.CKVI将视觉信息、协同信息和知识图谱信息有效结合起来用于推荐.
2)CKVI考虑到物品图像中蕴含的丰富信息,从网站收集图书封面以及电影海报图像,采用混合训练策略提取图像特征,丰富物品的表示.
3)用户的历史行为图像可以直观地反映用户的视觉偏好,设计了一种图像聚合方法,聚合用户的历史行为图像,捕获用户的视觉偏好.
4)用户历史交互的物品具有多样性,CKVI使用注意力机制动态捕获用户的历史偏好信息.
1 相关工作
知识图谱是表示来自多个领域的大规模信息的实用方法[13].迄今为止,知识图谱已经被创建并应用于多种场景,推荐系统是其最成功的应用之一,将用户和用户侧的信息集成到知识图谱中,更准确地捕获用户和物品之间的关系以及用户偏好.
目前,基于知识图谱的推荐算法主要分为3类:基于嵌入的、基于路径的、和基于传播的.基于嵌入的方法如:Zhang等人提出了CKE[7]模型,将CF与结构知识、文本知识和视觉知识结合起来进行推荐.Wang等人提出了DKN[8]模型,将知识图谱融入到新闻推荐中,提高了新闻推荐的准确性.基于嵌入的方法在使用知识图谱作为辅助信息进行推荐方面表现出高度的灵活性,但是这些方法中采用的知识图嵌入(Knowledge Graph Embedding,KGE)算法通常更适合与图相关的应用[14].基于路径的方法如:Wang等人提出了KPRN[9]模型,将知识图谱视为异构信息网络,提取基于元路径的潜在特征来为推荐提供额外的指导.基于路径的方法从图中提取元路径的潜在特征虽然易于理解,但是需要领域知识来定义有效的元路径,对于大规模的知识图谱来说是不实际.基于传播的方法如:Wang等人提出了RippleNet[4]模型,将用户的历史行为作为传播种子集,在知识图谱中执行传播操作来挖掘用户的潜在兴趣.Wang等人提出了KGAT[10]模型,将用户-物品二部图和知识图谱结合在一起称为协作知识图(Collaborative Knowledge Graph,CKG),然后使用图卷积网络递归地在CKG上传播,用于补充实体的嵌入表示.但是这两种方法都忽略了用户和物品历史交互数据中关键协作信息的重要性.Wang等人提出了CKAN[11]模型,采用异构传播策略对知识图谱信息和协作信息进行显示编码,并且在聚合时使用注意力机制为知识图谱中不同邻居分配权重.这些方法都有效缓解了传统推荐算法中的数据稀疏问题,但是当物品在训练数据中出现的次数较少时,它的参数将无法得到充分训练.物品图像中包含了丰富的视觉语义信息,可以为模型带来更好的泛化.
随着深度学习相关技术的广泛应用,图像表示任务也有了很大改进.使用深度学习相关技术提取图像特征[15],已被证明在大量任务中有效.之前的一些研究者试图在推荐系统中引入视觉信息来描述物品.Zhao等人提出了MF+[12]模型,从电影海报和静止帧中提取视觉特征,然后将它们嵌入到电影预测模型中.Wang等人提出了VRConvMF[16]模型,分别利用递归卷积神经网络[17](Recurrent Convolutional Neural Network,RCNN)和卷积神经网络(Convolutional Neural Network,CNN)从海报和描述性文本中提取的文本以及多级视觉特征进行推荐.Ge等人提出了DICM[18]模型,结合用户行为ID特征和行为图像对用户偏好进行建模,大大提高了推荐的准确性.多模态知识图谱通过图片、文本等信息去调整传统知识图谱中的语义关系.Sun等人提出了MKGAT[19]模型,提出了一种多模态图注意力技术,用于在多模态知识图谱上进行信息传播,然后使用得到的聚合嵌入表示进行推荐.这些方法表明了使用视觉信息可以有效提升推荐准确性.
2 模 型
CKVI 模型是一种端到端的模型.CKVI 分别提取协同信息、视觉信息、知识图谱信息,最后将3种信息结合起来进行推荐,模型结构如图3所示.CKVI由4个部分组成:协同注意力网络(Collaborative Attentive Network)、图像嵌入网络(Image Embedding Network)、知识图注意力网络(Knowledge Graph Attentive Network)、模型预测(Model Prediction).协同注意力网络利用注意力机制提取用户和物品历史交互数据中的相关信息,得到协同信息.图像嵌入网络采用混合训练的方法对物品图像进行建模,利用用户和物品的历史交互数据以及物品图像,得到用户的视觉兴趣.知识图注意力网络将用户和物品历史交互数据中的物品和知识图谱中的实体对应,在知识图谱中执行传播操作,得到知识图谱信息.模型预测将3种信息结合起来得到用户和物品的最终表示,最后输出预测结果.
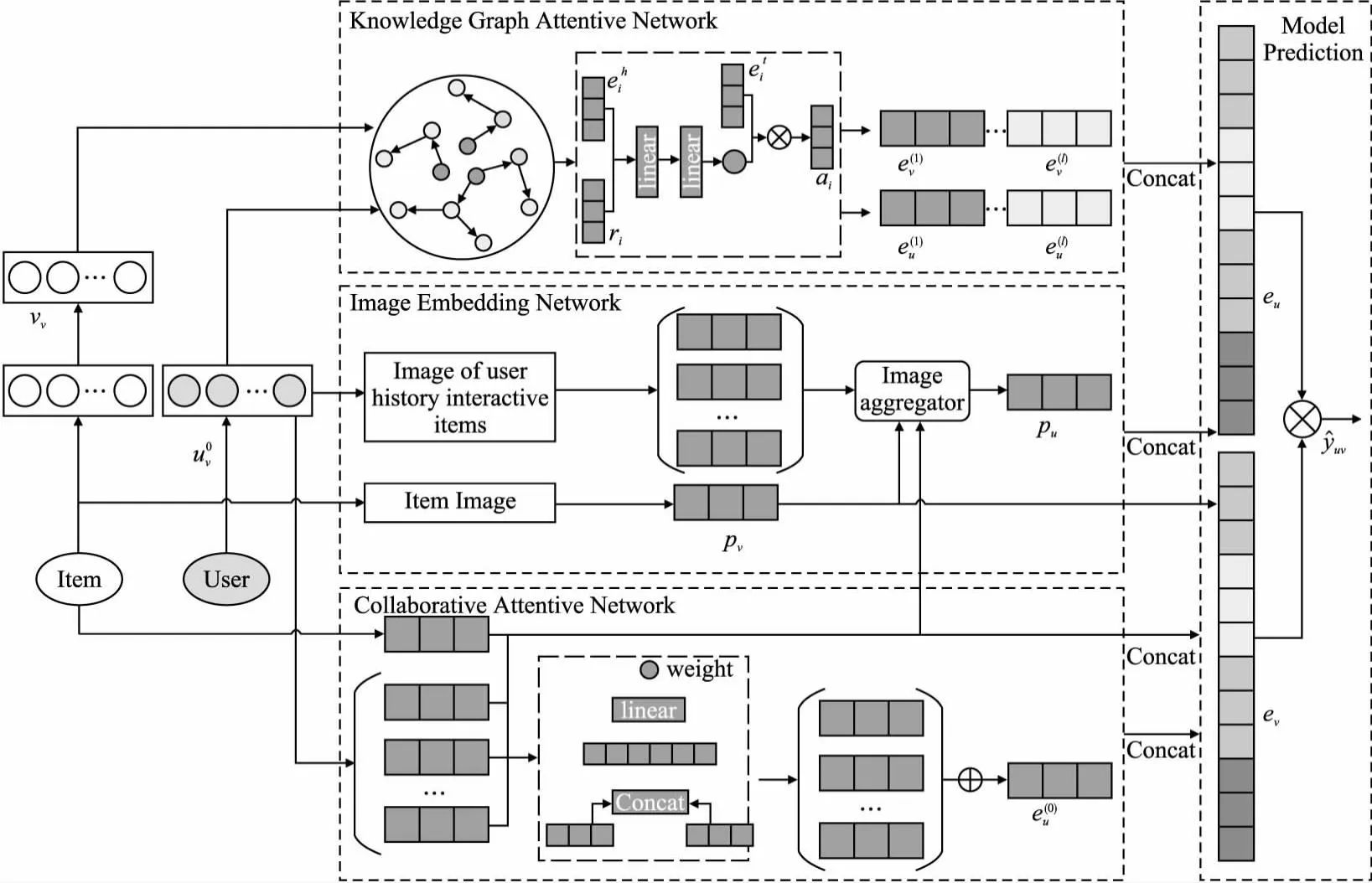
图3 CKVI 模型架构图Fig.3 CKVI model architecture diagram
2.1 符号说明
假设在某个推荐场景中,有M个用户U={u1,u2,…,uM}和N个物品V={v1,v2,…,vN}.根据用户和物品的历史交互数据,可以得到一个用户-物品交互矩阵Y∈M×N,其中yuv=1表示用户u已经与物品v交互,否则yuv=0.知识图谱中边的信息用G={(h,r,t)∣h,t∈ε,r∈R}表示.其中每个知识三元组(h,r,t)表示头实体h和尾实体t之间存在关系r,ε和R是知识图谱中实体和关系的集合.采用集合A={(v,e)∣v∈V,e∈ε}阐明物品和实体之间的对应关系.其中(v,e)表示物品v可以与知识图谱中的实体e对应.
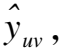
2.2 协同注意力网络
用户的历史行为在一定程度上反映了用户的偏好信息.通过与用户u相关的物品来表示用户u.通过用户u交互的历史数据来定义用户u的历史交互物品集,定义如公式(1)所示:
(1)
具有相似行为偏好的用户喜欢的物品也会相似,这些物品可以对物品的特征表示做出贡献,称为物品的协作邻居,定义如公式(2)所示:
Vv={vu|u∈{u|yuv=1}andyuvu=1}
(2)
用户的历史行为具有多样性,预测用户是否会喜欢目标物品时只取决于用户历史行为的一部分,使用注意力机制为用户的历史点击物品分配不同的权重,用户u的历史交互物品集表示如公式(3)所示:
(3)
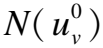
(4)
其中σ表示sigmoid激活函数,W0和b0是可训练的权重矩阵和偏置,‖表示连接操作.
2.3 图像嵌入网络
与文本描述相比,物品的图像往往包含更多细节的、直观的信息,具有更强的视觉冲击力,直接影响用户偏好.因此,提取物品的丰富的视觉特征,能有效挖掘物品特征.图像嵌入层将像素级的视觉信息提取为语义嵌入向量.
VGG19在提取图像特征方面具有很好的泛化能力,VGG19包含16个卷积层和3个全连接层.考虑到VGG19的复杂性,将整个网络分为一个固定部分和一个可训练部分.固定部分采用前18层预先训练的VGG19网络,具体来说从Conv1到FC7,得到4096-d的向量.可训练部分采用3层的全连接网络(4096-1000-128-64)得到图片的特征表示,表示如公式(5)和公式(6)所示:
s0=Tanh(Waporigin+ba)
(5)
pv=WcPReLU(Wbs0+bb)+bc
(6)
其中porigin表示固定部分输出,pv表示物品v的图像特征.
用户的历史行为图像可以增强行为表示,有助于了解用户的视觉偏好.考虑到用户的历史行为图像对捕获用户偏好的贡献不同,使用了图像聚合器来聚合用户的历史行为图像,图像聚合器架构如图4所示.图像聚合器使用两个注意力通道,分别将图像特征和目标物品原始表示作为查询向量,两个注意力通道分别生成各自权重以及加权向量.用户的历史行为图像表示为两个通道的加权向量加权求和,表示如公式(7)所示:
(7)
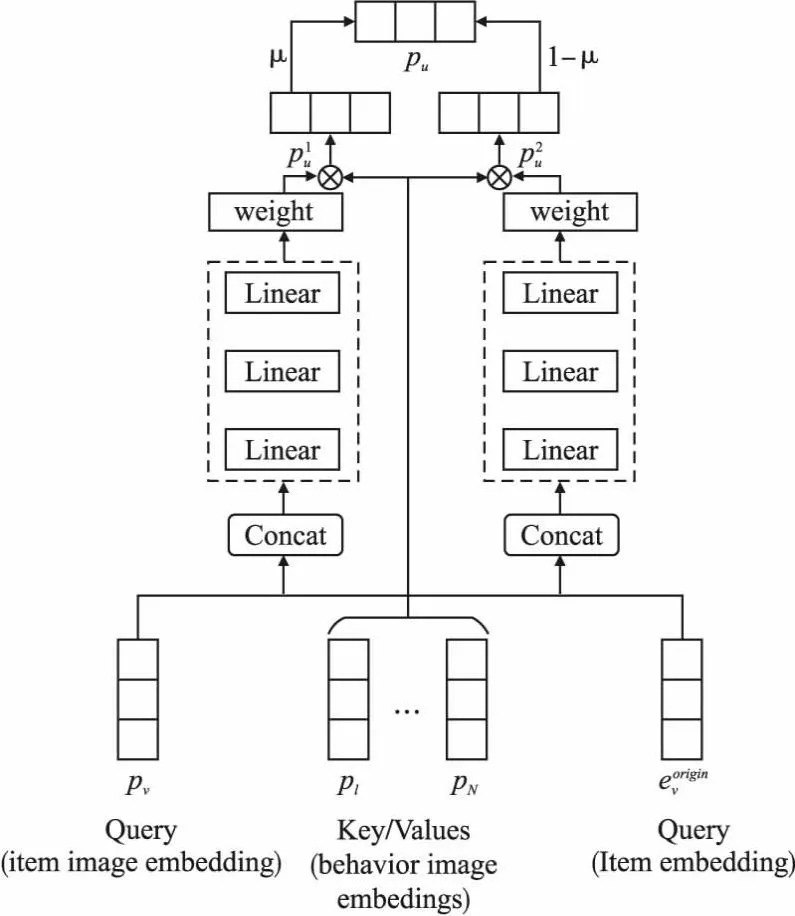
图4 图像聚合器Fig.4 Image aggregator

(8)
(9)
其中pi表示用户历史交互的物品中,第i个物品对应的图像嵌入表示,pv表示目标物品图像的嵌入表示.
2.4 知识图注意力网络
知识图谱可以连接用户的历史交互记录,沿着知识图谱中的边来传播知识关联,可以补充用户和物品的嵌入表示.
2.2节中通过用户的历史交互数据获得了用户历史交互的物品集,将其与知识图谱中的实体对应起来,作为用户在知识图谱中传播的初始实体集,定义如公式(10)所示:
(10)

物品的协作邻居和知识图谱中的实体对应后得到物品在知识图谱中传播的初始实体集,定义如公式(11)所示:
(11)
其中Vv是物品的协作邻居.
用户和物品的初始实体集在知识图谱中执行传播操作时不同距离的实体集,定义如公式(12)所示:
(12)
其中l表示与初始实体集的距离,o是u和v的统一占位符.根据实体集定义,用户u和物品v在知识图谱传播中第l层三元组集,定义如公式(13)所示:
(13)
当每个尾实体在知识图谱中具有不同的头部实体和关系时,其具有不同的含义和潜在向量表示.假设(h,r,t)是知识图谱传播中第l层实体集中第i个实体所在三元组,根据头实体和关系为尾实体添加注意力权重后表示为ai,定义如公式(14)所示:
(14)
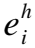
(15)
(16)
(17)
给定用户u或物品v在知识图谱中传播时实体集和三元组集的定义,用户u或物品v第l层三元组表示如公式(18)所示:
(18)
2.5 模型预测
经过协同注意力网络、图像嵌入网络、知识图注意力网络之后,用户u和物品v的表示集公式化如公式(19)和公式(20)所示:
(19)
(20)
将用户和物品表示集中的向量进行拼接,得到最终用户和物品的向量表示,表示如公式(21)和公式(22)所示:
(21)
(22)
模型的预测使用表示的内积来预测用户对该物品的偏好得分,计算方法如公式(23)所示:
(23)
本文为每个用户提取与正样本数量相同的负样本,用于平衡正负样本的数量.使用Adam[20]优化器优化模型的参数来最小化损失函数,保证模型训练的效果.CKVI模型的损失函数定义如公式(24)所示:
(24)
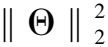
3 实 验
本节将介绍实验数据以及评价指标,通过在两个真实数据集Book-crossing和MovieLens上进行实验,对模型的推荐性能进行评价,实验内容包括:
1)CKVI与基线模型对比.
2)视觉信息对模型性能的影响.
3)图像聚合器对模型性能的影响.
4)协同信息中注意力机制对模型性能的影响.
5)模型的超参数设置对模型性能的影响.
3.1 实验数据及评价指标
3.1.1 实验数据
为了评估模型有效性,实验选用书籍领域和电影领域两个数据集.Book-crossing数据集是从Book-Crossing社区收集的,包含了17040个用户和11907本书籍,Book-crossing数据集是最不密集数据集之一.MovieLens中包括6036个用户和2474部电影.数据集的统计信息如表1所示.本实验将所有数据集按照0.6/0.2/0.2的比例划分为训练集、验证集、测试集.

表1 实验数据集信息Table 1 Statistics of experimental datasets
由于Book-crossing数据集和MovieLens数据集中用户和物品的交互都是显示反馈,需要将它们转换为隐式反馈,使用1表示正样本(MovieLens评分阈值设置为4,Book-Crossing由于其稀疏性,没有设置阈值).对于负样本,从每个用户的未观察项目中随机抽取与正样本大小相等的样本.
3.1.2 评价指标
本实验通过使用度量标准特征曲线下面积(Area Under Curve,AUC)和F1 Score来度量模型的推荐准确性.AUC是推荐系统中常用的模型评价指标之一,AUC的值越大,表明模型性能越好.F1的值是精准率与召回率的调和平均数,F1的值越大,表明模型性能越好.
3.1.3 实验超参数设置
本文在实验中使用PyTorch实现了所需的模型.实验中向量嵌入表示的维度设置为64,BatchSize设置为2048,学习率设置为0.002.MovieLens数据集的用户初始实体集的大小设置为80,物品初始实体集的大小设置为48,层数设置为2.Book-crossing数据集的用户初始实体集的大小设置为32,物品初始实体集的大小设置为64,层数设置为2.为了初始化模型参数,采用默认的Xavier[21]初始值设定项.
3.2 CKVI与基线模型的对比
为了验证CKVI 模型的有效性,实验1将CKVI 与基线模型进行对比,基线模型包括KGCN[5],KGNN-LS[6],CKAN[11],LKGR[22],模型参数与基线模型保持一致.
KGCN[5]:将知识图谱中每个实体的邻域采样作为其感受域,然后在计算给定实体的表示时有偏差地聚合邻域信息,可以学习知识图谱的高阶结构信息和语义信息.
KGNN-LS[6]:将知识图谱转换为用户特定的加权图,既可以学习知识图谱的语义信息,又可以学习用户的个性化兴趣.
CKAN[11]:它使用异构传播策略编码协同信息和知识图谱信息,并且使用知识感知注意力机制有差别地聚合邻居信息,最后将两种信息结合起来进行推荐.
LKGR[22]:它在双曲空间中采用不同的信息传播策略来显式地编码来自历史交互和知识图谱的异构信息,并且使用注意力机制为知识图谱中的邻居分配不同的权重,最后在双曲空间中聚合两种信息用于推荐.
表2展示了CKVI 在MovieLens和Book-crossing数据集上的整体性能,对比模型中最优结果使用下划线标出,CKVI模型实验结果加粗标出,观察实验结果可以看出CKVI 优于基线模型.具体来说,MovieLens数据集中CKVI 相比KGCN、KGNN-LS、CKAN、LKGR的AUC提升了3.33%、2.69%、1.6%、1.6%,Book-Crossing数据集中CIKG相比KGCN、KGNN-LS、CKAN、LKGR的AUC提升了7.84%、7.89%、1.79%、3.51%.MovieLens数据集中CKVI 相比KGCN、KGNN-LS、CKAN、LKGR的F1提升了3.43%、2.73%、1.53%、1.86%,Book-Crossing数据集中CIKG相比KGCN、KGNN-LS、CKAN、LKGR的F1提升了5.17%、4.91%、1.24%、3.06%.

表2 CKVI 与基线模型性能对比Table 2 Performance comparison between CKVI and baseline model
3.3 视觉信息对模型性能的影响
CKVI使用了视觉信息来丰富用户和物品的表示,本小节对其有效性进行了验证.实验2通过去除用户和物品的表示集中用户历史行为图像pu,和物品图像pv来测试视觉信息对模型性能的影响.将去除视觉信息后的模型称为CKVI-V,实验结果如表3所示,使用视觉信息后模型CKVI 较不使用视觉信息的模型CKVI-V,在MovieLens和Book-crossing数据集上AUC和F1均有提升,实验结果表明引入视觉信息可以进一步挖掘用户的偏好信息,补充物品的嵌入表示,提高模型的推荐性能.

表3 视觉信息对实验结果的影响Table 3 Effect of visual information on experimental results
3.4 图像聚合器对模型性能的影响
CKVI为了更准确地捕获用户的视觉信息,使用了图像聚合器来有差别地聚合用户历史行为图像,本小节测试了图像聚合器的有效性.实验3将使用图像聚合器聚合用户历史行为图像的方式改为求均值的方式来测试图像聚合器对模型性能的影响,去除后模型称为CKVI-A.实验结果如表4所示,使用聚合器后MovieLens数据集和Book-crossing数据集AUC和F1均有提升,实验结果表明使用图像聚合器可以更好地捕获用户的视觉信息,有效提升推荐性能,因为图像聚合器使用注意力机制自适应地捕获与当前任务最相关的行为,并且考虑到不同类型的特征之间的交互重要性,可以更准确地捕获用户偏好.

表4 图像聚合器对实验结果的影响Table 4 Effect of image aggregator on experimental results
3.5 注意力机制对模型性能影响
CKVI使用注意力机制加强模型对协同信息中重要信息的记忆能力,本小节测试了注意力机制对模型性能的影响.实验4将用户历史点击物品表示时的注意力机制,改为使用传统方法取最大值(MaxPooling)、求和(SumPooling)以及使用余弦相似度(CosSim)的方式,实验结果如图5和图6所示.实验结果表明使用注意力机制后,AUC和F1均有提升,表明使用注意力机制可以更精准地捕获用户兴趣,提高推荐准确率.

图5 注意力机制在MovieLens数据集中影响Fig.5 Impact of attention mechanism in MovieLens dataset
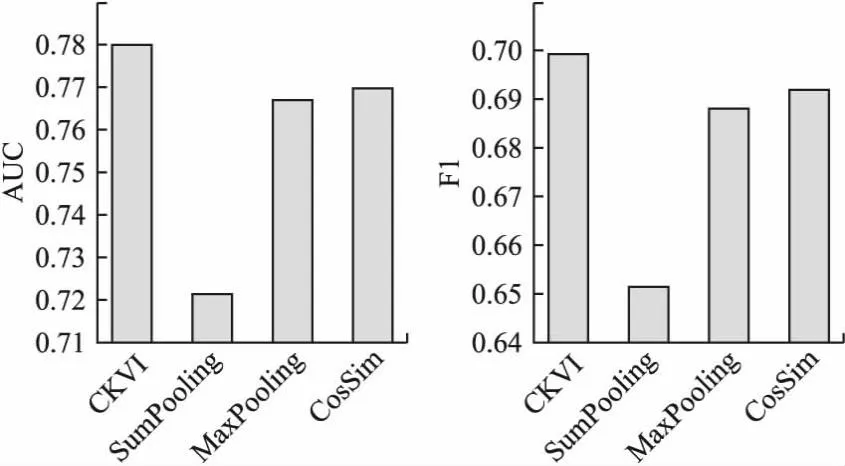
图6 注意力机制在Book-crossing数据集中影响Fig.6 Impact of attention mechanism in Book-crossing dataset
3.6 模型超参数设置对模型性能的影响
本小节在MovieLens和Book-crossing数据集上分析CKVI模型所使用的超参数.具体将涉及以下超参数:1)用户和物品的初始实体集大小;2)知识图谱传播深度
1)用户和物品的初始实体集的大小对模型性能影响.实验5通过改变用户和物品的初始实体集的大小来分析其对模型性能的影响.由于MovieLens和Book-crossing数据集稀疏性不同,所以两个数据集的用户初始实体集在不同的集合中搜索,Book-crossing数据集的用户初始实体集依次设置为{4,8,16,32,48},MovieLens数据集的用户初始实体集依次设置为{16,32,48,64,80}.物品初始实体集的大小依次设置为{16,32,48,64}.实验结果如表5、表6所示,观察实验结果发现,起初增加初始实体集的大小可以提高模型性能,达到最优值后模型性能开始降低.因为起初随着数据量的增大,模型可以不断获取相关信息来补充用户和物品的嵌入表示,达到最优值后,随着数据的增大模型在捕获有效信息的同时会引入越来越多的噪音,导致模型性能降低.

表5 MovieLens数据集中初始实体集的大小对性能影响Table 5 Impact of the size of the initial entity set in the MovieLens dataset on performance

表6 Book-crossing数据集中初始实体集的大小对性能影响Table 6 Impact of the initial entity set size in the Book-crossing dataset on performance
2)知识图谱传播深度对模型性能的影响.实验6将知识图谱传播深度分别设置为1,2,3来观察模型性能的变化,实验结果如表7所示,MovieLens和Book-crossing数据集中l取2时模型效果均达到最佳.观察实验结果发现,起初随着传播深度的增加模型性能提升,因为使用与实体相关的知识信息可以丰富实体的嵌入表示.当模型达到最优性能,l=3时模型性能开始下降,这可能是因为距离较远的实体包含的相关信息较少,会引入更多的噪音,导致模型性能降低.

表7 知识图谱传播深度对实验结果影响Table 7 Influence of the spreading depth of the knowledge graph on the experimental results
4 结 语
随着互联网中的数据呈爆炸式增长,提高推荐系统的性能成为了解决用户需求的重要手段,传统的推荐系统存在数据稀疏和冷启动问题,将知识图谱作为辅助信息引入到推荐系统中可以缓解数据稀疏和冷启动问题.本文提出一种融合协同信息、知识图谱信息、视觉信息的推荐模型.协同注意力网络层使用注意力机制在用户和物品的历史交互信息中动态地挖掘用户的偏好信息.在图像嵌入层,将VGG19划分为两部分,使用混合训练的方法提取物品图像特征,并且设计了一种聚合方法,聚合用户的历史行为图像,来增强用户的行为表示.在两个公开数据集上的结果,表明了提出模型的有效性.
本文在建模用户和物品的表示时,没有考虑到用户和物品自身的属性信息,在未来的研究中,将考虑使用用户和物品自身的属性信息来丰富用户和物品的嵌入表示,进一步缓解传统推荐算法的数据稀疏问题.另外,相似兴趣的用户喜欢的物品也会相似,在未来的研究中将尝试对用户进行聚类,在减少噪音的同时更精确地捕获用户兴趣.
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
少先队活动(2020年12期)2021-01-14 01:47:40
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
传媒评论(2017年3期)2017-06-13 09:18:10
中成药(2017年3期)2017-05-17 06:09:01
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
领导科学论坛(2016年9期)2016-06-05 14:59:58
小天使·一年级语数英综合(2015年8期)2015-07-06 06:23:32
