
一种用于答案选择的知识增强图卷积网络
2024-02-27 09:08郑超凡陈羽中徐俊杰
小型微型计算机系统 2024年2期
郑超凡,陈羽中,徐俊杰
(福州大学 计算机与大数据学院,福州 350108)
(福建省网络计算与智能信息处理重点实验室,福州 350108)
0 引 言
答案选择是问答领域的一个重要子任务[1],目标是根据问题从候选答案集合中选择最合适的答案,问答语义匹配是该任务的核心问题.
近年来,端对端的深度学习方法[2-27]成为当前自然语言处理领域研究的热点之一,并广泛应用于答案选择任务.基于深度学习的问答匹配模型通常基于融合注意力机制的卷积神经网络(Convolutional Neural Networks,CNN)[2,3]、循环神经网络(Recurrent Neural Network,RNN)[4-7]、图神经网络(Graph Neural Network,GNN)[8-10]或预训练语言模型[11-19].采用卷积神经网络获得问题、答案文本的局部语义信息.循环神经网络可以构建文本序列的语义依赖关系.注意力机制使得模型能够更加关注问答对中关键语义部分.根据不同单词之间的文本关系例如句法关系将问答对抽象成图数据结构,图神经网络则可以根据不同单词之间的文本关系将问答对抽象成图数据结构,对图节点间的依赖关系进行建模.基于大规模语料训练的预训练语言模型则在获得文本的潜在语义信息表示方面展现出巨大的优势.目前,已有许多研究工作提出了基于BERT[11]、RoBERTa[12]等预训练语言模型的问答匹配模型.此外,一些研究工作将知识图谱引入到答案选择任务之中[20-23].知识图谱中的事实背景包含大量实体信息,在问答匹配的过程中能够提供有效的常识性推理信息,提高答案选择的准确度.
现有的问答匹配模型在答案选择任务上取得了巨大进展,但仍存在一些亟待解决的问题.首先,现有的问答匹配模型主要专注于获得问题、答案文本中单词之间的上下文语义关联信息的特征表示,未充分考虑从语法结构的角度挖掘问题与答案之间的依赖信息,限制了模型对文本语义信息的理解.其次,现有的一些问答匹配模型虽引入了知识图谱,但是知识实体之间缺少上下文语义关联且未有效引导实体信息帮助模型学习不同语境下的正确语义表示,限制了模型性能的提升.最后,现有基于预训练语言模型的问答匹配模型通常将模型最后一层输出视为文本特征,忽略模型各编码层生成的语义信息,无法充分提取问答对的语义特征.针对上述问题,本文提出一种知识增强的图卷积网络KEGCN.主要贡献如下:
1)KEGCN提出了一种基于图卷积神经网络的问题-答案结构信息提取机制.该机制首先将问题、答案文本转换为具有句法结构依赖关系的图数据结构,计算句法结构图中不同单词节点之间的依赖关联权重.通过节点之间存在的结构依赖关系引导图卷积神经网络中语义信息的传播与更新,从而得到符合句法规则的文本结构信息特征,增强对问答对的语义信息的理解.
2)KEGCN提出了一种基于自注意力门控网络的扩展知识语义构建机制.该机制首先获得问题与答案文本在知识图谱中多跳扩展的知识节点.之后,利用自注意力机制构建知识实体之间的上下文语义关联性,并将问题、答案的知识特征经过门控网络进行过滤融合,减少知识噪声的影响,提高模型的鲁棒性.
3)针对预训练语言模型各编码层生成的不同粒度的语义信息,KEGCN提出多尺寸的卷积神经网络提取问答对的多粒度全局语义信息特征,从而解决模型文本语义特征提取不充分的问题.
1 相关工作
近年来,基于深度学习的问答匹配模型凭借其端对端的训练方式和强大的特征提取能力广泛地应用于答案选择任务之中.该任务的本质核心在于文本语义匹配,通过深度学习模型分别学习答案句子的不同文本特征表示,并计算特征之间语义相似性得分完成问答匹配.Severyn等人[3]提出一种基于CNN的问答匹配模型,通过逐层的卷积和池化操作将问题、答案的语义信息编码为高级向量,并采用逐点比较的方法将问答对重新进行排序.Chen和Hu等人[5]提出CA-RNN模型,在利用RNN对文本建模的基础上,提出一种上下文对齐的门控机制对问答对的隐藏状态进行更新.Zhou等人[6]提出循环卷积神经网络(Recurrent Convolutional Neural Network,RCNN)模型用于答案选择.该模型将CNN与RNN相结合,以捕获问答之间的语义匹配以及嵌入在问答序列之间的上下文相关性.注意力机制[24-27]可以使得模型更加关注句子中的一些关键信息,从而获得更加精确的问答对特征表示.Sha等人[24]提出了从问题句子的疑问词、动词以及问题语义等方面进行注意力特征建模,并使用co-attention获得问题、答案的交互特征.Yang等人[25]在通过CNN对文本表征的基础上,采用注意力机制对齐问答对之间的上下文语义特征和原始词嵌入点乘特征,极大的提高问答的匹配精度.Tian等人[8]提出了多视角图编码器(Multi-Perspective Graph Encoder,MPGE)应用于答案选择任务.MPGE分别从问答对之间的实体共现、句子距离、语义相似度以及动态注意力等多个角度构建问答之间的关系图,并利用GCN对不同关系图进行编码,最后获得聚合多种视角的问答特征表示.
近年来,预训练语言模型的出现极大推动自然语言处理领域的发展.预训练语言模型可以从海量的无标注文本中学习到潜在的语义信息.一些研究学者开展将预训练语言模型应用于答案选择任务的研究工作.Devlin等人[11]提出一个基于Transformer 架构[26]训练自然语言处理的通用模型BERT,并将其应用于答案选择任务.Laskar等人[13]将上下文的词嵌入送入BERT模型中进行问题与答案句子的相似度建模.Shao等人[14]提出BERT-MatchLSTM模型,在BERT模型获取问答对的深层次语义表征的同时利用BiLSTM进行序列匹配聚合.Li和Zhou等人[15]提出了多片段级交互网络(Multiple Fragment-level Interactive Network,MFIN),应用BERT和BiGRU以及动态分片注意力机制构建问答对的关键片段,从而实现片段级别的问答语义交互.
近年来,一些研究工作将知识图谱引入答案选择任务,也取得了一定进展.Li和Wu等人[20]提出词网增强层次模型,利用WordNet中同义词集和上位词来增强问答句中的词嵌入表示,并设计了两个基于同义词集和上位词的关系分数的注意力机制,从而捕获更加丰富的问答交互信息.Yang等人[21]提出一种知识丰富的层次化注意力机制,利用问答对中的上下文信息和知识库中的常识信息,捕获问答对之间的多层次交互,将问答中的语境信息和常识知识在3个粒度级别上充分融合.
2 模 型
2.1 任务定义

2.2 模型架构
本文提出的KEGCN模型架构如图1所示,模型主要分为5层:文本特征表示层、知识特征表示层、特征编码层、特征融合层以及分类层.其中,特征编码层包括文本结构特征编码、外部知识特征编码以及全局语义特征编码3个模块.首先,文本特征表示层采用预训练模型BERT获取问题、答案的语义特征表示,以及问题-答案的全局语义特征表示[CLS]序列.知识特征表示层利用知识图谱进行文本-知识匹配和多跳知识节点扩展.将获得知识节点信息转换为低维的向量表示,从而得到文本的知识扩展序列特征表示.特征编码层中的文本结构特征编码模块则根据问题-答案之间的句法结构依赖关系,通过图卷积网络获得文本之间的结构化信息.外部知识特征编码模块包含了自注意力门控机制,对来自知识图谱的信息进行学习,从而获得丰富的知识信息.全局语义特征编码模块利用多尺寸的卷积神经网络来获取多粒度的问题-答案全局语义特征信息.融合层将问答对的语义信息、结构信息以及外部知识信息进行融合,得到用于答案选择的最终特征表示.最后,分类层通过学习分类函数来预测给定问题的答案标签概率分布.

图1 KEGCN整体架构Fig.1 Overall architecture of KEGCN
2.3 文本特征表示层
(1)
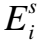
(2)
首先,令BERT模型的最后一层输出为Es,根据[CLS]和[SEP]标签在Es序列中的位置,对问题、答案的语义特征表示进行切分,从而分别获得问题、答案的语义表示Eq和Ea:
(3)
(4)
(5)
其中Eq∈m×d,Eq∈n×d,m为问题序列的长度,n为答案序列的长度,d为表征向量的维度.
连接BERT的各编码层输出中的[CLS]标记,得到问题与答案的全局语义序列Ecls:
(6)
其中Ecls∈l1×d,l1为BERT的编码器层数,d为表征向量维度.
2.4 知识特征表示层
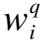

(7)

(8)
其中Cq∈l2×d,Ca∈l3×d,l2=(m+max_n×m)为问题知识扩展序列的长度,l3=(n+max_n×n)为答案知识扩展序列的长度,d为知识表征向量的维度.为的扩展知识节点,max_n为扩展节点的个数.
2.5 特征编码层
2.5.1 文本结构特征编码模块
文本结构特征编码模块利用多层图卷积神经网络在问题-答案文本的句法依赖图上进行卷积操作,通过句法结构依赖关系进行传播并学习邻接节点的信息来更新自身节点的结构信息.从而获得问题-答案之间的结构信息特征.

(9)
(10)
对文本序列Xqa依赖解析,生成无向的句法结构依赖图并转换为相对应的(m+n)阶句法结构依赖邻接矩阵A:
(11)
(12)

(13)
(14)


(15)
(16)

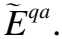
(17)
(18)
(19)

2.5.2 外部知识特征编码模块

αq=softmax(tanh(W6Eq×(W7Cq)T))
(20)
(21)
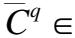

(22)
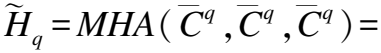
(23)
(24)
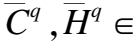
为了充分融合问题与答案的知识上下文表征Hq,Ha,抑制知识噪声,KEGCN利用门控机制对问题与答案的知识上下文进行过滤融合,获得问题-答案知识上下文特征Hqa:
g=sigmoid(W15Hq:W16Ha)
(25)
Hqa=(1-g)⊙Hq+gt⊙Ha
(26)
其中Hqa∈(l2+l3)×d,l2为Cq长度,l3为Ca长度.W15,WQ6为可训练参数,“:”为连接操作.

(27)
(28)

2.5.3 全局语义特征编码模块

(29)
其中MCNN()表示多尺寸CNN.
2.6 特征融合层
(30)
(31)
2.7 特征融合层
将问答特征表示Efinal通过一个线性分类层并使用softmax函数进行归一化处理,生成问题-答案之间的相关性分数f(q,a)∈[0,1]:
f(q,a)=softmax(W19Efinal+b4)
(32)
KEGCN在训练过程中,采用交叉熵损失函数作为目标函数,计算公式如下:
(33)
其中f(q,a)i∈[0,1]是由softmax分类器计算出的问题-答案的相关性分数,yi∈[0,1]是二元分类标签.
3 实 验
3.1 数据集与评价指标
本文使用WikiQA和TrecQA(TrecQA-CLEAN)两个数据集对KEGCN模型进行评估.WikiQA数据集是使用最广泛的公开数据集之一,其内容收集于英文维基百科之中.TrecQA数据集中的数据是从文本检索会议QA track 8-13 收集得到.TrecQA包含两个版本(TrecQA-RAW,TrecQA-CLEAN),两个版本的区别在于在TrecQA-RAW中,一些问题没有答案或者只有正确/错误答案,在TrecQA-CLEAN中则将这些问题去除.为了减少数据集噪声对模型训练造成影响,本文选用TrecQA-CLEAN版本数据集.WikiQA和TrecQA数据集的统计信息如表1所示.

表1 WikiQA和TrecQA数据集统计信息Table 1 Statistics of WikiQA and TrecQA datasets
本文使用MAP( Mean Average Precision)和MRR(Mean Reciprocal Rank)两个指标衡量模型的性能.
3.2 实验设置与对比模型
KEGCN模型基于Pytorch框架实现,使用Tesla-P100 GPU进行实验.预训练语言模型使用由 huggingface 官方提供的 BERT-base-uncased 模型,BERT-base-uncased包括12层transformer编码层,词嵌入维度为768,12个注意力头.预训练模型的最大输入长度为128个词,若超过将会被截断.外部知识图谱采用ConceptNet 提供的300维词嵌入.知识匹配过程中,未匹配到的单词通过在正态分布N(0,0.05)中采样完成词向量初始化.问题-答案句法依赖图通过Spacy工具构建,输入的长度为当前batch中问题长度和答案长度之和的最大值,当问题和答案长度之和小于输入长度时用0补充.模型采用Adam优化器进行优化,初始学习率设置为2×105,并在训练过程中逐渐减小.batch_size大小为32.多尺寸卷积神经网络采用2个不同大小的卷积过滤器,过滤窗口大小设置为[2,4].知识扩展的多跳次数设置为2,扩展节点的个数max_n设置为3.GCN的层数K设置为2.知识编码中的自注意力机制的注意力头的数量为6,BiGRU的隐藏单元维度为768.
为了实验的公平性比较,除基于RNN的CARNN[5]、Cross-Bi-nGRUR[7]、WHEM[20]、KE-HNN[22]外,选择基于BERT-base的答案选择模型KHAAS[21]、BERT[11]、BERT-Transformer[17]、BERT-GSAMN[17]、MFIN[15]、CKANN-BERT[23]、CETE[13]、BERT-INTall[18]以及BERT-BIG[19]作为对比模型.
3.3 模型性能分析
KEGCN及对比模型的在两个数据集上的实验结果如表2所示,表中所有对比模型的结果均取自对应的文献.从实验结果可以看出,KEGCN模型在WikiQA数据集上的两项指标MAP和MRR分别达到85.7%和87.45%,均优于所有的对比模型,包括WHEM、KE-HNN、KHASS以及CKANN-BERT等同样使用外部知识的模型.与综合性能最好的基准模型BERT-INTall相比,KEGCN模型的MAP和MRR分别提升了1.77%和1.45%.在TrecQA数据集上,KEGCN的MAP值为90.57%,略低于BERT-GSAMN和CKANN-BERT;MRR值为95.95%,略低于BERT-BIG.但是,KEGCN在WikiQA数据集上取得了远优于上述模型的MAP和MRR值.综合比较,KEGCN获得了最优的总体性能,且模型的鲁棒性更佳.

表2 KEGCN与基准模型的性能对比Table 2 Overall performance of KEGCN and baseline models
3.4 消融实验
本节通过消融实验分析KEGCN的各模型对其整体性能的贡献程度.KEGCN的消融模型包括KEGCN w/o GCN、KEGCN w/o KG,KEGCN w/o CNN.KEGCN w/o GCN表示从KEGCN中去除文本结构编码模块,KEGCN w/o KG表示在KEGCN中去除外部知识编码模块.KEGCN w/o CNN表示不利用CNN捕获BERT各编码层中的多粒度全局语义信息,仅将BERT最后一层输出的[CLS]视为全局语义特征与问答对文本特征相结合.
消融实验的结果如表2所示,从不同消融模型的性能表现来看,KEGCN w/o GCN的性能最差,表明利用图卷积网络得到符合句法规则的文本结构信息特征,对增强对问题、答案文本的理解具有重要作用.KEGCN w/o KG和KEGCN w/o CNN的性能分别排在第2和第3,KEGCN w/o KG的性能证明了KEGCN提出的自注意力门控网络机制捕获多跳扩展知识特征信息的方法能够在答案选择的过程中提供丰富的常识性推理信息,并增强模型的鲁棒性.KEGCN w/o CNN的性能证明了利用CNN捕获BERT各编码层中的多粒度全局语义信息对于模型性能的提升具有积极意义.
3.5 参数实验
本节通过多组参数实验分析不同超参数对于KEGCN模型的影响,选择的超参数包括KEGCN构造知识扩展序列中扩展节点的个数max_n以及文本结构特征编码中GCN的层数K.
构造知识扩展序列的过程中,扩展节点个数max_n的选择决定了KEGCN模型中外部知识语义的丰富性程度.图2给出了在WikiQA和TrecQA数据集上不同的max_n设置对于KEGCN的影响.从实验结果中可以看出,当max_n设置为3时,KEGCN在WikiQA和TrecQA均获得了最佳性能.当max_n设置为0,1,2时,KEGCN性能逐步提升,这表明扩展一定数量的知识节点可能帮助模型增强知识语义的丰富性,提高模型性能.其中max_n设置为0时表示没有进行知识节点扩展.当max_n设置大于3时,模型性能开始下降,表明扩展的知识节点太多,会对模型带来一定的知识噪声,影响性能.
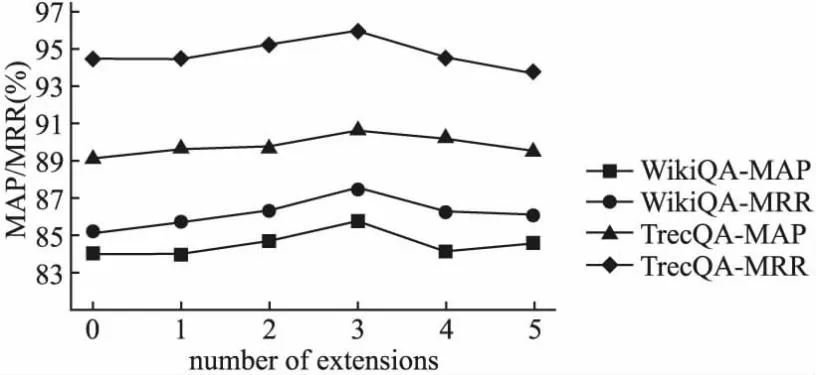
图2 扩展节点个数对KEGCN性能的影响Fig.2 Effect of the number of extension nodes on the performance of KEGCN
GCN网络的层数K对节点信息传播具有重要影响.图3给出了在WikiQA和TrecQA数据集上GCN层数K对于KEGCN的影响.从实验结果中可以看出,当K设置为2时,KEGCN在WikiQA和TrecQA均获得了最佳性能.K设置为1时,GCN对于模型性能的提升不明显,这是由于单层GCN无法令模型充分学习文本的结构信息.当层数大于2时,模型性能开始逐步下降,表明过多的GCN层数可能引入大量参数,增加了模型的复杂度,导致模型训练困难,可能造成学习的过程中信息的丢失.

图3 GCN层数对KEGCN性能的影响Fig.3 Effect of the number of GCN layers on the performance of KEGCN
4 总 结
针对现有应用于答案选择任务的模型对文本理解不足,未能充分利用外部知识信息以及全局语义信息提取不充分等问题,本文提出一种知识增强图卷积网络的问答匹配模型KEGCN.首先,KEGCN在BERT获取文本语义特征基础上,通过图卷积神经网络来学习问答对之间的句法结构依赖关系,增强对问题,答案文本的理解.其次,外部知识信息作为问答对语义信息的补充,KEGCN提出了一种基于知识图谱的多跳扩展知识序列的表示方法,丰富了知识信息的语义性.并利用自注意力门控网络机制构建知识实体之间的上下文语义关联和过滤知识噪声,增强模型的鲁棒性.最后,针对BERT各编码器生成的不同有效信息,KEGCN提出了利用多尺寸的卷积神经网络提取多粒度的全局语义信息特征,进一步提高答案选择推理的准确性.在WikiQA和TrecQA进行实验分析,实验结果表明KEGCN在两个数据集上均表现出优异的性能,并通过消融实验证实了模型中各个模块的有效性.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
开放教育研究(2020年2期)2020-03-31
电子制作(2019年22期)2020-01-14
电子制作(2019年11期)2019-07-04
疯狂英语·新读写(2018年3期)2018-11-29
北京航空航天大学学报(2018年1期)2018-04-20
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
