
基于关联规则的科研项目申报信息挖掘技术①
2024-02-26 03:32:04高大菊
佳木斯大学学报(自然科学版) 2024年1期
高大菊
(滁州城市职业学院,安徽 滁州 239000)
0 引 言
高校科研的核心力量是教师队伍,科研项目的立项是评价教师科研能力的主要依据,也是学校科研管理工作的一种重要方式。数据挖掘技术的产生和发展为教师科研工作提供了强大支撑,通过关联规则技术可以对科研数据进行分析,发现影响科研结果的关键性因素,并根据这些因素之间的联系规律,为高校组织、协调和评价教师科研工作、作出科研决策提供科学依据。因此,如何从众多科研项目申报资料中挖掘出隐藏的规律与知识,为高校教育和科研决策提供支持成为重要的研究项目。
1 关联规则数据概述
1.1 基本概念
1.1.1 数据项与数据项集
假设I={i1,i2,…,im}为m个项目的集合,其中ix(k=1,2,…,m)被称作数据项 (Item),I为数据项集,简称项集(Itemset),项集的元素数量被称作该项集的长度,如长度为k的项集简称为k-项集[1]。
1.1.2 事务
事务T表示项集I中的子集,两者关系表示为T⊆I,所有事务有且只有一个关联的标识符TID,不同事务组合成事务数据库D。
1.1.3 项集支持度
假设X⊂I表示数据项集,B表示事务集D中包含项数据项集X的事务数量,A表示事务集D包含的事务总数量,数据项集X的支持度Support表示为:
其中,Support(X)表示项集X的重要性。
1.1.4 关联规则
关联规则的表达式为:R:X⟹Y,其中X⊂I,Y⊂I,同时X∩Y=Φ,表示项集X如包含在某一事务,则项集Y必定也包含在同一事务中。X为关联规则先决条件,Y为关联规则结果[2]。
1.1.5 关联规则置信度
关联规R的置信度(Confidence)可表示为:
规则置信度衡量的是关联规则的可靠程度。
1.1.6 最小支持度与频繁项集
最小支持度表示发现关联规则的情况下,数据项需要满足的最低支持门限值,衡量的是项集的最低重要程度。只有满足最小支持度的情况下,数据项集才可能出现在关联规则中,支持度高于最小支持度的数据项集叫做频繁项集,反之,则为非频繁项集。
1.1.7 最小置信度
最小置信度表示关联规则需要达到的最低可信度,衡量的是关联规则的最小可靠性。
1.2 挖掘关联规则的基本过程
挖掘关联规则基本流程如下[3]:
(1)对数据进行预处理,包括数据清理、数据填充、数据离散化;
(2)确定支持门限最小值,置信度的最小值;
(3)基于关联规则挖掘算法挖掘出频繁项集,生成关联规则;
(4)对关联规则进行可视化生成和评价。
可见,将关联规则的数据挖掘涉及以下两个关键问题:
(1)查找所有能符合最小支持度要求的频繁项集,这一过程是数据挖掘中最关键的环节;
(2)基于最小置信度生成频繁项集的决策规则。
1.3 关联规则算法研究
Apriori是最典型的关联法则的数据挖掘方法,该算法通过多趟扫描事务集D的方式找出全部频繁项集[4]。其运算主要基于以下两个基本性质:
(1)一个频繁项集的子集必然也是频繁项集。
(2)一个非频繁项集的超集必然也是非频繁项集。
如图1所示,应用Apriori算法进行第一趟数据库扫描时,需计算项集I中所有数据项的支持度,找出符合最小支持度要求的1-频繁项集L1。在接下来的第k趟扫描中,先将第k-1趟扫描找出的包含k-1个元素的频繁项集的集合Lk-1组做为种子集,据此产生新的潜在k频繁项集的集合,也就是候选集Ck,接着对数据库进行扫描,计算候选项的支持度,从中选出一组符合最小支持度要求的k频繁项集集合Lk,并将其用作下一次扫描的种子集,不断重复直到产生最后一个频繁项集[5]。
假定在数据库中,所有事务的数据项均按字母次序排列,对于一个事务数据库D,一个数据项集的支持度可被视为包括这个数项集的事务数。每个数据项集都有一个域Count用于存储其支持度。
2 基于关联规则的科研项目申报信息挖掘
挖掘过程包括数据准备、关联规则挖掘实现、规则解释与表达三个部分[6]。以高校全部科研项目申报书中的信息为关联规则挖掘对象,从多个相关数据表中挖掘出合适的属性,构建源数据表,并实现数据标准化、离散化,进而得到相应的事务数据库。
2.1 数据准备
2.1.1 数据收集
收集广州城市职业学院2021年度的所有科研申报信息以及研人员人事数据,并整理导出到excel表中,数据源主要包括教师个人信息表、立项科研项目信息表、未立项科研项目信息表。其中教师个人信息表主要包括员工编号、姓名、部门号、性别、出生日期、学位、学历、专业、专业技术任职资格等;立项科研项目信息表主要包括项目编号、项目名称、项目负责人编号、项目来源、项目级别、立项时间、计划结项时间、资助经费、学校配套等;未立项科研项目信息表主要包括项目编号、项目名称、负责人编号、项目来源、项目级别、计划开始时间、计划结项时间、申请经费等。
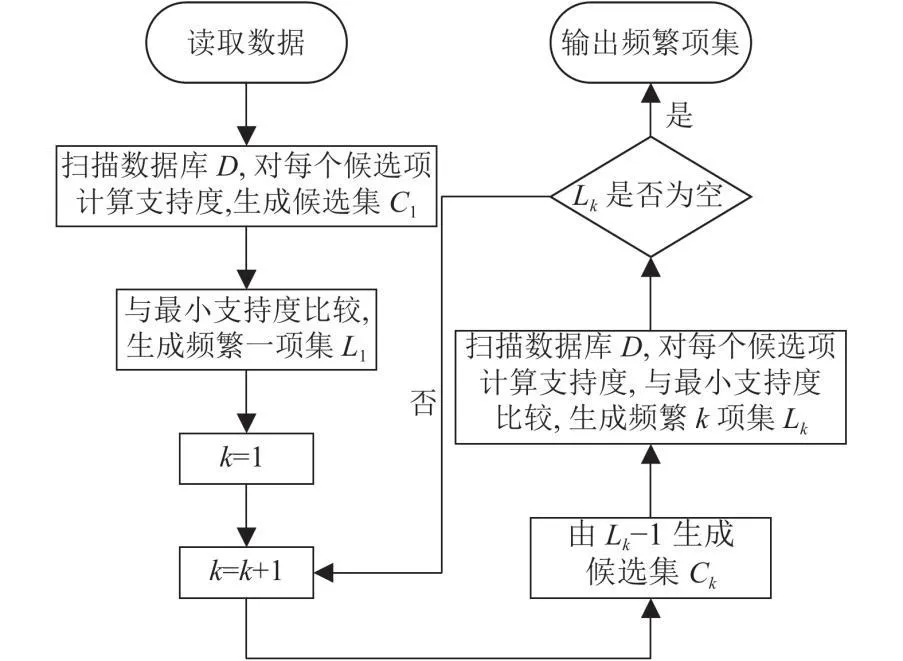
图1 Apriori算法流程
2.1.2 数据预处理
实践中收集的数据往往存在噪声、空缺、不一致等情况,需对其进行预处理,以清楚噪声,纠正不一致,确保数据挖掘效果。常用的预处理技术包括数据清理、数据集成、数据变换、数据归约。
(1)数据清理。数据清理的方式主要包括填补空缺值,平滑噪声数据,识别、删除孤立点等。采用计算机检查和人工检查结合的方式进行数据清理。用属性平均值或典型值填补空缺值,如年龄可用平均年龄填补空缺,职称信息可用无职称填补空缺,同时铲掉冗余数据,纠正数据不一致。
(2)数据集成。集成不同数据源中的数据并存储在同一个数据存储中。如将已立项、未立项的科研项目信息、人员信息、申报书中的项目基础数据集成构成数据表,其结构如表1所示。
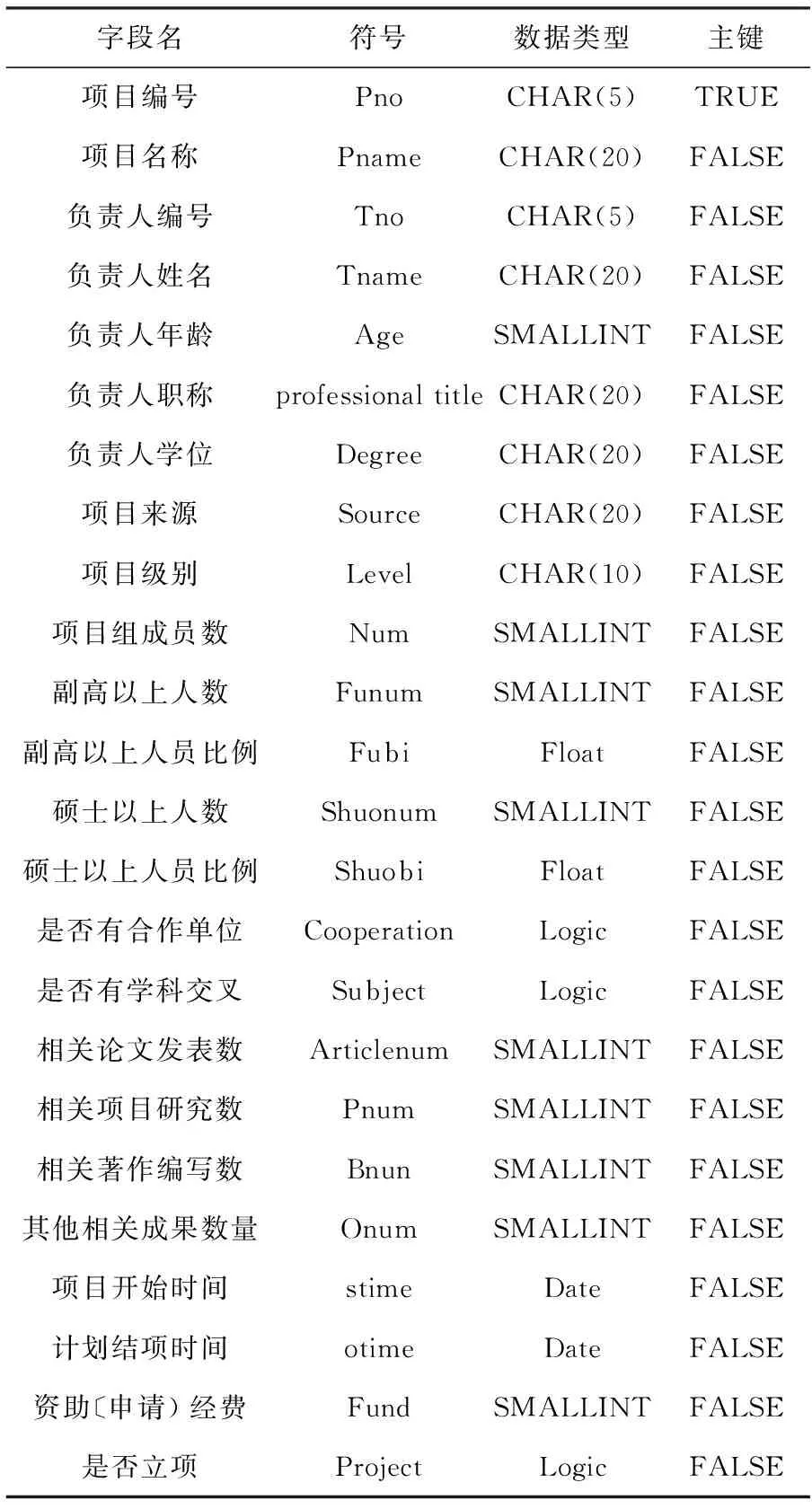
表1 集成后的科研项目数据表
(3)数据归约。集成后的数据量非常大,对其进行分析挖掘需很大的资源开销,为节省资源,提高挖掘效率,需进行数据归约,在保证数据完整性的前提下尽量缩小数据挖掘规模。数据归约方法主要包括立方体聚集、维归约、数据压缩、数值压缩、离散化等。本次研究采用维归约、数值压缩、离散化三种方式缩减数据量。
维规约,对于项目编号、项目名称、负责人编号、负责人姓名等对项目是否立项没有显著影响的属性可删除;而副高职称以上人员的比例及硕士学位以上人员的比例与人员的绝对数相比较,更能体现项目成员结构,因此可删除副高以上人数、硕士以上人数者两个属性;此外,该高校只有少量项目存在合作单位,故删除该属性。
先选取一批凝聚点,再使样品向最近凝聚点凝聚成类,得到原始分类,样品归入后重新计算分类的重心,替换原有的凝聚点,再计算下一个样品的归类,直至全部样品均归类。动态聚类的基本原理如图2所示。

图2 动态聚类基本原理
合理划分属性区间,建立各属性对应的变量映射表,逐条扫描数据库记录,按照映射表中的对应变量名填充到事务数据表中的对应位置,扫描完整个数据库时即完成了关系数据库到事务数据库的转换。
2.2 科研项目申报信息挖掘过程
运用Apriori算法,结合实际数据以及经试验得到最小支持度阈值为0.10,最小置信度阈值为0.80进行关联规则挖掘,同时满足上述阈值要求的为强关联规则,共计得到973条强关联规则。
2.3 规则的解释及表达
由于本次研究重点在于各指标和项目是否立项的关联,故以是否立项作为约束条件,筛选出前、后条件包含项目是否立项的关联规则,共计11条,如表2所示。

表2 关联规则的解释及表达
3 结 论
根据上述关联规则可得如下结论:
(1)项目负责人学历均为硕士以上,职称均为讲师以上,因此,教师需重视自己的学历、学位和职称的提高,同时学校应该采取合理的激励措施,促进青年教师的专业发展,促进高校科研水平的提升;
(2)项目组人员结构:市厅级项目组人员数量通常为5-7个,其它项目可以适当增减,其中副高级以上的人员占比应不低于29%,硕士以上学位的人员占比应不低于49%,否则不大可能立项。审核科研申报项目时可以参考这个结论给负责人提出人员结构优化建议;
(3)研究依据:对相关研究成果的数量要求因人而异,其中,中级职称教师的相关研究成果数应不低于6个,副高级教师的相关研究成果数应不低于12个;
由于抽样资料来自于单一高校的单年度科研项目申报数据,研究结论存在局限,受最小支持度和最小置信度的阈值选择的影响,产生的关联规则不够全面精准。
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
甘肃科技(2020年19期)2020-03-11 09:42:42
计算机与生活(2019年11期)2019-11-12 05:41:02
科技与创新(2019年14期)2019-08-12 12:55:20
计算机应用(2018年5期)2018-07-25 07:41:26
轴承(2015年2期)2015-07-25 03:51:04
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
计算机工程与设计(2011年7期)2011-09-07 10:16:42
电讯技术(2011年11期)2011-04-02 14:00:37
