
基于对比学习的暴力检测算法研究①
2024-02-26 03:29孙国林陈文龙王泓宇陈远磊周明航
佳木斯大学学报(自然科学版) 2024年1期
孙国林, 陈文龙, 王泓宇, 陈远磊, 周明航
(电子科技大学,四川 成都 611731)
0 引 言
目前基于深度学习的图像识别模型已走出实验室投入应用,而暴力检测在图像基础上需同时结合时间和空间维度的特征,在识别速度和精度上需要进一步提升[1]。随着计算机技术不断发展,出现了越来越多基于深度学习的暴力检测算法。Karen Simonyan等人提出一种双流的网络架构用于动作识别,采用单张图片输入和光流作为网络输入,其中图片输入用于捕获空间信息,光流输入用于捕获运动信息,网络结合提取到的时空特征判断行为的类别[2]。在双流基础上,DongZhihong等人提出一种用于暴力检测的多流输入的卷积网络结构[3],在原始视频和光流基础上,为捕获激烈的暴力行为信息提出一种加速流的特征描述符作为网络的第三输入,网络采用2D卷积网络和长短期记忆网络(Long short-term memory, LSTM)的结构处理视频的时空信息。对于2D卷积只能处理图片的空间信息,Du Tran等人将2D卷积核用3D卷积核代替,在做卷积核运算时同时结合了空间维度和时间维度上的信息,并提出C3D网络结构模型用于行为识别[4]。也有一些学者为了更好的暴力检测效果使用改进的LSTM,如卷积长短期记忆网络(ConvLSTM)[4], 双向长短期记忆网络(Bi-LSTM)[5]。对比学习利用无标签数据训练网络表征能力,使得网络在目标任务上有更好表现。Ting Chen等人提出一个简单的对比学习框架SimCLR(Simple Framework for Contrastive Learning of Visual Representations),其中在特征提取网络后增加了一个投影网络,将输出高维特征投影到更小的特征空间,并对比了不同图片增强方式组合对效果的影响[6]。MoCo(Momentum Contrast)采用大量正负样本对比,其结构有两个相同结构的特征网络,其中一个按照梯度更新方式,另一个采用动量更新方式,队列将存储动量网络的输出特征,因此队列中特征不会随着网络更新产生巨大的变化[7]。也有一些研究者只采用正例对比的方式,BYOL(Bootstrap Your Own Latent)在只采用正例对比情况下,使用两个结构相同的网络,一个称为在线网络,一个称之为目标网络,其中目标网络采取动量更新的方式[8]。
1 基于对比学习的暴力检测半监督训练框架
整体对比学习训练框架如图1所示,整个过程分为三个阶段,分别为对比学习阶段、监督学习阶段和微调阶段。在对比学习阶段中,过程仅使用无标注的数据集进行对比学习训练,其训练的网络结构由编码网络和多层感知机(Multilayer Perceptron, MLP)组成,MLP用于将编码网络输出的高维特征向量降至低维,用于后续计算对比损失。为监督训练阶段,数据集使用的是有标注数据集,采用完整的暴力检测网络模型,包括编码网络和分类网络。与一般的监督训练不同,其作为对比学习的下游任务,其编码网络的参数并不是随机初始化的,而是由第一阶段对比训练结束时,丢弃MLP网络,保留编码网络的参数,并赋值给监督训练阶段的编码网络。在微调阶段,其网络结构延续第二阶段的网络结构,网络参数初始化为第二阶段在测试集上表现最好的模型参数,采用的数据集为有标注数据和无标注数据。对于无标注数据集,利用第二阶段效果最好的网络模型对其进行伪标注。由于经过第二阶段,获得的网络模型已经再暴力分类上有较高的准确率,其对无标注数据集的标注大多数是正确的,但依然有少部分是标注错误的数据,为了减少标注错误数据的影响,设定一定的置信度阈值,只有暴力预测概率或者非暴力概率大于该阈值时,才作为第三阶段的训练数据。

图1 半监督训练框架
1.1 对比样本生成
针对对比学习中正负样本生成方式,训练框架采用两种生成方式,第一种是基于速度的对比,第二种是针对全局和局部的对比。基于速度对比以不同的采样速率来生成正样本对,对于同一视频经过不同的采样速率获得的两个采样样本为一对正样本对,而两个采样自不同视频源的则为负样本对。基于全局和局部对比首先以相同的采样速率对同一完整视频进行采样,采样获得两个新的样本,其均为全局采样样本,然后对其中一个采样样本随机丢弃前半部分或者后半部分,获得局部样本,由此生成的两个样本为正样本对,来自不同视频采样获得的样本为负样本对。
1.2 对比学习框架
训练框架中的对比学习框架结合了MoCo 和BYOL 的特点,在MoCo 对比的基础上,增加正样本之间的对比。设计的对比框架具体流程如图2所示,Xq和Xk分别代表输入的一对正样本,Xq先经过编码网络获得特征向量,后经过投影网络将特征向量映射到对比空间,获得投影向量z,后经过预测网络获得向量Q,Q是对下面动量网络输出的投影向量K的预测。Xk经过的网络结构与Xq相同,分别经过编码网络和投影网络,获得投影向量K,Q和K来源于同一对正样本,其计算的损失属于正例间的对比。与上面网络路径不同的是Xk经过的网络并不参与梯度回传,而是以一种动量更新的方式更新网络参数,如公式1所示,θ代表编码网络参数,θk代表动量网络的参数,θq代表非动量网络的参数,m代表动量更新系数,动量网络以一种更加缓慢的速率更新网络参数,防止由于网络学习速率过快导致存储在Memory Bank的投影特征相较于更新后网络产生的投影向量会产生较大变化,而不适合与新生成的投影向量进行对比。之后从Memory Bank提取所有的投影向量P作为负样本与Z进行比较,此为正例与负例之间的对比,值得注意的是,K在该批次训练结束后才加入Memory Bank,并不包含在P中。
θk=m·θk+(1-m)·θk
(1)

图2 对比学习框架
1.3 对比损失
对比损失是衡量模型是否能分编正负样本能力的指标,也是网络的优化目标。针对设计的对比框架,采用两种对比损失计算方式,第一种为InfoNCE,如公式2所示,包含正例之间和正负例之间的对比,第二种采用BYOL 的对比损失计算方式,只计算正例之间的对比损失,如公式3所示,对比学习阶段的损失由上述两种损失相加得到。
(2)

2 对比学习暴力检测模型实验
暴力检测基础模型采用ResNet[9]和TSM(Temporal Shift Module)[10],使用2D网络和时序处理模块提取视频的时空特征。实验使用两个暴力检测数据集,分别为 RWF2000[11],RVLS(Real Life Violence Situations)[12]。RWF2000采集自YouTube,并将视频剪辑在5 s,帧率为30 fps暴力和非暴力的视频数各占一半,均为1000个,总共有2000个视频,其中训练集和测试集按 8∶2分,在训练集和测试集中暴力和非暴力的视频数相等。RLVS也是从YouTube采集了1000个暴力行为和 1000个非暴力行为的视频,其中暴力视频包含了许多在不同环境下真实的街头斗殴情况,非暴力视频包含了许多不同的人类行,如运动、饮食、散步等,总共也有2000个视频,每个视频的时间大概在5 s左右,与RW一样,但其并没有划分训练集和测试集,为和 RWF2000数据集保持一致,其训练集和测试集也按照 8∶2划分。
2.1 对比学习框架实验
为了验证对比学习对暴力检测模型带来的效果,同时对比已有对比学习框架和所设计对比学习框架带来的效果增益,在RWF2000和RVLS数据集下,在对比学习阶段使用所有2000个视频作为对比学习训练集,在监督训练阶段分别取训练集的5%、15%、25%作为训练数据,最后比较不同对比学习框架获得模型在测试集上的检测效果。训练配置如下,训练轮次为100轮,初始化学习率为0.01,采样余弦退火策略,优化器采用SGD。
实验对比四种对比框架,分别为 SimCLR[6],MoCo[7],BYOL[8]以及设计的对比学习框架,在对比样本生成上只采用基于采样速度的生成方式,对一个完整的视频样本,快采样采集16帧,而慢采样只采集8帧,均使用均匀采样,即将视频样本分成16份和8份,从每份中随机采集一帧。

表1 RWF2000下对比框架对比实验结果
RWF2000 数据集实验结果如表1所示,Base为只使用监督训练的基线方法,在所有比例训练数据下,设计的对比框架测试准确率均为最高,分别达到了63.25%、73.6%和75.6%。从表中可以看出,对比学习初始化的特征网络对模型的准确率提升均起到了帮助作用。在5%和15%训练比例下MoCo所提升的准确率收益最小,在25 %训练比例下BYOL所提升的准确率收益最小。设计的对比框架在大量正负样本对比同时增强了正样本对比,达到的效果均为最优。

表2 RVLS下对比框架对比实验结果
RVLS 数据集下实验结果如表2所示,在5%,25%训练比例下,设计的对比框架测试准确率均为最高,分别达到了81.8%,89.3%,在15%训练比例下,准确率排第二,达到了 83.7%。从表中可以看出,对比学习初始化的特征网络对模型的训练均起到了帮助作用。BYOL与设计的对比框架提高的效果较为显著,在5%训练数据下准确率均提升了2.55%,在15% 训练数据下准确率分别提升了3.35%,2.5%,在25%训练数据下准确率分别提升了2.25%,2.5%,设计对比框架在大多数情况下取得的效果均为最好。
2.2 消融实验
2.2.1 对比样本生成方式消融
对提出正负样本生成方式进行消融实验,设计的两种正负样本生成方式,分别为基于采用速度的生成方式和基于全局的局部采样的生成方式。实验的对比样本生成方式配置分如下三种配置:1、采用基于采样速度方式,用Speed表示;2、采用基于全局采用和局部采样方式生成,用 Global-local表示;3、同时使用以上两种采样方式,用 Speed+Global-local表示。实验均使用设计的对比学习框架,使用RWF2000数据集,参数配置与对比框架实验相同。

表3 RVLS下对比框架对比实验结果
实验结果如表3所示,Base为对比基线,表示完全使用监督学习进行模型训练。可以看出,在对比学习帮助下,模型检测准确率有提升,尤其是在训练数据只有15%时,最好的对比模型相较于基准提高了将近8%准确率。在对比样本生成方式比较中,基于采样速度对比方式要比全局和局部采样的方式对比要好一些,由于基于采样速度方式是全局采样,其收集到的信息更为全面,模型比较正样本的相同点和不同点更方便,更容易学习到样本的本质特征,而局部采样会损失样本的一些信息,造成正样本间的差距更大,对模型的挑战更高,更不容易学习到样本的本质特征。不过,从混合生成方式和基于采样速度生成方式的结果对比中,可以看出,基于全局和局部对比方式对模型是有增益的,且混合方式综合前两种对比方式的特点,使得模型在学习过程中既有很容易分辨的正样本对,也有较难分辨的正样本对,使得模型能够从简单到困难学习到不同样本之间的本质特征,将其在对比空间更好的表示。
2.2.2 微调置信度消融
在微调阶段中,不是所有无标签数据再加上伪标签后就能加入监督训练的,有一个阈值参数来筛选置信度比较高的样本作为训练样本,防止脏数据对模型性能的影响。对于无标签所得到伪标签采样如下处理方式,将伪标签的概率分布转化为真实标签的概率分布,即只有一个类别概率为1,其他概率为0的方式,取预测概率最大的作为其真实类别。
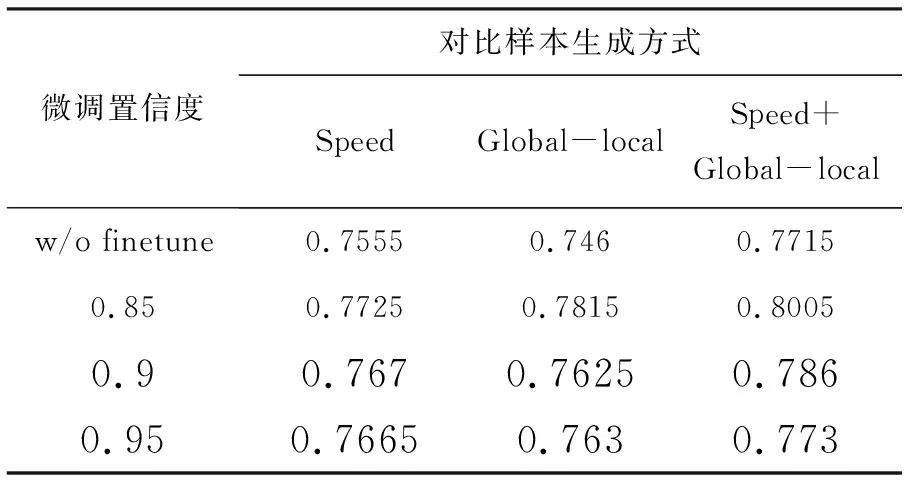
表4 RVLS下对比框架对比实验结果
实验设置如下,分别在 0.85,0.9,0.95微调置信度下,在3种对比样本生成方式下以25%训练比例得到的模型进行微调训练。微调阶段训练过程参数配置如下,训练轮次为 50,学习率初始化为 0.001,学习率变化采用余弦退火方式,RWF2000训练集剩下的75%的数据作为无标签数据。实验结果如表4所示,其中微调阶段均能提高模型的检测准确率,当模型已达到较高准确率时,如果置信度设置太高,将只能使用少量的数据样本,从而使得微调的作用不大。可以看出,当置信度为0.85时,在所有对比生成方式下,模型提升效果最明显,准确率分别提升了1.7%,3.55%,2.9%,说明可以利用对无标签数据进行伪标注,从而几乎无成本利用无标签数据,但是要保证数据分布于训练数据一致,且需要筛选出执行度较高的数据,以防混入脏数据,影响模型效果。
3 结 语
暴力检测对社会安全有很高的应用价值,但其在实际部署时依赖大量的数据样本,数据制作标注成本高。在前人暴力检测模型基础上提出基于对比学习的半监督训练框架,分为三个阶段,对比学习阶段、监督训练阶段和微调阶段。对比学习阶段负责利用无标签数据训练编码网络表征能力,设计两种对比样本生成方式,基于速度对比和基于全局和局部对比,增加正样本的多样性。设计对比学习框架在MoCo基础上增加正例对比损失计算,在大量正负样本对比过程中,增加正例间对比,使得模型对比更加均衡,不会太偏向于正负例对比。在微调阶段,为了进一步使用无标签数据价值,用监督阶段训练好的模型对无标签数据进行伪标注,选择置信度高的数据加入训练集中,对模型进行微调训练。最后进行了对比学习框架实验,对比了SimCLR,MoCo,BYOL三种对比框架,所设计对比框架在〗RWF2000和RVLS数据集下在大部分情况下均取得最优效果,在RWF2000和RVLS5%训练数据集下相较与不使用对比学习的基础模型分别提升了3.9%,2.55%准确率。在对比样本消融实验中,混合对比样本生成方式训练模型效果最好,相较于不使用对比学习基础模型提升了约8%准确率。在微调阶段,当微调置信度设为0.85时,微调训练的模型最好,在混合对比样本生成方式下,比微调前的模型提升了约3%准确率。
猜你喜欢
环球时报(2022-03-09)2022-03-09
小资CHIC!ELEGANCE(2022年1期)2022-01-11
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
数学物理学报(2020年3期)2020-07-27
作文成功之路·小学版(2020年3期)2020-04-21
中国交通信息化(2018年5期)2018-08-21
法大研究生(2017年1期)2017-04-10
小学生必读(低年级版)(2017年11期)2017-03-15
