
基于自适应回归模型和视频面部跟踪的三维动画表情驱动研究①
2024-02-26 03:29米娜
佳木斯大学学报(自然科学版) 2024年1期
米 娜
(安徽绿海商务职业学院科学与艺术学院,安徽 合肥 230006)
0 引 言
三维动画是指通过计算机视觉技术,将人体模型在虚拟空间中显示出来的一种技术。在三维动画中,表情是一个非常重要的元素,它可以直接反映出角色的内心情感状态。伴随着科技的快速发展,面部三维表情仿真技术已经成为虚拟现实、计算机视觉等领域不可回避的热门课题,特别是在三维动画电影、游戏等娱乐行业快速发展的情况下,人们对于三维表情模型的需求也在不断增加[1]。然而,目前主流的以用户表情为驱动的表情建模方法,大部分都是以包含深度信息的三维图像为基础,所使用的图像采集装置主要是双眼相机或红外测距相机,这种方式的成本很高,而且远不如常规的单眼相机普及[2-3]。为了解决这些问题,研究基于自适应回归模型和视频面部跟踪的三维动画表情驱动研究,构建了一种三维动画表情驱动模型。首先通过融合自适应回归模型和视频面部跟踪技术,然后将融合后的技术用于模型的构建。最后将模型运用到数据集中进行训练,验证模型在三维动画表情驱动中的性能。研究旨在为三维动画表情驱动的研究提供新思路。
1 三维动画表情驱动
三维动画表情驱动是一种通过计算机技术来实现三维动画的表情管理和驱动的方法。它可以帮助制作公司和电影、游戏等制作团队更好地展现三维动画中人物的表情和情绪,从而提高动画的质量和效果[4]。目前,三维动画表情驱动的研究一直在不断发展和改进。主要的研究成果有面部表情识别、肌肉运动捕捉、骨骼蒙皮和情绪驱动。面部表情识别是指随着计算机视觉技术的发展,越来越多的研究者开始研究如何识别和提取三维动画中人物的面部表情。其中一种方法是使用深度学习模型,如VGG网络和ResNet等,来识别面部肌肉的运动和表情。肌肉运动捕捉是指利用计算机算法等来捕捉角色身体的运动和表情。骨骼蒙皮是另一种常用的肌肉运动捕捉方法,它将角色的骨骼模型和皮肤表面分开,使得制作团队可以更方便地控制角色的表情和情绪。情绪驱动是指将角色的表情与情绪相联系,并通过驱动动画参数来表现角色的情绪。这包括一些基于物理模型的方法,如Bayes方法和LT方法[5-6]。总的来说,三维动画表情驱动研究是一个不断发展和完善的领域,为制作高质量的三维动画作品提供了有力的支持。
2 融合自适应回归模型和视频面部跟踪的三维动画表情驱动模型构建
2.1 融合自适应回归和视频面部跟踪的三维动画系统
自适应回归模型是一种机器学习算法,是在大规模数据集上训练一个高效的回归模型,以根据输入数据的类型和模式自动调整模型的参数,以便对不同类型的数据进行最有效的预测。自适应回归模型的基本思想是通过对输入数据进行建模,自适应地学习输入数据与目标变量之间的关系,然后利用该关系来预测目标变量的值[7-8]。在自适应回归模型中,通常会使用一种称为“自适应神经网络”的机器学习算法来进行建模和预测。这些神经网络通常会使用不同的层来处理输入数据,例如图像、语音或文本。自适应回归模型通常可以分为两个步骤:数据准备和模型训练。其中,数据准备是指准备输入数据以供模型进行预测;而模型训练则是指利用训练好的模型来预测未知的新数据。
视频面部跟踪是一种基于计算机视觉技术的任务,在视频面部跟踪中,研究人员会通过对人脸进行特征提取和匹配,来确定角色的身份和位置[9-10]。首先,研究人员会使用摄像头将人脸图像采集到计算机中。这可以通过扫描人脸识别软件或使用摄像头捕捉人脸图像。其次,研究人员需要提取人脸图像中的特征,例如眼睛、鼻子、嘴巴等特征。这些特征可以用来确定角色的身份和位置。最后,研究人员需要与已知数据进行匹配,以确定角色的位置和身份。如果匹配成功,研究人员可以将其设置为新的面部图像中的目标角色。
融合自适应回归和视频面部跟踪的三维动画系统是一个非常具有挑战性的任务,因为需要处理许多复杂的因素,如实时性、鲁棒性和准确性等。然而,随着计算机视觉技术的不断发展,这个问题已经得到了有效的解决。三维动画系统可以分为视频面部跟踪、自适应回归和表情驱动三个部分。视频面部跟踪是指通过摄像机或其他设备捕捉视频中的面部表情和动作,并对这些面部表情进行跟踪和重建,以实现三维动画。首先使用摄像头捕捉视频,然后使用深度学习技术对视频中的表情进行识别和重建,最后将三种技术进行融合,以实现高效、准确和自然的三维动画效果。该系统的流程图如图1所示。
在视频面部跟踪过程中,由于物体的表面特性会受光照、变形、旋转等多种因素的影响而产生较大的改变,因此,如何对图像进行自适应的算法模型进行更新显得尤为重要。以增强对目标形态特性改变的适应能力。研究将自适应回归和视频面部跟踪技术进行融合,提出一种三维动画系统,在三维动画系统中要考虑目标-背景直方图模型的补偿机制。此时每个目标的置信度都由两部分组成,分别是目标图的均值和滤波响应最大值,可用公式(1)表示。
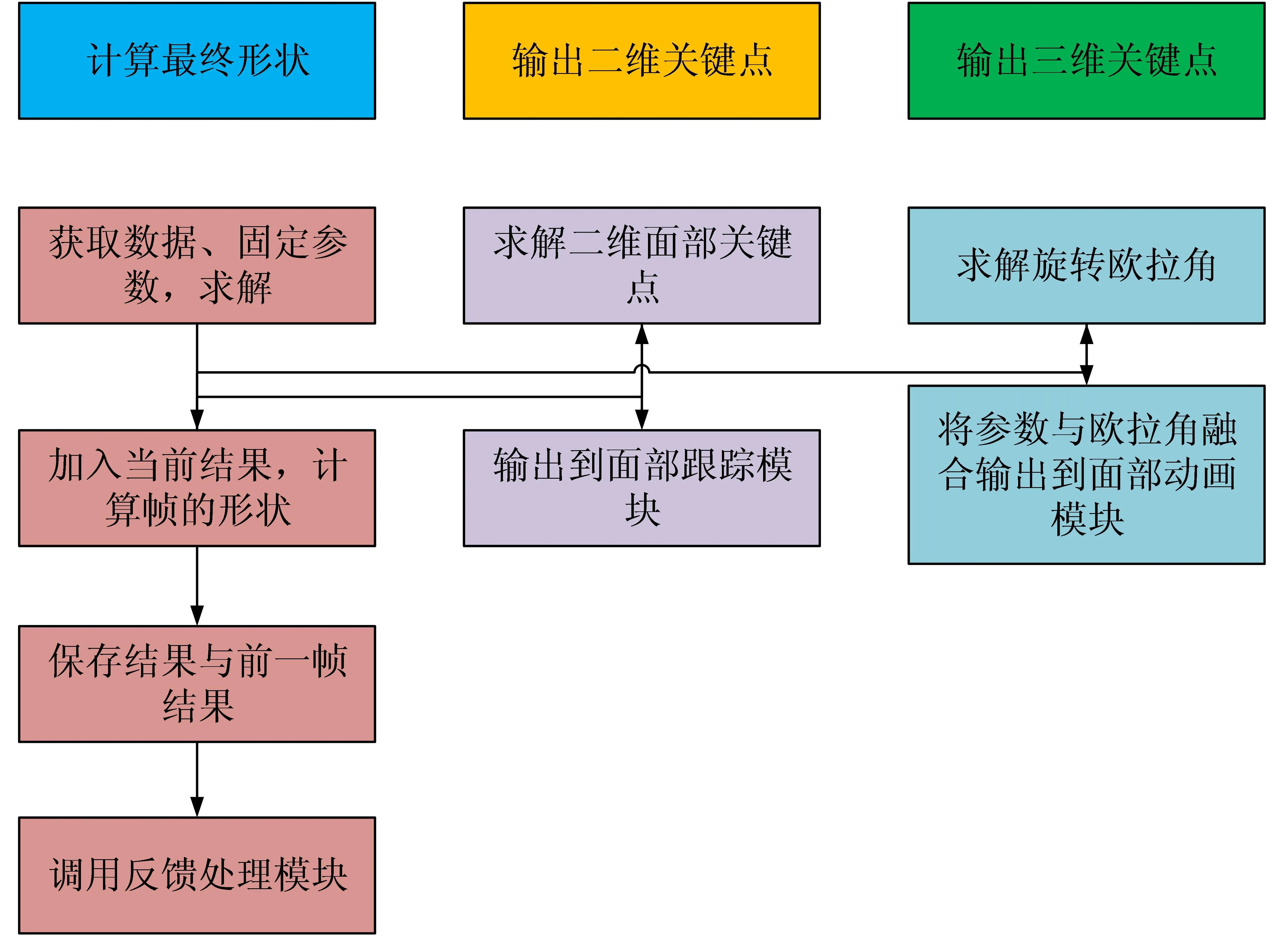
图1 融合自适应回归模型和视频面部跟踪的三维动画流程
ci=mean(Mi)max(yi)
(1)
公式(1)中,ci表示置信度;Mi表示第i个目标图像对应的目标概率图。此时还需要满足距离误差和重叠率的要求,为了消除传统中心距离误差对目标大小的敏感性,在三维系数中重新定义了一个中心距离误差,可用公式(2)计算。
(2)
公式(2)中,x,y表示矩形的中心;ω表示目标矩形的宽;h表示目标矩形的高;G表示跟踪真实目标的结果;T表示算法跟踪的结果。
2.2 基于三维动画系统的表情驱动模型构建
三维动画系统可以将角色的动作和表情记录在三维模型中,并通过捕捉场景中物体的运动来驱动角色的动作。这种模型的优点是它可以准确地捕捉表情信息,并且可以在多个场景中使用。首先,可以使用特征提取算法来提取角色的表情特征。三维动画系统通常会使用一些特定的算法来提取角色的特征,如眼睛、鼻子和嘴巴等。这些算法可以被用来识别角色的情绪和行为,从而驱动角色的表情。其次,可以使用机器学习算法来训练模型,这种方法基于对数据的学习和训练,使得模型能够自动识别和理解不同种类的表情,并且能够根据需要进行调整。在模型中,表情信息被存储在特征提取算法中,而动作则被驱动成角色的动作。此外,还可以使用机器学习算法来训练模型,从而使其能够适应不同的场景和要求。
为了构建一个融合自适应回归模型和视频面部跟踪的三维动画表情驱动模型,研究首先设计了一个高效的人脸特征提取网络,用于从视频中提取角色的特征。然后再融合加入自适应回归模型,用于预测角色的表情和行为。在空间中,每一个的三维几何特征都可以被看作一个空间矢量。当选择的三维几何特征为空间三角形时,三角形所在平面的法线方向为这个空间矢量的方向,三角形的面积就是表示矢量的大小。如果选取的是一条线段,则向量的方向是这条线段所在的那条线,两个点之间的欧式距离就是这条线的幅值。从合力投影原理出发,在任意一个姿势空间中,通过一套3D几何特征的线性加权组合,对其进行拟合,并通过构建不同姿势空间中的映射关系,将不同姿势下的表情关键特征映射到相同的姿势空间中。由于视频中图像帧具有连续性,此时帧可以用公式(3)表示。
(3)
公式(3)中,ni表示帧的缩放比例;i-1表示参考帧;n0表示噪声谱密度;S′表示帧指针。

图2 三维表情驱动流程
3 模型实验结果分析
为了验证模型的应用效果,研究利用模型方法与三维形状回归模型、局部约束模型在同一数据集中进行仿真实验,分别计算三个模型的误差,通过回归器运行误差来判断模型方法在面部表情驱动的准确率,结果如图3。
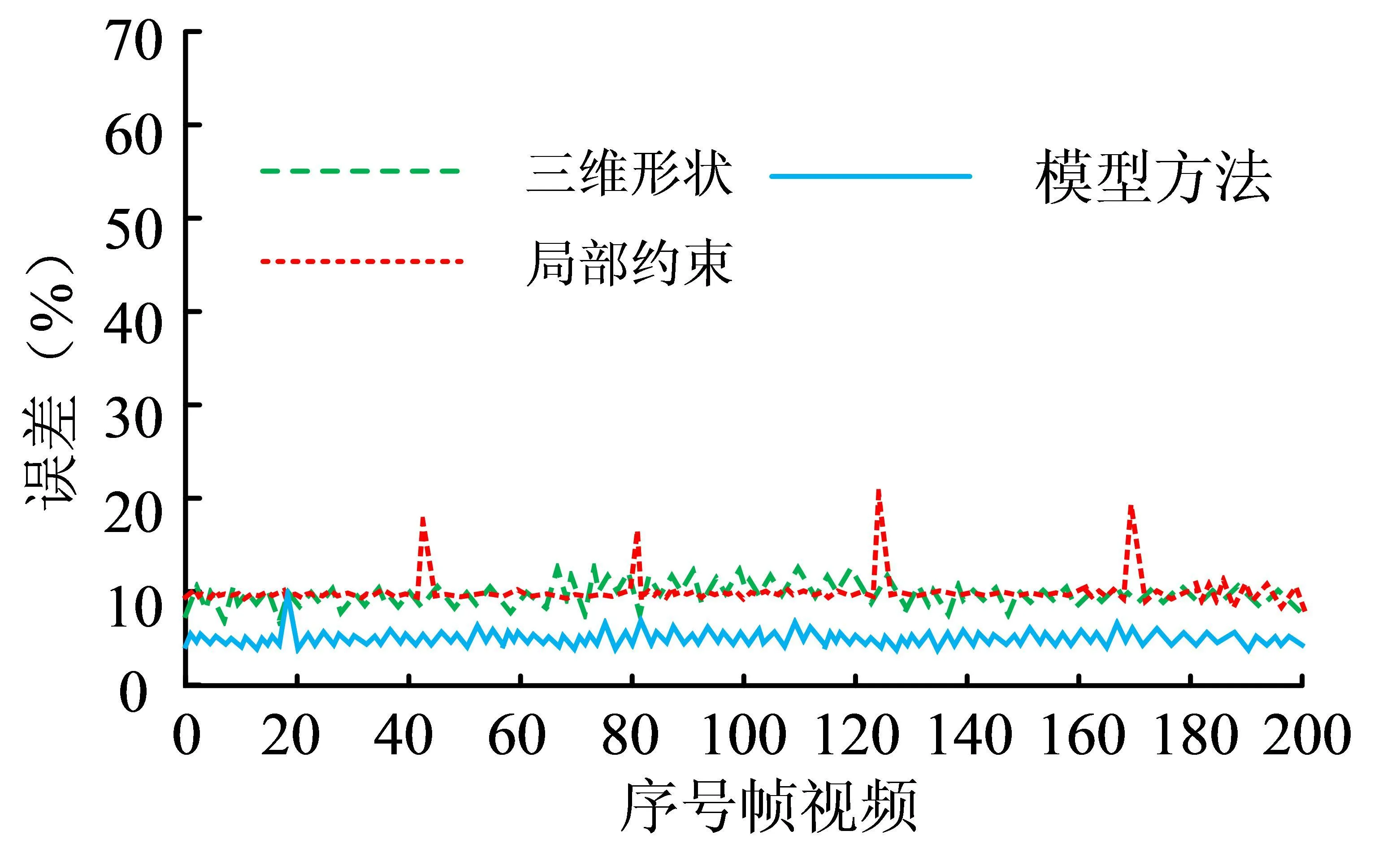
图3 不同模型的训练误差
由图3可知,模型方法在追踪初期的误差会增大,但随着帧数的增加,误差值趋于一个稳定的波动状态,其中模型方法的误差平均值为5.37%。局部约束模型和三维形状回归模型的误差平均值分别为12.17%和9.89%。这说明模型方法在成功追踪到头部旋转动作后还能处于一个较稳定的状态。为了验证模型实时性能,研究将模型方法与三维形状回归模型、局部约束模型在同一数据集中进行训练,计算在运行过程中处理每一帧所消耗的时间,结果如图4所示。

图4 不同模型的单帧处理时间
由图4可知,模型方法追踪单帧处理的平均耗时为35.17 ms,三维形状回归模型处理单帧的平均耗时为37.19 ms,而局部约束模型处理单帧的平均耗时为47.81 ms。三种方法在遇到较大头部旋转的处理时,耗时均会增加,但模型方法处理耗时更短,这说明模型方法能够有效地解决视频中头部的大幅旋转。为了验证模型方法面部追踪的准确性,研究将不同的面部关键点位对同一组视频中的面部图像进行识别、定位,并利用均方根误差来表示定位的准确程度,结果如图5所示。
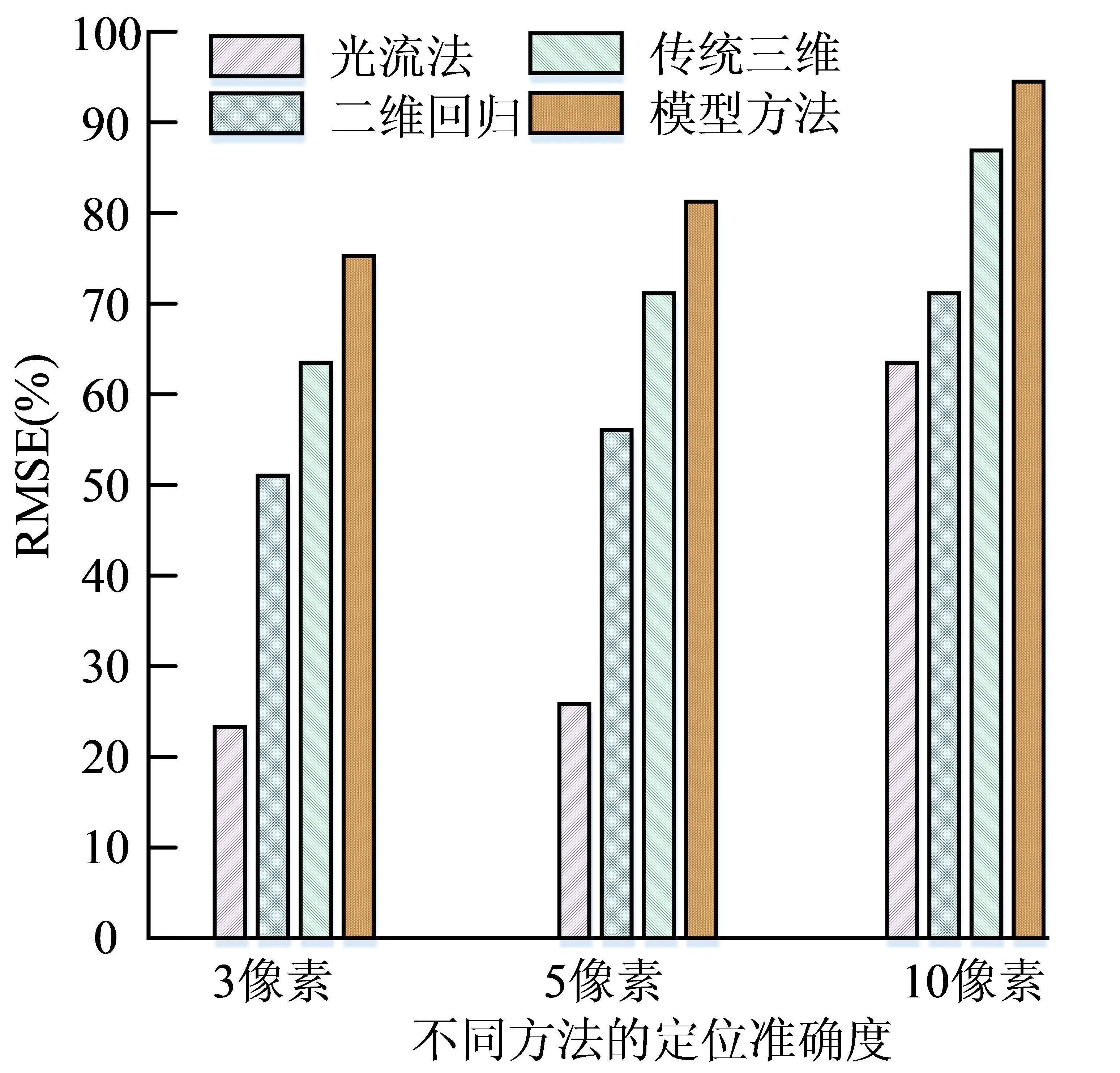
图5 不同方法的定位准确度对比
由图5可知,在不同像素下,模型方法的RMSE值均为最大值。随着像素的增加,模型方法的RMSE值越大,其次是传统三维模型法和二流回归模型法,最差的是光流法。在3像素条件下,模型方法、传统三维模型法、二流回归模型法和光流法的RMSE值分别为77.35%,62.85%,51.09%和24.39%。在5像素条件下,模型方法、传统三维模型法、二流回归模型法和光流法的RMSE值分别为83.67%,71.83%,56.48%和26.12%。在10像素条件下,模型方法、传统三维模型法、二流回归模型法和光流法的RMSE值分别为94.70%,86.74%,72.51%和63.85%,这说明模型方法在面部追踪的过程中具有很高的准确性。
4 结 语
研究提出了一种基于自适应回归模型和视频面部跟踪的三维动画表情驱动方法。该方法使用自适应回归模型来预测用户的其他面部表情,并通过视频面部跟踪来实时更新用户的三维动画表情。与现有的一些方法相比,本方法具有更高的准确性和鲁棒性,并且可以在大规模的三维动画场景中应用,且研究提出的方法还可以有效地降低计算成本,提高三维动画表情驱动的效率和质量。通过与三维形状回归模型、局部约束模型相比,模型方法具有更好的分辨和追踪能力,说明研究提出的方法是一种有效的三维动画表情驱动方法。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
汽车实用技术(2022年7期)2022-04-20
河北画报(2021年2期)2021-05-25
河北画报(2021年2期)2021-05-25
房地产导刊(2020年11期)2020-12-28
作文小学中年级(2020年6期)2020-07-24
铁道通信信号(2019年4期)2019-10-10
通信电源技术(2016年1期)2016-04-16
中国教育技术装备(2015年21期)2015-03-11
湖北科技学院学报(2014年6期)2014-07-12
