
结合图像块比较与残差图估计的人脸伪造检测
2024-02-24 09:09冯才博刘春晓王昱烨周其当
中国图象图形学报 2024年2期
冯才博,刘春晓*,王昱烨,周其当
1.浙江工商大学计算机科学与技术学院,杭州 310018;2.浙江工商大学信息与电子工程学院,杭州 310018
0 引言
由于图像深度合成技术日益成熟,人眼已经难以辨别真实与伪造图像。目前已经有不少软件提供了方便的换脸功能,人脸图像的伪造成本大幅度降低。通过修改图像中的人脸,可以伪造他人的身份,这在人脸支付安全、视觉通信安全等方面构成了极大的威胁。为了保护人脸图像的安全,迫切需要一个有效且鲁棒的人脸图像伪造检测方法。
目前,人脸图像伪造检测方法面临的挑战主要有两方面。一方面,由于人脸图像的伪造方法不断更新,无法获得所有伪造方法的数据用于训练模型;另一方面是网络模型结构的设计。由于伪造人脸的方法不同,使用不同方法制作的样本数据之间可能存在较大的分布差异,容易导致分类模型对训练数据产生过拟合现象。
为了应对上述挑战,已经出现了不少针对人脸图像的伪造检测方法(曹申豪 等,2022)。在伪造样本制作方面,一些工作(Li 等,2020a;Zhao 等,2021a;Shiohara 和Yamasaki,2022)通过相似的样本之间拼接边缘的光滑过渡来生成具有挑战性的伪造人脸图像。
在网络结构设计方面,一些工作(Liu 等,2021;Luo 等,2021;Chen 等,2021a;Miao 等,2023)利用真实与伪造人脸图像的频域差异来完成检测任务。一些工作(Zhao 等,2021b;Chen 和Yang,2021;Wang等,2022a)通过引入注意力机制来提高网络的泛化性能。Chen 和Yang(2021)将原始图像与背景、人脸、五官图像一起输入含有局部与语义注意力模块的网络,捕捉人脸五官中的细粒度信息。为了解决检测性能随图像质量的退化而下降的问题,Wang等人(2022a)通过约束从原始图像与退化图像中提取的特征相同,并引入多头自注意力机制来引导模型捕捉有效信息。Wang 等人(2022b)与Chen 等人(2022)使用对抗样本来提高模型的泛化能力。Wang 等人(2022b)引入像素级高斯模糊,通过破坏图像中的伪造痕迹来提高样本的识别难度。Chen等人(2022)在对抗训练的过程中动态地合成样本来干扰网络以提高检测的鲁棒性。Ni 等人(2022)与Cao 等人(2021)分别使用基于对比学习与度量学习的方法来提高模型的检测准确率。Guo 等人(2021)提出自适应卷积层来预测图像中的伪造痕迹,避免下采样操作导致伪造痕迹的消失。Kim 等人(2021)提出基于迁移学习的方法,保持网络的先验知识。Wang 和Deng(2021)和Das 等人(2021)使用随机遮盖来消除图像伪造痕迹,强迫网络提取有效线索。一些工作(Du 等,2020;Wang 等,2022c;Chen 等,2021b;Cao 等,2022;Zhou 等,2017;Nirkin 等,2022)主要运用多任务学习策略来提高模型的泛化性能。总之,已有方法仍然存在检测准确率不高、网络泛化性能不足等问题。
一方面,考虑到在真实图像的人脸区域与背景区域中包含的光照分布、相机参数等特定信息是一致的,而在伪造图像经过修改的人脸区域与背景区域中包含的特定信息是不一致的,Zhang 等人(2022)利用不同图像块之间特定信息的不一致性来分辨真实与伪造人脸图像,但是他们没有注意到同时包含人脸与背景信息的混合图像块对特征差异比较的干扰作用;另一方面,注意到已有工作(Wang等,2022a)中残差图预测任务可以促使骨干网络学习到具有更高泛化性的特征表示,但是伪造图像中远离原始背景区域、周围缺乏可靠信息的像素的残差预测难度较大,此处类似图像补全那样无中生有式的残差图预测任务容易导致网络对训练数据产生过拟合现象。为了解决上述问题,本文提出了结合纯净图像块比较与可靠残差图估计的多任务人脸图像伪造检测方法(pure image patch comparison and Reliable residual map estimation,PuRe)。
本文的主要贡献如下:1)引入“图像块归属纯净性”的概念,提出了纯净图像块比较(pure image patch comparison,PIPC)模块,通过比较纯净人脸图像块与纯净背景图像块之间的特征差异来检测伪造图像,图像块的纯净性保障了特征提取的纯净性,从而提高了特征比较的鲁棒性。2)引入“残差图估计可靠性”的概念,提出了可靠残差图预测(reliable residual map estimation,RRME)模块,有针对性地设计了一个距离场加权的残差损失(distance field weighted residual loss,DWRLoss),引导骨干网络重点关注真伪图像在伪造边缘附近的差异,增加了特征提取的丰富性和可靠性。3)基于上述两个模块,提出基于多任务学习的人脸图像伪造检测网络框架,RRME模块通过预测伪造图像与对应真实图像之间的残差图来引导骨干网络差异化从伪造人脸区域与原始背景区域提取的特征,从而辅助PIPC 模块更好地分辨人脸区域与背景区域之间的特征差异。在常用数据集上开展的大量实验证实了本文方法的有效性。
1 本文方法
1.1 总体网络框架
图1 展示了本文提出的多任务学习网络框架。将通道数为3、高度为H、宽度为W的待检测人脸图像I∈ R3×H×W输入骨干网络进行特征提取,得到通道数为C、高度为H'、宽度为W'的特征图F∈ RC×H'×W'。特征图F中的每个位置对应一个局部图像块,表示为特征向量V∈ RC,总共有S=H' ×W'个图像块。

图1 总体网络框架Fig.1 Overall network architecture
输入特征图F与其对应的人脸区域掩膜M∈R1×H×W到纯净图像块比较(PIPC)模块,同时将特征图F输入可靠残差图估计(RRME)模块。PIPC 模块根据人脸区域掩膜M选择只包含人脸区域的纯净人脸图像块和只包含背景区域的纯净背景图像块,通过比较两种纯净图像块之间的特征差异来区分真实图像与伪造图像。RRME 模块预测输入图像与真实图像之间的残差图R∈ R3×H×W,并且在距离场加权的残差损失(DWRLoss)的约束下重点关注在伪造边缘附近的可靠残差值。RRME 模块通过预测伪造图像与对应真实图像之间的残差图,引导骨干网络加大从伪造图像的人脸区域与背景区域中提取特征的差异,减小从真实图像的人脸区域与背景区域中提取特征的差异,助力PIPC 模块分辨人脸区域与背景区域之间的特征差异,若特征差异较大,则认为输入图像为伪造图像;若特征差异较小,则认为输入图像是真实图像。
1.2 纯净图像块比较模块
如果图像中的人脸是伪造的,那么从人脸图像块与背景图像块中提取的特征应该是有差异的,因此PIPC 模块通过比较人脸图像块与背景图像块之间的特征差异来完成人脸图像伪造检测任务。然而,如果图像块同时包含人脸和背景像素,则从中提取的特征会混合人脸和背景信息,从而干扰了两个图像块之间的比较,导致神经网络的过拟合。针对上述问题,PIPC 模块使用只包含人脸像素的纯净人脸图像块与只包含背景像素的纯净背景图像块。
将特征图F及其对应的人脸区域掩膜M输入PIPC 模块。首先使用1 × 1 卷积层将特征图F映射到新的特征空间得到F',再通过双线性插值将人脸区域掩膜M的尺寸调整到与特征图相同,得到纯净性分数图M' ∈ R1×H'×W'。其中像素i的值表示特征图F'中对应像素的特征向量Vi所对应的局部图像块的纯净性分数si∈[0,1],0 表示纯净背景图像块,1 表示纯净人脸图像块,处于0与1之间的值表示混合图像块。
为了减少被挑选的纯净图像块之间感受野的重叠,避免特征向量中信息的冗余,本文定义了一个纯净人脸图像块与纯净背景图像块的选择优先级计算函数(∙),具体为
式中,当y=1时,表示选取纯净人脸图像块;当y=0时,表示选取纯净背景图像块。式(2)和式(3)中,ω1、ω2和ω3分别表示3 个权重系数,Vf与Vb分别表示锚点纯净人脸图像块和锚点纯净背景图像块。为了方便计算,本文选取掩膜M'中人脸区域最小外接四边形的中点为锚点纯净人脸图像块Vf,选取特征图F中左上角的图像块为锚点纯净背景图像块Vb。fd(∙,∙)是一个用于计算两个图像块之间距离的函数,具体为
式中,Va表示锚点纯净图像块,Vi表示当前图像块,xa和ya分别表示锚点纯净图像块的x轴坐标和y轴坐标,xi和yi分别表示当前图像块的x轴坐标和y轴坐标。计算所有图像块的fsy值,并按从大到小的顺序进行排序,取前N-1 个fsy值最大的图像块和锚点纯净图像块对应的特征向量。当y=1 和y=0时,分别得到特征向量Vf∈ RC×N和Vb∈ RC×N,用于比较纯净人脸图像块与纯净背景图像块之间的特征差异。
首先使用全局平均池化将Vf和Vb分别压缩为V'f∈RC和V'b∈RC,聚合两种纯净图像块的信息,再将V'f和V'b拼接起来并依次输入全连接层和softmax激活函数,输出分类结果Cpre。
1.3 可靠残差图预测模块
将特征图F输入RRME 模块,预测输入图像与真实图像之间的残差图Rpre∈ R3×H×W。网络训练时使用的残差图真值Rgt可以表达为
式中,I为输入图像,IR为其对应的真实图像。I和IR的像素值在[0,1]之间,所以I-IR的像素值在[-1,1]之间,式(5)通过线性变换将残差图Rgt的值映射至[0,1]之间。特别地,若I为真实图像则I=IR,意味着真实图像的残差图真值Rgt为全灰图像。
残差图预测任务引导骨干网络提取有利于人脸伪造检测的特征,但是通过对所有像素施加相同权重的损失约束,简单地约束网络预测残差图是不合适的。与图像修补任务类似,伪造区域就像图像修补任务中的空洞,RRME 模块用空洞周围的已知背景信息来估计伪造区域中的残差信息。越靠近已知背景区域,残差估计所依赖的可靠信息越多,残差估计的可靠性越高;反之,越远离已知背景区域、靠近伪造区域的中心,残差估计所依赖的可靠信息越少,残差估计的可靠性越低。无差别地约束RRME模块估计伪造区域中所有像素的残差值,尤其是远离已知背景区域的残差值,容易导致严重的过拟合现象。为了解决上述问题,本文设计了一个如图2所示的距离场加权的残差损失(DWRLoss),引导网络重点关注伪造边缘附近的残差估计结果,其计算为
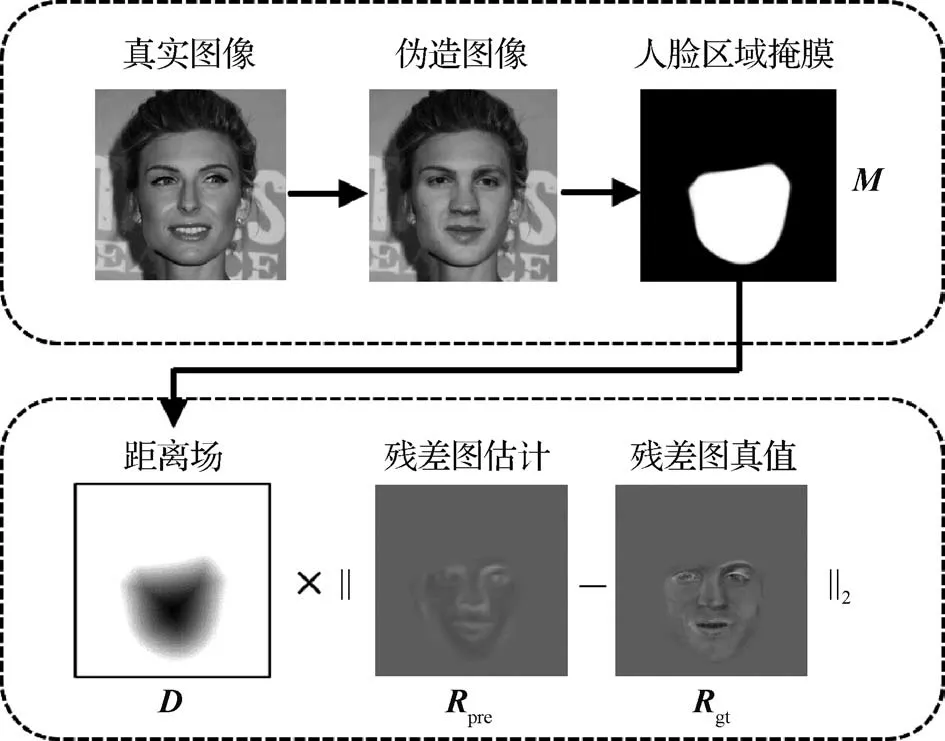
图2 距离场加权的残差损失示意图Fig.2 Illustration of the distance field weighted residual loss
式中,Rpre∈ R3×H×W为网络输出的残差图预测结果,D∈ R1×H×W为距离场。在距离场D中,背景区域的值为1,人脸区域(即伪造区域)的值随着像素与背景区域的距离增大,由1递减至0。这意味着若像素距背景区域近,该像素的损失被赋予的权重系数较大;若像素距背景区域远,该像素的损失被赋予的权重系数较小。特别地,当输入图像为真实图像时,距离场中的像素值全部为1。
1.4 多任务学习策略
在训练过程中,整体损失函数Ltotal由分类损失Lcls和距离场加权的残差损失Lres两部分组成。分类损失Lcls优化PIPC 模块,距离场加权的残差损失Lres优化RRME模块,两个损失共同优化骨干网络,整体损失函数Ltotal可定义为
式中,分类损失Lcls采用交叉熵损失函数,λ1和λ2分别为距离场加权的残差损失Lres和分类损失Lcls的权重系数。
2 实验与分析
2.1 实验设置
2.1.1 训练数据集
本文选择FaceForensics++(FF++)(Rössler 等,2019)作为训练数据集之一。FF++是一个广泛使用的大型人脸伪造检测数据集。该数据集包含1 000 个从YouTube 采集的真实视频,以及使用这1 000个真实视频制作的4 000个伪造视频。伪造视频由4 种方法制作:1)DF(DeepFake)(Tora,2019);2)FS(FaceSwap)(Thies 等,2016);3)F2F(Face2-Face)(Kowalski,2016);4)NT(NerualTexture)(Thies等,2019)。该数据集提供了3 个不同质量等级的版本:原始(RAW)、轻压缩(light compression,C23)和重压缩(high compression,C40)。本文使用RAW 版本的FF++作为训练数据,并按照8∶1∶1 的比例划分训练集、验证集和测试集。
CelebA(CelebFaces attributes)(Karras 等,2018)是一个大型人脸属性数据集,包含202 599幅人脸图像。它通常被用于人脸识别、人脸检测和人脸属性识别任务中。本文增广它的高质量版本中的部分人脸图像作为训练数据集,以增加人脸样本数量。
2.1.2 测试数据集
除了从FF++中划分的测试集,本文还使用了两个公开数据集作为测试数据:1)CDF(Celeb-DF)(Li等,2020b);2)DFD(Deepfake detection)(Dufour 和Gully,2019)。CDF 数据集由590 个真实视频和5 639 个伪造视频组成。相较于FF++,CDF 使用的伪造方法更加先进,检测难度更大。因此,已有工作通常使用CDF 数据集来测试人脸伪造检测方法的泛化性能。DFD是由Google公开的人脸伪造检测数据集,更接近现实世界中的人脸伪造样本。该数据集同样有3 个压缩版本,本文使用轻压缩版本(C23)。
2.1.3 实现细节
本文利用dlib 库提取人脸特征点并制作人脸区域掩膜。从CelebA 数据集中随机选取20 000 幅人脸图像作为真实样本,使用Li等人(2020a)的方法进行增广,即计算每幅图像与其他图像的人脸特征点的L2 距离,选取距离小于25 的图像作为最近邻图像,然后将最近邻图像中的人脸与当前图像混合,得到新的伪造人脸图像。对于其他数据集,每个视频提取32 帧图像作为训练或测试数据。所有图像的尺寸均为256 × 256 像素,在输入网络前归一化到[0,1]之间。
选择AdamW 优化器来训练网络模型,初始学习率与批量大小分别设置为0.000 2 与128。使用ResNet-34(residual network 34)作为骨干网络并使用在ImageNet 上的预训练权重来初始化网络参数,将ResNet-34 第3 阶段提取的特征图F作为PIPC 模块和RRME模块的输入。本文的训练策略是首先固定PIPC 模块的参数,使用FF++数据集和增广后的CelebA 数据集训练骨干网络和RRME 模块120 轮。然后,开放网络的所有部分训练200轮。超参数ω1、ω2、ω3、N、λ1和λ2分别默认设置为1、3E-3、3E-3、16、100 和1E-2。本文方法在Pytorch 框架下实现,使用一张NVIDIA GeForce RTX 3090 GPU 显卡进行训练。参考已有工作,本文主要使用准确度(accuracy,ACC)和AUC(area under the ROC curve)指标来评估网络性能。
2.2 库内数据集测试
2.2.1 库内总精度
在FF++的3 个不同版本上进行了库内测试,结果如表1 所示。在两个压缩版本的数据集上,本文方法取得的指标优于已有方法。特别地,在重压缩版本(C40)上,本文方法相比LiSiam,ACC 指标提升2.49%,AUC指标提升3.31%。
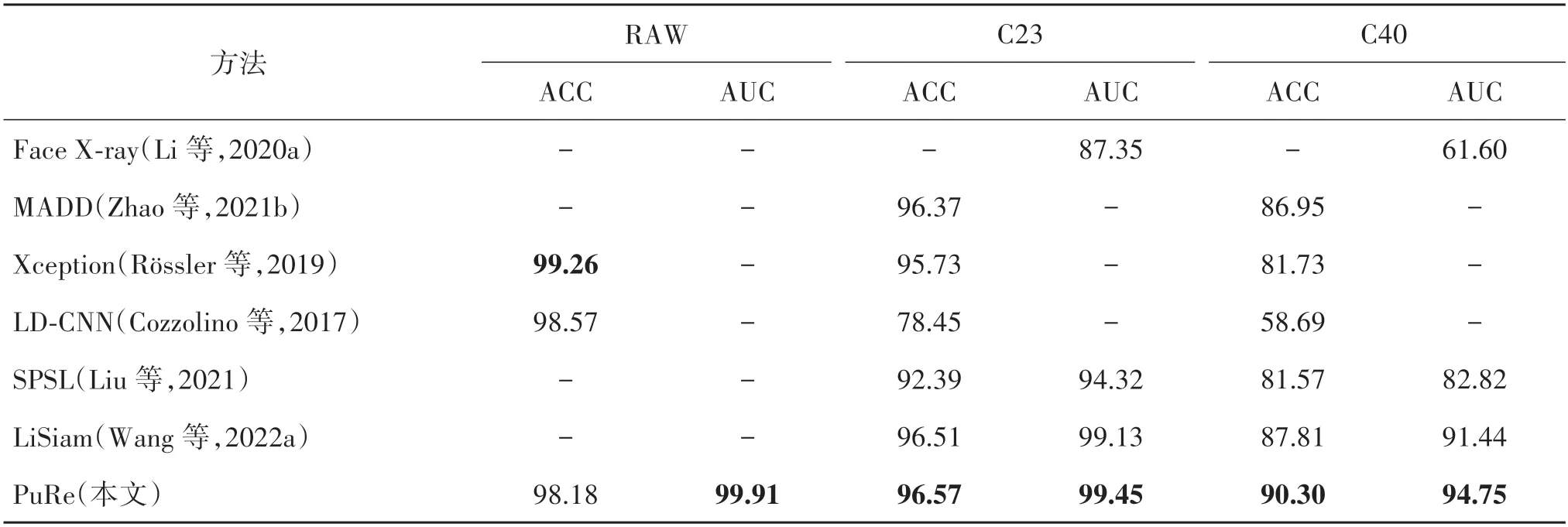
表1 不同方法在FF++数据集上的测试结果Table 1 Test results of different methods on the FF++dataset/%
2.2.2 不同伪造方法测试
针对FF++中的4 个伪造方法,本文分别在3 个版本的数据集上进行测试并展示准确率(ACC),测试结果如表2—表4 所示。在表3 中,本文方法在FS和F2F 两种伪造类型数据上的ACC 指标分别超越MTD-Net 0.24%和0.57%。在其他两个伪造类型的数据集上与表中对比方法基本持平。在表4 中,本文方法在FS 和F2F 两种伪造类型的数据上的ACC指标分别超越GRCC 方法6.01%和3.99%。从表3和表4 的实验结果可以看到,本文方法在FS 类型的伪造样本上,检测准确率远超表中对比方法。

表2 FF++(RAW)数据集中不同伪造类型数据的测试结果Table 2 Test results of different forgery types on the FF++dataset(RAW)
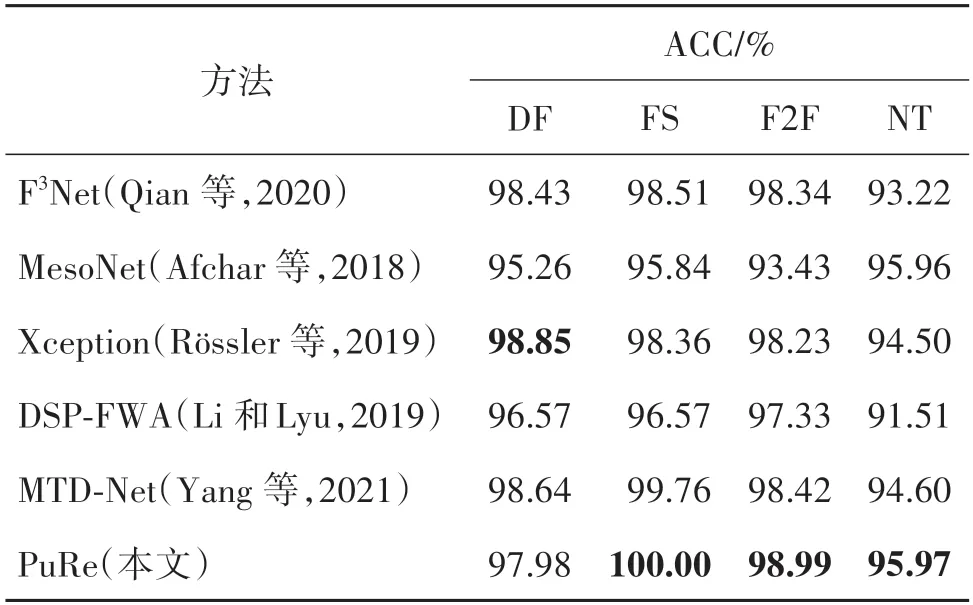
表3 FF++(C23)数据集中不同伪造类型数据的测试结果Table 3 Test results of different forgery types on the FF++dataset(C23)

表4 FF++(C40)数据集中不同伪造类型数据的测试结果Table 4 Test results of different forgery types on the FF++dataset(C40)
2.3 交叉数据集测试
如果一个网络模型具有优秀的泛化性能,当遇到未知类型的伪造样本时,它依然能够提取到样本中的伪造线索。因此,使用交叉数据集测试的方式来评估本文方法的泛化性能,即在一个数据集上训练,在另一个数据集上测试。表5 分别展示了视频层面与图像层面的交叉数据集测试结果。参照已有方法,本文在视频层面的测试方法是从每个测试视频抽取32 帧,对网络输出的32 个分数取平均,作为对该视频的预测结果。本文方法与11 种已有方法进行了比较,结果如表5 所示。由于大部分工作没有公开难以复现的代码,而且只展示了AUC 性能指标,因此在性能比较时直接引用作者在原始论文中提供的AUC 测试结果。在视频层面和图像层面,相较于F2Trans-B,本文方法在CDF 数据集上的AUC指标分别提高了1.85%和1.03%。

表5 不同方法在视频和图像层面的交叉数据集测试结果Table 5 Cross-datasets test results of different methods in video-level and image-level
2.4 消融实验
使用FF++(RAW)、CDF 和DFD(C23)作为测试数据,对本文提出的PIPC 模块和RRME 模块进行消融实验,通过不同参数设置下的交叉数据集测试AUC指标,以评估两个模块的有效性。
2.4.1 图像块的数量对网络性能的影响
本文选取不同的纯净图像块数量N=8,16,32,64 进行网络训练和测试,测试结果如表6 所示。当N为16 时,网络在FF++和CDF 数据上的表现最好。当N为32 时,网络在DFD 数据上的表现最好。综合来看,设置N=16时取得最佳性能。

表6 图像块的数量对网络性能的影响Table 6 The effects of patches number on the network performance
2.4.2ω2和ω3对网络性能的影响
式(2)和式(3)中的ω2和ω3用来控制当前图像块与同类锚点纯净图像块的距离以及当前图像块与异类锚点纯净图像块的距离的重要性。若ω2>ω3,表示当前图像块与同类锚点纯净图像块的距离更重要;若ω2<ω3,表示当前图像块与异类锚点纯净图像块的距离更重要;若ω2=ω3,表示两个距离同样重要。实验结果如表7 所示。当ω2=ω3时,在FF++与CDF 数据集上的表现最好。当ω2<ω3时,在DFD 数据集上的表现最好。综合来看,设置ω2=ω3时取得最好性能。
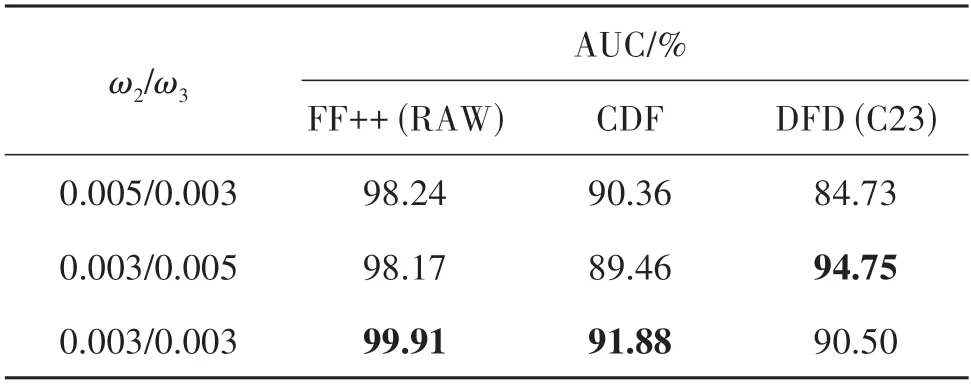
表7 ω2和ω3对网络性能的影响Table 7 The effects of ω2 and ω3 on the network performance
2.4.3 损失函数权重系数对网络性能的影响
本文通过λ1和λ2来平衡残差损失和分类损失的重要性。实验结果如表8 所示,两个损失函数的权重会对模型的表现有不同的影响。当λ2较大时,网络更容易出现过拟合的现象;当λ1较大时,距离场加权的残差损失可以引导骨干网络学习到更加有效的特征。设置λ1=100、λ2=0.01 时取得最佳性能。
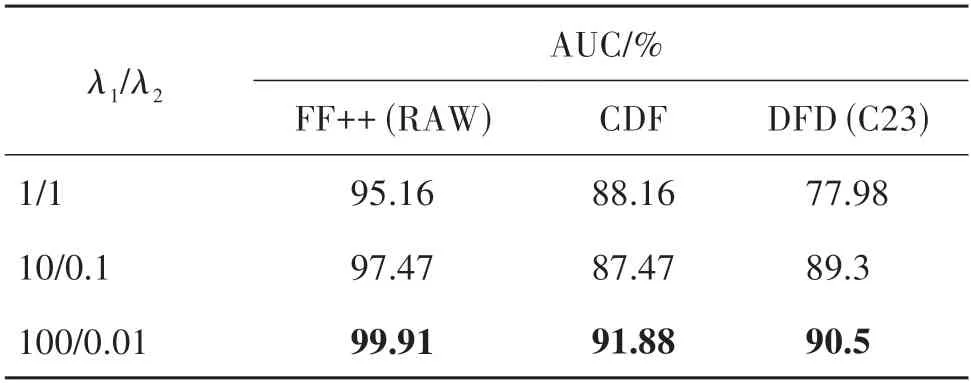
表8 损失函数权重系数对网络性能的影响Table 8 The effects of weights in loss function on the network performance
2.4.4 不同模块对网络性能的影响
为了证明PIPC 模块、RRME 模块与距离场加权的残差损失(DWRLoss)的有效性,本文训练了只包含PIPC 模块的网络、无距离场加权的残差损失(w/o DWR)约束RRME 模块的网络以及有距离场加权的残差损失(w/ DWR)约束RRME 模块的网络进行性能测试和比较。从表9 中的测试结果可知,有距离场加权的残差损失(w/ DWR)相较于无距离场加权的残差损失(w/o DWR)能够更好地引导网络的学习过程。另外,当两个模块共同作用于网络的训练过程时,网络的性能表现最好。
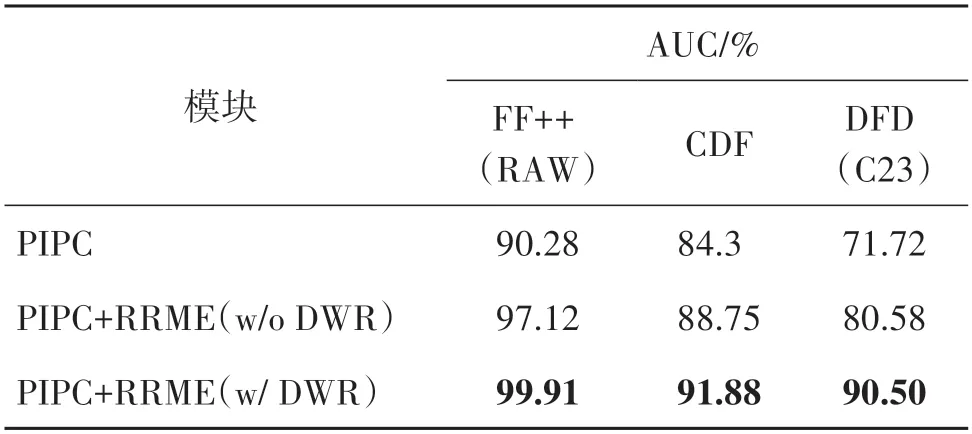
表9 不同模块对网络性能的影响Table 9 The effects of different modules on the network performance
3 结论
为了进一步提高神经网络在人脸图像伪造检测任务中的泛化能力,本文提出了包含纯净图像块比较(PIPC)模块与可靠残差图性预测模块(RRME)的多任务学习网络模型(PuRe)。PIPC 模块通过比较纯净人脸图像块与纯净背景图像块之间的特征差异来检测伪造图像,图像块的纯净性保障了特征提取的纯净性,从而提高了特征比较的鲁棒性。RRME模块通过预测伪造图像与对应真实图像之间的残差图,引导骨干网络加大从伪造图像的人脸区域与背景区域中提取特征的差异,减小从真实图像的人脸区域与背景区域中提取特征的差异,助力PIPC 模块分辨人脸区域与背景区域之间的特征差异。在面对未知样本攻击时,本文方法的泛化性能比已有方法更好。未来仍然需要进一步提升人脸伪造检测算法的各方面性能。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
汽车工程师(2021年12期)2022-01-17
少儿美术·书法版(2021年9期)2021-10-20
当代陕西(2020年14期)2021-01-08
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
动漫星空(2018年9期)2018-10-26
贵州师范学院学报(2016年4期)2016-12-01
河南科技(2015年8期)2015-03-11
发明与创新(2015年33期)2015-02-27
