
具有超分辨率行为伪装效果的可逆图像隐藏
2024-02-24 09:09贾孟霖杨杨孙冬
中国图象图形学报 2024年2期
贾孟霖,杨杨,2*,孙冬
1.安徽大学电子信息工程学院,合肥 230601;
2.合肥综合性国家科学中心人工智能研究院,合肥 230026;
3.安徽大学电气工程与自动化学院,合肥 230601
0 引言
图像信息隐藏技术是将秘密图像以不被察觉的方式隐藏在载体图像中,从而生成载密图像的技术。它只允许被授权者恢复秘密图像,而未被授权者难以察觉到秘密图像的存在(张卫明 等,2022)。出于安全考虑,载密图像通常与载体图像无法区分,这使得它更适合秘密通信。
传统的图像隐藏方法通常通过调整载体图像在空间域中的像素值(Tamimi 等,2013)或修改载体图像的频率系数来隐藏秘密信息(Hsu 和Wu,1999)。由于这些方法通过手动微调载体图像的特征信息来隐藏秘密图像,因此它们很容易被现有的检测技术检测到(Holub 和 Fridrich,2013)。这些方法除了安全性较弱外,对图像信息的隐藏能力也不强,无法满足大容量图像隐藏任务的需求。
随着卷积神经网络技术的进步,基于深度学习的图像隐藏技术得到了迅速发展。Baluja(2017)最早提出了一种基于深度学习的方法,将全尺寸的秘密图像隐藏在载体图像中。Weng 等人(2019)进一步提出了一种视频隐写深度网络,通过时间残差建模将视频片段隐藏到另一个视频片段中。Jing 等人(2021)提出了一种基于可逆神经网络(invertible neural network,INN)的新框架来实现全尺寸图像隐藏,随后Guan等人(2023)使用多个可逆神经网络实现了多图像隐藏。这些深度学习方法寻求实现高水平的容量、不可见性和恢复准确性。然而,随着隐写分析技术的快速发展,现有的图像隐藏技术很容易被深度学习分析方法检测到(Zhang 等,2020;You等,2021)。
实际上,目前无论是传统的图像隐藏方法,还是基于深度学习的图像隐藏方法,都是从内容层面进行伪装,追求载密图像与载体图像的不可区分性,从而让未被授权方无法感知到秘密图像的存在。一般而言,二者越相似,安全性和不可见性就越好。然而,这在某种程度上对于追求图像隐藏的安全性与不可见性起到了一定的限制作用。实际上,图像隐藏的本质是追求行为安全,即追求隐藏秘密信息这一特殊行为和用户的正常图像处理行为是区分不开的。因此,不仅可以在内容层面伪装,更应该在行为层面伪装。一些已有的工作也是从行为安全的角度出发,如Li 和Zhang(2019)直接将秘密消息转换为指纹图像,不需要任何载体信号参与。Hu等人(2021)将秘密数据表示为新闻上的“爱”标记的数量。王健等人(2023)使用可逆神经网络同时实现了可逆图像变换以及自然隐写。然而,这些伪装方法不灵活,容量有限,并不能完整地隐藏一幅全尺寸的图像。
因此,从行为安全的角度提升图像隐藏的安全性仍有相当广阔的领域未被探索。本文旨在通过图像处理操作作为行为隐藏的伪装手法,从而不引起未授权方对载密图像的怀疑。超分辨率是一种常见的图像处理手段,旨在将低分辨率的图像不失真地放大到指定尺寸。由于低分辨率图像和超分辨率图像首先在尺寸上有着较明显的视觉差异,这一特性为行为伪装提供了新思路。所以,本文提出了一种基于行为安全的可逆图像隐藏方法,该方法通过超分辨率这一普通图像处理行为对图像隐藏的操作进行伪装。传统图像隐藏方法与本文提出的超分辨率行为伪装方法的区别如图1 所示。首先,利用可逆神经网络将秘密图像可逆地隐藏在载体图像中,得到载密图像;其次,与现有的图像隐藏技术不同,本文对载密图像进行超分辨率处理,得到伪装图像;最后,授权接收方对秘密图像进行可逆提取,得到恢复后的秘密图像。
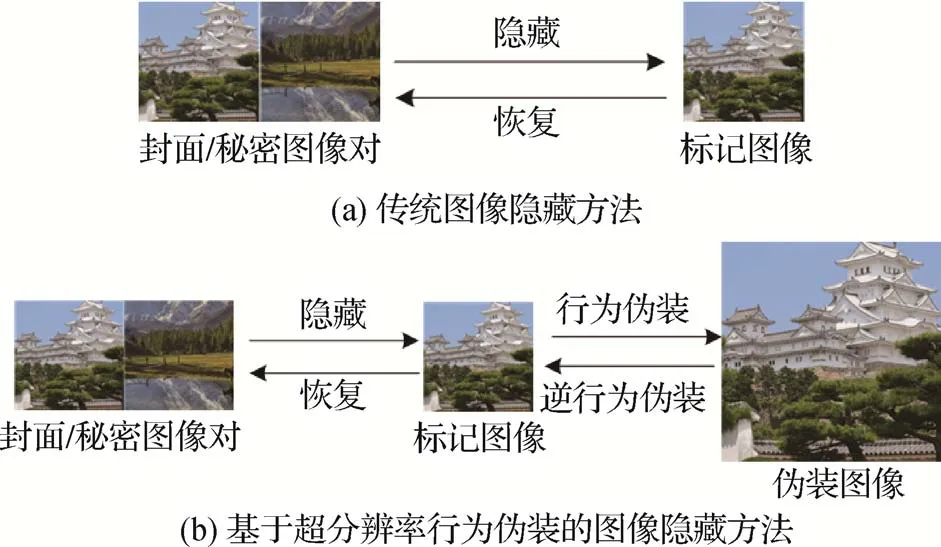
图1 传统隐藏方法与基于超分辨率行为伪装方法的区别Fig.1 The difference between the traditional hiding method and the super-resolution behavior camouflage method((a)traditional methods;(b)our super-resolution behavior camouflage method)
本文的主要贡献有:1)提出一种基于超分辨率行为伪装技术的可逆图像隐藏方法,该方法通过普通的超分辨率处理行为来掩盖图像隐藏操作。2)提出一种新的网络框架,将图像隐藏与超分辨率模块相结合,同时实现了图像隐藏和超分辨率效果。3)实验结果表明,该方法具有较好的恢复精度和安全性。
1 相关工作
1.1 图像隐藏
图像隐藏是信息隐藏的一个重要研究领域,其目的是在不改变载体图像任何视觉特征的情况下,将秘密图像隐藏在载体图像中。一般来说,传统的图像隐藏方法试图将秘密信息嵌入到空间域中。最低有效位(least significant bit,LSB)(Tamimi 等,2013)是最经典的传统图像隐藏技术,它通过将每个像素的最低有效位替换为秘密消息位来隐藏信息,因为修改最低有效位并不会实质性地改变像素的颜色或亮度。在此基础上,提出了LSB 替换(Wu 等,2005)、LSB匹配(Mielikainen,2006)等改进方法。然而,这些方法的嵌入能力较低,容易检测到隐藏在空间域中的秘密信息的存在。
除了传统的图像隐藏方法外,也提出了一些基于深度学习的图像隐藏方法。Baluja(2017,2020)首先提出使用深度神经网络将整个彩色图像隐藏在另一幅图像中。图像隐藏和恢复使用3 个独立的网络:预处理待隐藏秘密图像的准备网络、融合处理后的秘密图像和载体图像的隐藏网络以及恢复秘密图像的恢复网络。Ur Rehman 等人(2018)提出了一种基于深度学习的通用编解码器架构,用于图像隐写,以及一个旨在实现端到端训练的损失函数。Weng等人(2019)通过时间残差建模实现了视频隐写。Lu 等人(2021)提出了一种可逆隐写网络(invertible steganography network,ISN),该网络将隐藏和恢复作为图像域的一对逆问题来处理。Xu 等人(2022)提出了一种更关注鲁棒性的可逆隐写方法(robust invertible image steganography,RIIS)。以往的研究表明,与传统的图像隐藏技术相比,深度网络在容量和不可见性方面都有显著提高。它们都经过伪装,与载体图像的内容相融合,满足载密图像与载体图像不可区分的标准。然而,图像隐藏的核心是行为安全,隐藏机密信息的行为与普通用户的行为密切相关,这在很大程度上仍未探索。
1.2 可逆神经网络
可逆神经网络(INN)最早由Dinh 等人(2014)提出。基于此,Kingma 和Dhariwal(2018)提出了一种可逆1 × 1 卷积,引入INN 中并提出了Glow(genera⁃tive flow )算法,他们还使用激活归一化(activation normalizaton,ACT-norm)代替批归一化(Batchnorm),取得了更好的效果。
可逆神经网络的基本原理是,对于给定变量x和前向计算过程y=fθ(x),假设x是从y推断出来的,然后直接计算反向映射x=f-1θ(y),其中反向映射f-1θ被设计为与正向计算fθ共享相同的参数θ,这使得推算更为便利。在后续工作中,Dinh 等人(2017)提出了一种耦合层结构来实现可逆性。在加性耦合层中,每层的输入从通道或空间上分成x1和x2两部分,输出按下式计算,具体为
连接y1和y2得到输出y。当网络反向传播时,将该层的输出y按与拼接相反的方式分成y1和y2两部分,输入x由下式求得,具体为
为了保证卷积运算所需的局部相关性,只能采用通道或者空间棋盘的方式对图像进行分割。在仿射耦合层中,将每层的输入x分成x1和x2两部分后,输出y可由下式求得,具体为
在反向传播中,将y分为y1和y2,输入x由下式得到,具体为
式中,⊗和/分别代表Hadamard 乘积或逐元素乘积及其逆过程。
随后的几项研究进一步证明了INN 的卓越性能。Ardizzone 等人(2019)提出了一种称为条件可逆神经网络(conditional invertible neural network,CINN)的新架构来指导图像生成和着色。Xiao 等人(2020)使用INN 进行图像的可逆缩放。Liu 等人(2021)提出了一种可逆去噪网络(invertible denois⁃ing network,InvDN)来去除噪声,恢复干净的图像。而在可逆图像隐藏这一方面,INN 同样表现出优异的性能。国内的Lu 等人(2021)和Jing 等人(2021)率先将INN 应用于可逆图像隐藏,并取得了SOTA(state-of-the-art)性能。徐勇和夏志华(2023)使用INN 完成了发送方可否认图像隐写。Mou 等人(2023)则将INN 应用于视频隐写中。上述所有研究都证明了INN 在完成可衍生任务方面的卓越能力,这表明INN是实现可逆行为伪装的合适工具。
2 本文方法
一般来说,传统的图像隐藏技术倾向于在内容层面优先考虑载体图像和秘密图像的不可区分性,但在本文中,旨在从行为安全的角度实现图像隐藏。具体来说,本文的目标是使图像隐藏行为与常规图像处理操作无法区分。图2 给出了所提方法的概述,整个框架可以分为3 个部分:前向隐藏、行为伪装和反向恢复。在第1 部分,将载体图像和秘密图像输入,进行前向隐藏,输出和载体图像内容层面一样但藏有秘密信息的载密图像;第2 部分将载密图像进行可逆的超分辨率处理,以此实现行为伪装的目的,同时利用行为伪装的可逆性重构载密图像;第3 部分将重构图像和辅助矩阵输入,进行反向恢复,输出原始的秘密图像和载体图像。
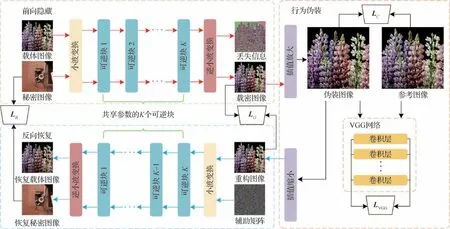
图2 本文方法的整体框架Fig.2 Framework of proposed method
2.1 前向隐藏
已有的一些工作已经证明了INN 在处理可逆图像隐藏的有效性(Lu 等,2021;Jing 等,2021;Guan等,2023;徐勇和夏志华,2023)。因此,在本文中,仍然沿用了INN 的框架。然而,单纯利用可逆神经网络对图像进行处理需要大量的计算资源,获取的有用信息较少。而本文的目标是通过使用下采样技术来减少计算负担并获得更多有用的特征。离散小波变换(discrete wavelet transform,DWT)是一种简单有效的下采样方法。它可以将输入的原始图像在垂直、水平和对角线方向上分解为低频分量和高频分量,从而在减少冗余的情况下更有效地表示图像。此外,一些研究表明,将图像隐藏在像素域中更容易导致纹理复制伪影和颜色失真(Weng等,2019)。因此,使用离散小波变换进行图像隐藏可以在频域上更有效地将秘密信息与掩蔽图像融合。此外,离散小波变换是一种可逆操作,这意味着它可以使用逆小波变换(inverse wavelet transform,IWT)进行反转以恢复原始输入,这个特性使它非常适合本文网络。
在秘密图像和载体图像传入网络之前,使用DWT 对二者进行预处理。之后,秘密图像送入前向隐藏网络并隐藏到载体图像中。前向隐藏网络由K个具有相同架构的可逆模块组成,该模块的详细信息如图3所示。
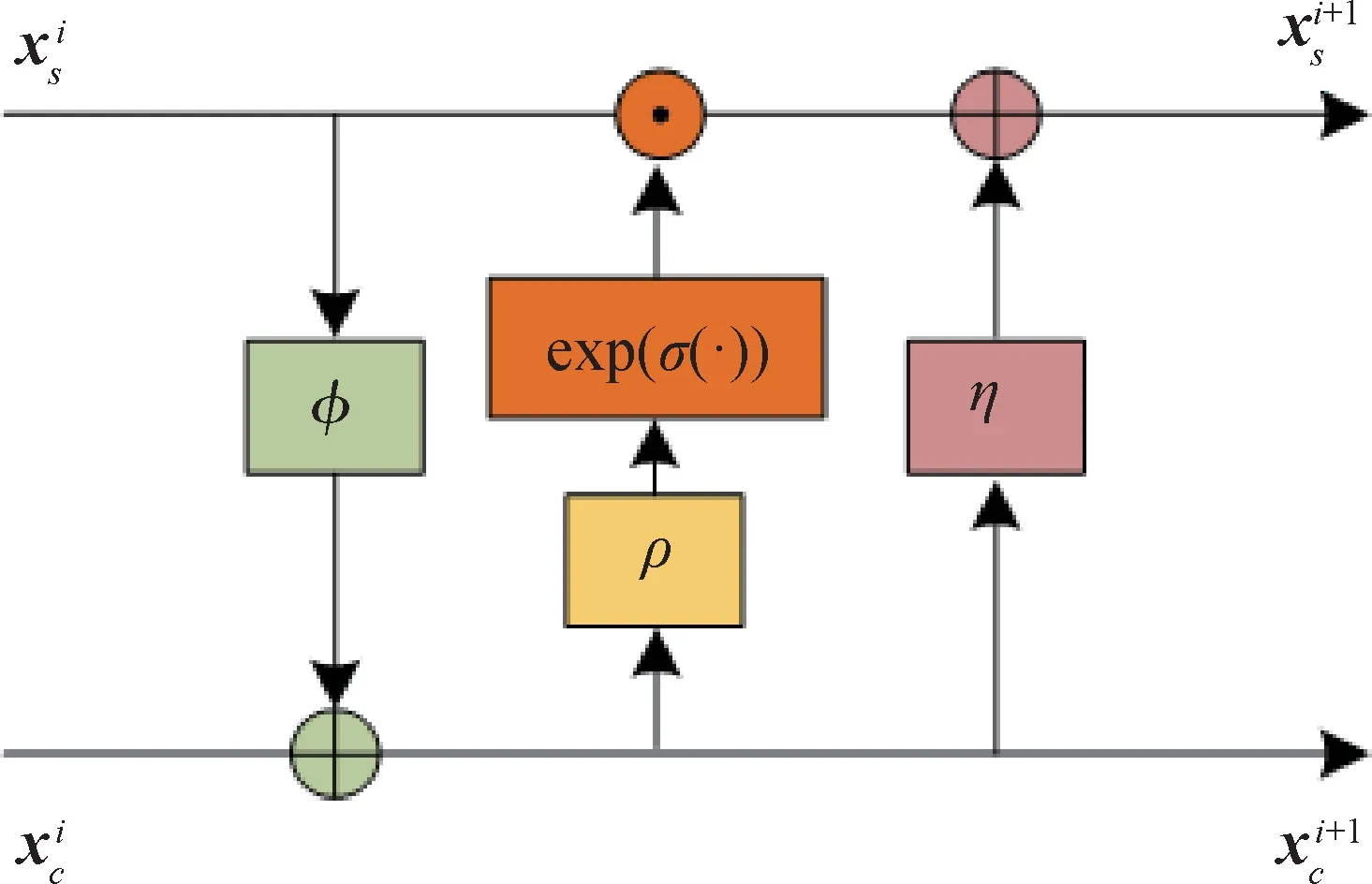
图3 在前向隐藏中的第i个可逆块Fig.3 The i-th invertible block in forward hiding
在经过最后一个可逆模块之后,将结果进行IWT 变换,输出载密图像和在隐藏过程中丢失的信息M。注意,在前向隐藏的过程中,不仅会生成载密图像,还会生成丢失信息M,这是因为只能保留三通道的输出作为最后图像的输出结果。在本文方法中,没有对丢失的信息进行约束,它可以遵循任何分布,从而在进行反向恢复时可以用任何矩阵代替。
2.2 行为伪装
在上一节中,讨论了如何以可逆的方式将秘密图像隐藏在载体图像中。在本节中,将从行为安全的角度演示超分辨率的行为伪装处理。如图2 所示,首先使用双三次插值法进行上采样,然后用一个预训练好的VGG19(Visual Geometry Group-19)网络(Simonyan 和Zisserman,2015)提取高级特征信息,进一步指导伪装图像的生成。接着仍使用双三次插值法进行下采样,恢复至原始尺寸,得到重建图像。
超分辨率一般被认为是一个不可逆的过程,因为超分辨率及其逆过程不可避免地需要使用常规卷积进行上采样和下采样。卷积过程可能会进行填充,其次,卷积的参数矩阵可能不是满秩的,这会导致下采样过程中信息丢失。因此,在本次实验中,选择常用的双三次插值法进行上下采样。双三次插值法是一种简单有效的方法,具有良好的可逆性能。双三次插值法的计算过程可表示为
式中,(x,y)代表插值点位的坐标,ci,j是原始图像中相应像素点的值,Bi(x)和Bj(y)都是双三次插值的权重函数。在此,本文使用一种较为常见的权重函数,可表示为
式中,t代表距离目标像素位置最近的相邻像素点的偏移量。对于x方向和y方向的插值,分别使用B(x-x0)和B(y-y0)来计算权重,其中x0和y0代表当前像素点的位置。通过计算相邻像素点的权重和像素值,然后进行加权求和,即可得到目标像素的插值结果f(x,y)。通过这种方式,实现了几乎可逆的超分辨率行为伪装。
但是,如果仅仅使用插值法进行放大,视觉效果是有限的。因此,本文在此处引入了一个预训练好的VGG19 网络,分别将生成的伪装图像和对应的参考图像送入,提取它们各自经过卷积层后得到的特征。一般来说,卷积层数越深,提取的特征层次越高,相关的纹理特征信息越多。在训练过程中,目的是通过迭代减少像素级损失和高级特征损失的加权和,从而生成视觉效果更好的伪装图像。通过该方法,实现了载密图像的超分辨率行为伪装操作。
2.3 反向恢复
在2.2 节中,可逆超分辨率行为伪装已经实现。接下来,需要进行反向恢复来实现秘密图像的恢复。为了实现这一点,需要执行前向隐藏的反向过程。注意,辅助矩阵N是一个随机生成的矩阵。本文使用辅助矩阵N来模拟丢失信息的分布M,并让辅助矩阵N强制捕获丢失信息的分布M,从而重建原始的秘密图像。本文中使用的辅助矩阵N遵循高斯分布。具体而言,随机采样同尺寸大小的高斯噪声N,将其送入反向恢复网络中,利用损失函数的约束,使得高斯噪声经由反向恢复网络的输出结果逼近秘密图像,由于可逆神经网络的参数共享,降低了图像重建的难度。对重构图像和辅助矩阵N进行DWT 小波变换,然后将小波变换的结果输入到反向恢复模块。反向恢复网络同样由K个具有相同架构的可逆模块组成。每个可逆块的结构与2.1 节中前向隐藏过程中的可逆块相同,但连接方式与信息流方向不同,如图4所示。
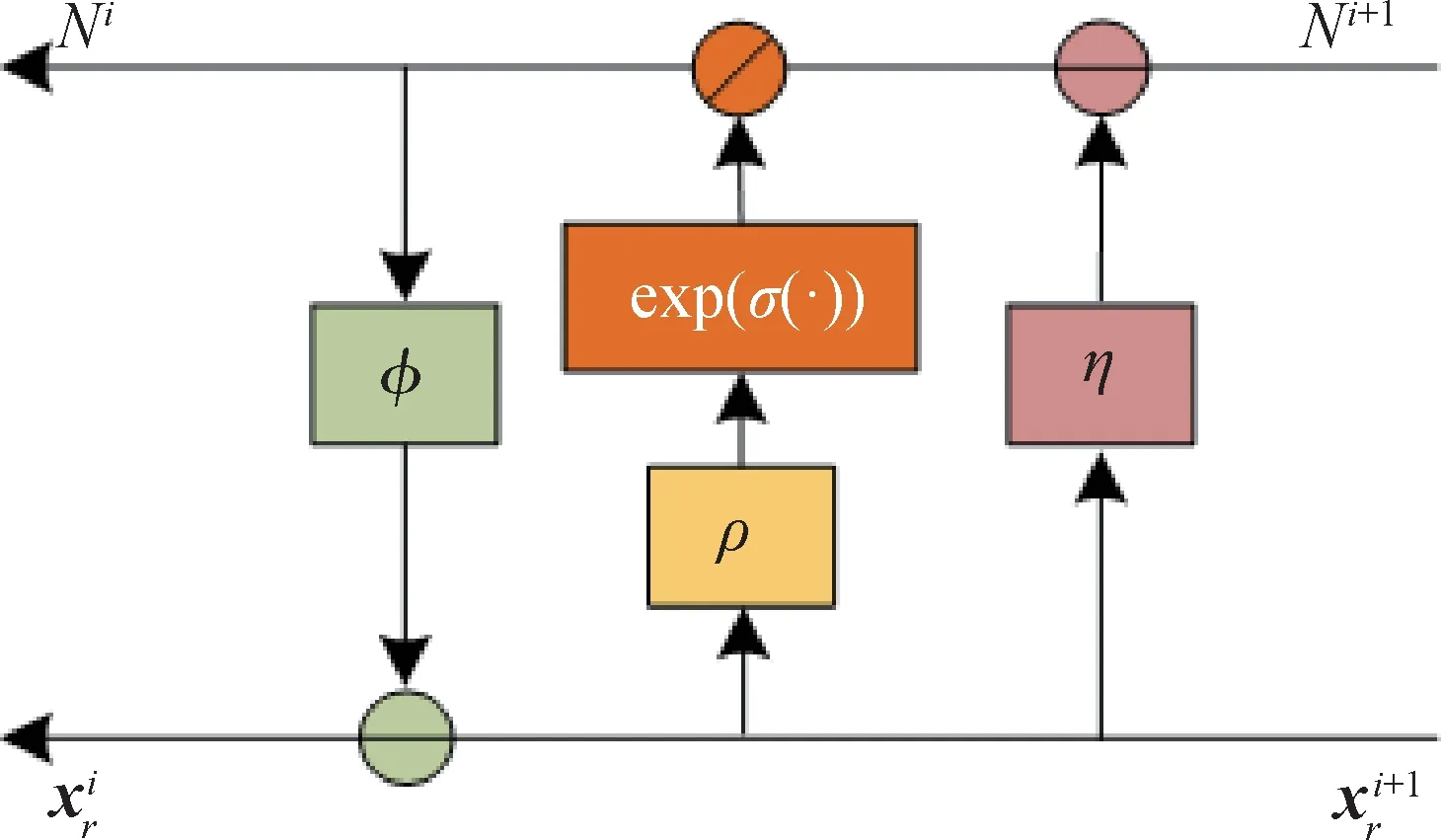
图4 在反向恢复中的第i个可逆块Fig.4 The i-th invertible block in backward revealing
信息流的方向是从第i+1 个可逆块到第i个可逆块,这与隐藏过程的顺序相反。具体来说,对于第i个可逆块,假设输入分别为和Ni+1,输出分别为和Ni,计算为
2.4 损失函数
对于秘密图像恢复这一任务,本文使用了均方误差(mean square error,MSE)损失函数LR对模型进行训练。其具体计算过程为
式中,代表秘密图像经前向隐藏过程之后的输出结果,N(t)代表辅助矩阵经反向恢复过程之后的输出结果。T代表训练样本的数量。lp代表和N(t)之间的欧氏距离(L2范数)。
对于超分辨率行为伪装这一任务,本文将低级别的像素损失LC(Dong 等,2016)和高级别的感知损失LVGG(Wang 等,2018)结合起来,计算二者之间的加权和,以谋求更好的超分辨率伪装视觉效果。其中,LC的具体计算过程为
LVGG的具体计算过程为
式中,ϕp,q表示VGG19网络内第p层最大池化层之前的第q层卷积层输出的特征映射。Wp,q和Hp,q表示VGG 网络内各自特征映射的维度。lp代表ϕp,q(xrf)m,n和ϕp,q(xsr)m,n之间的曼哈顿距离或者欧氏距离。具体选择哪种距离来计算损失函数,本文将在3.3小节深入探究。
为了保证行为伪装的可逆性,本文仍然使用了均方误差(MSE)损失函数LG进行训练。其具体计算过程为
综上,本文的总损失函数定义为
式中,λR、λC和λV均为超参数。本文将在3.2小节中进行详细探究。
3 实验与分析
3.1 实验设置
本文使用DIV2K(DIVerse 2K)公开数据集(Agustsson 和Timofte,2017)和Flickr2K(Timofte 等,2017)公开数据集进行训练及测试。DIV2K 是一个常用的单图像超分辨率数据集,包含1 000幅不相关且具有不同场景的图像,并有不同的分辨率版本。Flickr2K 包含2 650 幅图像。考虑到计算资源以及计算成本,本文随机选取了500 幅来自DIV2K 数据集的图像作为训练数据集,100 幅作为验证数据集,剩下的图像全部用来测试,评估性能的优劣。在所有实验中,本文将其随机平均分为两组,分别作为本文的载体图像和秘密图像。需要注意的是,在超分辨率行为伪装的任务中,参考图像的内容必须与载体图像的内容匹配,但分辨率不同,即对应超分辨率任务中的HR(high-resolution)图像。在数据预处理阶段,本文使用随机裁剪、随机旋转和随机翻转策略来增强数据。最后,参考图像仅在训练和验证期间可用,测试期间不可用。
在评价指标方面,本文使用峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似度指数(struc⁃ture similarity index measure,SSIM)(Wang 等,2004)来评价秘密图像的恢复效果。对于超分辨率的效果,本文使用PSNR 和感知指数(perceptual index,PI)(Blau 等,2019)来评估。PSNR 和SSIM 值越大,PI值越小,表示图像质量越好。
本文实验在Windows 10 上进行,使用Inter(R)Core(TM)i9 5.0 GHz CPU,64.0 GB 内存和NVIDIA RTX 3090 GPU。其中ρ(),η(),ϕ()中残差密集块(RRDB)的深度为5 层,可逆块K的数量设置为16,优化器采用Adam,学习率设为1E-5,每迭代5 000 次减半,训练总轮次为30 000 次,LVGG中的p和q分别是5和4,Batch大小为16。
3.2 损失函数权重设置实验及分析
在损失函数中,λR,λC和λV是用来平衡不同损失函数的权值。在这里,本文讨论了参数λR、λC和λV在实验中的影响。通过调整λR和λC的值,可以找到合适的值,使秘密图像和恢复的秘密图像不仅在视觉层面上难以区分,而且在像素层面上也难以区分。通过调整λV的值,也可以找到合适的值,使伪装图像和参考图像在视觉层面上相似。在本次实验中,本文应优先考虑秘密图像的恢复效果,其次是行为伪装。这意味着与恢复性能相关的λR和λC的取值范围应该设置得更大。此外,由于λR对结果的影响更为直接,所以应该赋予它最大的值。通过这种方式简化参数选择,可以得到最优的结果。本文使用划分好的测试数据集来探索经验参数。结果列在表1中,“↑”表示值越高越好,“↓”表示值越低越好。可以看出,λR参数越高,实验性能越好。其中,5∶3∶1的比例效果最好。因此,在接下来的实验中,本文将比例设置为5∶3∶1。
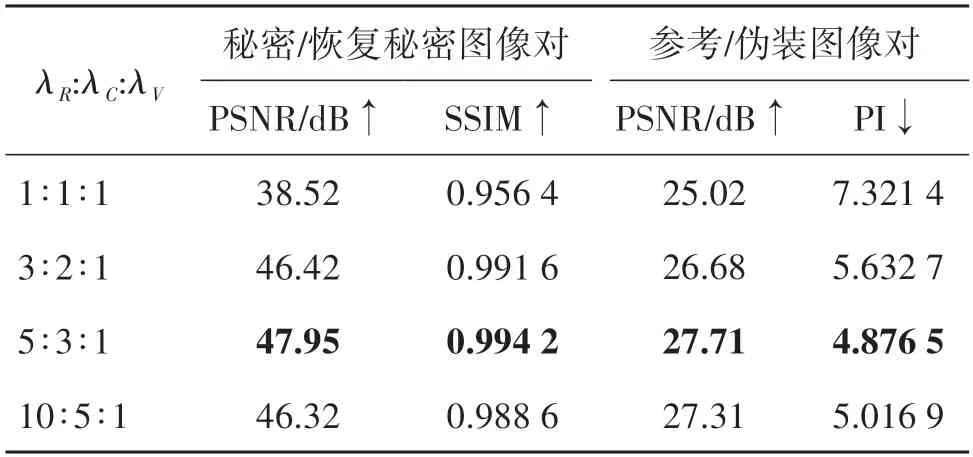
表1 不同参数下的性能表现Table 1 Performance under different parameters
3.3 消融实验结果及分析
首先,本文探究了在超分辨率行为伪装中使用不同的距离计算损失所得到的伪装图像性能。像素损失LC的原理是直接计算两幅图像对应像素之间的L1 范数或者L2 范数。通过该损失函数得到的隐藏图像通常具有较高的PSNR值。然而,当获得较高的PSNR时,由于缺乏高频内容信息,图像纹理往往过于光滑。所以本文在像素损失的基础上增加了感知损失LVGG。在实验中,本文使用VGG损失函数对参考图像和伪装图像的高级别特征计算约束,而不仅仅是浅层的像素。高级特征是通过一个预训练的VGG19网络提取的,网络越深,所提取的特征就越高级。通过对伪装图像和参考图像之间的高级特征的约束监督,使伪装图像具有更丰富的细节。本文同样使用L1范数或者L2范数来计算高级特征之间的差异。
本文使用4 种不同的损失函数对模型进行训练,并使用划分好的DIV2K 测试集图像测试不同的距离选择对超分辨率行为伪装效果的影响,随机选取1幅并截取细节作为展示。如图5所示,当LVGG选择L1 范数,LC选择L2 范数时,图像最为清晰,颜色失真最低。

图5 LVGG/LC中不同的范数选择的实验结果细节比较Fig.5 Details comparison of results obtained by different norm choices in the LVGG/LC
表2展示了所有测试图像的平均PSNR和PI值,因此,在后续的实验中,LVGG选择L1 范数,LC选择L2范数。
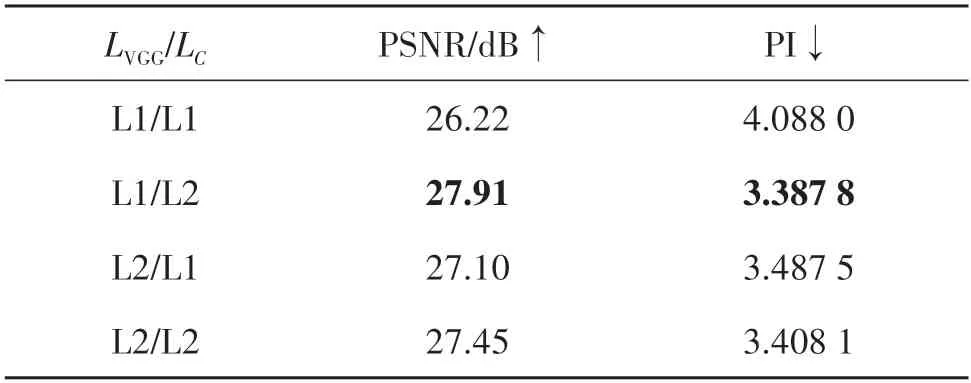
表2 不同范数下超分辨率图像平均定量指标结果对比Table 2 Comparison of average quantitative metrics results of super-resolution image under different norm
其次,关于在本网络的可逆模块中的ρ(),η(),ϕ()选择,本文也做了相应的消融实验,探索最佳结果。通常而言,ρ(),η(),ϕ()可以是任意的函数堆叠。本文使用3 种不同的卷积神经网络进行测试,分别是传统卷积直连网络、ResNet(residual network)(He 等,2016)和DenseNet(densely connected convo⁃lutional network)(Wang 等,2018)。为了进行客观比较,本文将3 种不同连接模式的卷积神经网络深度设为5层。如表3所示,本文在不同架构的模型上进行了重新训练与测试,并记录了秘密图像与恢复图像之间的PSNR 和SSIM 值。可以看出,DenseNet 给出了最好的PSNR 和SSIM 结果。因此,在接下来的实验中,本文的ρ(),η(),ϕ()采用DenseNet来表示。
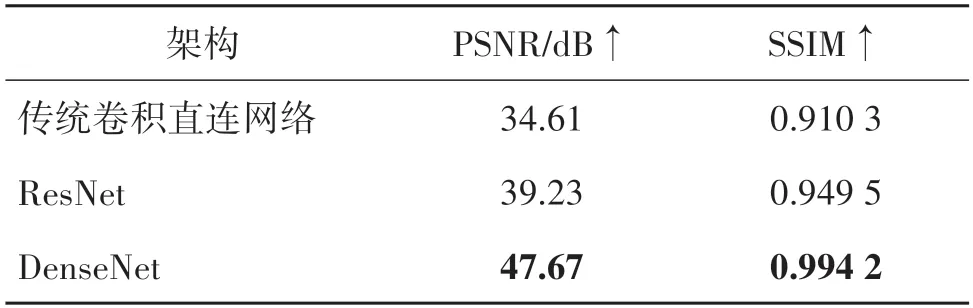
表3 不同架构的ρ(),η(),ϕ()下的定量指标结果比较Table 3 Comparison of quantitative metrics results of different architectures of ρ(),η() and ϕ()
最后,本文探究了LG损失函数的有效性。由于在超分辨率行为伪装中使用了双三次插值法进行上下采样,而插值法虽然有着较好的可逆性,但并不是完全可导的。这可能会对秘密图像和恢复图像产生不好的影响。因此,本文设计了本次消融实验来验证LG是否会影响恢复秘密图像的精度。
本文在使用LG损失和不使用LG损失的情况下分别训练了模型,并且在测试集上进行了测试。表4统计了秘密图像/恢复秘密图像对的平均PSNR 值以及SSIM值。从表中可以看出,使用LG损失要比不使用LG损失得到的PSNR值高1.86 dB,SSIM高0.012 9,证明了该损失函数的有效性。由此可见,重建图像必须和载密图像尽可能相似,以及在本文所提出的网络中保持端到端可逆的重要性。
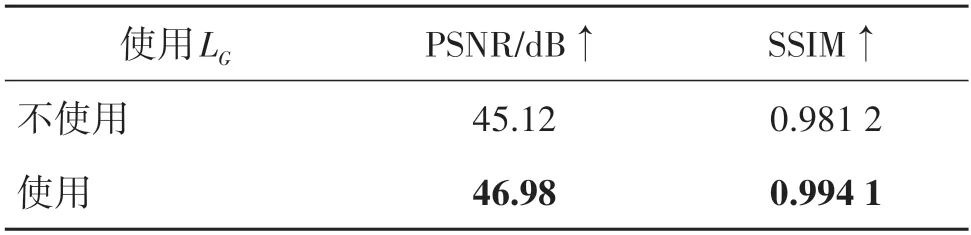
表4 LG损失消融实验下的定量指标结果比较Table 4 Comparison of quantitative metrics results of ablation study on LG loss
3.4 隐藏容量实验结果及分析
考虑隐藏容量的前提是载密图像不出现明显失真。本文将所有对比方法根据不同的隐藏容量做了定量实验。表5 记录了不同每像素隐藏比特数(bits per pixel)下的载密图像/载体图像对之间的PSNR值,以此来证明本文所提方法的容量优势。从表5中可以看出,所有方法得到的载密图像/载体图像之间的PSNR 值都会随着隐藏容量的不断增加而发生下降,当最终嵌入全尺寸的秘密图像(24 bit/像素)时,4bit-LSB 已明显超出负荷容量。基于深度学习的方法在隐藏容量方面具有较好的载荷,其中本文方法与HiNet 几乎持平,一方面是因为INN 本身的性能,另一方面是在此阶段没有对载密图像进一步修改,因此载密图像/载体图像对之间的PSNR 值较高。这证明了在保证载密图像/载体图像对性能的前提下,本文方法的隐藏容量具有一定的优势。
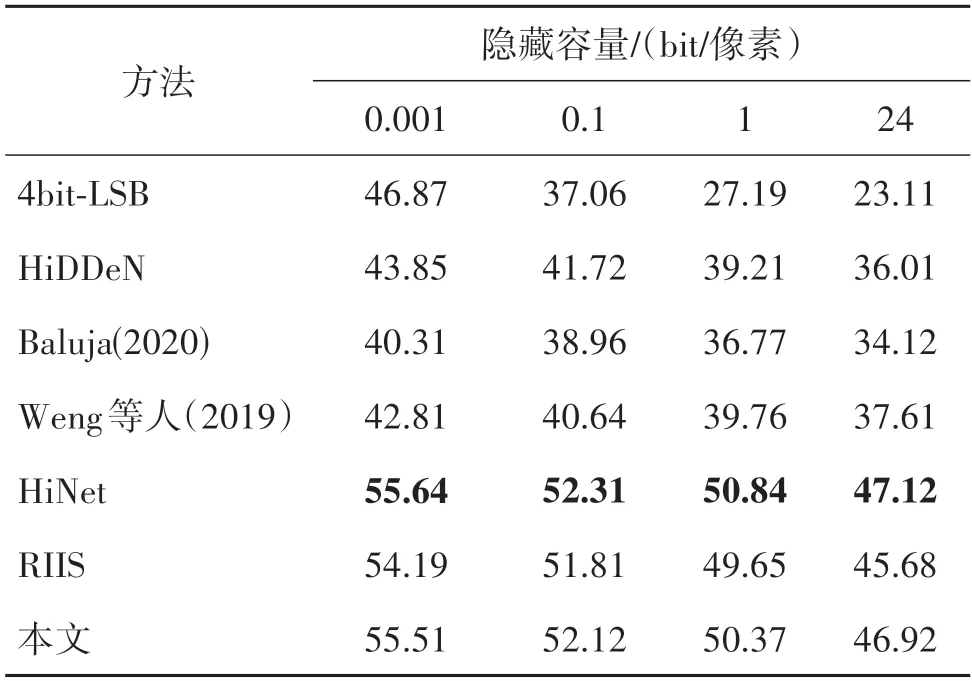
表5 不同方法在不同隐藏容量下的PSNR定量指标结果比较Table 5 Comparison of PSNR quantitative metrics results of hidden capacity under different methods/dB
3.5 恢复秘密图像实验结果及分析
在恢复秘密图像的质量方面,本文方法分别与4bit-LSB、HiDDeN(hiding data with deep networks)(Zhu 等,2018)、Weng 等人(2019)、Baluja(2020)、HiNet(Jing 等,2021)和RIIS(Xu 等,2022)这6 种目前先进的图像隐藏方法进行了对比实验。其中,4bit-LSB是传统的方法,其他5种方法都是基于深度学习的方法。
本文将训练好的模型在测试集上进行测试,并从实验结果中随机选择一幅图像进行显示。图6显示了该方法和其他6种方法的恢复秘密图像。从图像细节可以看出,4bit-LSB、HiDDeN、Weng 等人(2019)和Baluja(2020)经常会出现颜色偏差和模糊的伪影。与这些方法相比,本文方法和HiNet、RIIS 都具有较高的色彩保真度,且没有伪影出现。这体现了基于INN 的可逆图像隐藏方法相较于传统基于Encoder-Decoder 结构的方法(HiDDeN、Weng 等人(2019)、Baluja(2020))的优越性。主观上而言,本文结果与HiNet产生的结果之间没有明显的视觉差异。

图6 恢复秘密图像的细节对比Fig.6 Details comparison of recovery secret images((a)ground truth;(b)4bit-LSB;(c)HiDDeN;(d)Baluja(2020);(e)Weng et al.(2019);(f)HiNet;(g)RIIS;(h)ours)
表6 为不同方法下的恢复秘密图像的定量指标结果比较。客观上来看,本文方法得到的PSNR 和SSIM 值与HiNet的结果非常接近。这是由于在行为伪装过程中使用了双三次插值法进行上采样和下采样,而这一步是有损失的,所以本文的秘密图像恢复性能会比HiNet 稍微差一些。但本文更强调从行为安全的角度去提升可逆图像隐藏的安全性,而模拟逼真的正常图像处理行为与图像隐藏的可逆性之间存在着平衡。如何权衡二者之间的关系,也是本文研究的重难点。相比之下,同样使用INN结构的RIIS则更加强调鲁棒性,在训练过程中对载密图像加入了噪声,接着再进行训练去噪,这一步同样是有损失的。但本文方法的平均PSNR 值仍可以达到47+dB,SSIM 值可以达到0.99+。轻微的损失从行为伪装的角度是可以接受的。
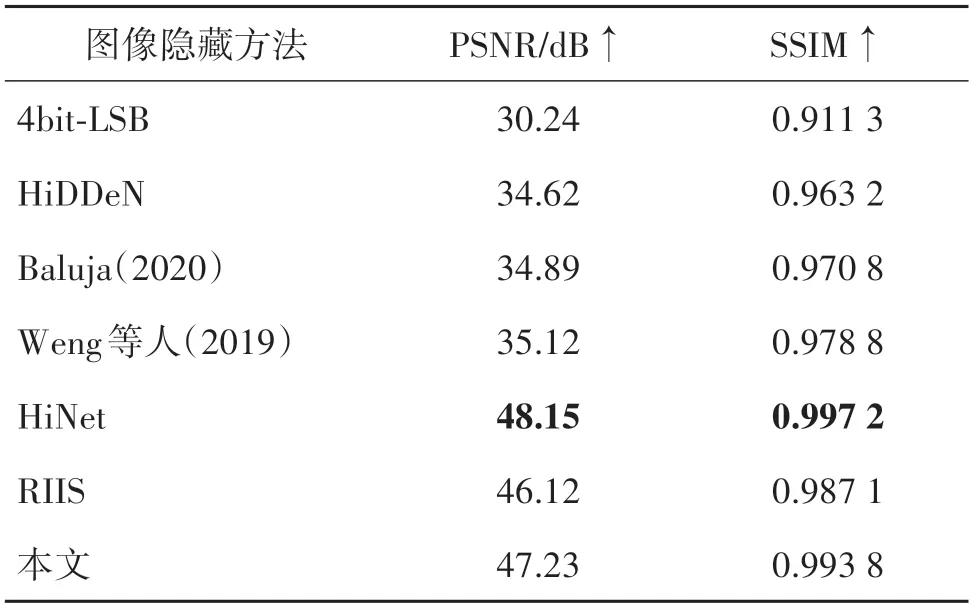
表6 不同方法下的恢复秘密图像的定量指标结果比较Table 6 Comparison of quantitative metrics results of recovery secret image under different methods
3.6 超分辨率行为伪装的实验结果及展示
在超分辨率行为伪装的质量方面,本文选择了传统的双三次插值法以及基于深度学习的方法SRCNN(super-resolution convolutional neural net⁃work)(Dong 等,2016)作为本文比较的方法。需要注意的是,本文的主要目标是实现具有超分辨率行为效果的可逆行为伪装,而不是追求极致的超分辨率效果。
本文将训练好的模型在测试集上进行测试,并随机选择一幅超分辨率图像进行显示。图7 显示了本文的超分辨率结果与其他方法的结果比较。从图7可以看出,双三次插值法得到的结果较为模糊,而SRCNN 虽然具备了更多细节,但是从边缘来看,存在着较为明显的失真与像素结块。而本文方法的结果更为清晰自然,且失真较小。

图7 超分辨率图像的细节对比Fig.7 Details comparison of super-resolution images((a)high-resolution;(b)Bicubic;(c)SRCNN;(d)ours)
从客观的角度来看,表7 展示了测试集图像的平均PSNR 和PI 值,本文方法得到了最高的平均PSNR 和最低的平均PI 值。这证明了本文方法不仅在像素水平上取得了最好的结果,在人眼感知方面,也达到了令人满意的水平,可以满足超分辨率行为伪装的需要。
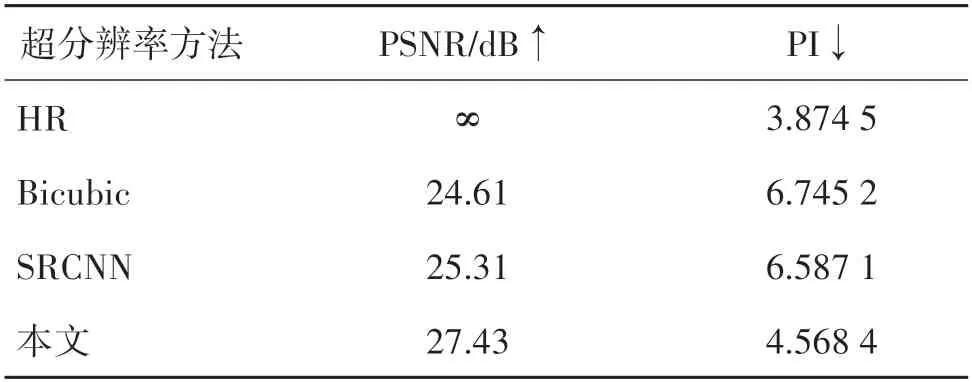
表7 不同方法下的超分辨率图像的定量指标结果比较Table 7 Comparison of quantitative metrics results of super-resolution image under different methods
3.7 隐写分析实验结果及分析
隐写分析是衡量图像隐藏技术安全性的重要指标。基于深度学习的隐写分析方法利用网络的强大学习能力来独立识别图像的异常特征,从而产生检测结果。因此,在本节中,通过使用两个较为先进的隐写分析网络Xu-Net(Xu 等,2016)和SRNet(stega⁃nalysis residual network)(Boroumand 等,2019)将本文方法与其他图像隐藏方法进行比较。
本文使用Weng等人(2019)方法中概述的最新训练策略,即观察隐写分析网络需要多少对载体/载密样本学习训练,才能在测试阶段正确区别出载密图像与载体图像,以研究隐写分析网络准确分类载体和载密图像所需的最小样本数。本文单独对行为伪装模块进行训练,得到一个超分辨率处理网络,接着将原始载体图像直接通过该网络,得到隐写分析实验中的载体图像。其次,本文将通过前向隐藏和行为伪装模块后的伪装图像作为本次隐写分析实验中的载密图像,成对送入隐写分析网络进行训练并测试。
由图8和图9可以看出,基于INN的3种方法(本文方法、HiNet和RIIS)被隐写分析网络完全识别所需的训练样本量与其他方法相比而言具有显著的优势。从结果可以看出,本文方法与HiNet 几乎持平,这得益于INN 优异的性能。而RIIS 方法稍差,这是由于对载密图像做了进一步的并不完全可逆修改,而本文方法则是因为超分辨率行为伪装并不能降低载密图像中原有的因前向隐藏过程中出现的轻微噪声。同理,HiNet 的载密图像也存在着轻微的噪声,这些都是由于前向隐藏网络中六通道卷积所导致。当然,随着训练样本量的逐步增加,最终均被识别。综上所述,本文方法具有一定的抗隐写分析能力。
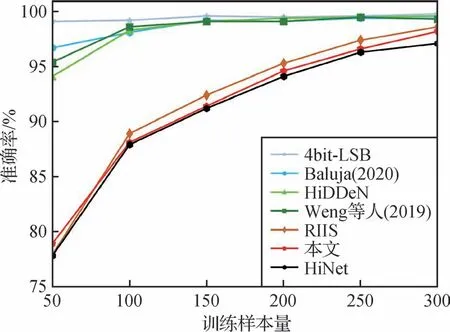
图9 SRNet隐写分析检测结果Fig.9 SRNet steganalysis
4 结论
本文从行为安全的角度出发,提出了一种新的基于超分辨率行为伪装的可逆图像隐藏方法,即在隐藏秘密图像的过程中,同时进行超分辨率行为伪装处理,获得具有秘密信息的超分辨率图像,从而转移未授权方的注意力,实现对秘密图像的保护,增强秘密图像的安全性。实验结果表明,本文方法不仅可以实现高容量、高隐蔽性和高恢复精度,而且在未授权方的混淆中起到很好的作用,伪装后的图像仍然保持良好的视觉效果。
然而,本文方法依然存在一些不足。采用可逆神经网络虽然取得了较好的恢复效果,但是对于行为伪装而言,如何平衡行为伪装的效果与整个网络的可逆性,仍然是一个值得研究的问题。未来将探索更多适合行为伪装的图像处理操作,以及如何开发一种较为通用的网络框架,能够实现各种行为伪装操作的同时,保证秘密信息的恢复精度。最后,希望图像隐藏中的行为安全领域得到更多的关注。
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
数学物理学报(2019年3期)2019-07-23
今日农业(2019年15期)2019-01-03
家庭影院技术(2018年9期)2018-11-02
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
小溪流(画刊)(2016年11期)2017-01-05
作文与考试·小学低年级版(2015年22期)2015-12-07
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
小学科学(2015年11期)2015-12-01
