
面向感知哈希的图像数据集
2024-02-24 09:08周元鼎房耀东秦川
中国图象图形学报 2024年2期
周元鼎,房耀东,秦川
上海理工大学光电信息与计算机工程学院,上海 200093
0 引言
随着互联网和多媒体技术的发展,图像数据交换、搜索和识别的需求不断增加。与此同时,未经授权的图像复制、篡改等侵权行为也导致版权问题更加突出(Jing 等,2022;赵若宇 等,2023)。在这种背景下,快速查询图像是否侵权已成为一项重要任务。
感知图像哈希又称图像摘要或图像指纹,是一种主动认证图像版权的方法,该技术通过将图像的鲁棒特征转化为固定长度的哈希序列来实现图像版权认证(Xing 等,2023)。通过比较目标图像和原始图像哈希序列的相似程度,可判断目标图像是否由原始图像经过修改后得到。感知哈希算法认证时不需要对图像进行修改,可以将图像数据转化为较短的特征值,从而减小存储空间需求。感知图像哈希有3 个主要的性能指标:感知鲁棒性、抗冲突性和密钥依赖安全性(欧阳杰 等,2011)。感知鲁棒性要求原始图像经过内容保留操作得到的相似图像和原图之间的哈希距离尽可能小。抗冲突性要求不相似图像产生的哈希序列和原图完全不同,也就是原图和不相似图像的哈希距离较大。密钥依赖安全性要求不同密钥生成相同哈希序列的概率几乎为0,使得攻击者无法伪造哈希序列。
感知图像哈希任务中图像的分类如图1 所示,绿色的部分代表原始图像和感知相似的图像,感知相似图像的定义为原始图像经过各种图像内容保留操作后得到的图像,这些编辑图像保留了原始图像的鲁棒特征。感知不相似图像则是除了感知相似图像以外的其他图像(图1 中的灰色部分),首先是与原图具有相同语义对象的图像,由于感知图像哈希侧重于保护图像的鲁棒特征,并不关注语义信息,所以这些与原图语义对象相同的图像也应该被认为是感知不相似的图像。其余感知不相似的图像是与原图毫无关联的图像。感知图像哈希领域的数据集也可以分为原图、感知相似图像和感知不相似图像3个部分。原图一般是从其他图像领域所使用的数据集中挑选出来的,感知相似图像是原图经过图像内容保留操作后得来的,感知不相似图像则是从其他数据集里随机挑选的。
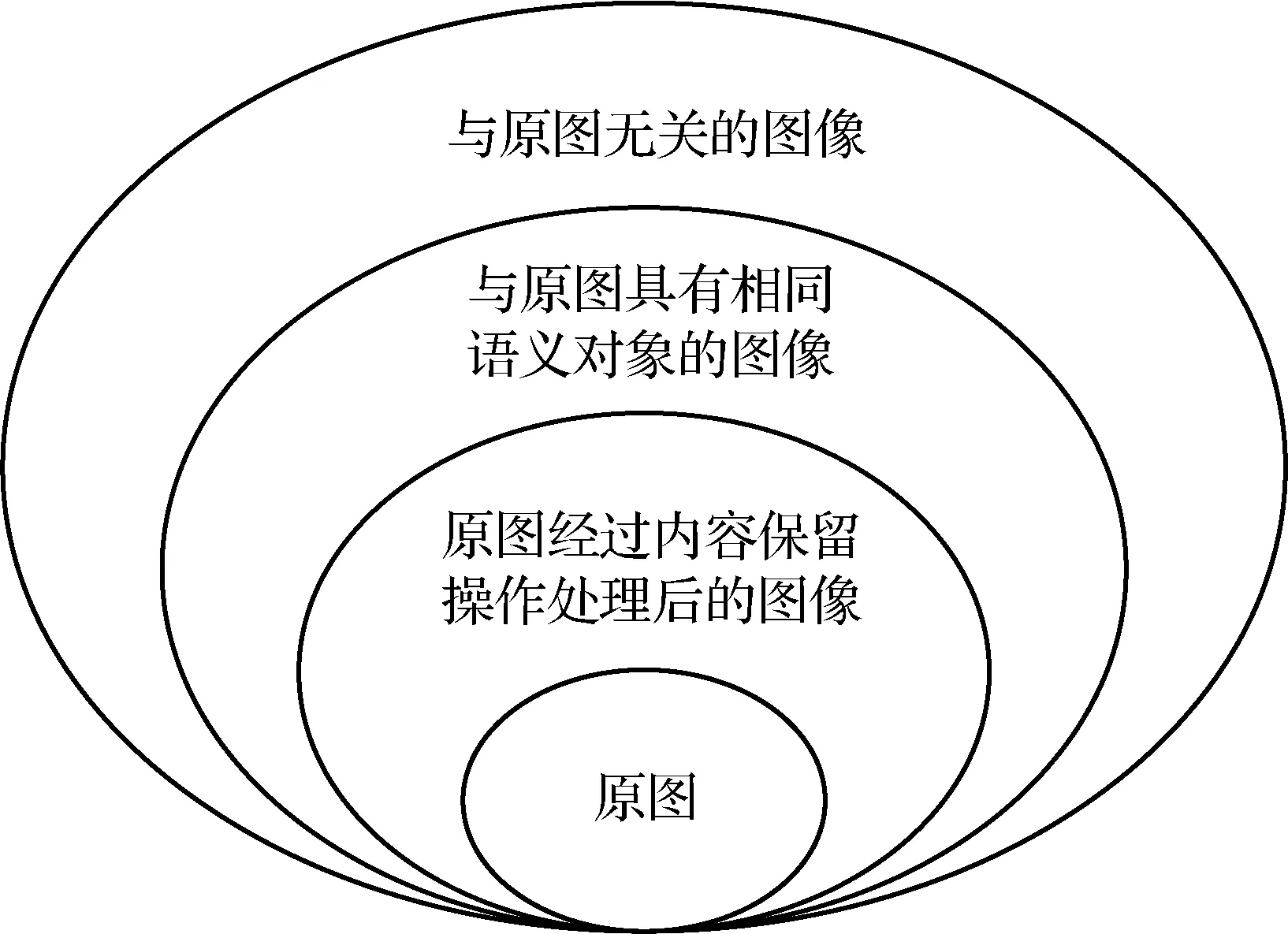
图1 原图、感知相似与感知不相似图像的划分Fig.1 Division of original,perceptual identical and perceptual distinct images
感知哈希的研究已进行了很久,但目前该领域所使用的数据集仍然存在一些普遍问题(黄小燕等,2021)。首先,现有的图像内容保留操作比较简单,而现实中的图像编辑是比较复杂的,通过简单图像内容保留操作训练出来的神经网络效果有限,难以成为良好的内容认证手段。其次,现有数据集在结构上不够完善,原图与不相关图像的差距过大,导致面对比较难以分辨的图像时容易判断错误,模型的泛化能力有待提高。
为了解决这些问题,本文构建了一个全新的感知图像哈希数据集(perceptual image hashing data⁃set,PIHD)。该数据集中所使用的内容保留操作更加复杂、丰富,本文将现在常用的图像内容保留操作进行总结,并分类得到了35 种单一的图像内容保留操作。现实中对于图像的编辑参差不齐,所以对于每一个图像内容保留操作,本文都设计了一个参数范围,在这个范围中随机选择参数,影响内容保留操作的强度。现实中对于图像的编辑也往往不是单一的操作,所以除了单一的图像内容保留操作,还设计了13 种随机的组合操作,丰富了相似图像的种类,增加了数据集的复杂度。对于不相似图像,除了使用之前数据集所使用的随机图像以外,还挑选了许多和原图语义相似的图像,增加了数据集的挑战性,也提高了所训练模型的泛化性能。本文的新数据集一共包含116 400幅图像,充足的图像基数也保证了模型的有效训练。
本文所构建的数据集PIHD 旨在提高感知图像哈希技术在实际应用中的效果和泛化能力。本文所构建的数据集创新点如下:1)数据集的原始图像来源广泛,其感知相似图像所使用的图像内容保留操作复杂、丰富,不相似图像的选择也更加符合感知图像哈希任务。2)大量的实验结果表明,在本文数据集上训练得到的神经网络模型不需要重新训练或微调,直接迁移到其他数据集上也能达到很好的效果。本文的研究成果将进一步推动感知图像哈希技术的发展和实际应用,有助于更好地保护图像版权。
1 相关工作
1.1 感知图像哈希算法
研究者已经提出了许多感知图像哈希算法,根据哈希序列的提取方式,现有的感知哈希算法可以分为基于空间域、变换域、降维和学习的4类。
1.1.1 基于空间域的算法
这类算法通常从空间域中提取鲁棒特征,该类算法对噪声、失真等攻击有很强的鲁棒性。Tang 等人(2016)通过提取梯度场的方式将图像分成多个同心环,计算每个环的熵得到特征向量,从而产生哈希序列。此外,他们还提出了一种基于环分区和不变向量距离的算法,该算法提取每个同心环的梯度特征向量和局部二进制模式(local binary patterns,LBP)纹理特征。随后,将这两组特征向量合并以生成哈希码。Shen 和Zhao(2020)将彩色图像转换为颜色拮抗对,并根据颜色分量的特性对每个分量进行降采样,然后使用四叉树结构对每个通道进行划分,利用其颜色分量计算其特征向量,并最后整合得到哈希码。Choi和Park(2012)将图像分成多个连续的区域,并对每个区域生成一个直方图。然后将每个直方图进行压缩和离散化,以生成哈希码。
1.1.2 基于变换域的算法
这类算法通常从变换域中提取鲁棒特征,然后利用系数生成最终的哈希值,该类算法对平移、旋转和缩放等攻击具有很强的鲁棒性。Ouyang 等人(2016)将图像转换成四元数域上的复数,然后利用四元数Zernike 矩来提取图像特征,最后将特征映射为哈希码。Liu 和Huang(2019)基于局部特征点检测对图像进行预处理,并且使用方向梯度直方图(histogram of oriented gradient,HOG)算法提取图像的全局特征,之后利用局部特征和全局特征来构建图像的哈希码。Tang 等人(2013a)将图像分解为多个小波子带,然后基于局部熵的特性来选择图像的不同频带,对选定的频带进行小波系数量化,生成哈希码。
1.1.3 基于降维的算法
基于降维的感知哈希算法将图像特征降低到较低的维度后映射为哈希码。Sun 和Zeng(2014)利用压缩感知技术将图像重构为稀疏表示,并基于这种表示构造图像哈希码。Tang 等人(2014)将图像划分成多个环形区域,然后利用非负矩阵分解(non⁃negative matrix factorization,NMF)技术提取每个区域的特征,并将这些特征组合成最终的哈希码。Qin等人(2016)将图像分为多个大小相等的块,然后利用块截断编码算法对每个块进行压缩,并将压缩后的数据作为哈希码的第一部分,同时利用图像的梯度信息、边缘信息和色彩信息来构建哈希码的另一部分,以提高哈希码的鲁棒性和区分度。除此之外,他们还利用图像的局部结构特征,包括边缘、角点和空白区域等信息来构建哈希码,并且采用选择性采样机制,将图像中的结构特征进行筛选和排序,选取最显著的特征进行哈希编码。
1.1.4 基于学习的算法
在这类算法中,可以通过大量的数据训练卷积神经网络,将图像哈希生成过程纳入神经网络的学习过程中,最终的哈希码是根据学习到的神经网络参数生成的。Li等人(2020)提出了一种基于去噪自编码器的图像哈希算法,通过向自编码器添加内容保留操作进行模型训练。Qin 等人(2021)则提出了一种基于多约束卷积神经网络(convolutional neural network,CNN)的感知哈希算法,使用两种约束进行模型训练,并动态调整约束值以提高感知鲁棒性和判别能力。而Sun 和Zhou(2022)提出的CNN 算法基于哈希中心,将原始图像及其感知上相似的图像视为同一类别,并将它们收敛到相应的哈希中心。除了监督学习之外,Gao 等人(2023)提出了一种基于对比学习的无监督感知图像哈希模型。该模型利用对比增强结构,通过改变样本增强方式和强度来优化模型,同时还设计了一个综合损失函数帮助模型学习未标记数据的感知特征表示。
虽然现有的感知图像哈希算法在增强感知鲁棒性方面取得了一定的进展,但现有数据集中使用的内容保留操作种类较少,在面对实际应用中日趋复杂的编辑图像时性能会显著下降。因此,在未来的研究中除了需要进一步探索和改善感知图像哈希算法以外,还需要优化数据集的构建,引入更多、更实际的图像内容保留操作以提高算法的实用性。
1.2 感知图像哈希中的常用数据集
感知哈希算法中的数据来源一般是一些公开的图像数据集(Huang 等,2023;Yang 等,2022)。由于图像处理的需求不断增加,研究人员构建了许多数据集。
1)COCO(common objects in context)数据集(Lin等,2014)。COCO 数据集是一个用于目标检测、图像分割和图像字幕等任务的大规模数据集。该数据集中包含了超过330 000幅图像,每幅图像都包含多个目标,总共涉及80 个不同的目标类别,如人、车、动物、食物等。除了图像和标注信息外,COCO 数据集还提供了一个图像字幕的数据集,包含了超过200 000 幅图像和相关字幕,使得COCO 数据集可以用于多个计算机视觉任务。
2)CASIA(Chinese Academy of Sciences,Insti⁃tute of Automation)数据集(Dong 等,2013)。CASIA数据集是基于哈希算法的篡改检测领域中常用的一个数据集。CASIA v1.0 包含800 幅原始图像和921幅篡改图像,涵盖了不同的图像类别,包括场景、建筑、植物、人物、动物、物品、自然景观和纹理等。这些图像都是以JPEG 格式存储的,尺寸为256 × 384像素。CASIA v2.0 包含了更多的图像类别,同时也包含了更加复杂的篡改场景。
3)RAISE(raw images dataset)数据集(Dang-Nguyen等,2015)。RAISE数据集是一个用于数字伪造检测算法评估的大规模数据集。它包含了超过8 000 幅高分辨率RAW 图像,图像采用了3 种不同的相机,拍摄于不同的场景和时刻。RAISE 数据集为每幅幅图像提供了丰富的标注,涵盖了室内、室外、景观、自然、人、物品和建筑等标注,其中也包含了多种复杂的伪造场景,如数字插入、删除、平滑、复制、粘贴等。图像尺寸从580 × 387 像素到5 760 ×3 840像素不等。
4)UCID(uncompressed colour image dataset)数据集(Schaefer 和Stich,2004)。UCID 数据集中包括1 338 幅RGB 非压缩图像,其分辨率为384 × 256 像素或256 × 384 像素。UCID 数据集中的图像涵盖了多种场景和主题,如自然风光、城市街景、室内场景、人物照等。UCID 数据集也提供了丰富的图像特征和注释,非常适合于图像处理、计算机视觉和机器学习方面的研究和实践。
5)USC-SIPI(University of Southern California,Signal and Image Processing Institute)数据集。USCSIPI数据集是由美国南加利福尼亚大学信号与图像处理实验室收集和整理的,是广泛应用于图像处理和计算机视觉领域的经典数据集之一。该数据库根据图像的基本特征分为多个分类卷,包括纹理、航拍和序列等。所有的图像都以TIFF格式储存。
6)VOC2012(visual object classes)数据集。VOC2012 数据集是图像识别领域一个非常受欢迎的数据集。该数据集包含从互联网上搜集的20 个物体类别,共20 000幅图像,其中每个类别的样本图像数量不少于500 幅。每个物体都提供了高标准的标注信息,所有图像均由手动标注物体区域,给出了物体所在的像素坐标(如边缘点、顶点),便于计算机视觉专业人员的研究和工作。该数据集广泛用于目标检测、分割以及物体识别领域的研究和应用。
7)现有感知图像哈希数据集存在的问题。传统的感知哈希数据集通常从公开数据集中选取原始图像,然后在这些原始图像上使用设计好的内容保留操作生成感知哈希数据集。然而,这些数据集往往存在着以下问题:1)图像内容保留操作的种类较少,一般不超过10 个,因此训练出的神经网络模型泛用性较差;2)在以往的数据集中,待认证的图像与无关图像的差别过大,使得神经网络模型能够很容易地学习到这些图像之间特征的差别,从而在这些数据集上取得良好的认证效果。而在实际的认证场景中,情况通常更加复杂,因此很多在这些简单数据集上训练得到的模型实用性较差。为了解决这些问题,本文提出了一个新的感知哈希数据集,更加贴近现实中的应用场景,从而提高了模型的泛用性。
2 数据集构建
本文在以往感知哈希数据集的基础上构建了新的数据集,该数据集同样由原始图像、感知相似图像和不相似图像构成。下面将从这3 个部分介绍本文的数据集。
原始图像是感知哈希任务中需要认证的图像,本文数据集中一共有1 200幅原始图像,一部分来源自现有的图像处理数据集,另一部分则是从互联网上选取的。ImageNet-1K(a large-scale ontology of images built upon the backbone of the worldnet,1 000 classes )数据集(Deng 等,2009)是目前图像分类领域常用的数据集,该数据集中共有1 000个类别的图像数据,所涉及的图像种类非常丰富,涵盖了大部分生活中可见的图像类别。本文首先从这1 000 类的每个类中挑选1 幅图像作为原图。还有200 幅原始图像是从互联网上选取的,本文让ChatGPT(chat generative pre-trained Transformer )(Brown 等,2020)随机生成200 个物体的名字,然后去互联网上爬取对应的图像。图2 展示了数据集中的一部分原始图像。数据集中挑选的都是分辨率较高的图像,在预处理阶段统一将其压缩到224 × 224 像素进行后续处理。

图2 数据集的部分原始图像Fig.2 Some of the original images in our dataset
感知相似图像是原图经过图像内容保留操作之后得到的,针对以往数据集中感知相似图像过于简单的情况,首先丰富了图像内容保留操作的种类。将图像内容保留操作大致分为4 个类别,分别是几何变换、图像增强、滤波操作以及图像编辑。每一个大类下面又细分成了许多种不同的操作类型,一共35 种单一的图像内容保留操作。为了充分保证随机性,对于每一种操作都在一个限定的范围里随机设置其参数。使用2021 Image Similarity Dataset and Challenge 提供的官方工具库AugLy(Douze 等,2022)来制作内容保留操作,表1 展示了本文所使用的操作名称及其参数范围。

表1 本数据集所使用的图像内容保留操作及其参数范围Table 1 The image content-preserving manipulations and their parameter ranges used in our dataset
现实中对于图像的篡改也往往不是单一的内容保留操作,所以还设计了13 种组合操作,它们是从35 种单一操作中随机选取4 种作用于原图得来的。由于随机性的存在,数据集的测试集里会出现一些在训练集中没有学习过的组合操作,这也是符合实际情况的,因为现实场景中也会出现许多没有学习过的组合图像篡改方式。35种单一操作加上13种组合操作,本文数据集的图像内容保留操作共48种,超过了大多数现在使用的感知哈希数据集。
感知不相似图像的范围非常广泛,除了原图经过适当强度的内容保留操作得到的图像以外,其他图像都是感知不相似的。之前数据集所采用的感知不相似图像往往是随机选择的,本文则在此基础上加入了来自同类别的其他图像,原图来自于哪个图像类别,则不相似图像也从这个类别中进行挑选,这部分图像是手动筛选的,挑选的都是与原始图像比较接近的同类图像。这也是符合感知图像哈希任务的,因为感知图像哈希是认证图像内容的,并不涉及语义信息,所以语义相同的其他图像也应该被认为是感知不相似的。为了平衡感知相似和不相似图像的数量,对于每一幅原始图像,本文也挑选了48 幅感知不相似图像,其中24 幅是同类别的其他图像,另外24 幅是随机挑选的图像。图3 展示了2 幅原始图像和它们所对应的一些感知相似与不相似图像。

图3 数据集的图像示例Fig.3 Image examples in our dataset
综上所述,与以往的数据集相比,本文所提出的数据集原始图像来源广泛,相似图像所使用的内容保留操作种类更加丰富多样,不相似图像的选择也更加符合感知图像哈希任务。该数据集称为PIHD,意为面向感知图像哈希任务的数据集,本文期望通过该数据集训练得到的模型,在实际的应用中能有更好的认证效果,并且有一定的泛化能力。
3 数据集验证与评估
3.1 实验设置
为了验证本文数据集PIHD的性能,选取不同的深度学习模型在多个数据集上进行对比。在数据集的选择上,选取了感知哈希领域比较经典的4 个方案所使用的数据集进行对比,分别是HCE(Hash CEnter )(Sun 和Zhou,2022)、DAE(Denoising Auto⁃Encoder )(Li 等,2020)、MCND(Multi-Constraint Net⁃work Dataset )(Qin 等,2021)和RPIVD(Ring Parti⁃tion and Invariant Vector Distance)(Tang 等,2016),由于这4 个方法均没有公开数据集,所以按照其论文中所提供的图像内容保留操作及参数复现了这4 个数据集。复现数据集的原始图像来自1.2 节中所提到的感知图像哈希常用的数据集,表2 列出了从这些数据集中所选取的图像数量,先从前5 个数据集中选取,不够时再从COCO数据集中补充。
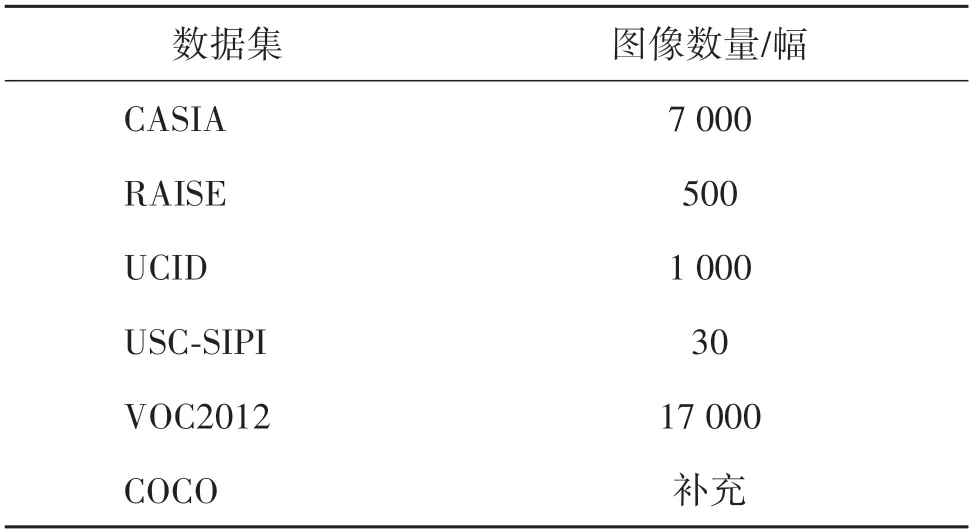
表2 对比数据集的图像来源和数量Table 2 Source and number of images in the dataset used for comparison
需要注意的是,为了使复现的数据集能够用于训练神经网络模型,图像数量与原文中的略有不同,具体的图像数量如表3 所示。所有的数据集都按照7∶2∶1 的比例来划分训练、测试和验证集。复现数据集的图像组成方式与本文数据集一样,每一批输入神经网络的图像组都是按照1 幅原图、m幅感知相似图像和m幅感知不相似图像组成。这2m+1幅图像可以表示为
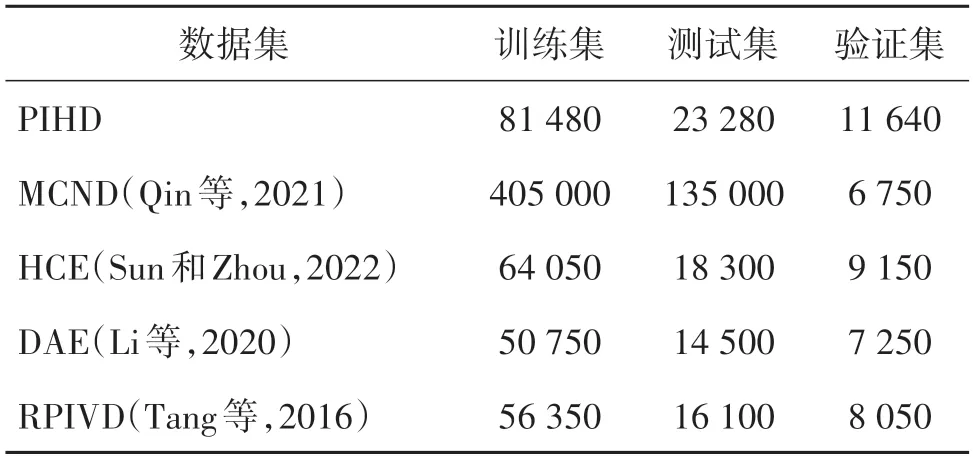
表3 本文数据集PIHD与4个对比数据集中训练、验证、测试集图像数量Table 3 Number of training,validation,and test images in our PIHD and four compared datasets/幅
在模型的选择上,本文选取了图像感知哈希领域效果很好的深度学习模型MCCNN(multiconstraint convolutional neural network)(Qin 等,2021)和经典的ResNet50(deep residual network-50)(He 等,2016)、Convnext(convnet for next decadetiny)(Liu 等,2022)、AlexNet(Alex Krizhevsky net⁃work )(Krizhevsky 等,2012)作为比较的深度感知哈希模型,将网络最后的输出层换成了哈希生成网络,分别在表3中的5个数据集上进行训练并测试。
3.2 有效性
首先,验证在PIHD数据集上训练得到的模型性能,通过错误接受率(false acceptance rate,FAR)和错误拒绝率(false rejection rate,FRR)来评价感知图像哈希方法的性能。FAR用于计算感知不相似图像被错误判断为感知相似的概率,而FRR 则用于计算相似图像被错误判断为感知不相似图像的概率。FAR 和FRR 值越小,代表模型的认证性能越好,对于原始图像I、相似图像和不相似图像-I,FAR 和FRR计算为
式中,D(I,)代表原图与相似图像的哈希距离,P(∙)则代表概率函数,通过设置不同的阈值T,可以得到相应的FAR 和FRR,从而画出受试者特征曲线(receiver operating characteristic curve,ROC),结果如图4 所示,横坐标是FRR,纵坐标是1-FAR,画出的ROC 曲线越接近左上角,则代表该模型的性能越好。图4是将上文提到的4个深度学习模型在PIHD训练集上训练,并在该数据集测试集上测试得到的结果。可以看出,虽然本文所提出的数据集本身比较复杂,但是这4 个深度学习框架在该数据集上均取得了不错的结果,这说明数据集本身的结构设计是合理的,在该数据集上训练得到的模型具有图像认证的能力。除此之外,还在PIHD数据集上测试了DCP(dual-cross pattern)(Qin 等,2018)、DAE(denois⁃ing auto encoder)(Li 等,2020)和RPIVD(ring parti⁃tion and invariant vector distance)(Tang 等,2016)这3 个方法。其中,DCP 和RPIVD 是传统方法,DAE 虽然是深度学习方法,但是也不需要训练。结果如图4 所示,可以看出本文所提数据集是具有一定难度的,这3个方法在该数据集上表现均不理想。
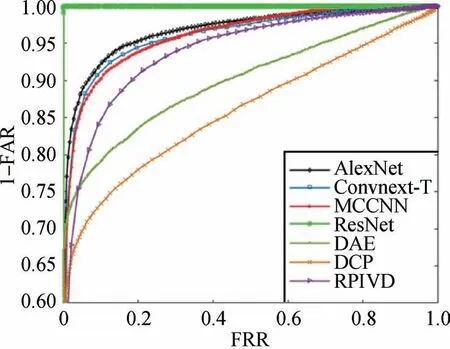
图4 7个感知图像哈希方法在PIHD数据集上的ROC曲线Fig.4 ROC curves of the seven perceptual image hashing schemes on the PIHD dataset
3.3 泛用性
接下来,验证PIHD数据集的泛用性。本文希望在该数据集上训练后的网络模型可以应对目前大多数的内容保留操作。在PIHD 数据集上,分别训练3.1 节中所提到的4 个深度学习模型(MCCNN、AlexNet、ResNet50、Convnext-T),并直接在表3 中所提到的5 个数据集上进行测试,结果如图5(b)(d)(f)(h)所示,由于PIHD 数据集使用的内容保留操作更加丰富,不相似图像也更加符合感知图像哈希任务,所以可以看出,即使不在MCND、HCE、DAE、RPIVD 这4 个数据集上进行重新训练或者微调,在PIHD上训练完的网络也可以取得较好的结果。图5(a)(c)(e)(g)是在另外4 个数据集上训练,再在PIHD 数据集上测试的结果。可以发现,在这些图中都是在PIHD 数据集上训练之后的测试效果最好。横向对比每一行也可以发现,相同模型在图5 左列其他数据集上训练并测试的结果普遍低于右列在PIHD 数据集上训练后的结果。这充分证明了本文所提出的PIHD数据集的泛用性,即使面对从未见过的图像内容保留操作,在该数据集上训练得到的模型也能较好地完成图像内容认证。

图5 4个深度学习模型在不同数据集上测试得到的ROC曲线Fig.5 ROC curves of the four deep learning models on different datasets
3.4 稳定性
最后,验证PIHD数据集的稳定性。稳定性要求神经网络模型在该数据集训练后,在其他数据集进行测试,性能表现不会出现较大波动。使用曲线下面积(area under curve,AUC)来评价各神经网络的性能,该数值是ROC 曲线下与坐标轴围成的面积,数值越接近1代表性能越好,结果如表4所示。
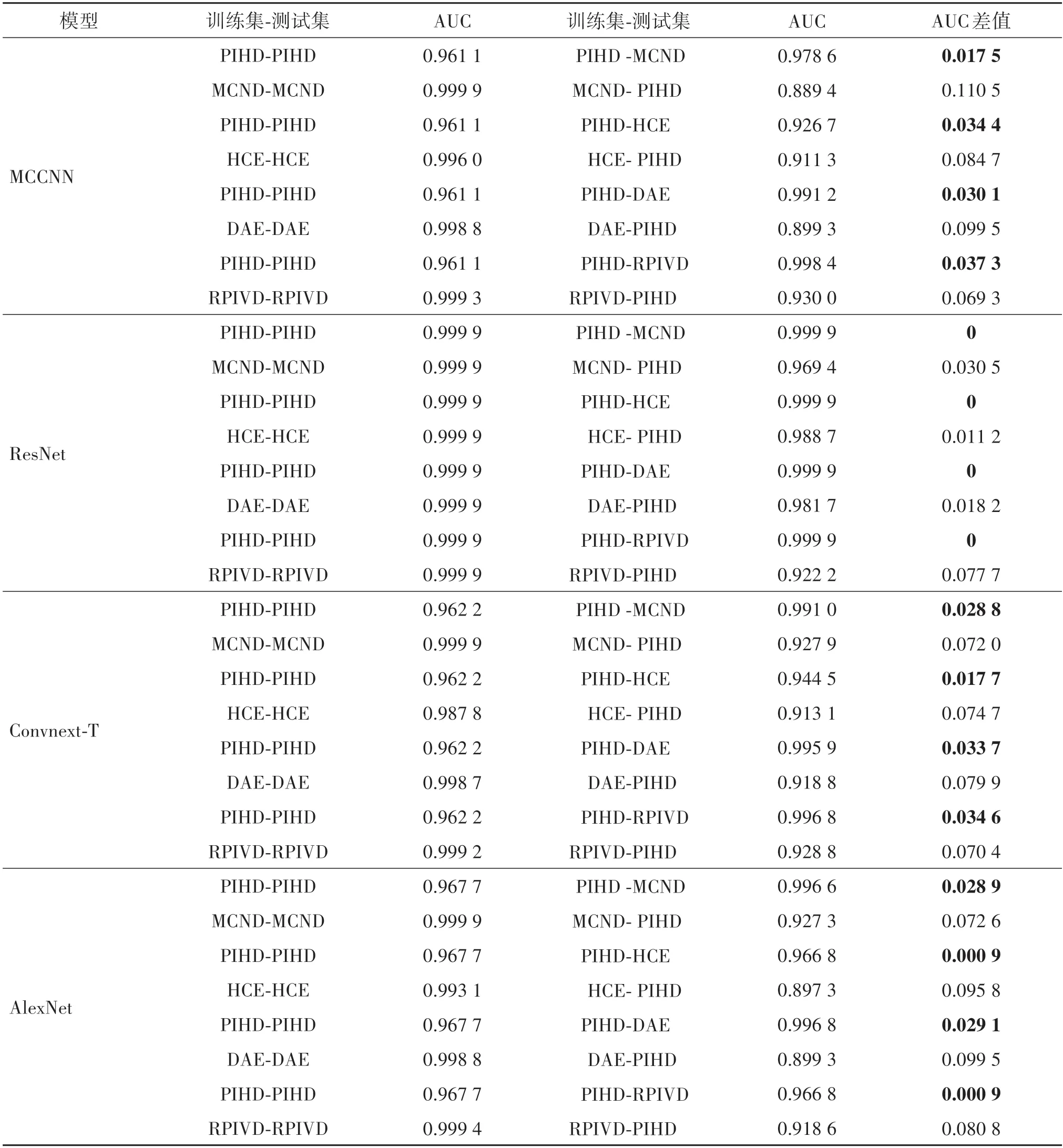
表4 不同模型在相应训练—测试数据集的AUC值以及差值Table 4 AUC values and differences of different models on corresponding training-testing datasets
以MCCNN 部分的内容为例说明表4。第1行表示以PIHD 数据集训练集训练MCCNN 模型,再在PIHD、MCND 数据集测试集上进行测试得到的AUC值,结果分别是0.961 1 和0.978 6,差值为0.017 5。第2 行则是MCCNN 模型在MCND 数据集训练集上训练,并在MCND、PIHD 数据集测试集上进行测试的结果,AUC值分别为0.999 9和0.889 4,差值为0.110 5。可以发现,在MCND 数据集上训练的模型在不同数据集上测试的结果差值远大于在PIHD 数据集上训练的模型,第1、第2 行最后两个差值之间相差了0.093,类似的结果也出现在其他3 个对比数据集上,对应行数之间的差值相差分别是0.069 4、0.050 3、0.032 0。该结果表明,MCCNN 模型在PIHD 数据集上训练后在其他数据集上测试结果变化较小,而在另外4 个对比数据集上训练后的结果变化较大,说明本文所提出的PIHD数据集具有更好的稳定性。表4 的后3 部分则是在另外3 个深度模型上的测试结果,结果也与MCCNN 模型类似,进一步说明了本文数据集的稳定性。
4 结论
目前,感知图像哈希领域缺少一个通用的数据集,其他方法构建的数据集也存在着许多问题。在这些数据集上训练出来的神经网络模型泛用性较差,难以应对现实中复杂多样的图像编辑操作,这一问题已经成为制约感知图像哈希领域发展的重要因素。基于上述认识,本文提出了一个针对感知哈希任务的图像数据集。首先,将目前感知图像哈希领域常用的内容保留操作总结并归类为4 大类 35 种单一的图像内容保留操作,除此之外,还随机组合多种单一的内容保留操作形成组合操作,进一步丰富了内容保留操作的种类。在不相似图像的构建上,除了保留之前数据集所使用的完全不相关的图像之外,还加入了语义相似的同类图像来增加数据集的难度,提高所训练神经网络模型的泛用性。数据集总共116 400 幅的图像基数也保证了神经网络模型的有效训练。大量的实验表明,在该数据集上训练得到的模型较为稳定且具有一定的泛化能力,能够应对复杂多样的实际环境。本文的工作有助于更好地保护图像版权,促进感知图像哈希技术的发展与应用。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
孩子(2019年5期)2019-05-20
数位时尚(幼儿教育)(2017年12期)2018-01-05
数学物理学报(2017年5期)2017-11-23
工业设计(2016年8期)2016-04-16
计算机工程(2015年8期)2015-07-03
计算机工程(2014年6期)2014-02-28
电子设计工程(2014年12期)2014-02-27
测绘科学与工程(2014年6期)2014-02-27
