
结合金字塔Transformer与浅层CNN的变电站图像篡改检测
2024-02-24 09:09邢建好田秀霞韩奕
中国图象图形学报 2024年2期
邢建好,田秀霞*,韩奕
1.上海电力大学计算机科学与技术学院,上海 201306;2.上海电力大学电子与信息工程学院,上海 201306
0 引言
随着智能化电力巡检的广泛应用,图像信息变得尤为重要(郭嘉华,2021)。然而,如今图像篡改技术的迅速发展给一些不法分子提供了危害电力系统的新途径。变电站作为电力系统的重要组成环节,负责不同电压等级的相互转换,保证变电站全时输出稳定的电压以及合理利用变电站的各项资源是整个电力网络安全稳定运行的基础。但是如果采集到的变电站图像被恶意篡改,不仅有可能造成智能电网系统失效,还可能会使操作人员对变电站的实际情况产生误判,最终导致电力系统故障,甚至造成大面积停电等重大事故,给国民生产带来不可逆的损失。因此,如何检测出变电站篡改图像是确保电力系统稳定性的一项关键任务。
图像拼接篡改是最常见的一种图像篡改手段,指把其他图像的一部分裁剪出来,然后拼接到真实图像中,有时还会对图像进行后处理,使篡改区域更加难以分辨。图像篡改检测与一般目标检测并非完全相同,图像篡改检测模型除了需要识别篡改区域内容之外,还要分辨出篡改区域的边缘,这意味着模型需要同时学习图像篡改区域内容及其边缘特征。传统的篡改检测方法是通过检查异常的局部痕迹,如JPEG(joint photographic experts group)压缩伪影(Niu 等,2021)、噪声水平(Lyu 等,2014)、局部描述符统计(Fan 等,2015)等,对图像篡改区域进行检测和定位。这些传统检测方法往往需要手工制作提取篡改区域特征,并且在很大程度上依赖于篡改图像的先验知识,同时检测速度不够快。
卷积神经网络(convolutional neural network,CNN)作为一种有效的图像处理深度学习模型,具备平移不变性、局部特征描述等特点,可以自动地从图像中提取有效的图像篡改特征,从而摆脱传统方法对手工设计特征的依赖(Wang等,2023)。通过设计合适的网络结构,可以建立起端到端的图像篡改检测模型,直接输出像素级篡改定位结果。Ding 等人(2023)提出了一种双通道U-Net 网络结构,该模型主要包括编码器、特征融合和解码器3 个部分,在编码解码过程中引入了扩张卷积和跳层连接,既增大了感受野,还充分利用了上下文语义信息。Zhuang等人(2021)为了更好地提取篡改特征,设计了一种全卷积Encoder-Decoder 架构,网络使用密集连接和空洞卷积来实现更好的定位性能。Li等人(2021)在网络中引入通道和空间注意力机制来增强双通道特征提取能力,该方案提升检测精度的同时也带来了较大的运算量。由于CNN 更擅长聚焦图像局部区域特征,网络整体感受野受限,像素点之间的联系不够紧密,致使图像篡改检测结果出现误检和漏检情况。于是,吴旭等人(2022)将CNN 提取的空间特征与长短期记忆递归神经网络(long short term memory,LSTM)提取的频域特征融合,再经过简单的解码网络预测出图像的篡改区域。
Transformer 首先在自然语言处理中(Vaswani等,2017)取得了优异成绩,它解决了循环网络模型,如LSTM 和门控循环单元(gate recurrent unit,GRU)等存在的无法并行训练以及占用大量存储资源的问题。同时,Transformer对大数据适配能力很强,更加关注特征之间的相互关系,一开始低层就被看做全局信息,建立全局特征点之间的联系。Dosovitskiy等人(2021)在图像分类模型中采用了Transformer,具体来说,将图像拆分为若干块(patches),并将这些块的线性嵌入序列作为Transformer的输入。该模型在足够大规模的数据集上预训练,然后迁移到数据较少的任务进行微调,最终取得了优异的效果。陈港等人(2022)采用Transformer 和LSTM 两通道分别处理视频片段特征,再将两通道生成的特征层进行级联,最后将级联特征传入全连接层进行表情分类,该方法提升了视频中动态人脸表情的识别性能。李颖等人(2023)针对深度伪造视频检测问题,结合CNN 与Transformer 在伪造检测方面的优势,提出了一种实用的联合模型。该模型利用注意力机制、数据增强机制和域特征,优化了复杂场景下的检测效果,提高了检测精度。
基于深度学习的方法在检测精度和速度上都有了一定程度的提高,但是当篡改场景比较复杂以及篡改图像经过一系列后处理操作时,模型检测精度会不同程度地降低。尽管图像篡改检测已受到广泛关注,但在电力系统中的实际应用较少,并且检测效果不够好。
针对上述问题,本文基于现有深度学习方法,对变电站图像拼接篡改检测进行研究,提出一种特征金字塔结构Transformer 与浅层CNN 结合的双通道图像拼接篡改检测模型。篡改图像和残差图像分别为两通道的输入,其中篡改图像包含丰富的色彩特征和内容信息,残差图像重点凸显了篡改区域的边缘;采用特征金字塔结构Transformer作为编码器,网络从底层开始即可在全局感受野上高效地提取篡改图像特征,建立特征点之间的联系,同时金字塔结构使网络具有更好的泛化性和多尺度特征处理能力;设计一种浅层CNN 作为模型的辅助分支,在残差图像上提取篡改区域的边缘特征,有助于模型识别篡改区域的边缘轮廓;结合Transformer 和CNN 在图像篡改检测方面的优势,提出的双通道检测模型在自制变电站图像篡改数据集和标准数据集上均取得了优异的成绩,检测结果可视化进一步表明本文模型的实用价值。
1 本文模型
本文提出一种基于特征金字塔结构Transformer与浅层CNN 双通道结合的变电站图像拼接篡改检测模型,网络结构如图1 所示。输入端包括篡改图像、空间富模型(spatial rich model,SRM)高通滤波层和残差图像;主干网络包括Transformer模块、残差模块和平行轴向注意力模块;输出端包括主干网络提取的特征层、网络头部和篡改图像的检测定位结果。
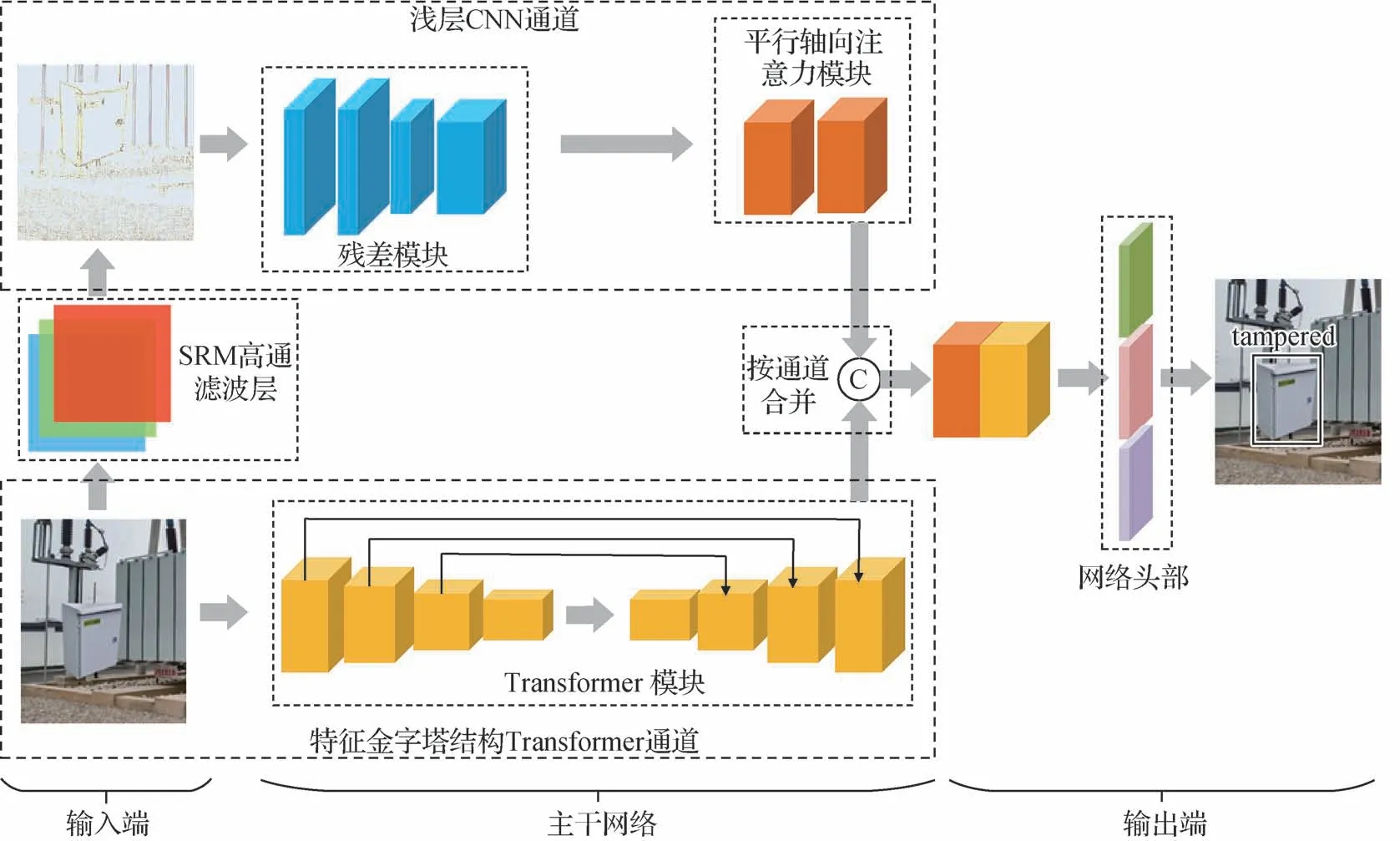
图1 本文模型结构Fig.1 Model structure of this paper
本文将特征金字塔结构Transformer通道作为主特征提取通道,其中,Transformer模块的编解码部分包括金字塔结构Transformer(Xie等,2021)和一个渐进式局部解码器(progressive local decoder,PLD)。Transformer 能够通过全局注意力从模型的第1 层开始就在全局感受野上高效地提取特征,建立特征点之间的联系。同时,使用金字塔结构使网络具有更好的泛化性和多尺度特征处理能力。PLD 使不同深度和表达能力的特征相互引导、融合,可以解决注意力分散和低估局部特征的问题,以提高细节处理能力。
浅层CNN 通道作为辅助检测通道,采用浅层网络提取残差图像中篡改区域的边缘特征,使模型在整体轮廓上更容易定位篡改区域。其中,残差模块构成浅层网络的主干,其输入为篡改图像经过SRM高通滤波层生成的残差图像。平行轴向注意力(Kim 等,2021)模块(parallel axial attention block,PAA block)引入不同大小的空洞卷积,增加了浅层网络的感受野,平行轴向注意力机制有助于网络提取上下文语义信息。
将两条支流的特征按通道融合传入网络头部,由网络头部检测出图像中有无篡改区域,并准确定位篡改区域。下面详细介绍特征金字塔结构Transformer 通道、浅层CNN 通道和网络头部的网络结构。
1.1 篡改图像与残差图像的特征
1.1.1 篡改图像的特征
篡改后的变电站图像与原图像存在一定差异,如图2和图3所示。在图2配电箱篡改图像中,可明显看出篡改区域的边界比较清晰,而真实区域的边界则相对模糊;图3绝缘子篡改图像中,篡改区域相比真实区域周围的色彩变化更加强烈。本文将以上两种特征信息作为拼接篡改图像检测依据,通过Transformer通道对图像语义信息和视觉特征进行有效提取。

图2 配电箱篡改图像Fig.2 Distribution box tampered image((a)tampered image;(b)tampered region;(c)real region)

图3 绝缘子篡改图像Fig.3 Insulator tampered image((a)tampered image;(b)tampered region;(c)real region)
1.1.2 残差图像的特征
篡改图像经过SRM 高通滤波层(Fridrich 和Kodovsky,2012)后生成残差图像,使得篡改区域的边缘特征被增强。残差图像具有篡改图像没有的噪声特征,在不同的场景下,语义信息和噪声特征在检测篡改痕迹方面起到了互补的作用,从而提高了篡改检测模型的检测效果。
本文使用SRM 高通滤波层来提取篡改图像的残差特征作为图像篡改检测的辅助信息。为了减少滤波层参数量,同时不降低其性能,本文模型的SRM 滤波层只使用了3 个滤波器(Zhou 等,2018;田秀霞 等,2021),图4 为3 个滤波器的权重。为了检验3 个滤波器的有效性,在图5 中同时展示了6 个滤波器作用下的残差图像作为对照。从图5(c)中可以看出,篡改区域的边缘轮廓特征被增强,一些无关的区域特征得到了过滤。对比图5(c)(d)可以发现过多的滤波器并没有使篡改区域的边缘轮廓特征被增强,反而引入了冗余的噪声特征。本文将残差图特征作为拼接篡改图像检测依据,通过浅层CNN 通道对篡改区域边缘特征进行有效提取。
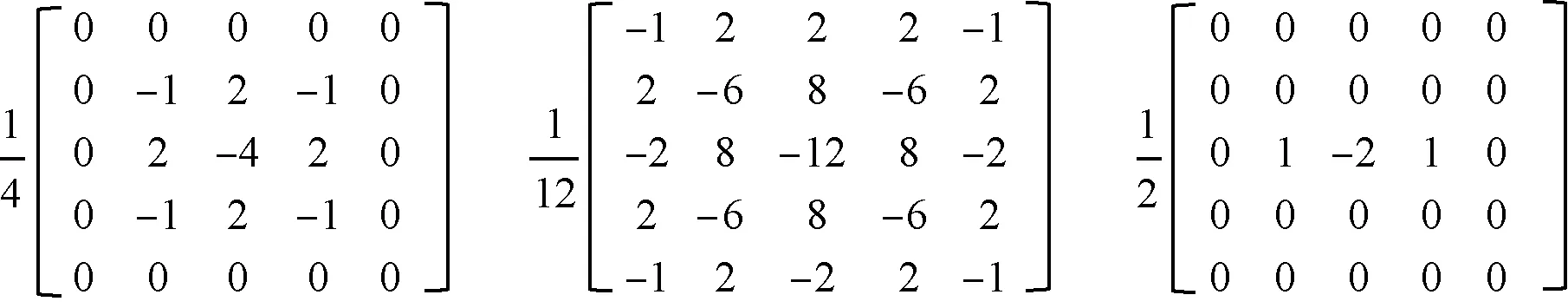
图4 滤波器权重Fig.4 Filters weight

图5 残差图像特征Fig.5 Residual image features((a)tampered image;(b)ground-truth;(c)the number of filters is 3;(d)the number of filters is 6)
1.2 特征金字塔结构Transformer通道
特征金字塔结构Transformer通道的输入是大小为512 × 512 × 3 的篡改图像,输出是大小为128 ×128 × 64 的特征图。该通道中Transformer 模块的结构如图6 所示,由编码器和解码器组成。编码部分(encoder)是4 层Transformer 编码器组成的特征金字塔结构,随着层数增加,生成的特征图通道数增加,尺寸减半。
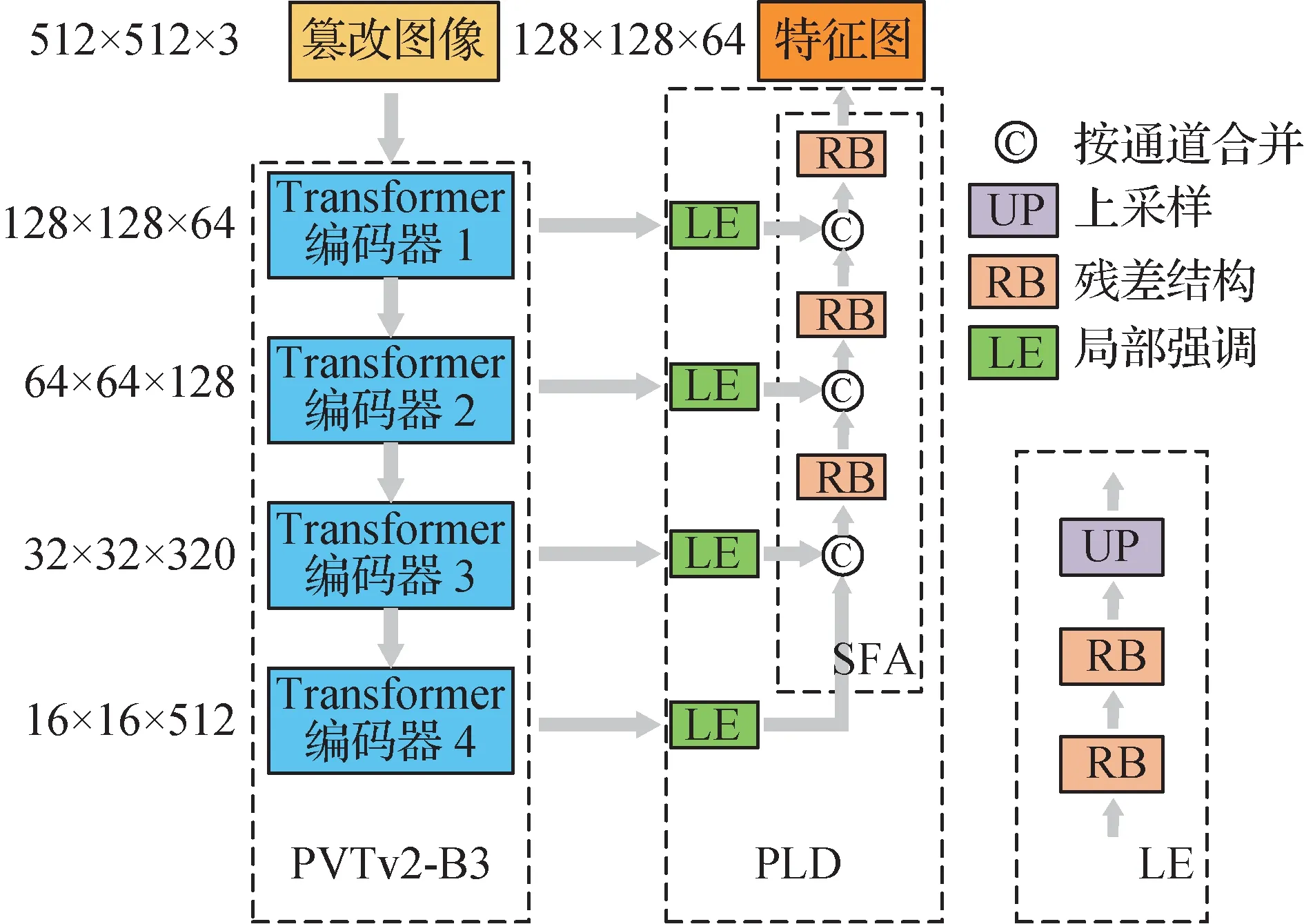
图6 Transformer模块结构图Fig.6 Transformer block structure diagram
Transformer 编码器结构如图7所示,首先把1幅篡改图像拆分成多个4 × 4 大小的块并将其传入块嵌入层生成序列化的嵌入块,接着将块序列嵌入编码器模块。Transformer 编码器i(i=1,2,3,4)分别由n(n=3,4,18,3)个编码器模块堆叠而成。编码器模块包括层归一化(layer-norm)、多头注意力机制(multi-head attention)、正则化(drop-path)、多层感知器(multi-layer perceptron,MLP)以及跳层连接。其中,MLP是全连接层、激活函数层和正则化层串联的简单结构。金字塔Transformer编码器具有出色的泛化能力和多尺度特征处理能力,本文将ImageNet 上预训练的金字塔视觉Transformer v2 的B3 变体(PVTv2-B3)作为编码器的预训练模型。

图7 Transformer编码器结构图Fig.7 Transformer encoder structure diagram
金字塔Transformer编码器每个层级的输出特征图分别传入PLD,PLD 是Transformer 模块的解码部分(decoder)。在PLD 中,局部强调模块(local emphasis,LE)由简单的残差结构和上采样层依次串联而成。编码器的每个层级由一个LE 模块单独处理,以解决基于Transformer 的模型不擅长表示局部特征的缺点。接着通过逐步特征聚合模块(stepwise feature aggregation,SFA)自底向上按通道融合特征金字塔的各层级特征。多级特征聚合结构可以使不同深度和表达能力的特征相互引导,以解决网络注意力分散和局部特征弱化的问题。Transformer通道最后输出的特征图为128 × 128 × 64。
1.3 浅层CNN通道
1.3.1 残差模块
残差模块是预处理层和一个堆叠块组成的浅层网络,结构如图8 所示。残差图像先经过预处理层,用于调整其空间大小。预处理层包括卷积、批归一化、激活函数和最大池化。堆叠块由3 个Res2Net module(Gao等,2021)依次串联而成。

图8 残差模块结构图Fig.8 Residual block structure diagram
残差模块提取的浅层特征更偏向于表示图像的边缘轮廓。值得注意的是,Res2Net module 相对以往使用的ResNet(residual network)(He 等,2016)结构上有所不同,前者通过在单个残差块内构造具有层次化的类似残差连接,取代了后者的单个3 × 3卷积核,从而使网络能在细粒度级别表示多尺度特征,并增加了每个网络层的感受野,其结构如图9所示。
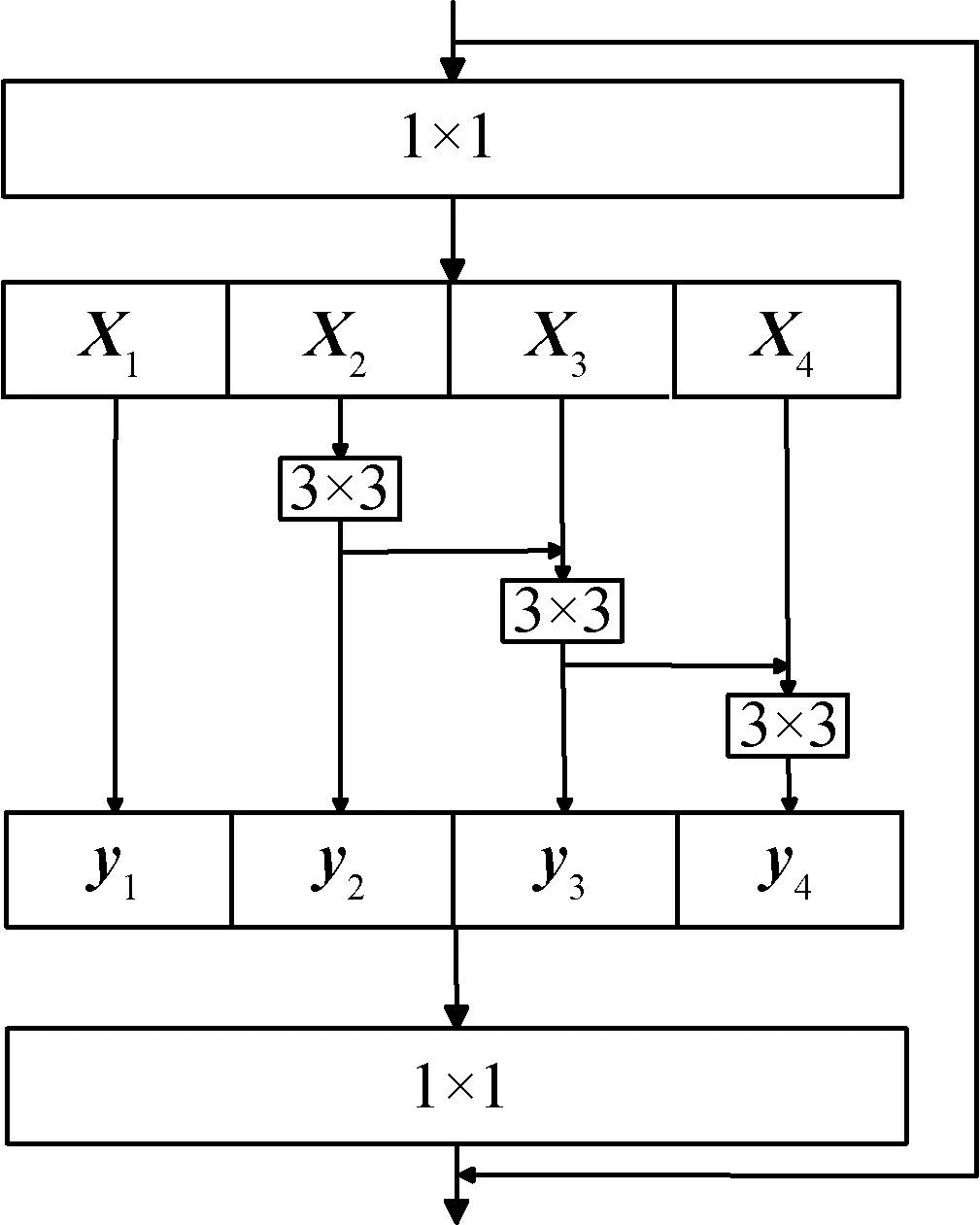
图9 Res2Net module结构图Fig.9 Res2Net module structure diagram
Res2Net module两端卷积层的卷积核仍为1 × 1,不同的是,它的中间层用一组更小的滤波器组替换了ResNet 中间层的3 × 3 卷积核。每个Xi的通道数是c,其中,i=1,…,w;c=n/w,n为输入特征图通道数,w为输入通道平分数量,图9中w取值为4。
1.3.2 PAA block
PAA block 对残差模块生成的特征图进行二次特征提取,其结构如图10 所示。特征图分别作为4 条支路的输入,第1 条支路只有一个卷积层,卷积核大小为1 × 1,用来调整特征图通道,其余3条支路均包含非对称分解卷积、空洞卷积和PAA。非对称分解卷积将一个大卷积核分解为两个小卷积核,不仅减少了参数量,还增加了非线性表示能力。通过调整空洞卷积的空洞系数来增加网络的感受野以及提高网络的多尺度表示能力。PAA有助于网络提取上下文语义信息,同时解决了自注意力机制计算量大的问题。最后,4 条支路的特征按通道融合后再经过卷积层调整空间维度,生成了大小为128 × 128 ×64的特征图。
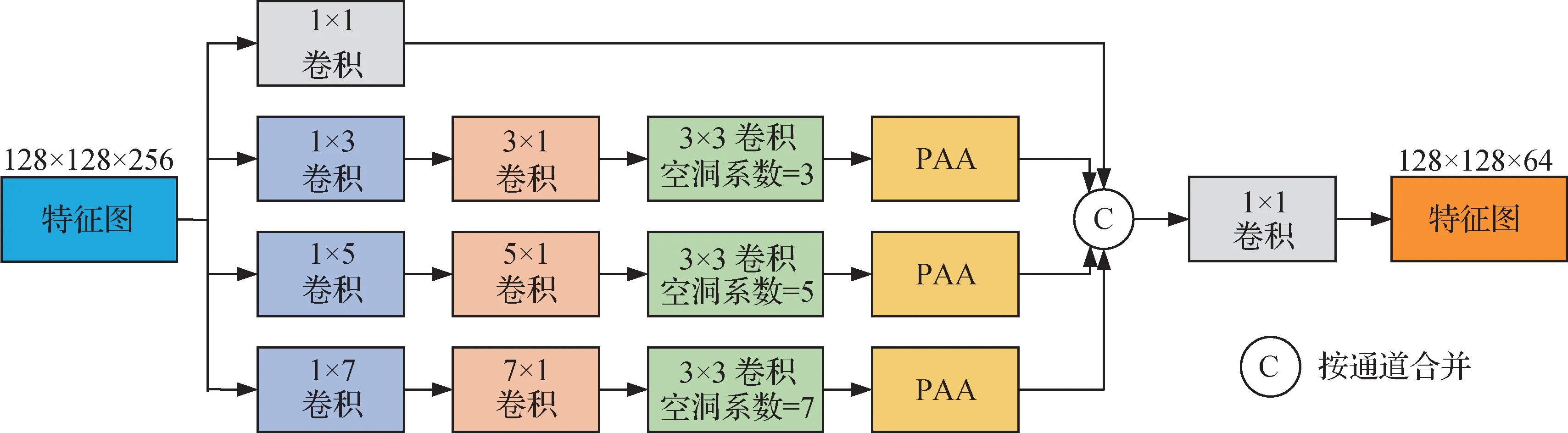
图10 PAA block结构图Fig.10 PAA block structure diagram
1.4 网络头部
将特征金字塔结构Transformer 通道与浅层CNN 通道生成的特征图融合后传入网络头部。网络头部结构如图11 所示,由热力图预测部分、宽高预测部分和中心点偏移量预测部分组成,其中热力图预测部分预测图像中有无篡改区域,宽高预测部分预测篡改区域检测框的高度和宽度,中心点偏移量预测部分预测篡改区域检测框的中心点偏移量。本文参考Zhou等人(2020)损失函数的设置,用L1、L2和L3分别表示热力图损失、宽高损失和中心点偏移量损失,再将3 部分损失累加得到模型的总损失L,具体为

图11 网络头部组成结构Fig.11 Network head composition structure
式中,α和β为比例系数,本文取α=0.1,β=1。通过训练模型不断降低模型损失,进而不断调整网络参数值,最终训练出各项指标都比较好的图像篡改检测模型。
2 实验与分析
2.1 实验环境与参数设置
实验的操作系统为Windows 10;CPU 为Inter(R)Core(TM)i9-9900K;内存为32 GB;显卡为NVIDIA GeForce RTX 2080Ti,16 GB;CUDA 版本为11.6;CUDNN 版本为8.6.0;深度学习框架为Pytorch,其版本为1.13.1。在训练中,初始学习率设置为1E-4,使用Adam 优化器训练网络、Reduce-LROnPlateau 调整学习率,学习率最小值设为1E-8,动量大小为0.9,共迭代100轮次,批量大小为8。
2.2 评估指标与数据集
2.2.1 评估指标
本文采用精确率(precision,P)、召回率(recall,R)、F1 分数和平均精度(average precision,AP)作为图像篡改检测的评价指标。
2.2.2 实验数据集
本文使用的图像拼接篡改数据集包括PTDS(pre-trained datasets)、NIST16(National Institute of Standards and Technology 16)(Guan 等,2019)、CASIA(Chinese Academy of Sciences Institute of Auto⁃mation dataset)(Dong 等,2013)和SSSTD(self-made substation splicing tampered dataset)。其中,PTDS 包含大量篡改图像用于模型的预训练,其余数据集用于微调模型并检测模型的性能。将数据集分为训练集、验证集和测试集3 部分。利用训练集对模型进行训练,验证集调整模型学习效果,测试集评定最终训练结果。同时,在模型训练中采用数据增强技术,增强的方式有缩放、翻转和色彩变换。
1)预训练数据集。PTDS 由PASCAL VOC 2012(pattern analysis,statistical modeling and computa⁃tional learning visual object classes)(Everingham 等,2010)中的原始图像和标注信息拼接而成,共有5 016 幅图像,图像内容来源广泛,包含动物、植物、物品和场景等信息。
2)微调数据集。(1)SSSTD:使用PS(Adobe pho⁃toshop)合成的拼接篡改图像数据集,图像内容为变电站工作场景,篡改内容包括电压互感器、电流互感器、绝缘子、配电箱、变压器、变电柜等。该数据集共552幅拼接篡改图像。(2)CASIA:CASIA v1包含复制移动和拼接两种篡改手段的图像。CASIA v2 的图像数量远多于CASIA v1,图像格式也更多样。此外,CASIA v1 中的篡改图像只经过了简单处理,容易被察觉。CASIA v2 中的篡改图像经过了较为复杂的处理,给人感觉更加真实,增加了模型检测难度。本文分别从v1 和v2 中选取拼接篡改图像,共计1 024 幅。(3)NIST16:该数据集提供复制移动、拼接、移除3种篡改手段的图像,本文选取其中164幅拼接篡改图像。
2.3 消融实验
模型的检测性能受不同模块组合方式和特征融合方式的影响,本文设置了表1 所示6 种模型变体(CNN、RGB-Transformer、CTA、SRM-Transformer、RGB-CTC和CTC-noPAA)进行实验对比,来验证它们在模型中的作用及有效性。表1中RGB指篡改图像,SRM指残差图像,Addition指两通道输出的特征层按元素累加,Concatenation指两通道输出的特征层按通道合并;CTC 是本文模型,包含RGB、SRM、Trans⁃former模块、残差模块、PAA block和Concatenation。
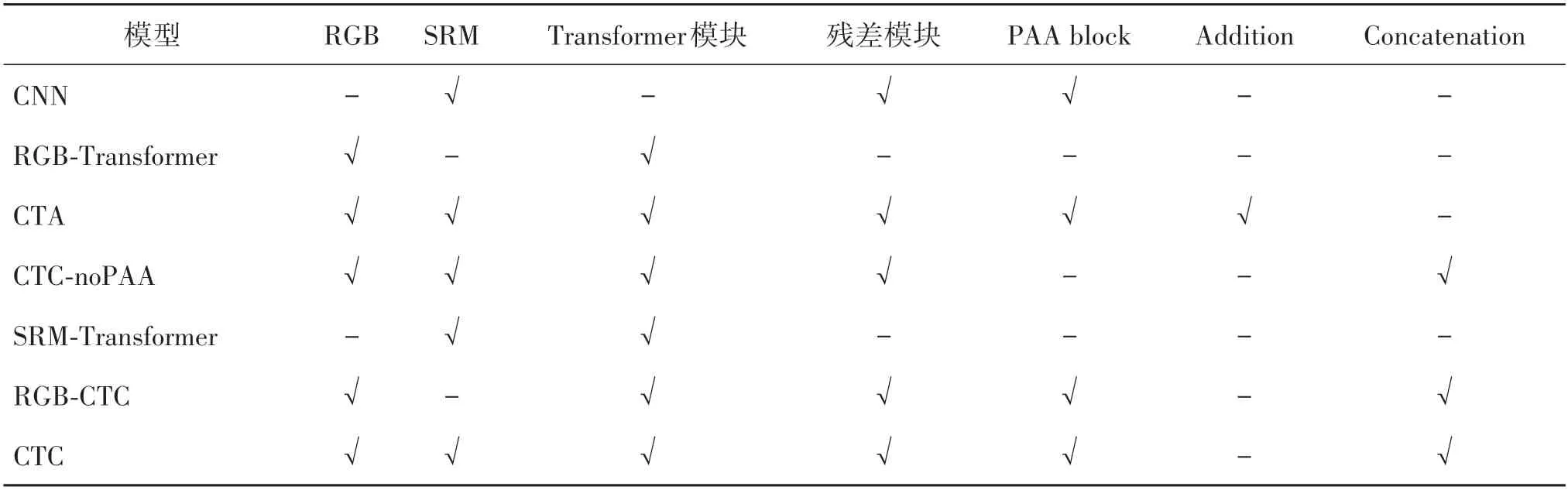
表1 本文模型及其6个变体组成Table 1 Our model and its six variants
首先,在相同的参数策略下使用PTDS训练本文模型及其变体,并记录训练过程中的训练集和验证集损失。图12 是模型及其变体在验证集上的损失变化曲线,横坐标是训练轮次,纵坐标是网络损失值。由图12 可得,各模型在80 轮附近收敛,损失值由低到高分别为CTC、CTC-noPAA、RGB-Transformer、SRM-Transformer、CTA、RGB-CTC和CNN。
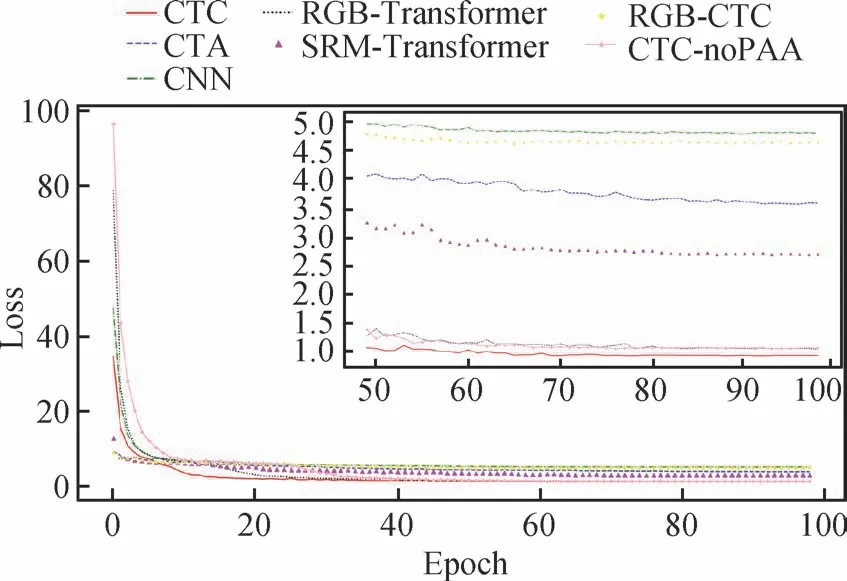
图12 本文模型及其6个变体在验证集上损失变化Fig.12 The loss changes of our model and its six variants on the validation set
为进一步对模型及其变体性能进行客观分析,本文在测试集上对精确率、召回率、F1 和AP 共4 项指标进行评估,实验结果如表2 所示。综合各项指标来看,本文所提CTC 表现最好,可以验证以下结论:1)由于浅层CNN 网络提取特征能力有限,单独使用时模型检测结果很差。2)将两通道按元素累加生成的特征层的表示能力相较于按通道合并明显降低。3)对比RGB-Transformer 和SRM-Transformer 的检测结果可知,将特征金字塔结构Transformer 通道的输入换成残差图像会失去篡改图像丰富的色彩和纹理特征,导致检测指标大幅度下降。4)将CTC 中浅层CNN 网络通道的输入由残差图像换成篡改图像得到模型变体RGB-CTC,分析RGB-CTC的检测结果发现,当两通道的输入均为篡改图像时,模型检测效果大大降低,说明将SRM 高通滤波层生成残差图像作为浅层CNN 网络输入的优势。5)删除CTC 中的PAA block 得到模型变体CTC-noPAA,相较于CTC,CTC-noPAA 的检测效果有所下降,验证了PAA block 进行二次特征提取的有效性。6)浅层CNN 网络着重提取篡改区域的边缘特征,使模型在整体轮廓上更容易定位篡改区域。利用特征金字塔结构Transformer的全局交互机制获取图像的全局信息,建立关键点之间的联系,使模型具有良好的泛化性和多尺度特征处理能力。
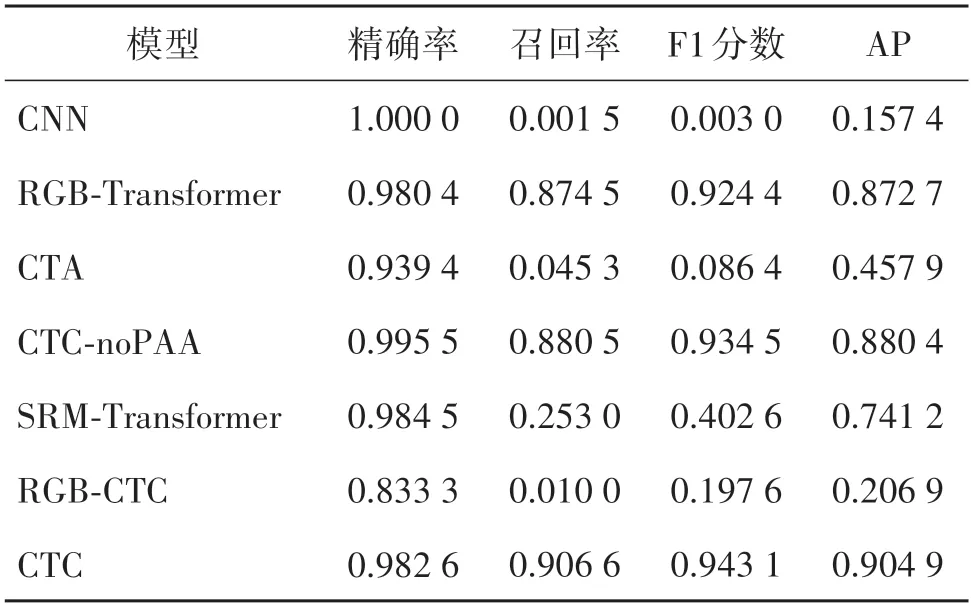
表2 本文模型及其6个变体在测试集上的各项指标Table 2 The indicators of our model and its six variants on the test set
最后,在PTDS 上可视化所提模型的检测结果,如图13 所示。第1 行为3 幅篡改图像,篡改区域已由蓝色实线框标出;第2 行是检测结果。从检测结果可以清晰看出,所提模型能够识别篡改图像,并精准定位篡改区域。

图13 本文模型在PTDS上可视化检测结果Fig.13 Visualization of our model on PTDS
2.4 对比实验
2.4.1 检测性能对比
在SSSTD、CASIA 和NIST16 共3 个数据集上进行微调训练后,选取4 种同类型先进模型与本文模型进行检测性能对比,用来检验本文所提双通道网络作为模型主干网络的有效性。具体操作是将本文模型的主干网络分别替换为4 种对比模型的主干网络,本文模型的输入端和输出端保持不变,然后分别在同一数据集上对比各模型实验结果。4 种对比模型分别是U-Net(Ronneberger 等,2015)、DeepLab V3+(Chen 等,2018)、双通道CenterNet(刘正 等,2022)和DCU-Net(Ding 等,2023),各模型简介绍如表3所示。
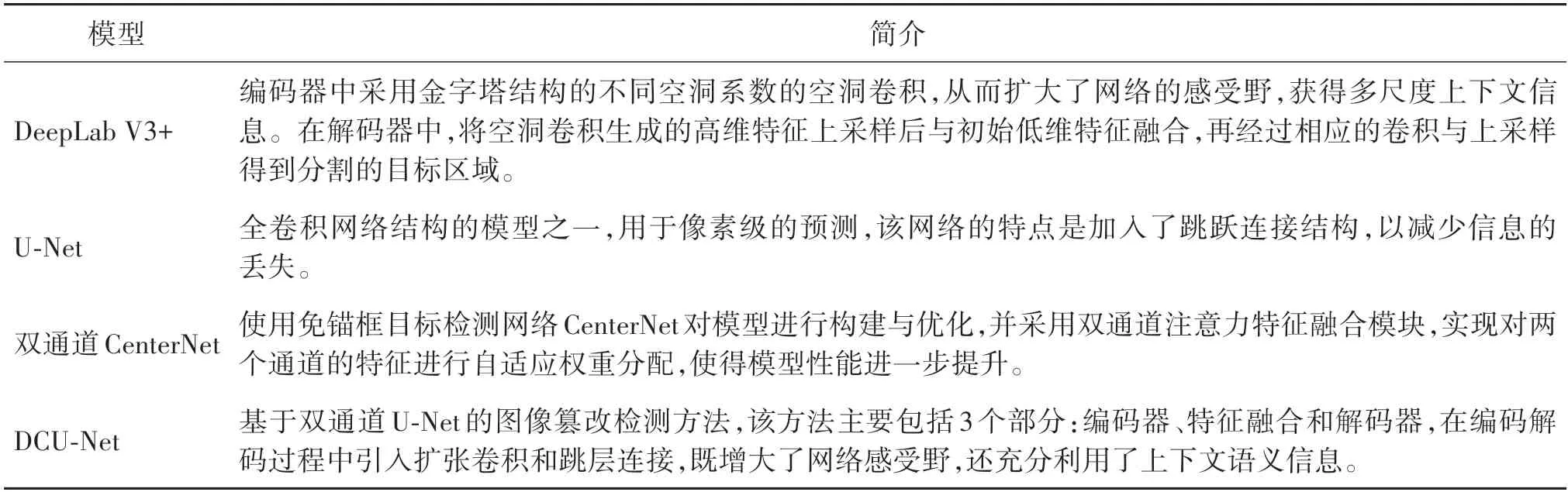
表3 4种对比模型简单介绍Table 3 A brief introduction of four comparative models
依次在SSSTD、CASIA 和NIST16 共3 个数据集上检测不同模型的性能,各模型的精确率、召回率、F1 和AP 的实验结果如表4 所示。由表4 可知,5 种检测模型在3 个数据集上都取得了较高的精确率,其中本文模型和DeepLab V3+的精确率值最高,证明空间金字塔结构有效增大了网络感受野,同时,网络融合多尺度特征增强了特征表示。除了精确度,4种对比模型在另外3个指标上的表现一般。但是,本文模型在4 个指标上都取得了优异结果,说明特征金字塔结构Transformer 通道能够在全局感受野上高效地提取特征,充分捕获图像像素之间的相关性,同时具有更好的泛化性和多尺度特征处理能力。浅层CNN 通道提取的残差特征重点凸显了篡改区域的边缘轮廓,从而辅助模型做出更全面的检测。
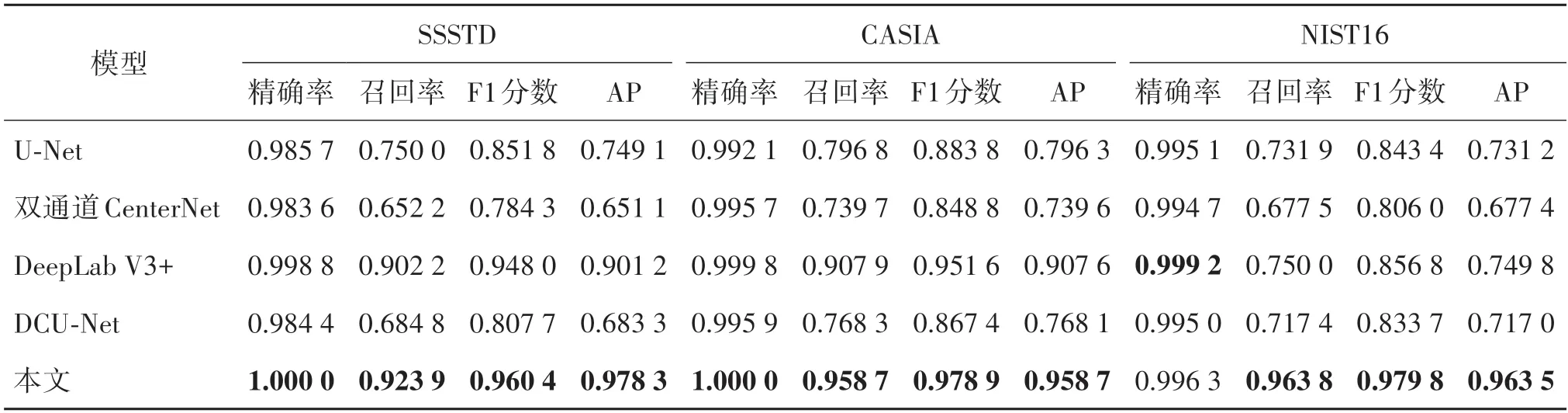
表4 不同模型在SSSTD、CASIA和NIST16数据集上的对比Table 4 Detect results of different methods on SSSTD,CASIA and NIST16 datasets
2.4.2 检测结果可视化对比
图14为本文模型与4种对比模型在SSSTD上的检测结果可视化,图中第1 列篡改图像中蓝色实线框内是篡改区域,篡改内容包括变电柜、配电箱、电压互感器、电流互感器、绝缘子等。
由图14 可知,各模型对相关篡改内容都具有一定检测效果,本文模型不存在误检漏检情况,但是4 种对比模型存在不同程度的误检漏检情况。其中,U-Net 存在大量误检,双通道CenterNet 和DCUNet存在误检和漏检,DeepLab V3+没有漏检,误检率比较低。检测结果可视化表明,本文模型改善了误检和漏检问题,具有更高的定位精度,整体检测效果优于其他模型。
3 结论
变电站图像拼接篡改影响电力系统的安全运行,如何检测出变电站拼接篡改图像是确保电力系统稳定性的一项关键任务,本文设计了一种新的基于特征金字塔结构Transformer 与浅层CNN 双通道的复杂变电站图像拼接篡改检测模型。首先,特征金字塔结构Transformer通道通过全局交互机制获得丰富的篡改图像语义信息和视觉特征,增强了检测模型的精确度和多尺度处理能力。其次,浅层CNN作为辅助通道着重提取残差图像边缘特征,使模型在整体轮廓上更容易定位篡改区域。最后,网络头部利用双通道融合特征准确检测出篡改区域。在SSSTD、CASIA 和NIST16 这3 个数据集上对各模型进行测评,本文模型取得了最优结果,适用于复杂变电站场景下的拼接篡改目标检测。由于变电站图像篡改还存在其他情形,所以下一步将对其他类型的篡改图像进行研究,以提高模型检测的准确性。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
建材发展导向(2021年24期)2021-02-12
环境影响评价(2020年5期)2020-12-02
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
水利规划与设计(2016年10期)2017-01-15
华北地质(2015年3期)2015-12-04
