
基于张量分解嵌入的时序知识图谱推理
2024-02-23 04:03:40刘伟谢璐钧张智慧陈亚繁
北京信息科技大学学报(自然科学版) 2024年1期
刘伟,谢璐钧,张智慧,陈亚繁
(1.北京信息科技大学 自动化学院,北京 100192;2.北京航天智造科技发展有限公司,北京 100143)
0 引言
知识图谱可以看作是由多个三元组组成的语义网络,主要用于描述现实世界中实体、概念或事件之间的关系。传统用三元组表示的语义网络,其表达的关系往往是静态的,然而在实际使用场景中,实体之间的关系通常会随着时间的推移而变化。因此,学者们提出构建四元组形式的知识网络,也就是为原始三元组多分配一个额外的时间变量。加入时间属性的知识图谱被称为时序知识图谱(temporal knowledge graph,TKG)。
关于时序知识图谱的推理,目前较为流行的方法是基于嵌入的推理方法[1],即将实体与关系转换为嵌入表示来进行推理。表示学习模型可分为平移距离模型、语义匹配模型以及神经网络模型。其中,平移距离模型使知识图谱中的头实体、关系以及尾实体向量满足平移距离约束。典型的模型如TransE[2],使用L1和L2范数衡量两实体之间的距离,实现使头实体向量和关系向量的和贴近尾实体向量的目的,在处理复杂关系时实体区分性较低。为解决这个问题,TransH[3]将头尾实体分别投影到关系所在的超平面。上述方法虽效果有所提升,然而因为引入空间投影,导致参数增多,复杂度变高。语义匹配模型使用基于相似度的评分函数来计算实体和关系的语义联系。典型的模型有RESCAL[4],它通过低维的实体矩阵和低维的关系矩阵乘积的形式,来判断每个三元组成立的可能性。为克服RESCAL模型过拟合的问题,DisMult[5]将原关系矩阵转化为对角矩阵。近来的TuckERT[6]模型,将一个三阶张量分解为一个核心张量每一维度乘上一个矩阵作为评分函数。神经网络模型是使用深度神经网络的表达能力,进行实体和关系的特征学习。典型的方法如NTN[7],用一组神经网络的参数来表示关系。另外,ConvE[8]对实体和关系的向量进行二维卷积操作,来建模实体间和关系间的交互;RGCN[9]通过图卷积神经网络将实体的邻域信息进行聚合,来更新实体的嵌入表示。近几年提出的TDT[10]、ReNet[11]、TA-GAT[12]、EvoKG[13]、TeMP[14]以及RE-GCN[15]等模型也是基于神经网络的方法。
目前关于时序知识图谱嵌入方法的研究可分为内推与外推[16],其中内推是补全部分事实已知的时序知识图谱序列所缺失的事实,而外推更多关注于时序知识图谱的预测,即通过已知事实来预测未来的事实。现有的时序知识图谱表示学习模型,如CyGNet[17]可以基于历史事实来识别可能重复发生的事实。
然而,在类似方法中,TKG中四元组的嵌入并没有充分利用时间信息。TNTCompEx[18]中的关系具有不同的时间特性,具体可以分为静态属性和动态属性。受其启发,本文将关系的张量嵌入分解为静态和动态(时序)部分,同时将上述关系和实体张量嵌入的乘积作为TKG模型的评分函数,对模型进行训练,得到模型的各个张量嵌入表示,所提方法可称为分解张量嵌入序列网络(decomposed tensors embedding sequential net,DTESN)。最后,通过对比实验验证了该模型的有效性。
1 分解张量嵌入序列网络
时序知识图谱可以看作是四元组(头实体,关系,尾实体,时间戳)事实的集合,将四元组记为(s,r,o,t)。实体集合中,元素数量为N,张量嵌入的维度为d。s和o分别对应头实体和尾实体,s,o∈N×d;r对应关系,关系集合中元素的数量为M,r∈M×d;t对应时间戳,时间戳集合中的元素数量为K,t∈K×d。
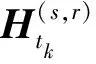
本文所提出的模型使用分解张量嵌入的双线性函数,同时结合历史词汇表的指导作为评分函数,通过训练四元组各元素的嵌入以及相关网络参数,使有效的四元组比无效的四元组得分更高。训练完成后,使用上述评分函数来推断确定四元组事实的可能性。具体地,在四元组事实的有效性得分判定之后,通过分数排序确定在给定时间的事件中预测缺失实体的最大可能,例如(s,r,?,t)表示给定头实体、关系和时间戳,预测尾实体;或者(?,r,o,t)表示给定关系、尾实体和时间戳预测头实体。
对于预测缺失实体,该模型假设既可以从历史事件中得到结论,即已经发生过的事情可能重新发生;也可以从历史事实中推导结论,即发生以前没有的事实。对应地,模型中构建了2种推理模式:复制模式和生成模式。前者实现从历史词汇表中预测出一个对象实体,后者则从整个实体集中预测出一个新的对象实体。
1.1 历史词汇表构建

(1)
1.2 四元组的分解张量嵌入
时序知识图谱中,实体、关系和时间的张量嵌入维度分别为N×d、M×d和K×d。设训练时一个批次的四元组数量为b,为了便于对每个批次进行分解张量嵌入网络的训练进行介绍,将每个批次的张量嵌入的定义具体为该批次的张量值,即实体张量嵌入为S∈b×d、关系张量嵌入为R∈b×d和时间张量嵌入为T∈b×d。
由于关系具有时间属性,可能会随着时间发生变化,即对于同一个对象实体,在不同的时间对应的关系和实体可能不同。因此,模型在评估实体间关系时,将关系视为时变的。然而,并非所有的关系都会随时间而变化,因此,模型将关系张量嵌入R分解为静态关系张量嵌入Rs和动态时间关系张量嵌入的叠加。其中,动态时间关系张量嵌入可表示为动态关系张量嵌入Rt与时间张量嵌入T的哈达玛(Hadamard)积,即Rt⊙T。设时间基张量嵌入tb∈b×d,令T为tb和当前时间戳t的乘积。则时序知识图谱的关系张量嵌入R可计算如下:
R=Rs+Rt⊙T
(2)
式中:第一部分是通过初始化静态关系张量嵌入并学习不同时间的事实集合得到的;第二部分是动态关系张量嵌入和时间张量嵌入的哈达玛积。它也需要先对模型进行初始化,并根据不同时间的事实集进行学习后获得。
1.2.1 复制模式
首先,利用双线性评分函数vq得到头实体、关系矩阵和整个实体集之间的相关性。vq是一个N维向量,E表示对应于所有实体的嵌入张量,E∈N×d。
vq=S⊙R*ET
(3)
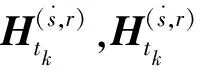
(4)
pc=Softmax(cq)
(5)
1.2.2 生成模式
生成模式是复制模式的补充。由于待预测实体也可能出现在历史词汇表中已存在的实体之外,因此需要构建新的模式来预测它们。与复制模式不同,生成模式的尾实体是整个实体词汇表,生成的预测实体不需要参考历史事实,可以直接视为新实体。
生成模式同样使用双线性模型来获得头实体和关系矩阵和整个实体集间的相关性,用一个N维向量gq表示。
gq=S⊙R*ET
(6)
由于生成模式不考虑历史事实,所以无需对历史词汇表进行修改,直接通过Softmax函数得到从整个实体词汇表中生成尾实体的概率pg。
pg=Softmax(gq)
(7)
1.3 学习目标
给定预测范围的实体预测可以视为多分类任务,其中每个分类对应一个实体。因此,所提模型的学习目标是对训练期间存在的所有事实最小化以下交叉熵损失L。
(8)
式中:oik表示tk时刻时序知识图谱中的第i个尾实体标签;p(yin|s,r,tk)表示当尾实体标签为oik时,实体集中第n个实体yin的预测概率值。
1.4 推理
为了对四元组(s,r,?,t)中缺失的尾实体o进行预测,复制模式和生成模式都给出了相应的预测结果,但两者的预测对象都是整个实体集。因此,为了保证实体集中所有实体的概率之和等于1,引入了一个系数α,α∈[0,1],来调整复制和生成模式之间的权重,通过对2种模式得到的概率值,如式(5)和式(7)所示,进行加权求和,得到整个实体集中所有实体的预测概率值。最终的预测对象将是组合概率p(o|s,r,t)最高的实体。
p(o|s,r,t)=α×pc+(1-α)×pg
(9)
2 实验
实验在3个公开数据集上验证该模型的有效性。首先阐明实验的配置,包括实验环境及实验参数设置,然后对实验结果进行讨论。
2.1 实验配置
本文实验使用中央处理器为Intel(R)n Core(TM) i7-10700 CPU,显卡为NVIDIA GeForce RTX 3070 GPU的硬件配置。所提出的模型使用相同的3个基准数据集进行测试。这3个数据集分别是:GDELT[19],一个关于时间、语言和语调的全球数据库;维基百科的子集WIKI[20]和YAGO3的子集YAGO[20]。表1展示了3个数据集的统计量。3个数据集根据时间顺序按8∶1∶1的比例分为训练集、验证集和测试集。

表1 不同数据集的统计量Table 1 Statistics of different datasets
将所提出的模型与目前较为流行的模型,如TransE[2]、Dismult[5]、CyGNet[1]等进行了性能对比。本文选取平均倒数排名(mean reciprocal rank,MRR)、Hits@1、Hits@3和Hits@10对模型的性能指标进行度量。其中,Hits@n代表在链接预测中排名小于n的三元组的平均占比。在测试时,针对所提出的模型评测,还使用了常用的过滤评价约束,即从测试候选四元组中剔除真实的四元组所对应的尾实体,同时加入未在训练集中的尾实体,以获得相关性能指标。
超参数的设置取决于每个验证集的MRR性能,如式(9)中的系数α在范围0.1~0.9之间以步长为0.1进行调节取值。经实验测试,本文在GDELT集上的α设置为0.7,YAGO和WIKI上设置为0.5。由于超参数的选择会影响模型性能,实验选取了不同超参数值来验证模型的有效性。由表2可以看出,在YAGO数据集上,本文算法在α为0.5时的性能优于0.7。

表2 不同超参数在YAGO数据集上的性能对比Table 2 Performance comparison of different hyperparameters on YAGO dataset
除了超参数的选取,嵌入维度的选择也会对模型性能产生影响。实验对比了嵌入维度为200和400测试结果,如表3所示。可以看出,在YAGO数据集上的效果前者要比后者好。因此,本文选择嵌入维度为200进行后续实验。另外,模型选用Xavier方法进行初始化,然后使用AMSgrad方法进行优化。学习率设为0.001,批大小为1 024,训练轮次设置为30。

表3 不同嵌入维度在YAGO数据集上的性能对比Table 3 Performance comparison of different embedding dimensions on YAGO dataset
2.2 实验结果
本文所提模型与其他6种模型性能对比如表4所示,其中最好的结果用加粗表示,次好的结果用下划线表示。由表4可以看出,本文提出的模型性能优于目前几种流行的模型。这表明,在考虑实体之间的关系时,考虑关系的时间属性会带来性能的提升。表4显示,在不同的数据集上,性能的提升是不同的。在GDELT数据集上,本文所提模型性能提升优于其他基准数据集。但是这并不意味着所有预测精度的提高。从表5可以看到,YAGO数据集虽然整体预测效果提高,但是Hits@3和Hits@10的值分别下降了0.19%和0.97%。

表4 不同模型在3个数据集上的性能对比Table 4 Performance comparison of different models on three datasets %
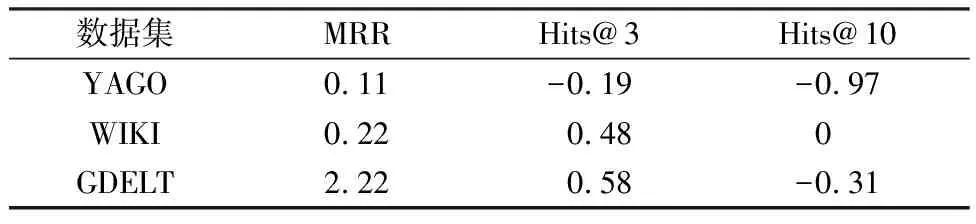
表5 本文所提模型相比于CyGNet模型的性能增量Table 5 Performance increments of the proposed model compared with the CyGNet model %
该模型在YAGO数据集上的训练过程中,尾实体和头实体预测的损失函数变化如图1所示。可以看出,针对头实体和尾实体,在训练初始阶段,该方法就可以达到较好的效果。尤其针对尾实体,该方法收敛更快。这是因为YAGO数据集中重复的头尾实体比例不平衡,经统计得到训练集中尾实体的历史重复率为93.8%,而头实体的历史重复率为99.0%,也就意味着在预测头实体过程中,本文所提模型的复制模式将无法对重复率过高(99.0%)的头实体相关事实进行有效筛选,也将无法有效降低历史上未发生事实的预测概率,这时复制模式无法发挥优势。然而,对于没有达到非常高重复率的尾实体的预测,本文所提模型将会表现出其优势。

图1 训练过程中损失函数的变化Fig.1 Changes of loss function during training process
3 结束语
时序知识图谱的表示和推理是一个具有挑战性的问题。本文根据关系的时变特性,将关系嵌入分解为静态和动态2个部分来解决这个问题。同时,本文所提DTESN模型融合了复制模式和生成模式2种推理模式,既可以从历史事件中得到结论,即已经发生过的事情可能重新发生,也可以从历史事实中推导结论,即发生以前没有的事实。实验结果表明,具有时间属性的关系嵌入矩阵在预测时序知识图谱中未来事实方面具有更好的性能。进一步地,可以对历史词汇表的构建进行改进,以提高模型的性能。
猜你喜欢
《学习方法报》历史中考版(2024年8期)2024-12-31 00:00:00
中国农业信息(2021年3期)2021-11-22 06:44:48
数学物理学报(2021年1期)2021-03-29 03:13:38
五邑大学学报(自然科学版)(2020年4期)2020-12-09 06:28:48
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
数学物理学报(2017年5期)2017-11-23 07:51:31
电子制作(2016年15期)2017-01-15 13:39:08
山西大同大学学报(自然科学版)(2016年2期)2016-12-12 03:19:27
河南科技(2014年19期)2014-02-27 14:15:33
