
基于改进YOLOv7的口罩佩戴检测算法
2024-02-23 04:00:12张文铠刘佳
北京信息科技大学学报(自然科学版) 2024年1期
张文铠,刘佳
(北京信息科技大学 自动化学院,北京 100192)
0 引言
许多病毒和细菌可通过空气中的飞沫和气溶胶进行传播,佩戴口罩是防止呼吸道传染病传播最有效的手段之一[1]。在特殊时期,公共场所一般都会有工作人员提醒大家佩戴口罩,但在人流量较大的情况下,很容易出现漏检的现象,这会增加呼吸道传染病传播的风险。如果增加检查的工作人员,则会耗费大量人力。因此,研发出一种口罩佩戴检测算法具有极为重要的现实意义。
自从2012年Hinton教授团队[2]利用卷积神经网络(convolutional neural network,CNN)研发出AlexNet之后,目标检测算法开始快速发展,逐渐从传统的目标检测转向为基于深度学习的目标检测。目标检测算法大体可以分为2大类别:两阶段检测和一阶段检测。两阶段检测算法的代表主要是基于区域的卷积神经网络(region based CNN,R-CNN)[3]系列算法,比如Fast R-CNN[4]和Faster R-CNN[5]。一阶段检测算法的代表主要是单步多框检测器(single shot multibox detector,SSD)[6]和YOLO(you only look once)[7]系列算法。两阶段检测算法检测精度高,但检测的速度较慢。而一阶段检测算法正好与之相反,检测速度快,但精度相对略低。对于口罩佩戴检测这种实时性要求较高的任务来说,应用一阶段检测算法更为合适。目前已经有许多研究将目标检测算法应用在口罩检测领域,如薄景文等[8]基于YOLOv3的轻量化口罩佩戴检测算法,金鑫等[9]基于改进YOLOv4的口罩佩戴检测算法,李小波等[10]融合注意力机制的YOLOv5口罩检测算法。上述方法虽然在一定程度上提高了算法的性能,但在精度上还是存在不足。2022年7月,YOLOv4团队正式发布YOLOv7,它采用了扩展高效层聚合网络、复合模型缩放、计划的重参数化卷积以及更有效的标签匹配策略,在速度和准确度方面都超过了所有已知的目标检测器[11]。为进一步提升口罩佩戴检测算法的精度,本文在YOLOv7算法的基础上做了相关的改进。首先,在YOLOv7模型的主干网络引入感受野模块,增大模型的感受野,提高算法的检测精度。其次,在头部网络引入基于卷积块的注意力机制,使得特征图上的特征信息更容易被突显出来。
1 YOLOv7算法
YOLOv7网络模型结构主要分为输入层、主干网络、头部网络 3个部分。
YOLOv7的输入层主要是对输入的图片进行预处理,主要包括 Mosaic数据增强、自适应锚框计算、自适应图片缩放等操作。YOLOv7的主干网络主要功能是特征提取,主要包括CBS模块、ELAN模块和MP模块。CBS模块是由1个卷积层、1个批归一化层和1个Silu激活函数层构成。ELAN模块由多个CBS模块构成,它通过控制最短和最长的梯度路径,使一个更深的网络同样可以有效地进行学习和收敛。MP模块的主要作用是进行下采样。YOLOv7的头部网络主要包括SPPCSPC模块、UP模块、ELAN-H模块和REP模块。SPP模块的作用是通过最大池化来增大感受野,提升模型精度。CSP模块的主要作用是减小计算量。它将特征分为两部分,其中一部分进行常规处理,另一部分进行SPP结构处理,最后再将两部分合并在一起。这样做可以减少计算量,而且还可以提升模型的精度。UP模块的主要作用是通过最近邻插值的方式进行上采样。ELAN-H模块与ELAN模块非常相似,不同的是ELAN-H模块选取的输出数量比ELAN模块多。REP模块在训练时将1个用于特征提取的3×3卷积、1个用于平滑特征的1×1卷积和1个无卷积操作融合在1个卷积层中,在推理时则重参数化1个3×3的卷积。
2 改进的YOLOv7算法
2.1 改进后的模型结构
为进一步提升口罩佩戴检测算法的精度,本文在YOLOv7算法的基础上做了相关的改进。首先,为了增大模型的感受野,提高算法的检测精度,在主干网络第24层引入RFB模块;其次,为了使得特征图上的特征信息更容易被突显出来,在模型的头部网络第63层引入卷积块注意力模块(convolutional block attention module,CBAM),改进后的算法模型结构如图1所示。图1中的cat表示拼接操作。
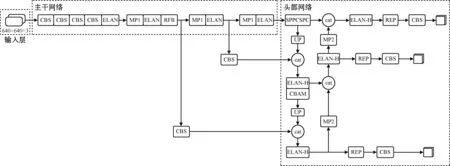
图1 改进的YOLOv7模型结构Fig.1 Model structure of improved YOLOv7
2.2 CBAM注意力机制
检测精度与模型的特征提取能力紧密相关,原YOLOv7算法在特征提取能力上还有一定进步的空间。本文为进一步增强模型的特征提取能力,在原YOLOv7算法的基础上引入了CBAM,使模型更加关注重要信息,进一步提升精度。
CBAM是由通道注意力机制(channel attention module,CAM)和空间注意力机制(spatial attention module,SAM)串行连接组成,在输入特征F的基础上依次融合了通道和空间两种维度上的注意力权重[12],最终与输入特征不断相乘输出一个新的特征FZ。这样不仅节约了计算力,而且与单一使用通道和空间注意力机制相比,特征图上的特征信息更容易被突显出来,从而提高模型的准确率[13]。CBAM基本结构如图2所示。
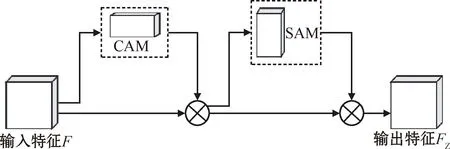
图2 CBAM基本结构Fig.2 Basic structure of CBAM
通道注意力机制处理过程如图3所示。输入特征F分别经过全局最大池化和全局平均池化,然后送入共享多层感知机[14],将得到的特征进行对位相乘并进行加和操作,最终经过Sigmoid激活函数得到通道注意力特征FC。
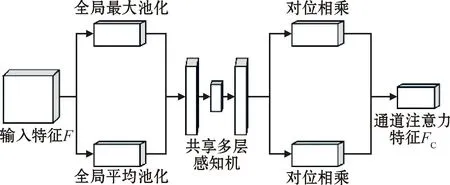
图3 通道注意力机制处理过程Fig.3 Processing process of channel attention mechanism
空间注意力机制处理过程如图4所示。输入特征F1是原始输入特征F与通道注意力机制生成的通道注意力特征FC进行乘法操作所得到的,输入特征F1经过基于通道的全局最大池化和全局平均池化,得到2个特征图并将其进行通道拼接和非线性运算,再经过一层卷积进行降维之后得到空间注意力特征FS。最后,再将输入特征F1与空间注意力特征FS进行乘法操作得到最终的输出特征FZ。
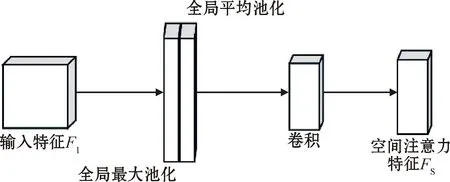
图4 空间注意力机制处理过程Fig.4 Processing process of spatial attention mechanism
2.3 RFB模块
YOLOv7主干网络的主要作用是对输入图像进行特征提取,但原YOLOv7主干网络感受野相对较小,导致获得的局部信息过多,全局信息过少,进而影响检测的准确率。所以为进一步增大模型的感受野,提高算法的准确率,在原YOLOv7的主干网络引入RFB模块。
RFB模块模仿了人类视觉的特点,将感受野和偏心率联系在一起,其结构与Inception结构相似,主要由不同尺度的常规卷积组成的多分支卷积层和不同尺度的空洞卷积层组成。多分支卷积层主要用来模拟群体感受野中不同的感受野,空洞卷积层主要用来模拟群体感受野尺度与偏心率之间的关联度[15]。这种结构不仅不会增加参数量,而且还扩大了感受野,提高了算法的检测精度。
图5为RFB网络结构,输入特征图首先通过3个分支来完成特征融合,3个分支分别通过1×1卷积(Conv)降低特征图的通道数,然后其中2个分支分别通过3×3和5×5的卷积核构成多分支结构来获取多尺度特征,并在对应的每个分支上分别引入扩张率(rate)为1、3、5的3×3空洞卷积来增大网络的感受野[16]。当扩张率为1时,空洞卷积就是常规的卷积。空洞率不同时,获得感受野的大小也不同。RFB模块将扩张率设置为1、3、5这种组合,使得采样点交错,尽可能多的学习局部信息,减少了网格效应带来的信息丢失。最后将3个分支的输出通过1×1卷积和拼接操作(Concatenation)连接在一起完成特征融合。将特征融合后的特征图与输入特征图通过捷径连接(Shortcut)层进行张量相加,并通过Relu激活函数完成最后的输出。
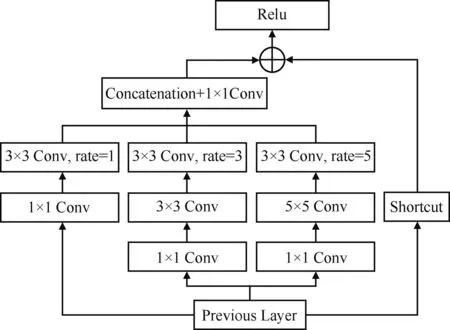
图5 RFB网络结构Fig.5 RFB network structure
3 实验及结果分析
3.1 数据集与实验环境
本文实验所用的口罩数据集主要来自于MAFA数据集中的部分图片、网络上收集的图片和生活中收集的图片。数据集总共有5 000张,划分为训练集3 000张,测试集1 000张,验证集1 000张,图6为部分数据集示例。图6(a)为单人脸数据集示例,其中包含单人正面未遮挡佩戴口罩情况、单人正面遮挡未佩戴口罩情况、单人正面未遮挡未佩戴口罩情况、单人侧面未遮挡佩戴口罩情况等。图6(b)为多人脸数据集示例,其中包含多人侧面佩戴口罩以及未佩戴口罩混合情况、多人正面佩戴口罩以及未佩戴口罩混合情况、多人正面佩戴口罩情况、多人侧面佩戴口罩情况等。

图6 部分数据集示例Fig.6 Partial dataset example
在建立数据集的时候通过LabelImg软件对图片进行标记,佩戴口罩的标记为mask,未佩戴口罩的标记为face。
为确保改进算法的准确性和有效性,本文所有实验统一在表1实验环境及配置下进行。
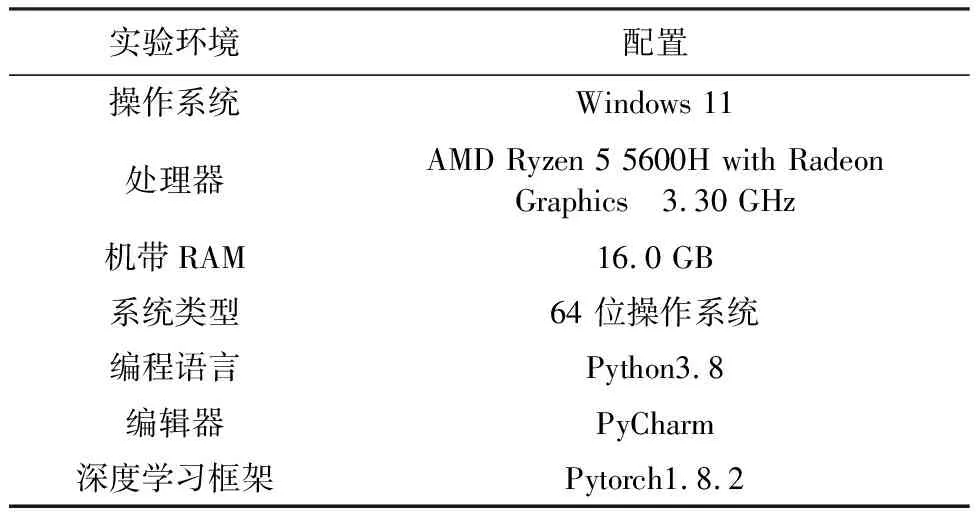
表1 实验环境配置Table 1 Experimental environment configuration
3.2 实验参数和评价指标
实验的具体参数如表2所示。为确保改进算法的准确性和有效性,本文所有实验均在同一参数下进行。

表2 实验的参数设置Table 2 Parameter settings for the experiment
实验主要的评价指标有:精确率(precision)、平均精度均值(mean average precision,mAP)和召回率(recall)。
3.3 实验结果与分析
为验证本文所提方法的有效性,在原始YOLOv7算法的基础上依次加入RFB模块、CBAM注意力机制、RFB模块和CBAM注意力机制,同时与目前几种主流的目标检测算法进行对比,消融实验的结果如表3所示。

表3 消融实验结果Table 3 Results of ablation experiment
从表3可以看出,在原YOLOv7算法的基础上引入RFB模块后,精确率提高2.6百分点,平均精度均值提高1.4百分点;在原YOLOv7算法的基础上引入CBAM注意力机制后,精确率提高3.3百分点,平均精度均值提高1.6百分点;在原YOLOv7算法的基础上同时引入RFB模块和CBAM注意力机制后,精确率提高5.6百分点,平均精度均值提高2.6百分点。在原YOLOv7算法的基础上同时引入RFB模块和CBAM注意力机制的精确率和平均精度均高于在原YOLOv7算法的基础上单独引入RFB模块和CBAM注意力机制,进而验证了本文所提改进算法的有效性。同时,本文提出的改进YOLOv7算法与YOLOv5s算法相比,精确率提高9.6百分点,平均精度均值提高2.9百分点;与最新提出的YOLOv8s算法相比,精确率提高12.0百分点,平均精度均值提高12.6百分点,召回率提高5.0百分点。本文提出的改进YOLOv7算法在满足实时检测的基础上,检测精确率及平均精度均值均大幅优于其他算法。
图7所示为算法改进前后的精确率-召回率曲线对比。精确率-召回率曲线与坐标轴围成的面积即为该类别的平均精度值,围成的面积越大表示平均精度值越高。平均精度均值是指交并比阈值为0.5时所有类别的平均精度均值。
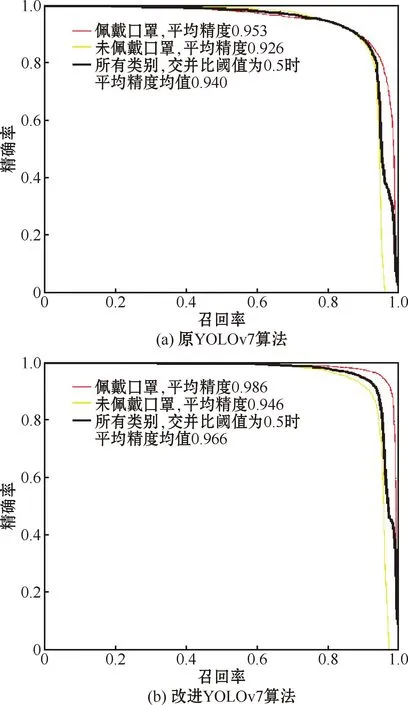
图7 YOLOv7算法改进前后精确率-召回率曲线对比Fig.7 Comparison of precision-recall curve before and after improvement of YOLOv7 algorithm
由图7可知,改进后的YOLOv7算法平均精度均值由94.0%提升至96.6%,提高2.6百分点。其中佩戴口罩类平均精度由95.3%提升至98.6%,提高3.3百分点;未佩戴口罩类平均精度由92.6%提升至94.6%,提高2.0百分点。综上所述,本文改进的YOLOv7算法平均精度和平均精度均值均优于原YOLOv7算法。
图8为算法改进前后的检测效果对比,其中图8(a)为输入图片,图8(b)为原YOLOv7算法的检测效果,图8(c)为本文改进YOLOv7算法的检测效果,其中检测框上方标示着检测类别以及该类别的置信度。
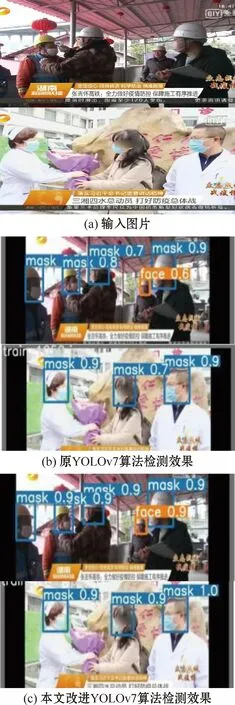
图8 算法改进前后检测效果对比Fig.8 Comparison of algorithm detection effects before and after improvement
由图8可知,原YOLOv7算法和本文改进的YOLOv7算法都可以准确地检测出口罩佩戴情况,但本文改进的YOLOv7算法检测效果置信度高于原YOLOv7算法,可以证明本文改进的YOLOv7算法检测效果优于原YOLOv7算法。
4 结束语
为提升口罩佩戴检测算法的精度,本文提出了基于改进YOLOv7的口罩佩戴检测算法。在YOLOv7的基础上,在头部网络引入CBAM注意力机制,在主干网络引入RFB模块。实验结果表明,改进后的YOLOv7口罩佩戴检测算法精确率达到95.7%,较原网络提高5.6百分点,平均精度均值达到96.6%,提高了2.6百分点,模型精度在原有的基础上得到大幅提升。但在引入注意力机制和各种模块之后,会增加原有模型的参数量,所以后续的工作将着重于模型轻量化的研究。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
意林(2020年9期)2020-06-01 07:26:22
海峡姐妹(2020年4期)2020-05-30 13:00:08
电子制作(2019年11期)2019-07-04 00:34:38
作文大王·笑话大王(2019年3期)2019-04-22 23:58:02
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
作文评点报·低幼版(2017年8期)2017-03-11 20:44:08
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
