
基于随机森林的输气管道压缩机流量软测量技术研究
2024-02-22 08:36孙海芳胡天亨马亚欣刘忠刚梁昌晶
石油化工自动化 2024年1期
孙海芳,胡天亨,马亚欣,刘忠刚,梁昌晶
(1. 中油国际管道有限公司 中哈天然气管道项目,北京 100029;2. 四川省天宇锐集团有限公司,四川 成都 610000;3. 中国市政工程西北设计研究院有限公司,甘肃 兰州 730000;4. 中国石油华北油田公司 第五采油厂,河北 辛集 052360)
随着国民经济的发展,天然气在一次能源消费中的比重越来越大,中国近年来兴建了中缅天然气、中哈天然气、西气东输、陕京线等一系列管道工程,逐步形成了横贯东西、纵贯南北、连通海外的输气管网。在管道运行期间,压缩机流量参数是核算压缩机效率、绘制性能曲线、分析管道能耗的基础参数[1-2]。但限于目前国内仍以体积计量作为天然气贸易和消费的主要结算方式,通常只在首站进出口汇管处安装超声波、容积式或气体涡轮流量计,对于并联压缩机组中的单台压缩机没有计量,各中间压气站也没有单独计量,这就导致管道方在协调上游气源和下游用户气量时,存在一定的盲目性和未知性,特别是在冬季或节假日用气高峰的工况下,压缩机的运行状态无法达到最优。因此,如何获得单台压缩机的流量参数是管道方亟待解决的主要问题之一。目前,已有诸多学者将数据驱动软测量技术应用于汽油干点预测[3]、海上油气生产系统预测[4-5]和污水化学需氧量[6]预测等方面,但针对压缩机流量的预测还鲜有报道。基于此,在现场测试实验的基础上,构建随机森林的流量预测模型,并采用网格搜索对影响模型精度的超参数进行寻优,最终实现最优预测模型,为能源管控和流量优化提供实际参考。
1 数据驱动软测量技术
软测量技术是在生产知识的基础上,选择一些容易测量的变量作为自变量,难以测量的变量作为因变量,用数据驱动和计算机技术构建两者之间的非线性关系,对因变量实施预测的过程[7-8]。实现过程包括自变量选择、数据采集及预处理、软测量建模三部分,其中,软测量建模是预测结果准确性的关键,采用随机森林模型构建。
2 软测量模型构建
2.1 随机森林模型
随机森林模型属于以决策树为个体的集成学习算法,可用于分类或回归预测,避免了传统模型存在的过拟合或欠拟合现象[9]。首先,采用Bootstrap方法抽取训练集数据,该方法是在原始样本容量不变的前提下,有放回的抽取观察样本,保证每个观察样本被抽到的概率相等,最终形成n个子样本集{X1,X2, …,Xn};随后,建立与子样本集对应的决策树,并随机选择m个特征变量作为当前决策树节点的分裂特征集;最后,对每个决策树回归得到的数据汇总,即为{Y1,Y2, …,Yn},取回归结果的均值作为模型最终预测结果[10]。
2.2 网格搜索和交叉验证
在随机森林算法建模的过程中,决策树的个数n和分裂特征数m属于超参数,两者决定着预测模型准确性和泛化能力。n数量太小,导致训练阶段拟合不充分;数量太大,导致计算时间过长。m数量太小,导致特征分裂准确性存在误差;数量太大,导致计算效率过低。在此,采用网格搜索对超参数进行寻优,即对所有可能出现的n和m组合下的随机森林模型的预测效果进行遍历,以期找到精度最高的参数组合。但网格搜索在面临数据量较大样本时,计算复杂度会呈指数增长,故继续采用交叉验证的方式提高被评估模型的准确性和可靠性,避免数据集分组不均衡带来的数据偏移现象[11]。
交叉验证是将全部样本集分为K组,其中K-1组作为训练集,剩余的1组作为测试集,每次训练结束后,输出K个模型的预测结果,将平均得分作为模型评价标准。
2.3 软测量模型预测流程
预测流程如下:
1)数据收集。选择压缩机进口压力、出口压力、进口温度、出口温度、转速、气质中甲烷含量、大气压力、环境温度、燃料气消耗量作为输入变量,选择压缩机流量作为输出变量。
2)数据预处理。考虑到不同变量具有的量纲和量纲单位不一,为消除各维数据之间的数量级差别,对变量进行归一化处理,如式(1)所示:
(1)
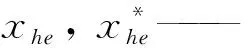
3)确定输入变量。为避免输入变量间的冗余性对模型预测精度造成影响,根据“平均基尼指数”下降的原则衡量袋外数据的回归准确性,如该变量的基尼指数对样本回归的误差结果影响较大,则该变量的重要程度较大。
4)确定模型参数。在网格搜索和交叉验证的基础上,确定模型超参数,交叉验证K取10,即为10折交叉验证。
5)模型训练及结果分析。将训练集和测试集代入设定好参数的模型中,将预测结果进行反归一化处理,得到最终预测结果,并通过均方根误差(RMSE)、平均绝对百分比误差(MAPE)对模型精度进行定量评价,如式(2),式(3)所示:
(2)
(3)

3 实例分析
3.1 数据收集及处理
以某输气管道典型离心式压缩机为例,首站配有1台国产CGT30-D型燃气轮机驱动的PCL805型离心式压缩机,3台进口RR型燃气轮机驱动的RFBB36型离心式压缩机,最大进站压力为5 MPa,在出口汇管处配有超声波流量计。利用用户调峰及设备检修间隙,参照SY/T 6637—2018《天然气输送管道系统能耗测试和计算方法》中的测试步骤,由获取计量资质的专业人员通过便携式流量测试设备对单台压缩机组的流量进行连续监测,同时采集与流量数据相关的特征作为输入变量。其中,压力、温度、转速根据现场数据采集与监控系统(SCADA)的监测结果获取,气质中甲烷含量通过便携式气相色谱仪获取,燃料气消耗量通过燃料气流量计获取。测试期间,在5 min之内,转速的波动范围应在±0.5%,压力的波动范围在±2%,温度的波动范围在±0.5℃为稳态工况的判定依据,由此测试不同条件下的压缩机流量数据。以PCL805型离心式压缩机的数据为例,共获取不同工况下的500组数据,部分数据见表1所列。随后,利用式(1)对表1的数据进行归一化,完成数据预处理过程。

表1 PCL805型离心式压缩机流量数据(部分)
3.2 确定输入变量
设置n和m的缺省值分别为200,3,则输入变量重要程度如图1所示。其中,燃料气消耗量和大气压力的重要程度小于0.3,说明这2个参数对压缩机流量的预测结果不构成影响,应予以删减。

图1 输入变量的重要程度示意
3.3 模型参数确定
在n=200的条件下,考察不同m值下预测结果的RMSE和拟合优度,见表2所列。其中,m=5时,预测结果的RMSE最小、拟合优度最大,即m=5为最佳参数。

表2 不同m值下预测结果的RMSE和拟合优度
在m=5的条件下,考察不同n值下预测结果的RMSE,如图2所示。随着n的增加,模型计算误差逐渐减小,在n>200时,模型计算误差接近下限。考虑到模型误差要求一定程度上保持平稳性,故最终n取300。

图2 不同决策树数量下的预测结果示意
3.4 模型预测结果
将测试集数据代入训练好的随机森林模型,得到压缩机流量预测结果。为了验证本文结果的准确性,与支持向量机(SVM)模型、朴素贝叶斯(NB)模型和经网格搜索确定超参数的支持向量机(GS-SVM)模型的预测结果对比,见表3所列。其中,GS-SVM模型中的惩罚因子为10,不敏感参数为0.001,SVM和NB模型的超参数为默认值。将SVM和GS-SVM模型相比,GS-SVM模型的预测精度大幅提升,说明超参数直接影响模型的泛化能力,合理的超参数寻优方法对于节省模型算力具有重要意义,网格搜索方法具有一定合理性。将GS-SVM和本文模型相比,两者只是数据驱动的模型不一致,但明显本文模型的预测效果更好,这是由于支持向量机虽然可以在小样本条件下建立数据逼近和回归,但本质上属于浅层神经网络模型,对于压缩机流量这类复杂非线性的数据集理解和剖析能力有限,随机森林的中间层是由数个决策树构成,通过剪枝操作得到最终结果,其结果反映了多数的决策结果,故预测效果更好。将NB和本文模型相比,NB的预测效果最差,这与该模型在实施预测时需确定先验概率,而先验概率取决于假设条件,当假设条件不恰当时,对模型预测精度影响较大。
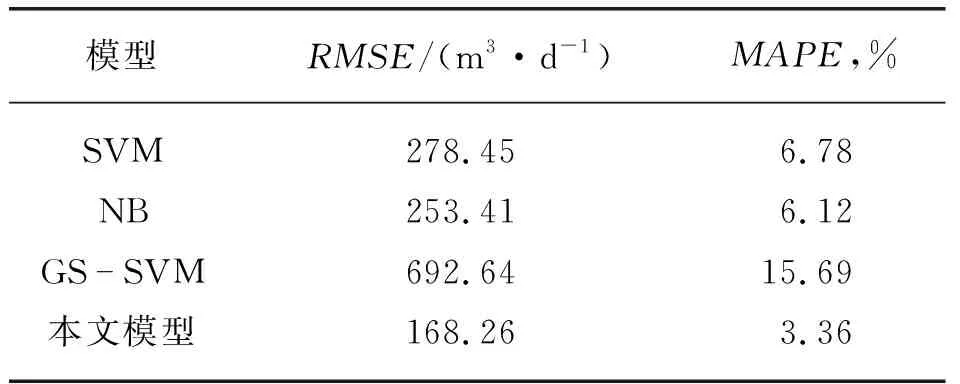
表3 不同模型中RMSE与MAPE的预测结果对比
绘制真实值与本文预测值的点线图,对比如图3所示。可以看出两者的吻合性和一致性较好,仅有部分预测值偏离真实值,但偏离程度较小。总体上看,基于随机森林的软测量技术可以真实地反映单台、多台并联压缩机及汇管的工艺气流量,对于提高站场自动化水平、制定节能降耗措施具有重要意义。
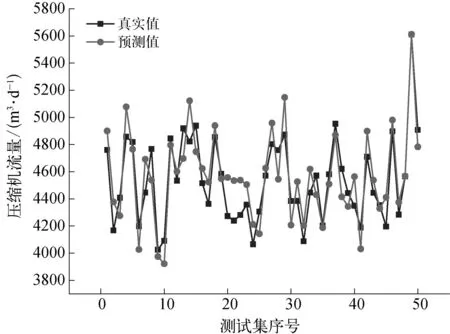
图3 真实值与预测值对比示意
4 结束语
本文模型在融合网格搜索和随机森林算法的基础上,实现了基于数据驱动的压缩机流量软测量建模,通过基尼指数确定了燃料气消耗量和大气压力对压缩机流量的相关性较小,其变量应予以删减。通过交叉验证和网格搜索确定了随机森林的超参数,决策树的个数n为300,分裂特征数m为5时的预测效果最佳。与SVM,NB,GS-SVM模型相比,本文模型的RMSE和MAPE均最小,说明了本文模型可以用于压缩机流量的软测量,具有一定的先进性和科学性。
猜你喜欢
中学生数理化·七年级数学人教版(2022年10期)2022-11-11
数学年刊A辑(中文版)(2019年3期)2019-10-08
成都信息工程大学学报(2019年3期)2019-09-25
船舶标准化工程师(2019年4期)2019-07-24
石油化工建设(2018年3期)2018-11-30
石油化工自动化(2018年5期)2018-11-14
电子制作(2018年16期)2018-09-26
北京航空航天大学学报(2017年6期)2017-11-23
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
浙江大学学报(工学版)(2016年10期)2016-06-05
