
融合多样频度与分布差异的Android恶意软件检测
2024-02-22 07:44赵旭康刘晓锋
计算机工程与设计 2024年2期
赵旭康,刘晓锋+,徐 洁
(1.西华师范大学 计算机学院,四川 南充 637009;2.西华师范大学 电子信息工程学院,四川 南充 637009)
0 引 言
传统的恶意软件检测依赖恶意软件库的建立来进行检测工作,但是无法有效应对恶意软件的变种[1]。伴随人工智能的兴起,机器学习等技术逐渐被应用至恶意软件检测领域并取得较好的成果[2],主要通过特征工程将移动应用转换为向量进行表示。在特征选择方面,文献[3]选择卡方检验(chi-square test,Chi)作为特征选择方法,与基尼不纯度增量相结合来寻找数据集中包含的关键特征;文献[4]提出一种基于信息增益(information gain,IG)的恶意软件特征选择方法,在减少特征数量的同时取得了较好的实验效果。然而IG算法借助熵的概念去判断某个特征对于整个数据集的重要性,并未体现出不同类别中特征的差异性;Chi算法通过辨别实际与理论在数值上的差距来确定特征的地位,只记录数据集中该特征是否出现,从而忽略此特征的频率。
为此,本文提出一种特征重要性评分算法(feature importance scoring algorithm,FIS),改进词频-逆文档频率(term frequency-inverse document frequency,TF-IDF)算法对于常见特征权重下降的不足,突出类间频度和特征在不同类别之间表现的分布差异的重要性。选取权限、意图和接口3种特征,将FIS算法分别与传统的特征选择算法和其它的主流检测工具在数据集上做对比实验。实验结果表明,FIS在准确率等性能评价指标上相比其它算法,有着一定提升。
1 相关工作
本文对于恶意软件特征的提取工作主要集中于静态分析方面。其中接口(application program interface,API)、权限和意图等在应用程序包(Android application package,APK)中包含的特性通常会被为判断应用程序是否具有恶意行为的依据。静态分析的优点在于速度快和能耗低,可以帮助分析人员快速了解一个应用的大致行为。文献[5]提出一种基于权限的贝叶斯分类检测系统,其最佳准确率为91.1%;文献[6]专注于Android应用程序的调用资源,将API作为特征并选择支持向量机来检测恶意程序。同时,更多的研究倾向于选择多特征结合的方案来提升最终效果。文献[7]结合权限和API调用来建立分类模型,并通过3种不同的分组策略来筛选最有价值的特征;文献[8]提出包含权限和意图特征的Android恶意软件检测,将主成分分析PCA和t-SNE相结合,最终达到91.7%的准确率。
从上述文献可看出,接口、意图以及权限组合一起可用来表征一个应用的具体行为,同时具备检测速度快的优点。采用多特征与机器学习技术进行恶意软件检测是现在研究的趋势,因此本文选择静态分析的方式提取应用特征,同时结合机器学习模型弥补准确率不足的问题,进一步提升检测的效果。
2 基于FIS的恶意软件检测
2.1 总体框架
如图1所示,本文提出的基于FIS算法的Android恶意软件检测方法的关键步骤为:通过分析不同类别之间特征分布的差异性与在多类别中出现的频繁程度,计算出特征的差异指数和频度以淘汰重要性较低的冗余特征,最后将筛选出的最优特征子集交给分类器。
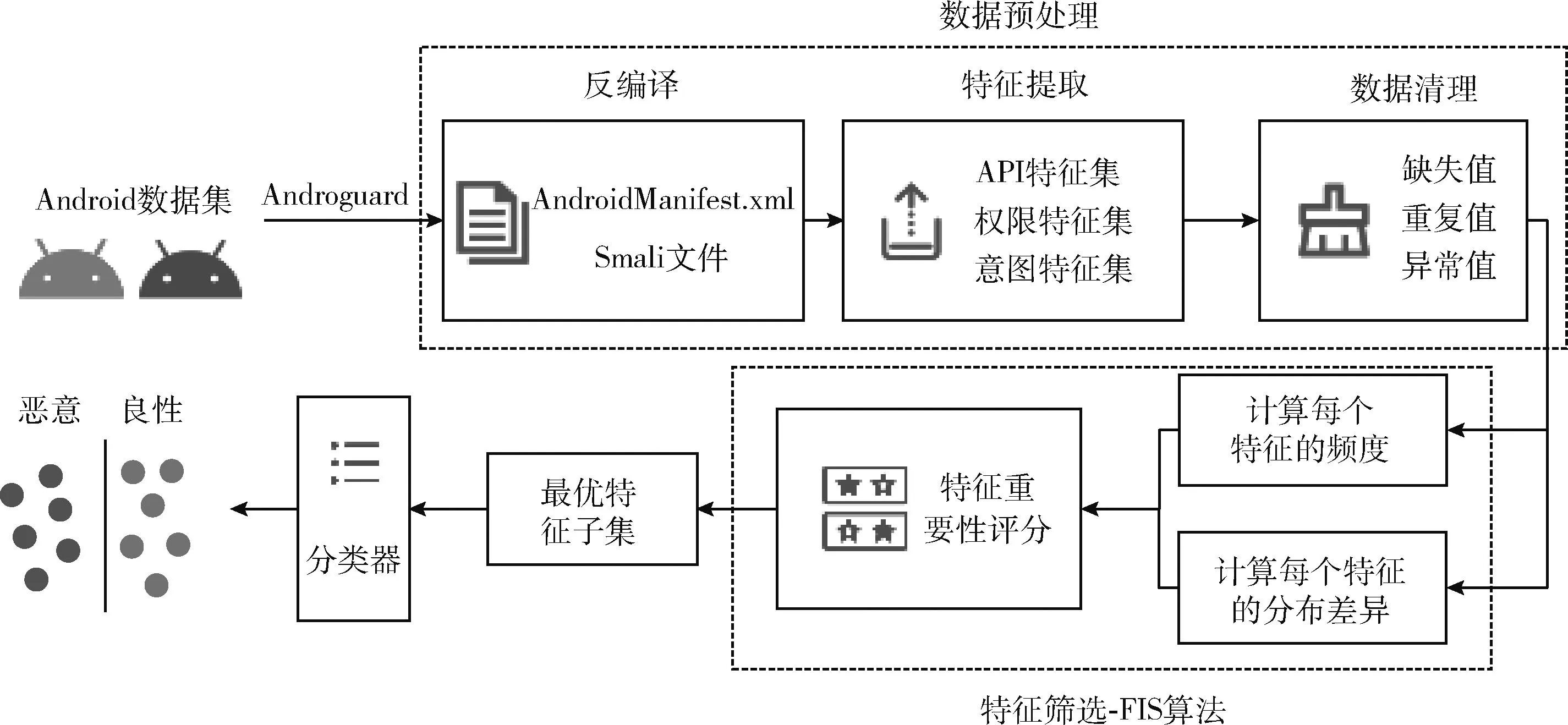
图1 恶意软件检测的总体框架
数据预处理与FIS算法模块是该方法的核心。在预处理过程中,需要对原始数据做详细的扫描来提取出原始特征集,同时对集合里的特征进行逐一分析,剔除一些异常的数据保证之后特征选择工作的顺利进行。
在特征选择模块中,对预处理之后的特征集运用FIS算法,计算出每个特征的频度和分布差异指数,通过最终的重要性评分来评选出最优特征子集。
在数据预处理步骤中使用Androguard开源工具对安卓样本集进行逆向分析。通过批处理的形式从反编译后的AndroidManifest.xml文件中提取Intent意图和Permission权限的特征信息,从smali字节码文件中获取API接口的特征,将三者一并组合成原始特征集。
2.2 特征重要性评分算法
FIS算法借鉴TF-IDF中重视频度的思想,在其基础上加以改进,引入类间特征分布的差异指数,以此来筛选出更有代表性的关键特征从而改善实际的分类效果。
2.2.1 FIS算法的定义
TF-IDF在数据挖掘中普遍用来评价一个单词对于文件的重要程度。该方法认为,一个单词的重要性与它在本文件中重复的次数成正比,和在语料库中出现的频率成反比。其中,TF认为某个特征的重要性与它在总体样本集上出现的次数有关,却没考虑到多类别的具体情况。IDF在削弱常见特征同时,会导致部分有区分度且数量不少的特征重要性下滑。因此需要对上述问题进行重新设计,达到特征选择的要求。
FIS算法从特征在不同类别中表现出的多样频率和其在类间分布的差异性两个角度对每个特征进行评分,为之后的特征筛选提供依据。一般而言,区分度较高的特征具有如下两种特点:①代表性:该特征至少在一种类别的样本集中具有较高的出现频率;②差异性:该特征在某个类别的样本集中具有普遍性,同时在另一类别的样本集中保持一定的低占比。
FIS算法以某个特征的分布差异为基准,辅以该特征在不同类别中表现出的多样频率作为衡量此特征重要性评分的标准。其相关定义如下:
定义1 特征多样频度:特征i的频率反应出在样本集中出现的频繁程度。若频率越高,特征i总体出现的次数越多;相反若频率越低,i出现的次数越低。记作FEi,计算公式如式(1)所示
(1)
其中,Nmal表示恶意样本集中软件的总数量,Nben表示良性样本集中软件的总数量,Ei,j代表应用j中是否包含特征i,若存在,则Ei,j=1, 否则为0。 P(Xi=1) 表示包含特征i的应用程序的出现概率。与TF-IDF中词频TF相比,FEi增加对于具体类别的分布情况,而不是仅从整体样本集上计算。
定义2 特征分布差异:特征i差异指数的数值与其在类间分布的差异性呈正比关系,用DNi表示,其计算的公式如式(2)所示
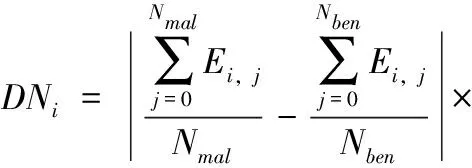
|P(C=mal)-P(C=ben)+1|
(2)
其中,P(C=mal) 表示在样本集中应用为恶意的概率,P(C=ben) 代表应用为良性的概率,并在末尾添加1用来预防出现在均衡样本集中出现两种概率相等的情况。DNi改进TF-IDF中仅关注单一类别的局限性问题,量化出不同类别表现出的实际差异,更好应对不同样本数量不均等的问题。
定义3 特征重要性指数:表示特征i的重要程度。如果重要性指数越高,代表该特征i的重要程度越高,记作Si,评价公式如式(3)所示
Si=FEi×DNi
(3)
Si综合考虑某个特征的频度与分布差异两种因素来计算出某个特征具体的重要性评分。在之后的特征筛选过程中,并不设置具体的阈值来判断某个特征是否具备区分度。本文认为区分度并不是只有是否存在两种可能性,应该由Si来量化其重要程度,最后根据分数的高低从大到小依次选择。
2.2.2 FIS算法的过程
本文涉及到的特征选择分为特征评分与筛选两个部分。其核心步骤如下:
(1)计算多样频度。在第(7)行中,根据某特征在全部应用出现的次数与总应用的数量的占比计算出包含该特征的应用程序的出现概率,再按照公式(1)将其与在不同类别的出现的频率相乘得到多样频度。
(2)计算分布差异。第(8)行,计算出某特征在不同类别中出现的频率差值,根据式(2)分别计算出不同类别样本集的数量差距与特征出现的频率差值相乘得到特征的分布差异。
(3)构建特征评分集合。第(9)行中,将之前计算出的多样频度与分布差异结合式(3)得到每个特征的重要性评分,将其添加评分集合中作为特征筛选的唯一依据。
在算法1的描述中,第(2)、第(3)行均是统计出相关应用的数量,仅需执行一次。算法主要的时间损耗发生在第(4)~第(11)行对特征集进行遍历的过程。遍历特征集的循环次数为集合中含有的特征个数,其余环节均不涉及重复执行。
算法1:特征重要性评分算法
输入:恶意应用特征个数映射函数Lmal,良性应用特征个数映射函数Lben,全部特征集D1
输出:特征重要性评分映射集合List_Score
(1)List_Score=null; //全部特征的FIS评分集
(2)M=恶意应用的全部数量;
(3)B=良性应用的全部数量;
(4)forfiinD1do
(5)NMi=Lmal(fi); //fi在全部恶意应用中出现次数
(6)NBi=Lben(fi); //fi在全部良性应用中出现次数
(7)FEi=(NMi/M+NBi/B)*(NMi+NBi)/(M+B);
(8)DNi=|NMi/M-NBi/B|*|M/(M+B)-B/(M+B)+1|;
(9)Si=FEi*DNi; // 得到单个特征的评分
(10) Add (Si,fi) inList_Score;
(11)end for
相比于TF-IDF 算法,FIS在输入时加入包含特征个数的映射,能够大大减少时间消耗,其时间复杂度为O(n),在时间消耗方面的代价相比TF-IDF更低。
3 实验结果与分析
本文共进行以下实验评估FIS算法的特征选择效果:
实验1:围绕分类器模型和特征的数量与类型展开,印证FIS算法能够有效地筛选出关键特征。
实验2:为了验证FIS算法在识别准确率等评价指标方面的优越性,选择信息增益、卡方校验和TF-IDF的特征选择方法与FIS算法做横向对比,同时与其它成熟的检测工具进行比较,评估FIS算法在实际应用中的具体成效。
3.1 数据集
实验使用的数据集由Android良性和恶意应用两种类型的样本组成。其中1400个恶意应用来自CICMalDroid2020[9,10]与CICInvesAndMal2019[11]开源项目,1400个良性应用在安卓网(https://www.apk3.com/app)自行下载获得,并且所有良性应用在实验前均由360安全杀毒引擎进行二次验证,确保它们的非恶意性。
采用Androguard开源工具对数据集中2800个应用进行反编译处理,通过数据预处理后一共提出到3844个特征。为方便机器学习,需要对特征向量化。定义集合S为样本集中所有类型特征的并集,如式(4)所示,集合S1、S2和S3分别代表权限、API和意图3大类别的特征。若当前APK包含某种特征,则标记为1,否则表示为0
S=S1∪S2∪S3
(4)
因为恶意检测的本质是二分类问题,所以在最后添加isMalware一列。值为1,代表这个应用是恶意软件,为0表示这个应用是良性软件。表1以转置的形式展示了部分特征属性的向量化信息。

表1 部分特征属性向量化信息
3.2 评价指标
本文使用准确率ACC(accuracy)、假正率FPR(false positive rate)、召回率Recall、F1值和ROC(receiver ope-rating characteristic)曲线5个指标对本文提出的检测算法进行评估。其中TP(true positive)和FP(false positive)分别表示为良性软件被正确预测为良性软件的数量与恶意软件被错误判定为良性软件的数量;TN(true negative)与FN(false negative)分别表示为恶意软件被正确识别成恶意软件的数量与良性软件被错误识别成恶意软件的数量。具体的公式定义如下所示
(5)
(6)
(7)
(8)
(9)
(10)
ROC的纵坐标是真正率TPR,其值与召回率等同,横坐标为假正率FPR。
3.3 FIS算法的效果验证
FIS算法的设计初衷是为了在特征选择过程中筛选出更具有代表性的特征,降低一般特征的重要性。
在权限、接口和意图3种类别中,从数据集中2800个样本里一共提取出重要性分数从大到小排名前30、90、150和全部3844个特征。将它们分别作为朴素贝叶斯Naive Bayes、支持向量机SVM(support vector machine)、K近邻KNN(k-nearest neighbor)和随机森林Random Forest这4种分类器的输入,最终的结果如图2所示。

图2 FIS算法使用不同分类器的准确率
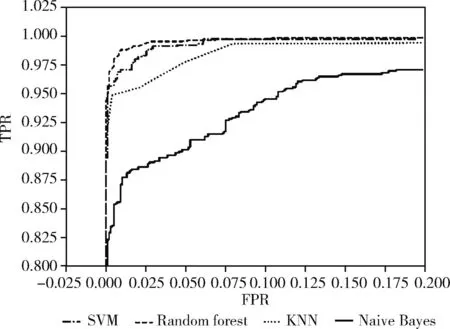
图3 FIS算法使用不同分类器的ROC曲线
结果表明,随机森林分类器获得的准确率最高,整体效果最好;SVM次之,准确率略低于随机森林,其次是KNN,效果最差的朴素贝叶斯分类模型最高准确率仅为93.8989%。
图3表示在特征数量固定为150的情况下,4个分类器ROC曲线的局部放大对比。随机森林分类器的曲线朝左上方凸起的表现最为明显,朴素贝叶斯的曲线最靠近右下方。
因此,4种分类器中最适合FIS算法的是随机森林模型,它带来的效果更好,朴素贝叶斯对于本算法来说是最不合适的。从FIS算法应用在随机森林模型上的表现可以得出该算法能够有效地筛选出有区分度的关键特征。在特征集合中选出重要性指数排名前150个的特征,最后训练的效果与全部特征的训练效果基本等同甚至略好(特征数量为150时准确率为98.8448%,3844个全部特征的准确率为98.7091%)。因此,FIS算法可以有效地筛选出具有区分度的关键特征,在特征数量较少的情况下达到较好的分类效果,满足了其设计的初衷。
为验证接口API、意图Intent和权限Permission这3种类型结合的特征除了理论上优势,是否具有实际数据的参考意义,所以分别选出API、Intent、Permission和三者结合的类型,各自提取重要性评分排名前30、90和150个特征作为对比。统一选择随机森林作为分类器,最终结果如图4所示,本文选择的3种特征结合的方式更占据优势。在特征数量相同的条件下,结合后的结果都比单独的特征效果好。
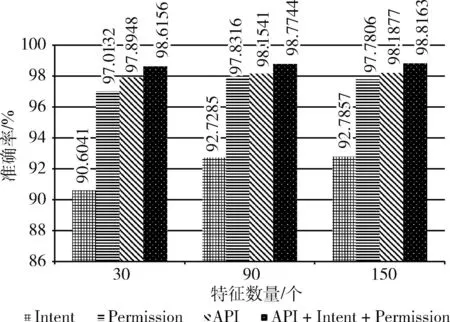
图4 多特征在不同数量下的准确率
3.4 与其它特征选择方法的对比实验
为进一步验证FIS算法在特征选择过程中的实际表现和优势,将其与IG、Chi和TF-IDF这3个算法进行对比。表2展示在特征数量固定为150的条件下,IG、Chi、TF-IDF和FIS这4种选择算法在朴素贝叶斯NBayes、支持向量机SVM、K近邻KNN和随机森林Random Forest这4种分类器模型的实验数据对比。

表2 不同特征选择方法的实验结果对比
数据表明,在K近邻和支持向量机的分类器中,FIS表现不及TF-IDF和卡方检验算法,但是在朴素贝叶斯和随机森林两种模型中,FIS相比其它算法的表现更优,同时随机森林与FIS算法的组合能够在3个指标下均获得本次实验的最高评分。虽然在K近邻和支持向量机两种模型下表现不及TF-IDF和卡方检验,但是分类器的作用仅是为了逼近最终结果上限。从总体来看,FIS算法对恶意软件的识别效果明显优于其它传统的选择算法。
同时将FIS算法计算每个特征的重要性评分所花费的时间与TF-IDF算法进行对比,FIS算法总共花费约1.725 s的时间,相比于TF-IDF的0.888 s可以节约48%。
将同类文献提出的特征选择方法与本文的FIS算法同时应用在相同的数据集上(一共3844个特征)进行实验测试。其中,文献[12]提出一种检测外观比率间隔的特征选择方法来筛选关键特征。文献[13]使用遗传算法去除数据集里冗余特征,实验的数据结果见表3。

表3 与其它恶意软件检测情况对比
可以看出,文献[12]的F1值和文献[13]的准确率与本文提出算法的效果接近,但是筛选出的特征数量远远多于FIS算法得出的150个特征。文献[12]的外观比率间隔算法通过Mann-Whitney检验得到特征集,但其检验的效率较低,要足够的样本容量才能达到合适的结果;文献[13]采用的遗传算法会对大量个体样本进行计算评估,同时涉及多种参数需要调整,如种群大小和交叉率等,所需的计算成本较高。本文提出的FIS算法实现简单,不受样本集规模和各种参数的影响,拥有良好的适应性。实验结果表明,在效果接近的情况下,本文提出的FIS算法明显更具有优势,能更高效地判断应用的恶意性。
本文从CICInvesAndMal2019数据集中选出不同于之前数据集的143个恶意软件,用来验证FIS算法对于未知软件的检验识别能力。使用之前训练成功的随机森林模型生成的检测工具分别与小红伞、腾讯电脑管家、火绒和金山毒霸4种软件进行检测,结果见表4。

表4 不同检测工具的准确率
结果表明,腾讯电脑管家检测的准确率最高,达到97.22%,其次是93%准确率的小红伞。表现较差的是金山毒霸和火绒,准确率均低于60%。本文提出的基于FIS算法检测工具准确率在90%以上。因此该算法可以有效应对未知的恶意软件。
4 结束语
本文从特征的频度和差异性两个角度提出了一种特征选择算法FIS,用来筛选出具有代表性的少量特征来体现恶意行为,作为分类器的输入。与TF-IDF算法相比,FIS算法加强对不同类别应用的特征频率表现,同时加入分布差异指数,用以表征同一类别中的应用中不同特征体现出的差异性。实验结果显示,FIS算法可以有效提高恶意软件检测的效率,最佳准确率为98.82%。
另一方面,FIS算法仅对单一特征进行了重要性分析,没有重视多种特征之间的关联特性[14]。下一步工作中,将在未来工作中完善上述不足,并着力于函数调用图等图模型结合图卷积网络进一步研究[15]。
猜你喜欢
电子测试(2018年1期)2018-04-18
电子制作(2017年23期)2017-02-02
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
西北工业大学学报(2015年4期)2016-01-19
新校长(2016年8期)2016-01-10
商事法论集(2014年1期)2014-06-27
电测与仪表(2014年15期)2014-04-04
中国中医药现代远程教育(2014年16期)2014-03-01
振动工程学报(2014年4期)2014-03-01
