
基于主成分分析的随机森林钢材缺陷检测算法
2024-02-21 00:14王纯杰谭佳伟
吉林师范大学学报(自然科学版) 2024年1期
王纯杰,张 钺,谭佳伟
(长春工业大学 数学与统计学院,吉林 长春 130012)
0 引言
钢材是广泛应用于汽车、建筑等行业的重要材料,具有高强度和强耐久性等特点.然而,在生产加工过程中,钢材往往会出现划痕、污渍等缺陷.这些缺陷不仅影响钢材的整体质量,还对产品的安全和性能产生巨大影响.缺陷检测是制造生产过程中的关键步骤,对于质量控制和生产效率来说至关重要.传统的缺陷检测算法往往效率较低且准确性有限.因此,本文提出一种基于主成分分析[1-2](Principal Component Analysis,PCA)和随机森林[3](Random Forest)的钢材缺陷检测方法,提高对不同类型的钢材缺陷的检测效率和准确性.
本文首先利用PCA方法,对钢材数据进行特征提取,然后利用随机森林算法,对PCA提取的特征进行快速准确分类,最后为了进一步提高模型缺陷检测的性能,引入合成少数类过采样算法[4](Synthetic Minority Over-sampling Technique,SMOTE),用于解决在钢材缺陷检测数据集中的样本类别不均衡问题.
1 缺陷检测方法
1.1 主成分分析
PCA是一种经典的降维方法,常用于特征提取和去除数据冗余信息,其主要通过线性变换将数据映射到一组新的正交特征上,使这些特征能够最大程度地解释原始数据的方差,保留信息最大化.PCA的算法步骤如下:
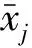
标准化后的数据Xij和样本矩阵X分别为
(2)计算标准化后样本的协方差矩阵为
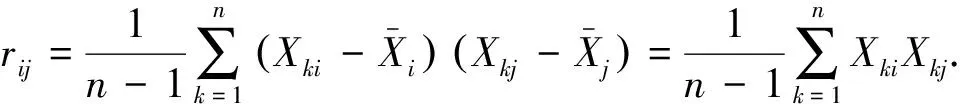
(3)计算协方差矩阵的特征值λ1≥λ1≥…≥λp≥0和特征向量a1,a2,…,ap.
(5)得出主成分.一般选取累积贡献率超过80%的特征值所对应的第一、第二、…、第m(m≤p)个主成分,其中第i个主成分为
Fi=a1iX1+a2iX2+…+apiXp,i=1,2,…,m.
PCA通过将原始的高维数据投影到低维空间中进行降维,减少了数据冗余和噪声,较大程度提高了模型的精度和可解释性.
1.2 SMOTE
SMOTE作为一种过采样算法,常用于解决样本分布不均衡的问题,其主要是基于样本的特征空间,通过对少数类样本进行插值处理,生成新的少数类样本来增加该类在数据集中的样本量,以达到数据集的样本均衡,起到提高分类模型性能的作用.SMOTE算法流程如下:
(1)对于每一个少数类样本,利用欧氏距离计算其到所有其他少数类样本间的距离,得到其k近邻;
(2)从k近邻中随机选择一个样本,计算该样本与当前样本的差异;
(3)根据差异比例,生成一个新的合成样本,该样本位于两个样本间的连线上;
(4)重复上述步骤,直到生成指定数量的合成样本.
通过SMOTE算法,少数类样本的特征空间得到有效扩展,模型能够完整地学习到少数类样本的特征,降低模型过拟合的趋势,提高模型的泛化能力、预测准确性和稳健性.
1.3 随机森林算法
随机森林是一种常用于解决分类和回归问题的有监督学习算法,其本质是集成多个决策树的估计预测方法.在随机森林中,各决策树通过对原始数据进行有放回抽样得到的一部分样本进行训练,每个决策树得到一个分类结果,将所有分类结果取众数即为最终预测结果.值得注意的是,随机森林中的各决策树间没有关联,同时在每个节点上,随机森林还可以通过随机特征选择机制进一步增强模型的泛化能力[5-7].
随机森林通过集成多个决策树模型来提高预测准确率,同时能够有效处理高维数据和大规模数据集,且对噪声和异常值的敏感性较低,使得模型对噪声和异常值带来的影响反应较小,具有良好的鲁棒性.
2 实验结果与分析
2.1 实验对象
实验数据选取UCI钢板缺陷数据集,该数据集收集了1 941个样本和对应的27种特征数据与7种故障类型,分别是Pastry、Z_Scratch、K_Scatch、Stains、Dirtiness、Bumps和Other_Faults.
在建立模型前先对样本数据进行分析处理.首先,统计27种不同特征下的数据分布,判断是否存在异常值、缺失值等情况.不同特征下的箱型图如图1所示.

图1 27种特征的数据分布箱型图
根据图1可知,不同特征的取值范围均不同且数据值分布范围较广,数据集中不存在数据缺失等情况.然后,对数据集中的7种故障类型数量进行统计,判断样本类别分布是否均衡.不同故障类型的数量和故障数据分布直方图如表1和图2所示.

表1 不同故障类型的数量
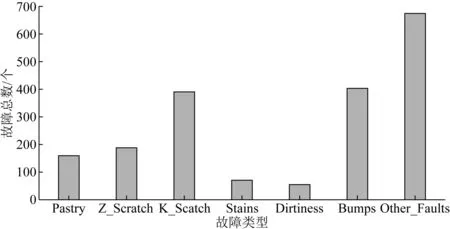
图2 7种故障的数据分布直方图
结合表1和图2可知,UCI钢材缺陷检测数据集存在明显的样本分布不均衡情况,因此,利用SMOTE算法进行数据扩充,将7种故障的样本数均扩充至673进行分析.
然后,利用PCA进行降维和特征提取.首先进行数据归一化,提取出主成分特征并构建新的数据集,再将数据随机打乱进行训练集和测试集的划分,两者比例为4∶1.
最后,分别建立Logistic回归、支持向量机(Support Vactor Machine,SVM)、决策树、梯度提升决策树(Gradient Boosting Decision Tree,GBDT)和随机森林模型进行方法对比,并使用网格搜索法寻求最优参数组合,利用精确率(Precision)、召回率(Recall)和F1值(F1-score)进行模型评价.
2.2 评价指标
本文选取精确率、召回率和F1值对模型的性能进行评价.精确率常用于衡量模型对正例样本的预测准确性,表示为正确预测为正的样本占全部预测为正的样本的比例,召回率常用于评价模型对于正例样本的识别程度,表示为预测为正的正例占全部真值为正例的样本的比例.为了能够直观地判断预测值与真实值之间的差异,引入如表2所示的混淆矩阵.

表2 混淆矩阵
其中xTP表示预测值为正例真值也为正例的真正例,xFP表示预测值为正例真值却为负例的假正例,xFN表示预测值为负例真值却为正例的假负例,xTN表示预测值为负例真值也为负例的真负例.根据混淆矩阵,可得精确率与召回率的表达式为

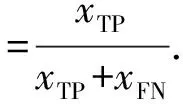
由于精确率和召回率间存在相互影响和相互制约的关系,无法达到理想状态下两个评价指标都高的情况,因此将F1值作为综合指标进行评价更加全面.F1值是对精确率和召回率取调和平均值,F1值越大,模型效率越高,分类预测效果越好.F1值的表达式为
2.3 实验结果与分析
实验对是否施加PCA特征提取的Logistic回归、SVM、决策树、GBDT和随机森林模型进行对比.对比结果如表3和表4所示.
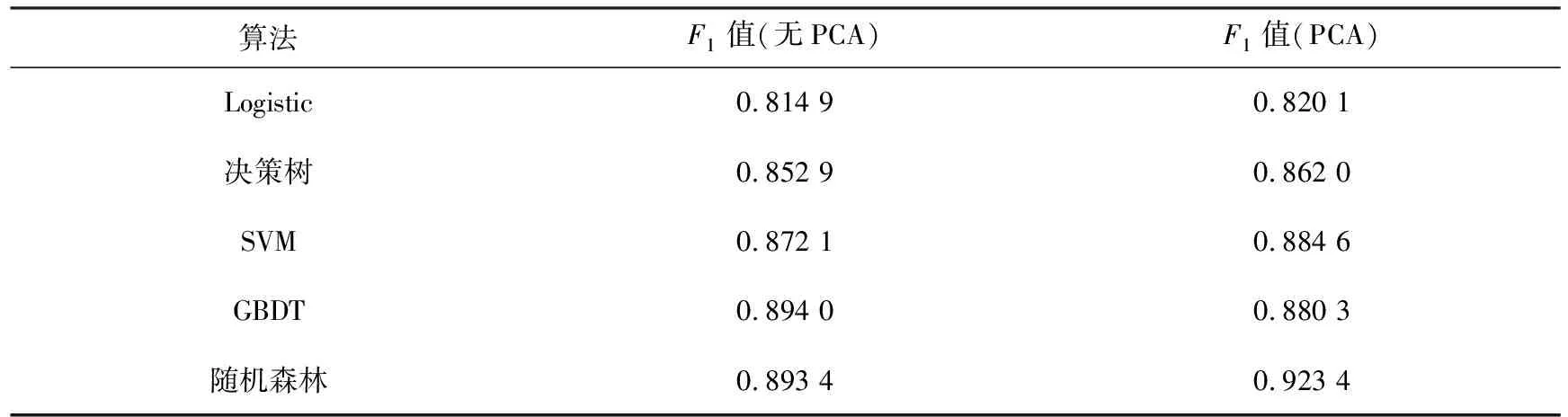
表4 不同模型F1值对比
根据表3可知,当不经过PCA特征提取处理时,GBDT和随机森林方法的精确率和召回率值较高且相差不大,说明模型对正例样本的预测准确度和识别程度较高.经过PCA特征提取处理后,随机森林方法的精确率和召回率最高,均大于0.92,相较于不经过PCA处理提升了2%,说明基于主成分分析的随机森林算法在正例样本的预测准确度和识别度上都有很好的表现.结合表4的结果可得,在经过PCA特征提取处理后,随机森林的F1值最大,相较于不经过PCA处理,有3%的提升,说明模型效率高,分类预测效果好,进一步确定了本文提出的基于主成分分析的随机森林算法有较好的效果.
对比表3和表4中五种算法在是否经过PCA特征提取处理的评价指标值可知,本文提出的基于主成分分析的随机森林算法与传统的分类算法和未经PCA处理后的各算法在精确率和召回率上都有较大提升,对分类效果有较好改善,进一步验证了算法的有效性.
3 结论
本研究引入特征提取和数据降维方法PCA、数据过采样算法SMOTE以及随机森林算法,提出一种基于主成分分析的随机森林钢材缺陷检测方法,用于钢材制造生产过程中不同缺陷的分类识别.通过实验分析,可以得到以下结论:(1)通过PCA进行特征提取处理,有效剔除冗余信息并降维,提高检测性能;(2)引入SMOTE进行数据扩充,弥补了数据类别分布不均衡的问题,对不同缺陷类型都能做到有效检测,提高检测效率;(3)与传统的四种分类方法相比,本文提出的基于主成分分析的随机森林算法得到的精确率、召回率和F1值均是最优的.因此本文提出的方法能有效提升缺陷检测效率.
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年19期)2018-11-14
电子制作(2018年16期)2018-09-26
自动化学报(2017年11期)2017-04-04
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
作文大王·笑话大王(2016年2期)2016-02-24
郑州大学学报(医学版)(2015年1期)2015-02-27
