
基于节点相似性的二阶链路预测方法
2024-02-21 06:00王嘉宾
软件导刊 2024年1期
刘 臣,王嘉宾
(上海理工大学 管理学院,上海 200093)
0 引言
现实世界中的很多复杂系统,如社交关系、交通运输、生物系统、信息系统等,都可以建模为网络。其中,将某个实体对象表示为节点,它们之间的交互关系表示为连边(或链接)。然而,由于收集数据时人为统计的失误或者数据本身有隐私设置等原因,构建的网络并不一定反映真实的数据,使得收集网络数据的完整结构变得尤为困难[1-2]。因此,根据观察到的网络信息预测缺失的节点或者链路是一项极为重要的工作,其对于补全相对完整的网络具有重要意义[3]。
链路预测的目的是根据观察到的链路和节点属性估计两个节点之间存在链路的可能性,如果两个节点彼此相似,则它们之间也更有可能存在链路。链路预测方法主要有三大类:基于相似性的方法、基于概率和最大似然的方法以及基于降维的方法。基于相似性的方法是基于邻域结构计算节点之间的相似度,分别从局部和全局的角度计算。局部相似度指标通常使用节点的近邻和节点度的信息进行计算,包括共同邻居指标(CN)[4]、优先链接指标(PA)[5]等,计算复杂度低,在聚类系数低的稀疏网络中很难得到高的准确率。全局相似度指标如Katz 指标[6]和SimRank 指标[7]是利用网络的整个拓扑信息进行计算,计算复杂度较高且不适用于大型网络。基于概率[8-9]和最大似然[10-11]的方法依赖网络的层次结构判断节点连边的可能性,操作复杂且耗时,不适用于真实的大型网络。面对高维度的难题,研究者将网络嵌入和矩阵分解技术作为降维技术,也将其用于链路预测。DeepWalk 和Node2vec 网络嵌入方法通过保留节点的邻域结构,将图中的高维节点映射到较低维度的表示空间[12-13]。Berahmand 等[14]将网络结构和节点属性相结合,引入新的链接预测随机游走模型用于解决属性网络中的链路预测。Menon 等[15]将结构链接预测问题建模为矩阵补全问题,并使用矩阵分解进一步求解。
链路预测在不同的网络类型中都有相应研究,在不同的领域也都有成熟的应用,例如在社交网络中从大量的注册用户中为单个用户自动推荐熟人;在科学合作网络中预测哪些作者或团体在未来可能合作,以更好地了解一些研究领域的发展情况。这些研究针对两个节点之间是否存在链路展开,本文探讨网络中的二阶链路该如何预测,在计算节点对之间的相似性时,识别一个中间节点,同时预测涉及中间节点的两条链接。本文学习基于相似性的链路预测算法,提出了一种基于节点相似性的二阶链路预测方法,用于为用户或者合作者双方找到可以实现通信的第三方,还可以在社交网络中为两个本不相识的用户识别出可能各自与他们相熟的目标用户,为双方用户搭建沟通的桥梁。一个更有意义的工作是监控恐怖主义网络中的隐藏关系[16],推测不同的恐怖分子或团体是经由哪一个团体或个人联络,即使他们之间的交互没有被直接观察到,以据此做好安全防范工作。
在链路预测中,一个相当大的挑战是数据稀疏性。如果网络中的数据过于稀疏,则无法从简单的公共邻居数量或其他相关变体指标中提取出有价值的相似性信息[17],此时只考虑局部信息可能会导致较差的预测。顾秋阳等[18]使用高阶路径作为判别特征对复杂网络中的缺失链接进行有效预测;LYU 等[19]使用较长的路径(长度大于2 的路径)度量节点相似性。但由于涉及高阶信息,计算过程中会产生很多噪声,不利于相似度计算。Liao 等[20]发现基于相关性的方法在计算基于高阶路径的相似度时非常有效,不会受噪声影响,进一步与资源分配方法相结合,对稀疏网络和密集网络都适用。目标网络的稀疏性会导致一个问题,即一条链路的先验概率通常都很小,很难建立统计模型。与传统的链路预测任务不同,本文提出在网络中实现二阶链路预测,为一对已知节点识别中间节点并补全二阶链路。本文构造新的计算指标用于识别节点,并构建了一个二阶可达网络以筛选可能的节点,一方面减小了计算复杂度,另一方面也缓解了数据稀疏性。利用邻接矩阵构造二阶可达矩阵,记录网络中的二阶链路信息。相比于原始网络中传达的一阶信息,二阶可达矩阵所对应的二阶可达网络保留了原始网络中所有的二阶链路,有助于实现本文的二阶链路预测。
1 问题描述
令G=(V,E)表示无权无向网络,V是网络G中节点的集合,节点数为|V|,E是网络G中边(或链接)的集合,边数为|E|。将不相连的节点对vi与vj记为(vi,vj),节点对之间的相似性定义为sim(vi,vj),该值越大,节点对之间越有可能存在链接。因此,可以将sim(vi,vj)看作节点对之间是否存在链接的评分。网络G的链接用邻接矩阵A表示,当节点vu与vw之间存在链接时,邻接矩阵中的元素auw值为1,否则为0。如果节点vu和vw之间存在链接,则这两个节点互为邻居节点,称vu和vw之间是一阶可达的。如果节点vu和vw不直接相连,存在节点vk使之形成二阶链路vu-vk-vw,则称vu和vw之间是二阶可达的,互为二阶邻节点。
二阶链路预测任务通过在一对已知节点的二阶邻域交集中确认最有可能分别与节点对存在链路的同一个节点身份,实现已知节点对之间的二阶链路预测。如图1 所示,在可观测节点集{v1,v2,v3,v4,v5,v6,v7,v8}中,v1的二阶邻域节点集为{v3,v5,v8},v6的二阶邻域节点集为{v3,v8}。从节点对(v1,v6)的二阶邻域交集{v3,v8}中比较它们各自与节点v1、v6的相似性,如sim(v1,v3),sim(v3,v6),若与v1、v6均有较大相似性的节点为v3,则可以确认v1、v6之间的一条二阶链路为v1-v3-v6。
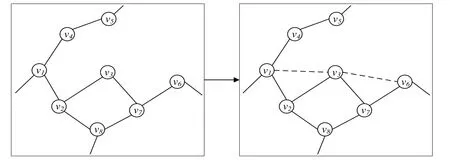
Fig.1 Second-order link prediction task图1 二阶链路预测任务
2 网络中的二阶链路预测
本文利用节点相似性进行二阶链路预测,首先将目标节点的搜索范围缩小至节点对的二阶邻域,然后基于相似性指标sim(vi,vj)进行加工,求得与节点对均有很高相似度的节点,以确认目标节点的身份,从而实现二阶链路预测任务。图2描述了网络中的二阶链路预测过程。
2.1 二阶可达网络
当网络中的部分链接不被观察到或网络中的部分链接被去除,剩下的网络结构偏向于稀疏图,这不利于提取节点的邻居信息,因此首先处理数据稀疏问题。网络中的链接用邻接矩阵A表示,对邻接矩阵A进行变换操作,得到矩阵A2,其中每个元素就是节点vi和vj之间长度为2 的路径的数目。将其对角线元素置0,非零元素的数值替换为1,得到一个0-1 矩阵,称之为二阶可达矩阵。也即当节点对vi与vj之间存在二阶链路时,二阶可达矩阵中的元素值为1,否则为0。根据二阶可达矩阵所描述的节点间的链接信息构建新的无向网络,称之为二阶可达网络G'。
本研究主要介绍了组合可调式Halo -骨盆固定支具的设计及初步临床应用结果,仍存在一些不足:①样本量少,尤其是针对结核性脊柱后凸畸形方面需要进一步积累临床病例;②缺乏与其他类型脊柱牵引技术的对照研究;③Halo -骨盆固定支具刚性牵引作用力大,容易导致盆针切割及变形,盆针的穿针方式、牵引策略及器材设计有待进一步改善。
当一对节点是二阶可达,但它们之间的链路不被检测到时,中间节点的身份是未知的。受基于相似性的链路预测算法启发,两个存在链接的节点相似性必定极高,且它们之间存在公共邻居节点,则目标节点与已知节点在网络中可能是二阶可达的。因此,可以从已知节点对的二阶可达节点集的交集内找到目标节点,而候选目标节点的集合在二阶可达网络中可见。
2.2 二阶链路预测指标
当去除网络中的一部分链接时,网络变得稀疏,由于基于节点局部信息的相似性指标不能计算没有共同邻居的节点之间的相似性[17],因此链接预测指标在稀疏网络中很难得到高的准确率。为了解决这一不足,本文考虑将目标节点的搜索范围放在二阶可达网络内,不仅降低了计算复杂度,而且预测准确率也在一定程度上得以提高。在网络中分别与节点vi、vj存在链路的节点很有可能不止一个,是否为同一个目标节点还需作进一步判断。本文拟在可能与节点vi或节点vj存在链路的多个节点中,找到可能同时与节点vi、vj存在链路的目标节点。
基于节点相似性,本文提出二阶链路预测指标,用于在已知节点对的二阶邻域内寻找公共一阶邻节点。指标如下:
其中,sim(x,y)是度量节点相似度的一个指标,评分值越大,节点对之间存在链路的可能性越大,它可以是任意一个普通的链接预测指标。Γ2(vi)指节点vi的二阶可达节点集,v是vi、vj的二阶可达节点集交集中的节点。
2.3 基础链路预测指标
基于节点局部信息的相似性指标如CN 指标、AA 指标、RA 指标、PA 指标可以计算节点间的相似度,因此借助这类指标完成二阶链路预测任务。
CN(Common Neighbors)指标即共同邻居指标,基于共同邻域大小度量节点间的相似性,如果两个未知链接的节点i和j共同的邻居越多,则它们之间产生链接的可能性就越大[4]。相似度计算如下:
其中,Γ(i)为节点i的邻居节点的集合;Γ(j)为节点j的邻居节点的集合。
其中,kz为节点z的度数。
JC(Jaccard Coefficient)指标是基于CN 指标,考虑节点度的影响所产生的同样基于共同邻居思想的相似性指标。
AA(Adamic-Adar)指标在CN 指标的基础上考虑了共同邻居间的权重差异,认为共同邻居的节点度越小,对相似度的贡献越大,为度较小的邻居节点分配更高的权重[22]。
PA(Preferential Attachment)指标认为节点i和j产生新链接的可能性与节点度的乘积成正比[5]。
2.4 样本构造
针对网络中满足最小度为4 的目标节点,按一定比例剔除一部分与之相连的链接,将被剔除链接的目标节点之外的节点两两组合构造正节点对。在网络的二阶可达矩阵中,节点度大于2 且元素值为0 所对应的节点对为负节点对。
3 实验与结果分析
3.1 数据集
本文使用4 个真实网络的数据对二阶链路预测算法性能进行评估。Cora 是一个引文网络,其中节点代表机器学习方面的论文,只有当其中一篇论文被另一篇论文引用时,两篇论文之间才会形成一条边缘,该网络由2 708 个节点和5 429 条边组成。Citeseer 同样是引文网络,由3 312个节点和4 715 条边组成。Washington 和Texas 包含两所大学网站中的网页引用,节点和边分别代表网页和网页之间的引用。Washington 由230 个节点和446 条边组成,Texas 由187 个节点和328 条边组成。4 个网络的统计信息如表1所示。

Table 1 Statistical information of four networks表1 4个网络的统计信息
3.2 实验相关设置
3.2.1 参数设置
每次独立实验中,去除目标节点的链接比例为0.2,将数据集按照0.7、0.1、0.2 的比例划分为训练集、验证集和测试集。
3.2.2 评估指标
由于随机因素的存在,根据二阶链路预测指标计算得到的最大指标值所对应的节点并不一定是真正缺失的目标节点。Liben-Nowell 等[23]通过几个相似性度量提取两个节点之间的相似性。根据这些相似性为每对节点分配排名,然后将排名较高的节点对指定为预测链接。因此,本文将得到的计算指标由大到小排序,对应得到一系列可能的缺失节点{v1,v2,v3,…}。为了验证该指标的有效性,给定一个阈值,设置为k,在这一系列节点的前k个节点中检验是否真正找回目标节点并关注找到节点的精确率,进而评判该指标的预测性能。
本文采用的评估指标是AUC 和Precision,AUC 用于评估是否识别到缺失的链路,Precision 用于评估在阈值内识别到真实目标节点的精确度。AUC 在链接预测中的定义为从测试集和负样本中各随机取一条链接,比较这两条链接的分数。假设在n次独立比较中,测试集中的链接比负样本中的链接拥有更高分数的次数为n1,两者拥有相同分数的次数为n2,则AUC 的计算公式为:
精确率(Precision)指在识别为真链接的样本中真正是真链接的样本所占比例,精确率越高,说明模型效果越好。
3.3 结果分析
本文基于普通链路预测算法的相似性指标,利用RA、JC、AA、PA 这4 项指标作为基准链路预测指标帮助实现本文提出的二阶链路预测方法,并在4 个真实网络中检验其效果。表2 和表3 分别列出了相应的AUC 值和Precision值,其中每个网络的最优值用加粗表示。由表2 可知,各项基准指标在Citeseer 网络上均表现良好;JC 指标和PA 指标可以分别在其中两个网络上实现较好的性能。在Washington 和Texas 网络中,JC 指标相比其他指标得到的AUC值提升了0.29%~17.15%;在Cora 和Citeseer 网络中,PA 指标相比其他指标得到的AUC 值提升了1.92%~2.05%。但相比而言本文提出的方法在Texas 网络上表现并不好,在Washington 网络上的表现也不显著,这与网络本身的结构有关。当网络规模较小时,按一定比例剔除部分链接会使网络结构发生很大改变,容易造成采样不充分,因此在这样的网络上进行二阶链路预测任务效果并不好。

Table 2 AUC values of four networks表2 4个网络中的AUC值

Table 3 Precision values of four networks表3 4个网络中的Precision值
由表3 可知,将每对节点所得的计算指标做排序之后,各项基准指标均可以在候选目标节点集的前两位中找到最优节点,说明它们的预测性能较好。其中,4 项基准指标在Cora 网络中均呈现出较高的精确率,因此可以推测本文的二阶链路预测方法在Cora 这样的大规模网络结构中有不错的表现。而Citeseer 网络中的精确率较低,与表2中的AUC 结果不相符合,原因可能在于AUC 是从全局考察预测方法的性能,而Precision 是从几条链接中检验预测精度,二者评价任务不一样。综合而言,该方法在Citeseer 网络中的表现依然不错。
为了进一步说明构建二阶可达网络以缓解数据稀疏性对本文所提方法的必要性,本文从所用数据集的网络密度角度对各网络上的表现进行比较分析。首先,一个包含N 个节点的网络的密度ρ 是指网络中实际存在的边数M与最大可能的边数之比。对于无向网络,网络的密度ρ有:
本文数据集所对应的网络密度如表1 所示,可见稀疏度的关系表现为:Citeseer > Cora > Washington > Texas,因此本文选择在稀疏度上有所区分的前3 个网络上根据AUC 指标值评估该方法的性能,实验结果如图3所示。

Fig.3 Changes of AUC value under different indicators图3 不同指标下的AUC值变化
在各项基准指标下,稀疏度最大的网络Citeseer 保持最优的AUC 值,稀疏度中等的Cora 次之,稀疏度最小的Washington 网络AUC 值最低。由此可见,网络稀疏度越大,该方法的性能越好,因此本文所提出的方法相对适用于稀疏度较大的网络。
为了探索训练集比例对预测效果的影响以及各项指标的相对表现,本文在Cora 和Citeseer 网络上作了进一步探究。图4 给出了训练集比例从0.4 增长到0.7 时,Cora 和Citeseer 网络中基于不同基准链路预测指标的AUC 值变化。在Cora 网络中,AUC 值初始呈上升趋势,是因为训练集比例增加能够提供更多的训练信息,从而提高了AUC值。随着训练集的增加,测试集会相应减少,当训练集的比例增加到一定程度,在测试集中获取链接的概率会降低,因而不易找到缺失的二阶链路,故AUC 值会下降。在Citeseer 网络中,AUC 值初始呈下降趋势,是因为此时并没有在训练集中学到有用信息,而中间上升的值说明开始在训练集中学到有效的训练信息,并表现出来;之后,AUC 值表现出下降趋势同样是因为训练集增加到一定程度,在测试集中获取链接的可能性会减小。此外,网络本身的结构特征(度数)在各项基准指标中占据着不一致的重要性,因此AUC 值在不同基准指标上的表现会有所差异。
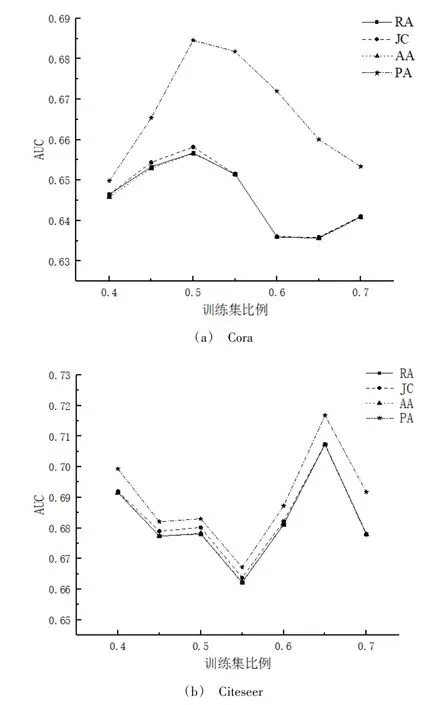
Fig.4 Changes of AUC value when ratio of training set increases from 40% to 70% in Cora and Citeseer network图4 Cora和Citeseer网络中训练集比例由40%增加到70%时AUC的变化
4 结语
本文提出了基于节点相似性的二阶链路预测方法,并构造了二阶链路预测指标以识别节点对的中间节点,然后补全节点对之间的二阶链路。该方法可以结合RA、JC、AA、PA 4 项相似性指标加以实现,为了验证各指标性能及方法的有效性,分别在4 个真实的网络数据上进行了实验。结果表明,此方法在稀疏度较大的网络上会表现出相对更好的性能,在AUC 和Precision 指标上表现良好,能够精确地预测到所丢失的链路。下一步研究的重点是在基准预测指标上找到更加合适的搭配,比如基于节点的嵌入向量等,同时期待能够在更普遍的网络上发挥该方法的作用。
猜你喜欢
纺织科学研究(2023年9期)2023-10-23
数学物理学报(2022年5期)2022-10-09
移动通信(2021年5期)2021-10-25
河北画报(2020年8期)2020-10-27
应用数学(2020年2期)2020-06-24
数学物理学报(2018年6期)2019-01-28
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
浙江大学学报(工学版)(2016年2期)2016-06-05
中国交通信息化(2014年3期)2014-06-05
