
基于可解释机器学习模型的南宁市野火灾害易发性研究
2024-02-20 01:28岳韦霆任超梁月吉郭玥张胜国
科学技术与工程 2024年2期
岳韦霆, 任超,2*, 梁月吉,2, 郭玥, 张胜国
(1.桂林理工大学测绘地理信息学院, 桂林 541006; 2. 广西空间信息与测绘重点实验室, 桂林 541006)
野火灾害是指由自然或人为引起,在林地内自由蔓延、扩大,并造成一定危害和损失的林火行为[1]。近年来,由于气温升高、降雨减少、旱期延长等异常气候因素以及人类活动的干预,导致野火灾害的发生频率增加。野火不仅对环境、生态和经济造成重大破坏,而且对人类生命和财产造成严重威胁[2]。近年来,南宁市发生了多起野火灾害。其中,2021年11月29日,南宁市兴宁区五塘镇增山坡尖山岭发生了一起重大野火灾害,过火面积约为500亩(1亩=667 m2),烧毁了周边大量植被,严重威胁了周边林场、水库和村庄的安全,并造成了巨大的经济损失。因此,开展南宁市野火空间易发性评价,进而制定有效的防火和治理措施变得极其重要且迫切。
早在20世纪20年代,中外就林火发生预测预报开展了大量的研究工作[3]。此后的研究表明,多种环境和人为因素均可能是引发野火灾害的原因[4]。由于不同地域的建模指数的权重和变量可能不同,因此为找出对该地区野火发生具有重要影响的因子,其相关研究考虑的环境和人为因素数据也不尽相同[5]。自Roger等[6]提出了“地理信息系统” (geographic information system,GIS)概念后,极大方便了基于数据驱动的灾害风险评估工作的开展。现常用的数据驱动模型分为频率比[7]、证据权[8]等统计学模型,逻辑回归[9]、随机森林[10]等机器学习模型。其中,机器学习模型较统计学模型能更好地拟合数据样本,更适合用于灾害易发性研究中[11]。高博等[12]基于Logistic回归模型建立大兴安岭地区的林火预测模型,并对其影响林火发生的主要驱动因素进行评估分析。蔡霁初等[13]利用Logistic回归和随机森林算法对广东省的林火发生概率进行预测,发现随机森林算法的预测性能更优。Rodrigues等[14]利用多种机器学习模型对西班牙半岛的野火易发性进行研究,发现随机森林模型的预测性能最佳。Rafaqat等[15]利用5种机器学习算法评价巴基斯坦的野火灾害易发性并对关键影响因素进行分析。
综上所述,现阶段对野火易发性的研究主要集中于算法及模型的改进,以改善预测精度。虽然机器学习模型在处理非线性问题上有很大的优势,但它本质上是一个黑箱模型,欠缺可解释性,其只考虑因子间的全局相对重要性,无法对野火易发性预测结果进行全面的评价[16]。因此,需要一种客观的可解释方法,找出影响野火灾害发生的关键因子,并阐明模型的决策机制,帮助野火风险防控工作者更好地理解野火易发性的评估结果。沙普利加和解释(shapley additive explanations,SHAP)作为最新的可解释性方法之一,其通过因子间的协同交互作用反映每个样本的每个特征的影响力,具有高度的归因一致性[17]。
鉴于此,现以南宁市为研究区,以2012—2022年11年内的野火样本为数据基础。综合考虑区域内的野火空间分布特征,从土壤地形、植被覆盖、水文气象等方面选取评价因子。采用分类和回归树、随机森林、轻量的梯度提升机和极致梯度提升4种具有良好预测性能的机器学习算法构建野火易发性模型。同时,使用SHAP可解释性方法在全局和局部维度上,对所构建的最优野火易发性模型进行机理解释和特征分析,为南宁市野火灾害的急防治措施及治理工程规划提供科学依据。
1 研究区及数据概况
1.1 研究区与历史火点数据
南宁市位于广西壮族自治区南部偏西,地处107 °45′~108 °52′E,22 ° 13′~23 °33′N,高程为19~1 745 m(图1)。全域总面积约为22 100 km2,占广西总面积的9.31%。南宁市属湿润的亚热带季风气候,阳光充足,雨量充沛,年平均气温在21.6 ℃左右,年均降雨量达1 304.2 mm。其良好的水、热条件孕育着丰富的植物资源。近年来,南宁市野火灾害频发,对当地的社会经济和生态环境造成严重的威胁。
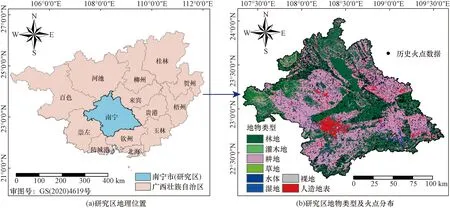
图1 研究区及历史野火分布情况Fig.1 Study area and historical wildfire distribution
地球观测卫星为探测和监测活跃火灾提供了宝贵的数据,目前常用的基于卫星的主动火灾探测产品是全球范围内的消防信息资源管理系统(fire information for resource management system,FIRMS)火灾信息[18]。本文研究选用具有375 m的空间分辨率的VIIRS(S-NPP)火灾产品,其在相对较小的区域内对火灾有更好的响应,并改善了夜间性能[19]。由于本研究对象为南宁市内的野火灾害,因此需对所获取的数据进行筛选。首先,在FIRMS官网(https://firms.modaps.eosdis. nasa. gov/)获取2012—2022年内的历史火点数据,并筛选除南宁市范围内的数据;然后,依据“Type”和“Confidence”属性字段将置信度等级为“Low”的不合格数据,并只提取数据属“假定的植被火灾”的火点数据;最后,依据地表覆盖类型数据,筛除位于“人造地表”“裸地”和“水体”的非目标样本;最终共获取到9 988个属单独栅格的历史野火样本。
1.2 评价因子数据概况
地形、气候、人文和植被等因素均可能影响野火灾害发生的概率。在全面考虑南宁市野火灾害空间分布特征的前提下,从土壤地形、气象水文、人类活动和植被覆盖情况方面选取18项评价因子,进行野火易发性评价研究。数据来源如下。
(1)数字高程模型(digital elevation model,DEM)数据,用于提取高程、坡度、坡向、平面曲率、剖面曲率、地形湿度指数(topographic wetness index,TWI)和水流强度指数(stream power index,SPI)。
(2)ERA5-Land再分析数据,用于提取平均气温、平均风速(U分量)、平均风速(V分量)和平均风速。其中,风速U分量表示东西向风速,西风为正;风速V分量表示南北向风速,南风为正;平均风速由风速U分量和V分量的平方和并开根而计算得到。
(3)全国地理信息资源目录服务系统(https://www.webmap.cn/),用于获取道路和河流矢量文件。
(4)Landsat 8光学影像,用于提取地表归一化植被指数(normalized difference vegetaion index,NDVI)。
(5)CHIRPS降雨量产品,用于年均降雨量。
(6)GlobeLand30 V2020产品(http://www.globallandcover.com/),用于提取2020年地物类型数据。
(7)世界土壤数据库(https://www.fao.org/soils-portal/soil-survey/),用于提取地表土壤类型数据。
(8)WOPR产品(https://hub.worldpop.org/),用于提取2020年人口密度分布。为统一因子数据分辨率,以DEM栅格为基准,将各因子影像投影至UTM_Zone_49N坐标系,并重采样至30 m×30 m分辨率。整个研究区可划分为7 947×6 891,共24 566 450个栅格。研究区各评价因子信息如图2所示。
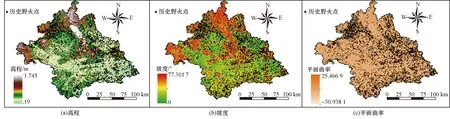
图2 评价因子概况Fig.2 Overview of assessment factors
2 研究方法
2.1 机器学习模型
使用4种已被证明并广泛适用于研究二项式因变量的机器学习算法,以构建野火易发性模型,其分别为分类和回归树(calssification and regression tree,CART)、随机森林(random forest,RF)、轻量的梯度提升机(light gradient boosting machine,LGBM)和极致梯度提升算法(extreme gradient boosting,XGBoost)。
CART是一种递归分区方法,它最显著的优势在于可以处理异常值和缺失值的问题。CART模型更适合处理各种类型的数据,因为它能够应对输入和输出参数之间相关性事先未知的问题,同时其输出结果也更容易被理解和解释[20]。
RF是由许多单独训练的决策树组成的集成模型[21],其基本原则是在每棵树的每个节点上选择一个随机的特征子集;使用bagging选择用于训练每个组件树的样本,并对原始数据集进行重新采样。RF模型中的每个分量决策树都会做出分类决策,从而确定具有最多票数的类作为输入数据的最终分类。该模型可用于解决回归问题,最终输出由每棵树的输出平均值来确定[22]。
LGBM是一种新颖的基于树的梯度提升算法,其涉及两个过程:①基于梯度的单侧采样;②通过分组相互排斥的特征,有效地减少特征的数量[23]。在数据样本可变维数较高、数据规模较大时,具有效率高、支持并行、占用GPU内存小、数据处理规模大的优点。
XGBoost是一种基于梯度提升算法的优化扩展算法。其通过梯度下降法以弱分类树的提升集成的形式生成一个预测模型,以优化损失函数[24]。XGBoost使用多个CART,并使用梯度提升方法将它们集成。该模型有三个重要的方面:正则化目标函数用于更好地泛化;梯度树提升用于相加训练;收缩和列下采样用于防止过拟合。
2.2 性能评价指标
对于野火易发性模型的预测性能的评价,通常由多个不同维度的指标决定。本研究使用受试者工作特征(receiver operating characteristic,ROC)曲线极其曲线下面积(area under curve,AUC),混淆矩阵以及均方根误差(root mean square error,RMSE)评价各模型的预测性能。ROC曲线通常用于直观地评估基于二项式因变量模型的预测性能,其AUC值越高,ROC曲线偏离对角线越多,模型分类的性能越好。当AUC>0.9时表示模型的整体性能优秀。混淆矩阵是分类性能的汇总。总体预测精度(accuracy)、灵敏性(sensitivity)、特异性(specificity)和Kappa系数(Kappa coefficient,KC)均由混淆矩阵计算得到。此外,通过计算野火样本(1)、负样本(0)和全部样本(All)的预测结果与实际属性的RMSE值,以评估模型的预测误差。上述指标的计算公式为

(1)
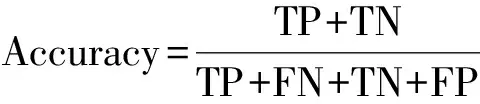
(2)
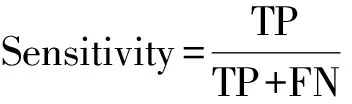
(3)
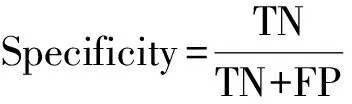
(4)
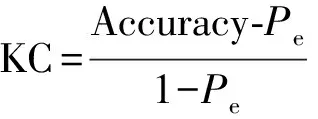
(5)
(6)
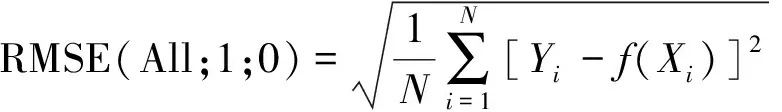
(7)
式中:TP和FN分别为正样本预测正确和预测错误的数量;TN和FP分别为负样本预测正确和预测错误的数量;Accuracy为总体预测精度;Pe为模型随机预测的概率;N为验证样本总数;Yi和f(Xi)分别为第i个样本的实际值和预测值。
2.3 SHAP可解释性方法
SHAP是一种解释机器学习模型预测结果的方法,核心是计算每个特征对于模型预测结果的贡献度[25]。其基于博弈论中的Shapley值思想,通过计算每个特征对于模型预测结果的Shapley值,将其转化为特征重要性。分析结果可以帮助我们了解整个数据集中每个特征对于模型预测结果的影响程度(方向和力度),并帮助我们识别出哪些特征对于模型的预测结果具有重要影响。由于其在理论上的可解释性,SHAP方法在解释黑盒模型中得到了广泛的应用。Shapley的计算公式为
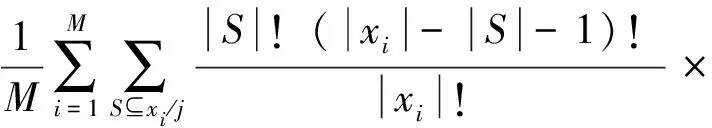
(8)
式(8)中:xi为第i个样本;j为其中一个特征;S为不包含特征j的特征子集;fS(xi)为去掉特征S后的模型预测输出;fS∩j(xi)为加入特征j后的模型预测输出;M为样本数。
Shapley值的含义是:特征j对于样本xi的预测输出的贡献,等于将特征j加入或移除后,与不考虑特征j时的预测输出的差异,乘以考虑j时的样本子集的权重,最后再取平均。本文研究利用SHAP方法在全局和局部为维度分析特征对野火易发性预测结果的作用方向和贡献程度。
2.4 研究流程
综上,基于4种机器学习模型构架南宁市野火易发性模型,并利用SHAP可解释方法在全局和局部维度对最优野火易发性模型的预测结果进行解释分析。实验流程如图3所示。
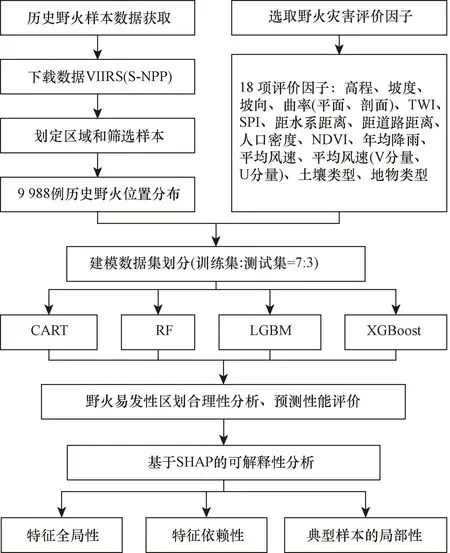
图3 研究路线Fig.3 Research route
具体步骤为:①数据集构建,包括历史野火样本获取和筛选,野火易发性评价因子的获取和处理;②利用4种机器学习模型构建4种南宁市野火易发性模型,并根据易发性区划合理性和预测性能选取最优模型;③基于SHAP可解释方法对最优预测模型进行特征全局性解释、特征依赖性和典型样本的局部性分析。
3 野火灾害易发性评价
3.1 野火易发性预测模型的构建
以南宁市历史野火点作为正样本,将野火散布密度较大的地区剔除获取负样本选取区域。运用ArcGIS 10.2的“创建随机点”工具,随机选取与历史野火样本数量相等的9 988个负样本数据。将正样本属性赋值为“1”,表示发生野火;将负样本赋值为“0”,表示不发生野火。整合正负样本数据组建样本数据集,将其样本点所在的各个因子的属性提取至样本点,按照7∶3的比例随机划分训练集和测试集。选用训练集样本构建模型,将样本的因子属性值作为输入,样本属性作为输出。此外,选取未参与模型构建的2 976个正样本和3 017个负样本,检验模型的预测稳定性和泛化能力[26]。利用10折交叉验证法对各模型的超参数进行调整,以获取良好的预测结果,参数调节结果如表1所示。
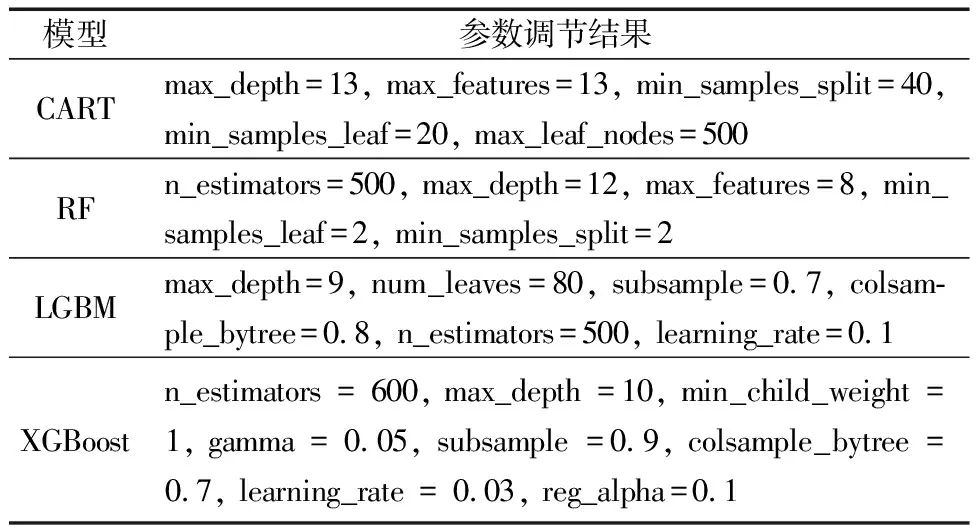
表1 参数调节结果Table 1 Parameter adjustment results
3.2 野火易发性区划合理性分析
为对比不同模型间的预测结果,统一按照[0,0.20],(0.20,0.40],(0.40,0.60],(0.60,0.80]和(0.80,1.0]作为分级标准,将4种模型在研究区内的野火易发性概率划分为极低、低、中、高和极高5个易发性等级,如图4所示。可见,基于不同模型的野火易发性区划结果的分布规律相似,极高易发区主要分布在研究区西北部、东部及南部;极低易发区主要分布在北部、西部和西南部。各模型的区划结果均良好地反映了南宁市野火易发地区的分布特征。
各模型易发性区划结果的详细统计信息如表2所示。CART、RF、LGBM和XGBoost模型的极高易发区面积占比分别为42.717%、38.570%、39.426%和39.113%。其中,历史野火数量占比分别为73.690%、70.968%、73.421%和73.690%。可见,XGBoost模型在较少的区域内拥有更多的野火样本。根据不同野火易发性等级区域的频率比可知,所有模型的频率比均随着易发性等级的增大而增大。其中,相较于其他模型,XGBoost模型的极低易发区的频率比更低(0.154),极高易发区的频率比更高(1.884),说明该模型的野火易发性区划结果对野火样本的拟合程度更好,区划结果更为合理。
3.3 预测性能分析
样本数据在不同易发区的占比只能反映模型在特定阈值条件下的预测精度,考虑到ROC曲线不受阈值的影响,并可以清晰表示野火发生的累计百分比与野火易发性指数之间的关系[27]。因此,使用ROC曲线评价不同模型间的整体性能和泛化能力。如图5所示,CART、RF、LGBM和XGBoost模型的ROC曲线的AUC值分别为0.925、0.954、0.956和0.959,其值均大于0.900,表明各模型均具有优秀的预测性能。其中,XGBoost模型的AUC值最高,表明该模型的整体预测性能优于其他模型。
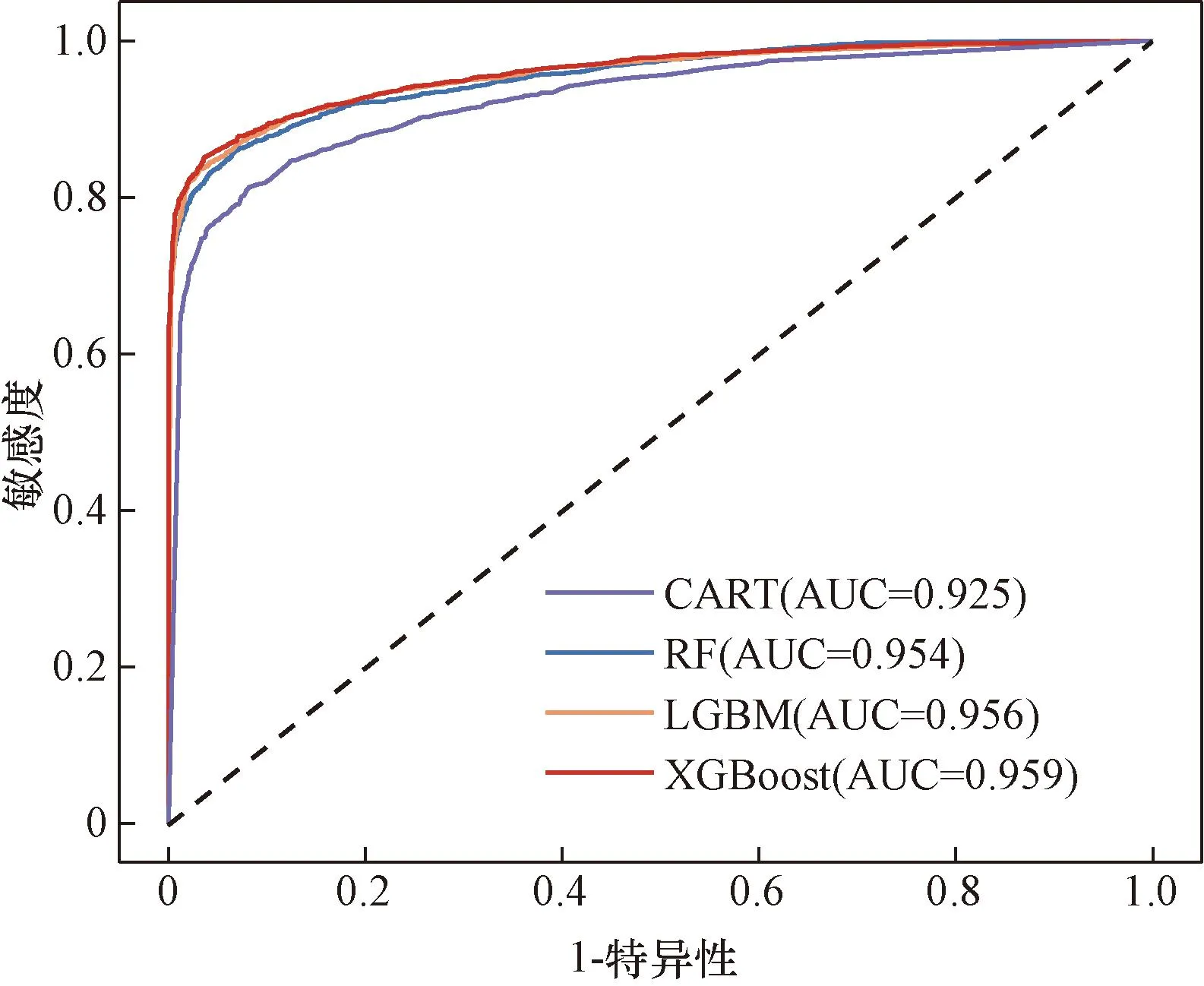
图5 ROC曲线Fig.5 ROC curves
在验证模型的整体性能的前提下,使用多个指标评价各野火易发性模型对野火样本的预测精度,如表3所示。在4种模型中,CART模型对正负样本的预测准确率最低,总体预测精度为0.861。RF模型对正负样本的预测准确性均较高,总体预测精度为0.902。LGBM模型对野火样本的预测准确性最好,而对负样本的预测准确性相对较差,总体预测精度分别为0.899。XGBoost模型在保证拥有野火样本拥有良好的预测精度的同时,对负样本预测准确性最高,总体分类精度为0.906,Kappa系数为0.812,说明XGBoost模型对野火样本的区分效果更高,具有更高的可靠性。此外,XGBoost模型的RMSE-All、RMSE-1和RMSE-0值相较于其他模型更低,说明XGBoost模型对野火样本、负样本和所有样本的预测误差均最小,预测情况更贴近真实情况。
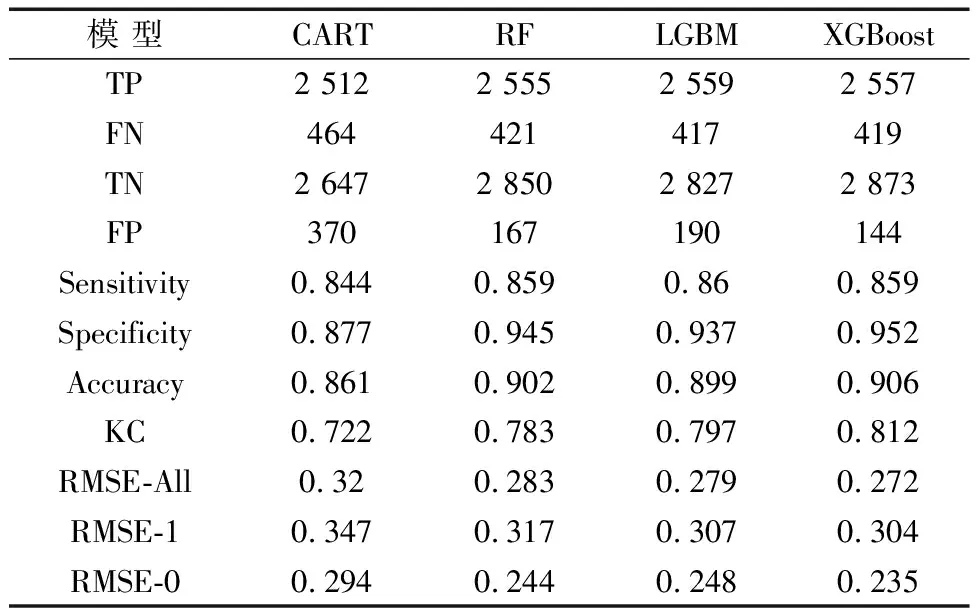
表3 性能评价结果Table 3 Performance assessment results
总的来说,XGBoost模型的预测性能最优,LGBM和RF模型次之,CART模型的预测性能相对最差。
4 SHAP解释性分析
通过上述对CART、RF、LGBM和XGBoost模型的野火易发性区划结果合理性和样本的预测性能的分析结果可知,基于XGBoost模型取得的野火易发性评价结果相较于其他模型更好。因此,利用基于数据驱动的SHAP可解释性方法对XGBoost模型的野火易发性决策机理进行解释分析。
4.1 特征全局性解释
图6显示了各个因子对野火易发性预测结果的作用方向和重要性程度。图6(a)绘制了每个样本的每个因子的Shapley值,x轴显示了Shapley值,值越大表示因子对该样本预测结果的影响越大,正值表示具有正向影响,负值表示具有负向影响;y轴每一行表示一个特征。每个点表示数据集中的单个样本,点的颜色表示给定条件因子的值,红色表示相应因子的属性高值,蓝色表示属性低值。例如,NDVI值较大时,Shapley值普遍较大,表示植被覆盖率的增大有利于野火灾害的发生;风速值较大时,Shapley值较小,表示在该地区较小的风速会增加野火发生的可能性。对于连续型因子,NDVI、降雨、气温、风速(U分量)、距道路距离和SPI等因子对野火易发性预测结果起不同程度的正向影响;风速(V分量)、风速、距水系距离、人口密度和TWI等因子起不同程度的负向影响。对于离散型因子,酸性土壤(Ach、Acf、Acu等)较其他土壤类型对野火有较强的促进影响;林地、草地较其他地物类型更易发生野火灾害。
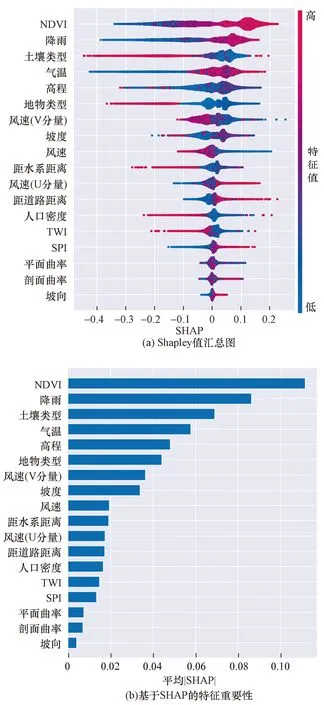
图6 特征全局性解释结果Fig.6 Global interpretation result of features
对图6(a)中每个样本的Shapley绝对值取平均值,得到因子重要性排序结果,如图6(b)所示。模型中对南宁市野火易发性预测影响最重要的因素有NDVI、降雨、土壤类型、气温、高程、地物类型、风速(V分量)、坡度和风速因子,其余9项影响因子对野火易发性的影响程度较小。
4.2 特征依赖性分析
特征依赖性分析可以显示单个或两个特征对模型预测结果的边际效应。单依赖性分析描述了单个因素对野火易发性预测结果的影响;双依赖性分析描述两个因子在交互作用下对预测结果的影响[28]。如图7所示,对模型中最重要的9项因子进行单依赖性分析。图8描述了NDVI与其余因子的交互作用对野火易发性预测结果的影响。联合图7和图8进行分析可得如下结果。
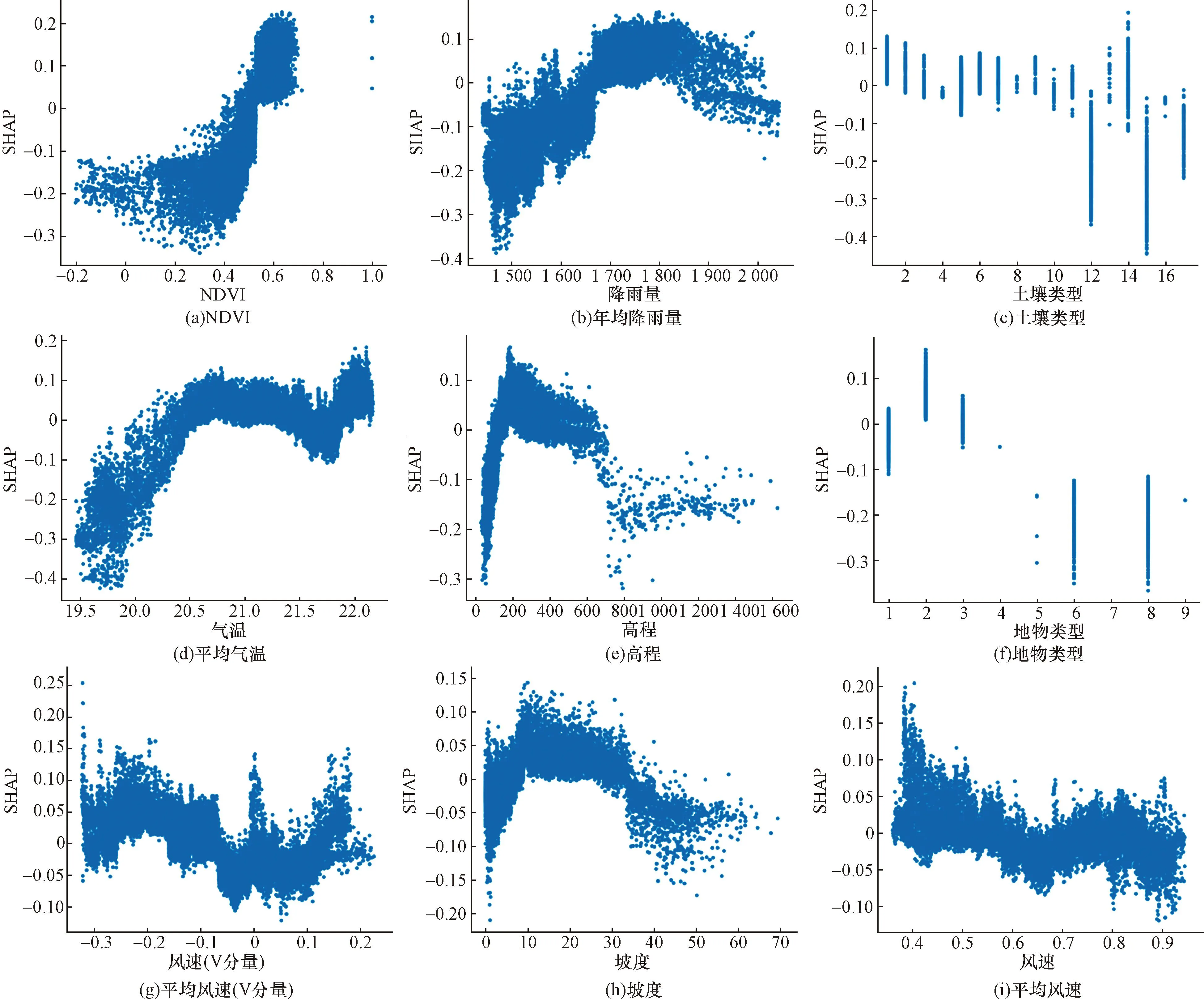
图7 主要影响因子的单依赖性结果Fig.7 Single-dependent results of main influencing factors
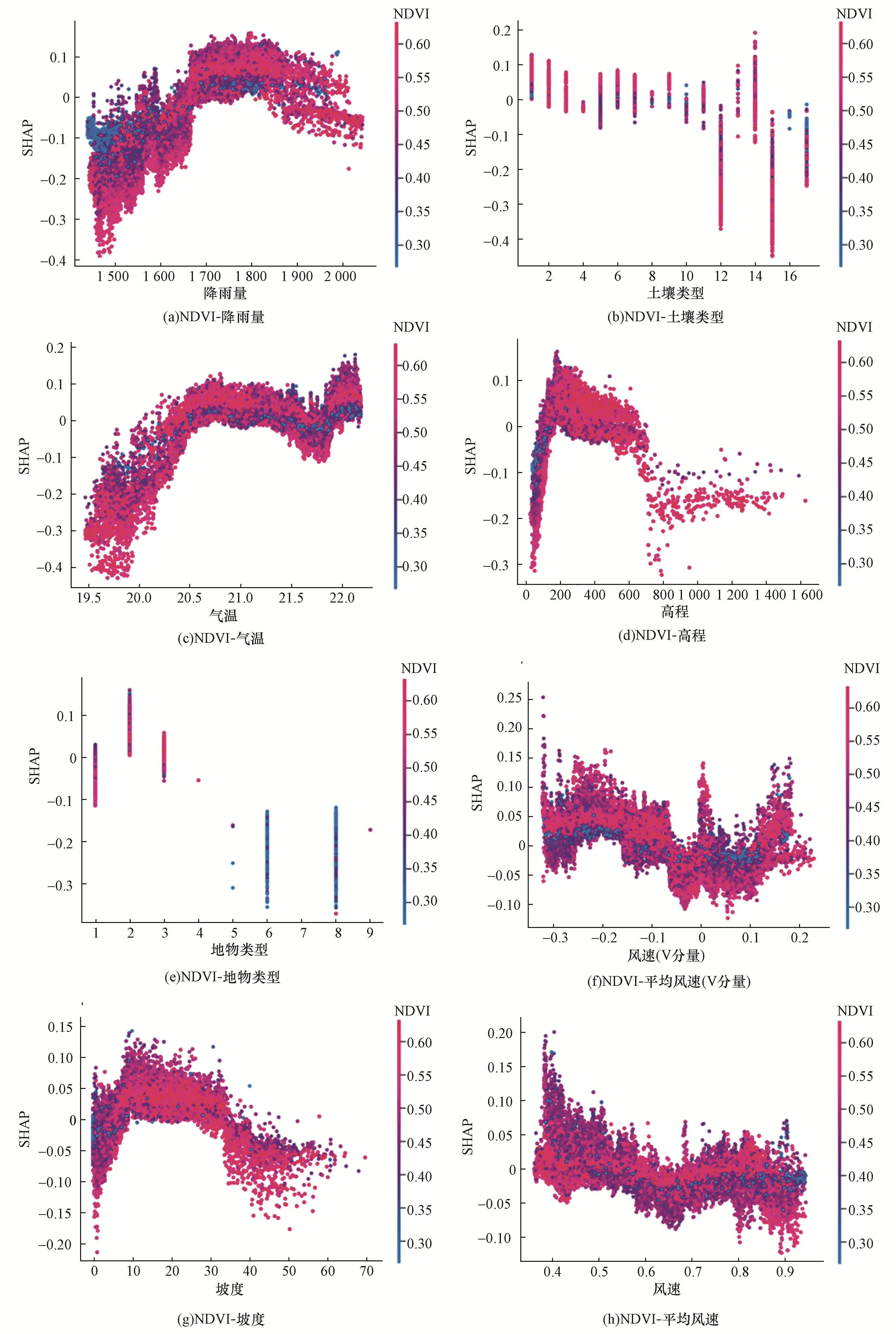
图8 NDVI与其他主要影响因子的双依赖性结果Fig.8 Double-dependence results of NDVI and other main influencing factors
(1)NDVI对野火发生有积极的正向作用,当NDVI>0.5时,Shapley>0,更易发生野火,符合客观事实规律。NDVI与其余因子间存在较强的交互作用。
(2)降雨量与NDVI的交互作用较强,降雨量越多,植被发育能力越强,促进了野火发生的基础条件。当年降雨量>2 000 mm时,地表及空气湿度过大,不利于野火灾害的发生。
(3)当地物类型为林地和草地时,NDVI较大,Shapley>0,更易发生野火灾害。
(4)气温对野火发生存在正向影响,气温越高,发生野火的可能性越高。当气温>20.5 ℃时,易发生野火灾害。
(5)高度与野火发生间存在非单调关系。高植被覆盖地区主要分布于200 m以上海拔区域,野火发生概率大;当高程>700 m时,野火可能性降低。
(6)除Alh、LVh、RK、UR和WR外,其余土壤类型均存在发生野火的可能性,其中,属Ach、Acf和Acu等土壤类型的样本Shapley普遍大于0,野火灾害更容易发生。
(7)平均风速(V分量)与野火易发性预测结果间没有明显的区间单调关系。整体规律为,基于0 m/s的风速为对称,当东西向风速>0.1 m/s时,大部分样本的Shapley>0,对野火发生有促进作用。
(8)当10 °坡度<30 °时,样本的植被覆盖率高,样本Shapley普遍大于0,利于野火灾害的发生。
(9)平均风速对野火发生存在负向影响,Shapley>0 m/s且数值较高的样本,普遍位于风速值<0.5 m/s的区间,野火发生概率较大。
4.3 典型野火灾害的局部性分析
SHAP不仅可以在全局维度上解释分析各因子对全域野火易发性结果的影响,还可以在局部维度上分析模型对单个样本中不同因子对其预测结果的影响[29]。本文研究基于国内主流媒体获取到2012—2022年内南宁市重大野火灾害和样本数据信息,结合所构建的野火易发性预测模型,对其进行局部性解释分析。表4为检索到的3起历史重大野火的详细信息,图9为3起野火灾害对应的样本解释图,图9中纵轴为该样本主要影响因子的名称及属性值;中央红色表示利于野火发生的正向因素的力度,蓝色相反;各个因子的正负向的力度相互抵消,得到图9上侧的最终预测值f(x)。
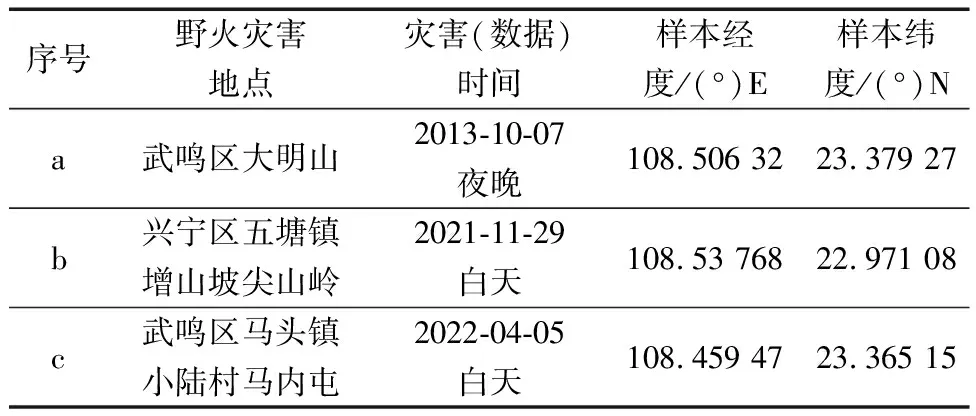
表4 南宁市重大野火灾害信息Table 4 Information of historical major wildfire disaster in Nanning
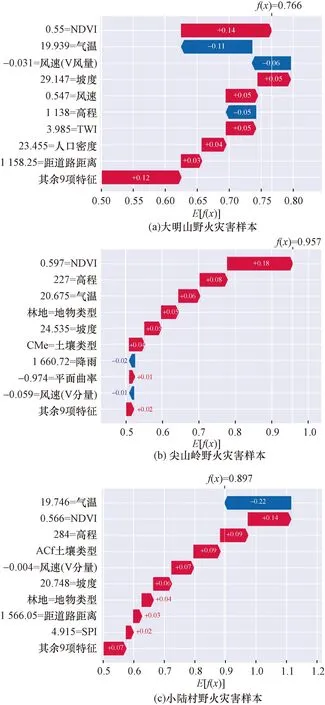
图9 历史野火灾害的局部性解释结果Fig.9 Local interpretation results of historical wildfire disasters
经过分析可得如下结果。
(1)对于野火样本a,NDVI、坡度、风速、TWI、人口密度和距道路距离因子起主要的正向力度;气温、风速(V分量)和高程对样本起着负向力度;其余9项因子贡献0.12的正向力度,最终预测的野火易发性指数为0.736,判断为野火样本。
(2)对于野火样本b,NDVI、高程、气温、地物类型、坡度、土壤类型和平面曲率起正向力度;降雨和风速(V分量)起微弱的负向力度;其余9项因子贡献0.02的正向力度,最终预测的野火易发性指数为0.957,判断为野火样本。
(3)对于野火样本c,NDVI、高程、土壤类型、风速(V分量)、坡度、地物类型、距道路距离和SPI起正向力度;气温起主要的负向力度;其余9项因子贡献0.07的正向力度,最终预测的野火易发性指数为0.897,判断为野火样本。
5 结论
以南宁市历史野火灾害数据为样本,选取高程、年均降雨量、平均气温、平均风速、NDVI等18个因素作为评价因子。分别基于CART、RF、LGBM和XGBoost模型进行野火易发性建模,利用多维评价指标验证各模型的预测性能,并选出最优模型。并且,基于SHAP可解释方法对模型进行特征全局性解释、特征依赖性分析、典型样本的局部性分析。研究结论如下。
(1)基于CART、RF、LGBM和XGBoost模型的野火易发性等级区划结果的分布规律相似,其极高易发区主要分布于研究区西北部、东部及南部。就南宁市野火易发性评价结果而言,XGBoost模型较其他模型拥有更合理的易发性区划结果和更优秀的预测性能,其极高易发区占区域总面积的39.113%,ROC曲线的AUC为0.959,样本总体预测精度为0.906,预测结果更可靠且更贴近样本的真实属性。
(2)对最优模型进行特征全局解释和特征依赖性分析,得知研究区内各因子对野火发生的作用方向和力度,发现重要性较高的因子有NDVI、降雨、土壤类型、气温、高程、地物类型、风速(V分量)、坡度和风速,并分析了主要影响因子的变化对野火易发性预测结果的影响。
(3)典型野火样本的局部性解释结果,与因子依赖性分析结果相符。其不仅提高了野火易发性模型分析结果的可信度,还有效验证了模型对典型野火灾害的预测稳定性,为南宁市野火灾害的防治提供了理论基础及针对性建议。
对区域性野火易发性的解释均基于具有优秀预测性能的数据驱动模型进行的,并不是客观地解释物理原理。当样本或因子的数量或属性发生变化时,可能导致决策结果发生改变。因此,要想使野火易发性模型的解释结果接近客观现实,除了选择具有优秀性能的模型外,还应确保样本数据的准确性和评价因子的全面性。
猜你喜欢
科学大众(2024年5期)2024-03-06
中国药学药品知识仓库(2022年9期)2022-05-23
大众科学(2022年5期)2022-05-18
今日农业(2021年10期)2021-11-27
疯狂英语(双语世界)(2021年2期)2021-07-03
今日农业(2021年1期)2021-03-19
宝藏(2019年3期)2019-03-28
成都信息工程大学学报(2018年4期)2019-01-23
城市道桥与防洪(2013年8期)2013-03-11
中共南宁市委党校学报(2012年2期)2012-08-15
