
融合周期变化和多尺度特征的组合模型园区能耗预测
2024-02-20 06:48梁文建石卫兵韩玉稳戴峰马亚文
城市建设理论研究(电子版) 2024年3期
梁文建 石卫兵 韩玉稳 戴峰 马亚文
1.中车青岛四方机车车辆股份有限公司 山东 青岛 266000
2.云南省机电一体化应用技术重点实验室 云南 昆明 650031
3.南通市中央创新区建设投资有限公司 江苏 南通 226010
4.元始智能科技(南通)有限公司 江苏 南通 226010
世界范围内的建筑能耗已超越了工业、交通等领域,世界各国的建筑能耗普遍约为33%[1]。我国建筑能耗已达到全国总能源消费的三分之一,工业园区能耗作为建筑能耗的主要组成部分,园区能源消耗精准预测对园区节能有着重要作用。目前,园区能耗预测模型方法主要分为两种,一种是工程模型或正演模型,另一种是基于数据驱动模型。技术建模使用物理和热力学函数来量化理论过程和系统的能耗。技术模型可提供精确的结果,但也需要详细的输入数据[2]。
数据驱动模型,其目的是能在缺少园区物理参数的情况下对园区能耗进行预测,是通过过去的数据以此来建立能耗数据驱动模型。当前,广泛使用的机器学习方法有支持向量回归(Support Vector Recovery, SVR)[3]、人工神经网络(ANN)[4]和梯度渐进回归树(GBRT)等。然而,大多数机器学习方法用来降低数据的复杂性是需要大量的人为操作进行特征提取。
随着数据规模的不断扩大和技术不断发展,基于数据驱动的模型正逐步从浅层向深层过渡[5],即在多层网络中直接从数据中进行特征提取。与传统的机器学习方法相比,深度学习的预测准确率随训练样本数量的增加而持续提升[6]。在能源预测领域,循环神经网络(RNN)和长短期记忆网络(LSTM)等模型目前在园区能耗预测中占主导地位,而卷积神经网络(CNN)则较少使用,因为CNN更能捕捉局部特征,能有效学习到影响园区能耗的变量之间的非线性关系。
针对目前园区能耗预测方法存在的问题和两种模型各存在的不足和各自的优势,本文提出了一种基于CNN-LSTM联合模型的园区能耗融合预测模型。具体来说,这个联合模型是用来对数据进行平稳分析的,再将数据输入到ARIMA预测模型,得到一组预测值;将经过预处理的数据进行特征构造得到处理后的数据,然后用CNN-LSTM联合模型对其进行拟合,获得了预测结果。在此基础上,利用卷积神经网络的预测精度与ARIMA拟合趋势的一致性,对预测结果进行加权融合,实现能耗融合预测的目的。为了验证所提预测模型性能的有效性,本文利用某高铁制造工业园区动力柜输出用电数据进行实验。实验结果表明,本文提出的融合预测模型在能耗预测准确率方面均高于ARIMA模型和CNN-LSTM模型。本文的主要贡献可以概括为:(1)将CNN和LSTM两种算法结合起来,同时提取局部关联特征和时序特征,实现更可靠的园区能耗预测;(2)采用stacking集成学习的模式,将深度学习预测结果与ARIMA预测结果进行融合;(3)利用深度学习模型预测的准确率和ARIMA拟合趋势的吻合度进行权重分配。
1 模型原理
整体结构分成四个部分,第一部分是数据采集;第二部分是数据处理,对采集到的原始数据进行处理,该数据为本文实验数据;第三部分是模型构建,第四部分给出了本文所建模型的预测结果。
1.1 卷积神经网络
CNN通过处理输入数据的局部相关性可以避免过多的参数模型,而卷积操作最重要的特点之一就是权值共享。
通常用全连接层、池化层和卷积层构成CNN。其中,卷积层的主要作用是从输入数据中提取有用的信息,通过卷积核对数据进行特征提取,形成特征映射图。
1.2 长短期记忆网络
长短期记忆网络(LSTM)是一种能够学习并记忆序列长期信息的递归模型。LSTM的核心是由三个存储单元组成,每一次都可以对输入信息进行编码。其运算公式如下所示,
其中x表示输入向量,h表示输出向量,⊙表示点乘运算符,矩阵表示待训练参数。σ(·)表示sigmoid非线性函数,tanh(·)表示双曲正切函数。
差分自回归移动平均模型
差分自回归移动平均模型(ARIMA)是时间序列预测常用的一种模型。ARIMA模型将时间序列数据默认为一组随机序列,是非平稳的数据经过差分后趋于平稳,转换为平稳的时间序列,并对以往数据间的线性关系构建模型,以预测数据未来值。ARIMA(p, d, q)模型的表现形式为:
式(2)中,yt为当前预测值,µ为常数项,p为自回归的阶数,q为移动平均的阶数,tε为随机扰动项序列。
1.3 CNN-LSTM预测模型
针对园区能耗预测领域,在CNN模型中,可通过卷积核构成高维特征;在LSTM预测模型中,LSTM模型有输入门it、输出门ot、和忘记门ft,信息流ct;CNN-LSTM组合模型是混合模型,分为两层,第一层采用CNN网络;第二层采用LSTM模型。CNN模型接受训练数据的输入,提取特征信息,最后输出预测结果,将预测结果输入到后端LSTM模型中,LSTM再对输入进行训练。可以提升网络的非线性映射能力,同时避免过拟合。
1.4 SCLA融合预测模型
融合预测模型(Stacking CNN-LSTM ARIMA,SCLA)是将ARIMA预测模型和CNN-LSTM预测模型结合起来,在有限的数据上,提高模型的预测能力。该模型主要包含基于ARIMA模型预测、CNN-LSTM模型预测以及融合预测三个阶段。

图1 融合预测模型
2 数据表示和处理
2.1 数据集选择
本文选择了某高铁制造工业园区动力柜用电2022年8月9日到2022年8月23日共358个电表读数作为数据集,来进行训练和测试。将2022年8月9日到2022年8月22日的数据作为训练集,2022年8月23日的数据作为测试集。
2.2 异常值清洗
异常值是指在样本中明显偏离其他数值的样本点,这些异常值与其他数据点相比具有显著的差异。本文使用箱线图对异常值进行处理。
2.3 模型评估指标
为了更好地评估模型的预测结果,本文选择三个性能指标,利用均方误差(MSE)、平均绝对误差(MAE)和平均绝对百分比误差(MAPE),以评估和比较模型的预测能力。MSE是真实值与预测值的差值的平方然后求和平均;MAE揭示误差绝对值的均值情况;MAPE是统计预测准确性的一种方法。以上三类误差均实数值越小表示模型预测效果越好。其方程如下
其中,表示预测值,yi表示真实值。
3 实验分析
3.1 实验数据处理
本文使用某高铁制造工业园区电表读数作为数据源,且需要对其进行处理,计算出其每小时的用电量。
3.2 箱线图异常检测结果
本文使用箱线图检测异常数据,其结果如图2所示。从图7中可以发现,数据集中各个时间段均存在异常值的情况,对于所检测出的异常值,采用删除异常值的方式进行处理。
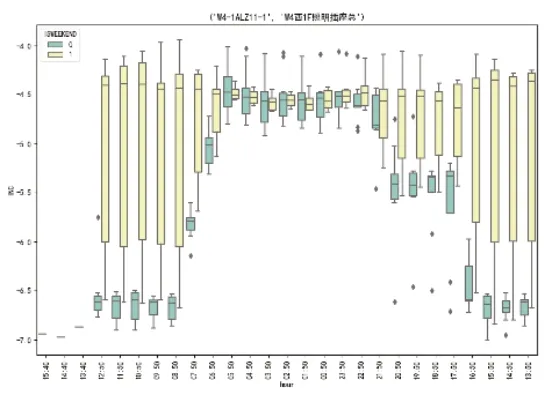
图2 异常数据检测
3.3 ARIMA参数选择
为了确定ARIMA模型的结束,本文应用AIC准则确定最终模型的阶数。AIC准则是由日本统计学家Akaike提出的,该准则要求选择使下式最小化的模型:
计算p,q取不同的值得到的ARIMA模型的AIC值,最小AIC值对应的p,q即为最优参数。本文所用ARIMA模型的最优阶数是(3,0,4)。
3.4 模型预测效果对比
为了验证本文所提模型的有效性和可行性,与ARIMA算法和CNN-LSTM算法进行对比分析。几种模型的评估指标如下表所示:
从表1可知,本文所提SCLA模型的MSE指标、MAE指标和MAPE指标均低于ARIMA算法和CNN-LSTM算法。

表1 模型评估指标
为了更好的对比三种模型的预测效果,三种模型的预测结果的预测结果如图3所示。
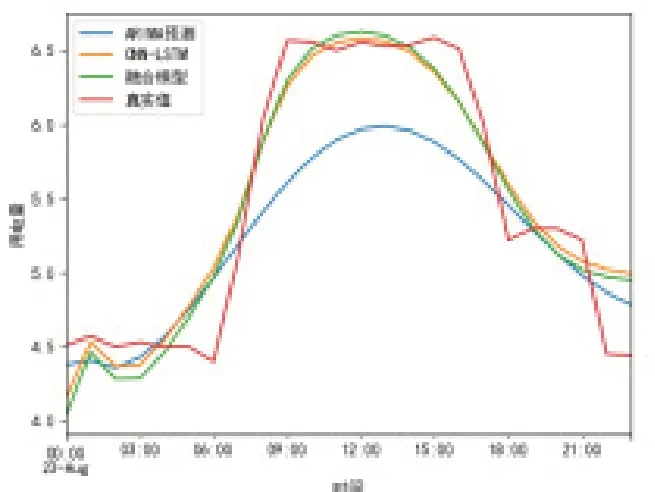
图3 预测结果对比
由图3可知,本文所提的融合模型SCLA的预测曲线更加平滑,相较于ARIMA模型和CNN-LSTM模型其预测结果更接近真实值,预测效果更好。
综上,根据三个模型的预测结果和评估指标对比可以看出,本文所提SCLA融合模型预测的整体趋势和真实值更吻合,特别是在峰值处的预测值和真实值十分贴近,预测效果更好。
4 结语
本文建立了基于ARIMA和CNN-LSTM融合模型的园区能耗预测模型利用高铁制造工业园区能耗实测数据进行验证和分析,并得出以下结论:
(1)利用ARIMA预测模型对数据进行平稳性检测,并利用箱线图检测并删除异常值得到了有利于能耗预测的平稳、完整的实验数据。
(2)提出了CNN-LSTM组合模型,利用卷积神经网络对提取局部关联特征的能力以及长短期记忆网络学习时序特征的能力进行能耗预测,以实现深度学习在预测公园能耗方面的重要性。
(3)提出了一种新的改进算法,该算法将ARIMA和CNN-LSTM预测进行了校准,该算法充分利用了周期性趋势的优势,使之能更好地反映实际的变化趋势。实验结果显示,本文所提模型相较于ARIMA和CNN-LSTM的预测精度都大幅度提高。
猜你喜欢
昆钢科技(2022年2期)2022-07-08
当代水产(2021年10期)2022-01-12
北京航空航天大学学报(2021年9期)2021-11-02
建材发展导向(2021年23期)2021-03-08
华人时刊(2019年19期)2020-01-06
电子制作(2019年11期)2019-07-04
商周刊(2018年24期)2019-01-08
华人时刊(2018年15期)2018-11-10
商周刊(2018年12期)2018-07-11
北京航空航天大学学报(2018年1期)2018-04-20
