
面向边缘端设备的轻量化视频异常事件检测方法
2024-02-18 18:46李南君李爽李拓邹晓峰王长红
计算机应用研究 2024年1期
李南君 李爽 李拓 邹晓峰 王长红
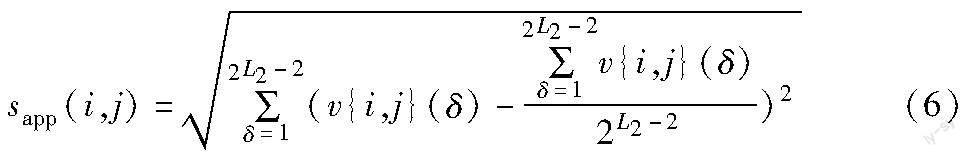
摘 要:现有基于CNN模型的视频异常事件检测方法在精度不断提升的同时,面临架构复杂、参数庞大、训练冗长等问题,致使硬件算力需求高,难以适配无人机等计算资源有限的边缘端设备。为此,提出一种面向边缘端设备的轻量化异常事件检测方法,旨在平衡检测性能与推理延迟。首先,由原始视频序列提取梯度立方体与光流立方体作为事件表观与运动特征表示;其次,设计改进的小规模PCANet获取梯度立方体对应的高层次分块直方图特征;再次,根据每个局部分块的直方图特征分布情况计算表观异常得分,同时基于内部像素光流幅值累加计算运动异常得分;最后,依据表观与运动异常得分的加权融合值判别异常分块,实现表观与运动异常事件联合检测与定位。在公开数据集UCSD的Ped1与Ped2子集上进行实验验证,该方法的帧层面AUC分别达到86.7%与94.9%,领先大多数对比方法,且参数量明显降低。实验结果表明,该方法在低算力需求下,可以实现较高的异常检测稳定性和准确率,能够有效兼顾检测精度与计算资源,因此适用于低功耗边缘端设备。
关键词:智能视频监控;边缘端设备;异常事件检测;主成分分析网络;分块直方图特征
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)01-049-0306-08
doi:10.19734/j.issn.1001-3695.2023.04.0225
Lightweight video abnormal event detection method for edge devices
Abstract:Existing CNN-based video anomaly detection methods improve the accuracy continuously,which are faced with issues such as complex architecture,large parameters and lengthy training.Therefore,the hardware computing power requirements of them are high,which makes it difficult to adapt to edge devices with limited computing resources like UAVs.To this end,this paper proposed a lightweight abnormal event detection method for edge devices.Firstly,the method extracted gradient cuboids and optical flow cuboids from video sequence as appearance and motion feature representation.Secondly,the method designed a modified PCANet network to obtain high-level block-wise histogram features of gradient cuboids.Then,the method calculated the appearance anomaly score of each block based on histogram feature distribution,and calculated the motion ano-maly score based on the accumulation of optical flow amplitudes of internal pixels.Finally,the method fused the appearance and motion anomaly scores to identify anomalous blocks,achieving appearance and motion abnormal events detection and localization simultaneously.The frame-level AUC of proposed method reached 86.7% on UCSD Ped1 dataset and 94.9% on UCSD Ped2 dataset,which were superior to other methods and the parameters were much smaller.Experimental results show that the method achieves better anomaly detection performance under low computational power requirements,making the ba-lance between detection precision and computing resources,which is suitable for low-power edge devices.
Key words:intelligent video surveillance;edge device;abnormal event detection;principle component analysis network;block-wise histogram feature
0 引言
當前,全球城市化进程加快,人口数量激增,社会公共安全问题日渐突出。面对现实公共区域中频发的各类安全事故与突发情况,以监控摄像机为核心设备的视频监控系统逐渐凸显优势。视频监控系统通过前端摄像机能够全天候采集监控区域场景画面,利用网络传输技术将采集到的视频信息输送回监控室并在电视屏幕上实时播放,工作人员对视频画面进行观察分析,及时发现可疑情况并采取措施,以维护社会秩序、保障人民生命财产安全。因此大量监控设备被广泛安装在街道、办公楼、商场等公共场所,以及医院、机场、火车站等重要机构,逐渐形成大规模视频监控联网建设应用,如“天网监控系统”。然而,传统监控系统依赖人工进行视频场景事件分析与信息提取的方式在面对众多监控设备产生的海量视频数据时存在执行效率低下、运行成本昂贵等问题,亟待发展能够自主理解视频内容并反馈异常情况的智能监控系统。
作为智能监控系统的核心功能之一,视频异常事件检测技术受到产业界与学术界研究人员的共同关注,研究人员不断探索新方法并提供创新研究成果。该技术旨在采用图像处理与机器学习相关方法,自主识别监控视频场景中各类目标(行人、汽车等)引发的各种偏离常规的事件。因此可以最大程度地协助工作人员及时发现异常事件,在降低人力成本的同时提高监控效率,并减少误报和漏报情况,提升现有视频监控系统的智能化水平。
近期,以卷积神经网络(convolutional neural network,CNN)为代表的深度学习模型在由浅自深提取视频图像特征方面展现出优异性能,并在各项计算机视觉(computer vision,CV)任务上,如行为识别、目标检测、姿态估计等取得极佳效果。由此,诸多研究工作将CNN应用于视频异常检测任务。
不同于其他CV任务,视频异常事件检测实现过程面临诸多难点:a)异常事件定义场景相关性,相同事件根据其所处的时空上下文场景不同,异常属性判定存在差异;b)异常事件样本稀疏性,通常情况下,异常事件属于偶发事件,发生频率远低于正常事件,且通常持续时间很短难以被记录,导致可用的异常样本不足。因此,当前基于CNN的异常事件检测方法广泛采用半监督学习策略,即在训练阶段只使用正常事件样本训练检测模型,并在推理阶段,将明显偏离检测模型的待测样本判为异常。其中,两种常用的CNN模型为卷积自编码器(convolutional autoencoder,CAE)与生成对抗网络(generative adversarial network,GAN)。
当前基于CAE与GAN的半监督异常事件检测主流框架有基于重构的方法、基于预测的方法以及基于判别的方法。其中,基于重构的方法充分利用CAE对输入样本的复现能力,其核心思想是:训练阶段对正常事件样本进行编解码操作,并以较低误差重构正常输入为目标训练网络;在测试阶段,重构训练过程未出现异常事件样本时将得到较差的重构样本,进而获得较大的重构误差。基于预测的方法充分利用CAE与GAN的生成能力,大多数情况CAE会用作GAN中的生成器(gene-rator),与重构过程单纯复现已知输入事件不同,其核心思想是采用连续历史时刻事件作为先验信息,预测未知的未来时刻事件,预测值与真实值间的偏差为预测误差,用作异常判定标准。同样地,使用正常事件样本训练的预测网络仅能对其进行精准预测,而对于异常样本的预测结果不理想,从而产生较大的预测误差。基于判别的方法则充分利用GAN中判别器(discriminator)对生成样本与真实样本的区分能力,其核心思想是利用正常事件样本学习的GAN无法识别生成正常样本,但能够识别生成异常样本。现阶段大多数方法沿用上述三种基本框架,通过在原始网络中引入长短期记忆单元[1]、注意力模块[2,3]、记忆模块[4~6]、概率模型[7,8]、跨越连接机制[9,10]来解决CAE的强泛化能力以及GAN的训练过程不稳定等问题,从而优化异常检测结果。具体而言,Zhong等人[2]提出一种基于CAE的双向视频帧预测框架,设计基于空间注意力与通道注意力的双向特征融合机制,同时进行前向帧预测与后向帧预测。肖进胜等人[6]构建概率记忆自编码网络,在自编码主干网络中嵌入概率模型和记忆模块,提升其视频帧重建质量;同时使用因果三维卷积和时间维度共享全连接层,避免未来信息丢失,强化编码器特征提取性能。类似地,针对现有重构方法忽略正常数据内部结构致使效率较低的问题,钟友坤等人[8]整合自编码器与高斯概率模型,提出深度自动编码高斯混合网络。其中,自编码器映射输入视频片段的低维隐层表示并生成重构样本,而高斯混合模型拟合正常片段的概率分布,进而通过能量密度概率判斷异常。周航等人[11]研究基于时空融合图网络学习的视频异常检测方法,在充分挖掘视频空间相似性与时序延续性的基础上开展异常事件推理。
除此之外,Transformer网络[12]作为具有全局感受野的前沿深度学习模型,能够利用自注意力机制挖掘视频图像全局依赖关系,表现出比经典CNN更强的特征提取能力。基于视觉Transformer(vision Transformer,ViT)的半监督异常事件检测方法[13~15]应运而生。需要特别说明的是,大多数ViT方法仍然使用前面所述的三种基本框架。Lee等人[14]构建多分支ViT预测架构,在充分利用视频时空上下文的基础上,开展不同任务设置下的未来帧预测,以完成异常识别。刘成明等人[15]设计融合门控自注意力机制的生成对抗网络,在原始GAN的生成器部分引入门控自注意力机制,逐层对采样过程中的特征图进行权重分配,抑制输入视频帧中与异常检测任务不相关背景区域的特征表达,从而优化时空信息建模。
然而,上述方法在依靠复杂深度学习模型取得高精度异常检测结果的同时,也面临网络规模大、训练参数多、计算开销大等问题。特别是ViT网络,由于需要捕获全局注意力,训练参数量往往达到千万级别。这决定了这些方法必须依赖高算力的硬件设备进行训练与推理,无法部署到计算资源有限且功耗要求严格的边缘端设备上,同时难以实现在线实时检测。为此,提出一种面向边缘端设备的轻量化视频异常检测方法LVAD(lightweight video abnormal event detection),该方法利用一种性能高效、架构简洁的主成分分析网络(principle component analysis network,PCANet)[16]进行视频序列不同局部区域图像高层次特征提取,其具备规模小、参数少、无须迭代训练等优势。在此基础上设计一种全新的快速异常识别策略,根据不同区域的特征分布直接计算异常得分作为异常判别标准,进而实现视频序列中局部异常事件定位。同时,为了实现运动与表观异常事件联合检测,该方法采用双流分支结构,其中表观分支中使用梯度特征作为视频事件外观表示,运动分支中使用光流特征作为视频事件运动表示。由于PCANet无须依靠大量人工预标注的视频事件样本进行参数迭代训练的特性,使得该方法硬件算力要求不高,适用于低功耗边缘端设备下的高速推理。
具体而言,本文的主要贡献如下:
a)提出一种全新的基于PCANet的轻量化异常事件检测方法LVAD。首先使用PCANet在原始视频序列划分的梯度时空立方体中提取高层次分块直方图特征,进而直接依据特征分布计算标准差作为表观异常得分,并与基于光流值计算的运动异常得分进行融合,用于异常分块判定,以同时实现异常事件检测与定位。
b)设计一种改进的PCANet架构。利用差异扩展化操作替代原始网络中去均值化操作,通过该措施增大视频图像不同重叠采样块间差异,保证后续PCA滤波器能够更容易捕获特征变化,进而有助于识别异常图像块。此外,不同于原始网络仅能处理单帧图像,改进网络以特征立方体为输入,在全面考虑时序信息与空间信息基础上生成卷积滤波器。
c)在多个公开标准数据集上的实验结果表明,本文方法在更小空间占用、更低算力需求、更快推理速度下的性能优于部分基于大规模CNN的方法,实现了异常检测精度与运算延迟间的最佳平衡。
1 本文方法
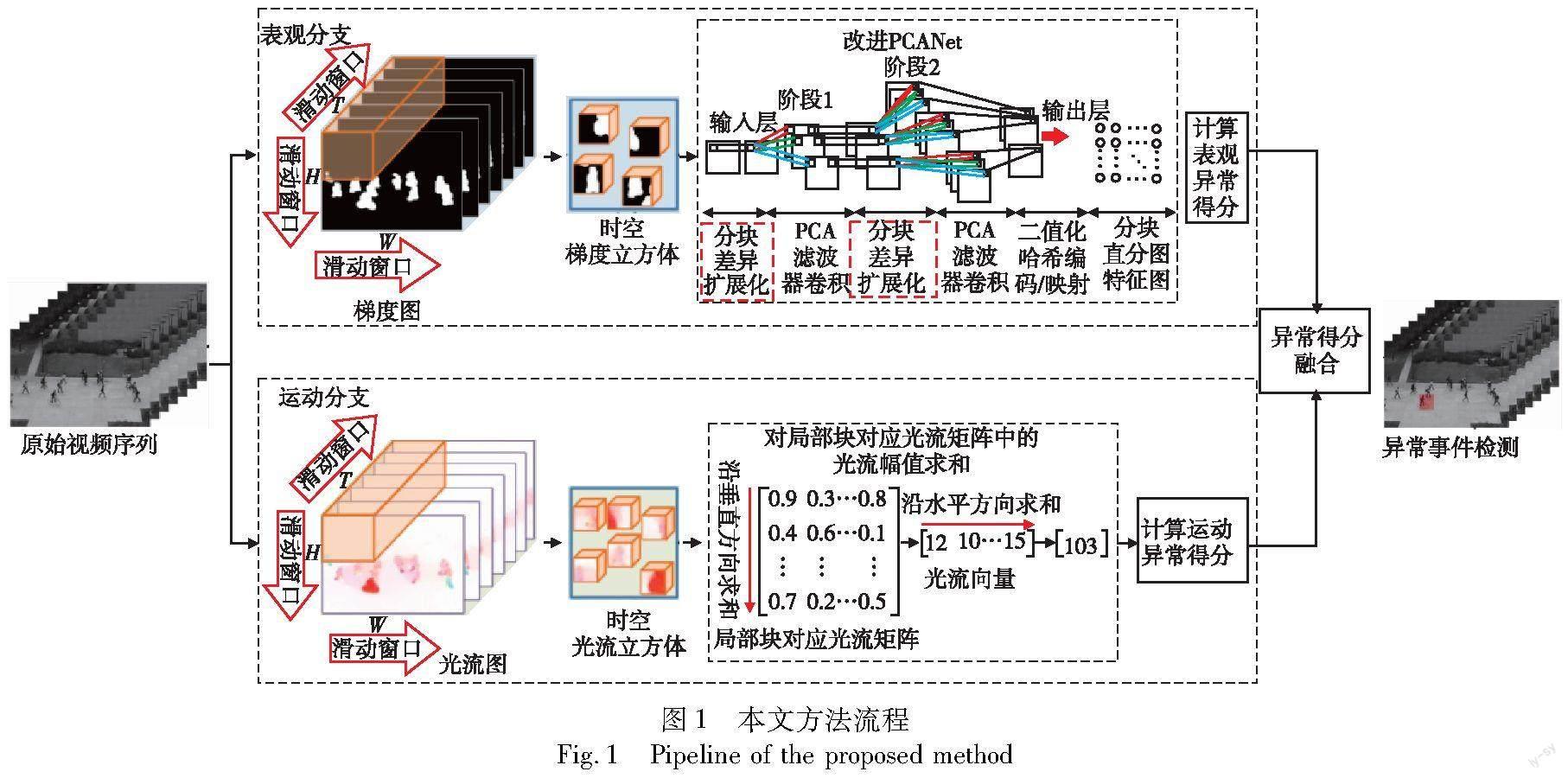
基于改进PCANet的轻量化异常事件检测方法LVAD的基本流程如图1所示。首先,针对原始视频序列进行预处理,基于滑动窗口提取梯度特征立方体与光流特征立方体作为视频事件表观与运动表达;继而,采用改进PCANet处理梯度特征立方体,获取其高层次分块直方图特征向量,并通过计算每个局部分块对应直方图特征分布的标准差作为其表观异常得分;最后,将表观异常得分与基于光流特征幅值计算的运动异常得分进行加权融合,同时采用单类别分类器对融合后异常得分进行阈值化处理,判别每帧视频图像内的异常分块,实现局部异常事件定位。值得注意的是,PCANet属于一种简化的深度学习模型,其卷积层数少、参数量低、无须冗长迭代训练,适用于在计算资源有限的边缘端设备上运算。
1.1 视频序列特征立方体划分
针对视频序列进行预处理,将其划分为用于分析处理的基本单位,是实现视频中局部异常事件区域定位的必要步骤。为此,采用一种基于滑动窗口的视频预处理方法,具体流程如图2所示。首先,设置大小为W×H×T的滑动窗口,其中W和H分别为滑动窗口的宽度和高度,T为时间深度。使用滑动窗口将每个图像帧分割成大小为W×H、互不重叠的多个二维图像单元(patch);继而,将连续T帧时序维度上相邻的视频图像中同一空间坐标的二维单元堆叠在一起,构成三维时空立方体(spatial-temporal cuboid),用于视频处理与异常检测的基本单位;最后,提取每个立方体对应梯度特征立方体与光流特征立方体作为表观信息与运动信息载体,用于表观与运动异常事件联合检测。
针对梯度特征立方体,首先基于式(1)计算视频帧Ft中每个像素点的时空梯度得到时空梯度图,其中p表示Ft中的像素点。其时空梯度Fp共包含三个元素:前两个元素Fp,x和Fp,y分别为图像水平方向与垂直方向的梯度值,用于描述目标的姿态与形状;第三个元素Fp,t为时间方向的梯度值,用于刻画目标表观特征随时间的变化。因此,每个时空梯度图包含三个通道,随后采用上述滑动窗口对多个时空梯度图构成的序列进行采样,获得梯度立方体。
针对光流特征立方体,首先采用Horn-Schunck光流法计算每个像素点的水平方向光流值Ip,x与垂直方向光流值Ip,y作为光流图前两个通道;之后,使用式(2)计算每个像素点的合成光流幅值Ip作为光流图的第三个通道;最后,利用滑动窗口处理光流图序列获得光流立方体。
1.2 基于改进PCANet的高层次表观特征提取
PCANet作为一种结构简洁的深度学习模型,已在人脸识别、手写字符识别以及目标识别等基于视觉语义的分类任务上取得较高精度,充分验证其在高层次表观特征提取方面的有效性。与CNN相似,PCANet采用分层级联的特征学习结构,由浅自深地自动提取精细特征。然而,相较于CNN,PCANet规模较小(一般仅包含两层卷积),且无须使用梯度下降法进行反复调参、训练以获取更佳效果,因而算力需求不高,适用于计算能效有限的边缘端处理器。
PCANet基本特征提取流程包括主成分分析PCA(principal component analysis)、二值化哈希编码(binary hashing)、分块直方图(block-wise histograms)三步,三个步骤分别对应CNN中的卷积、非线性处理以及下采样操作。首先利用PCA算法学习多层滤波器(卷积核),然后使用二值化哈希编码进行非线性处理,最后采用分块直方图进行重采样,输出分块直方图特征,该特征具备一定变换上的稳定性(如尺度不变性)。
很明显,输出的PCA滤波器W1l中记录了输入梯度立方体中最为关键的时空信息。
将每个Ol,nt输入二值化函数H(z)处理后进行哈希编码,编码位数与W2n个数相同,表示为
1.3 视频分块表观异常得分计算
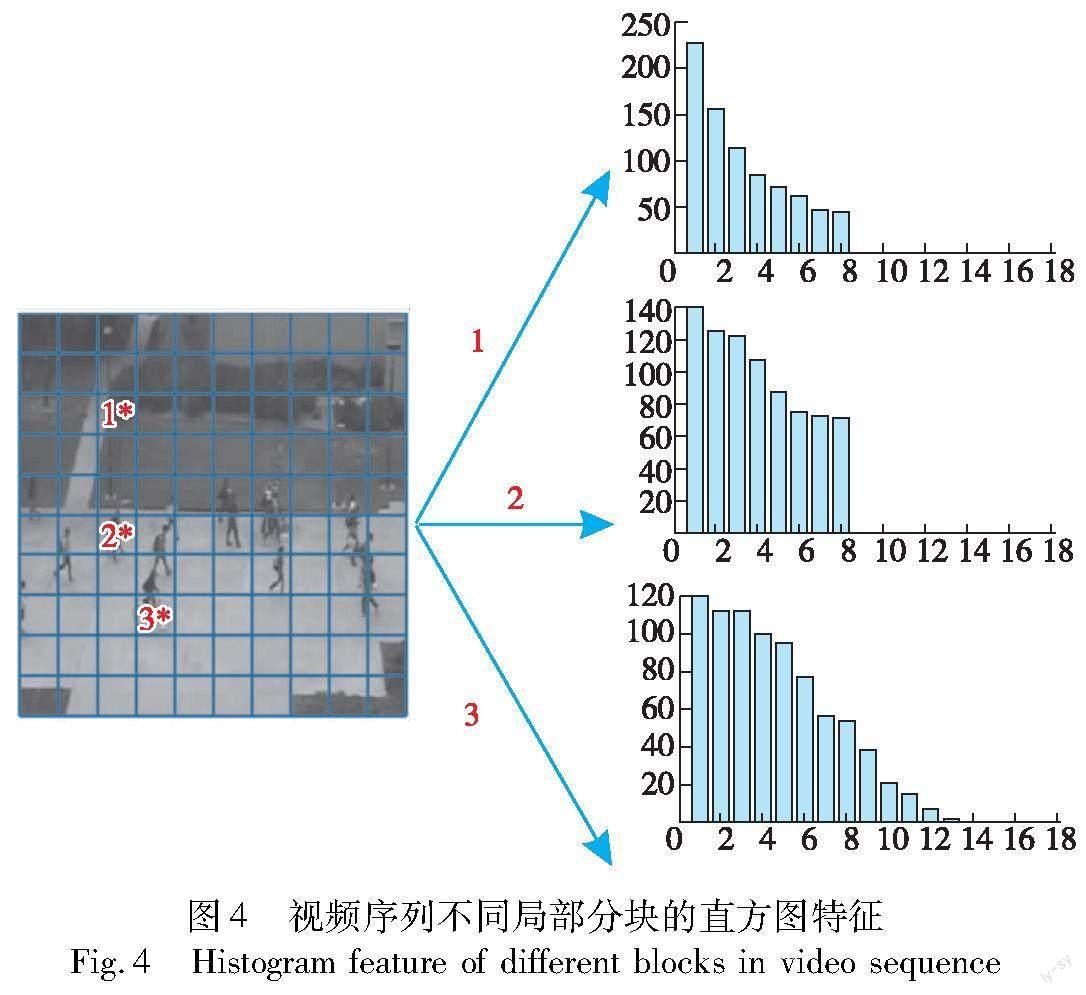
针对局部分块Bt(i,j)的表观异常得分,基于其直方图特征进行计算。一般来说,只包含正常事件的分块对应直方图特征分布较为集中,像素特征值主要分布在前端取值区间;而对于异常分块,由于包含异常像素,直方图特征分布更为均匀,像素特征值分布占据更多取值区间,如图4所示。其中,分块3中包含骑自行车异常事件,而分块2仅包含行人行走正常事件,分块1仅包含背景信息。由图4可以看出,分块1像素特征值集中分布于前几个区间,分块2特征值更均匀地分布于区间1~8,相较之下,分块3特征值则更广泛地分布于区间1~12。
因此,通过计算直方图特征的标准偏差作为Bt(i,j)表观异常得分:对于正常分块,由于其像素特征值集中分布在直方图前端区间内,在后续取值区间没有分布,致使直方图特征不同区间的高度值離散程度较大,将产生较高标准差;相反地,对于异常分块,直方图特征不同,区间高度值则更加连续,将产生较低标准差。Bt(i,j)直方图特征标准差计算如下:
其中:sapp(i,j)为表观异常得分;v(i,j){δ}表示其直方图特征第δ个区间对应高度值。
1.4 视频分块异常判别
针对局部分块Bt(i,j)的运动异常得分,对其包含所有像素的光流幅值进行求和,获得
其中:Nf为Bt(i,j)中像素个数。通常来说,smot(i,j)越大,代表Bt(i,j)中像素运动速度越快,其中包含非常规运动事件概率越高(如正常行走人群中突然驶入的车辆),而sapp(i,j)越小,代表Bt(i,j)中像素表观与常规偏差越大,Bt(i,j)中包含非正常外观目标概率越高(如正常行走人群中缓慢进入的自行车)。因此,运动异常得分与表观异常得分的融合过程为
sfus=αsmot+β(1-sapp)(8)
其中:α与β为加权融合权重。
设定检测阈值θ,根据融合异常得分,利用单类别分类器(one-class classifier)判别异常局部块,实现异常事件检测与定位:
2 实验结果与分析
2.1 数据集
本章在UCSD[17]与UMN[18]两个公开标准异常事件数据集上对本文方法的有效性进行实验验证。
2.1.1 UCSD数据集
UCSD数据集由Ped1和Ped2两个子集组成,分别包含两台固定视角摄像机拍摄的加利福尼亚大学圣迭戈分校(University of California,San Diego,UCSD)校园内两条不同道路场景的多段视频。两个子集中均将视频场景中的行人按正常道路方向以常规速度行走定义为正常事件,而将突然进入人行道的非人目标(如手推车、汽车等)及行人非常规行为模式(如滑滑板、骑自行车)定义为异常事件。
Ped1子集的训练集由34段只包含正常事件的视频序列组成,测试集由36段包含不同类型异常事件的视频序列组成,每段视频均由200帧图像构成,空间分辨率为238×158。相较于Ped1,Ped2子集体量更小,训练集和测试集分别包含16段正常视频序列和12段异常视频序列,每段视频图像帧数不等,由120帧变化到200帧,空间分辨率为360×240。
Ped1子集中仅有10段测试视频的异常事件帧层面与像素层面真实值标注被同时提供,而Ped2子集中所有测试视频的异常事件帧层面与像素层面真实值标注被同时提供。
2.1.2 UMN数据集
UMN数据集来源于明尼苏达大学(University of Minnesota System,UMN)人工智能实验室,记录了3个不同场景(2个强光照室外场景和1个昏暗室内场景)发生的共11段视频序列,共包含分辨率为320×240的7 739帧图像。每段视频以人群正常地随意行走为开始,以突然逃散或奔跑为结束。该数据集仅提供异常事件的帧层面真实值标注,未提供像素层面的真实值标注。换言之,只知道视频序列中哪些帧存在异常,但不知道异常帧中哪些像素是异常的(即异常发生的具体区域)。相较于UCSD,该数据集包含的异常事件侧重群体行为(人群逃散、奔跑)。因此,本章在UMN数据集上进行测试以评估本文方法面向群体异常事件检测性能。
2.2 评价标准
本文实验同时使用如下两种准则或其中之一评估本文方法的异常检测效果:视频帧层面(frame-level)标准和像素层面(pixel-level)标准,分别对应视频异常的帧层面与像素层面真实值标注。两个准则的基本原理均是通过统计实际检测结果与真实值标注的匹配程度评估性能,定义异常结果与正常结果为阳性(positive)与阴性(negative)。
1)帧层面准则 视频帧中只要一个像素被判为异常(本文中异常分块所含像素全部被认定为异常),则被认定为异常帧,若其对应帧层面真实值同样为异常,将视为真阳性(true positive,TP)检测;否则,视为假阳性(false positive,FP)检测。该评价准则一般用于衡量算法在视频序列时序维度上的异常事件检测(判断视频中哪帧图像包含异常)准确率。
2)像素层面准则 视频帧中判为异常的像素覆盖至少40%的真实异常像素时,才视为TP检测;而与帧层面准则一致,正常帧中只要一个像素被检测为异常,将视为FP检测。该评价准则适用于衡量算法在视频序列空间维度上的异常事件定位(判断异常图像帧中哪些像素为异常)准确率。
基于帧层面或像素层面准则评判视频序列每帧图像后,计算真阳率(true positive rate,TPR)和假阳率(false positive rate,FPR)。
通过变换检测阈值(式(9)中的θ)的取值,可以得到多组 FPR-TPR值,以FPR为横坐标,TPR为纵坐标,绘制帧层面和像素层面的受试者操作特征(receiver operating characteristic,ROC)曲线。
利用ROC曲线,计算下述三个量化指标进行方法性能评估:
a)ROC曲线下的面积(area under curve,AUC)。
b)等错率(equal error rate,EER)。当假阳率等于漏检率时被误判为异常的视频帧比例,即在ROC曲线上FPR=1-TPR时的FPR值,通常用于帧层面评价标准。
c)等检率(equal detected rate,EDR)。等错率处的检测率,即EDR=1-EER,通常用于像素层面评价标准。
AUC与EDR值越大,EER值越小,代表方法性能越好,异常检测精度更高。
2.3 实验设置
实验过程中,数据集中视频序列的每帧图像尺寸被调整为360×240,相应的梯度图与光流图大小为360×240×3。滑动窗口大小W×H×T设置为40×40×7,由此二维图像单元(patch)大小为40×40,而三维视频立方体(cuboid)大小为40×40×7。在改进PCANet中,滤波器大小(采样大小)k1×k1初始化为5×5,第一层和第二层的滤波器个数分别設置为L1=8和L2=6,局部分块(block)大小设置为10×10,每个分块的直方图特征向量长度为2L2-2=16,即16个取值区间。融合权重系数α和β为0.5。
算法推理代码在Windows系统下运行,仅使用Intel i5-4460@3.20 GHz CPU、8 GB内存,无须高算力、大功耗GPU显卡。
2.4 实验结果
2.4.1 UCSD Ped1数据集上的实验结果
图5展示了本文方法在UCSD Ped1数据集上可视化异常事件检测结果示例,异常事件区域使用红色矩形标记(参见电子版)。可以发现,本文方法LVAD能够同时检测与定位运动异常事件,如突然驶入的汽车,以及表观异常事件,如缓慢出现的轮椅,这得益于LVAD采用的双流分支融合策略。
至于定量分析,选取近年发表于顶级会议或期刊上的前沿方法(绝大多数来源于近三年)与LVAD基于帧层面和像素层面量化指标进行对比。同时,为了更清晰地阐明LVAD在轻量化异常检测方面的优势,针对其与对比方法的模型参数量、硬件平台、推理速度进行详尽统计,如表1所示(表中“—”代表文献未公布相应结果或信息,其余表格与此相同)。由表1可以看出,在异常检测轻量化方面,LVAD拥有最小的模型参数量,相应地仅需要CPU设备完成异常检测训练与推理。而大部分对比方法的参数量在十万级以上,必须依赖高算力GPU开展模型训练与异常推理。值得注意的是,LVAD在仅使用CPU的前提下达到了0.11 s/帧的推理速度,印证其可以进行实时异常检测,易于部署到实际应用。
除此之外,在异常检测效果方面,LVAD在帧层面评价标准上取得最低EER值与最高AUC值,分别为19.5%与86.7%,相较于排名第二的方法分别提升2.5%与0.8%,充分验证了其优异的异常检测性能。而像素层面评价标准,近期工作大多未基于其进行异常定位精度评估,因此公开的量化指标有限。LVAD的像素层面EDR值与AUC值分别为62.1%与62.8%,说明其面向异常定位的有效性。需要特别说明的是,对比同样仅使用CPU执行异常推理的方法GLVP与SHAP(GPU只用于预处理阶段目标检测),LVAD的帧层面AUC分别增加了5.4%与0.8%。SHAP采用小规模降噪自编码器(仅包含3个全连接层)作为异常检测模型,表明了LVAD设计改进PCANet进行高层次特征提取并基于提取特征的分布特性执行异常检测的优势。综上所述,LVAD在较低算力需求下,取得了更高的异常事件检测与定位准确率,更加适用于边缘端推理场景。
2.4.2 UCSD Ped2数据集上的实验结果
图6展示了本文方法在UCSD Ped2数据集上可视化异常事件检测结果示例,异常事件区域使用红色矩形标记。能够看出LVAD在不同摄像机拍摄视角下仍可以同时检测和定位多种类型的异常事件,例如正常行走人群中出现的骑自行车者、突然驶入的汽车等。
表2提供了在Ped2数据集上的基于AUC、EER和EDR指标的定量比较结果及对比方法参数量等信息统计。可以看出,在帧层面评价标准上,LVAD的AUC值在所有对比方法中最高,达到94.9%,超过次优方法Siamese-Net 0.9%。至于EER指标,略差于ISTL(△1.2%)。在像素层面评价标准上,LVAD的EDR值与AUC值分别为82%与86.2%,在所有公开结果中最高,再次验证其在局部异常定位方面的优势。相较于GLVP与SHAP,与Ped1子集上的结果一致,EER与AUC指标实现了大幅提升,进一步阐明了LVAD在轻量化异常检测方面的出色性能。
2.4.3 UMN数据集上的实验结果
图7展示了本文方法LVAD在UMN数据集上可视化群体异常事件检测结果示例,异常事件所在帧使用红色长条标记,局部异常区域使用红色矩形标记。能够看出其不仅可以在时序维度上实现群体逃散异常事件检测,还可以在空间维度上完成逃散个体定位。
由于UMN数据集仅提供帧层面的异常真实值标注,所以只采用帧层面准则与先进方法对比,图8给出了在UMN数据集上LVAD与其他方法帧层面ROC曲线对比,而详细的基于EER与AUC的定量结果比较如表3所示。能够发现,所有方法在UMN数据集上都取得了较为理想的异常检测表现,LVAD同样实现了极佳效果,EER值为4.6%,AUC值达到98.7%。相较于spatial-temporal net,在量化指标上的细微差距可能是由于将视频序列划分为时空立方体作为检测单元,当视频中人群逃散过程接近结束时,随着行人相继跑离场景视野,每个人占据区域面积过小无法划分到时空立方体内,从而导致漏检。
3 实验讨论
3.1 双流分支融合有效性分析(消融实验)
为了验证本文方法所用的运动分支与表观分支融合机制的有效性,本节开展消融研究。具体而言,基于融合系数α和β的不同设置值在UCSD Ped2进行实验:a)α=0,β=1,仅使用表观信息进行异常检测;b)α=0.5,β=0.5,同时使用表观信息与运动信息进行异常检测;c)α=1,β=0,仅使用运动信息进行异常检测。表4展示了上述三种系数设置下的EDR和AUC指标对比结果,能够发现,通过表观信息与运动信息的加权融合能够有效提升实驗表现,有力说明了其有效性。
3.2 差异扩展化操作有效性分析
为了阐明改进PCANet中设计的差异扩展化操作的优势,本节在UCSD Ped2数据集上对改进PCANet与传统PCANet的实验表现进行对比,量化指标结果如表5所示。可以看出,改进PCANet在EDR与AUC指标上有了大幅度提升,进而验证了使用差异扩展化操作替代原始去均值化操作的优势。
3.3 超参数敏感性分析
为了探究超参数对模型性能,进而对实验结果的影响,本节在Ped2数据集上进行超参数敏感性分析,重点针对网络层数、滤波器尺寸及滤波器个数三个关键参数,实验结果使用视频帧层面 AUC指标值表示。表6展示了PCANet层数变化时对异常检测效果产生的影响,至于滤波器尺寸及个数对实验结果的影响,分别在表7和8中列出。由表6可以看出,对于单层PCANet,由于其视频事件刻画能力不足,相应实验结果较差。之后将网络层数增加至两层,异常检测精度提升,但持续增加层数精度提升有限。相反地,层数过多会出现精度下降的情况,同时延长检测运算耗时(特征提取步骤增多)。因此,本文以平衡检测精度与运行效率为目的,将网络层数设置为2。
由表7能够发现,滤波器尺寸在一定范围内变化时对异常检测效果影响不大,然而当其不断增大超过阈值后,由于难以捕获图像局部精细特征,致使异常检测精度大幅下降。而滤波器个数对实验结果整体干扰不大,但取值过高会导致特征图映射阶段卷积运算增多,增加异常推理耗时。
4 结束语
本文提出一种面向边缘端设备的轻量化异常事件检测方法LVAD。首先,将原始视频序列划分为多个局部时空立方体,并提取相应的梯度特征立方体与光流特征立方体;其次,引入改进PCANet获取梯度特征立方体对应的高层次分块直方图特征;再次,基于每个局部块的直方图特征计算其表观异常得分,同时基于内部像素光流幅值求和计算运动异常得分;最后,将表观与运动异常得分进行加权融合,使用单类别分类器判别异常局部块,实现运动与表观异常事件联合检测与定位。所使用的PCANet属于架构简洁的轻量化深度学习模型,特征提取过程无须耗费大量计算资源反复进行参数訓练,因此可以高效部署到边缘端设备上。在公开标准数据集上的实验结果表明,本文方法在低算力需求下取得了优异的异常事件检测表现。然而,该方法依赖视频序列RGB图像对应的特征表示,容易受到由可见光透视投影引起的目标尺度变化影响,距离摄像机设备远近不同的同类别目标在视频图像中所占区域面积大小变化极大,致使异常检测结果不佳。因此,未来工作中考虑在PCANet中设计金字塔卷积结构,以精确捕获不同尺度目标细节,从而提升异常检测效果。
参考文献:
[1]Luo Weixin,Liu Wen,Gao Shenghua.Remembering history with con-volutional LSTM for anomaly detection[C]//Proc of IEEE International Conference on Multimedia and Expo.2017:439-444.
[2]Zhong Yuanhong,Chen Xia,Hu Yongting,et al.Bidirectional spatio-temporal feature learning with multiscale evaluation for video anomaly detection[J].IEEE Trans on Circuits and Systems for Video Technology,2022,32(12):8285-8296.
[3]Le V T,Kim Y G.Attention-based residual autoencoder for video ano-maly detection [J].Applied Intelligence,2023,53(3):3240-3254.
[4]Wang Le,Tian Junwen,Zhou Sanping,et al.Memory-augmented appearance-motion network for video anomaly detection[J].Pattern Recognition,2023,138:109335.
[5]孙敬波,季节.视频监控下利用记忆力增强自编码的行人异常行为检测 [J].红外与激光工程,2022,51(6):368-374.(Sun Jingbo,Ji Jie.Memory-augmented deep autoencoder model for pedestrian abnormal behavior detection in video surveillance [J].Infrared and Laser Engineering,2022,51(6):368-374.)
[6]肖进胜,郭浩文,谢红刚,等.监控视频异常行为检测的概率记忆自编码网络 [J].软件学报,2023,34(9):4362-4377.(Xiao Jinsheng,Guo Haowen,Xie Honggang,et al.Probabilistic memory auto-encoding network for abnormal behavior detection in surveillance videos[J].Journal of Software,2023,34(9):4362-4377.)
[7]于晓升,许茗,王莹,等.基于卷积变分自编码器的异常事件检测方法 [J].仪器仪表学报,2021,42(5):151-158.(Yu Xiaosheng,Xu Ming,Wang Ying,et al.Anomaly detection method based on con-volutional variational auto-encoder[J].Chinese Journal of Scienti-fic Instrument,2021,42(5):151-158.)
[8]钟友坤,莫海宁.基于深度自编码-高斯混合模型的视频异常检测方法 [J].红外与激光工程,2022,51(6):375-381.(Zhong Youkun,Mo Haining.A video anomaly detection method based on deep autoencoding Gaussian mixture model [J].Infrared and Laser Engineering,2022,51(6):375-381.)
[9]Saypadith S,Onoye T.Video anomaly detection based on deep generative network [C]// Proc of IEEE International Symposium on Circuits and Systems.2021:1-5.
[10]Nguyen T N,Meunier J.Anomaly detection in video sequence with appearance-motion correspondence [C]// Proc of IEEE/CVF International Conference on Computer Vision.2019:1273-1283.
[11]周航,詹永照,毛启容.基于时空融合图网络学习的视频异常事件检测 [J].计算机研究与发展,2021,58(1):48-59.(Zhou Hang,Zhan Yongzhao,Mao Qirong.Video anomaly detection based on space-time fusion graph network learning[J].Journal of Computer Research and Development,2021,58(1):48-59.)
[12]Vaswani A,Shazeer N,Parmar N,et al.Attention is all you need[C]//Advances in Neural Information Processing Systems.2017.
[13]Feng Xinyang,Song Dongjin,Chen Yuncong,et al.Convolutional Transformer based dual discriminator generative adversarial networks for video anomaly detection [C]// Proc of the 29th ACM International Conference on Multimedia.New York:ACM Press,2021:5546-5554.
[14]Lee J,Nam W J,Lee S W.Multi-contextual predictions with vision transformer for video anomaly detection[C]//Proc of International Conference on Pattern Recognition.2022:1012-1018.
[15]劉成明,薛然,石磊,等.融合门控自注意力机制的生成对抗网络视频异常检测 [J].中国图象图形学报,2022,27(11):3210-3221.(Liu Chengming,Xue Ran,Shi Lei,et al.The gaining self-attention mechanism and GAN integrated video anomaly detection[J].Journal of Image and Graphics,2022,27(11):3210-3221.)
[16]Chan T,Jia Kui,Gao Shenghua,et al.PCANet:a simple deep learning baseline for image classification? [J].IEEE Trans on Image Processing,2015,24(12):5017-5032.
[17]Mahadevan V,Li Weixin,Bhalodia V,et al.Anomaly detection in crowded scenes[C]//Proc of IEEE Computer Society Conference on Computer Vision and Pattern Recognition.2010:1975-1981.
[18]Mehran R,Oyama A,Shah M,et al.Abnormal crowd behavior detection using social force model[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.2009:935-942.
[19]Xu Dan,Yan Yan,Ricci E,et al.Detecting anomalous events in videos by learning deep representations of appearance and motion [J].Computer Vision and Image Understanding,2017,156:117-127.
[20]Wu Peng,Liu Jing,Li Mingming,et al.Fast sparse coding networks for anomaly detection in videos[J].Pattern Recognition,2020,107:107515.
[21]Nawaratne R,Alahakoon D,De Silva D,et al.Spatiotemporal anomaly detection using deep learning for real-time video surveillance[J].IEEE Trans on Industrial Informatics,2019,16(1):393-402.
[22]胡正平,赵梦瑶,辛丙一.结合全局与局部视频表示的视频异常检测算法[J].模式识别与人工智能,2020,33(2):133-140.(Hu Zhengping,Zhao Mengyao,Xin Bingyi.Video anomaly detection algorithm combining global and local video representation[J].Pattern Recognition and Artificial Intelligence,2020,33(2):133-140.)
[23]Guo Aibin,Guo Lijun,Zhang Rong,et al.Self-trained prediction mo-del and novel anomaly score mechanism for video anomaly detection[J].Image and Vision Computing,2022,119:104391.
[24]Ramachandra B,Jones M,Vatsavai R.Learning a distance function with a siamese network to localize anomalies in videos[C]//Proc of IEEE Winter Conference on Applications of Computer Vision.2020:2598-2607.
[25]Zhang Qianqian,Feng Guorui,Wu Hanzhou.Surveillance video ano-maly detection via non-local U-Net frame prediction[J].Multimedia Tools and Applications,2022,81(19):27073-27088.
[26]Kommanduri R,Ghorai M.Bi-READ:bi-residual autoEncoder based feature enhancement for video anomaly detection[J].Journal of Visual Communication and Image Representation,2023,95:103860.
[27]Wu Chongke,Shao Sicong,Tunc C,et al.An explainable and efficient deep learning framework for video anomaly detection [J].Cluster Computing,2021,25:2715-2737.
[28]Fan Yaxiang,Wen Gongjian,Li Deren,et al.Video anomaly detection and localization via gaussian mixture fully convolutional variational autoencoder[J].Computer Vision and Image Understanding,2020,195:102920.
[29]Song Hao,Sun Che,Wu Xinxiao,et al.Learning normal patterns via adversarial attention-based autoencoder for abnormal event detection in videos[J].IEEE Trans on Multimedia,2019,22(8):2138-2148.
[30]Deepak K,Chandrakala S,Mohan C K.Residual spatiotemporal autoencoder for unsupervised video anomaly detection [J].Signal,Image and Video Processing,2021,15(1):215-222.
[31]Ali M M.Real-time video anomaly detection for smart surveillance[J].IET Image Processing,2023,17(5):1375-1388.
[32]Szymanowicz S,Charles J,Cipolla R.Discrete neural representations for explainable anomaly detection[C]//Proc of IEEE Winter Confe-rence on Applications of Computer Vision.2022:148-156.
[33]Chen Tianyu,Hou Chunping,Wang Zhipeng,et al.Anomaly detection in crowded scenes using motion energy model [J].Multimedia Tools and Applications,2018,77(11):14137-14152.
[34]Zhou Shifu,Shen Wei,Zeng Dan,et al.Spatial-temporal convolutional neural networks for anomaly detection and localization in crowded scenes[J].Signal Processing:Image Communication,2016,47:358-368.
[35]Aziz Z,Bhatti N,Mahmood H,et al.Video anomaly detection and localization based on appearance and motion models[J].Multimedia Tools and Applications,2021,80(17):25875-25895.
[36]Zhang Sijia,Gong Maoguo,Xie Yu,et al.Influence-aware attention networks for anomaly detection in surveillance videos[J].IEEE Trans on Circuits and Systems for Video Technology,2022,32(8):5427-5437.
[37]Sabih M,Vishwakarma D K.A novel framework for detection of motion and appearance-based anomaly using ensemble learning and LSTMs [J].Expert Systems with Applications,2022,192:116394.
[38]Xia Limin,Li Zhenmin.An abnormal event detection method based on the Riemannian manifold and LSTM network [J].Neurocomputing,2021,463:144-154.
