
基于词性标注的启发式在线日志解析方法
2024-02-18 08:13蒋金钊傅媛媛徐建
计算机应用研究 2024年1期
蒋金钊 傅媛媛 徐建
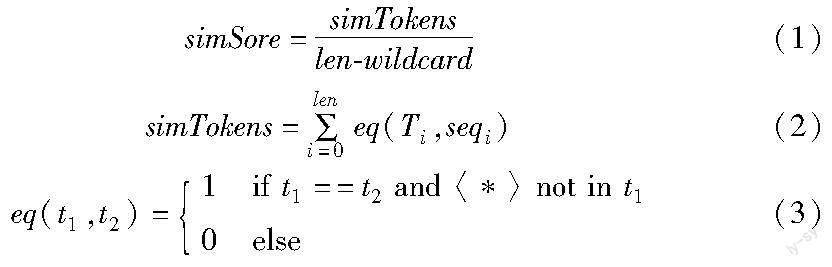
摘 要:为了解决现有启发式日志解析方法中日志特征表示区分能力不足导致解析精度低、泛化差的问题,提出了一种启发式在线日志解析方法PosParser。该方法使用来源于触发词概念的功能词序列作为特征表示,包含解决复杂日志易过度解析问题的两阶段检测方法和处理变长参数日志的后处理流程。PosParser在16个真实日志数据集上取得了0.952的平均解析准确率,证明了功能词序列具有良好区分性、PosParser有良好的解析效果和鲁棒性。
关键词:日志分析;日志解析;触发词提取;词性标注;系统运维
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)01-033-0217-05
doi:10.19734/j.issn.1001-3695.2023.05.0212
Heuristic online log parsing method based on part-of-speech tagging
Abstract:To solve the problems of low parsing accuracy and poor generalization caused by the insufficient distinguishing abi-lity of log feature representations for logs used in existing heuristic log parsing methods,this paper proposed PosParser,a heuristic online log parsing method.The method used function token sequence(FTS) derived from the concept of trigger words as feature representations,and consisted of the two-stage detection method for solving the problem of complex logs that were prone to over-parsing,and the post-processing for dealing with variable-length parameter logs.PosParser achieved an average parsing accuracy of 0.952 on 16 real-life log datasets.The results demonstrate that FTS has adequate distinguishing ability for logs and PosParser is effective and robust.
Key words:log analysis;log parsing;trigger word extraction;part-of-speech tagging;system maintenance
0 引言
现代计算机系统往往被期望能够提供7×24小时的无间断服务,但随着计算机系统复杂程度的不断增加,即使技术人员花费大量的努力来维持系统的稳定和可用,各种软硬件的故障仍然难以避免。计算机系统的复杂性也导致了通过人力检测和修复故障的困难程度在不断提高。在此背景下,基于机器学习或深度学习的自动化智能故障发现与根因诊断技术具有很高的研究价值,受到了广泛关注。日志作为系统运行的重要产物,由系统中的日志输出语句产生,能够反映系统的动态特征及系统发生故障时的上下文信息[1]。日志既包含重要的系统运行时信息,也在各个系統中常常使用,使之成为了多种智能运维任务的数据支持,如异常检测[2,3]、故障诊断[4]、故障预测[5]。日志是典型的非结构化数据,但上述各种基于学习的智能运维方法需要结构化数据作为输入。因此,日志解析,即将非结构化日志文本转换为结构化日志事件的过程,是这些方法中重要的第一步。一条结构化日志由日志事件模板和动态参数组成,可以通过获取日志事件模板或者识别动态参数完成日志解析。现有的日志解析方法大致可以分为基于规则的、基于静态代码分析的[6]和基于数据驱动的自动化日志解析方法三类。基于规则的日志解析方法需要针对不同的日志数据人工设计规则,即预先定义日志事件模板,然后与每条日志消息进行匹配;基于静态代码分析的日志解析方法考虑到源代码中的日志输出语句包含了日志事件信息,期望通过分析程序源代码,从日志输出语句中获取日志事件模板。由于日志数据的特点,上述两类方法的泛用性通常很差。为了提高日志解析方法的适用性和降低人力开销,以数据驱动的自动化日志解析方法受到了广泛关注,这类方法期望从日志数据中学习到日志事件模板或完成动态参数识别。现有的基于数据驱动的日志解析方法使用的技术可分为如下几类[7]:频繁项目挖掘、聚类、启发式和其他。根据工作模式的不同还可以将日志解析方法分为离线和在线方法。由于在线解析模式更能够满足现代计算机系统实时的日志分析需求,近年来的日志解析器多支持在线模式或者在线与离线混合模式。
启发式的日志解析方法与其他方法相比具有轻量级的特点,同时其流式的处理过程符合在线工作模式,具有较高的研究价值。但现有的多数启发式日志解析方法存在解析准确率不高和泛用性不强的问题,产生这些缺陷的主要原因是这些方法使用的日志特征表示以及设计的日志解析流程区分性不足,无法很好地处理由不同系统产生的异构且结构复杂的日志。日志事件涉及一个或多个参与者,即计算机系统组件,描述了在特定时间系统状态的变化和系统事件的发生。在自然语言处理领域的事件检测任务[8]中,触发词是区分不同事件的重要标准。受到这一概念的启发,本文认为日志事件同样存在触发词,在不同事件产生的日志中大概率不同,但在由同一事件产生的日志中相同,可以作为一种具有良好区分性的日志特征表示。由于日志文本中通常存在大量的非字典词以及不具备完整句子结构,针对自然语言的触发词提取方法无法直接应用于日志文本。考虑到触发词多为动词和名词,本文基于词性标注,提取出日志中动词和部分名词,构建日志特征表示,称做功能词序列(function token sequence,FTS),并在此基础上提出了一种启发式日志解析方法PosParser。为了评估FTS的区分性和PosParser的有效性和泛用性,本文使用16个真实日志数据集进行了充分的实验。实验结果表明:FTS具有很好的区分性。PosParser在取得优于以往方法的解析效果时还具有较好的鲁棒性。本文的贡献总结如下:a)将事件抽取任务中的触发词概念运用到日志解析任务中,提出了FTS作为启发式在线日志解析方法中的日志特征表示;b)基于FTS,提出了一种启发式在线日志解析方法PosParser,包含用于解决长日志易于出现过度解析的问题的两阶段检查方法以及处理变长参数日志的基于最长公共序列(longest common sequence,LCS)的后处理流程。
1 相关工作
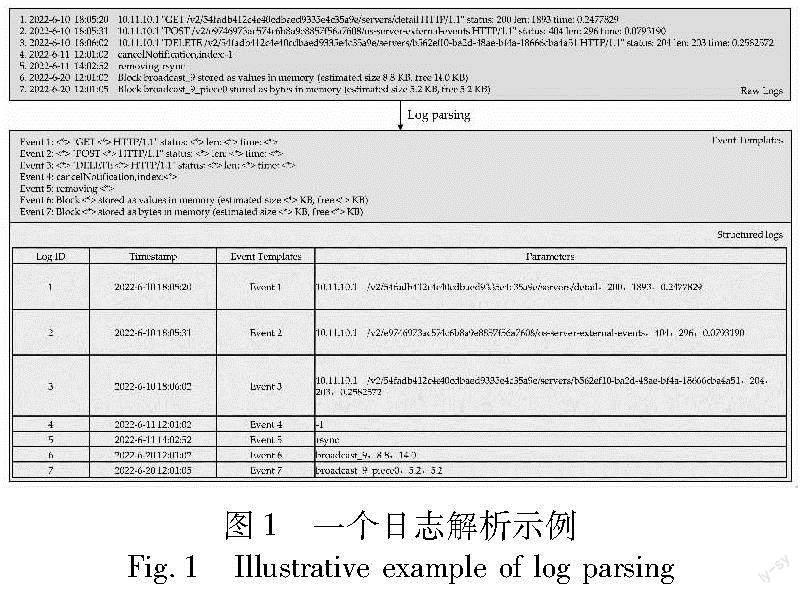
图1展示了一个日志解析过程的示例,原始日志经过日志解析后产生日志事件模板和结构化日志两部分数据。一条原始日志消息通常包括日志头和日志内容两部分。日志头中会含有时间戳、严重等级等表明日志产生时间、产生来源和重要性的信息,这些信息一般无法作为判断日志事件归属的依据;日志内容则可以分为静态常量和动态参数两部分,常量是系统编程人员在日志输出语句中固定的字符部分,参数是在系统中变量的值,是在运行时才能确定的状态信息。日志中的常量和通配符“〈*〉”构成了日志事件模板,通配符替代了参数在日志中的位置。日志解析的目标是在原始的日志消息中识别出日志事件模板和动态参数,形成结构化日志数据。
现代计算机系统产生的日志数据通常具有数量庞大、异构与组成复杂以及处于演化状态的特点,使得基于规则的和基于静态代码分析的日志解析方法在实践中通常难以使用。基于数据驱动的自动化日志解析方法期望从原始日志数据中学习到日志事件模板或者完成动态参数的识别。各种基于数据驱动的日志解析方法使用的技术大致可分为频繁项目挖掘[9,10]、聚类[11,12]、启发式和其他,例如基于LCS的流式在线日志解析方法Sepll[13];将日志解析视做多目标优化问题,基于遗传算法的MoLFI[14]以及基于深度学习的日志解析方法NuLog[15]。
基于频繁项目挖掘的日志解析需要多次扫描数据集,在处理大容量日志数据时会出现性能问题,基于聚类的日志解析方法的解析准确率受参数设置影响较大。相较之下,启发式日志解析方法设计不同的日志特征表示逐步将日志划分到不同的簇,具有轻量级的特点,同时其处理流程符合在线工作模式,更能满足日志的实时处理需求。例如AEL[16]首先提出了两条启发式规则识别日志中的动态参数,然后根据每条日志中单词和参数个数的不同将日志划分到不同的组,最后在每一组中产生最后的日志事件模板。IPLoM[17]则定义了三种启发式规则来逐步划分日志数据,它们分别是按日志的令牌数划分、按单词出现数最少的列位置上的令牌划分和通过搜索满足双射关系的单词位置划分日志。Drain[18]首先将日志中的令牌数目作为划分依据,然后使用了前缀树的方式检查日志的前几个令牌进一步划分日志,同时定义了日志之间的相似度计算模型作为最终的划分标准。ML-Parser[19]构建了一个具有两层框架的在线日志解析方法,其第一部分使用与Drain类似的前缀树技术,用于初步划分日志;第二部分则基于LCS进行更细粒度的处理。
2 PosParser
2.1 工作流程
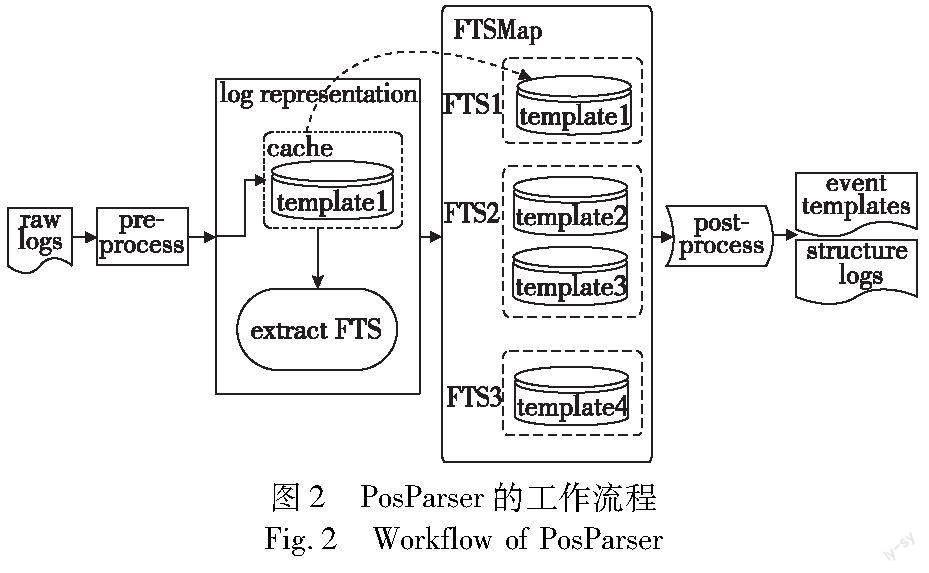
PosParser的基本工作流程如图2所示,它由预处理、日志表示、日志集合组织和后处理四个部分组成。当一条日志消息进入解析器后,首先进行预处理流程,提取出日志内容部分,并使用简单的正则匹配识别日志内容中的常见参数;然后在日志表示流程中提取日志的FTS,或者经由缓存结构跳过FTS提取。在日志集合组织流程中,PosParser利用FTS和Hashmap结构管理日志集合的生成、搜索与更新,在输出之前的后处理流程中将处理具有变长参数的日志。
2.2 预处理
PosParser的预处理流程由两部分工作构成:a)日志内容的提取,一條日志消息由日志头和日志内容两部分组成,日志头部包含时间戳、严重性等级等信息,与日志的事件归属无关,因此需要使用正则表达式获取日志内容部分;b)常见变量替换,已有的工作已经证明[20],即使只设计少量的正则表达式来替换日志内容中的变量,也可极大提高日志解析的效果。预处理阶段消除的变量应该是如IP地址、URL和数字等,常见而明确的变量。PosParser默认设计了正则表达式识别日志内容中的IP地址、内存地址、文件地址和时间四类变量,并使用通配符“〈*〉”替换。用户可以自行设计针对不同日志的正则表达式。
2.3 日志表示
PosParser在日志表示流程中会先通过缓存结构确定当前处理日志是否可以直接并入某个日志集合,若不能则转入日志FTS的提取。算法1展示了FTS的提取方法。算法1中a)使用空格、等号和冒号对日志内容分词;b)清洗掉分词后的令牌序列中疑似参数的部分,主要有如下几类:含有数字的令牌;位于等号和冒号后的一个令牌;在只含有字母和特殊字符的令牌中需要清洗的字符串和程序错误信息。这些疑似参数的部分会影响后续无空格英文分词和词性标注。获取清洗后的令牌序列后,算法中的c)对该序列做进一步的无空格英文分词,这一步骤主要有两个目的:一是去除部分令牌中的特殊字符,避免影响后续词性标注工作;二是更好地暴露日志中的触发词信息。算法中d)使用词性标注工具获取经过两次分词后令牌的词性,e)获取日志的FTS。具体地,提取出其中的所有动词和第一个名词,如果一条日志经过两次分词后的令牌序列长度大于3,算法将其视做长日志,将提取出的内容组合作为该日志的FTS;否则视做短日志,单独将动词序列作为FTS,这是由于短日志的信息量少,其中的名词很可能是变量。为了保证FTS的区分性,如果无法提取出动词,使用名词和经过两次分词后的第一个令牌的组合作为FTS;如果无法提取出任何动词或名词信息,将第一次分词后的令牌序列中的第一个令牌作为FTS。
算法1 提取FTS
输入:一条日志内容cnt。
输出:日志内容的FTS,fts。
a) wordTokens=split(cnt);
b) cleanedTokens=cleanMayParameters(wordTokens);
c) pieceTokens=splitWithoutSpace(cleanedTokens);
d) partOfSpeechs=posTag(pieceTokens);
e) fts=extractFTS(wordTokens,cleanedTokens,partOfSpeechs);
f) return fts;
FTS的提取流程要经过两次分词、一次清洗、词性标注和最终的组合,其中词性标注是一件相对耗时的事情。由于相同或者来源同一事件的日志具有很大概率相邻出现,PosParser加入了缓存机制,以提高解析效率。具体地,缓存结构中常有最近日志并入或新增的日志集合,当一条日志进入日志表示流程时,会首先与缓存中的日志集合进行相似度计算,如果相似度为1,则直接并入该日志集合,否则转入提取FTS。这样可以避免非必要的FTS提取和日志集合搜索。
2.4 日志集合组织
日志集合组织流程中涉及三种对象:FTSMap、事件集合和日志集合。每条日志最终将流入某一个日志集合。日志集合管理日志编号集、相似度阈值和事件模板。事件集合管理其下的日志集合,这些日志集合中的日志具有相同的FTS。FTSMap以HashMap为结构,使用FTS作为键,事件集合作为值。当一条日志经过日志表示流程后,将进入FTSMap,使用日志的FTS查找事件集合。如果没有找到,PosParser将使用这条日志新建事件集合和日志集合,放入FTSMap中;如果找到,将使用两阶段检查的方法搜索该事件集合,决定是否能够并入某一日志集合。并入日志集合将引起日志集合的更新,否则在该事件集合下新建日志集合。
1)日志集合的搜索 日志能否并入事件集合下的某个日志集合需要进行两阶段检查,一是阈值检查。每一个日志集合会具有不同的相似度阈值,日志与事件模板的相似度需要大于日志集合目前的相似度阈值。使用T表示当前日志集合的事件模板,seq表示当前日志的令牌序列,相似度的计算方式表示如下:
其中:len表示模板和日志的令牌长度;simTokens表示T与seq对应位置上相同且不含有通配符的令牌个数;wildcard表示在模板T中的令牌含有通配符“〈*〉”的个数。如果计算得到的simTokens大于当前日志集合的相似度阈值,将尝试合并当前日志和日志模板,生成新的日志模板Tn,比较Tn与T,如果产生了新的参数位置,将开始第二阶段的参数位置检查。检查Tn和T对应位置的令牌,找到新增的参数位置索引。依次检查序列T和序列seq中索引位置上的令牌,使用arg1和arg2表示,判断该位置是否为变量,主要有如下几种情况:a)arg1和arg2中同时存在字母、数字和特殊字符,認为该位置为变量;b)arg1和arg2中含有数字和字母时,检查arg1和arg2的字母组成是否相同。相同判断该位置为变量,反之为常量;c)arg1和arg2中含有特殊字符和字母或全由字母组成。这种情况下,取模板Tn中目前检查位置的令牌、前一位置的令牌和后一位置的令牌构成序列进行词性标注,若前一位置为一般名词或者动词,判断该参数位置为变量;若前一位置为介词,判断arg1和arg2的词性,若为一般名词,判断该位置为变量,否则为常量。
参数位置检查的目的是通过检查参数构成的相似性或语义的相似性来解决长日志由于相似度过高易出现过度解析的问题。以图1中的日志6、7为例,这两条日志被定义于不同的日志模板,模板之间只有一个令牌不同,阈值检查时计算相似度为0.89。若只考虑相似度,这两条日志将被合并;在参数位置检查中,两条日志在新产生的参数位置上的值分别为“va-lues”和“bytes”,不具有结构上的相似性,都不是一般名词,且前一个令牌为介词“for”,判定该位置为常量,不应该合并。
一次检查中可能有多个参数位置,当每个参数位置都被判定为变量,则认为通过检查。如果在搜索日志集合的过程中有多个日志集合满足要求,日志应该并入相似度值最大的日志集合;若没有一个日志集合通过检查,PosParser会使用当前的日志令牌序列生成新的日志集合。
2)日志集合的新增 存在两种情况:a)在日志集合搜索中无法找到通过两次检查的日志集合,PosParser会在当前事件集合中生成新的日志集合;b)使用日志的FTS在FTSMap无法找到对应的事件集合,此时PosParser新增日志集合并放入新建的事件集合,然后将事件集合放入FTSMap。新的日志集合使用当前待处理的令牌序列作为日志集合的事件模板,同时设置日志集合的初始相似度阈值。日志集合的初始相似度阈值stinit使用了文献[20]提出的动态设置方法,表示如下:
其中:st是解析器的输入参数,tokenLen为事件模板的长度,digNum是序列中含有数字的令牌个数。
3)日志集合的更新 新的日志序列并入日志集合会引起日志集合的更新:a)将当前日志的编号加入日志集合管理的日志编号集;b)事件模板的更新。将事件模板与并入的日志对应位置上不同的令牌使用通配符“〈*〉”替换;c)相似度阈值的更新。PosParser同样使用了文献[20]提出的相似度阈值更新规则,表示如下:
stn=min{1,stn-1+0.5* logbase(η+1)}(5)
其中:η初始设置为0,每当事件模板中有令牌被替换为通配符“〈*〉”,将导致η的值增加1。base定义如下:
base=max{2,digNum+1}(6)
其中:base和digNum只在生成日志集合时计算一次。
2.5 后处理
大部分事件集合下只有一个日志集合,这部分日志集合的事件模板可以直接输出,但有少部分事件集合下有多个日志集合。引起这一情况的原因主要有两个:a)变长日志的存在,变长日志是指来源于同一事件但参数部分长度不同的日志,这部分日志需要合并;b)由于词性标注工具的精度问题导致FTS在极少部分日志上的区分性不足,将不属于同一事件的日志划分到了同一事件集合下,这部分日志不需要合并。PosParser在后处理阶段中只合并由于变长日志存在而产生的多个日志集合,具体地,解析器会依次检查事件集合,事件集合下的日志集合数目如果大于3,考虑合并操作。首先识别哪些事件模板来源于同一事件。由于变量已经在先前的处理中被替换为了“〈*〉”,来源于同一事件的事件模板应当具有相同的常量令牌序列。因此按照事件模板的常量令牌序列对日志集合进行分组,在具有多个日志集合的组中使用最长公共子序列算法以及其回溯算法,提取出最终的事件模板。
3 实验及分析
3.1 数据集
参照以往的工作,本文使用了Zhu等人[7]收集的开源日志数据集LogHub,LogHub包含总数据量为77 GB的来源于16个不同系统的日志数据,这些系统分别为分布式系统、超级计算集群、操作系统、移动设备、应用服务器以及独立软件。LogHub在每个系统的日志数据集中选取出了大小为2 KB的子数据集,并标注了日志对应的事件模板。同时,本文在HDFS和BGL上抽取了大小从300 KB至100 MB的日志数据集,并使用LogHub提供的事件模板进行标注。
3.2 评价指标
本文采用解析准确率(parsing accuracy,PA)[7]来评价方法的有效性。PA定义为正确解析的日志与日志总数的比值。日志经过解析后会形成日志簇,每一簇的日志具有相同的事件模板,当且仅当解析后形成的日志簇与标注数据中对应事件模板的日志簇完全相同时才认为这些日志被正确解析。例如,如果日志序列[E1,E2,E3,E4]被解析为[E1,E2,E2,E3],则PA为0.5,因为第二和第三条日志被错误解析到同一日志簇中。相较于精确率、召回率和F1值,PA在评价方法有效性时更加严格。
3.3 实验设置
本文基于PyCharm,使用Python实现了PosParser。在预处理流程中,为与其他基线方法保持一致,采用LogPai[7]中预设的正则表达式提取日志内容并消除常用变量。方法的后续流程中,使用了wordninja作为无空格英文分词工具,NLTK作为词性标注工具。除敏感性实验外,解析器输入参数st的取值均为0.5。实验环境为Windows 10 64位操作系统,处理器为Intel CoreTM i7-10700K CPU @ 3.80 GHz。
3.4 FTS的区分性
在启发式的日志解析方法中,使用的启发式规则或者日志的特征表示是方法中的重要一环。为证明本文提出的FTS具有良好的区分性,可以有效地作为启发式日志方法中日志消息划分的指导依据,本节进行了两方面的相关实验。
a)有关日志解析过程中涉及参数,即式(4)中的解析器输入参数st的敏感性实验。st决定了日志集合的初始相似度閾值,当st的取值较小时,容易导致日志的异常合并;当st取中间值时,容易出现长日志的过度解析问题;当st的取值过大时,日志易于被过度解析。st的值过大或者过小都会导致解析效果不佳,其值的确定是一项烦琐的工作。该组实验设置st的取值为[0.1,0.9],步长为0.05。实验结果如图3所示。
当st的取值小于0.5时,在所有的日志集上的解析效果都对st取值的变化不敏感;当st取值在0.5~0.7时,在13个日志集上的解析效果同时保持了稳定,在三个数据集上具有小幅度的变化;当st取值大于0.7后,在八个日志集上的解析效果仍然相对稳定,在六个数据集上的解析效果有明显下降,在Android和Mac日志数据上的解析效果呈现上升趋势。这初步证明了FTS具有良好的区分性,大部分不属于同一事件模板的日志不会流入同一事件集合,不需要进行日志集合的搜索,st取值的变化无法影响这部分日志的解析,使得在低st取值时的解析效果呈现相对稳定的状态;同时,st取0.5时能够在大部分日志集上获得较优的解析效果,在少部分日志集上也只需要考虑高st值的调参工作,降低了参数设置的复杂性,提高了日志解析工作的自动化程度。
b)统计后处理流程之前的事件集合中的日志集合数目,进一步讨论FTS的区分性。统计结果如表1所示。表中展示了在FTSMap中含有一个日志集合、两个日志集合和大于两个日志集合的事件集合数目占FTSMap中所有事件集合数目的比值。从表1可以看到,在16个数据集中,含有一个日志集合的事件集合数量占比在所有数据集上都大于80%,同时该项数值在9个数据集上大于90%。含有两个日志集合的事件集合数量占比在13个数据集上小于10%;而含有大于两个日志集合的事件集合数量占比在12个数据集上小于5%,且该项数值在4个数据集上为0%。平均来看,90.32%的事件集合中只含有一个日志集合,只有3%的事件集合中含有超过两个的日志集合。这说明日志的FTS能够决定绝大部分日志的事件归属,只有小部分的日志需要参与日志集合搜索流程,进一步证明了FTS具有良好的区分性。
3.5 解析准确率对比
本节通过对比实验来证明PosParser方法的有效性,选取了经典的启发式方法作为对比方法,包括AEL[17]、IPLoM[18]和Drain[19]。各方法在16个大小为2 KB的数据集上的解析准确率结果如表2所示。表中的每一行对比了不同方法在同一数据集上的解析准确率,表中的每一列展示了某一方法在不同数据集上的解析准确率。为了使结果展示更清晰,表中的最后一行展示了不同方法的平均解析准确率,在某一数据集上的最优解析准确率使用了粗体标注。
从表2的结果可以看到,在16个数据集中,PosParser一共在15个数据集上取得了最优的解析准确率,同时取得了最优的平均解析准确率。若考虑所有的数据集,Drain的平均解析准确率为0.865,是对比方法中最优的。与Drain相比,PosParser的平均解析准确率提升了10.06%,证明了本文提出的方法是有效的,在绝大多数系统的日志数据集上都能够获取优于以往方法的解析准确率。
PosParser能够取得优于以往启发式日志解析方法的原因主要如下:a)采用了具有良好区分性的日志特征FTS表示作为日志的划分依据;b)针对具有复杂结构的日志提出了两阶段检查的方法缓解其容易出现过度解析的问题,使得在如Linux、Andriod和 OpenStack等数据集上的解析准确率有较为明显的提升;c)设计了后处理流程处理具有变长参数的日志,在含有典型的具有变长参数的日志的数据集,如HDFS、HPC和Proxifier,也获得了明显提升。
3.6 鲁棒性对比
为了探究面对不同体积日志时,日志解析方法能否保持稳定的解析准确率。本节使用了从HDFS和BGL中抽取的,大小从300 KB到100 MB的标注日志数据进行对比实验。实验设置与3.3节相同。实验结果如图4所示。其中图(a)是在HDFS数据集上的实验结果,当数据集大小为300 KB时所有方法都获得了较好的准确率,当数据集大小达到100 MB后,只有PosParser、AEL保持了较好的准确率,Drain和IPLoM的解析准确率明显下降;图(b)展示了在BGL数据集上的实验结果,当数据集体积大于300 KB后,所有方法的解析效果都有一定的下降,其中IPLoM准确率下降明显,但PosParser在大于300 KB的所有数据集上保持了相对稳定的解析准确率。这证明了PosParser在面对日志数据大小变化时能够保持稳定的解析效果,具有较好的鲁棒性。同时可以看到,相较其他方法,PosParser在所有数据集上都获得了很好的解析效果,进一步证明了PosParser的有效性。
4 结束语
日志解析是一项具有挑战性工作,受到自然语言处理领域事件抽取任务的启发,本文提出了一种基于词性标注的在线日志解析方法PosParser。PosParser的工作流程由预处理、日志表示、日志集合组织和后处理四个部分组成。在预处理中,使用正则表达式提取、日志内容并消除常见变量;在日志表示中,设计了FTS的提取流程;在日志集合组织中,提出了两阶段检查方法处理过度解析问题;在后处理流程中,使用最长公共子序列算法以及其回溯算法合并具有变长参数的日志。最后,本文在16个真实日志数据集上进行了充分的实验,证明了本文提出的功能词序列具有良好的区分性,设计的启发式日志解析方法不仅能获得优于以往启发式日志解析方法的解析准确性,还具有良好的鲁棒性。FTS的区分性依赖于词性标注工具的精度,本文设计的FTS提取流程中的很多操作正是为了减少词性标注不精确带来的影响。在未来工作中,将考虑如何优化日志特征表示的提取流程并进一步提高区分性。
参考文献:
[1]贾统,李影,吴中海.基于日志数据的分布式软件系统故障诊断综述[J].软件学报,2020,31(7):1997-2018.(Jia Tong,Li Ying,Wu Zhonghai.Survey of state-of-the-art log-based failure diagnosis[J].Journal of Software,2020,31(7):1997-2018.)
[2]Li Xiaoyun,Chen Pengfei,Jing Linxiao,et al.SwissLog:robust and unified deep learning based log anomaly detection for diverse faults[C]//Proc of the 31st IEEE International Symposium on Software Reliability Engineering.Piscataway,NJ:IEEE Press,2020:92-103.
[3]Huang Shaohan,Liu Yi,Fung C,et al.HitAnomaly:hierarchical transformers for anomaly detection in system log[J].IEEE Trans on Network and Service Management,2020,17(4):2064-2076.
[4]Yuan Ding,Mai Haohui,Xiong Weiwei,et al.SherLog:error diagnosis by connecting clues from run-time logs[J].ACM SIGPLAN Notices,2010,45(3):143-154.
[5]Li Longhao,Znati T.AtFP:attention-based failure predictor for extreme-scale computing[C]//Proc of the 13th International Conference on Reliability,Maintainability,and Safety.Piscataway,NJ:IEEE Press,2022:23-27.
[6]Nagappan M,Wu Kesheng,Vouk A M.Efficiently extracting operational profiles from execution logs using suffix arrays[C]//Proc of the 20th IEEE International Conference on Software Reliability Enginee-ring.Piscataway,NJ:IEEE Press,2009:41-50.
[7]Zhu Jieming,He Shilin,Liu Jinyang,et al.Tools and benchmarks for automated log parsing[C]//Proc of the 41st IEEE/ACM International Conference on Software Engineering:Software Engineering in Practice.Piscataway,NJ:IEEE Press,2019:121-130.
[8]馬春明,李秀红,李哲,等.事件抽取综述[J].计算机应用,2022,42(10):2975-2989.(Ma Chunming,Li Xiuhong,Li Zhe,et al.Survey of event extraction[J].Journal of Computer Applications,2022,42(10):2975-2989.)
[9]Vaarandi R,Pihelgas M.LogCluster:a data clustering and pattern mi-ning algorithm for event logs[C]//Proc of the 11th International Conference on Network and Service Management.Piscataway,NJ:IEEE Press,2015:1-7.
[10]Dai Hetong,Li Heng,Chen Cheshao,et al.Logram:efficient log parsing using n-gram dictionaries[J].IEEE Trans on Software Engineering,2022,48(3):879-892.
[11]Xiao Tong,Quan Zhe,Wang Zhijie,et al.LPV:a log parser based on vectorization for offline and online log parsing[C]//Proc of IEEE International Conference on Data Mining.Piscataway,NJ:IEEE Press,2020:1346-1351.
[12]Hamooni H,Debnath B,Xu Jianwu,et al.LogMine:fast pattern recognition for log analytics[C]//Proc of the 25th ACM International on Conference on Information and Knowledge Management.New York:ACM Press,2016:1573-1582.
[13]Du Min,Li Feifei.Spell:online streaming parsing of large unstructured system logs[J].IEEE Trans on Knowledge and Data Enginee-ring,2019,31(11):2213-2227.
[14]Messaoudi S,Panichella A,Bianculli D,et al.A search-based approach for accurate identification of log message formats[C]//Proc of the 26th Conference on Program Comprehension.New York:ACM Press,2018:167-177.
[15]Nedelkoski S,Bogatinovski J,Acker A,et al.Self-supervised log parsing[M]//Machine Learning and Knowledge Discovery in Databases:Applied Data Science Track.Berlin:Springer-Verlag,2021:122-138.
[16]Jiang Zhenming,Hassan A E,Flora P,et al.Abstracting execution logs to execution events for enterprise applications(short paper)[C]//Proc of the 8th International Conference on Quality Software.Washington DC:IEEE Computer Society,2008:181-186.
[17]Makanju A A O,Zincir-Heywood A N,Milios E E.Clustering event logs using iterative partitioning[C]//Proc of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM Press,2009:1255-1264.
[18]He Pinjia,Zhu Jieming,Zheng Zibin,et al.Drain:an online log parsing approach with fixed depth tree[C]//Proc of IEEE International Confe-rence on Web Services.Piscataway,NJ:IEEE Press,2017:33-40.
[19]蒲嘉宸,王鵬,汪卫.ML-Parser:一种高效的在线日志解析方法[J].计算机应用与软件,2022,39(1):45-52.(Pu Jiachen,Wang Peng,Wang Wei.ML-Parser:an efficient and accurate online log parser[J].Computer Applications and Software,2022,39(1):45-52.)
[20]He Pinjia,Zhu Jieming,Xu Pengcheng,et al.A directed acyclic graph approach to online log parsing[EB/OL].(2018-06-12)[2022-06-30].https://arxiv.org/pdf/1806.04356.pdf.
