
基于自蒸馏与自集成的问答模型
2024-02-18 07:05王同结李烨
计算机应用研究 2024年1期
王同结 李烨
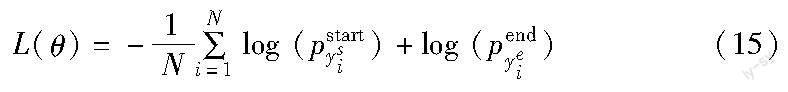
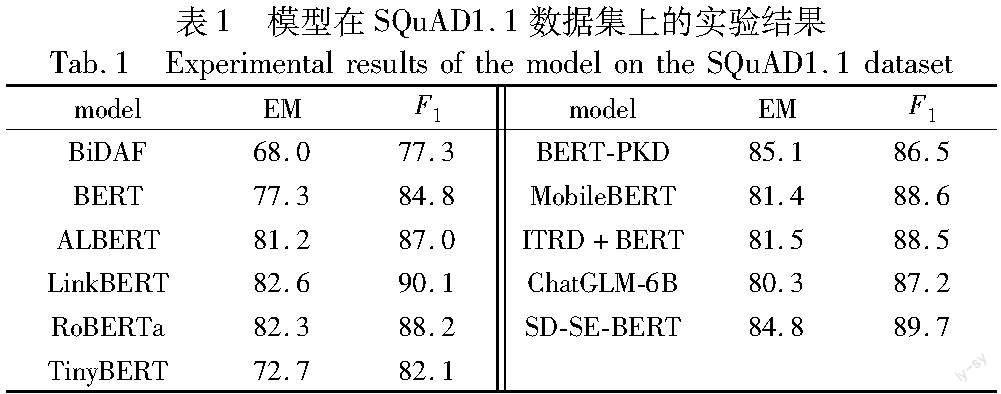
摘 要:知识蒸馏结合预训练语言模型是构建问答模型的主要方法之一,然而,这类方法存在知识转移效率低下、训练教师模型耗时严重、教师模型和学生模型能力不匹配等问题。针对上述问题,提出了一种基于自蒸馏与自集成的问答模型SD-SE-BERT。其中:自集成基于滑窗机制设计;学生模型采用BERT;教师模型由训练过程中得到的若干学生模型基于其验证集性能进行加权平均组合得到;损失函数利用集成后的输出结果和真实标签指导当前轮次的学生模型进行训练。在SQuAD1.1数据集上的实验结果表明,SD-SE-BERT的EM指标和F1指标相比较BERT模型分别提高7.5和4.9,并且模型性能优于其他代表性的单模型和蒸馏模型;相较于大型语言模型ChatGLM-6B的微调结果,EM指标提高4.5,F1指标提高2.5。证明SD-SE-BERT可以利用模型自身的监督信息来提高模型组合不同文本数据特征的能力,无须训练复杂的教师模型,避免了教师模型与学生模型不匹配的问题。
关键词:问答模型;知识蒸馏;集成学习;BERT
中图分类号:TP391.1 文献标志码:A 文章编号:1001-3695(2024)01-032-0212-05
doi:10.19734/j.issn.1001-3695.2023.05.0281
Question answering model based on self-distillation and self-ensemble
Abstract:Knowledge distillation combined with pre-trained language models is one of the primary methods for constructing question-answering models.However,these methods suffer from inefficiencies in knowledge transfer,time-consuming teacher model training,and mismatched capabilities between teacher and student models.To address these issues,this paper proposed a question-answering model based on self-distillation and self-ensemble,named SD-SE-BERT.The self-ensemble mechanism was designed based on a sliding window;the student model used BERT;the teacher model was derived from a weighted average combination of several student models during the training process,based on their performance on the validation set.The loss function used the output of the ensemble and the true labels to guide the training of the student model in the current round.Experimental results on the SQuAD1.1 dataset show that the EM and F1 scores of SD-SE-BERT are respectively 7.5 and 4.9 higher than those of the BERT model,and the models performance surpasses other representative single models and distillation models.Compared to the fine-tuning results of the large-scale language model ChatGLM-6B,the EM score was improved by 4.5,and the F1 score by 2.5.It proves that SD-SE-BERT can leverage the models supervision information to enhance the models capacity to combine different text data features,eliminating the need for complex teacher-model training and avoiding the problem of mismatch between teacher and student models.
Key words:question answering model;knowledge distillation;ensemble learning;BERT
0 引言
問答模型是自然语言处理中的热点研究领域。该任务的价值在于利用计算机帮助人类在大量文本中快速找到准确答案,从而减轻信息获取的成本[1],具有多样的落地场景。阅读理解任务中的跨度提取任务[2~4]的目标是从段落中预测出包含答案范围的跨度。由于其答案形式不局限于个别单词、数据集构建成本小且评估指标明确,利于测试机器对文本的理解。
目前,微调训练语言模型是解决此类任务的主要方法[5],其中最出名的预训练语言模型是Devlin等人[6]提出的BERT(bidirectional encoder representations from Transformers)。由于BERT采用MLM(masked language model)和NSP(next sentence prediction)这两种预训练任务,可以学习到更加全面和丰富的语言表示,提高下游任务的性能。其在问答数据集SQuAD1.1[7]上的表现一举超越了之前所发布的模型,成为自然语言处理领域的重要里程碑。Liu等人[8]在BERT的基础上构建了RoBERTa(robustly optimized BERT pretraining approach),在训练过程中加载更多的文本数据,使用动态掩盖(dynamic mas-king)策略随机掩盖短语或句子,能更好地学习到单词的上下文信息,在SQuAD1.1数据集上取得当时的最好结果。许多研究者注意到为语言模型新增加预训练任务可以有效提高模型性能,2022年Yasunaga等人[9]为原始BERT模型增加文档关系预测的预训练任务。以学习跨问题的依赖关系,在问答数据集HotpotQA和TriviaQA上的性能相比BERT提高了5%。一些研究者按照使用更多种预训练任务和更大量级的训练数据的思路,推出了大型语言模型(large language models),例如Chat-GPT[10]、讯飞星火、ChatGLM[11]等。这些大语言模型在人机对话以及其他NLP领域上迅速占据了统治地位。大语言模型的参数量和所采用的数据量十分惊人,比如ChatGPT的参数量高达1 750亿,采用的训练数据为45 TB,且仍在快速增长,总算力消耗约为3 640 PF-days。然而,部分研究者认为大模型的能力可能被高估,如文献[12]通过分析大型语言模型Codex证明,如果将任务目标替换,Codex的性能会大幅度下降,这表明大型语言模型的性能可能依赖于对训练语料的记忆。文献[13]通过在自制数据集上精调7B的LLaMA,在BIG-bench算数任务上取得和GPT-4相当的表现,证明在特定任务上微调预训练语言模型的训练方式依然有效,但会牺牲模型的通用性。
限制预训练模型应用范围的关键问题是模型的泛化性和复杂度[14]。引入集成学习是提高模型泛化性能的有效途径,例如Pranesh等人[15]通过集成多个BERT变体模型的前K个跨度预测,来确定最佳答案。这类方法的主要缺点是基础模型需要分别训练,导致训练成本过高,且集成后的模型的参数量庞大,难以在资源有限的环境中部署[16],因此,将大型模型与模型压缩技术相结合成为了研究热点。文献[17]通过Transformer distillation方法,使得BERT中具有的语言知识可以迁移到TinyBERT中,并设计了一种两阶段学习框架,在预训练阶段和微调阶段都进行蒸馏,确保TinyBERT可以从BERT充分学习到一般领域和特定任务两部分的知识。Yang等人[18]提出两阶段多教师知识蒸馏,预训练语言模型在下游任务上微调的同时能够从多个教师模型当中学习知识,缓解单个教师模型的过拟合偏置问题,在教师模型的选择一般采用固定权重或者随机选择某一个教师模型。Yuan等人[19]提出了一种动态选择教师模型的知识蒸馏方法,其基本假设是,由于训练样本的复杂性以及学生模型能力的差异,从教师模型中进行差异化学习可以提高学生模型的蒸馏性能。
知识蒸馏方法存在教师模型和学生模型不匹配导致知识转移效率低下问题[20,21],使得学生无法有效学习教师的表征,在推理期间相对教师模型会出现不同程度的性能下降[22]。自蒸馏是一种比较特殊的蒸馏模式,其利用训练到一定阶段的模型作为教师模型来提供蒸馏监督信号。在模型训练前期按正常方式训练,训练到指定轮数后将此刻的模型作为教师模型,指导后续的学生模型训练。Yang等人[23]截取ResNets训练过程中的前幾轮作为教师模型对后续训练进行知识蒸馏,在图像分类数据集CIFAR100和ILSVRC2012上取得了较好结果。
针对上述问题,设计了一种基于自集成与自蒸馏的问答模型SD-SE-BERT(self-distillation and self-ensemble BERT),将训练过程中各次迭代得到的学生模型集成起来作为教师模型,指导下一轮学生模型的学习。模型内容具体包括:设计一种基于加权平均的集成策略,并引入自蒸馏思想,将集成和自蒸馏结合;改进了一种数据增强模块,并设计出基于归并排序的答案输出模块。在问答数据集SQuAD1.1上进行实验,SD-SE-BERT在F1和EM指标上优于目前的问答模型。所提方法主要贡献为:a)将自集成与自蒸馏相结合,引入到跨度提取任务中,使得问答模型在每轮训练中学习到的知识得到及时传递,利用了模型本身提供的监督信息,有利于捕获和组合不同的文本数据特征以提高整体的预测能力;b)设计了以F1和EM(exa-ct match)的加权和作为权重的加权平均自集成策略。由于不需要预先训练出复杂的教师模型,避免了教师模型与学生模型不匹配的问题。而学生模型的结构和容量可以根据应用场景来确定;c)改进了EDA(easy data augmentation techniques)[24]数据增强技术,以此提供适量的噪声、并增加文本多样性,减轻模型对固定样本的过拟合。设计基于归并排序的答案输出模块,降低输出答案过程的复杂度。
1 提出的方法
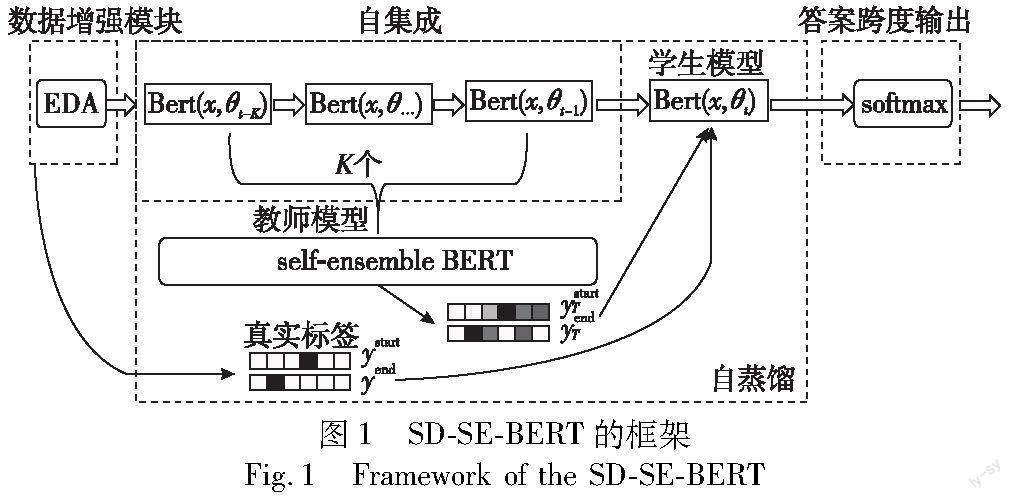
方法的流程框架如图1所示,由数据增强模块、自集成、自蒸馏、答案跨度输出四个部分构成。首先利用数据增强技术对样本进行扩充,在训练中按批提供给BERT模型。自集成基于滑窗机制设计,窗口中包含相对当前轮次的前K轮训练得到的学生模型。将K个学生模型基于其各自的验证集性能,采用加权平均的方法进行集成,集成的预测输出与真实标签提供给当前轮次训练的学生模型进行学习。最后,依据最终的学生模型的预测结果输出答案候选项。
1.1 数据增强模块
数据增强模块实现将样本扩充,在训练中按批提供给BERT,其是对EDA技术的一种改进实现。考虑到数据集中文本长度参差不齐的特性,模型的输入端添加改进的EDA进行数据增强操作。具体改进为,对样本中段落长度超出输入序列最大长度max_seq_length的上下文段落进行截断。为避免遍历寻找和比较最长文本的操作,统一将句子长度与max_seq_length比较得出EDA四种操作的概率。其次,由于跨度提取任务的样本标签(答案)是从问题文本中抽取的一段跨度文本,数据增强操作中,段落文本和答案文本需要同步更改。改进EDA后,训练集中的文本通过数据增强模块随机选择数据集中句子,按预设概率选择单词数量,执行以下增强操作:
a)同义词替换:从段落文本中随机选择n个不是stop word的单词。从总词汇表中随机选择这些单词的任意同义词进行替换。如果被替换掉的单词在答案文本出现,保持一致,替换相同同义词。
b)随机插入:从句子中随机选择n个不是停顿词的单词后,从总词汇表中随机选择这些单词的任意同义词,插入句子中的随机位置。
c)随机交换:随机选择句子中的两个单词并交换它们的位置,选择n次。
d)随机删除:随机删除句子中的n个单词。
1.2 自集成
首先,将BERT最后一层的输出结果进行softmax运算,得到段落中每个位置作为答案开始或结束的概率。
Pstart=softmax(W1,Jp),Pend=softmax(W2,Jp)(2)
其中:W1和W2是可以被训练的参数矩阵,Jp是BERT最后一层的输出结果,Pstart和Pend是段落中词向量分别作为答案的起始位置的概率。假设当前训练轮次为t,窗口大小设置为K,相对当前轮次t的前K轮模型为BERTK={BERTt-K ,BERTt-k ,…,BERTt-1},假设样本段落词序列为Xi=[x1,x2,…,xn]。BERTK预测此序列中词向量为开始位置的概率矩阵PKstart为
其中:PKstart的每一行为第t-k轮得到的BERT模型预测Xi各词向量为开始位置的概率序列。记录窗口内的K个历史模型的性能指标,针对跨度提取任务性能指标是EM与F1,得到EMK={EMt-K , EMt-k ,…, EMt-1}与F1K={F1t-K , F1t-k ,…, F1t-1}。使用EM和F1指标的加权和Acc代表模型的性能。
其中:a和b为权重系数,Z为归一化因子。由此得到前K轮模型输出在结果集成中的权重。在第t轮训练时,将PKstart与指标加权和AccK矩阵进行哈达玛运算。
其中:PS(X)为前t-K轮的K个BERT模型预测段落词序列Xi中所有词向量为开始位置的加权平均概率值序列。同理,可以得到前t-K轮BERT模型预测段落词序列X中所有词向量为结束位置的加权平均概率值序列PE(X)。
1.3 自蒸馏
在跨度提取类型的问答任务中,假设C是上下文段落,Q是问题,而A是段落中存在的答案,问答模型的目的是对概率分布p(A|C,Q)进行建模。通常将p(A|C,Q)拆开为预测答案在段落中的开始位置n与结束位置m。
p(A|C,Q;θ)=pstart(n)pend(m|n)(7)
其中:p(C|P,Q;θ)表示模型的输出分布;pstart(n)和pend(m|n)分别为pstart(n|C,Q;θ)和pend(m|n,P,Q;θ)的简写,表示模型对答案开始和结束位置的输出分布;θ表示模型参数。使用交叉熵损失函数最小化答案开始位置n和结束位置m的概率之和。
其中:ystart和yend分别是答案开始和结束位置的真实标签;ystartn表示ystart中的第n个标签具体的值;lp表示上下文段落C的长度,且n≤m,表示答案的开始位置总在结束位置之前。
知识蒸馏由教师模型T、学生模型S和损失函数组成。在数据集中通过最小化交叉熵损失函数让学生模型从数据中学习,并使用教师模型的输出概率分布pT代替真实标签,如下:
其中:α和β是softmax函数之前的预测概率,τ是温度系数。通过让学生模型学习教师模型的输出分布,可以将教师的知识迁移到学生模型,从而提高学生模型的精度与泛化能力。学生模型通过结合上述两种损失函数来进行训练。
L(θS)=LCE(θS)+λLKD(θS)(11)
其中: λ是自蒸馏损失函数权重。在自蒸馏的具体运用上借鉴多教师知识蒸馏[17]方法,采用批处理的方式,对于每一批样本,依据该轮次中模型的性能,调整其输出在集成中的权重,该权重称为可信程度。使用self-ensemble BERT模型作为教师模型,将模型结果集成的输出分布替代真实标签。当前轮次的模型作为学生模型,基于联合损失函数进行训练。
具体而言,当训练轮次t
关于答案开始位置的预测概率分布。在训练的每个轮次,当前的Bert(x,θt)模型从样本标签和self-ensemble BERT模型的输出分布中学习。总的损失函数定义为
其中: λ是损失函数权重,η是正则项调节参数。在训练前期准确率不高的情况下 λ取较小值,交叉熵损失LCE起到主导作用;随着训练的进行,集成的性能不断提升, λ的取值相应不断增加。正则化项可减少网络对噪声的敏感性,提高模型的泛化能力。
1.4 答案跨度输出
答案跨度输出模块的作用是分别预测每个位置是答案的开始和结束的概率。训练损失为预测分布中的开始位置和结束位置的负对数概率之和,对所有输入样本进行平均并使其最小化:
其中:θ是模型中所有可训练权重的集合;N是数据集中的样本数量;ysi和yei分别是第i条的真实开始和结束索引;pK表示向量p的第k个值。按照语义规则使用归并排序输出概率之和最大的跨度位置。具体而言:
a)对于长度为n的等长序列PS(X)和PE(X),分别计算它们的前缀和,得到两个数组P和Q,其中P[i]表示P中前i个元素的和,Q[j]表示Q中前j個元素的和。
b)定义一个元素为(pair,s)的数据结构,其中pair表示PS(X)和PE(X)中的元素下标对,s表示对应的j和。对于所有的pair,按照它们的和s降序排序,存储在一个大小为n2的数组C中。
c)对于数组C中的元素,依次检查它们对应的pair是否满足以下条件:
(a)越界条件A:
pair[0] (b)语义条件B: pair[0] (c)更新条件C: [pair[0]]+Q[pair[1]]≥P[pair[0]-1]+Q[pair[1]-1](18) 如果满足条件A和B、C,则将该元素的pair添加到结果集中。 d)返回结果中前k个pair,输出与答案最匹配的一个。 2 实验结果 2.1 实验设置 在跨度提取任务数据集SQuAD1.1上评估所提出的SD-SE-BERT模型,SQuAD1.1为包含536篇维基百科文章以及超过100 000个问题与答案的基准数据集,问题和答案均由人工进行标注,答案被限定出现在相应的段落当中。 实验采用exact match(EM)和F1 score(F1)作为评价指标。选取bert-base-uncased版本的BERT模型;batch size为16;epochs为4;输入序列最大长度为384;初始学习率为5E-5,使用AdamW优化器在每100个迭代周期衰减学习率,衰减系数为0.1;在数据增强模块EDA中同义词替换、随机插入、随机交换、随机删除这四种操作的概率设置为0.25;在使用基于加权平均的自集成策略时,取前K=3轮epoch的BERT模型得到self-ensemble-BERT模型。在自蒸馏过程中,温度系数τ固定设置为2,自蒸馏损失函数权重λ为0.1,为可学习参数,使用AdamW优化器进行更新;大型语言模型ChatGLM选用ChatGLM-6B的量化int4版本,选择默认参数配置,一次训练迭代以1的batchsize进行16次累加的前后向传播。实验在CUDA11.1和PyTorch 1.8.1的环境中实现了模型的最优性能。 2.2 实验结果与分析 在SQuAD1.1数据集上,将所提出的SD-SE-BERT模型与近些年问答领域表现较为出色的问答模型比较。 对比模型包括:五种单模型BiDAF[25]、BERT、ALBERT[26]、LinkBERT[9]、RoBERTa;四种蒸馏模型TinyBERT[17]、BERT-PKD[27]、MobileBERT[28]、ITRD[29]以及大型语言模型ChatGLM。实验结果对比如表1所示。 a)在单模型的对比中,BERT相比于BiDAF通过预训练可以更好地处理长文本与未知单词,有利于其捕捉问题和段落之间的交互信息。因此,BiDAF实验效果相比于BERT较差;而ALBERT在BERT的基础上使用自监督损失函数,并将预训练任务NSP替换为SOP(sentence order prediction),预测两个句子是否为同一篇文章中的连续句子,可以更好地学习句子语义信息和相互关系。LinkBERT新增加文档关系预测任务,以学习跨文档的句子之间的关系。RoBERTa则是在更大的数据集和最优的参数中训练BERT。其中,ALBERT、RoBERTa、LinkBERT和ChatGLM模型的思路更为接近,均是在多种类的更大规模的数据集上改变或者增加预训练任务。 b)在蒸馏模型的对比中,BERT-PKD由于使用知识蒸馏差异的方法,可以在保持模型性能的同时,在教师模型网络的先前层中提取多层知识,相对于TinyBERT模型在EM指标上较优。MobileBERT则进一步使用特征图迁移的方式允许学生模型模仿教师模型在每个Transformer层的输出,整体上提高了模型性能。ITRD方法中教师模型使用BERT-base,除只使用12层encoder外,学生模型架构和BERT-base相同,其引入相关性损失和互信息损失使得学生模型在特征级别上与教师表示相匹配,并从教师网络中提取补充信息。 SD-SE-BERT在测试集上的EM和F1分别为84.8和89.7,整体上比其他模型有所提升。相比较单模型中性能最佳的LinkBERT,EM指标提高2.2,F1指标下降0.4。相比五种单模型,EM指标平均提高6.52,F1指标平均提升4.22;证明了所提方法在改善BERT模型性能上的有效性。相比较四种蒸馏模型,EM指标平均提高4.625,F1指标平均提升3.275,表明SD-SE-BER相对其他蒸馏模型效果更好。相比较在SQuAD1.1数据集上微调的大型语言模型ChatGLM模型,EM指标提高4.5,F1指标提高2.5。由于ChatGLM已经在其他任务上进行预训练,其通用性更强,在具体数据集上微调后的表现不佳的情况符合文献[12,13]的结论。为进一步研究自集成和自蒸馏的联合使用对于模型训练过程中的影响,在训练时记录来自前几轮训练得出的教师模型的蒸馏损失和当前训练的交叉熵损失,即式(16),得到SD-SE-BERT模型在SQuAD1.1上的训练的误差收敛曲线,如图2所示。 当训练开始时,CE损失主导优化目标。在训练最后阶段,交叉熵损失变小且变化较平稳,但蒸馏损失继续呈现下降趋势,说明目标函数中的自蒸馏部分对模型贡献了很大的增益。在训练阶段结束时优化CE损失不能继续提高BERT的性能,但以self-ensemble-BERT为教师的自蒸馏将继续提高整体预测能力。 2.3 消融实验 对基线模型添加EDA模块、采用加权平均集成策略和使用自蒸馏的训练方法来验证提出方法的有效性。提出方法的几种组合如表2所示,各项实验结果以在SQuAD1.1数据集上EM和F1指标表示。第一行为基线模型BERT-base的结果,第二至六行为基线模型与对应方法组合的结果。 通过第一行和第二行结果的比较可以看出,在基线模型中添加所提的EDA模块后,模型性能略有提升。第四行中,使用普通平均策略代替加權平均集成结合自蒸馏,模型的性能相较于只使用加权平均集成的第三行,在提升幅度上更大,说明方法中自蒸馏部分提供的增益较大。通过第一行和第五行结果的比较可以看出,对跨度提取任务,所提的加权平均集成策略结合自蒸馏的训练方法相对基线,在EM和F1指标上分别提高了7.5%和4.9%。验证了同时采用加权平均集成策略结合自蒸馏方法的有效性。 表3给出了部分样本在经过所提方法训练后的答案跨度预测结果,第三列probability表示跨度开始位置和结束位置的概率值。在针对“who”类别的答案预测里,BERT模型很好地捕捉到了上下文信息,使得其更多地关注到人物的身份信息,输出正确答案“Rev.William Corby”,但在第三条样本示例,答案并未直接在段落给出,需要模型理解文本并推理信息,BERT输出错误答案“Rev.Theodore M.Hesburgh”,BERT受限于之前训练中学到的知识,而所提的方法并不受此影响,进一步证明自蒸馏对于模型“知识更新”的有效性。在第一和第二条样本示例中,虽然BERT和所提方法都预测正确,但在对于跨度中开始和结束位置的概率预测上,所提方法对于正确答案的关注更强,归功于自蒸馏使得模型能够更好地关注到目标词的位置。 3 结束语 针对知识蒸馏结合预训练语言模型在问答领域上存在的问题,将自蒸馏和自集成结合,构建出一种基于自蒸馏与自集成的问答模型SD-SE-BERT。使用不同训练阶段的BERT模型作为学生模型,自集成机制按学生模型在验证集上的性能,对输出结果进行加权平均以作为教师模型提供的监督信号,设计并结合自蒸馏损失函数和交叉熵损失函数,有效利用模型自身的监督信息和模型间的多样性。该方法提高了模型组合不同文本数据特征的能力,避免了事先训练教师模型、以及教师模型与学生模型不匹配的问题,通过与其他代表性方法的对比,证明了所构建的问答模型在跨度提取任务上的有效性。笔者相信,这项研究对于进一步发展问答模型以及相关领域的研究具有一定意义。在未来工作中,将继续研究自蒸馏结合其他模型压缩的方法,进一步提高问答模型性能,并将持续关注大型语言模型的动态,探索在问答领域的各类任务上微调其他大型语言模型的效果。 參考文献: [1]Chen Danqi.Neural reading comprehension and beyond[M].Redwood City:Stanford University Press,2018. [2]Liu Shanshan,Zhang Xin,Zhang Sheng,et al.Neural machine reading comprehension:methods and trends[J].Applied Sciences,2019,9(18):3698. [3]叶俊民,赵晓丽,杜翔,等.片段抽取型机器阅读理解算法研究[J].计算机应用研究,2021,38(11):3268-3273.(Ye Junmin,Zhao Xiaoli,Du Xiang,et al.Research on span-extraction algorithm for machine reading comprehension[J].Application Research of Computers,2021,38(11):3268-3273.) [4]王寰,孙雷,吴斌,等.基于阅读理解智能问答的RPR融合模型研究[J].计算机应用研究,2022,39(3):726-731,738.(Wang Huan,Sun Lei,Wu Bin,et al.Research on RPR fusion model based on reading comprehension intelligent question answering[J].Application Research of Computers,2022,39(3):726-731,738.) [5]Joshi M,Chen Danqi,Liu Yinhan,et al.SpanBERT:improving pre-training by representing and predicting spans[J].Trans of the Association for Computational Linguistics,2020,8:64-77. [6]Devlin J,Chang Mingwei,Lee K,et al.BERT:pre-training of deep bidirectional transformers for language understanding[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics.Stroudsburg:ACL Press,2019:4171-4186. [7]Rajpurkar P,Zhang J.Squad:100,000+questions for machine comprehension of text[C]//Proc of Conference on Empirical Methods in Na-tural Language Processing.Stroudsburg:ACL Press,2016:2383-2392. [8]Liu Zhuang,Lin W,Shi Ya,et al.RoBERTa:a robustly optimized BERT pretraining approach[C]//Proc of the 20th Chinese National Conference on Computational Linguistics.Beijing:Chinese Information Processing Society of China Press,2019:1218-1227. [9]Yasunaga M,Leskovec J.LinkBERT:pretraining language models with document links[C]//Proc of the 60th Annual Meeting of Association for Computational Linguistics.Stroudsburg:ACL Press,2022:8003-8016. [10]Aljanabi M,Ghazi M,Ali A H,et al.ChatGPT:open possibilities[J].Iraqi Journal For Computer Science and Mathematics,2023,4(1):62-64. [11]Du Zhengxiao,Qian Yujie,Liu Xiao,et al.GLM:general language model pretraining with autoregressive blank infilling[C]//Proc of the 60th Annual Meeting of the Association for Computational Linguistics.Stroudsburg:ACL Press,2022:320-335. [12]Karmakar A,Prenner J A.Codex hacks HackerRank:memorization issues and a framework for code synthesis evaluation[EB/OL].(2022).https://arxiv.org/abs/2212.02684. [13]Liu Tiedong,Low B K H.Goat:fine-tuned LLaMA outperforms GPT-4 on arithmetic tasks[EB/OL].(2023).https://arxiv.org/abs/2305.14201. [14]Zhang Wenxuan,He Ruidan,Peng Haiyun,et al.Cross-lingual aspect-based sentiment analysis with aspect term code-switching[C]//Proc of Conference on Empirical Methods in Natural Language Processing.Stroudsburg:ACL Press,2021:9220-9230. [15]Pranesh R,Shekhar A,Pallavi S.Quesbelm:a BERT based ensemble language model for natural questions[C]//Proc of the 5th Internatio-nal Conference on Computing,Communication and Security.Pisca-taway,NJ:IEEE Press,2020:1-5. [16]Pant K,Dadu T,Mamidi R,et al.BERT-based ensembles for modeling disclosure and support in conversational social media text[C]//Proc of the 3rd Workshop on Affective Content Analysis.Menlo Park:AAAI Press,2020:130-139. [17]Jiao Xiaoqi,Yin Yichun,Shang Lifeng,et al.TinyBERT:distilling BERT for natural language understanding[C]//Findings of the Association for Computational Linguistics.Stroudsburg:ACL Press,2019:4163-4174. [18]Yang Ze,Shou Linjun,Gong Ming,et al.Model compression with two-stage multi-teacher knowledge distillation for Web question answering system[C]//Proc of the 13th International Conference on Web Search and Data Mining.New York:ACM Press,2020:690-698. [19]Yuan Fei,Shou Linjun,Pei Jian,et al.Reinforced multiteacher selection for knowledge distillation[C]//Proc of AAAI Conference on Artificial Intelligence.Stroudsburg:ACL Press,2021:14284-14291. [20]Chen Defang,Mei Jianping,Zhang Hailin,et al.Knowledge distillation with the reused teacher classifier[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Washington DC:IEEE Computer Society,2022:11933-11942. [21]He Ruifei,Sun Shuyang,Yang Jihan,et al.Knowledge distillation as efficient pre-training:faster convergence,higher data-efficiency,and better transferability[C]//Proc of IEEE/CVF Conference on Compu-ter Vision and Pattern Recognition.Washington DC:IEEE Computer Society,2022:9161-9171. [22]葉榕,邵剑飞,张小为,等.基于BERT-CNN的新闻文本分类的知识蒸馏方法研究[J].电子技术应用,2023,49(1):8-13.(Ye Rong,Shao Jianfei,Zhang Xiaowei,et al.Knowledge distillation of news text classification based on BERT-CNN[J].Application of Electronic Technique,2023,49(1):8-13.) [23]Yang Chenglin,Xie Lingxi,Su Chi,et al.Snapshot distillation:teacher-student optimization in one generation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Washington DC:IEEE Computer Society,2019:2859-2868. [24]Wei J,Zou Kai.EDA:easy data augmentation techniques for boosting performance on text classification tasks[C]//Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing.Stroudsburg:ACL Press,2019:6382-6388. [25]Seo M,Kembhavi A,Farhadi A,et al.Bidirectional attention flow for machine comprehension[C]//Proc of the 5th International Confe-rence on Learning Representations.2017:147-154. [26]Lan Zhenzhong,Chen Mingda,Goodman S,et al.ALBERT:a lite BERT for self-supervised learning of language representations[C]//Proc of the 8th International Conference on Learning Representations.2020:344-350. [27]Sun Siqi,Cheng Yu,Gan Zhe,et al.Patient knowledge distillation for BERT model compression[C]//Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing.Stroudsburg:ACL Press,2019:4323-4332. [28]Sun Zhiqing,Yu Hongkun,Song Xiaodan,et al.MobileBERT:a compact task-agnostic BERT for resource-limited devices[C]//Proc of the 58th Annual Meeting of the Association for Computational Linguistics.Stroudsburg:ACL Press,2020:2158-2170. [29]Miles R,Rodriguez A L,Mikolajczyk K.Information theoretic representation distillation[C]//Proc of the 33rd British Machine Vision Conference.2022:385.
