
用于双阈值脉冲神经网络的改进自适应阈值算法
2024-02-18 07:05王浩杰刘闯
计算机应用研究 2024年1期
王浩杰 刘闯
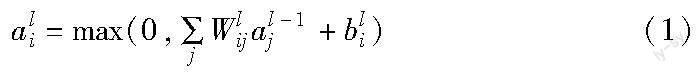
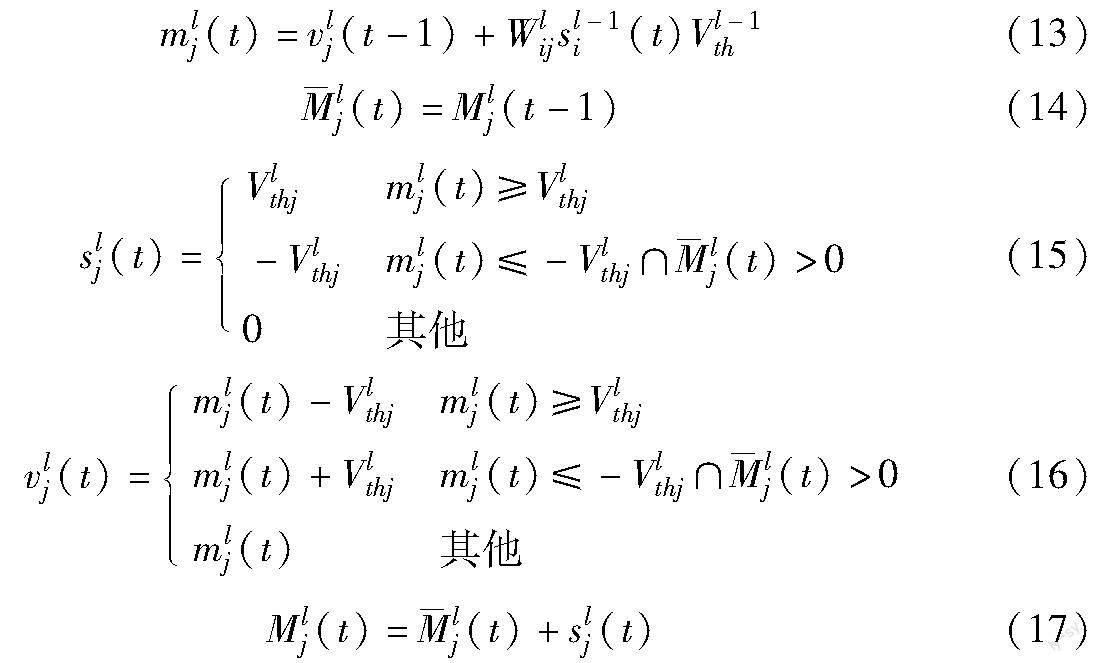
摘 要:脉冲神经网络(spiking neural network,SNN)由于在神经形态芯片上低功耗和高速计算的独特性质而受到广泛的关注。深度神经网络(deep neural network,DNN)到SNN的转换方法是有效的脉冲神经网络训练方法之一,然而从DNN到SNN的转换过程中存在近似误差,转换后的SNN在短时间步长下遭受严重的性能退化。通过对转换过程中的误差进行详细分析,将其分解为量化和裁剪误差以及不均匀误差,提出了一种改进SNN阈值平衡的自适应阈值算法。通过使用最小化均方误差(MMSE)更好地平衡量化误差和裁剪误差;此外,基于IF神经元模型引入了双阈值记忆机制,有效解决了不均匀误差。实验结果表明,改进算法在CIFAR-10、CIFAR-100数据集以及MIT-BIH心律失常数据库上取得了很好的性能,对于CIFAR10数据集,仅用16个时间步长就实现了93.22%的高精度,验证了算法的有效性。
关键词:脉冲神经网络;高精度转换;双阈值记忆神经元;自适应阈值
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)01-026-0177-06
doi:10.19734/j.issn.1001-3695.2023.05.0210
Improved adaptive threshold algorithm for double threshold spiking neural network
Abstract:SNN has gained widespread attention due to its low power consumption and high-speed computing capabilities on neuromorphic chips.The conversion from DNN to SNN is an effective training method for SNN.However,there are approximation errors in the conversion process,leading to significant performance degradation of the converted SNN under short time steps.Through a detailed analysis of the errors in the conversion process,this paper decomposed them into quantization and pruning errors and asymmetric errors,and proposed an improved adaptive threshold algorithm to balance the threshold of SNN.It used the mean square error(MMSE) to achieve a better balance between quantization and pruning errors.Additionally,this algorithm introduced a dual-threshold memory mechanism based on the IF neuron model to effectively address the asymmetric errors.Experimental results demonstrate that the improved algorithm achieves excellent performance on the CIFAR-10,CIFAR-100 datasets,and the MIT-BIH arrhythmia dataset.For the CIFAR-10 dataset,it achieves a high accuracy of 93.22% with only 16 time steps,validating the effectiveness of the algorithm.
Key words:spiking neural network;high precision conversion;dual-threshold memory neuron;adaptive threshold
0 引言
深度神經网络在图像分类、语音识别、自然语言处理等广泛的应用中取得了巨大成功[1,2]。作为人工智能的代表,深度学习在许多领域的表现已经超越了人类。然而,DNN的训练程序需要巨大的能量消耗和大量的内存,这对应用于轻量级设备和有限的存储场景来说是一个挑战。人工智能与物联网需求量的持续攀升,进而催生高效神经网络和加速器的开发与应用,尤其是在推理方面,一些研究侧重于减少网络连接和使用低精度参数,但计算消耗仍然很大。与传统DNN不同,脉冲神经网络[3]以一种模拟大脑的方式利用离散脉冲进行信息表示和传输,所以计算的能力更强大,而且在生物学上也是合理的。另外,SNN中的信息是基于事件的,即不发射脉冲神经元不参与计算,神经元的信息整合是累加(accumulate,AC)操作,这比DNN中的乘法累加(multiply accumulate,MAC)操作更节能。SNN促进了神经形态计算平台的发展,这些平台已经成功展示了比传统计算平台节能数个数量级的出色性能[4,5]。
虽然SNN具有上述优点,但由于脉冲的不可微性,广泛应用于神经网络的反向传播算法不能直接用于训练脉冲神经网络。到目前为止,训练高效的脉冲神经网络仍然是一个开放性的问题。直接训练和间接训练两种主流方法被开发出来克服训练深度SNN的挑战。直接训练SNN需要解决不可微二元激活函数的问题,流行的方法是对脉冲神经元使用代理梯度函数。一些方法[6,7]设计可微的代理激活函数(和相应的代理梯度)来优化SNN。直接训练的方法在小型和中型数据集上的训练性能与传统人工神经网络相当,甚至优于传统人工神经网络[8],然而训练过程需要大量的时间和内存,并且对于像VGG这样的大型网络来说,在收敛方面存在困难。为了缩小SNN与DNN之间的差距,出现了一种间接转换方案,通过将预先训练的DNN的参数映射到相同架构的SNN,即DNN-SNN转换方法。这种转换方法利用DNN中的先进技术来实现与SNN相当的精度,避免了梯度估计问题,因为它适应了最先进的DNN学习算法,所以在复杂任务中实现了高可扩展性。Cao等人[9]首先开始了DNN-SNN的研究,将具有一定约束的训练的浅卷积网络成功地部署到SNN中,从而在传统的目标识别基准上产生良好的准确性。并且发现脉冲神经元的放电率可以近似于DNN中具有足够时间步长的对应神经元的激活,这一发现已经成为转换方案的基本原则。在随后的工作中,Diehl等人[10]提出了基于数据的归一化,通过阈值平衡来提高深度SNN的性能。这里的归一化是对网络的权重归一化,归一化尺度是DNN中每一层的最大激活值。Rueckauer等人[11]通过结合DNN的更多技术对转换方法进一步改进,把减法复位机制[12]方法应用到转换SNN,这种方法也称为软重置[13]。Sengupta等人[14]将转换方法扩展到VGG和ResNet架构,并提出Spike-Norm算法,它根据转换后的 SNN 中每层的最大输入来调整阈值。Han等人[13] 提出剩余膜电位(RMP)脉冲神经元,通过缩放脉冲标准阈值改进了阈值平衡。Kim等人[15]提出了基于信道数据归一化的Spiking-YOLO,这是第一个基于脉冲的目标检测模型,并在目标检测任务上实现了与DNN相当的结果。最近,Ding等人[16]提出了分阶段加权和阈值训练的方法,以优化激活与激活之间误差的上界函数。Li等人[17]进一步提出使用量化微调校准权重和偏差。Bu等人[18]为人工神经网络设计QCFS移位激活函数,更好地近似SNN的激活函数。然而,它们都是复杂的过程,容易受到高推理延迟的影响;此外,使用批量归一化(batch normalization,BN)层转换低延迟SNN仍然是一个持续的挑战。尽管DNN-SNN转换已经取得了一定的进展,但SNN 与DNN之间的性能差距仍然存在,尤其是在遇到更复杂的任务时。并且有限的时间步长(<256)将导致精度显著下降,现有的DNN转换SNN方法需要数千个推理时间步长才能在准确性方面达到DNN的水平,导致SNN的功耗和延迟在应用中高于DNN。虽然较长的推理时间可以进一步减少转换误差,但这也阻碍了SNN在神经形态芯片上的实际应用。本文分析了DNN和SNN的神经元模型和工作机制的差异导致的转换中的近似误差,即SNN离散化引起的量化和裁剪误差以及由于脉冲到达激活层的时间序列不同而引起的不均匀误差[18]。通过最小化均方误差,本文提出了一种改进量化误差和裁剪误差之间平衡的自适应阈值算法,在该算法中,阈值是动态调整的。此外,引入了双阈值记忆神经元来解决不均匀误差。CIFAR-10和CIFAR-100数据集上的实验结果表明,与其他方法相比,本文提出的自适应阈值机制的SNN在分类准确率、准确率损失和网络延迟方面都有很大的提高。
1 转换误差分析
1.1 神经元模型
1.1.1 DNN神经元模型
DNN中的模拟神经元的计算可以简化为线性变换和非线性映射的组合,在数学上前馈网络中第l层中神经元i的激活值ali(ReLU之后)可以计算为
其中:l∈{1,…,L}表示具有L层神经网络的第l层;Wlij是l层中的神经元i和l-1层中神经元j之间的权重;bli表示第l层神经元i的偏置,为了方便起见,在下面的描述中省略了偏置。
1.1.2 SNN的神经元模型
与以前的工作类似,本文考虑积分发放(integrate-and-fire,IF)神经元模型,IF神经元由于输入和输出之间的功能关系类似于ReLU而被广泛应用于DNN-SNN转换算法中。在每个时间步长t,脉冲神经元j接收传入脉冲并通过整合输入膜电位来更新其状态,在时间步长t处l层IF神经元j的膜电位vlj(t)为
mlj(t)=vlj(t-1)+Wlijsl-1i(t)Vl-1th(2)
其中:mlj(t)和vlj(t)分别表示在时间步长t时触发脉冲之前和触发脉冲之后神经元j的膜电位;sl-1i(t)是时间步长t时来自突触前神经元i的二进制输出脉冲,一旦神经元j的膜电位mlj(t)超过放电阈值Vlth,神经元将产生脉冲并更新膜电位vlj(t)。就硬复位机制而言,在发射脉冲后,膜电位将立即恢复到静息电位,因此,硬复位机制忽略了放电瞬间的剩余电位,导致转换SNN的准确性下降。软复位神经元避免了上述问题,并广泛应用于各种模型中。为了避免信息丢失,如式(4)所示,本文使用“软复位”机制[11]。软复位神经元在触发脉冲后不会恢复到静息电位,而是将剩余电位保持在触发阈值以上。
由于IF神经元的最大放电速率为1,神经元在每个时间步长最多发出一个脉冲,这要求ReLU激活函数的输出范围为[0,1],所以需要DNN的参数进行变换。这就需要用到文献[11]提出的分层参数归一化,其通过使用DNN第l层的最大激活值λl重新缩放所有参数,如下所示:
用软复位神经元代替DNN的神经元,并将软复位神经元的放电阈值设置为其对应层的最大激活值。可以将预训练的DNN转换为可以直接使用的SNN,本文采用阈值平衡的方法来进行归一化处理。
1.2 转换误差
DNN-SNN的转换思想是将DNN的模拟神经元的ReLU激活与SNN中的脉冲神经元的放电速率(或平均突触后电位)联系起来。其转换误差主要来自两个方面:a)直接将DNN转换为SNN,产生量化误差和裁剪误差;b)由于脉冲到达激活层的时间顺序不同而导致的误差。下面给出了近似过程的解析解释,将式(2)代入式(4)可以得到
vlj(t)-vlj(t-1)=Wlijsl-1i(t)Vl-1th-sli(t)Vlth(7)
通过将式(7)从时间步长1~T求和,并在等式两边除以T可以得到
式(9)描述了相邻层神经元的平均突触后膜电位关系,而且ψlj(T)≥0,观察式(1)和(9)可以发现,如果能够将DNN中模拟神经元的激活值al全部映射到SNN中IF神经元的ψl(T),那么就能够用反向传播算法对源DNN进行训练,并通过用IF神经元代替ReLU激活来将其转换为SNN,这是DNN-SNN转换的核心思想。如果将初始膜电位vli(0)设置为零,那么当模拟时间步长T足够长时则可以忽略剩余膜电位vli(t)/T,转换后的SNN具有与源DNN几乎相同的激活函数,然而这会导致很高的推理延迟以至于阻碍SNN的实际应用。
1.2.1 量化和裁剪误差:SNN动力学离散化的误差
如图1所示,如果将λl设置为DNN中的实际阈值以映射SNN的有限离散集合ST中的最大值Vlth,al可以通过以下等式映射到ψl(t),即
其中:Floor函数x」返回小于或等于x的最大整数,而clip函数用于设置上限和下限,即
为了减少人工神经网络到SNN转换产生的量化误差,可以通过增加延迟T或降低λl来实现,这就是为什么DNN-SNN转换后,延迟和精度具有权衡关系的原因。然而,较低的λl会导致裁剪误差增大,这也降低了转换的SNN的准确性。另一方面,较大的λl会减小裁剪误差但会伴随量化误差的增加,文献[10]将Vlth設置为 DNN 中跨样本的最大预激活以消除剪裁误差。然而,最大预激活通常是异常值,基于这种认识,异常值可能会极大地增加量化误差,因此必须使用非常大的T(如2 000)来减少量化误差。
1.2.2 不均匀误差
在DNN中,一个神经元同时将输入相加得到激活值;但是在SNN中,由于脉冲可能会沿时间轴散布在任何时间步长,所以神经元的输出速率可能会有很多变化。理想情况下,期望从前一层接收脉冲的时间是均匀的。通过分析可以发现,对负权重传递的脉冲延迟到达的不当处理导致脉冲神经元的输出速率过高,使得DNN和转换后的SNN无法对应,下面通过图2中的例子来解释。
如图2上方框图中第一个图所示,假设输入数据x1=3并且x2=2,则在DNN中神经元的输出为1。根据基于速率的编码,将数据编码成一定数量的脉冲,可以假设x1对应于三个脉冲,x2对应于两个脉冲。此外,IF神经元的静息电位为0,脉冲发放阈值为1。深层SNN中神经元的输出脉冲可能在时间轴上显示各种分布。理想情况下,期望从前一层接收脉冲的时间是均匀的,即图2上方框中的第二个图。然而在现实中,当脉冲传递到深层时脉冲时间将是不均匀的,这将导致比预期发射更多的脉冲。本文分析两种特殊情况,即由负权重传输的脉冲的延迟到达或提前到达,这分别对应图2下方框中的第一个图和第二个图。从图2下方框中可以看出,当负权重传递的脉冲首先到达时,神经元的输出速率可以对应于DNN中神经元的输出;然而当正权重传递的脉冲首先到达时,神经元会立即放电,导致输出速率过高。对于使用基于速率编码的SNN,虽然可以控制输入脉冲的分布,但隐藏层中输出脉冲的分布无法控制,使得上述误差不可避免。
2 解决方法
2.1 双阈值记忆机制
如果所有的脉冲均匀地分布在时间轴上,或者负突触传递的脉冲总是提前到达突触后神经元,则可以避免脉冲到达激活层的时间序列不同带来的不均匀误差。为了解决这一问题,结合IF神经元模型引入了双阈值记忆(double-threshold memory,DTM)机制。DTM神经元有效地解决了输出速率过高的问题,而记忆机制的使用确保了记忆神经元能记住其传输的脉冲之和(正负脉冲可以相互抵消)。只有当记忆值大于零时,負的脉冲才能传输到下一层,通过这种方法,在时间步长t处,第l层中的神经元j的动力学方程描述如下:
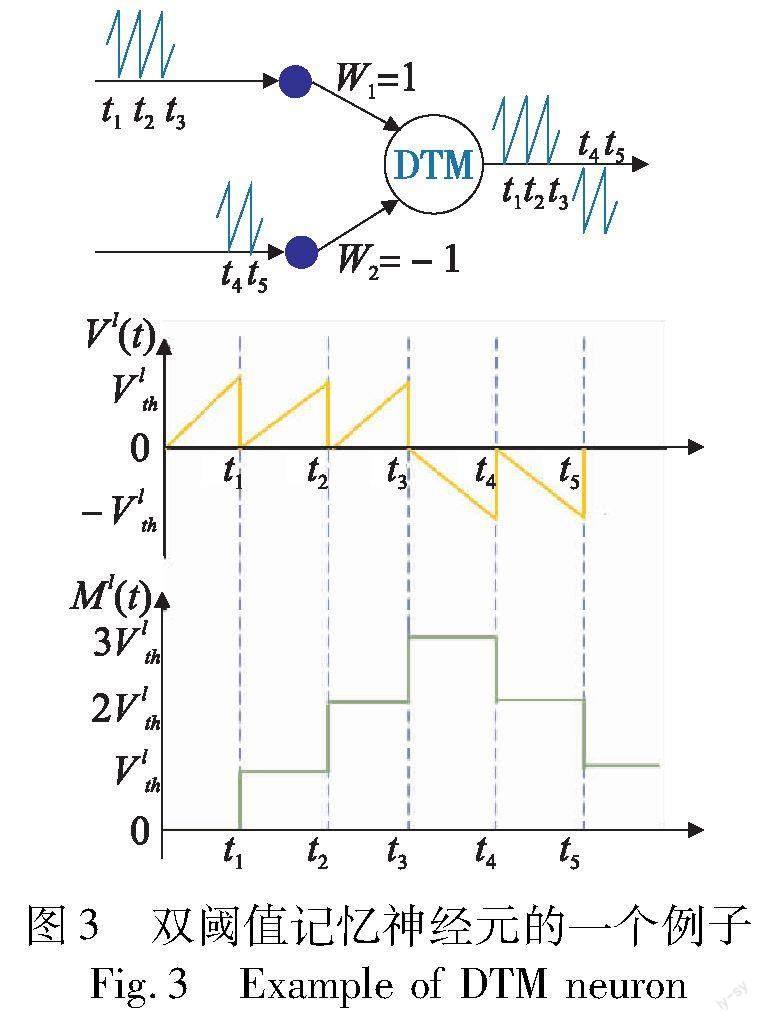
其中:Mlj是第l层神经元j的记忆值。当mlj超过放电阈值Vlthj时,神经元j将向其突触后神经元发送脉冲slj(t)。下面通过图3来说明双阈值记忆神经元,请注意图3的误差条件与图2的相同。
从图3可以看出,三个脉冲分别在t1、t2和t3从突触W1输入到记忆神经元,在t3时,虽然神经元此时的膜电位为0,但记忆值为3Vlth,这是已经被传递的所有脉冲的数量;在t4时,记忆神经元可以发出负脉冲,因为它满足式(15)的条件;t5时情况也是一样。通过上面的例子可以说明双阈值记忆神经元的输出速率等于它的记忆值。普通的有符号神经元如果传输的负脉冲比正脉冲多,那么神经元的输出速率可能就是负的,这与ReLU激活函数相矛盾,但双阈值记忆神经元由于有记忆值的存在,可以确保脉冲发射速率不会低于0。
2.2 通过MMSE自适应阈值
由于膜电位在很大程度上取决于网络的权重,许多研究寻求更好的阈值权重比,以促进SNN的深化,同时减少近似误差。权重标准化[10]和Spike-Norm[14]是其中两个杰出的代表,在权重标准化中,权重和偏差根据DNN中相邻层的最大激活或所有激活的第99.9个百分位数进行缩放,阈值不变。首先通过一定数量的训练样本估计网络各层的最大激活值,然后根据相邻层的最大值缩放权重,然而这种基于DNN的权重调整不太适合转换后的SNN。文献[14]提出了Spike-Norm,其中根据相应层中突触后膜电位的最大值设置特定神经元的阈值。
尽管这些方法取得了成功,但消除更深层次的CNN和SNN之间的近似误差仍然是一个挑战。上述两种阈值调整方法都是基于一定数量样本的最大输入或输出值,这种方式对单个样本参数不是最优的,可能会导致部分神经元激活不足。基于以上原因,本文提出了一种自适应阈值的调整方案。受文献[15]启发,所提出的自适应阈值方案是基于神经网络通道的,详细的方法如图4和算法1所示。这里的主要任务是减少每一层的激活差异,通过利用ClipFloor函数来确定触发阈值。为了更好地平衡量化误差和裁剪误差,使用最小化均方误差(MMSE)来获得给定不同预定义时间步长T的阈值Vlth,其公式为
在此对几批训练图像进行采样,并使用网格搜索来确定Vlth的最终结果。具体来说,线性采样[0,almax]的N个网格,并找到MSE最低的网格。设置N=100,发现这个选项在搜索效率和精度之间取得了很好的平衡。按通道应用MMSE阈值,以进一步降低MSE误差。
算法1 基于通道搜索脉冲发射阈值
输入:预训练的DNN;网格大小N。
输出:网络每个神经层的阈值平衡因子。
for all i=1,2,…,n th layer in the DNN model do
for j in output channels do
初始化每个通道的最大激活值;
收集DNN输出;
遍历每个通道找到最大激活值max(Alj);
for all j=1,2,…,N th grid do
临时设置阈值为j/N max(Alj);
计算ReLU和ClipFloor激活之间的MSE;
找到最小MSE的阈值;
end for
end for
end for
返回所有神经元层的通道阈值。
为了定量证明改进方法对减少每一层激活差异的有效性,本文计算每一层的相对误差‖al-ψl(t)‖2F/‖al‖2F并在图5中可视化。在每一层中计算每个通道的相对误差,并将它们放入箱形图中,箱线显示第5~95个百分位数的范围,橙色线表示中间值(见电子版)。选择在Cifar100数据集上使用VGG16模型,并将其转换为步长为16的SNN。对于传统方法,首先确定每个IF神经元层中的放电阈值,然后DNN的网络参数被简单地复制到SNN。从图5可以观察到相对误差最初很低,在使用传统方法转换的SNN倒数第二层中,部分通道的相对误差甚至达到10以上,从而导致相当大的精度缺陷。使用本文算法,激活差异得到了显著改善,从图5可以看出,大多数层的相对误差小于0.75,倒数第二层的最大相对误差仅为0.7。
3 实验验证与分析
3.1 实验数据
3.1.1 CIFAR10和CIFAR100数据集
CIFAR10数据集由10个类别的60 000张32×32图像组成,有50 000张训练图像和10 000张测试图像。与CIFAR10数据集类似,CIFAR-100数据集由100个类别的60 000 张32×32图像组成,有50 000张训练图像和10 000张测试图像。另外将填充设置为4,其他数据扩充包括随机水平翻转、裁剪和自动扩充[19]。
3.1.2 MIT-BIH心律失常数据库
本文使用麻省理工学院心律失常数据库[20],该数据库可在Physionet官网免费获取,它包含48条持续时间约30 min的双导联ECG信号记录。这些记录以每通道每秒360个样本的速度数字化,具有11位的分辨率,覆盖了10 mV的范围。因此,每个记录包含大约648 000个样本数据点,在每个记录中,第一个通道固定为改良导联II(modified-lead II,MLII),第二个通道根据记录的不同,是V1、V2、V4和V5(六个单极胸导联中的四个)之一。由于只有MLII在所有记录中都可用,已经证明了一个导联就足以达到高精度,所以在这项工作中只使用MLII数据。本文采用医疗器械促进协会(AAMI)在1998年提出的常用标记标准,该标准将心跳标记为正常(normal,N)、室上异位搏动(supraventricular ectopic beat,SVEB)、心室异位搏动(ventricular ectopic beat,VEB)和融合(fusion,F)。MIT-BIH数据集包括74 363次正常心跳、2 941次室上异位心跳、5 805次室上异位心跳和793次融合心跳。对于患者间分类,本文将MIT-BIH心律失常数据库分为训练数据集和测试数据集,其中不同心跳类型的比例在每个训练和测试数据集中是相似的。
a)训练数据集:101,106,108,109,112,114,115,116,118,119,122,124,201,203,205,207,208,209,215,220,223,230。
b)测试数据集:100,103,105,111,113,117,121,123,200,202,210,212,213,213,219,221,222,228,231,232,233,234。
此外,麻省理工學院数据库中的48条记录中有4条没有包括在内,即102、104、107和217,因为这些记录中的节拍类型高度不平衡(90%的节拍是N节拍,3%和6%是SVEB和VEB,只有1%是F)。使用MIT-BIH 数据集中提供的R峰注释位置对信号进行分段,只需取以 R 峰值为中心的180个点的窗口,每侧90个点,即可获得分段节拍。
3.2 实验参数配置
本文实验均在Windows11操作系统上完成,CPU型号为Inter CoreTM i7-12700H CPU,主频大小2.30 GHz,GPU 采用NVIDIA GeForce RTX3060,显存的大小为6 GB。实验使用Python 3.8进行编程和测试,选用深度学习框架PyTorch,版本号为1.9.0,CUDA版本为11.6,cuDNN版本为8.4.0。
为了验证算法的有效性和效率,本文使用VGG16和ResNet20网络结构在CIFAR10、CIFAR100上进行了实验。对于CIFAR数据集,优化算法采用的是随机梯度下降(stochastic gradient descent,SGD)算法,SGD算法中还使用了0.9的动量参数。另外学习率衰减采用了一个因子为0.2的策略,即在训练到第180、240和270个epoch时,学习率会分别乘以0.2,以减小学习率的大小。还采用了L2正则化,超参数λ被设置为5E-4。此外,为了防止过度拟合,在DNN中加入了批量归一化层(batch normalization,BN)。在SNN推理阶段,本文遵循文献[11]的方法合并卷积层和随后的BN层形成新的卷积层。在目前的SNN研究中,通常需要将实数的输入值转换为脉冲,再输入到SNN中进行处理[21];以前的方法通常将模拟输入激活(如灰度级或RGB值)转换成泊松发射率,但是这种转换给网络的启动带来了可变性,并损害了其性能。对于转换后的SNN,使用恒定编码方案将输入图像像素强度转换为脉冲率,根据IF神经元的动态,通过在连续的时间步长上分布输入电流(模拟神经元的激活值)来产生脉冲序列[11]。在SNN中,神经元的激活是二进制的而不是模拟值,执行最大池化会导致下一层的重大信息损失,因此过去的大多数研究都使用平均池化。本文遵循先前的工作,所有的最大池化层都使用平均池化层替换。
对于MIT-BIH心律失常数据库,本文所使用的网络结构如图6所示。由于心电信号是一维数据,所以使用一维DNN进行分类。图6的卷积层和池化层的第一维度是1,其中的四分类DNN模型将ECG信号分类为N、SVEB、VEB、F四个详细类别。该模型在其前两个卷积层中使用16个滤波器,在最后一个卷积层中使用24个滤波器,平均池化层应用于每个卷积层,使用的学习率为0.001。采用脉冲速率编码,其中归一化为[0,1]的每个数字信号值被编码为长度为T的脉冲序列。
3.3 消融实验
本节中将证明所提出的方法能够以更高的预测精度和更短的模拟时间实现SNN。为了验证所提出方法的有效性,采用VGG16和ResNet20对CIFAR10进行了消融实验。在用于比较的基准模型中,使用每层的最大激活值来归一化权重和偏置,即文献[11]中提出的Max-norm方法,然后分别验证所提两种方法对转换的影响。首先验证双阈值记忆神经元对转换的影响,如表1所示,与基于Max-norm+IF的方法相比,使用本文的Max-norm+DTM方法,转换的准确性和速度明显提高。粗体代表该项性能对比在所有模型中最高,当进一步将基准模型的Max-norm方法换成本文的MMSE自适应阈值的方法时,性能提升更加明显。例如,当转换ResNet20时,本文方法只需要32个时间步长就可以获得93.30%的准确率。
图7显示了当使用四种不同转换方法时VGG16结构的SNN推断精度,可以得到更加直观的效果。其中,用于比较的基准模型标记为灰色线(参见电子版)。在将基准模型的IF神经元改为双阈值记忆神经元之后,如图中蓝色曲线所示,可以看到在16个模拟时间步长以后,精度显著提高。黑线表示的是加入MMSE后的效果,可以看出提升效果更加明显,仅仅使用32个模拟时间步长就达到甚至超过基准模型的效果。最后从绿色的线可以看出,结合所提两种方法转换后的SNN的推理精度超过了单独使用任何一种方法的精度,并且只用32个时间步长就可以实现近乎无损的DNN-SNN转换,说明结合本文中提出的两种方法对DNN-SNN转换的效果非常好。
3.4 与相关工作的比较
将本文算法与其他的先进DNN-SNN算法在CIFAR数据集上的转换结果进行比较分析,结果如表2所示,粗体代表该项性能对比在所有模型中最高,网络结构包括VGG16和ResNet20。首先,本文关注转换的SNN性能,对于VGG16和ResNet20,本文算法的精度都可以超过所有以前的算法,而且在32个时间步长内实现了不到1%的性能损失。该方法除了具有优越的性能外,在仿真时间上也有突出的优势。用ResNet20使用CIFAR10进行仿真实验,所提算法仅用16个时间步长就实现了93.22%的精度。在CIFAR100数据集上32个时间步长也能实现可接受的转换精度。为了证明所提出的算法无须过多的推理延迟(T>128),表2还列出了不同时间步长的推理准确性,并与其他研究进行了比较。实验结果证明了本文算法法具有更好的性能。
3.5 心电图分类的应用
本节将图6所示的DNN训练好并转换为SNN,然后应用本文算法对心电图分类。使用以下两个绩效指标展示转换前DNN 和转换后SNN两种网络的性能,即敏感度(Se)和阳性预测率(P+),计算公式如下:
其中:TP、TN、FN和FP分别为真阳性、真阴性、假阴性和假阳性。
表3展示了四分类DNN的混淆矩阵,其中正确的预测以粗体突出显示。本文重点关注检测SVEB和VEB疾病的Se和P+,结果如表4所示。由表4可知,检测SVEB和VEB的Se分别为91%和85%,证明了本文的DNN模型的良好性能。表4还显示了DNN到SNN转换的精度损失,可以看出转换后的脉冲神经网络在检测疾病SVEB和VEB时有少量的精度损失,但在检测疾病N和F时表现更好。当使用本文的优化算法来搜索各层的最佳阈值时,精度增益来自SNN阈值的可配置性。
3.6 能耗分析
在DNN中,每个操作计算涉及一个浮点(floating-point,FP)乘法和一个FP加法,而在SNN中,由于二进制脉冲,每个操作仅是一个FP加法。在SNN中,不发射脉冲的神经元不参与计算,因此SNN在硬件上的实现具有节能的特性,尤其是在神经形态硬件上。本文选择VGG16在CIFAR100上验证所提出方法的能量效率,并使用文献[22]中的能量估计方法。32位DNN中MAC运算的能量成本(4.6 pJ)比SNN加法运算(0.9 pJ)高5.1倍[23]。对于不同的技术,这些数值可能不同,但是在大多数技术中,加法运算比乘法运算更加节能。如图8所示,本文计算了当模拟长度为32时在CIFAR100整个验证集上每一层的平均脉冲发射率,需要注意的是,这里的发射速率是用脉冲的数量来计算的。与之前不同,这里的正负脉冲不会抵消。在本文的方法中,除了第一层的神经元执行乘法运算,其余的神经元只执行加法运算。在图8中显示了当模拟长度为32时每层的发射速率,并且平均发射速率仅为0.052 5。根据文献[22]提到的能耗比计算公式(式(20))可以计算出当模拟长度为32时,本文的模型只需要DNN模型能量消耗的65.70%。
4 结束语
本文旨在减少从DNN到SNN转换中由近似误差引起的性能损失。分析了模拟神经元和脉冲神经元在神经元模型和神经元活动方面的差异,以及权重和阈值之间的平衡对逼近误差的影响。先前的研究主要集中在SNN中量化和裁剪误差的优化上,较少研究脉冲到达激活层的时间序列不同而引起的不均匀误差。为此,本文基于IF神经元提出了双阈值记忆神经元模型,可以有效解决脉冲时间不均匀导致比预期更多的脉冲的问题;此外,提出了一种改进的自适应阈值的算法,通过使用最小化均方误差方法有效地最小化量化和裁剪误差。实验结果表明,所提出的算法在较短的时间步长下实现了近乎无损的DNN-SNN转换。本文所采用的网络结构所有的最大池化均用平均池化来代替,这在一定程度上可能会限制DNN的性能,后续工作将继续研究使用最大池化的DNN-SNN转换以及将转换好的SNN模型部署到神经形态芯片上。
参考文献:
[1]王清华,王丽娜,徐颂.融合LSTM结构的脉冲神经网络模型研究与应用[J].计算机应用研究,2021,38(5):1381-1386.(Wang Qinghua,Wang Lina,Xu Song.Research and application of spiking neural network model based on LSTM structure[J].Application Research of Computers,2021,38(5):1381-1386.)
[2]Tavanaei A,Ghodrati M,Kheradpisheh S R,et al.Deep learning in spiking neural networks[J].Neural Networks,2019,111(3):47-63.
[3]Maass W.Networks of spiking neurons:the third generation of neural network models[J].Neural Networks,1997,10(9):1659-1671.
[4]Davies M,Srinivasa N,Lin T H,et al.Loihi:a neuromorphic manycore processor with on-chip learning[J].IEEE Micro,2018,38(1):82-99.
[5]Song Shihao,Balaji A,Das A,et al.Compiling spiking neural networks to neuromorphic hardware[C]//Proc of the 21st ACM SIGPLAN/SIGBED Conference on Languages,Compilers,and Tools for Embedded Systems.New York:ACM Press,2020:38-50.
[6]Li Yuhang,Guo Yufei,Zhang Shanghang,et al.Differentiable spike:rethinking gradient-descent for training spiking neural networks[C]//Advances in Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2021:23426-23439.
[7]Lee C,Sarwar S S,Panda P,et al.Enabling spike-based backpropagation for training deep neural network architectures[J].Frontiers in Neuroscience,2020,14:119.
[8]Zhang Wenrui,Li Peng.Temporal spike sequence learning via backpropagation for deep spiking neural networks[C]//Proc of the 34th International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2020:12022-12033.
[9]Cao Yongqiang,Chen Yang,Khosla D.Spiking deep convolutional neural networks for energy-efficient object recognition[J].International Journal of Computer Vision,2015,113(1):54-66.
[10]Diehl P U,Neil D,Binas J,et al.Fast-classifying,high-accuracy spiking deep networks through weight and threshold balancing[C]//Proc of International Joint Conference on Neural Networks.Piscataway,NJ:IEEE Press,2015:1-8.
[11]Rueckauer B,Lungu I A,Hu Yuhuang,et al.Conversion of conti-nuous-valued deep networks to efficient event-driven networks for image classification[J/OL].Frontiers in Neuroscience.(2017).https://doi.org/10.3389/fnins.2017.00682.(下轉第187页)
