
面向垃圾分类场景的轻量化目标检测方案
2024-02-12 07:43陈健松蔡艺军
浙江大学学报(工学版) 2024年1期
陈健松,蔡艺军
(厦门理工学院 光电与通信工程学院,福建 厦门 361024)
随着人民生活水平的提高,生活垃圾数量迅猛剧增,大量的垃圾对人类的健康、环境的破坏及经济的发展带来严重的威胁.传统的垃圾回收需要大量的人力和物力,利用深度学习技术,对垃圾进行智能化、自动化处理将成为一种趋势,可以提高垃圾的处理效率,有利于绿色经济和低碳循环发展.
近年来,基于深度学习的目标检测算法已经成为主流,深度学习以其强大的特征表示能力和端到端的学习能力,极大地提高了目标检测的精度和效率.其中目标检测算法主要分为一阶段和二阶段算法两大类.二阶段算法在第一阶段专注于找到物体的位置,得到建议框,提高准确率和召回率;第二阶段专注于对建议框进行物体分类,找到更加精确的锚框,其算法有R-CNN、SPPNet、Fast R-CNN 和 Faster R-CNN[1-4].一阶段算法减少了生成建议框这个阶段,直接产生物体的类别概率和位置坐标值,经过单次检测可以直接得到最终的检测结果,其代表算法有Yolo[5]、SSD[6].这2 种算法的处理过程不同,在性能表现上的差异较大.前者在检测精度和定位精度方面具有优势,后者在速度方面具有优势.
Yolo 系列算法作为一阶段算法,因其优秀的检测性能得到了广泛的应用,对于边缘端设备十分友好.研究人员对Yolo 系列算法提出许多改进方法.李小波等[7-8]在模型中添加注意力机制,增强特征图的信息表达能力,提高模型对小尺度目标的检测能力,但是模型的复杂度相应增加,不利于边缘端部署.李仁鹰等[9-11]通过将模型的主干网络替换为MobileNetV2,并嵌入注意力机制来实现模型的轻量化,在模型复杂度上有了改进,但没有很好地兼顾精度.王相友等[12-13]利用通道剪枝来实现模型的轻量化,杨小冈等[14]在将模型的主干网络修改成MobileNetV3 的基础上进行迭代剪枝.这2 种改进方式都使模型的推理速度大大加快,但是精度有所下降.
以上研究只针对精度和轻量化其中一种进行改进,不能同时满足检测精度和推理速度2 种要求.本文对Yolov5s 模型进行轻量化改进,在保证模型精度的同时,提高模型的推理速度,对于边缘端设备更加友好.
1 Yolov5 算法改进
从模块和数据2 个方面进行改进.如图1 所示,在模块方面,引入Stem 模块和深度可分离卷积,对C3 模型进行改进.在数据方面,利用Kmeans++算法重新计算物体的锚框值.
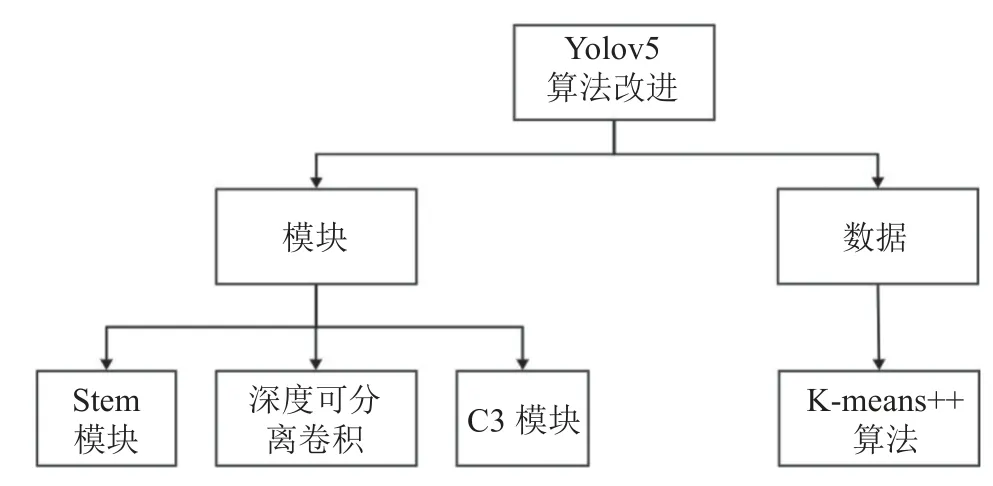
图1 Yolov5 算法的改进树状图Fig.1 Improvement tree graph of Yolov5 algorithm
1.1 改进模型的结构图
以Yolov5 结构为基础,对模型的主干网络和颈部网络进行修改.模型结构如图2 所示,模型主要由输入(Input)、主干网络(Backbone)、颈部网络(Neck)和检测头(Detect)4 部分组成.将Stem 模块作为输入图像处理模块,能够在几乎不增加模型参数量的同时,提高模型的特征提取能力,因此采用Stem 模块作为图像输入的处理模型[15].为了减少模型的复杂度,提高模型的推理速度,将主干网络和颈部网络中的3×3 降采样普通卷积改成深度可分离卷积.为了进一步减少参数量和模型复杂度,将颈部结构中的C3 模块改进成C3-C 模块来减少参数量,将backbone 中的C3 模块改进成C3-B 模块来增强图像特征的提取能力.
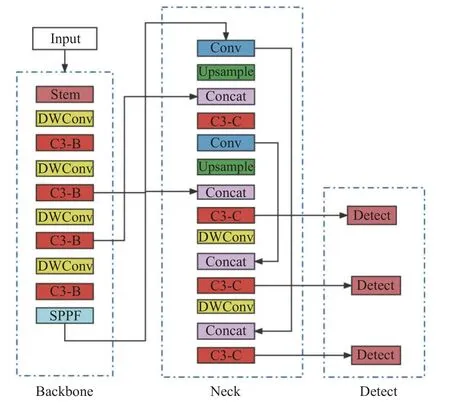
图2 改进后的Yolov5 模型结构图Fig.2 Structure diagram of improved Yolov5 model
1.1.1 Stem 模块 Stem 模块来源于移动端的实时目标检测模型Peleenet[16].图3 给出Stem 模块结构图.可以看出,Stem 模块首先进行快速降维操作,采用卷积核为3×3、步长(stride)为2 的卷积层实现.采用两分支的结构:一个分支用步长为1、卷积核为1×1 的卷积层和步长为2、卷积核为3×3的卷积层,另一个分支使用步长为2、卷积核为2×2 的最大池化层(Maxpool).最大池化层在保留主要特征的同时,减少了参数量和计算量,防止了过拟合的发生.Stem 模块在进行第一次降采样后,分成2 条路径对图像特征进行提取,使得模型可以提取更加丰富的特征.这样可以在不带来过多计算耗时的前提下,提高网络的特征表达能力.

图3 Stem 模块的结构图Fig.3 Structural diagram of Stem module
1.1.2 深度可分离卷积 一些轻量级的网络,如MobileNet 网络中,使用深度可分离卷积(depthwise separable convolution)来提取图像特征[17-19].在特征提取的过程中,随着网络深度的增加,特征图的通道数不断增加,当使用传统卷积对深层特征图提取特征时,必然会产生较大的参数量,导致算法的计算运行速度较慢.与常规的卷积操作相比,深度可分离卷积的参数量和运算成本较小.
深度可分离卷积主要分为2 个过程,分别为逐通道卷积(depthwise convolution) 和逐点卷积(pointwise convolution).如图4(a)所示为深度可分离卷积的实现,深度可分离卷积首先进行逐通道卷积,其卷积核数量与输入的通道数相同,每个卷积核负责一个通道,经过卷积后得到的特征图的通道数与输入的通道数一致.由于逐通道卷积没有利用特征图的空间特征,需要利用逐点卷积,逐点卷积相当于1×1 的普通卷积(普通卷积如图4(b)所示),它的卷积核尺寸为1×1×M(M为输入的通道数),这里的卷积运算会将上一步的特征在深度方向上进行加权组合,生成新的特征图.

图4 深度可分离卷积模块的结构图Fig.4 Structural diagram of depthwise separable convolution module
传统卷积的计算量为
深度可分离卷积的计算量为
式中:DK×DK为卷积核的尺寸,M为卷积核的深度,DW×DH为输出特征图的尺寸,N为输出特征图的深度.深度可分离卷积分为深度卷积和逐点卷积2 个阶段,相比于传统卷积,深度可分离卷积在完成相同计算目的的情况下计算开销更小.深度可分离卷积与传统卷积的计算量之比为
以3×3 卷积为例,深度可分离卷积的参数量可以减少至普通卷积的(1/9+1/N)倍,随着网络层数的增加,通常会导致模型参数量的显著增加,但使用深度可分离卷积能够有效地减少模型参数量.
1.1.3 C3 模块改进 对于在嵌入式端实现的垃圾分类识别,既要应对算力不足的情况,还要考虑复杂环境下对物体的识别准确率,因此对主干网络和颈部网络的C3 模块进行改进.如图5(a)所示为主干网络使用的bottleneck 模块.该模块包含了跨界融合层,又包含了多个Conv2d 卷积层,因而该模块既可以实现对图像低层特征和高层特征的融合(可以弥补低分辨率的高层特征图中空间信息的损失),又能够实现对图像更深层特征的提取.在主干网络的C3 模块中使用了2 个Bottle-Neck-1 模块(见图5(b)),使得改进后C3 模块的输出特征图含有更强的语义信息与更多的细节信息,以提升该模块的特征提取能力[20].如图5(c)所示,该模块将颈部网络中bottleneck 模块的普通3×3 卷积改成深度可分离卷积(DWConv),将修改后的bottleneck 模块应用于颈部网络的C3 模块中,形成C3-C 模块(见图5(d)),减少了模型的参数量.
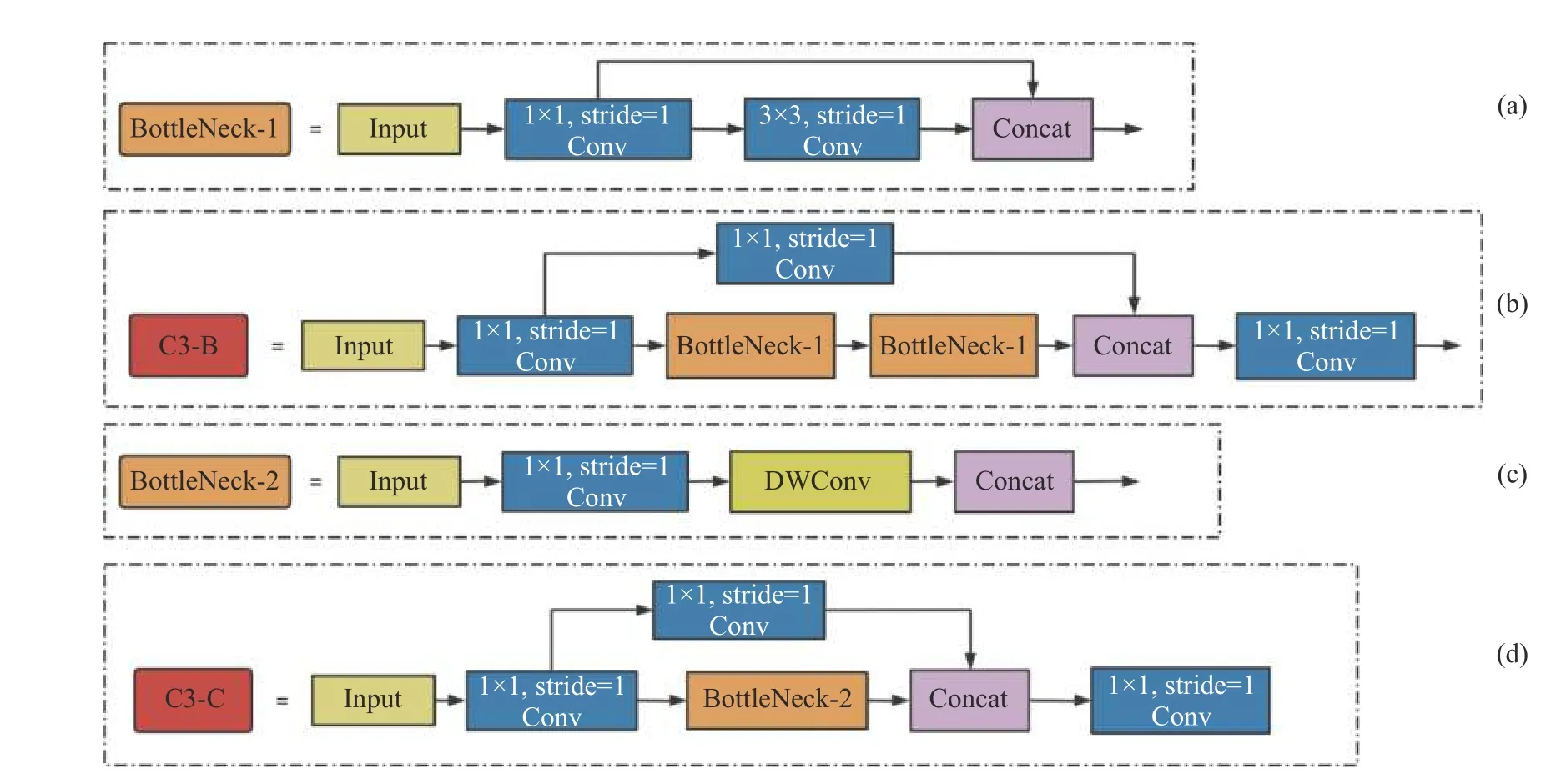
图5 C3 改进模块的结构图Fig.5 Structural diagram of C3 improved module
1.2 数据预处理
Yolov5 使用 K-means 算法对通用目标检测数据集COCO 进行聚类,获得初始的先验锚框参数.利用K-means 算法,随机分配初始聚类中心,可能会导致初始聚类中心与最佳聚类中心相差甚远,且初始的先验锚框参数仅适用于COCO、VOC 和ImageNet 等开放场景数据集,而本文数据集的检测对象与其存在较大的差异[21].选择 K-means++算法对锚框进行重新聚类,生成更优的锚框值,不会带来额外的参数和计算量.
利用K-means++算法,随机选择一个样本,作为当前的初始聚类中心;计算每个样本和已有聚类中心之间的最短距离,将该样本归类到与其相距最小的聚类中心所对应的类别中[22-23].计算每个样本被设定为下一个聚类中心的概率,选择概率最大的样本作为下一个中心.概率的计算公式为
式中:D(x)为每一个样本点到当前中心的最短距离,每次分配一个对象,会根据现有的聚类对象重新计算聚类中心,重复该过程直到没有对象被重新分配到其他的聚类中,最后筛选出K 聚类中心.尽管K-means++算法中用于初始选择聚类中心的方法需要花费额外的时间,但是K-means 算法在选取合适的聚类中心后会很快收敛,使用Kmeans++算法选择物体的锚框值,使得Yolov5 算法可以选择最具代表性的锚框值,使其在训练过程中能够更好地预测目标框的大小,提高模型的准确性和稳定性.
2 实验与结果分析
2.1 实验数据
使用自己拍摄的垃圾分类数据集和从网上爬取的数据集,重新组合成包含3 305 张图片的垃圾分类数据集.该数据集涵盖了6 种常见垃圾(瓶子、电池、笔、口罩、易拉罐和纸杯),每张图片的物品标注数量不同,这样的数据集可以更好地反映现实场景.为了获得更准确的训练效果,将数据集按照9∶1 的比例进行划分,其中90% 的数据,即2 975 张图片用于训练,剩下的10% 的数据,即330 张图片用于验证.每个类别的训练样本数量如下:瓶子1 571 个、电池1 850 个、笔812支、口罩902 个、易拉罐946 个、纸杯887 个.
2.2 实验参数配置
模型的训练采用pytorch1.10.1 深度学习框架,CUDA 10.1.硬件配置为GeForce RTX 3080 显卡、10 GB 显存.训练时的参数配置如表1 所示.
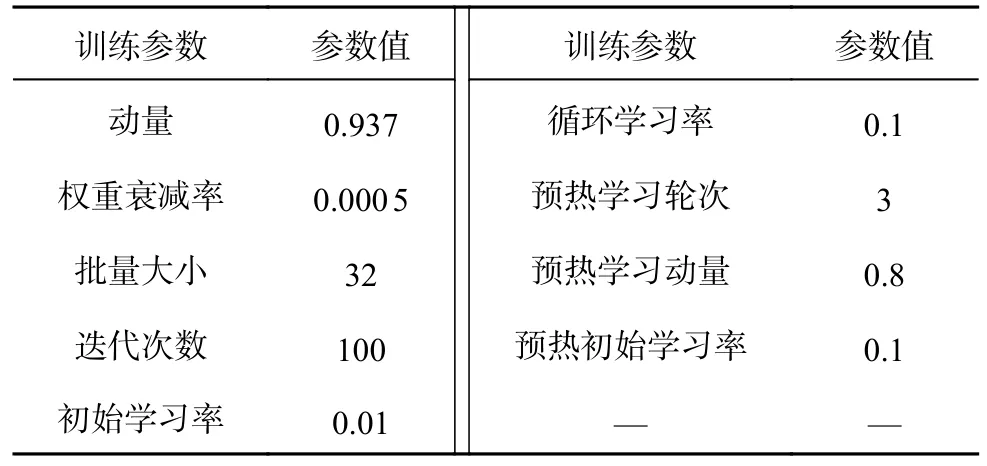
表1 超参数设置
2.3 实验评价指标
在上述统一的实验配置环境中进行对比实验,采用召回率R、精确率P、均值平均精度(mean average precision,mAP)、模型参数量和模型推理速度作为评价指标.mAP@0.5 为IOU 设为0.5 时,计算每一类的所有图片的AP,对所有类别的AP 求平均值.mAP@0.5:0.95 表示在不同IOU 阈值(0.5~0.95,步长为0.05)下的平均mAP[24].mAP 的计算如下所示:
式中:TP为正确识别出的垃圾样本数量,FN为模型未能识别出的垃圾样本数量,FP为模型错误识别的垃圾样本数量;P为精确率,表示模型预测为垃圾的样本中预测正确的占比;R为召回率,表示所有的垃圾样本中模型能够识别出来的数量占比;n为垃圾样本的类别数;i为当前类别的序号.
2.4 实验结果分析
如图6 所示为Yolov5s 模型和改进模型在使用K-means++算法后精度和锚框损失L的变化情况.图中,N为迭代次数.图中,K-means++表示使用该算法调整数据集中的锚框值进行训练.从mAP的表现(见图6(a)、(b))来看,在加入K-means++算法后,模型的精度收敛速度更快,mAP 比未使用K-means++算法的模型高.如图6(c)所示为模型的锚框损失情况.可以看出,在加入K-means++算法后,损失的收敛速度更快;与未使用K-means++算法的模型相比,锚框损失更小.
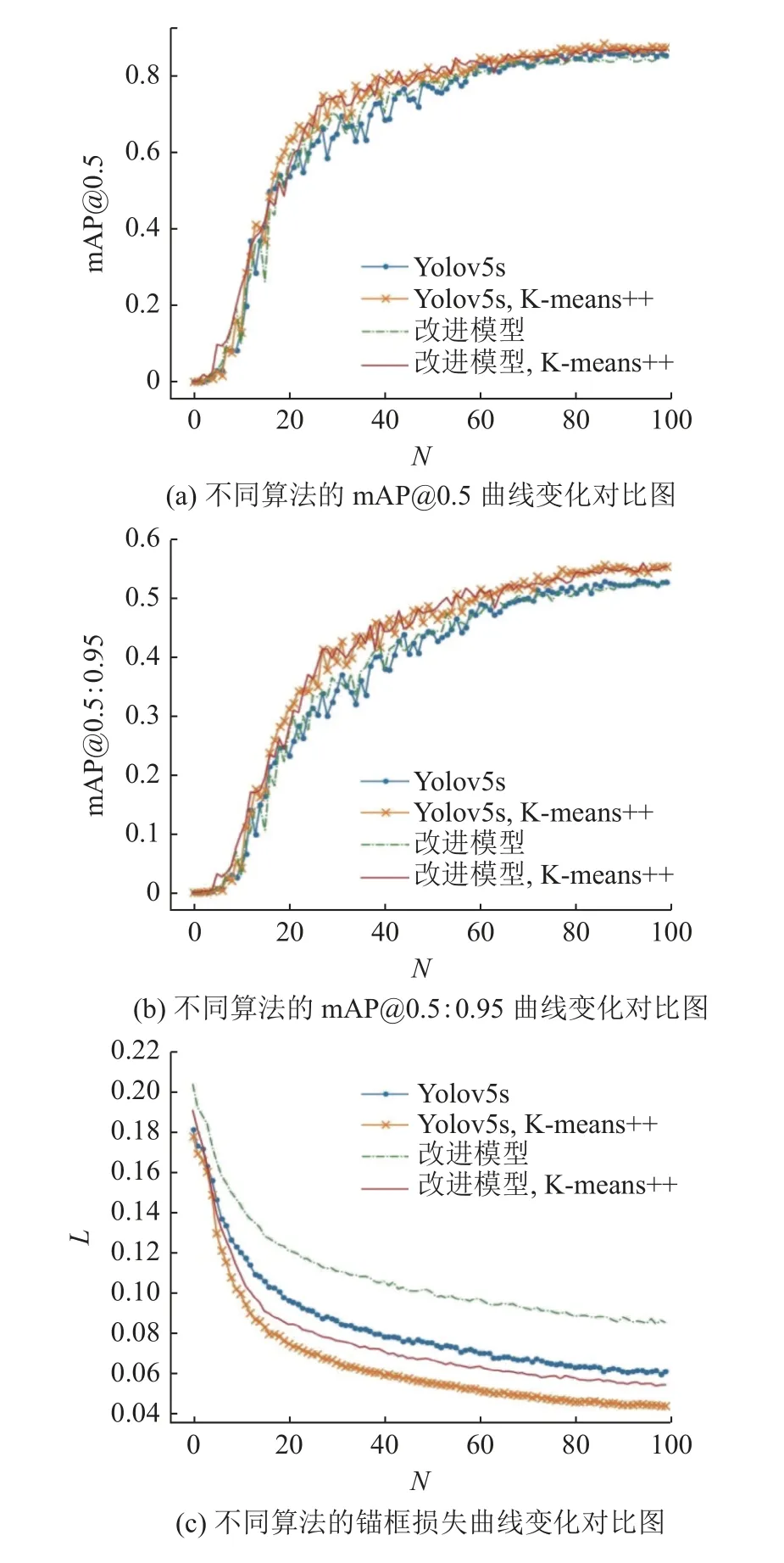
图6 Yolov5s 模型和改进模型的性能对比图Fig.6 Performance comparison between Yolov5s model and improved model
如表2 所示,改进模型和Yolov5s 模型在加入该算法后,准确率、召回率和平均精度都明显提升.具体来说,Yolov5s 模型在加入K-means++算法后,与未加入该算法相比,准确率提升了2.1%,召回率提升了4.4%,mAP@0.5 提升了2.2%,mAP@0.5:0.95 提升了2.6%.改进模型在加入K-means++算法后,与未加入该算法相比,准确率提升了3.8%,召回率提升了3.4%,mAP@0.5 提升了2%,mAP@0.5:0.95提升了2.7%.这说明K-means 算法对锚框进行优化的有效性,能够显著提高模型的准确率和稳定性.改进模型加上K-means++算法后,与未加入Kmeans++算法的Yolov5s 模型相比,检测任务的表现更加优越.具体来说,加上K-means++算法的改进模型与未加入K-means++算法的Yolov5s 模型相比,准确率提升了6.3%,召回率提升了1.9%,mAP@0.5 提升了0.8%,mAP@0.5:0.95 提升了3%.这表明最终改进的模型能够更好地适应各种场景和数据集,表现更加优异.改进模型在参数量上比Yolov5s 模型小,参数量减少至原模型的77.1%.将改进后的模型部署到Jetson Nano 上,每帧的推理时间达到106.1 ms,与Yolov5s 原模型相比,速度提高了21.9%.这表明改进后的模型具有更高的计算效率和更好的实用性,能够更好地满足实际需求.

表2 Yolov5s 模型和改进模型的实验结果对比Tab.2 Comparison of experimental results between Yolov5s model and improved model
将使用了K-means++算法的改进模型称为最终改进模型,未添加K-means++算法的Yolov5s 模型称为Yolov5s 原模型.表2 中,Np为模型的参数量,t为模型的推理时间.从表2 的实验结果可以看出,最终改进模型的性能优于Yolov5s 原模型.
为了进一步对比最终改进模型和Yolov5s 原模型的性能,从网上随机挑选图片进行测试.如图7(a)所示为Yolov5s 原模型的检测效果,如图7(b)所示为最终改进模型的检测效果.可以看出,最终改进模型对物体的识别精度有所提高,减少了误检率,提高了对遮挡物体的识别精度.实验结果表明,最终改进模型在垃圾分类检测任务上的表现更优秀.

图7 Yolov5s 模型和改进模型的检测结果对比图Fig.7 Comparison of detection results between Yolov5s and improved model
3 结语
针对边缘端算力不足导致目标检测模型实时推理性能差的问题,本文提出轻量化的Yolov5 模型.将自制的私有数据集和网上爬取的数据重新组合成垃圾分类数据集.在数据上,使用K-means++算法优化锚框;在模型上,引入Stem 模块提高特征提取能力,利用深度可分离卷积减少模型的参数量和复杂度.对主干网络的C3 模型进行改进,加强了特征提取能力.实验表明,改进模型与Yolov5s 模型相比,在提高模型精度和稳定性的同时,明显提升了推理速度,减少了摄像头实时检测卡顿的情况.本文的研究为边缘端的垃圾分类系统开发提供了科学设计的依据,具有广阔的应用前景.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
科普童话·学霸日记(2021年2期)2021-09-05
当代陕西(2019年24期)2020-01-18
电子制作(2019年11期)2019-07-04
小太阳画报(2018年10期)2018-05-14
北京航空航天大学学报(2018年1期)2018-04-20
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
作文周刊·小学一年级版(2016年36期)2017-03-03
电子设计工程(2015年6期)2015-02-27
