
基于AI与RPA结合的BOM系统自动化录入研究
2024-02-09 00:00:00杨斌杨微查安秦
电脑知识与技术 2024年36期



关键词:机器人流程自动化;人工智能;智能制造;效率提升;BOM系统
中图分类号:TP3 文献标识码:A
文章编号:1009-3044(2024)36-0020-04"开放科学(资源服务) 标识码(OSID):
0 引言
机器人流程自动化(Robotic Process Automation,简称“RPA”) 技术主要模拟人类在计算机等数字化设备中的操作,并利用和融合现有各项技术减少人为重复、有规律的、大批量的工作流任务,实现业务流程的自动化。近年来,随着人工智能(Artificial Intelligence,简称“AI”) 技术的不断发展和“数智化”时代的来临,RPA与AI的深度融合为应用发展创造了新的机遇。
在现代制造业中,精确管理和快速更新BOM(物料清单) 对于确保生产线的顺利运行至关重要。然而,手工录入零件信息不仅消耗时间和人力,还容易出现人为错误。刘浩[1]梳理了某企业的业务流程并开发了基于RPA的自动化办公系统,通过上线部署并测试运行后顺利通过了某企业的交付验证,为其他RPA 系统研发提供了一定的借鉴;谢博[2]分析总结了目前BOM技术在制造型企业实现过程中存在的诸多问题,并重点研究了BOM视图映射和BOM间模型转化算法设计,但未对文中提出的BOM数据手工录入过程中容易出错且耗时费力的问题展开有效研究。
因此,受上述文献启发,本文实现了一种基于Si⁃kuliX和OCR技术的自动化系统,旨在解决零件图纸中文本信息的自动提取与BOM系统文本信息的自动化录入问题,以提高工作效率和数据的准确性。
1 系统的技术实现
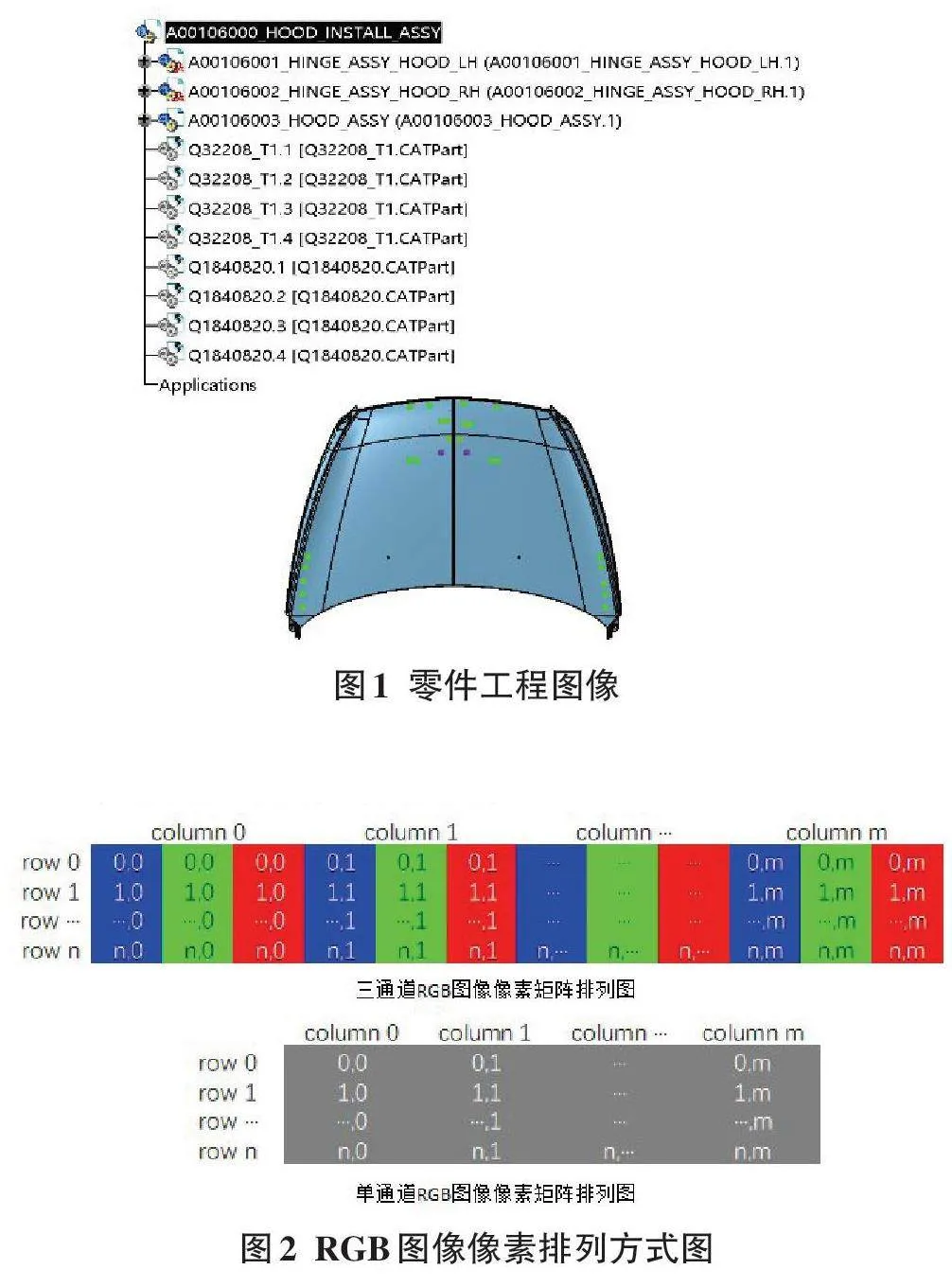
本文研究的BOM数据自动化录入系统,能够实现自动识别并提取零件工程图像中的文本信息(例如图1所示为某车型的机盖钣金总成零件工程图像,其目录结构树中包含了零件号码和零件名称信息) ,然后将提取的文本信息自动化录入BOM管理系统,整个过程无须人工介入,定制开发的RPA工具会驱动键盘和鼠标实现全流程自动化操作。该系统主要包含两大模块:OCR图像识别模块和文本信息自动化录入模块。其中OCR图像识别模块选用一个开源的OCR 引擎Tesseract,主要用于识别图像中的文本信息;文本信息自动化录入模块选用一款RPA开源工具Siku⁃liX,用于对图形用户界面进行自动化操作。
1.1 OCR 图像识别模块的实现
OCR图像识别模块采用Python程序实现,主要定义了preprocess_image和ocr_image两个函数,前者用于对图像进行预处理操作,主要包括图像的灰度化和二值化处理;后者主要用于对预处理后的图像进行OCR识别。
1.1.1 图像的灰度化
在图像识别与处理领域,灰度化是一种常见的预处理步骤,能够有效减少数据维度,从而提升后续算法的处理效率和性能。在RGB色彩模型中,任意一种颜色都可由红、绿、蓝三种原色光谱构成,其每个通道的像素级范围在0到255之间。图像像素值在内存中是以矩阵方式保存的,如图2所示。如果矩阵元素存储的是单通道像素,那么像素可能有256个不同的值,如果矩阵元素存储的是三通道像素,那么像素可能有224个不同的值,像素取值范围的激增将会对算法的性能造成严重影响,因此,需要将三通道的图像变成单通道,此过程即为图像灰度化[3]。
1.1.2 图像的二值化
二值化[5]操作的主要思想就是选取合适的阈值将图像划分为两类,一类中的所有像素值要高于选取的阈值,另一类的所有像素值要低于选取的阈值,最后划分后的图像即为二值化操作后的图像。图像二值化通过像素灰度值划分为前景和背景两个区域,前景通常包含目标对象,而背景则是目标对象的周围环境。
本文中的图像灰度分布较为均匀,选用自适应阈值法[6]来进行二值化处理,算法的基本思想如下:先设定一个对比度阈值S=15和一个图像前景和背景的差值ΔT=(255+0)/2=127.5。假设当前的像素点为P(i,j),其灰度值为Gray(i,j),以该点为中心做一个边长为(2k+1)的窗口,然后计算出窗口所在区域内所有像素点灰度级的最大值Max和最小值Min,再求二者的均值即可得到一个窗口中心阈值T,用公式进行计算如式(2) 所示,当前点P(i,j)的阈值计算如式(3) 所示。
通过将前景和背景分离成明显不同的像素值(通常为黑色和白色) ,可以更容易地进行目标检测、图像分割、字符识别等图像处理任务。图4所示即为经过二值化处理后的图像。
1.1.3 Tesseract OCR 文字识别
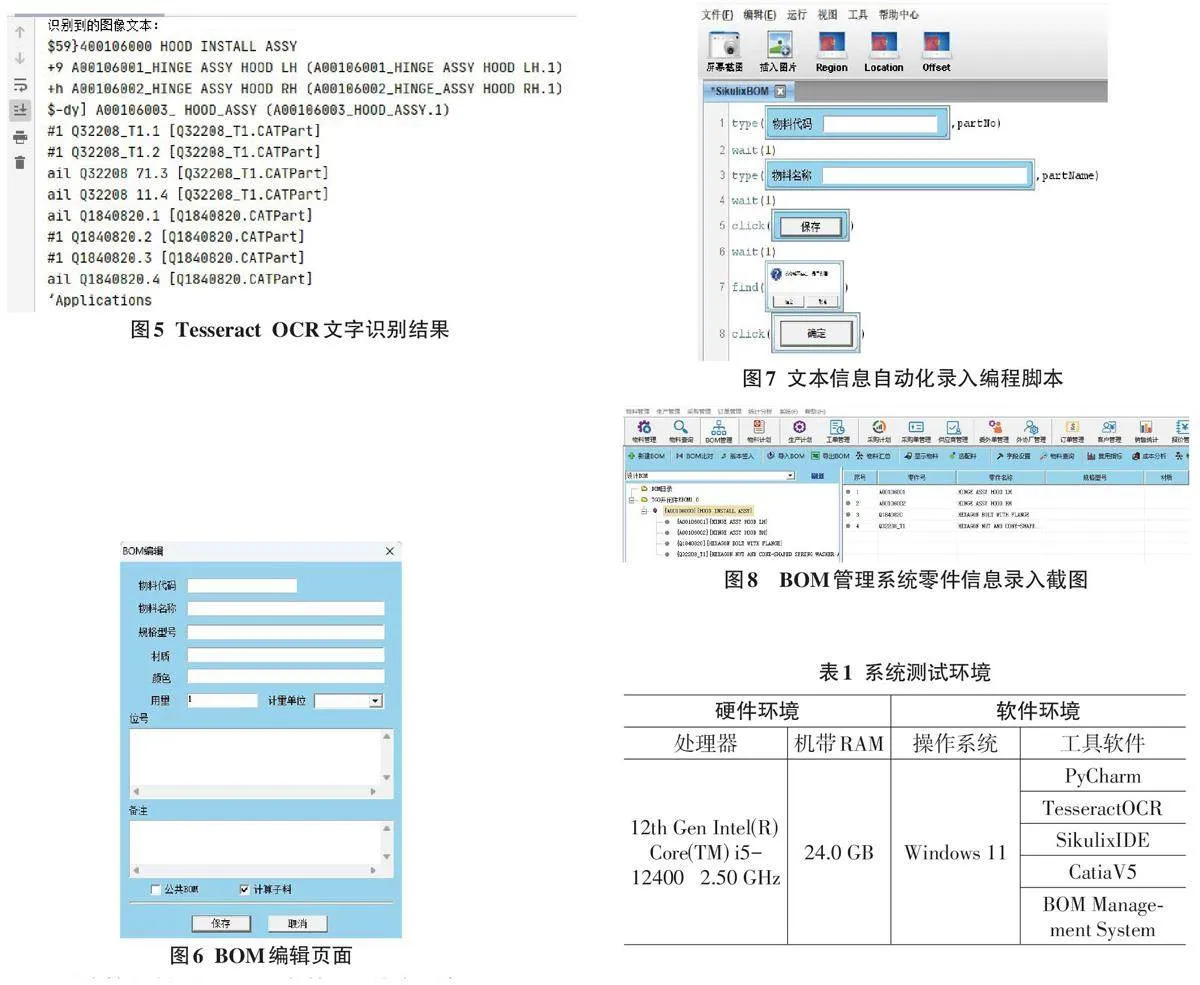
Tesseract OCR是一个开源的OCR引擎,其提供了许多参数,可以根据不同的需求进行调整和优化。本文设置语言参数language为“eng”,用于识别英语语言文本;设置页面分割模式参数psm为“6”,用于将识别的图像分割成不同的区域,然后对每个区域进行识别;设置OCR引擎模式参数oem为“3”,该引擎模式速度较慢但准确性较高。本文使用Tesseract OCR引擎进行文字识别,首先对预处理后的图像进行布局分析,找到目标文字区域后进行文字分割,随后进行字符识别并输出图片文本。文本识别结果如图5所示,零件工程图像结构树中的零件号和零件名称基本完整地识别出来了。
1.2 文本信息自动化录入模块的实现
文本信息自动化录入模块采用SikuliX脚本程序来实现,在脚本程序中,首先使用openApp(someApp) 自动打开或启动一个应用程序,调出如图6所示的BOM编辑页面,然后脚本程序会执行type(图像文件, \" 文本内容\"), 在BOM编辑页面定位相应的输入框并引导键盘在图像输入框中自动输入文本内容,当所有的输入信息完成以后,脚本程序会执行click(image⁃Button) ,在BOM编辑页面或弹框中定位某个操作按钮并引导鼠标点击“保存”或“确定”按钮,从而结束整个自动化操作流程。文本信息自动化录入编程脚本如图7所示。
采用计算机辅助企业生产管理,首先要使计算机能够读出企业所制造的产品构成和所有要涉及的物料,为了便于计算机识别,必须把用图示表达的产品结构转化成某种数据格式,这种以数据格式来描述产品结构的文件就是物料清单,英文全称为Bill Of Ma⁃terial,简称BOM,BOM数据管理和维护对于制造企业的各个环节都至关重要。在某BOM管理系统中采用自动化录入的实验结果如图8所示,图1中零件工程图像目录结构树中的零件号和零件名称已被准确识别并自动录入了。
2 实验与结果
2.1 实验设置
本研究的自动化系统在Windows环境下进行,主要针对CatiaV5中的零件工程图像截图实现文本信息识别和自动化录入,因此本文将主要从文本识别的准确率和自动录入时间两个维度对系统展开测试。系统测试环境如表1 所示,其中PyCharm 和Tesserac⁃tOCR分别为OCR文本识别程序的集成开发工具和引擎,SikulixIDE是一个基于图像识别的自动化工具,主要用于图形用户界面的自动化操作,CatiaV5是一款3D设计软件,在本测试中主要用于打开并显示零件工程图像,BOM Management System是一个维护BOM 数据的管理系统,以上工具部署在Windows 11操作系统上,共同为本文测试提供软件环境。
测试方法为:在自主开发的OCR文本识别程序中配置待识别的零件工程图像的路径,启动系统程序将识别的结果进行映射处理后保存到文本文件,自动化录入编程脚本会自动加载该文本文件,并驱动键盘和鼠标自动打开BOM管理系统,实现零件号和零件名称的自动化录入操作。在上述过程中,将识别的中间结果与零件工程原始图像进行比对,将判定为“识别准确”的文本条目数与原图中全部待识别的文本条目数的比值作为文本识别准确率测试结果记录保存;使用秒表记录上述自动化操作过程的执行时间,并作为测试结果记录保存。
选择9张不同复杂度的零件图像分别进行测试,由于测试方法、测试条件均相同,待测试的图像均来源于3D设计软件中的零件工程图像截图,属重复性实验,设计9次实验可有效减少随机误差的影响,提高测试和评估结果的准确性和可信度。
2.2 实验结果
因篇幅有限,表2仅列举3个不同零件工程图像的测试结果。在文本识别结果截图中,对连续正确的字符或数字且具有工程意义(代表一个正确的零件号或零件名称,标准件的零件号和零件名称相同) 的字符串整体判定为“识别准确”并做标记,从多个判定结果和录入计时结果来看,本文所实现的系统针对9张不同的零件工程图像的文本识别准确率和自动录入用时分别达到(91.7%,56秒) 、(85.7%,82秒) 、(85.7%,49 秒) 、(92.6%,86 秒) 、(90%,72秒) 、(75%,57 秒) 、(90%,77秒) 、(88.9%,55秒) 、(90%,79秒) (后6个数据的测试结果截图未在文中列出) ,平均识别准确率达到87.7%,自动化录入的平均用时为68秒,远低于人工录入143秒的平均用时。
2.3 结果分析
本文选取9张不同零件工程图像开展了9次重复性实验,通过实验测试和分析,结果表明本文提出的基于OCR和SikuliX技术的自动化解决方案针对英文字符的平均识别准确率达到87.7%,并且理论上还可以实现7×24小时不间断工作,极大地提升录入效率,在减少人为重复、有规律的、大批量的工作流任务方面具有显著优势。
3 结束语
本文针对制造型企业BOM系统零件数据手工录入过程中存在大量数据的重复操作,有一定出错的概率且耗时费力的问题,提出了一种基于SikuliX 和OCR技术的自动化解决方案,用于识别和自动化录入零件图像中的文本信息。实验结果表明,该方法在减少人为重复、有规律的、大批量的工作流任务方面具有显著优势,为智能制造中的数据处理提供了新的思路,未来可继续探索AI与RPA的更多应用。
猜你喜欢
商界(2019年12期)2019-01-03 06:59:05
IT经理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
中文信息(2016年10期)2016-12-12 14:51:16
考试周刊(2016年89期)2016-12-01 13:49:09
数学学习与研究(2016年19期)2016-11-22 10:48:39
企业技术开发·中旬刊(2016年10期)2016-11-12 16:31:53
南风窗(2016年19期)2016-09-21 16:51:29
