
基于多异构属性和不完全权重信息的案例检索方法
2024-02-06 11:21黄金凤
佛山科学技术学院学报(自然科学版) 2024年1期
张 恺,黄金凤
(福建船政交通职业学院信息与智慧交通学院,福建 福州 350007)
案例推理(Case-based reasoning,CBR)是一种通过对旧问题的求解来解决新问题的方法,因此经常被应用于应急决策领域[1-2]。在决策过程中,案例信息往往存在定性和定量两种情况,通常用异构信息来描述[3-5]。多异构属性案例相似度评价主要有两个研究方向:一是提出了一种新的异构多属性问题案例相似度评估方法。例如,Fan 等[6]提出了一种混合相似性评价方法,属性值有五种格式:清晰符号、清晰数、区间数、模糊语言变量和随机变量;Zheng 等[7]提出了一种混合多属性案例相似度评价方法,属性值有四种格式:清晰数、区间数、多粒度语言变量和直觉模糊数;Yu 等[8]考虑了清晰数、区间数、清晰符号、语言项和概率语言项集进行案例相似度评估,在另一项研究中,Yu 等[9]考虑了清晰数、清晰符号、区间数和模糊语言变量进行案例相似度评估。二是确定属性权重。例如,Zheng 等[10]提出了一种新的基于双边界数据包络分析(DEA)的案例检索方法:DEA 模型自动确定属性权重;Yan 等[11]提出了在案例检索过程中优化权值的方法,提高了问题求解的效率;WU 等[12]提出了一种基于粒子群优化的权值确定方法。然而,现有的研究很少考虑决策者的心理行为。各种情绪如高兴、后悔或不喜欢,可能会影响决策过程。因此,在评价案例相似性时,有必要考虑决策者的心理行为。
目前,前景理论(PT)[13-14]、后悔理论(RT)[14-15]和累积前景理论(CPT)[16]被提出用来模拟决策过程中的心理行为。PT 和CPT 有一定的局限性,例如,参考点必须提前给出,但很难确定,计算公式中必须设置很多参数。RT 不需要提前确定参考点,但参数较少,其侧重于在选择一种选择而不是另一种选择时的后悔和欣喜。RT 在许多研究中被用来解决决策问题,考虑决策者的心理行为。Zhang 等[15]将RT 纳入群体决策中,考虑决策者的后悔厌恶情绪。Zhou 等[17]提出了一种基于TOPSIS 和RT 的灰色随机多属性决策新方法。Peng 等[14]提出了一种基于RT 和PT 的新方法来解决随机多属性决策问题。因此,RT 是解决考虑心理行为的决策问题的有效工具。
本文针对具有多个异构属性和不完全权重信息的场景,提出了一种案例检索方法。首先,利用RT考虑决策者的心理行为来计算案例相似度。其次,根据基于案例相似度的感知效用构造一组相似的历史案例。然后,选择最合适的历史案例,考虑决策者的心理行为,并结合RT 来评价效用。最后,根据基于案例相似度的感知效用和基于评价信息的感知效用计算案例综合效用。此外,历史案例属性和评价属性的权重不完整,决策者对相似的历史案例进行偏好分配。利用线性规划的多维偏好分析(LINMAP)方法,构建了基于一致性和不一致性度量的数学规划模型,以确定属性权重。该方法创新之处在于:1)采用RT 考虑了决策者的心理行为,更符合实际决策,能够提供更好的决策结果。2)问题属性和评价属性的权重由LINMAP 确定。实例检索结果更加客观、准确。3)该方法不仅考虑了基于历史案例与目标案例相似度的感知效用,还考虑了决策者的评价效用。因此,该结果更适合于目标案例。
1 问题描述
1.1 模糊数
定义1[18]让U={u1,u2,…,um}成为一个有限集。U 中的直觉模糊集A 可以定义为A={<ui,uA(ui),vA(ui)>|ui∈U},其中函数:uA:U→[0,1]、vA:U→[0,1]分别表示隶属度和非隶属度,且满足条件0≤uA(ui)+vA(ui)≤1。设πA(ui)=1-uA(ui)-vA(ui)为满足条件0≤πA(ui)≤1 的直觉模糊集的犹豫程度。
为方便起见,定义满足条件uα∈[0,1],vα∈[0,1],0≤uα+vα≤1 的直觉模糊数为α=(uα,vα),分数函数可以定义为s(α)=uα-vα。
定义2[19]假设X 是一组对象。单值中性集合可以定义为A={x(TA(x),IA(x),FA(x))|x∈X},其中,TA(x)、IA(x)和FA(x)分别表示真隶属函数、不确定性隶属函数、假隶属函数,满足下列条件:∀x∈X,TA(x),IA(x),FA(x)∈[0,1]并且0≤TA(x),IA(x),FA(x)≤3。
为方便起见,将单值中性数定义为(TA(x),IA(x),FA(x)),简写为A=(Tx,Ix,Fx)。
1.2 不完整的权重信息
在现实世界中,案例信息往往是不确定的,属性权重也可能是不完整的。不完全权值信息有五种描述形式[20-21],Λt(t=1,2,3,4,5)用属性权值的一个子集Λ0表示。设W={w1,w2,…,wm}为属性权重向量,且,0≤wi≤1,i∈M,M={1,2,…,m}。
(1)弱排序:Λ1={w∈Λ0|wi≥wj,for all i∈I1and j∈J1},其中I1和J1是所有属性的下标索引集M 的两个不相交的子集。
(2)严格排序:Λ2={w∈Λ0|uij≥wi-wj≥λij,for all i∈I2and j∈J2},其中uij>0 和λij>0 为常数,满足uij>λij;I2和J2是下标索引集M 的两个不相交的子集。
(3)差异排序:Λ3={w∈Λ0|wi-wj≥wk-wl,for all i∈I3,j∈J3,k∈K3and l∈L3},其中,I3,J3,K3,L3是下标索引集M 的四个不相交子集。
(4)乘法排序:Λ4={w∈Λ0|wi≥ηijwj,for all i∈I4and l∈J4},其中ηij>0 且为常数;I4和J4是下标索引集M 的两个不相交的子集。
(5)区间排序:Λ5={w∈Λ0|λi≤wij≤λi+εi,for all i∈I5},其中λi>0 和εi>0 为常数;I5是M 的子集。
1.3 后悔理论
在案例检索过程中,决策者往往由于自身知识的不确定性和局限性而不能完全理性,在做决定时也会有一些情绪(如后悔和高兴等)。在决策过程中应该考虑情绪,它们往往会影响决策。RT 不仅考虑所选方案的效用,还考虑其他方案的效果[22-23]。因此RT 由两部分组成:当前结果的效用函数和与其他结果相比的后悔/欣喜函数。
设A={A1,A2,…,An}为一组备选项,其中,Ai表示第i 个备选项。Ai为选择备选方案后可能得到的结果为xi。然后,定义决策者对备选方案的感知效用ui为
其中,x*=max{xi|i=1,2,…,n}。这意味着决策者会后悔选择了另一个方案xi,而不是最好的方案。这里v(xi)是满足条件v'(xi)≥0 和v''(xi)≤0 的当前结果的效用函数。本文用幂函数来定义效用函数,即
其中,α 为决策者的风险规避系数,0≤α≤1。α 越小,表明决策者的风险规避程度越高。R(u(xi)-u(x*))表示后悔值,它满足条件R(u(xi)-u(x*))<0。后悔/欣喜函数为
其中,δ 为决策者的风险规避系数。δ 越小,表明决策者的风险规避程度越高。
2 方法步骤
2.1 基于属性相似度的感知效用计算
C={C1,C2,…,Cm}是历史案例的集合,其中,Ci为第i 个历史案例,C0为目标案例。历史案例和目标案例的问题属性向量为X={X1,X2,…,Xn},其中,Xj表示第j 个问题属性。历史案例的问题属性值为xij,其中,i∈{1,2,…,m}且j∈{1,2,…,n},目标案例的问题属性值为x0j。为属性权重向量,其中,表示jth 属性权重,。dj(C0,Ci)表示针对问题属性的目标案例与历史案例的属性距离。根据属性类型的不同,有以下四种场景定义问题属性距离。
(1)当属性Xj是一个确切数,则
(2)当属性Xj为区间数时,,则
(3)当属性Xj为直觉模糊数时,xij=
(4)当属性Xj为单值中性数时,xij=
利用逆指数函数计算属性相似度[6],计算公式为
在计算案例相似度时,RT 考虑了情绪。如果属性相似度的值不是最大的,决策者会后悔;否则,他们将会欣喜。因此,引入RT 来计算决策者对案例相似度的心理行为。基于案例相似度的感知效用计算步骤如下:
(1)假设问题属性Xj的理想属性相似度为Simj+,计算公式为
(2)基于属性相似度计算感知效用。根据上述1.3,感知效用包括两部分:效用值和后悔/欣喜值。设uij为基于属性相似度的效用,计算公式为
(3)假设基于属性相似度的后悔/欣喜值为rij,计算公式为
在此基础上,可以定义基于属性相似度的感知效用vij为
(4)计算基于案例相似度的感知效用Φi为
显然,Φi∈[0,1]。Φi值越高,历史情形越适用。
2.2 案例相似性、一致性和不一致性测量的感知效用值
设Ω={(k,l)|Ck≥Cl,k,l=1,2,…,m}为决策者给出的多维偏好信息。如果对于历史案例(k,l)∈Ω,Ck≥Cl,那么历史案例Ck比历史案例Cl有更多的感知效用。因此,基于由Φk和Φl确定的历史案例Ck和Cl的排序顺序与决策者给出的偏好是一致的。相反,如果Ck<Cl,则没有选择,因为由Ck和Cl决定的排序顺序与决策者给出的首选项不一致。随后,定义了一个指标来衡量由Ck和Cl决定的历史案例Ck和Cl排序的一致性程度。一致性指标定义如下
接下来,一致性索引可以重写为
此外,总一致性指标定义为
显然,完全一致性程度越高,G 越大。
同样,由Φk和Φl确定的衡量历史案例Ck和Cl排序不一致程度的指标定义为
随后,不一致性索引可以重写为
此外,总不一致性指数定义为
同样,完全不一致程度越高,B 越大。
2.3 基于LINMAP 的数学规划模型
对于案例检索,确定属性权重至关重要,因为它们与感知的效用值相关联。最近的研究主要采用两种方法:开发优化模型[7,24]和机器学习[11,25]。然而,因为考虑了模糊参考信息,这两种方法并不适合解决本文的问题,本文的权重信息包含主观的多维属性,是不完整的。LINMAP 方法是基于决策者给出的备选方案的两两比较。当解决方案接近理想的解决方案时,生成最佳替代方案。此外,LINMAP 方法通过构建数学规划模型来确定属性权值。因此,使用LINMAP 来确定属性权重。根据文献[15,26],数学规划模型应保证感知效用的一致性程度尽可能大,感知效用的不一致性程度尽可能小。构建以下模型来确定属性权重
其中,η>0 是一个由决策者给出的先验阈值。并且,ε>0 是一个足够小的正数来保证>0。
设λkl=max{0,Φk-Φl},(k,l)∈Ω。因此λkl≥0 且λkl≥Φk-Φl;λkl≥0 且Φl-Φk+λkl≥0。可以得到
可将式(20)改写为如下数学规划模型
2.4 历史相似案例集
如果满足条件Φi>ξ,则可以选择该历史案例Ci。此外,所选择的历史案例形成一个相似的案例集Sv,v∈{1,2,…,h},找到相似历史案例的索引集Sv={Ci}|i∈Nv}。
2.5 历史相似案例的效用评价
第p 个决策者Dp,p={1,2,…,h}根据相似的案例集,评估其备选方案应用于目标案例的效果。假设评估属性由R={R1,R2,…,Rt}和s={1,2,…,t}表示,其中Rs是评估属性。让表示类似历史案例Sv的Dp的评估属性值。设为求值属性权重的向量,使。在不确定的情况下,决策者主要考虑语言变量和清晰的数字来表示评估的属性值。然后对类似历史案例的效用进行评价的步骤如下:
(1)将语言变量转化为三角模糊数并进行去模糊化。设Y 是一个具有奇基数的语言项集,即Y={yq|q∈{1,2,…,T}},并将语言变量yq,yq∈Y 转化为如下三角形模糊数[29]
(2)规范化评估的属性。当语言变量转换为清晰数时,所有的评估属性都是清晰的。规范化计算的属性如下
其中,(β-γ)∈Ωp为决策者Dp给出的多维偏好信息。
(7)参照上述2.3 节,构建数学规划模型,确定属性权重
(8)根据评价标准计算综合感知效用Uv,即
2.6 案例的综合效用和历史案例的排名
为了检索最合适的历史案例,需要衡量案例的综合效用,并对相似的历史案例进行排序。因此,本文使用一种简单的加法方法基于案例相似度Φi(i∈Nv)来聚合感知效用Φv,以及基于评价标准的综合感知效用Nv,因此,综合案例效用定义为
显然,Γv的值越大,说明历史案例Cv越适用目标案例。
3 案例分析
3.1 案例研究
近年来,我国发生了各种瓦斯爆炸事件,给社会造成了巨大的损失。这类紧急情况涉及类似的问题,可以用类似的解决办法加以解决。因此,可以使用CBR 快速生成针对目标情况的替代解决方案。
A 公司是福建省的一家煤炭公司,当新的瓦斯爆炸紧急情况发生时,该公司使用CBR 检索最相似的历史案例,以生成替代方案。为此,这家公司收集10 个历史案例(C1,C2,…,C10),包含8 个属性(X1,X2,…,X8),即地下人员的数量(X1)、爆炸的影响(X2)、对通风系统的破坏程度(X3)、滑坡的程度(X4)、起火的范围(X5)、浓度(X9)、CO 浓度(X7)和CH4浓度(X8),其中X1、X6、X7和X8都是清晰的数字;X2为区间数;X3是一个直观数;X4和X5是单值中性数。表1 描述了历史案例和目标案例(C0)。本研究的目的是检索最合适的历史案例,并帮助决策者生成针对目标案例的替代解决方案。

表1 历史案例及目标案例信息
(1)使用式(4)~(8)计算属性相似度,计算结果如表2 所示。将多维偏好信息设置为Ω={(2,1),(3,4),(5,4),(6,3),(6,10),(7,4)(10,9)}。此外,我们假设属性权值是不完整的。Λ={w∈Λ0|w1>2w2;0.01≤w2-w3≤0.2,0.1≤w4≤0.2,w4-w5≥w1-w2,w5≥w6,0.1≤w7≤0.1,w8≥2w7}。

表2 属性相似度Simj(C0,C1)计算结果
(2)使用式(9)~(12)计算基于属性相似度的感知效用vij,计算结果如表3 所示。设置ρ=0.01、ε=0.05、α=0.08 和δ=0.3。然后根据式(14)~(19)构造数学规划模型,得到属性权值为wp={0.120 0,0.060 0,0.050 0,0.200 0,0.140 0,0.130 0,0.100 0,0.200 0}。

表3 基于属性相似度的感知效用
(3)根据式(13)得到基于案例相似度的感知效用。计算结果为Φ1=0.453 5,Φ2=0.580 2,Φ3=0.638 0,Φ4=0.538 2,Φ5=0.603 6,Φ6=0.516 5,Φ7=0.514 1,Φ8=0.521 6,Φ9=0.611 7,Φ10=0.675 0。
(4)决策者设定感知效用阈值ξ=0.6,得到一组相似的历史案例为S={S1,S2,S3,S4}={C3,C5,C9,C10}。随后,三位决策者对三个属性进行评价:应急救援效果(R1)、伤亡减少率(R2)、财产损失减少率(R2)。表4 列出了评估标准。评价属性R1由语言变量集s={very good:VG,good:G,normal:N,bad:B,very bad:VB}确定。

表4 评估信息
(5)根据式(23)~(24),将语言变量转换为清晰的数字。根据式(25)~(28),可以得到基于评价标准的感知效用,结果如表5 所示。
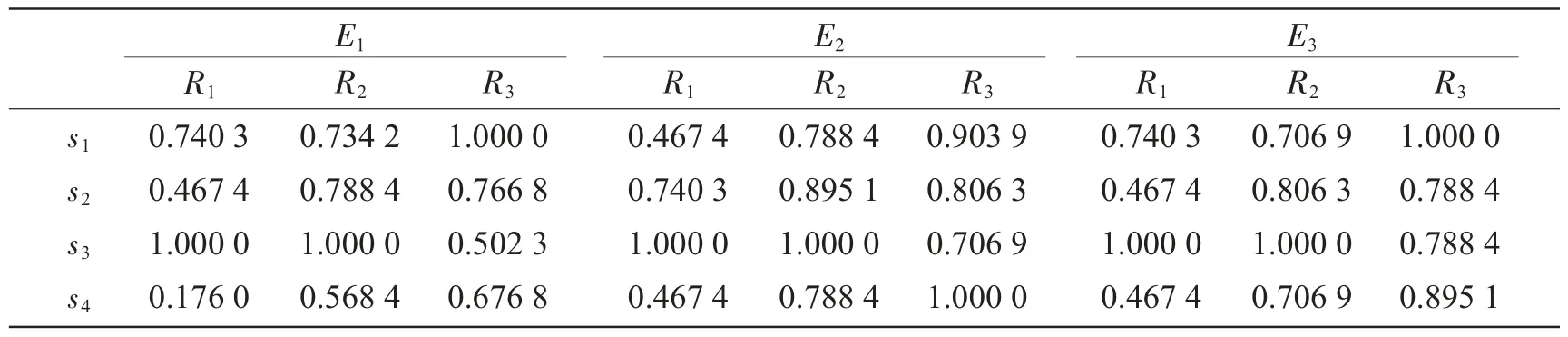
表5 基于评估信息的感知效用
(6)对于三个决策者,设置多维偏好信息:Ω1={(1,2),(1,3),(2,3),(3,4)},Ω2={(3,1),(2,4),(3,4)}和Ω3={(1,2),(2,4),(3,1)}。根据式(29)~(31),建立数学规划模型,确定属性权值Wp={0.218 0,0.436 0,0.346 0}。然后,根据式(32)评价的信息Uv计算综合感知效用,结果为U1=0.800 5,U2=0.755 9,U3=0.884 4,U4=0.677 3。
(7)使用式(33)计算案例综合效用Γv。计算结果为Γ1=0.510 7,Γ2=0.456 2,Γ3=0.540 9 和Γ4=0.457 2。接着,将类似的历史案例按其综合案例效用排序为Γ3≥Γ1≥Γ4≥Γ2。因此,最合适的历史案例是C9。
3.2 方法的比较分析及优势
为了说明本文所提方法的特点和有效性,将其与现有的案例检索方法进行了比较,包括:1)传统案例检索方法[6],即CBR-F;2)不考虑决策者心理行为的案例检索方法,即CBR-NPB;3)基于PT 的不考虑评价信息的案例检索方法,即CBR-PT;4)基于PT 考虑评价信息的案例检索方法,即CBR-PTT。基于上述案例研究的四种案例检索方法,最适合的历史案例如表6 所示。图1 显示了在没有考虑决策者评价的情况下,按案例检索方法对历史案例的排序,即本文提出的方法、CBR-F 和CBR-PT。图2 显示了按案例检索方法(即本文提出的方法、CBR-NPB 和CBR-PTT)对相似历史案例的排序。

图1 历史案例排序
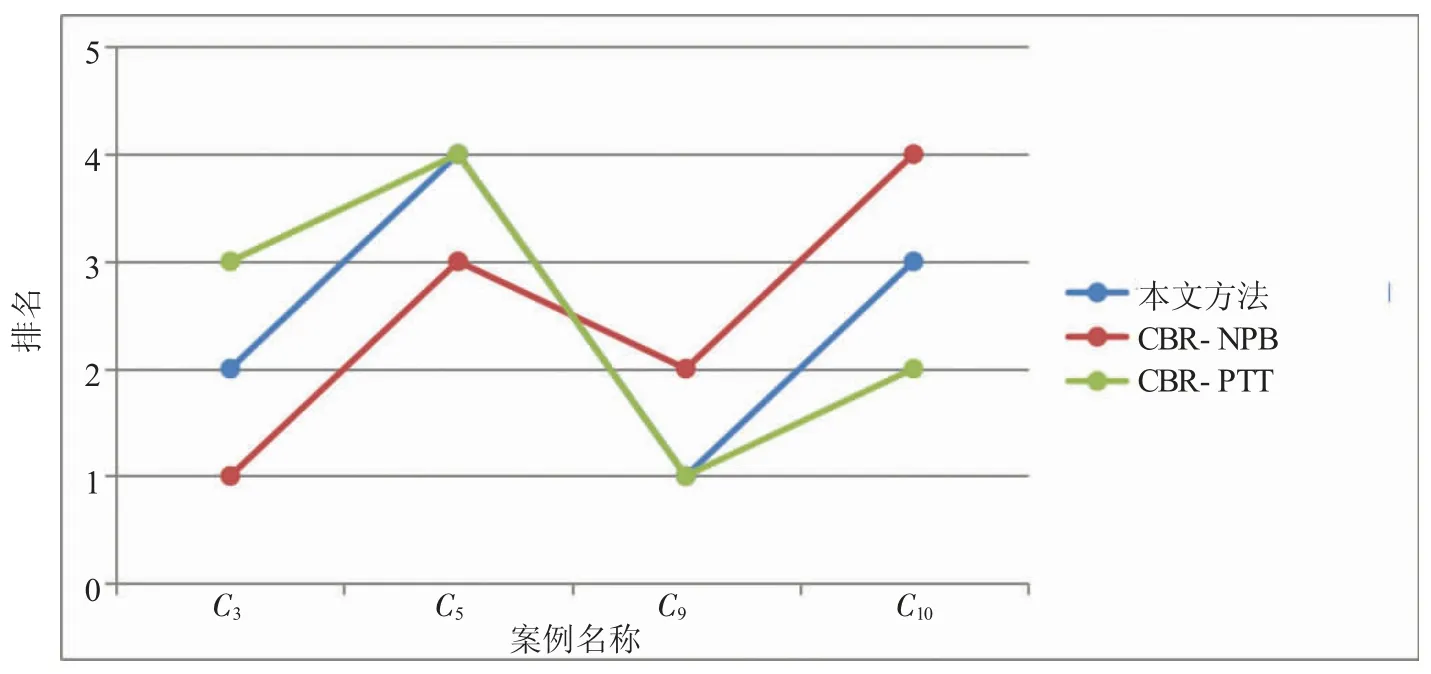
图2 历史相似案例排序

表6 不同方法的比较
根据表6 和图1,以下分析四种案例检索方法:
首先,CBR-F 基于案例相似性获得最适合的历史案例。案例相似性排序为C3>C10>C5>C9>C2>C8>C7>C4>C6>C1,最适合的历史案例为C3。但在现实中,应该在考虑案例相似度和历史案例相似度评价标准的同时,选择最适合的历史案例。此外,决策者在决策过程中也不是完全理性的[7]。因此,在现实的决策情景中,考虑评价标准和决策者的心理行为,选择最合适的历史案例更为合适。
其次,CBR-NPB 在计算案例相似性和效用时没有考虑决策者的心理行为。类似的历史案例为{C3,C5,C9,C10}。计算评价标准的效用[13],使用式(31)计算类似历史案例的综合效用。采用CBR-NPB 方法得到的排名为C3>C9>C5>C10,这与本文所提出的方法的结果不同,因为CBR-NPB 没有考虑决策者的心理行为。然而,在现实中,决策会受到个人偏好和心理行为的影响,因此,将心理行为纳入模型更加合理。
此外,将本文提出的方法与CBR-PT 方法进行了比较。将PT 中的参数设置为α=0.89、β=0.92 和γ=2.25,所有属性距离的参考点设置为0.5。案件相似性的排名是C10>C9>C8>C3>C6>C7>C5>C2>C4>C1,最相似的历史案例是C10,这与本方法计算案例相似度的结果一致。但是CBR-PT 没有考虑评价标准,最终结果是不同的。在选择最合适的案例时,不能仅仅依靠相似度来确定,相似度稍低的历史案例可能与目标案例更一致。因此,有必要通过对决策者的评价来确定合适的历史案例,结果会更加准确。
最后,对基于CBR-PTT 方法得到的类似历史案例进行排序C9>C10>C3>C5,最合适的历史案例为C9,与本文所提出的方法得到的结果相同。而PT 首先需要确定参考点,此外,还有几个参数需要确定,然而,RT 决定的参数更少,这些参数的确定通常由决策者给出,参数越多,决策者的主观决定会导致结果的偏差越大,因此,基于RT 的案例检索更适合基于PT 的方法。
案例属性和评估属性的权重由LINMAP 确定,使用该方法建立数学规划模型,考虑案例信息和不完全多维偏好信息来确定权重。与通过构建模型来确定权重的方法相比[7,22],该方法不仅考虑了客观信息,还考虑了决策者的主观偏好,因此,它更适合现实世界的决策过程。
通过与现有基于案例检索的案例检索方法的比较,发现本文提出的方法具有以下优点:1)现有案例检索方法在计算案例相似度时很少考虑心理行为。虽然基于PT 的案例检索考虑了心理行为,但在计算过程中需要设置很多参数,此外,参数的改变会改变结果。相比之下,本文方法不仅考虑了心理行为,而且参数少,计算简单。2)在选择最合适的历史案例时,本文方法考虑了与目标案例相似的历史案例对备选方案的评价。3)采用LINMAP 方法确定案例属性和评估属性的不完全权重。本文方法可以在计算案例相似性和综合效用时提供更客观、准确的结果。
4 结语
本文提出了一种基于案例检索和逆向检索的案例检索方法,用于在具有多个异构属性和不完全权重信息的场景中检索最合适的历史案例。该方法具有以下三个特点:1)在不确定情况下考虑了异构的多属性信息。2)考虑决策者的心理行为,计算案例相似性和综合效用,这是一个更加现实的情景。3)为提高结果的准确性,采用LINMAP 方法确定案例属性和评价属性的权重。此外,LINMAP 聚合了三种类型的信息:案例相似性或评估效用、不完整的权重信息和多维偏好信息。该方法有助于决策者选择最合适的历史案例,但也存在一些局限性。例如,案例检索过程只考虑一种状态,但实际中紧急情况可能不断变化。因此,未来的研究应侧重于突发事件动态演化情景的案例检索方法。
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
英语文摘(2021年12期)2021-12-31
科普童话·学霸日记(2020年1期)2020-05-08
少儿美术(2019年7期)2019-12-14
小天使·一年级语数英综合(2019年2期)2019-01-10
当代陕西(2018年9期)2018-08-29
中国塑料(2016年9期)2016-06-13
现代农业(2015年5期)2015-02-28
现代农业(2015年5期)2015-02-28
软科学(2014年8期)2015-01-20
