
基于混合神经网络模型的卷烟投放预测方法
2024-02-05 05:57张吴波马勋政
云南民族大学学报(自然科学版) 2024年1期
邹 旺,张吴波,2,马勋政,3
(1.湖北汽车工业学院,电气与信息工程学院,湖北 十堰 442002;2.武汉科技大学,计算机科学与技术学院,湖北 武汉 430081; 3.湖北省烟草公司十堰市公司,湖北 十堰 442000)
烟草部门落实国家“总量控制,稍紧平衡”的方针,为了更好的消化社会库存,促进市场良性发展,在每轮投放中都会根据卷烟规格和不同档位的零售户来制定具体的投放策略.由于卷烟品种繁多,投放策略需要每轮重新制定,任务繁重,同时存在主观情感等局限性,难以实现大规模的准确计算.建立科学的卷烟投放预测模型有利于烟草专卖局对资源合理的利用和产品精确的投放,有利于推进精细化管理.
目前卷烟投放预测技术的研究主要包括传统方法和机器学习方法.传统方法是应用概率统计学和计量经济学的思想,建立概率模型或多组线性函数去拟合并预测卷烟历史销售数据.王伟民等[1]提出1种基于灰色马尔科夫模型的卷烟需求预测方法,并在10年的全国卷烟销量数据集上验证该模型的准确性.王诗豪等[2]集成差分自回归移动平均模型(ARIMA)、向量自回归模型(VAR)、支持向量回归(SVR)以及习惯消费下的卷烟需求模型来实现卷烟需求的预测.随着机器学习算法的广受瞩目,不少研究者逐渐将其引入到卷烟销量预测的任务中.武牧等[3]提出1种线性模型整合支持向量机(SVM)的卷烟销量预测方法,该模型相比ARIMA模型的误差率降低45.79%.为了进一步提升学习器的性能,研究者考虑将单个学习器融合向集成学习方向发展.目前,集成学习按照优化方向可以分为用于减少方差的装袋算法(Bagging)[4]、用于减少偏差的提升算法(Boosting)[5]、用于提升准确率的堆叠算法(Stacking)[6]3大类.韩伟民等[7]提出1种极端梯度提升(XGBoost)的卷烟创新产品的工商交易预测.机器学习方法中的深度学习算法的适用性更广、精度较优.在卷烟销量预测中广泛使用有门控神经网络特点的长短期记忆网络(LSTM)[8]和循环门控单元(GRU)[9]模型.邓超等[10]提出1种基于LSTM和BP神经网络模型的卷烟智能投放模型,该模型能实现产品销量的预测和卷烟产品投放策略的生成.
1 相关技术
1.1 GRU神经网络
GRU作为LSTM的改进优化模型,拥有更少的参数和简单的结构.GRU只包含更新门、重置门两种门控结构,更新门负责对信息的筛选和存储;重置门负责对上一节点状态选择性遗忘.GRU内部结构如图1所示.
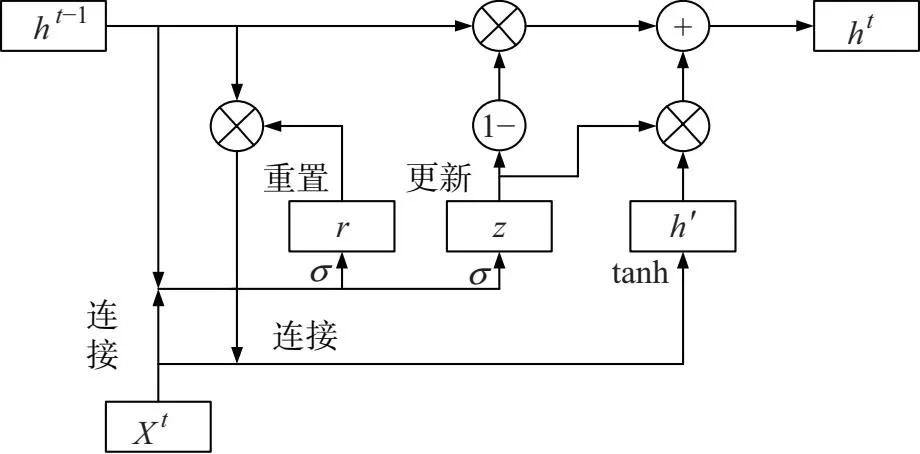
图1 GRU结构图
其中,Xt表示当前节点的输入;ht-1表示上一节点的隐藏状态;r为重置门;z为更新门;h′为候选隐藏状态;ht表示传递给下一节点的隐藏状态.GRU内部计算如式(1)-(4)所示.
r=σ(w1[ht-1,Xt]+b1).
(1)
z=σ(w2[ht-1,Xt]+b2).
(2)
h′=tanh(w3[r⊗ht-1,Xt]+b3).
(3)
ht=(1-z)⊗ht-1+z⊗h′.
(4)
其中:σ表示Sigmoid激活函数;tanh为激活函数;[ ]表示两个向量相连接;W1-3为权重矩阵;b1-3为偏置项.
1.2 Boosting-GRU模型
Boosting算法的思想是将多个基学习器串联组合,通过不断的调整样本权重来训练每个基学习器,然后计算每个基学习器的权重值,待所有基学习器训练完成后,按相应的权重值线性组合所有基学习器得到一个整体模型,以此来提升模型的性能.更新样本权重的目的是使本轮预测错误的样本在下一轮训练中得到更大的权重,受到更多的重视[11].权重值用于评估每个基学习器的重要性,基学习器预测越准确在整体模型中的权重越大.

图2 Boosting-GRU模型结构
Boosting-GRU模型的结构如图2所示,在Boosting模型中采用多个GRU模型作为基学习器.首先对训练集分配初始样本权重值,将带样本权重值1训练集输入到GRU1模型中进行训练.然后采用测试集进行模型的预测,计算预测的误差率并以此来更新样本权重2和计算当前基学习器的权重值1.最后采用带样本权重值2训练集训练第二个基学习器,依次串联的训练所有的基学习器.
2 卷烟产品投放策略生成模型
产品投放策略生成模型如图3所示.为精确的预测投放值序列(即下一年48轮投放值组成的序列),卷烟产投放策略生成模型采用3种不同的方法来计算投放值.第1种方法首先采用多元预测模型得到产品销售量序列,然后通过销售量与投放值之间的关系来计算投放值序列1;第2种方法直接采用多元预测模型来计算投放值序列2;第3种方法采用多分类模型进行海量数据的训练并预测投放值序列3,最后选择3种序列中误差值最小的序列为最终序列.
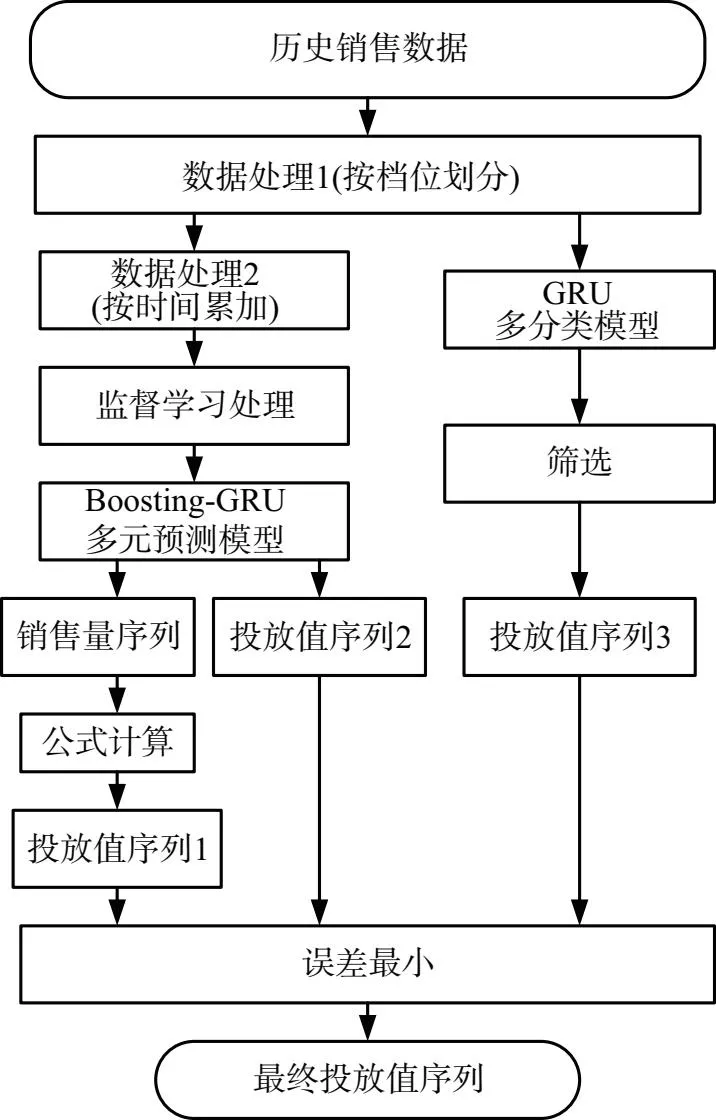
图3 卷烟产品投放策略生成模型
2.1 数据处理
数据处理将历史销售数据处理为模型所需的输入数据,历史销量数据为A卷烟产品的所有零售户的订购信息,其中包括时间、档位、投放值、订购量(销售量)、定足率、订单满足率共6条信息.首先将数据按不同的档位划分为1~30份数据,该数据可以用于训练GRU多分类模型.然后在档位划分的基础之上按时间进一步处理,得到数据包括总户数、订购户数、销售量(累加)、投放值、定足率(均值)、订单满足率(均值)、订购率(计算).其中定足率、订单满足率、订购率的计算方法如下:
定足率=(订购量÷投放量)×100%.
订单满足率=(客户订购量÷客户需求量)×100%.
订购率=(订购户数÷总户数)×100%.
最后将数据进行监督学习处理来用于训练Boosting-GRU多元预测模型.
2.2 多元预测模型原理
采用神经网络模型进行序列预测前需要对数据进行监督学习处理[12],设定一定长度的“回溯”值.例如,投放值序列为15,10,10,5,5,回溯值设置为1,则预测模型训练数据为x=[15,10,10,5]、y=[10,10,5,5];回溯值设置为2,则预测模型训练数据为x=[[15,10],[10,10],[10,5]]、y=[10,5,5],即采用前回溯个数据x来预测后一个数据y.多元预测是将每一行的总户数、订购户数、销售量、投放值、定足率、订单满足率、订购率采用归一化处理至0~1之间,然后将x作为数据y为标签输入Boosting-GRU模型进行训练,通过GRU模型捕捉这7种数据之间的关系和各自数据随时间变化的前后联系,Boosting算法能降低GRU模型预测的偏差,模型输出的结果为产品销售量序列和投放值序列.
烟草行业常规的投放策略主要按“档位”来制定.例如A产品卷烟在第1挡位投放5条,第2档位投放6条,….则属于1挡位的零售户订购上限为5条,属于2档位的零售户订购上限为6条,依次类推.由此来计算投放值的估值,第N档位零售户下一轮关于A产品销售量SN和投放值TN之间的计算公式如下:
TN=SN÷(SN总户数×RN订购率), 1≤N≤30.
(5)
其中,销售量SN通过模型预测得到;SN总户数为第N档位零售户数量;RN订购率为第N档位的订购率.
由于投放值只能为整数,采用公式计算和模型预测的投放值会存在小数的问题,模型采用四舍五入函数进行取整.
2.3 多分类模型原理
多分类模型采用有监督的学习方式,数据集为同档位内的零售户所有信息,将投放值作为标签y,其它相关数据为x.首先统计投放值有多少类值来确定模型属于几分类任务,如果投放值设置为1~15那么模型设置为15分类.然后将数据转化为计算机便于计算的形式,即x数据归一化至0~1之间,标签y数据采用独立热编码表示.最后将(x,y)输入到GRU模型中进行训练,模型会根据标签y来挖掘x数据之间的关联,并通过全连接层和Softmax层计算投放值类别的概率.由于模型在测试集上预测的不确定性,同时还需要对预测的结果进行筛选来确定最适合该时间段的投放值,筛选原则在某时间段预测结果类别数量最多则为该时间的投放值.
3 实验验证
3.1 数据集
实验的数据来源湖北省烟草公司十堰公司2016年1月1日至2021年12月30日的 2 630 万条历史销售数据,为实现对具体产品不同档位零售户的投放预测,选取191万条红金龙软装精品为实验对象.对实验数据按照档位处理得到30份平均6.4万条的历史销售数据,卷烟产品按周投放,不包括假期每年共48轮投放,按照时间段处理得到288条累计数据.采用2016-2020年时间段内的数据为训练集,2021年时间段内的数据为测试集,在2021年数据上验证投放策略生成模型的性能.卷烟产品投放策略生成模型的各部分输入输出和数据集划分如表1、表2所示.

表1 模型各部分的输入输出

表2 模型各部分的数据集划分
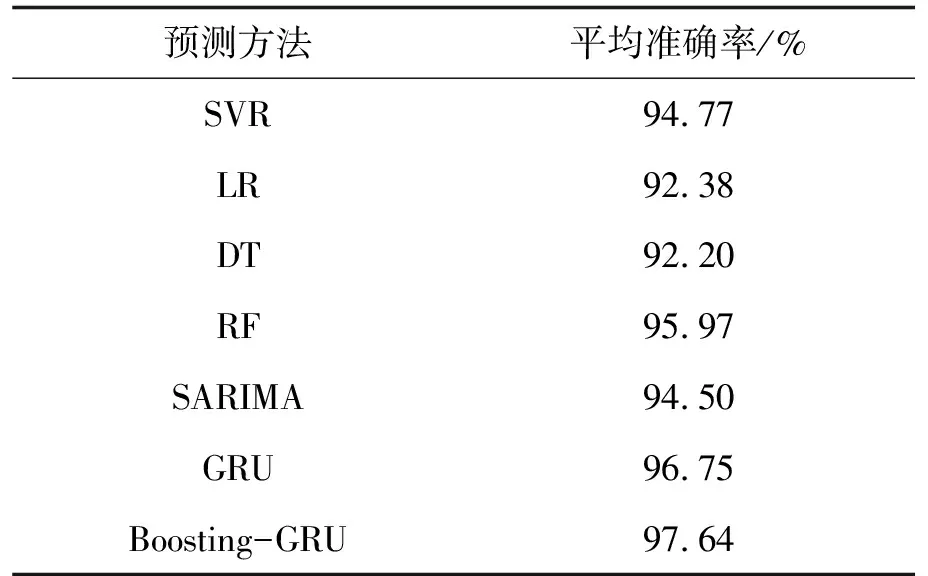
表3 各种预测方法的平均准确率对比
3.2 实验设置及评价指标
实验在Windows10上进行,CPU为Intel(R) Core(TM) i9,3.10GHz,GPU为RTX3060 12G,编程语言为Python3.7,深度学习框架为Tensorflow 2.4.1和Keras 2.4.3.
实验中模型的的参数设置:GRU中隐藏单元数为256;Boosting算法中GRU模型的个数为10;迭代次数为20次;批次大小设置为32;学习率为1e-5;优化器Adam;为防止过拟合dropout设置为0.2;预测模型的损失函数为均方根误差;分类模型的损失函数为交叉熵代价函数.
实验选用准确率和平均绝对误差(MAE)作为投放策略生成模型的衡量指标,其计算过程如下式(6)-(7)所示.

(6)
(7)

3.3 销售量预测
销售量预测通过多元预测模型来实现,为了验证Boosting-GRU多元预测模型的准确性,实验同时采用支持向量回归(SVR)、逻辑回归(LR)、决策树(DT)、随机森林(RF)、季节性差分回归移动平均模型(SARIMA)、GRU神经网络模型共6种回归预测方法作为对比.计算几种方法在1~30档位零售户的历史销售数据上预测销售量的准确率并取平均值,各种方法预测的平均准确率对比如下表3所示.为便于直观的观测模型预测的性能,列举多元预测模型在1档、15档和25档零售户上红金龙软装精品卷烟2021年的销售量预测如下图4所示.
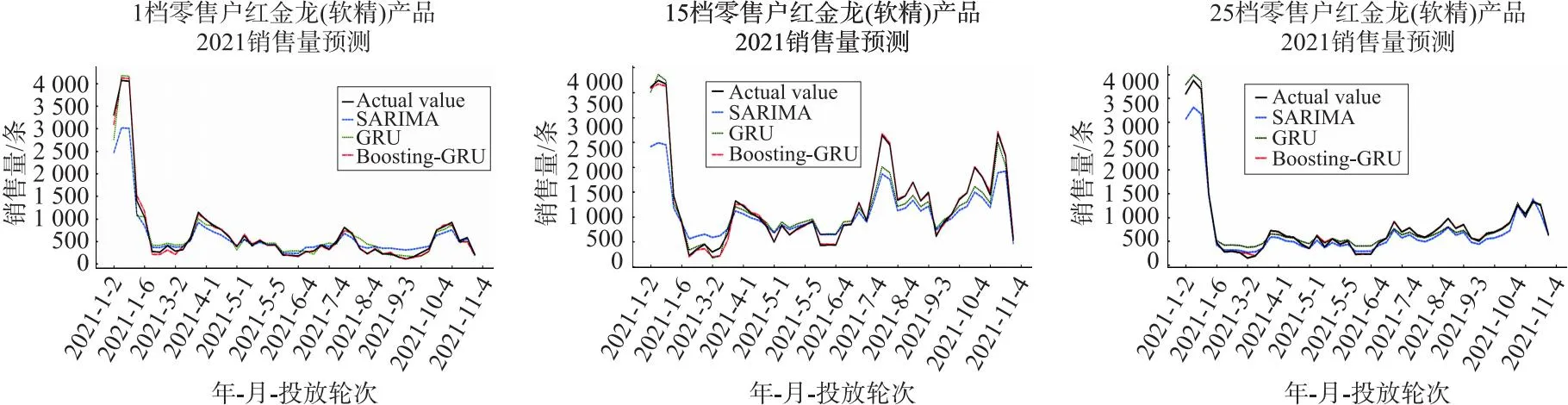
图4 多元预测模型的预测对比
由表3可知,Boosting-GRU模型在不同档位数据上的预测相比其它预测方法预测效果更优,平均预测准确率达到97.64%,对比另外6种预测方法的平均准确率最低提升1.67%,最高提升5.44%.由图4观测可知,在列举的1档、15档和25档零售户档位上预测的效果均为:Boosting-GRU>GRU>SARIMA,神经网络的预测结果要优于传统预测模型,而结合Boosting算法的神经网络模型能通过不断调整样本权重来降低预测结果的误差,从而提高整体模型的预测能力.
3.4 投放策略生成模型验证
卷烟产品投放策略生成模型在十堰市2021年红金龙软装精品的1~30档位零售户的历史销售数据上进行验证,通过观测模型销售量预测值以及投放值序列的平均绝对误差来验证模型的性能,实验结果如下表4所示.为便于直观的观测投放策略生成模型性能,同时列举模型在1档、15档和25档零售户上红金龙软装精品卷烟2021年的投放策略生成效果,如下图5所示.
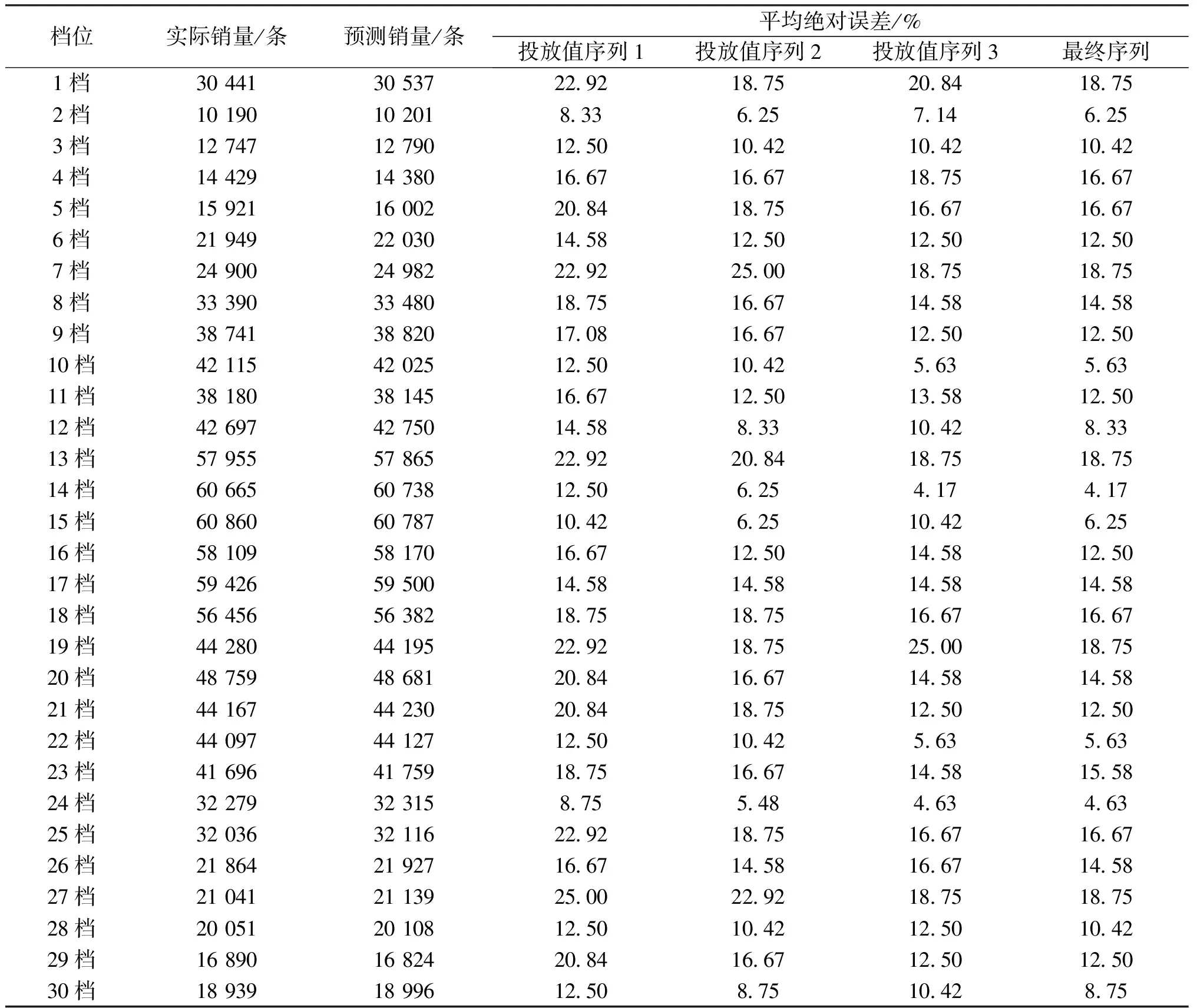
表4 投放策略生成模型验证
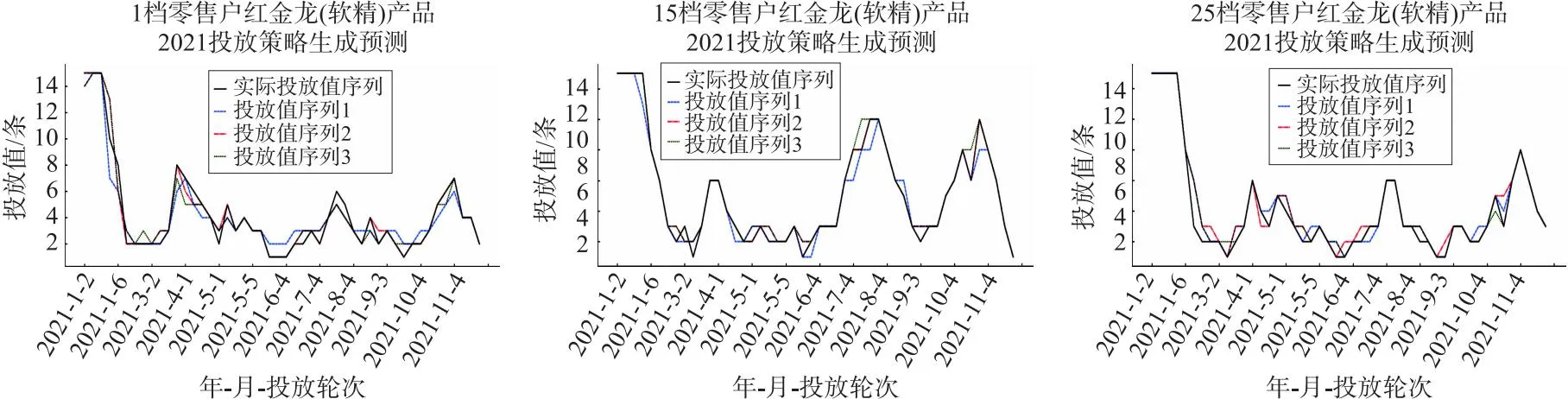
图5 投放策略生成模型预测效果
由表4对比计算可知,实际销量和预测的销量的差值均在100条以内.通过对比各投放值序列的误差,最终序列的平均绝对误差均低于20%.分析原因,最终序列是选择3种投放值序列误差最小的序列,因此最终序列更符合卷烟产品的投放策略.由图5观测可知,投放策略生成模型分别采用3种不同的方法计算投放值序列,在1档和15档零售户数据上预测效果,投放值序列2要优于投放值序列1和投放值序列3,模型最终会选择投放值序列2作为最终投放策略;在25档零售户数据集上预测的效果,投放值序列3优于投放值序列2和投放值序列1,即模型最终会选择投放值序列3作为最终投放策略.
4 结语
为科学制定卷烟产品投放策略,结合GRU神经网络模型和Boosting集成学习算法各自的优点,提出一种混合神经网络模型的卷烟投放预测方法.该模型采用Boosting-GRU多元预测模型、产品销量至投放值计算以及GRU多分类模型3种方法来分别计算卷烟产品投放值序列,并选择误差最小为最终的投放值序列.在湖北省十堰市卷烟产品的历史销售数据上进行实验,实验结果表明,该模型能很好的完成卷烟投放策略生成任务.
猜你喜欢
智富时代(2018年9期)2018-10-19
智富时代(2018年9期)2018-10-19
中国自行车(2018年5期)2018-06-13
北方牧业(2016年9期)2016-12-17
河南科技(2015年2期)2015-02-27
电测与仪表(2014年15期)2014-04-04
中国质量与标准导报(2014年10期)2014-02-28
钛工业进展(2014年3期)2014-02-11
中国烟草学报(2012年4期)2012-04-09
中国烟草学报(2012年4期)2012-04-09
