
基于强化学习的无人机网络资源分配研究
2024-02-04 04:34:32范文帝王俊芳杜龙海
计算机测量与控制 2024年1期
范文帝,王俊芳,党 甜,杜龙海,陈 丛
(中国电子科技集团公司 第54研究所,石家庄 050081)
0 引言
随着近几年无人机在关键技术上的突破,在军用和民用领域具有高机动性和低成本特性的无人机用途十分广泛。在人们的日常生活生产活动中,无人机越来越多地出现,在精准农业、应急救援、交通管制、货物递送等领域发挥着重要作用[1-3]。
然而随着无人化进程的加深,单无人机能力不足、资源有限、任务执行低效,如同自然界中动物通过成群结伴来弥补个体能力的有限[4],无人机集群执行复杂任务成为无人机应用的重要模式,无人机集群信息实现实时传递的关键是无人机通信网络。
但无人机通信网络在实际操作中存在着众多问题,比如,电力资源、功率资源等等都存在着资源利用率不高的问题。资源分配问题是智能场景下研究的一个热点,一些启发式算法被提出以解决资源分配问题,文献[5]运用禁忌搜索算法解决火力资源分配;文献[6]在资源分配问题上应用模拟退火算法,模拟退火算法容易实现,鲁棒性强、质量高,但优化过程所需时间较长;文献[7]提出武器动态资源分配问题,用动态规划的方法来解决,但是递归的使用在编码过程中使得效率非常低;文献[8]完善标准灰狼算法,提出解决资源分配难题的离散灰狼算法。群体智能算法的速度虽然与传统算法相比有所提升,但仅仅针对一个问题进行解决,很难扩展到其他问题的应用,在解决动态资源分配问题上效果不佳。
在无人机通信网络中,由于有限的频谱资源和动态的无人机用户需求,时隙分配最常被用来解决资源竞争和协调的问题。然而,时隙分配是一个经典的NP难题,困扰着众多研究者。其中一些传统的求解方式,如枚举法、分支定界法、动态规划法,这些都是很容易实现但又很缓慢的搜索方式;对于传统的智能算法,如遗传算法、差分进化算法,要想扩展有一定难度。巨大的状态空间和不断变化的环境使得传统的决策方法在这方面的效果并不理想。
随着各个研究领域深度强化学习技术的不断发展,强化学习被重新应用到此项问题。更多基于深度强化学习技术解决资源分配问题的方法被提出[9-12],强化学习算法训练出的模型不仅决策速度快,而且扩展性强,能够在各种场景中广泛应用,能够有效应对动态变化的环境,非常适用于动态资源分配问题。强化学习是一种基于经验学习和探索的智能算法,可以通过对实时环境的反馈以及循环性训练,不断优化决策结果。
文献[13]对无人机网络辅助移动边缘计算执行任务卸载策略这个领域做了一系列的研究探索,说明了基于强化学习的无人机网络的资源分配和路径规划可以在当前相关研究中达到不错性能;文献[14]集中探讨了无人机群网络频谱分配方面的研究,研究了使用强化学习的动态信道分配和动态时隙分配算法;文献[15]主要探讨了无人机集群中的资源分配和虚拟网络映射问题,该文献对现有的资源分配算法进行了分析,总结了其优劣之处,同时提出了一种全新的资源分配算法;文献[16]是以深度强化学习算法为基础的资源分配问题研究,结合专家经验与深度强化学习算法,探索引入专家数据对资源分配算法性能的影响。
为了对资源分配问题进行更好的研究,本文将在深度强化学习技术的帮助下,研究无人机通信网络中如何更好地解决时隙分配问题。
本文基于近端策略优化算法[17-18],设计了一个更高效的方法求解时隙分配问题。设计方法中的PPO算法使用Kullback-Leibler(KL)散度来限制更新前后的策略变化,解决了传统梯度下降优化算法[19-20]只能用最小步长进行更新的限制,PPO算法通常能优效地训练智能体执行复杂的控制任务。
1 无人机网络时隙资源分配方案
1.1 问题描述
无人机通信网络由M无人平台节点组成,由集合M={1,2,…,M}表示,m∈M表示无人平台节点的编号。其中,各无人平台节点之间构成多跳场景,节点维护自身的一跳和两跳邻居表,分别用N1(m)和N2(m)表示第m无人节点的一跳和两跳邻居集合。为了便于表示,利用矩阵C表示所有节点的一跳邻接矩阵:
(1)
其中:cm,n∈{0,1}表示第m节点和第n节点间是否存在链路,cm,n=1表示两个节点之间存在链路,第m节点和第n节点互为一跳邻居,即m∈N1(n),否则,两个节点之间不存在链路。
无人机通信网络因其拓扑结构的动态性导致难以预先设定中心节点作为集中控制设备,进行全局的时隙资源动态分配。为了在无人机通信网络中优化调度时隙资源,需设计以节点为中心的时隙分配算法。在一个时隙调度周期中,假设共有K空闲数据时隙可分配给M个无人平台节点用于发送数据,k表示时隙的编号。时隙的带宽被表示为B。利用二元变量tm,k∈{0,1}表示第k时隙到第m无人节点的分配情况,其中,tm,k=1表示第k时隙被分配到第m无人节点用于传输数据,否则tm,k=0。
此时,网络的信道利用率被定义为:
(2)
代表的是网络分配的时隙数和所有能够分配的时隙数的比值。
时隙分配问题可以构建为以提高信道利用率为目标的优化问题。
另外,无人节点在请求时隙时,同时上传自身网络状态信息,包括节点吞吐量、节点负载、时延等。考虑到不同无人平台节点上通信性能的差异性,将同一时隙分配给不同节点所带来的网络性能增益不同,因此为分配到节点的时隙设置效用函数。效用函数由每个时隙调度周期内节点上报的吞吐量、负载、时延等构成。为了消除不同性能指标间的量纲差异,对其进行归一化,下面以负载为例:
负载:假设节点的负载状态为Qm,每个节点可允许的最大负载和出现的最小负载分别是Qm,max、Qm,min,负载的归一化指标为:
(3)
每个节点的效用函数利用Um表示,指该节点负载的归一化指标的加权和,其表达式为:
(4)
其中:w的取值为1。
因此,为节点分配时隙的时候需要同时考虑网络的信道利用率以及节点本身的网络状态。
在广播调度问题中,存在两个限制条件:一是非传输限制,即在一个调度周期内,网络中的每个节点至少有一个时隙被调度;二是非冲突限制,即调度过程中要避免两类冲突,第一类冲突是节点不能同时发送和接收数据,第二类冲突是一个节点不能同时接收超过一个传输[21]。
此时,时隙分配问题被构建为:
(5)
(6)
其中:公式(5)为加权信道利用率,式(6)中C1保障了在一个时隙调度周期内所有无人平台节点至少存在1次时隙调度。假设两跳以上的节点可以利用空间复用的方式避免干扰,C2约束同一个时隙不会分配给相邻2个节点,C3约束分配到同一个时隙的节点间最多存在1条链路。
1)当存在中心控制节点时:
在无人机通信网络中,当存在一个无人平台节点是中心控制节点时,所有节点维护的邻居表和网络状态等信息可以被收集到集中控制节点处,并基于这些数据对上述优化问题进行全局求解。上述时隙分配问题是以二元时隙分配变量为优化对象的整数线性规划,可以利用混合整数线性规划(MILP)求解器或者深度强化学习算法进行求解。
MILP求解器是一种计算机程序,可以解决包含整数变量的线性规划问题。这些求解器使用分支定界法等算法来解决整数规划问题,但它们通常比手动实现更高效。
2)当不存在中心控制节点时:
然而,由于无人机通信网络中难以设定集中控制节点,求解上述以优化全局网络性能为目标的时隙分配问题时难以获取所有节点的网络状态信息。为了进行时隙调度,假设节点要维护的邻居表包括一跳和两跳,同时还会维护一跳和两跳邻居的时隙分配表,可以将上述优化问题拆分为以节点m为中心的时隙分配问题:
(7)
(8)
此时,优化对象是所有时隙到节点m的调度情况。对于节点m而言,其一跳邻居、两跳邻居、以及一跳邻居和两跳邻居的时隙占用情况都是已知的。上述以节点m为中心的时隙分配问题是整数线性规划问题,公式(8)中C1保障了在一个时隙调度周期内所有无人平台节点至少存在1次时隙调度,C2和C3约束了变量tm,k的上界,C2约束同一个时隙不会分配给相邻2个节点,C3约束分配到同一个时隙的节点间最多存在1条链路。另外,分析该优化问题可知,对于无人平台节点m,所分配到的时隙数量越多,其优化目标函数越大,其变化是随着其占用的时隙数量增加而单调递增的。此时,节点m的时隙分配结果可以直接以贪婪的思路最终确定。
上文将全网的时隙分配问题拆分为以节点m为中心的时隙分配子问题进行求解,不再需要将所有节点的网络状态信息收集到集中控制设备,但是这种求解方式难以获取全局最优的结果。并且,值得注意的是,时隙调度的最终目标是为所有节点分配数据时隙。在以节点m为中心的时隙分配问题中,将同一时隙分配给不同节点所带来的网络性能增益不同,这说明节点时隙分配的顺序对节点调度的公平性和稳定性具有重要影响,为此,需要提出基于优先级的节点时隙分配。

由于节点负载过高会导致时延提高和丢包率增加,当节点监测到自身负载Qm超过一定阈值αm时,就需要请求更多数据时隙尽快传输缓存队列的流量,此时该节点将临时提高自身优先级并将更新后的优先级信息广播给邻居节点,这时节点的时隙分配顺序也会相应的提前,有利于节点获取占用更多时隙进行数据传输。当节点监测到自身负载Qm低于一定阈值βm时,可恢复为初始优先级,并将其更新消息广播给其他节点。为了避免节点优先级的频繁变更导致时隙分配无法收敛,设置负载阈值αm和βm的取值满足αm>βm。
当Qm≥αm时,更新节点优先级的表达式可以定义为:
(9)
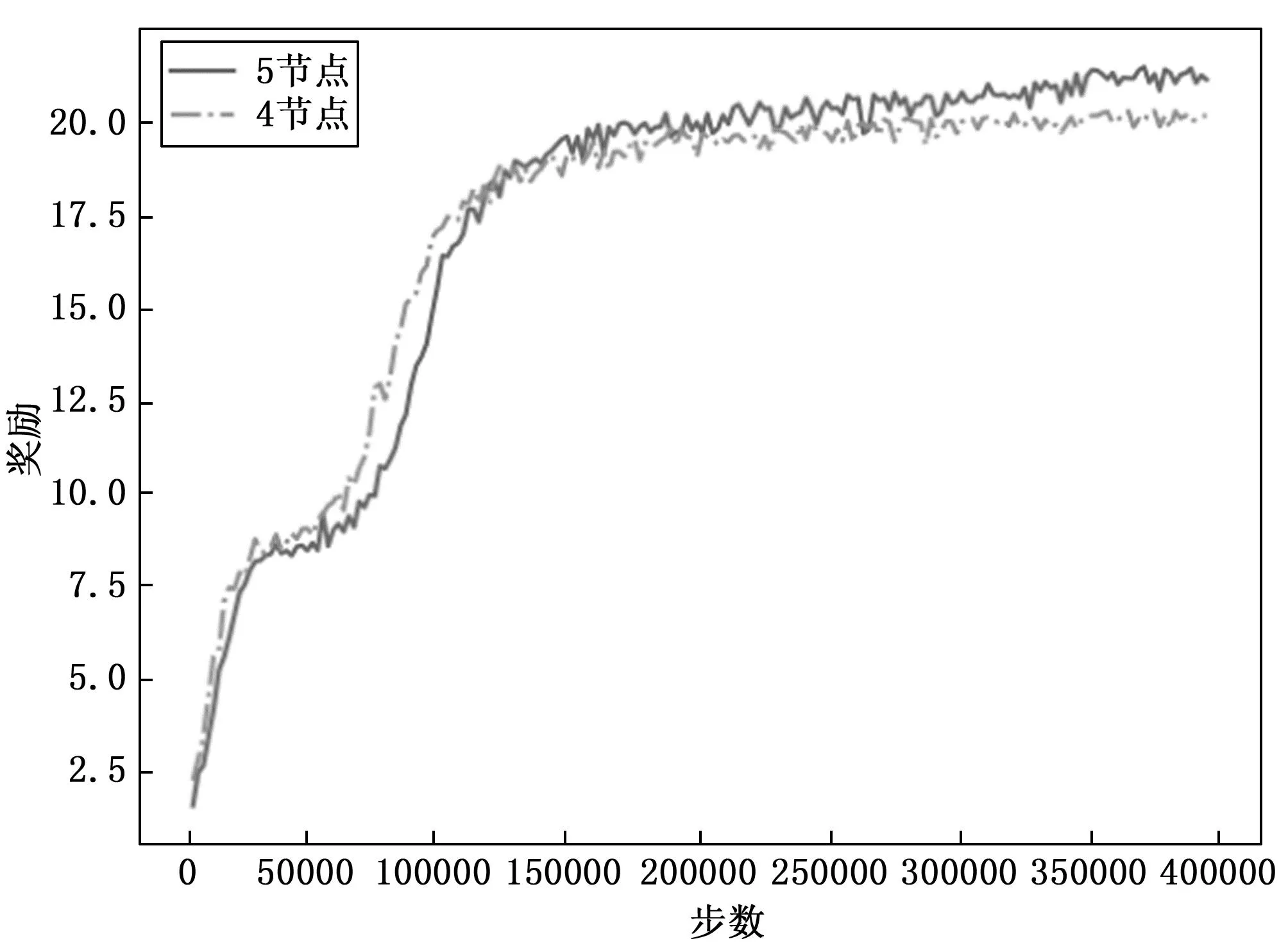
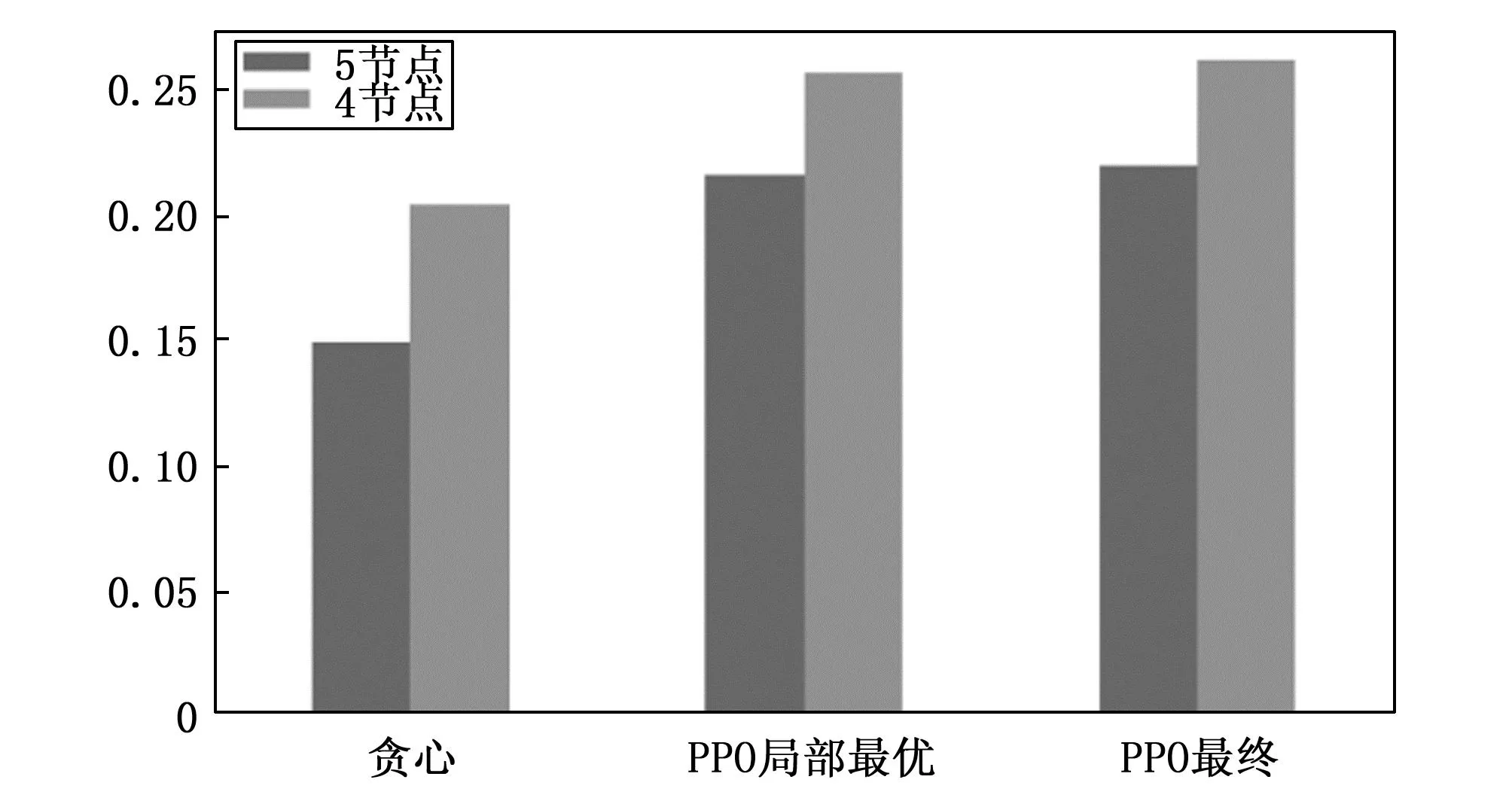
当βm 基于优先级的节点时隙分配允许优先级较高的节点获得优先进行时隙划分的机会,通过调整时隙请求期间的参数,优先解决高优先级节点的时隙分配优化问题,使得重要紧急的消息可以高效传输。基于优先级的节点时隙分配流程如图1所示。 图1 基于优先级的节点时隙分配流程 为了提高多无人机网络的通信效率和整体系统性能协作,本文将运用深度强化学习的研究成果,设计一种用于解决时隙资源分配问题的方案。 在2017年,OpenAI提出了PPO算法,这是一种深度强化学习算法,旨在通过使用PPO算法来让智能体解决问题。为此,需要先建立一个MDP模型,这个模型由状态空间(S)、动作空间(A)和奖励函数(R)组成[22]。在t时刻,环境处于状态St,智能体根据当前状态选择策略At,环境转移到下一状态St+1,同时智能体获得相应的反馈奖励Rt。 假设存在一个多无人机网络,其中包含一组环境状态S、动作集合A以及回报奖赏R。该网络中共有N架无人机,并且每个周期需要分配T个时隙。具体的动态时隙分配环境映射如下所述。 环境状态S:为了评估无人机在执行动作后对环境状态的影响,环境状态主要用于描述这些影响的程度。这种程度可以包含积极的和负面的影响。根据环境状态的变化,可以更方便地设计后续的奖励函数[14]。环境状态可以被定义如下: S={s1,s2,…,sN} 在动态时隙分配的背景下,环境状态可由多个方面来描述,即无人机节点的负载和无人机节点的链接拓扑等。 动作集合A:强化学习的另一个重要组成部分是动作。动作是无人机与环境交互的必备因素。通过不断尝试各种动作或策略,无人机可以获取环境反馈的信息和奖励值,以便快速了解采取何种动作或策略,以最大化环境收益[14]。动作集合可以定义如下: A={a1,a2,…,aN×T},ai∈{0,1} 式中,αi表示第i÷T时隙下的第imodT架无人机所采取的动作,也就是说该时隙下,无人机可以选择两种不同的动作再每个时隙中进行数据传输操作,ai=0表示无人机在该时隙中不进行数据传输;ai=1表示无人机在该时隙中试图进行数据传输。 奖赏函数R:奖励函数的作用是教导智能体向对环境有好处的方向前进,并且限制其行动范围。一般来说,奖励函数会根据环境的特点进行制定。在动态分配的情况下,通过状态反馈来衡量环境的优劣[14]。 为了实现让智能体快速学习最优时隙分配策略的优化目标,本文设计了两部分奖励。第一部分是满足三个约束条件下的评估情况,第二部分是计算网络中通信的总负载量。 图2展示了模型的决策流程。 图2 决策流程图 为了找到最佳的时隙分配策略,使得初始化状态S的预期奖励最大化,需要通过智能体与环境的交互来生成所有可能的时隙分配策略π*,以最大化系统整体的长期期望折扣奖励: (10) 最佳时隙分配策略可被表述为: (11) 本文使用时隙分配系统时,不必考虑长远回报。为此,我们引入衰减因子作为衰弱机制γ∈[0,1]。公式(11)中st+1描述无人机网络环境在t+1时刻的状态;at+1记录智能体在t+1时刻的时隙分配行为;Rt+1(at+1,st+1)记录t+1时刻的即时奖励;γRt+1(at+1,st+1)表示长时间的衰减奖励。 至此,我们已成功完成了强化学习中MDP建模的重要步骤。我们已经设计了模型中的状态、动作和奖励函数的三个关键要素。 如图3所示,本文所使用的PPO强化学习算法可以分为交互阶段和学习阶段两个关键阶段。 图3 基于PPO算法的时隙分配系统体系结构 交互阶段:智能体与环境互动,利用环境传递的状态信息做出决策,环境再返回智能体下一时刻的状态和基于该策略的奖励。PPO算法采用经验回放技术,运用经验数据池D,帮助智能体更好地学习到最佳决策。该算法是一种在线学习策略,需要大量的样本数据用于重新训练模型。但是,数据集过大会导致训练时间过长,收敛性较弱;而数据集过小则会影响模型的训练效果[22]。PPO算法利用重要性采样技术,通过创建一个固定大小的经验池D,在解决上述问题时能够重复使用样本。 学习阶段:每次进行迭代时,智能体会利用新生成的Actor网络所提供的策略来选取动作,并与无人机网络环境进行互动,以获取样本数据。当一个完整的经验池D中的数据样本被收集完毕后,Actor和Critic网络会对其中的数据进行学习。策略更新的流程如图3所示。 在每次迭代时,智能体使用新Actor网络生成的策略选取动作与无人机网络环境交互,得到一个(st,at,rt,st+1,πθ)样本数据,当收集完一个完整的经验池D的数据样本后,Actor、Critic网络会对经验池D中的数据进行学习。 根据公式(10)可以计算出每个时刻的值函数: γT-t+1rT-1+γT-tV(sT) (12) 此时可以计算得到Critic网络的损失函数: (13) 进行反向传播,以更新Critic网络。 对于经验池D中的每个状态,我们将其输入到两个Actor网络中,以获得相应的正态分布。同时,我们输入D中的每个动作以计算其在分布中的概率。通过将这些概率相除,我们得到了PPO算法的重要性采样权重: (14) 可以计算Actor网络的误差函数: (15) 其中:ε是一个超参数,它用于限制策略更新幅度的clip函数。然后,通过反向传播更新Actor新网络,最终PPO的整体损失函数如下: Lp=0.5×Lc+La (16) 如算法1所示是一种改进的无人机网络时隙资源分配算法。 算法1:基于PPO算法的时隙资源分配算法 输入: 马尔可夫决策过程模型 输出: 智能决策模型 1)设置模型超参数、训练总回合数、批大小、学习率、衰减率γ,每次更新次数、最大步长、更新频率 2)初始化经验回放池D 3)初始化无人机网络环境,生成网络拓扑 4)初始化算法模型,策略网络参数θ 5)Actor网络参数设置采样环境参数θold←θnew 6)fori= 1,2,…do 7) 重置环境 8) for each steptdo 9) 观察无人机网络初始状态st 10) 将状态st输入到Actor new网络得到动作at; 11) 在环境中执行操作和下一个状态st+1后得到奖励rt,是否终止d 12) 将(st,at,rt,st+1,πθ)存入经验回访池D中 13) 最终状态输入Critic网络中,根据公式(10)计算衰减后的奖励 14) if 更新步骤等于经验池D容量 then 15) 将记录的状态组合输入到Critic网络根据公式(12)估计优势函数 16) 使用梯度下降法优化目标函数并更新网络参数θnew 17) end 18) end 19) 更新旧策略模型参数θold←θnew 20)end 21)保存模型,绘制奖励曲线和网络损失曲线 仿真环境为OpenAI Gym框架,在Anoconda平台使用Python语言实现。 在无人机网络场景下,网络的拓扑结构多种多样,图4中为典型的网络拓扑,其中,链状拓扑结构下,节点时隙复用的方式更多,三种拓扑结构同样数量的节点下链状拓扑结构运算复杂度最高,因此选取链状拓扑结构进行仿真。 图4 三种网络拓扑图 在仿真中设定节点数为4,5,时隙数为8,网络拓扑为线性拓扑。下面以5节点举例,网络的邻接矩阵为: 其中:Cij代表节点i、j的联通情况,计算得到允许同时开通的矩阵: Bij代表节点i、j是否能够同时分配时隙。 随机生成节点当前负载为Q=[10,12,4,4]。 对载荷进行归一化后,U=[0.416 67,0.833 33,1,0.333 33,0.333 33]。 算法中奖励的衰减率为0.99,PPO算法中clip参数为0.2。 实验的损失函数如图5所示。 图5 损失函数 可以看出模型的损失函数整体趋势随着训练步数的增加而降低,说明模型朝预计的目标方向学习,算法收敛。 图6为PPO算法的平均奖励曲线,纵轴代表每轮中所有步数的奖励之和,奖励随着训练步数的增加而增大,在前150 000步的训练中,提升幅度较大,快速得到局部最优值,后250 000步的训练奖励值提升幅度较小,花销大量时间寻找最优奖励。与5节点相比,4节点奖励曲线增幅大致相同,比5节点快100 000步达到收敛得到最优解。 图6 奖励函数 最终算法输出如下时隙分配矩阵: 将负载代入公式(2)中计算加权信道利用率可得结果为21.875%。 其中200 000步时的局部最优解的时隙分配矩阵为: 计算加权信道利用率为21.458%。使用贪心算法进行对比,优先遍历分配时隙,满足一个周期至少开通一次的约束,再选择载荷最大的节点分配时隙,得出如下时隙分配矩阵: 可知加权信道利用率为14.791%。 图7为三种时隙分配矩阵的数据对比,其中PPO局部最优为200 000步时的时隙分配情况,由此可见PPO算法在前200 000步即可得到局部最优解,但寻找到最优解需要花费翻倍的时间,以5节点网络为例,最优解比局部最优解提高了1.94%,训练步数多出200 000步,因此PPO算法最优解与局部最优解存在折中关系,可以根据实际需求适当缩短训练时间得到加权信道利用率略微低于最优解的时隙分配方案。 图7 贪心算法、PPO算法局部最优、最优解加权信道利用率对比 与贪心算法对比可以看出PPO算法的局部最优解和最优解都显著优于贪心算法,与贪心算法相比,PPO算法局部最优解加权信道利用率提高了45.07%,最优解集权信道利用率提高了47.89%。 图8为节点数为4、5,需分配的时隙数为5~30的PPO算法与贪心算法的加权信道利用率对比。当节点数固定时,PPO算法得到的加权信道利用率随时隙的增加而增大;相比于5节点,4节点网络下PPO算法得到的加权信道利用率更高;PPO算法比贪心算法加权信道利用率提高了45%左右。 图8 贪心算法、PPO算法加权信道利用率对比 通过仿真结果对PPO算法在时隙分配优化方面的有效性进行分析,该算法能够收敛到最优,最优解与局部最优解间存在折中关系,可以根据实际需求来选取,对比贪心算法,PPO算法有巨大优势。 近些年来随着多无人机网络的研究与应用的不断深入,多无人机网络资源分配问题具有很重要的研究意义。本文根据多无人机网络差异化节点负载的特点,为了适配网络业务流量,针对多无人机网络动态时隙分配问题,将网络拓扑结构纳入考虑,提出了基于PPO算法的时隙分配方案。仿真结果表明,相比于贪心算法,提出的深度强化学习方案,有效提高了信道利用率。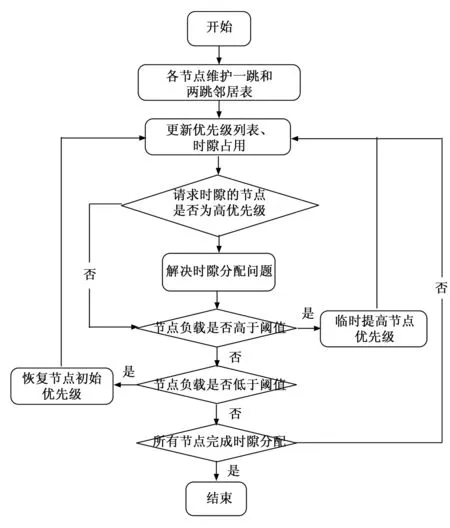
1.2 模型描述

2 基于近端策略优化算法的时隙分配算法框架
2.1 算法框架

2.2 算法流程
3 仿真与分析
3.1 仿真原理及参数
3.2 仿真结果与分析


4 结束语
猜你喜欢
英语文摘(2020年10期)2020-11-26 08:12:20
测控技术(2018年7期)2018-12-09 08:57:56
铁道通信信号(2018年9期)2018-11-10 03:26:46
舰船电子对抗(2016年3期)2016-12-13 05:15:55
广西大学学报(自然科学版)(2016年5期)2016-11-12 06:28:54
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:42
华东理工大学学报(自然科学版)(2015年4期)2015-12-01 04:00:44
电子设计工程(2015年8期)2015-02-27 12:05:33
计算机工程(2014年10期)2014-06-07 05:53:21
现代防御技术(2014年6期)2014-02-28 18:26:23
