
基于大数据运维系统的设计及应用
2024-02-03 08:52康峰
信息记录材料 2024年1期
康 峰
(宁夏职业技术学院 宁夏 银川 750021)
0 引言
我国信息化建设的发展促进了信息技术在多个工作领域得到了广泛的应用,并且各个领域在利用大数据信息资源时,在一定程度上优化了各个领域工作中运行设备的管理工作的方式[1]。 当前运维计算主要采用的是传统的能力分散化、管理集中化的方式进行构建的,这种方式在一定程度上增加传统运维工作的难度[2]。 大数据系统运维的核心技术主要是通过信息系统对数据的监控的分析来对系统运行风险进行评估,而传统的神经网络识别分析法、层次分析法以及风险矩阵等风险评估方法,在当前信息系统硬软件系统增加的背景下,已经无法满足运维的需要[3]。 因此,文章基于大数据以及数据包络分析法和最小二乘支持向量机(least squares support vector machine,GA⁃LSSVM)研究和设计了一种大数据系统运维系统,通过提供月内风险评估的精度,达到大数据资源优化管理的目的,保障大数据系统平稳运行。
1 系统设计思路
在当前大数据系统变化复杂的背景下,大数据云计算应用的程度越来越高[4]。 也就是说,设计运维系统需要确定信息系统的类型规划以及相关资源的管理工作,为大数据扩容的管理提供更好的服务器支撑,针对不同类型的数据进行多样性数据的保存,将全部数据一同写入Hadoop集群中,更进一步地分析和收集系统中采集到的各类数据。 利用数据包络分析法和GA⁃LSSVM 对其进行综合风险评估[5]。
2 系统框架
2.1 采集模块设计
随着大数据时代的硬软件系统更新升级,原先采用单一性的信息分析系统很难满足当前存在的大数据系统良好运行的信息。 因此在构造大数据运维系统的过程中,需要采用分布式信息采集方案,提升系统的硬件维护信息采集建设。 根据采集到的信息,有针对性地对大数据系统硬件上设计运行提供良好的运维方案。 同时,大数据系统中对相关软件的运维建设需要针对现实所有信息进行分布式处理。 也就是同时数据采集模块,采集大数据系统在运维过程中遭受攻击的所有信道信息,并且根据采集的攻击信息特征,确定大数据系统的攻击类型[6]。
2.2 信息储存模块
构建大数据运维系统,需要构建信息储存模块,将采集模块收集到的攻击类型的数据,以及硬件设备运行状态和性能数据等,实现对各类数据良好储存的效果,建立的数据存储模块需支持运维系统正常运行过程中调用各类信息。 在该模块设计中,通过建立结构化查询语言(structured query language,SQL)数据库,可以保障数据储存模块良好的性能[7]。 针对不同类型数据以及不同因软件功能、运行作用和目的以及运作对象方面产生的不同数据,有针对性地设计各个模块的信息存储模块[8]。
2.3 风险评估模块
根据前期采集并储存的数据信息,构建大数据运维系统中的风险评估分析模块。 在该数据风险评估模块中,利用数据包络分析法以及GA⁃LSSVM 设计并构建风险评估模型[9]。 通过模型评估测试的风险评估平均值绝对误差以及均方根误差来检测该数据风险评估模块的可靠性,具体的风险评估模块设计流程如图1 所示。
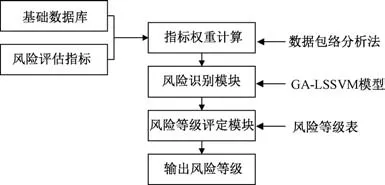
图1 数据运维风险评估模块流程
通过数据采集模块对大数据系统硬软件系统运行的相关数据,分析并确定风险评估系统的相关指标。 基于数据包络分析法来分析大数据系统运行过程中存在的数据权重指标,将其作为GA⁃LSSVM 分析的样本,如式(1)所示。
根据遗传算法对相关数据进行优化,对其参数和核函数参数进行优化设计,将径向基函数作为GA⁃LSSVM 计算的核函数,通过GA⁃LSSVM 算法构建其最优化的决策函数。 最后,在决策函数的优化基础上对大数据系统运行性能、状态、作为评价,并且输出相应的评价值。 根据输出的风险评价值来进行风险的等级评定,根据风险等级确定大数据系统运行是否存在风险,从而提升运维系统的有效性。
2.3.1 模型构建基本流程
风险等级的评定模块需要确定运维风险的等级,以及风险指标的权重进行计算,将大数据系统运行过程中存在的风险等级划分为Ⅰ、Ⅱ、Ⅲ、Ⅳ、Ⅴ共5 个等级风险等级,数字风险意味着风险等级越高,具体的风险权重值区间如表1 所示。

表1 大数据系统风险等级划分
根据表1 提供的风险等级权重值分布评估表,对采集的数据进行计算分析计算后对其风险等级进行评估。
根据数据包络分析法结合层次分析法(analytic hierarchy process,AHP)对大数据系统运维的风险指标权重进行评估根据公式(2)来判断该矩阵中的指标是否为最优值。
式(2)中,pij,qkj分别表示的是第j 个决策单元的第i种输入量以及第j 个决策单元的第k 种输出量。 而pij0,qkj0则表示两者中间的最优化的权重值,n 表示评价数据的数量,其中包含的input 以及output 指标为s,o。 根据式(2)优化处理后得到公式(3)。
根据式(3)输入决策最优化目标后,计算出input 以及output 的风险权重指标,输入的指标进行优化后,利用1 来代替输入指标,由此构建出新的数据包络分析模型,如式(4)所示。
式(4)中,θα及βα分别表示的第α个指标的权重值,将评价矩阵决策单元的输出值代入式(4)即可以得出大数据系统的风险评估指标权重。
2.3.2 风险评估模型参数优化
计算出的风险评估权重指标作为输出数据集对其进行风险评估,利用GA⁃LSSVM 将不等式约束转换为等式约束实现风险评估目标。 将GA⁃LSSVM 作为正则化参数c以及核函数参数σ 作为风险评估模型的决定性参数,来提升大数据运维系统风险评估的可靠性。 具体的参数优化流程如图2 所示。

图2 基于遗传算法的LSSVM 参数优化流程
由图2 可知,对两个参数实施编码处理,获得初始种群,预设遗传算法进行代数上限值、交叉处理和变异的概率来确定函数的适应度,得出最终个体的适应度。 并且根据结果判断算法是否符合终止条件,对于不符合终止条件的部分重复迭代进行选择、交叉、变异等操作,直到最终输出的权重值符合终止条件为止。
2.4 信息展示模块
将采集的数据信息、分析和更新评估过程中收集的信息利用信息传递方式将其展现出来。 利用可视化技术向外传输所有数据采集、分析、风险评估过程中出现的数据,以人机交互装置将收集到的数据信息展示出来。 通过该模型选取的各类专业化信息,来了解大数据系统在运行过程中硬软件系统内部或是外部存在的故障预警情况。
3 运维系统应用实验
因为运维系统的重点是风险评估模块,因此将重点对文章的风险评估模块进行风险识别仿真实验。 利用MATLAB 仿真平台作为仿真实验载体,以某企业大数据运行系统中产生的数据作为样本,采用2022 年1—3 月的数据作为样本a,4—6 月的数据作为样本b,7—9 月的数据作为样本c,以及10—12 月的数据作为样本d,以传统的PSO⁃LSSVM 风险评估系统以及GA⁃LSAVM 系统进行对比实验。
3.1 结果分析
根据仿真实验得出实验结果,如表2 所示。 通过数据统计结果可以看出样本1 的风险评估值低,不存在风险,与企业的运维的实际情况相符,由此可见,文章设计的运维系统风险评估模块的提供的评估数据准确度够高。
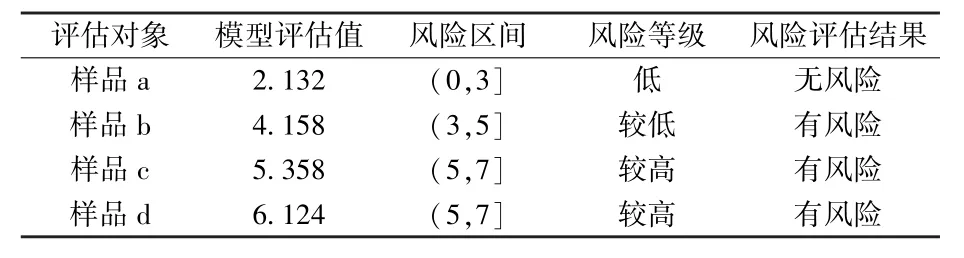
表2 风险评估结果
3.2 风险评估误差分析
利用平均绝对误差、均方根误差评价系统作为该系统风险评估性能的评价标准,对3 种评估系统进行对比,得出三个系统的风险评估误差结果,如图3 所示。
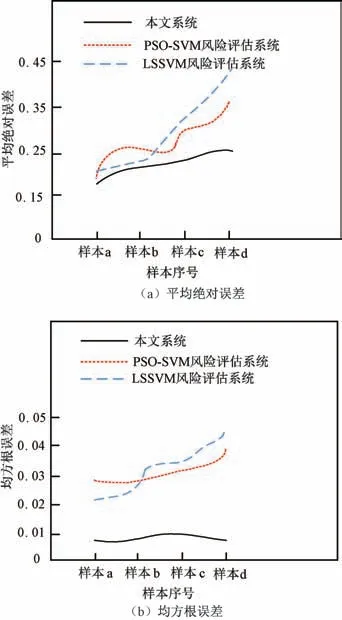
图3 三个系统风险评估误差对比
由图3 可以看出文章构建的大数据运维分析评估模块的评估计算出的风险评估误差值小,评估结果的可靠性和精度较高,与其他两个系统的风险评估结果相比效果较好。
3.3 大数据运维系统应用
该运维系统对大数据系统在运行过程中产生的初始数据进行采集、分析和完成隐蔽信道的发掘,对于攻击方的攻击行为形成攻击特征日志。 通过提供的攻击日志信息以及其他相关的硬软件系统的故障预警信息进行专业化的分析,通过信息展示模块,把采集的数据和各个系统和硬软件的数据利用人机交互技术展示出来,让运维人员充分了解大数据系统的运行情况。 有针对性地开展运维工作。
4 结语
综上所述,文章构建的大数据运维系统主要由信息的采集、数据的存储、风险评估以及信息可视化等多个模块构成。 对于这几个模块的设计和装配都需要以大数据云计算的技术作为支持,才能有效提升数据运用的能力,持续保障大数据运维系统运行的平稳性,使运维系统在运行过程中保持较高的性能。 系统中的风险评估模块是该系统的关键,是运维系统工作的重要支持,基于数据包络分析法以及GA⁃LSSVM 技术保障了运维系统风险评估的准确性。 将数据包络分析法引入风险指标权重计算,降低了层次分析法的主观性,以此获得的风险评估权重计算指标更加完整、精确,在一定程度上提升了运维系统提供数据的精准度,为后运维工作提供良好的参考。
猜你喜欢
防爆电机(2022年4期)2022-08-17
中国交通信息化(2019年5期)2019-08-30
中国交通信息化(2019年2期)2019-03-25
中国设备工程(2019年8期)2019-01-17
能源(2018年8期)2018-09-21
能源(2017年11期)2017-12-13
中国交通信息化(2017年9期)2017-06-06
自动化学报(2017年5期)2017-05-14
项目管理技术(2016年8期)2016-05-17
现代工业经济和信息化(2016年8期)2016-05-17
