
目标检测算法YOLOv5s用于柑桔成熟果实检测的改进
2024-01-31 04:17郑永强刘艳梅马岩岩易时来谢让金
中国南方果树 2024年1期
蹇 川,郑永强,刘艳梅,马岩岩,易时来,吕 强,谢让金
( 1 西南大学工程技术学院,重庆,400715;2 西南大学柑桔研究所/国家柑桔工程技术研究中心/国家数字种植业(柑桔)创新分中心,重庆,400712;3 重庆市北碚区经济作物技术推广站,重庆,400700 )
柑桔是我国乃至世界种植面积和产量最大的水果作物。据《中国农村统计年鉴(2021)》统计数据,2021年我国柑桔产量达到5 595.61万t,较2020年增长8.0%。采收前产量评估是柑桔生产过程重要环节,可为制订销售计划和下一年度施肥方案提供数据支撑。目前,桔园产量评估仍然以历史产量和人工使用计数器进行数量统计为主要手段。随着机器视觉和计算机技术的发展,目标检测得以快速发展。如能利用机器视觉检测技术对柑桔果实进行识别计数,则可能大幅减少有关人工投入、节省工作时间和提高经济效益,而且能有效提升果实检测和产量预估精度。果实精确计数与建立好的产量预估模型是精准预估产量的重要前提,对缩小预估值与真实值之间的误差至关重要[1-2]。
基于计算机视觉技术的水果检测和技术方法可以大致分为两类:基于手工设计特征的方法和基于深度学习的方法。前者主要由计算机视觉专家根据水果的形态、颜色和纹理特征,设计特定的特征描述方法,提取图像中果实的鲁棒特征,实现较为精准的检测与识别。例如,Zhang等[3]开发了一种图像分割技术,用于在图像上检测和计数柑桔类水果,并将该技术与基于人类视觉的计数进行了比较。张小花等[4]提出了一种基于霍夫变换,应用MATLAB软件对剔除背景的柑桔进行计数的方法,其识别正确率达到94.01%。 Linker等[5]使用了基于形状和颜色的图像处理方法,分别达到了85%和89%的准确率。基于手工设计特征的方法属于早期实验室阶段的研究探索,大多数模型和方法泛化性较差,对于真实环境采集的图像的光照变化、尺度变化和叶片遮挡具有较差的检测性能和稳定性。基于深度学习的水果检测与计数方法是当前的主流方法。其主要基于卷积神经网络或Transformer架构设计目标检测网络模型,同时实现特征学习、目标定位、目标分类[6],通过数据驱动的方式优化检测网络模型参数,使训练的网络模型能够精准地检测识别目标。目标检测网络模型进一步又分为单阶段模型和多阶段模型。在通用目标检测领域存在大量的经典目标检测模型,例如:多阶段的Faster R-CNN[7]、CenterNet[8]、Cascade R-CNN[9]等网络模型。最近几年,随着无锚点单阶段模型检测精度提高,其逐渐成为目标检测的主流框架,例如:迭代发展的YOLO系列[10]、SSD系列轻量级网络模型[11],以及最近基于Transformer架构的DETR模型和基于扩散模型的DiffusionDet模型。
在智慧农业领域,由于弱运算能力的农业机器人、移动终端、边缘计算盒子等设备的广泛部署和应用,简单有效的单阶段检测模型(YOLO和SSD模型)被广泛研究,并面向特定应用得到改进。例如,黄彤镔等[12]针对柑桔果实识别提出改进YOLOv5网络模型,平均识别精度达到91.3%。熊俊涛等[13]提出基于改进YOLOv3网络的夜间环境柑桔识别方法——Des-YOLO v3网络,其识别精度和F1值分别达到了97.67%和0.976,但模型太大(225.3 MB),无法作为嵌入式算法使用。汤旸等[14]面向采摘机器人提出了一种改进YOLOv3-tiny轻量化柑桔识别方法,提高了模型的识别精度,增强了算法的鲁棒性。然而,这些方法和模型对于叶片遮挡导致的小目标(单颗果实局部被拍摄)和多颗果实重叠两种情况的漏检率高[15-17],严重影响后期的产量预估。
笔者分析认为小目标局部果实和多颗重叠果实被漏检的原因如下:(1)叶片遮挡的局部果实在图形上可能呈现为各种形状,且尺度可能小于16像素×16像素,此时果实轮廓语义信息已失效,只有依赖于成熟果实的颜色和纹理才能定位和识别;(2)在提取特征过程中,随着卷积网络深度增加,特征图空间分辨率降低,小的局部果实的特征相应逐渐变弱甚至消失,从而导致漏检;(3)在检测网络Head阶段,多颗重叠果实由于目标中心距离近,在特征图下采样过程中,多颗果实的中心可能被映射到相同位置,从而导致错误地检测为单颗果实,特别是两颗果实重叠较多时,更容易检测为单颗果实;(4)多颗重叠果实的定位必须在高分辨率的网络低层阶段进行,需要设计额外的模块在网络低层挖掘和学习重叠果实之间的边界和中心位置用以辅助最终的定位。基于上述分析,笔者设计了一种集成多层Context Aggregation Block (CABlock)和特征金字塔思想的改进型YOLOv5s网络模型。模型的低层CABlock模块,通过设计的1×1卷积实现的特征通道注意力机制,能够更好地挖掘和学习小目标局部果实颜色和纹理特征,同时,像素级空间注意力机制也能够使CABlock更好地学习多颗重叠果实之间的边界特征。特征金字塔的特征图上采样和下采样机制,能够有效地将低层CABlock挖掘的小目标局部果实和多颗重叠果实特定的颜色纹理特征、边缘重叠特征融合到常规果实特征图中,从而保证在不降低常规果实检测精度的同时,有效地提高小目标局部果实和多颗重叠果实的检测精度。
1 材料与方法
1.1 数据采集与预处理
1.1.1 数据采集
果实图像数据采集区域位于重庆市北碚区西南大学柑桔研究所,采集时间在完全转色期和成熟期。使用数码相机、手机、全景相机等设备在不同天气、不同时刻、不同距离和光照角度条件下进行拍摄,包括单株整树果实图像、局部冠层果实图像和单个果实图像。拍摄的图像尺寸为4 160像素×4 160像素,保存为jpg格式。共采集了500幅图像,其中,整株和局部冠层果实图像(存在遮挡和目标较小)占比90%,无遮挡单果图像占比10%。
1.1.2 数据标注与增强
在数据处理阶段,使用LabelImg软件对采集的500幅原始图像进行手工标注,并生成相应的txt标注文件,文件信息包括果实在图像中的坐标位置、尺寸大小以及标签名“orange”。将标注好的文件按图像和对应标签的方式分别放在images和labels文件夹中,作为成熟柑桔果实数据集。
为了避免过拟合,增加训练数据,提高模型泛化能力和鲁棒性,降低模型对图像的敏感度,利用python工具对每幅原始图像随机使用模糊、亮度、裁剪、旋转、平移、翻转等方法进行5次(类)增强处理(见图1)。将原始图像和增强图像合在一起,最终得到3 000幅图像的柑桔果实数据集(增强图像的坐标位置等数据通过python编写程序完成,不用手工标注)。图像标注与增强工作完成后,将整个数据集按照8∶2的比例随机分为训练集和验证集,其中训练集为2 400幅,验证集为600幅。
1.2 YOLOv5s网络改进
YOLOv5是2020年6月由Glenn Jocher开发并开源的一种单阶段目标检测算法,该算法在YOLOv4的基础上改进而来,其速度与精度等性能得到了极大提升。YOLOv5是一个在COCO数据集上预训练的物体检测架构和模型,它使目标检测问题转化为回归问题,即先训练网络在初始锚框的基础上输出预测框,进而和真实框进行比对,计算两者差距,再反向更新,迭代网络参数,最后训练出一个精度最高的检测权重。YOLOv5网络结构由Backbone和Head两个部分组成。其中,Backbone是在不同图像细粒度上聚合并形成图像特征的卷积神经网络;Head则将上一部分得到的图像特征组合起来,并将图像特征传递到预测层,最后对图像特征进行预测,生成边界框并预测类别。YOLOv5分为YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x四个版本,其复杂程度和模型文件大小依次递增。
柑桔园里成熟柑桔果实数量过多、果实较小且背景复杂,容易出现枝叶遮挡、漏检和果实重叠等现象,会影响YOLOv5的识别效果和检测精度。结合需求和后续应用,选择最为轻量级的YOLOv5s进行改进,即在Head网络的最后一个卷积之后添加一个由3个Context Aggregation Block (CABlock)组成的金字塔结构特征提取层(spatial context pyranid,SCP),形成新的目标检测网络(见图2和图3)。金字塔结构特征提取层(SCP)每一层由一个带有剩余连接的CABlock组成[18],可以很容易地插入到Backbone或Head的末端。CABlock可以学习从整个特征图中聚合特征,并使用自适应权重将它们组合到每个像素中,增强特征提取能力并且扩大了感受野,可以有效地融合局部和全局特征,同时减少信息混淆,使网络对小目标和重叠遮挡目标的识别效果得到提升。
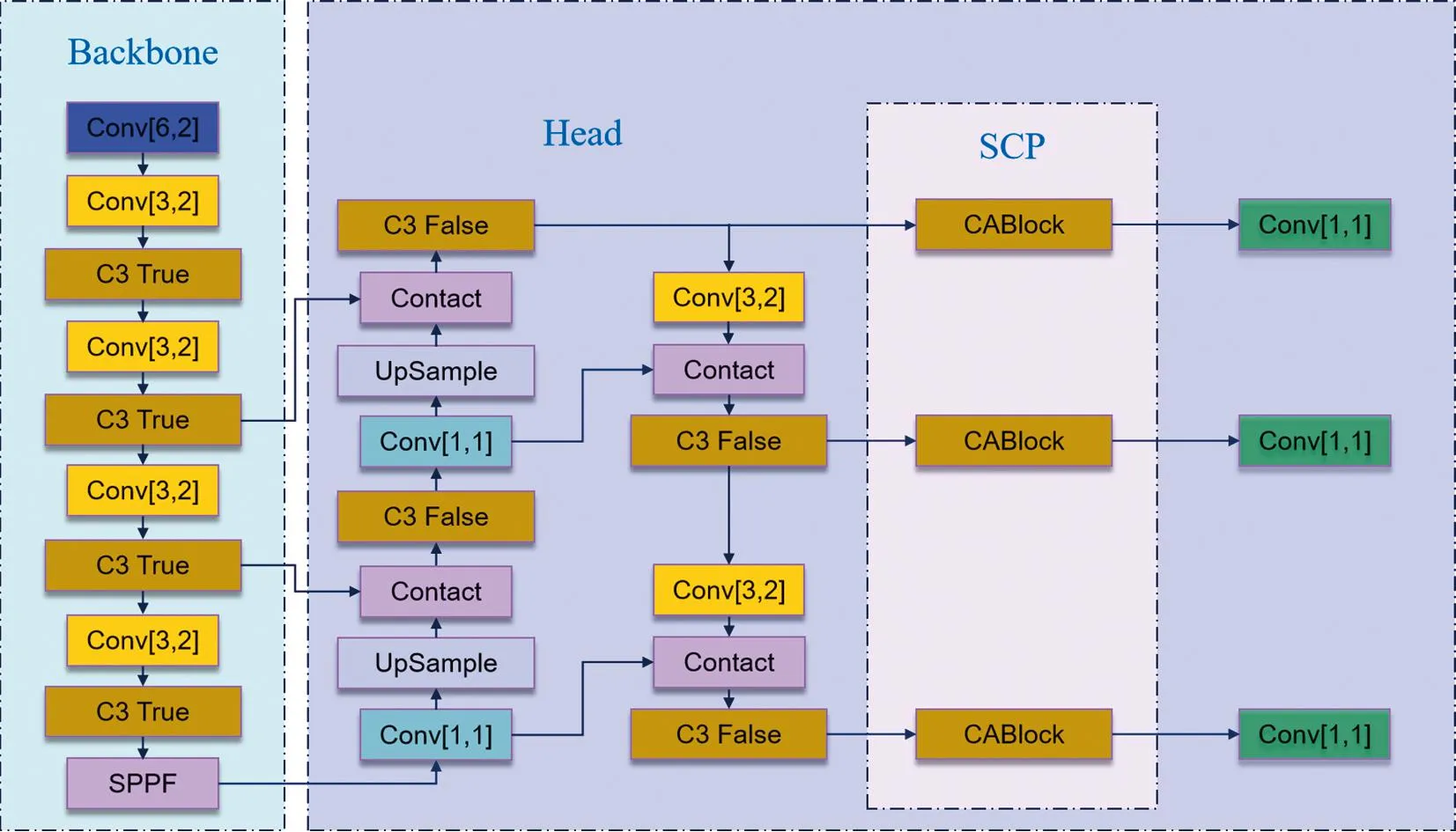
图3 改进YOLOv5s网络结构
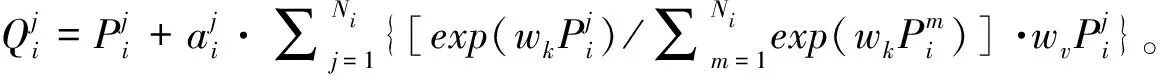
1.3 柑桔果实目标检测
1.3.1 评价指标

1.3.2 试验设计
模型训练使用的操作系统为Window10(64位)操作系统,CPU型号为12th Gen Intel(R) Core(TM) i9-12900@2.40 GHz,内存为32 GB,GPU为NVIDIA GeForce RTX 3080。采用的深度学习框架为PyCharm 2020.1 (Professional Edition),并配合CUDA进行训练加速。模型训练参数设置为:epochs=300,batch size=16,momentum=0.937,weight_decay=0.005,lr0=0.01,输入图像分辨率全部归一化处理为640像素×640像素,使用随机梯度下降优化器(SGD)。
为了检验改进模型的检测精度以及与其他模型的性能差异,采用同一数据集(训练集),在上述相同设备和训练参数条件下,对原始YOLOv5s、改进YOLOv5s以及Faster R-CNN进行训练测试,对比结果。
为了更加直观地展示网络模型的改进效果,特别是在小目标、重叠目标和遮挡目标的检测方面的精度提升,将包含这3类自然场景下的图像样本测试集(验证集)分别通过Faster R-CNN、原始YOLOv5s模型和改进YOLOv5s模型进行识别精度测试,对比结果。
2 结果与分析
2.1 不同模型训练测试对比
训练测试结果如表1所示,改进YOLOv5s模型的准确率和平均精度分别为98.21%和98.07%,相比于原始YOLOv5s模型准确率提升了0.31百分点,平均精度提高了0.17百分点;与Faster R-CNN相比,改进YOLOv5s模型的准确率和平均精度分别提高了8.41和8.31百分点。在模型大小方面,YOLOv5s最小,改进YOLOv5s略有增加,两者远小于Faster R-CNN。改进YOLOv5s模型的检测速率为30.76帧/s(单张成熟柑桔果实图像的平均检测时间32.5 ms),稍慢于YOLOv5s,是Faster R-CNN的2.6倍。

表1 各模型采用相同柑桔果实目标检测训练集训练测试结果
2.2 不同场景下不同模型识别精度对比
测试结果如表2所示,改进YOLOv5s模型在遮挡、重叠以及小目标等3类测试集上的平均精度分别为99.4%、97.2%和98.0%,均高于另外两种模型。从3类测试集检测样本中各随机挑选1幅图像进行检测的效果如图4所示。可以看出,原始YOLOv5s模型对3类自然场景的目标均存在漏检的情况,改进YOLOv5s模型的漏检情况有明显改善。

表2 各模型对遮挡、重叠以及小目标场景下柑桔果实目标的识别精度

注:图中方框为检测框,orange表示类别名,类别名后数字表示检测置信度;圆圈表示未检测到的柑桔果实。
3 讨论与结论
巡检机器人搭载的边缘设备通常受限于有限计算资源和低功耗要求,因此需要部署体积小、计算复杂度低的算法模型以提高推理速度和减少数据传输量。本研究以自然条件下成熟柑桔果实图像为研究对象,根据柑桔果实的生长特点,提出一种基于改进YOLOv5s模型的成熟柑桔果实检测方法。首先获取成熟柑桔果实图像,并建立相应的数据集。之后引入Context Aggregation Block来提高YOLOv5s模型的精度。在此基础上,对改进后的网络结构进行了优化,提高了检测速度。最后,通过训练和对比试验测试了改进模型的性能。采用相同数据集进行训练测试的结果表明,与其他模型(Faster R-CNN和YOLOv5s)相比,改进YOLOv5s模型的检测准确率(98.21%)与平均精度(98.07%)最高,识别效果得到增强;在模型大小方面,改进YOLOv5模型(15.8 MB)远小于Faster R-CNN(334.4 MB),略高于YOLOv5s模型(14.4 MB),不影响其后续迁移应用,可为柑桔果园产量预估以及柑桔采摘机器人等其他领域的视觉识别提供技术支持。改进YOLOv5s模型对于遮挡果实、重叠果实以及小目标果实的识别能力有提升,平均精度分别为99.4%、97.2%和98.0%,有效减少了误检、漏检等现象。成熟柑桔果实的自动检测,对于柑桔的产量预估和自动采摘意义重大,也为智慧果园向机械化发展提供了一定的技术支撑。本研究的改进YOLOv5s模型满足部署到各种移动平台的条件,可以进行自然环境下精度较高的柑桔果实检测作业。后续可以搭配目标追踪算法模型,以实现更为精确的检测计数与产量预估。
猜你喜欢
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
电子制作(2018年11期)2018-08-04
现代园艺(2018年1期)2018-03-15
现代园艺(2018年3期)2018-02-10
现代园艺(2018年3期)2018-02-10
现代园艺(2018年3期)2018-02-10
数学小灵通·3-4年级(2017年9期)2017-10-13
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
