
基于知识蒸馏和定位引导的Pointpillars点云检测网络
2024-01-31 06:13赵晶李少博郭杰龙俞辉张剑锋李杰
液晶与显示 2024年1期
赵晶, 李少博, 郭杰龙, 俞辉, 张剑锋, 李杰
(1.厦门理工学院 电气工程与自动化学院, 福建 厦门 361024;2.中国科学院 福建物质结构研究所, 福建 福州 350108;3.中国科学院 海西研究院 泉州装备制造研究中心, 福建 泉州 362000;4.厦门市高端电力装备及智能控制重点实验室, 福建 厦门 361024)
1 引言
激光点云是一种直观、灵活和存储效率高的三维数据表示方法,在三维视觉中已变得不可或缺。大规模激光雷达数据集的出现和端到端3D表示学习的巨大进步推动了基于点云的分割、生成和检测任务的发展。
不论是单阶段还是两阶段检测方法,点云的特征提取质量影响着算法的检测精度。Qi Charles R等[1]首次提出以端到端的方式通过多层感知来提取点的特征。随后,作者进一步提出PointNet++[2],以分层方式捕获局部结构,采用密度自适应采样和分组的方式提取点云特征。Point和Point++实现了直接对点云数据的处理和特征提取,被广泛应用到其他算法模型中。Zhou Y等人提出了VoxelNet[3],这是一种单级检测网络,可将点云划分为等间距的三维体素,并使用体素特征编码层进行处理,但是其采用了3D子流形稀疏卷积作为特征提取模块,致使网络推理速度相对较慢。Lang A H等人提出了Pointpillars[4]网络模型,提议将点云划分为几个体柱,将其转换为伪图像,可以使用2D卷积层进一步处理。此方法极大提高了网络模型的运算速度,使其能够满足自动驾驶实时性的要求,但其点云编码方式影响了特征提取的质量。Point R-CNN[5]和Pillar RCNN[6]是一种两阶段检测方法,首先基于原始点云生成自底向上的3D提案,然后对其进行细化以获得最终检测结果。随后,Fast point R-CNN[7]和PV-RCN[8]方法出现,利用体素表示和原始点云来发挥各自的优势。图神经网络是点云检测领域新兴的点云结构表示和特征提取方法。如为避免点云中心偏移和比例变化的3D-GCN[9],根据学习的特征生成自适应卷积核的AD-GCN[10]等。尽管点云的结构表示和特征提取方法多种多样,但复杂精细的结构设计可能会降低网络模型的推理速度。
早期的知识蒸馏方法主要是训练学生网络模仿教师网络预测的分类概率分布。近年来,以设计特定的知识提取方法用于提高目标检测的效率和准确性已成为一个新兴的热门话题。Chen等人首先提出将朴素预测和基于特征的知识提取方法应用于目标检测[11]。Wang等人证明前景对象和背景对象之间的不平衡阻碍了知识提取在目标检测中实现更好的性能[12]。为了解决这个问题,丰富的知识提取方法试图基于检测结果[13]、基于查询的注意力[14]和梯度[15]找到待提取区域。此外,最近还提出了提取教师与学生之间像素级和对象级关系的方法[16]。除了用于2D检测的知识蒸馏外,还引入了一些跨模态知识蒸馏,以将知识从基于RGB的教师检测网络转移到基于激光雷达的学生检测网络。然而,这些方法大多侧重于学生和教师在多模态框架中的选择,而基于纯点云数据三维检测的特定知识提取优化方法尚未得到很好的探索。
在Pointpillars的检测网络部分,其分类预测和回归框预测存在低相关性。低相关性主要是由于在训练阶段分类预测和回归预测使用各自独立的目标函数进行训练,因此正样本的回归框预测和分类置信度之间会存在不对齐的情况[17],影响置信度分数预测,最终影响网络模型的检测精度。
针对上述问题,本文做了如下工作:
(1)依据单阶段网络设计一组Teacher-Student模型框架对回归框尺度进行知识蒸馏。回归框尺度在数据类型上可以从连续表示转到离散表示,将教师网络的输出视为附加的回归框尺度目标,对教师网络和学生网络的回归框尺度输出进行连续值离散化,再做两组概率值拟合,制定蒸馏损失优化学生网络,提升物体的检测精度。
(2)设计定位引导分类项,将鸟瞰图视角下的正样本预测框与真实框的IoU值作为引导分数,以软化相应正样本硬类别标签,增加分类预测和回归预测的相关性,提高模型检测精度。定位引导分类项没有额外的网络嵌入,不影响网络模型的推理时间,使其保持高效性。
2 网络模型
2.1 总体框架
图1显示了本文的目标检测网络框架:(1)包含一个教师检测网络和一个学生检测网络,其中教师网络和学生网络的特征提取模块使用相同的网络结构。先训练教师网络模型,随后冻结教师网络参数,在训练学生网络模型时教师网络模型进行预加载,对输入学生网络的点云数据做增广,使学生网络探索更大的数据空间,并利用教师网络预测的软目标进行更好的优化。本文所用回归框蒸馏(Regression Box Distillation,RBD)策略作用于检测头的回归分支,而不是深层特征。(2)最终的检测网络是学生网络和其检测模块,为了增加分类预测与回归预测间的相关性而无需额外的网络嵌入,设计了定位引导分类(Positioning Guidance Classification,PGC)项作用于学生网络的分类预测,并改造分类损失函数。
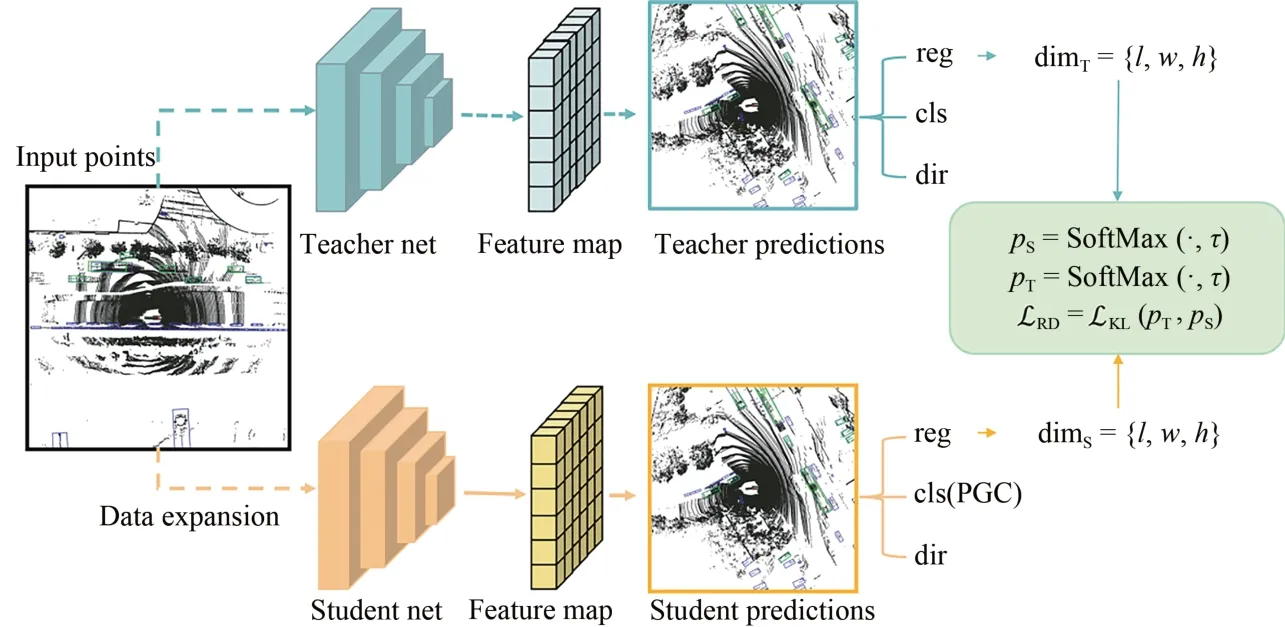
图1 网络框图Fig.1 Network block diagram
2.2 点云编码与特征提取
网络的点云编码和特征提取依照Pointpillars[4]进行设置。将点云在x-y平面上设置柱体,每个非空柱构成一组子点云Sx∈W,y∈H={Pi,i=1,2,…,nx,y},其中每个点Pi用一个向量(x,y,z,r)表示,nx,y是对应集合中的点的数量。将一帧点云编码成一个维度为(D,P,N)的稠密张量。对集合中的每个点用线性层+BatchNorm+ReLU激活函数处理,生成维度为(C,P,N)的张量,其中C是特征通道。再通过每个点的体柱索引值重新放回到原来对应的体柱的x,y位置上生成(C,H,W)维度的伪图像。特征提取网络由下采样网络和上采样网络组成。下采样网络块表示为ConvBlock(Cin,Cout,Sd,Nb),其中C是特征通道数,Sd是下采样因子,Nb是每个网络块中卷积层的数量。上采样网络块表示为DeconvBlock(Cin,Cout,Su),其中Su是2D反卷积的上采样因子。
2.3 回归框蒸馏
与只传递语义知识的分类蒸馏不同,回归框蒸馏能够传递目标物体的位置和尺度信息,来自教师模型的回归框尺度用作学生模型的额外回归目标,以帮助学生模型收敛到更好的优化点。此策略能够让学生网络模型的回归预测更为稳健,并实现更好的泛化能力,提升检测效果。
激光点云的三维目标检测中,网络模型的回归框预测输出为(x,y,z,l,w,h,θ),共7个维度的数据。本方法中,只对预测输出的回归框尺度(l,w,h)进行蒸馏处理。在二维图像目标检测中,其边界框的表示通常有(x,y,w,h)(中心点坐标,长和宽)、(xmin,ymin,xmax,ymax)(回归框左上角点和右下角点)和(t,b,l,r)(采样点到回归框的上、下、左和右的距离)表示方式。其中(x,y,w,h)和(xmin,ymin,xmax,ymax)可以直接互相转换,这两种表示方法进一步用其采样点(xs,ys)和相匹配的真实框(xgt,ygt,wgt,hgt)计算出采样点到真实框上、下、左和右的距离,也就是(t,b,l,r)。不论是Anchor-Base类型的检测网络还是Anchor-Free类型的检测网络,以上回归框的3种表示形式可以依据其相匹配的真实框进行互相转换,从离散值转换到连续值,从连续值转换到离散值。但是在带有旋转角的三维目标检测回归框中,其中心点、回归框尺寸和旋转角互相独立,本文的回归框蒸馏其思想是针对连续域上回归的变量先离散化处理,最后进行概率拟合。
本文所提的回归框蒸馏方法选择对正样本回归框的尺度Dim=(l,w,h)(回归框的长、宽、高)进行处理,(l,w,h)的每个变量的物理意义都是一致的,记每条边为e。设D为网络预测的3个回归框尺寸,分别由教师网络的DT和学生网络的DS表示,使用广义的SoftMax函数S(· ,τ)=SoftMax(· ,τ)将DT和DS转换为概率表示pT和pS。当τ=1时,它等价于原始的SoftMax函数;当τ>1时,输入的参数会携带更多的信息。
LRD用于衡量两组概率相似度的蒸馏损失,其定义如公式(1)所示:
其中:LKL表示KL发散损失,τ表示温度系数,S和T分别为教师网络和学生网络,p为概率值,D代表回归框尺度的集合。回归框尺寸S的3个维度的蒸馏可以化为公式(2),其中e代表回归框的边:
2.4 定位引导分类
为了增加分类预测和回归预测的相关性,设计了定位引导分类项,过程示意图如图2所示。物体在点云的BEV空间中有一个关键优势是位置不重叠,因此在BEV空间中真实物体的定位效果和定位质量较好。将网络的正样本回归预测和真实框在BEV空间下做IoU值计算,将计算得到的IoU值作为引导分数,分配给正样本对应的硬类别标签(One-hot),分配后的硬类别标签变为软标签(Soft Label)。整个过程中,具有高IoU的正样本在分类时被自适应地向上加权,正样本的回归预测质量引导对应的类别标签。定位引导项g定义如式(3)所示:

图2 定位引导分类Fig.2 Positioning guidance classification
目标监督值为:
其中:i是预测框和真实框的IoU值;pos代表正样本;bev是在BEV空间中边界框的维度表示;regpred表示预测框偏差值,通过预测框偏差值与先验框anchor解码,得出预测框bboxpred,将其与样本所匹配的真实框bboxgt做BEV视角下的IoU值计算,最终得到定位引导分类向量是用one-hot向量表示的真实标签;f是引入定位引导项的soft label表示形式的正样本标签。
目前Pointpillars网络的分类损失是焦点损失(Focal Loss,FL)损失函数,其一般形式如式(5)所示:
其中:y∈{0,1}是真实值的类别,p∈[0,1]是当真实标签y=1时模型预测的类别概率,γ是可调节焦点参数。焦点损失(FL)是由标准交叉熵-logpt和一个调节因子(1-pt)γ两部分组成。引入定位引导项g后,正样本真实标签从原本的y=0代表负样本和y=1代表正样本,变为f=0代表负样本和0<f≤1代表正样本的soft label表示形式。原本的焦点损失不能满足引入定位引导项后的计算要求,需要进行改造。焦点损失采用sigmoid算子α(· )的多二进制分类实现多分类,把sigmoid的输出标记为α,对焦点损失的两部分进行扩展,将交叉熵部分-logpt扩展为完整的表示形式-((1-y)log(1-α)+ylogα),代入定位引导项g后,交叉熵部分变为-((1-f)log(1-α)+flogα)。比例因子部分(1-pt)γ广义化扩展为估计α与其连续标签之间的距离绝对值,即表示为|f-α|β(β≥0),其中|· |保证了非负性。最后,将扩展的两部分组合起来,形成完整的分类损失函数,其定义如式(6)所示:
2.5 网络总损失函数
本文的损失函数中,回归损失选用与SECOND[18]相同的回归损失。每个真实目标或者其先验框的3D表示由一个七维向量来表示:(x,y,z,l,w,h,θ)。其中x、y、z表示3D边界框的中心点坐标,l、w、h分别表示3D边界框的长、宽和高,θ表示3D边界框的朝向角。在边界框定位回归任务中,真实边界框和先验框之间的残差定义为:
其中:xgt和xa分别表示真实边界框和先验框。da=边界框回归损失采用Smooth L1函数表示:
采用Softmax分类损失用于学习目标的朝向,朝向损失记为Ldir。
对于分类损失,使用改造过的焦点损失函数,即:
回归蒸馏损失为:
最终网络模型的总损失可表示为:
其中:Npos是正概率锚数;各项损失值的系数λ0=2.0,λ1=1.0,λ2=0.2,λ3=0.2。
3 实验结果分析
使用三维目标检测数据集KITTI对本文算法进行验证,在KITTI数据集上进行多种算法对比实验、模型推理速度比较和消融实验。
3.1 实验环境和优化器设置
本文实验环境操作系统为CentOS 7.6,硬件显卡型号为NVIDIA GeForce RTX 2080 TI,Intel(R) Xeon(R) 5220 CPU@2.20 GHz。深度学习框架为Pytorch 1.7,Python环境为3.7,使用CUDA 10.1用于GPU加速。
网络训练设置Batch Size为6,训练80个epochs。采用AdamW优化器,使用0.01的衰减权重。使用周期性重启学习率调整策略,初始学习率设置为0.001,最高学习率和最低学习率分别为10和0.000 1,训练期间循环次数为1次,学习率增加过程在整个循环中的比率为0.4。
3.2 数据集设置
在KITTI数据集上评估本文所提出的3D检测网络模型的性能。KITTI数据集中包含7 481个训练样本和7 518个测试样本。根据通用协议,将KITTI训练集分为3 712个样本的训练集和3 769个样本的验证集。对Car类、Cyclist类和Pedestrian类进行评估,其IoU阈值分别为0.7、0.5、0.5。此外,该基准在评估中有3个难度级别:简单、中等和困难,评估基于目标对象的遮挡和截断水平。按照官方KITTI评估指标,使用40个召回位置计算,以平均精度均值(mean Average Precision, mAP)评价检测结果。
在实验中将范围[0,69.12]、[-39.68,39.68]和[-3,1]米内的所有点分别沿着x、y和z轴体柱化,体柱的分辨率为[0.16,0.16,4],整个体柱网格大小为496×432×1。最大柱数(P)为16 000个,柱内最大点数(N)为100个。每个类的锚点由宽度、长度、高度和z中心来描述,具有0°和90°两个方向。在训练阶段,对输入的点云数据做数据增强处理,在x轴方向以0.5的概率随机翻转点云;将全局点云在z轴方向按照[-π/4,π/4]均匀分布的角度范围进行随机旋转,对全局点云按照[0.95,1.05]的范围进行随机缩放。
3.3 对比评估
为了评估所提模型方法的性能,在KITTI数据集与其他算法进行3D检测和BEV检测对比实验,结果如表1和表2所示。
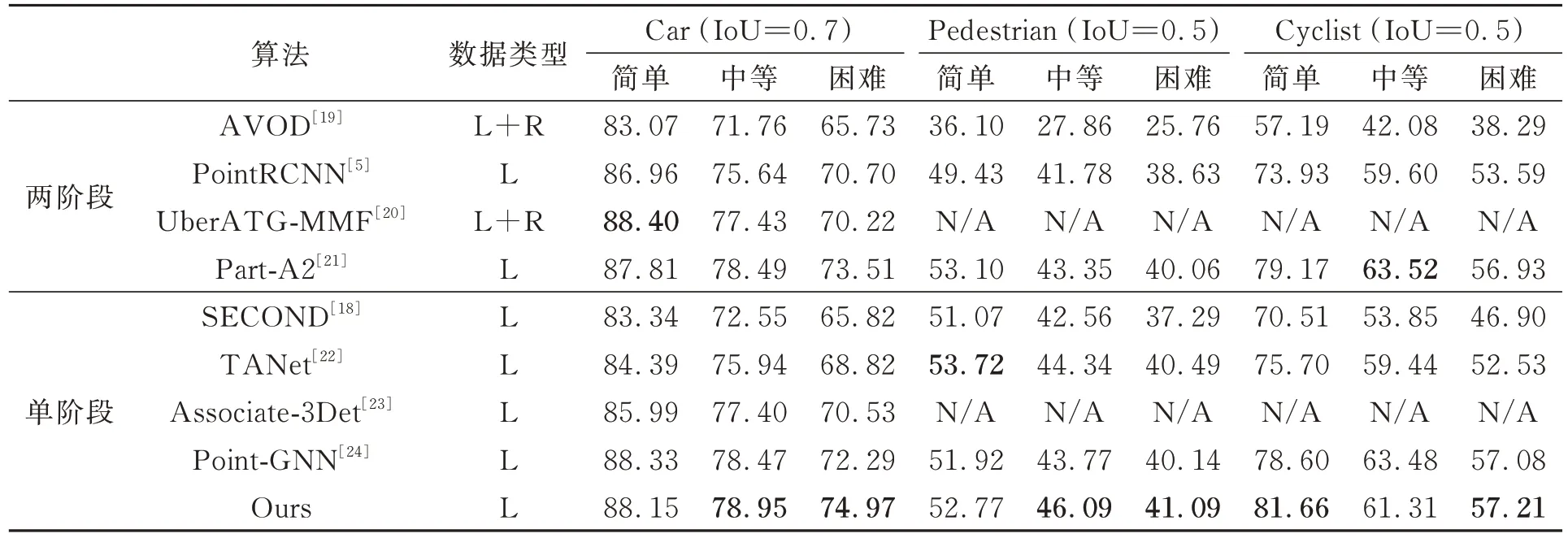
表1 KITTI数据集不同算法3D检测精度(3DR40)对比Tab.1 Comparison of 3D detection accuracy (3DR40) of different algorithms in KITTI dataset %
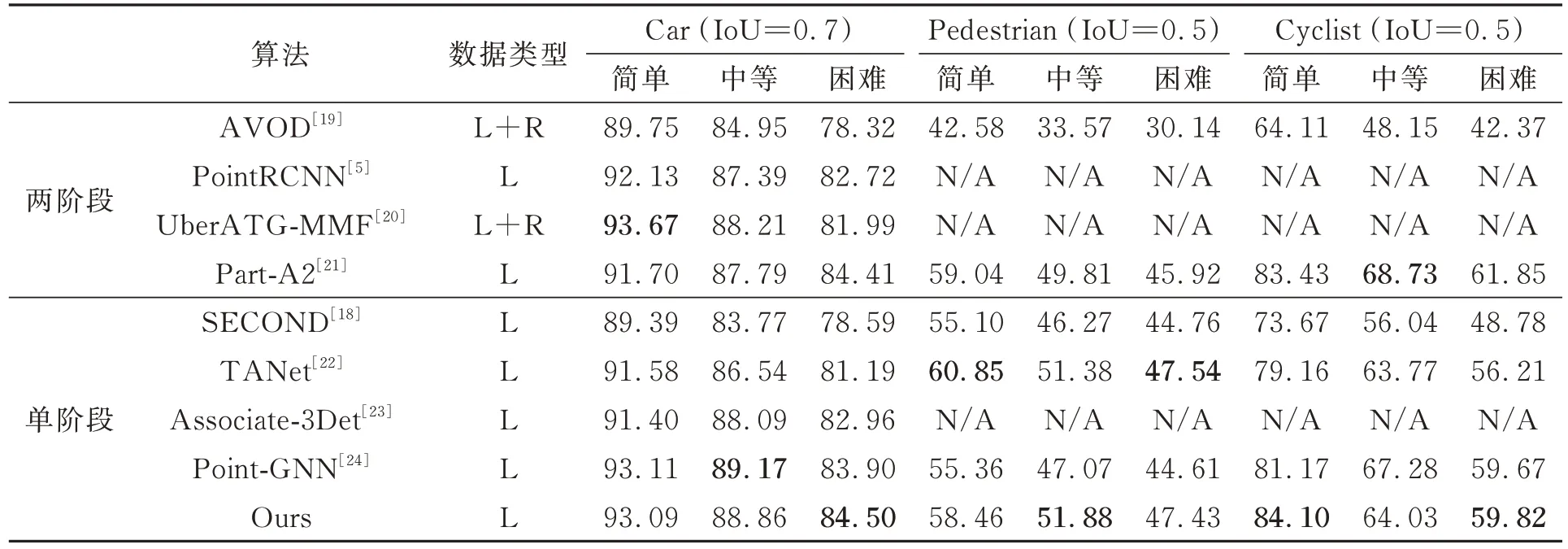
表2 KITTI数据集不同算法BEV检测精度(BEVR40)对比Tab.2 Comparison of BEV detection accuracy (BEVR40) of different algorithms in KITTI dataset %
在3D检测对比中,与经典的单阶段检测方法TANet[22]和SECOND[18]相比,在中等难度级别上,Car类和Cyclist类分别高3.01%、1.87%和6.4%、7.46%;与先进的单阶段检测方法Point-GNN[24]相比,Car类和Pedsetrian类在中等难度级别分别高了0.48%和2.32%。与两阶段检测方法PointRCNN[5]相比,3种类别的中等难度分别高出3.31%、4.31%和1.71%;与Part-A2[21]相比,Car类中等难度高出0.46%,本文模型优于多数两阶段模型方法。在BEV检测中,本文模型与TANet[22]和SECOND[18]相比,在Car类中等难度分别高出2.32%和5.09%。结果显示,本文的模型在所有3个难度级别的3D和BEV检测中与其他先进方法相比具有竞争力,验证了本文方法的有效性。回归框蒸馏能够传递目标物体的位置和尺度信息,帮助网络收敛到更好的优化点,使回归模型更为稳健;定位引导分类建立了预测框和分类预测间的相关性,提升模型分类效果,最终提升了模型检测精度。
本文方法采用体柱特征编码的方式,点云经过编码后,其分辨率显著低于体素特征编码和基于点的特征形式,所以其小目标如Pedestrian类的检测精度会低于部分基于体素特征编码和基于点的模型方法。
本文的回归框尺度蒸馏中引入温度系数τ,表3中显示了KITTI数据集中不同温度系数下的蒸馏结果,在温度系数τ=2时模型获得最好的效果。
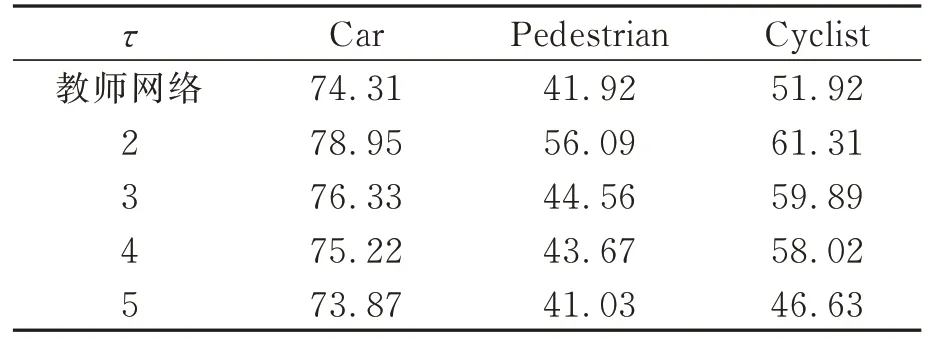
表3 蒸馏中温度系数在ModR40模式下对模型探测精度的影响Tab.3 Influence of temperature coefficient on model detection accuracy in distillation under ModR40 %
为了验证本文方法的检测效率,选择主流算法进行模型推理速度对比,结果如图3所示。在模型推理速度方面,本文模型方法是两阶段网络AVOD[19]和PointRCNN[5]的3~4倍;与单阶段网络SECOND[18]和TANet[22]相比,推理速度提高了大约2倍,达到45 FPS。虽然检测精度与Point-GNN[24]基本持平,但Point-GNN由于需要对点云构建“图”结构以及图卷积等操作,需要消耗大量算力,因此模型推理速度慢了许多,不符合实时性要求。与单阶段网络相比,本文网络模型具有检测精度优势;与两阶段网络相比,本文网络模型能够在检测精度上持平,但在推理速度上远高于两阶段网络。
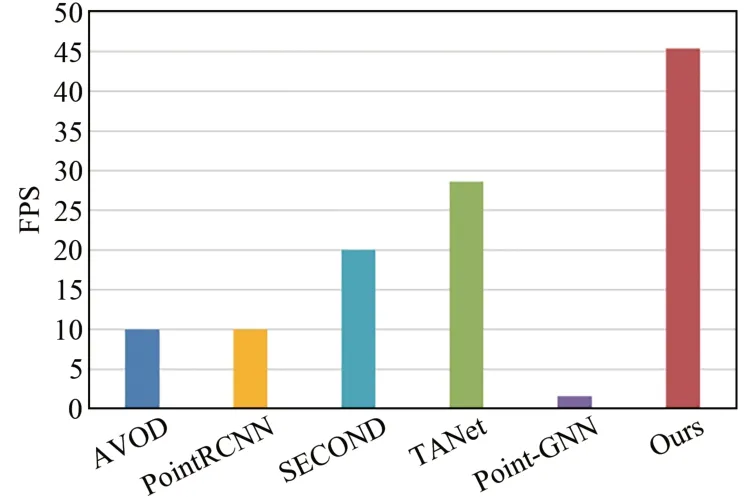
图3 网络模型推理速度对比Fig.3 Comparison of network model reasoning speed
如图4所示,将本文针对点云的蒸馏策略与其他蒸馏方法如Zagoruyko[25]、Zheng[26]、 Tian[27]、Heo等[28]、Zhang[16]等方法对比,以Pointpillars为基准网络,在KITTI数据集上进行Car类和3种难度级别的3D检测。可以观察到本文方法在Car类平均检测精度方面比所列蒸馏方法都要高。如图5所示,在3D检测难度级别为中等和困难难度级别中,本文的蒸馏策略比上述蒸馏方法效果提升更明显。
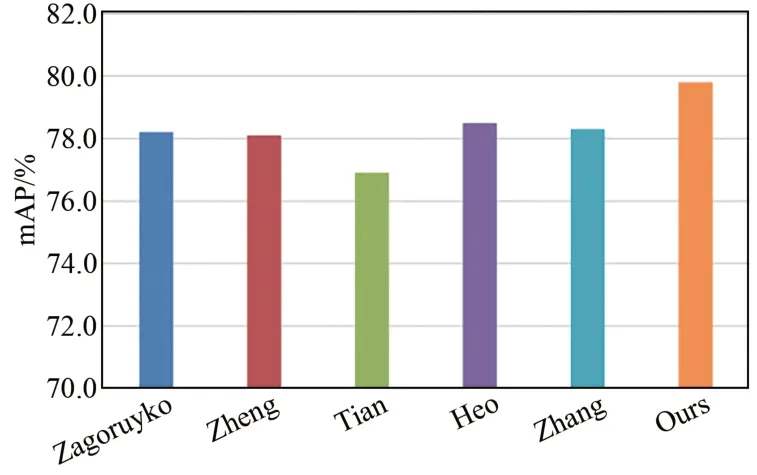
图4 Car类的平均精度均值对比Fig.4 Comparison of average precision of car class
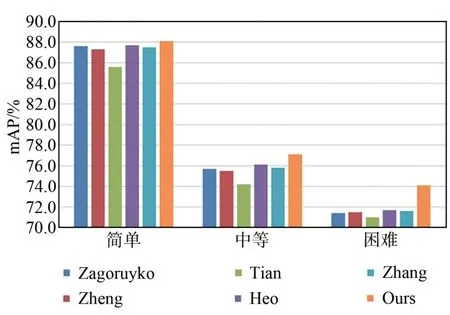
图5 3种难度级别的平均精度均值对比Fig.5 Comparison of average accuracy of three difficulty levels
3.4 消融实验
消融实验可以评估本文所提方法各个模块对检测结果的贡献。所有评估测试都在KITTI训练集上进行训练,在验证集上进行评估。基准网络为Pointpillars[4]网络模型,消融实验的设置以单独和总体结合的形式展示本文方法的有效性。其中“回归框蒸馏”记作RBD,“定位引导分类”记作PGC,使用40个召回位置计算平均精度均值(mAP),结果如表4所示。
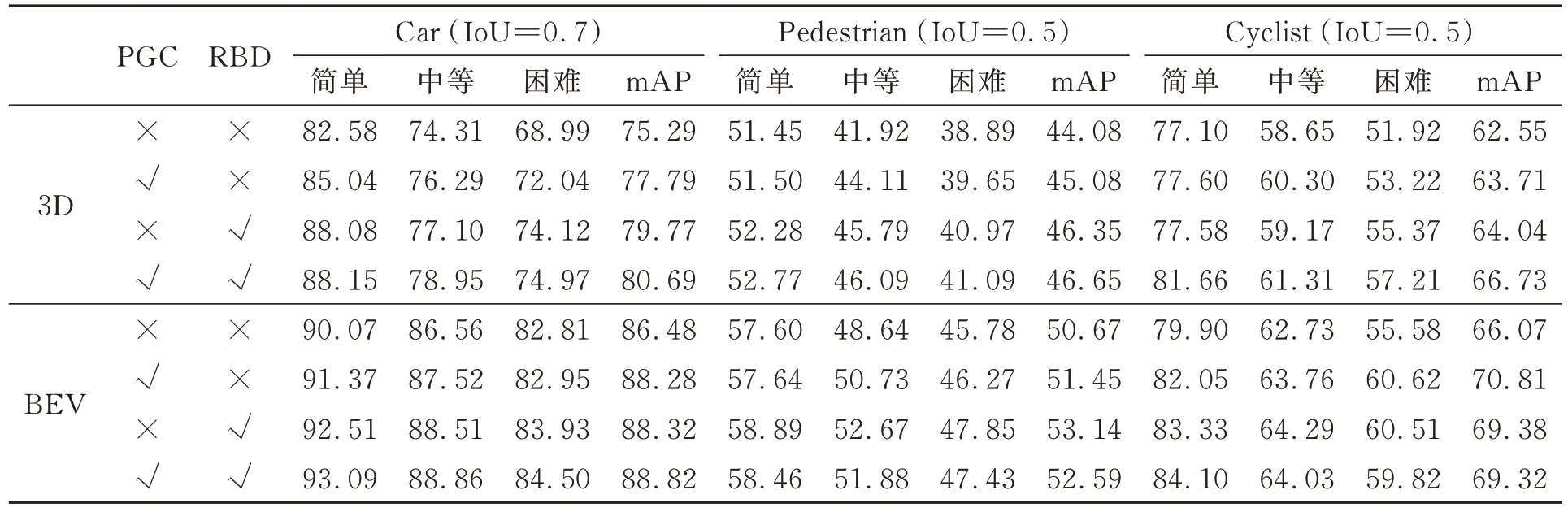
表4 回归框蒸馏和定位引导分类在KITTI数据集上的消融实验Tab.4 Ablation experiments of regression frame distillation and location-guided classification in KITTI dataset %
只增加RBD方法时,网络模型在3D检测中简单、中等、困难3类的平均均值精度提升了4.48%、2.27%和1.49%,表明给预测框的尺度增加额外的回归目标可以更好地优化模型,同时教师网络产生的软目标携带更多的信息,让学生网络在训练过程中学习到更多的信息熵,提升模型特征提取的质量,从而提高物体检测精度。只增加PGC方法时,3D检测中简单、中等、困难3类的平均均值精度提升了2.5%、1.0%和1.16%。定位引导分类项增加了回归预测和分类预测之间的相关性,具有高IoU的正样本在分类时被自适应地向上加权。最终综合评估,本文所提出的两种方法组合使用时,其检测效果提升最大。
4 结论
本文受图像目标检测中知识蒸馏思想的启发,针对激光点云数据的3D目标检测任务设计了预测框的尺度作为约束训练的蒸馏方法。此方法可以为检测网络在训练中提供更多的信息熵,使网络模型拥有更好的泛化能力,提升特征提取质量,提高模型检测效果。针对Pointpillars网络中回归预测和分类预测间的低相关性,设计了定位引导分类项,同时改造了分类损失函数,将正样本回归预测质量引导类别标签,以提升检测效果。在KITTI数据集中,本文算法模型比基准网络在Car类提升了5.4%mAP,在一众算法模型中具有竞争力。
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
导航定位与授时(2020年5期)2020-09-23
铁道通信信号(2020年9期)2020-02-06
今日农业(2019年15期)2019-01-03
电子制作(2018年11期)2018-08-04
知识经济·中国直销(2018年3期)2018-04-12
测绘科学与工程(2016年5期)2016-04-17
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
学习月刊(2015年1期)2015-07-11
读者·校园版(2015年19期)2015-05-14
