
面向云计算并发访问的计算机大数据调度负载均衡方法
2024-01-30 01:31:44王艳兵
滨州学院学报 2023年6期
王艳兵
(徽商职业学院 电子信息系,安徽 合肥 230000)
随着信息技术和网络技术飞速发展,计算机储存的数据种类及数量日益增多。由于网络规模不断扩大,将会有海量数据向计算机服务中心转移,从而导致数据中心能耗不断增大,运营商运行费用不断上升。计算机中心聚集了大量计算设备和平台,但由于无法合理地配置和利用这些资源,引起计算机服务中心能源消耗增大,从而导致了资源浪费和服务费用持续增长。文献[1]提出了一种基于神经网络的应用分析方法,该方法根据分块规模、分支执行步骤,使用针对神经网络规模化的应用方法,结合Winograd算法,实现对计算机数据存储的进一步优化;文献[2]提出了模拟退火法的应用分析方法,该方法通过开放排队网络对移动业务流时延进行优化建模,使用模拟退火求解模型,并在不同服务请求量和虚拟网络结构之间建立逻辑关联,实现对计算机虚拟网络功能部署。然而,这两种方法容易受到计算机存储内存影响,导致远程计算机无法根据目标需求发送计算机所需内容,也无法实现计算机数据有效反馈。针对该问题,本文提出了面向云计算并发访问的计算机大数据调度负载均衡方法。
1 计算机大数据云计算并发访问控制
1.1 基于正负理想解的大数据全面访问
在云计算环境中,多个用户同时访问和处理大数据是常见的情况,容易出现数据丢失导致数据访问不全面的问题。大数据全面访问机制可以通过正负理想解的大数据全面访问机制,将不同用户或应用程序的数据隔离开来,防止不同用户之间的数据冲突和干扰,确保数据的安全性和完整性。正负理想解关系如
图1所示。考虑到负理想解的关键参考作用,计算备选项与正理想解距离公式为
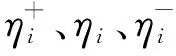
ε取值不同,可以反映决策者对指标偏离程度。当ε=1时,强调云计算部署方案整体效用最大化;当ε→∞时,强调云计算部署方案整体惩罚最大化。通过云计算部署方案的正负理想解大数据全面访问机制,可保证访问数据的全面性。
1.2 访问控制身份认证机制设计
在保证访问数据全面性的同时,为了保证数据的安全性和隐私保护,需要对访问身份进行验证,确保只有经过身份认证的用户才能访问数据,并且按照其权限进行合法的访问操作。访问控制机制利用预先定义的存取控制策略,对数据需求进行约束,使授权的合法使用者能够存取数据,而不能存取未获许可的数据。适当的访问控制机制,可以有效地限制使用者的存取权限,保证信息安全。利用云计算技术进行数据支持,将会给用户带来更好的数据处理体验效果。
访问控制身份认证机制主要包括密码、一次性令牌、条件属性验证,验证请求用户是否合法。当客户机以ID及口令登录时,若口令是有效的,则会产生一次令牌,将该令牌直接传送到客户端,结合一次性令牌提高云计算中客户认证效率。访问控制身份认证机制采用一次性令牌对客户端进行身份认证,而口令则是为了防止账户被非法访问而用来保护用户账户安全的密码。无论何时客户机登录,访问控制身份认证机制都会提供一种新的可使用标记。一次性令牌由系统自行根据下列公式自动产生,ID→OT,OT={p}。式中,OT表示一次性令牌,p表示素数。当客户端登录时,这个方法就会提供一个新的可用标签。这种一次性标记是通过系统按照
自动产生的。式中,X1、X2、X3分别表示计算机大数据密码、一次性令牌、条件属性。如果多阶段身份被认证,那么说明控制请求是有效性,具有一定可信性。反之,则不可信,无法通过访问控制身份认证。
2 计算机大数据多批处理调度
对计算机大数据云计算并发访问进行控制,可以提高数据访问的全面性和安全性,但是计算机大数据中的数据量过大和计算任务过多会造成计算机负载失衡,进而导致计算机系统性能降低,给计算中心带来更多能源消耗。因此,通过对计算机进行多批调度处理,在保证访问安全的条件下,可降低调度能耗,提高计算机的系统性能。
2.1 制定计算机大数据多批处理分级方案
利用MapReduce迭代法对基于云计算的多批次数据进行排序,每一个映射任务都会从HDFS上装载数据,而Reduce任务则会向HDFS发送一次迭代中间结果。在下一个循环中,同样装载和传送程序也会重复[3-4]。为防止因数据量过大和计算任务过多造成计算机负载失衡,将数据多批处理任务分配到固定节点上。因此,构建基于云计算的任务调度模型(图2)。
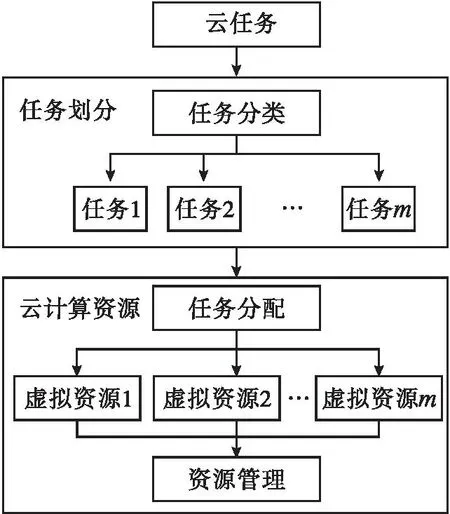
图2 基于云计算的调度模型
由于云计算具有大量计算机集群[5-7],这些集群的结构复杂且异构,所以通过负载均衡处理,使各个计算机集群均衡地分配数据和计算任务,降低计算机集群的能耗,让网络资源得到更加平衡和充分的利用,避免某些计算机过载而导致系统性能下降,或某些计算机空闲而浪费网络资源。在服务端收到批量数据后,通过评估其价值函数,计算出任务收益,从而判定是否接受[8]。服务方接收任务时的增益
式中,r表示任务接收后所带来的收益,t0、t1、tmax分别表示延迟时间、任务持续时间和任务完成时间,δ表示收益变化值[9]。由于计算机处理大数据时,面对的是多批处理任务,所以该情况下的服务方接收任务增益可表示为
式中,α、β分别表示收益和未收益成本比例,tB表示任务B持续时间,z表示任务B执行成本。将相同收益计算机大数据调度任务归一处理,通过数据分级调度策略达到多批大数据处理最大化收益目的[10]。
2.2 大数据多批处理调度方案的实现
在云计算环境下,用户提交的任务调度为待执行B任务,将调度分配到适当计算资源节点,以满足用户要求。调度分为两个阶段:第一阶段的调度是根据用户运行时间来安排任务到虚拟机[11];第二级段调度是根据任务特性和负载状况,对虚拟机进行合理分配,以保证系统资源负载平衡,同时降低系统整体功耗[12]。为了快速完成任务,需要大量的运算节点,这导致计算中心的能耗和运营商的成本上升。为了使任务能在最短时间内完成,必须调动更多计算节点,这就给计算中心带来更多能源消耗[13]。为了在低成本、短时间内调度多批大数据,构建了任务执行时间和能耗双重优化函数
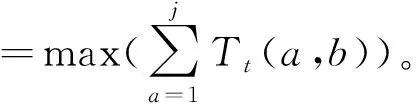
式中,Tt(a,b)表示任务从节点a到节点b预计完成的时间,j表示任务完成轮次。
任务调度能耗成本为
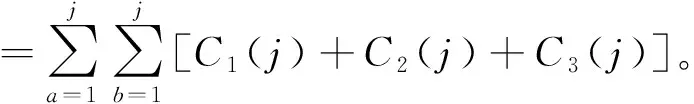
式中,C1(j)、C2(j)、C3(j)分别表示单位时间计算、传输和存储所消耗的能量。云环境中,当任务分配时,适应性高的个体会被更多地遗传到下一代,而适应性低的个体会在每次的竞争中被淘汰[14]。
采用双目标优化方法,以减少任务完成时间,降低计算服务中心能量消耗。构建基于时间-能耗双重任务调度的适应度函数
H(I)=ω时间h时间(I)+ω能耗h能耗(I)。
式中,ω时间、h时间(I)分别表示时间权重和适应度函数,ω能耗、h能耗(I)分别表示能耗权重和适应度函数[15]。假设计算机大数据从节点a到节点b的最短传输路径为d,那么数据传输路径迭代函数可表示为
dm(b)=dm-1(a)+ω′(a,b)。
式中,m表示迭代次数,ω′(a,b)表示节点a到节点b的权值。充分考虑收益要素,通过计算获取调度任务和计算机空闲状态下相匹配的动态调度方案,公式为
T(B,G)=u(B)-t(B,G)+ωBv(B,G)。
式中,u(B)表示任务执行优先等级,t(B,G)表示计算机空闲状态G下任务执行初始时间,ωB表示任务权重,v(B,G)表示任务处理速度,通过该式实现对计算机大数据多批处理调度,降低调度能耗,提高计算机的系统性能。
3 方法测试
为了检验面向云计算并发访问的计算机大数据调度负载均衡方法合理性,采用某企业的云计算管理系统平台进行测试。云计算管理系统平台如图3所示。根据图3的云计算管理系统平台,基于网络流量数据集,从任务调度和数据访问两方面对计算机的能耗调度、资源利用率和总隐私权重展开测试,其结构如图4所示。
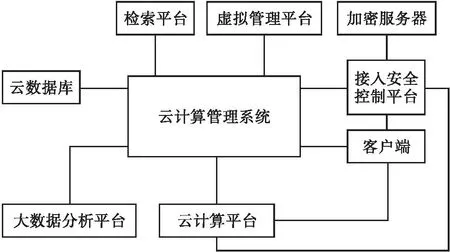
图3 云计算管理系统平台
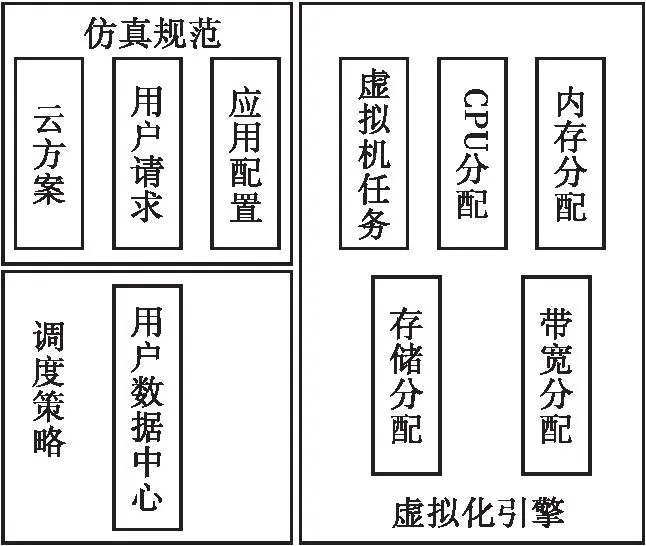
图4 CloudSim分层结构
计算机相关配置及负载参数如表1所示。

表1 计算机相关配置及负载参数
3.1 访问测试
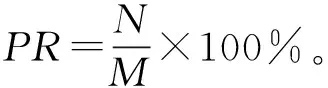
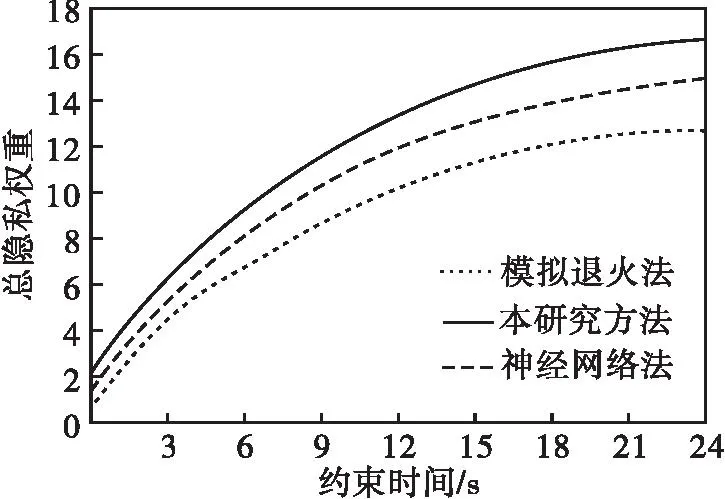
图5 三种方法总隐私权重对比分析
3.2 调度测试
CloudSim提供了专门的虚拟机、内存、带宽等接口,可以模拟虚拟环境中云计算技术,并能在这种环境中进行多批次数据调度。计算机运行时间和能耗是调度的关键因素,以调度能耗为例,使用神经网络法、模拟退火法和本研究方法对比分析能耗调度情况,对比结果如图6所示。
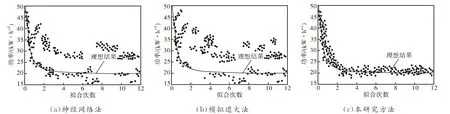
图6 三种方法能耗调度结果对比分析
由图6可知,使用神经网络法、模拟退火法能耗调度结果与理想结果相差较大,无法全部拟合在同一条曲线上,由此说明使用传统两种方法拟合效果较差,即能耗调度结果不理想;使用本研究方法能耗调度结果与理想结果接近,大部分数据拟合在同一条曲线上,由此说明使用本研究方法拟合效果较好,即能耗调度结果理想。
以调度时间为例,使用神经网络法、模拟退火法和本研究方法对比分析能耗调度情况,对比结果如图7所示。由图7可知,本研究方法在进行负载均衡调度时,网络资源利用率高于神经网络法和模拟退火法,说明使用本研究方法可以提高网络资源的利用率,负载均衡性能良好,能够达到最佳均衡状态。

图7 三种方法负载均衡调度结果对比分析
4 结束语
为了解决计算机大数据调度能耗高、访问不安全的问题,提出了一种面向云计算并发访问的计算机大数据调度负载均衡方法:给出了一种基于多级身份验证的云计算隐私保护算法,采用口令、一次性标识、条件属性等多种方式进行身份验证,以防止在计算复杂度较低情况下进行非法访问,从而提高了云数据隐私权保护。通过对多批数据的排序处理,保证了在以后数据调度中仍然能够很好实现负载平衡,防止了因负载不平衡而造成业务崩溃。
猜你喜欢
小猕猴学习画刊·下半月(2022年2期)2022-04-16 16:06:33
网络安全技术与应用(2019年7期)2019-12-24 09:19:34
测控技术(2018年3期)2018-11-25 09:45:08
计算机工程(2018年8期)2018-08-17 00:26:54
中国公共安全(2017年11期)2017-02-06 05:28:08
通信学报(2016年11期)2016-08-16 03:20:32
现代工业经济和信息化(2016年19期)2016-05-17 05:38:20
电测与仪表(2016年17期)2016-04-11 12:38:44
信息安全研究(2016年10期)2016-02-28 20:18:36
电源技术(2015年5期)2015-08-22 11:18:24
