
基于异构计算平台的卷积神经网络加速器的设计∗
2024-01-29 02:23周贤中
电子器件 2023年6期
王 帅,杨 帆,周贤中
(广东工业大学信息工程学院,广东 广州 510006)
近年来深度学习发展迅速,并在图像分类、目标检测、语义分割、语音识别等[1-4]领域取得成功。然而,深度学习的模型检测精度在不断提升的同时,对计算性能和内存的要求也在不断提升。当前云端GPU 部署复杂的深度学习模型面临高带宽消耗、高延迟性、网络可靠性不足、用户数据隐私难以保证等问题,因此在嵌入式边缘计算平台上推理复杂的深度学习模型已经成为当前的研究热点[5]。
面对上述问题,部分学者从神经网络本身的结构入手,优化算法模型,降低模型的运算量,如Mobilenet[6]、ShuffleNet[7]、Xception[8]等轻量级网络。还有部分学者使用数据位宽为2~16 位的精度来代替全精度的浮点数[9-10],进一步压缩模型。以上研究的关注点是网络模型本身的优化,而在实际的网络部署过程中,还需考虑硬件资源利用的合理性,系统的整体功耗以及数据传输吞吐率等问题。
FPGA 具有可编程性、可重构性、低延迟和低功耗等优点。若使用FPGA 加速神经网络模型,可根据算法模型来设计硬件结构[11]。Nguyen 等[12]为了避免频繁访问片外存储数据所造成的过多延时,设计了一种高效的Tera-OPS 流架构。这种架构下,网络中所有模块的权重数据存储在芯片上,以最大限度地减少片外数据传输,提高数据的复用次数,这导致最后设计的系统对硬件资源要求较高。Yu 等[13]设计了一个参数化架构,建立资源消耗和系统时延模型,对加速器资源空间进行探索,以确定优化系统延迟的设计点,同时满足资源约束,但是网络模型的量化,没有动态分配小数位。Adiono 等[14]用通用矩阵乘法的方式来加速卷积模块,该方法将基于滑动窗的卷积乘法形式转换为基于二维矩阵卷积乘法的形式,提高了访存的连续性和计算效率。Chen等[15]设计了数据流水化的结构,与文献[12]的流水化设计区别在于它只将卷积层和池化层数据流在FPGA 片上进行流水化计算。
针对上述研究现状,本文以YOLO-FASTEST 轻量级的网络结构为模型,在ZYNQ7020 平台上进行部署加速。主要工作如下:①对加速器的数据缓存单元与计算单元进行参数化设置。②调整卷积循环嵌套的次序,实现输出特征图复用,对Bottleneck 模块实现多层的片上流水运算。③使用16 位定点量化以及层融合的方法,将网络模型进一步压缩,降低硬件资源消耗和推理时间。
1 YOLO-FASTEST 算法模型
YOLO-FASTEST 是YOLO 系列改进的轻量级目标检测网络。网络模型的设计思路借鉴了Mobilenet[6]的方法,引用了Bottlenecks 模块对传统卷积进行替代。同时使用SPP 模块实现局部特征和全局特征的融合,丰富最终特征图的表达能力,网络模型的大小为3.5 MB,算法模型的复杂度为2.2 Bflops(billion float operations),在PSCAL VOC 2017数据集的mAP(Mean Average Precision)为69.43%。
YOLO-FASTEST 模型如图1 所示,由主干网络(backbone)和特征金字塔网络(Feature Pyramid)组成。Bottlenecks 由3 个卷积层组成,当输入特征图与输出特征的尺寸相等时带有一个shortcut 层,为Res-Bottlenecks。SPP 模块是由3 个尺寸为3×3、5×5 以及9×9 的最大池化层组成。模型共由84 个卷积层、3 个最大池化层、1 个上采样层、18 个shortcut 层、2 个YOLO 层以及5 个路由层组成。最终输出特征图分辨率大小有13×13 和26×26 两种,分别负责大目标和小目标的检测。
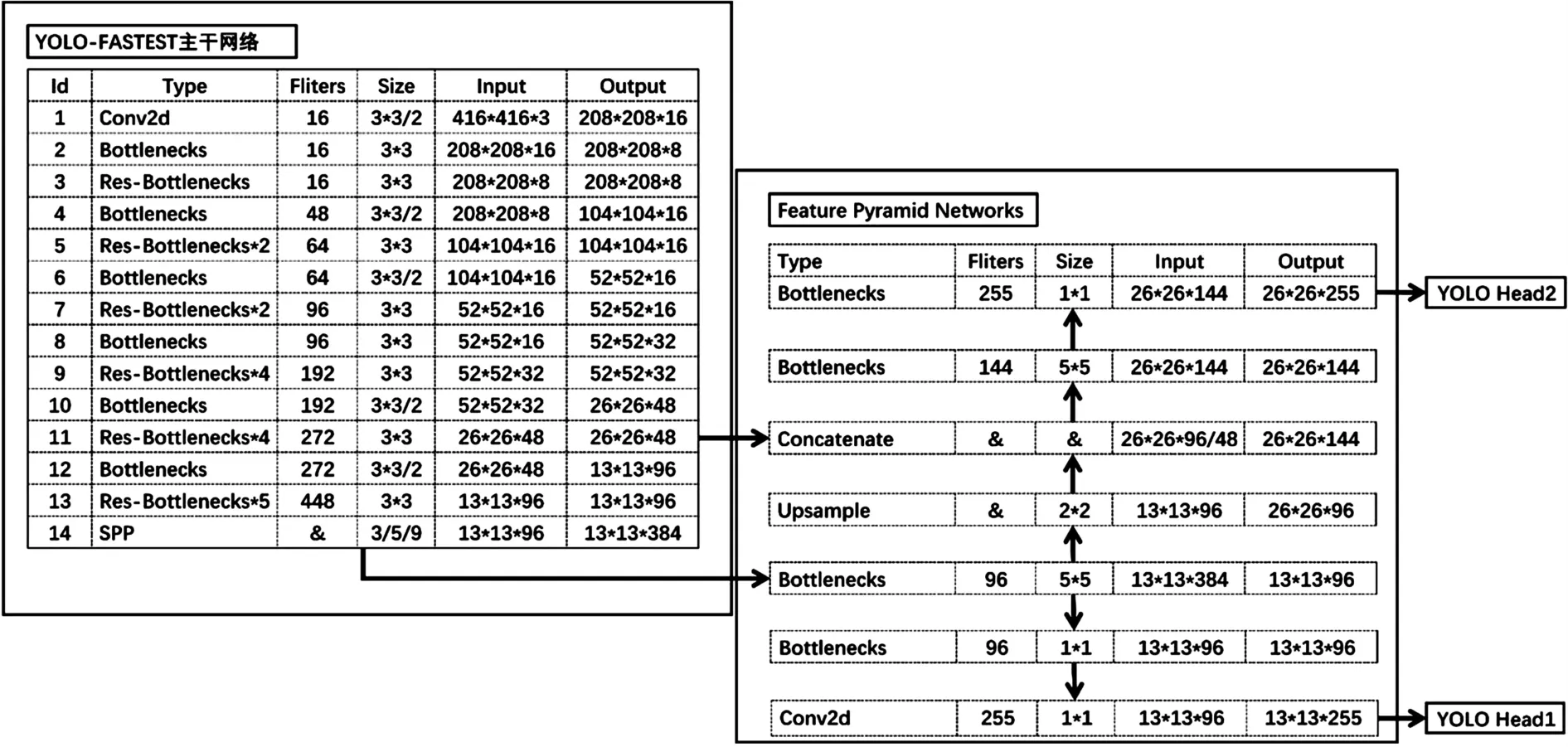
图1 YOLO-FSATEST 网络结构
2 系统设计
系统的整体架构如图2 所示,由PL 端FPGA 搭建的加速器与PS 端CPU 构成。PL 端加速器的架构以单指令多数据流的形式,由控制器、计算单元和数据缓存单元三部分组成。
当需要计算任务时,PS 端通过AXI-lite 将任务指令传输至PL 端的控制器中进行解析并以参数的形式传输至计算单元和数据缓冲单元。计算单元和数据缓冲单元分批次通过AXI 总线从外部存储器中读取数据、计算加速以及写回数据。
Bottlenecks 模块在PL 端上多层流水加速,最大池化层、上采样层、shortcut 层使用PL 端单层流水加速。路由层引用前面层的特征图,不涉及计算,通过PS 端的调度来完成。YOLO 层涉及复杂的指数计算以及sigmod 激活函数,使用PL 端计算将耗费大量资源,因此将YOLO 层的运算放入PS 端内。
PL 端内计算单元的计算能力以及数据缓存单元的数据吞吐量受FPGA 内部的资源约束,需要设计合理的优化方案,在有限的资源下,构建性能良好的加速器。
2.1 数据缓存单元
数据缓存单元的设计如图3 所示,单元中包含行缓存、输入数据缓存、输出数据缓存。数据在PL端内传输使用双缓存乒乓传输,每个缓存区在循环的周期内交替执行两项指令:1、存储上一个缓存或外部存储传来的数据。2、将存储的数据传输到下个缓存或外部存储。例如当一个周期内行缓存1 执行指令1 时,此时行缓存2 则执行指令2。同理,输入缓存1 执行指令1 时,此时输入缓存2 则执行指令2。这种数据传输模式以空间换时间,用数据传输的时间来掩盖计算时间。
PL 端的片内BRAM 资源无法容下整个特征图的数据,采取对输入特征图进行切割分块送入片上缓存进行运算,权重根据输入特征图做对应的分割。设置Si、So、Sr、Sc 四个切割参数分别对特征图的输入通道、输出通道、输出行数、输出列数进行切割。由上述切割参数得到的PL 端数据缓存设置及BRAM 资源消耗,如表1 所示。

表1 PL 端数据缓存配置以及BRAM 资源消耗
数据缓存配置中的S为步距,K为卷积核的宽,Nin为PL 端输入接口的数量,Nout为PL 端输出接口的数量。中间特征图缓存用来存储Bottlenecks 内DW(Depthwise Convolution)层的输入特征图以及shortcut 层另一个输入特征图。
CBRAM为单个BRAM 的存储容量18 k,bitwidth为数据位宽。以上缓存均乘以2 表示使用双缓存。权重缓存的数据量较少,因此使用LUT 存储,不消耗BRAM 资源。表1 中所有缓存消耗BRAM 总和应小于等于片上BRAM 总量。
给定以上数据缓存配置,PL 端时钟频率f,使用双缓存乒乓传输,从片外读取数据到输入缓存需循环((Sr-1)×S+K+1)×次,从输出缓存到片外存储需循环(次,输入输出缓存延时表达式如下:
设某层需使用PL 端循环计算N次,计算单元的时延设为Tcom,双缓存乒乓传输下PL 端单层运算的总时延为:
2.2 计算单元
计算单元内部根据层类别划分,构建类别不同的计算电路,利用时分复用的思想,在每个时钟周期不间断地计算来自数据缓存单元传输的数据。
卷积计算单元如图4 所示,由乘法器阵列和累加器构成。对输入通道和输出通道的维度进行并行乘法计算,不同输入通道上的同一坐标像素值与权重进行乘积,经累加器后将部分和暂存至寄存器中,等待与下一计算周期的部分和相加。直至权重滑动窗内的值都乘完后,将寄存器内的值通过多个输出通道维度保存至输出缓存中。
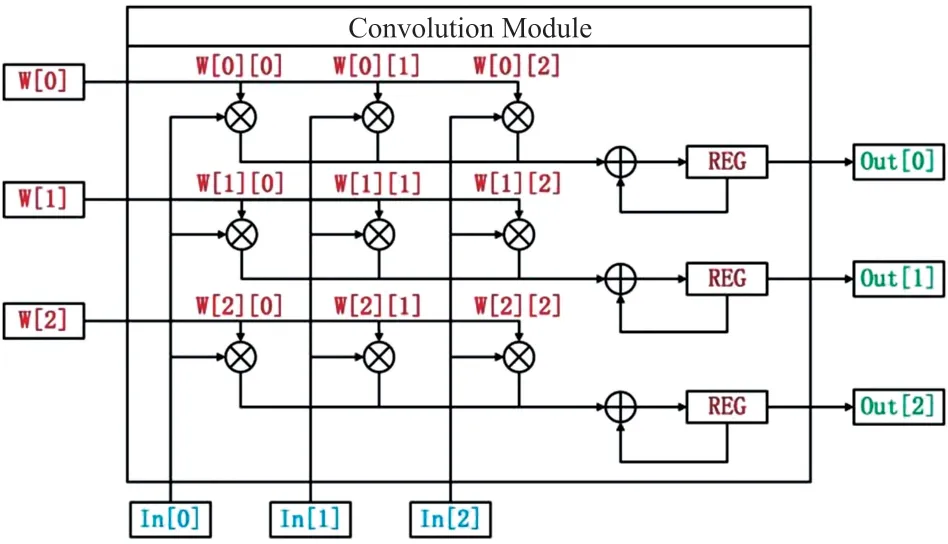
图4 卷积计算单元
在实际评估中,需要考虑计算并行度与资源约束之间的关系,DSP48e1 是FPGA 内部的专用硬件资源,用DSP48e1 构建乘法器阵列应满足式(4)的要求,其中NMul是乘法器的数量,Pi和Po分别表示输入通道和输出通道计算并行度参数,NDSP表示一个乘法器消耗的DSP48e1 的资源,与数据位宽bitwidth 有关。
给定时钟频率f、计算并行度参数Pi和Po以及片上数据缓存配置,单次卷积计算单元的处理时延Tconv为:
其他模块的计算单元如图5 所示,图5(a)所示是最大池化层计算单元,将用于输出的寄存器赋最小初始值,每个循环周期与输入的寄存器进行比较,将最大值保存至输出寄存器,当滑动窗内的值都比较完后,输出寄存器内的值保存至输出缓存中。图5(b)所示是上采样层,上采样层是将特征图的长和宽扩展,上采样单元使用寄存器取出输入缓存的值暂存后,根据扩展的比例大小循环存入输出缓存中。图5(c)所示为shortcut 层,将来自两个不同层的特征图进行相加。
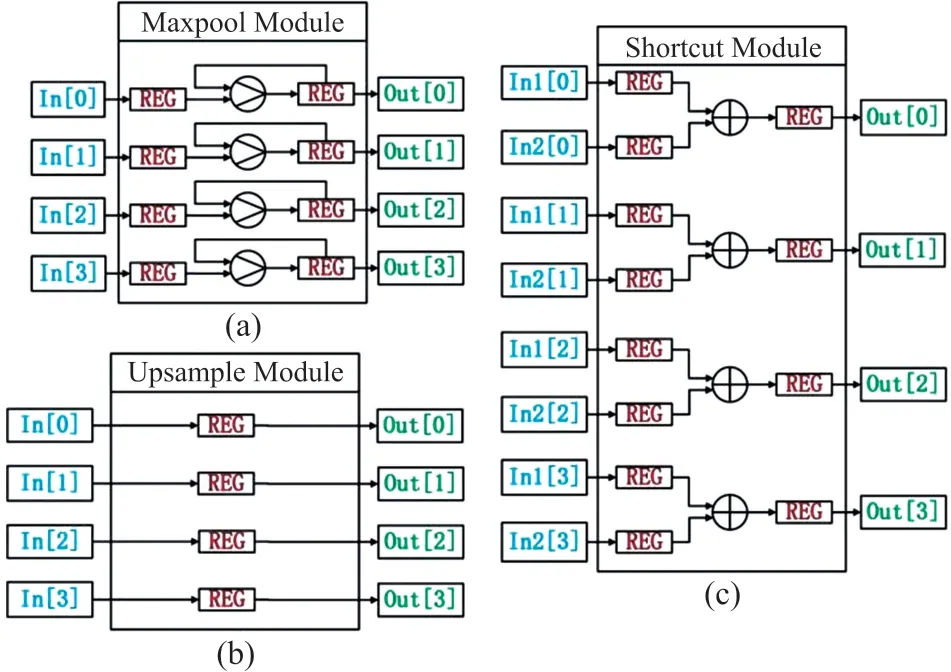
图5 其他模块计算单元
这三类模块由于输入输出通道的维度相等,计算单元的并行度Pi=Po。给定时钟频率f,三类模块处理时延Tmax、Tshortcut、Tupsample为:
3 优化方法
3.1 卷积层输出特征图复用
PL 端的卷积运算由四层循环嵌套组成。传统的权重窗口复用模式,将输出特征图的行和列的循环放入最内层,每轮循环复用权重数据,优先计算出完整的输出特征图,然后对输出通道进行循环。这种方法适用于PL 端对单个层的计算加速。
对于PL 端上连续多层流水运算,若使用权重复用的方法,优先计算出完整的输出特征图,会造成较大的延时。调整循环嵌套顺序,每次只计算出部分输出特征图就传递给下一层,无需等待完整的输出特征图。如图6 所示,循环嵌套由内到外按照LOOP1 至LOOP4 的顺序分别对输入特征图通道、输出特征图的通道、输出特征图行和列进行计算。每次循环的部分和暂存至输出缓存内,待下一轮循环的时候再复用。当LOOP1 循环结束后,所有部分和累加后的最终结果从输出缓存写回至片外存储或者传递至下一层。每层的循环间隔等于设置的4 个切割参数Si、So、Sc 和Sr。
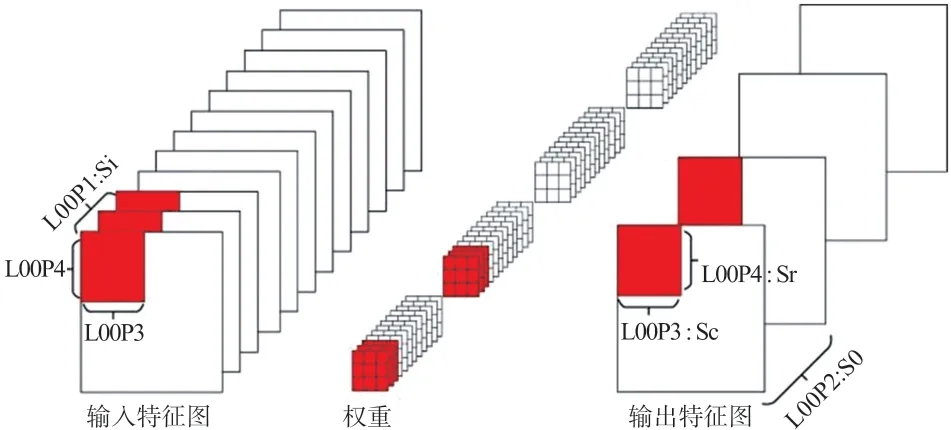
图6 输出特征图复用
使用输出特征图复用模式,设In 为输入特征图通道数,Out 为输出特征图通道数,则「In/Si⏋个循环周期后,即可将输出缓存内的数据传至下一层的计算单元中。
3.2 PL 端多层流水
PL 端连续多层流水相比于单层流水,可减少PL 端与外部存储器数据交互的次数,网络结构中的Bottleneck 由三层卷积组成,且结构固定,适合于整个模块放入FPGA 片上缓存进行多层流水计算,模块结构如图7 所示。输入特征图缓存首先经过第一层PW(pointwise)卷积,卷积结果存储在中间缓存内,中间缓存经过第二层DW(depthwise)卷积后,将结果覆盖至输入特征图缓存,最后再经过第三层PW(pointwise)卷积后,将计算结果存入输出缓存内。DW 卷积的卷积核无输入通道维度,卷积单元只对输出通道进行并行度为Po的并行运算。
使用输出特征图复用的模式,给定时钟频率f,第一层PW1 输入输出特征通道为In1 和Out1,使用双缓存乒乓传输,输入缓存延时Tinput与计算延时Tconv1重叠「In1/Si⏋次,取二者最大值。PW1 的延时表达式TPW1如下:
PW1 层的计算结果送入DW 层的进行运算,DW 计算单元延时Tconv2,DW 层的延时表达式TDW如下:
DW 层计算完后,紧接着进行PW2 层的计算。In2、Out2 为PW2 层的输入通道数和输出通道数,PW2 层「In2/Si⏋次的循环后,将结果通过输出缓存写回至外部存储中,PW2 层的延时表达式TPW2如下:
使用双缓冲乒乓传输后,输出缓存延时Tout与PW2 层的延时TPW2重叠(「Out2/So⏋-1)次,取二者最大值。Bottleneck 输出部分特征图的延时TBneck的表达式如下:
3.3 模型量化
模型的量化是指权重、偏置、特征图的数据由32 位浮点数,映射为16 位、8 位等低位宽数。使用低位宽数据在PL 端上进行存储和计算可以节约BRAM 和DSP 的资源,但模型的精度也有所下降。
本文使用一种逐层定点16 位量化的方法[10],16 位的定点数中使用1 位符号位,Q位小数位,剩下位表示整数位。量化过程中浮点数xfloat与定点数xfixed之间相互映射的关系式如下:
L表示定点数位宽,式(13)将浮点数的小数位在定点数中使用Q位表示,Q取值越大,定点数的精度就越高。式(14)将定点数还原成浮点数。模型每层根据参数的取值范围的不同,用不同的Q值来量化该层。
对84 层卷积的权重使用定点8 bit 和16 bit 的量化方法,利用式(15)计算总误差和平均每层的误差,根据表2 结果显示,本文将使用16 bit 的量化方案。
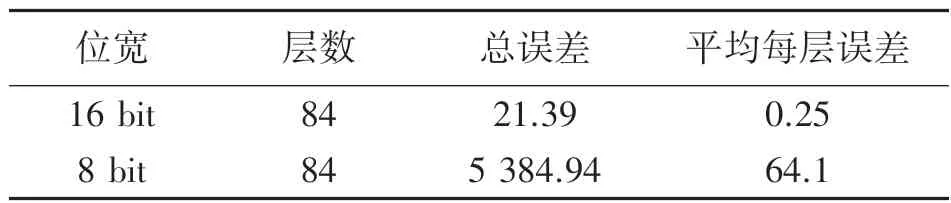
表2 定点量化权重误差
3.4 卷积层与批量归一化层融合
批量归一化层(Batch Normalization)能提高网络的训练速度,在模型推理阶段BN 层的计算固定,可以将其融合进卷积运算之中,加速推理时间,节约硬件资源。卷积层的计算式(16)和BN 层的计算式(17)如下:
式(16)和式(17)中X与Y都表示输入特征图和输出特征图,式(16)中W和B表示卷积层的权重和偏置。式(17)中γ为尺度参数,β为偏置参数,μ为输入样本的均值,δ为输入样本的标准差,这四个参数是在训练后已学习到的。ε通常设定为一个极小的值(如0.000 001),以防止分母为0 的情况。卷积层与BN 层的融合如式(18)所示:
化简:
融合后的新权重值Wmerged=,新偏置,预先计算出新的权重值和新的偏置,在FPGA 中直接进行融合后卷积运算,提高推理速度。
4 实验结果及评估
系统开发平台使用Xilinx 的Vivado 设计套件,使用高层次综合工具Vivado HLS 2019.1 设计YOLO-FASTEST 加速器IP 核,然后将设计好的IP核与ARM9 以及片外DDR3 在Vivado 2019.1 上进行综合、布局布线。最后,使用Vivado SDK 2019.1对ARM CPU 进行开发。
PL 端内的硬件资源包含630 KB 的BRAM、220个DSP48E、53 200 个LUT、106 400 个FF。PS 端主要使用的是双核ARM Cortex-A9 硬核处理器和一个存储大小为512 MB 的DRAM。特征图和权重数据均存储在片外DRAM 中的。在PL 端内的AXI_DMA IP 核为四通道的AXI_HP 存储映射接口和AXI-Stream 接口之间提供高带宽的直接存储访问。PS 端发出的控制指令则由AXI_GP 接口以及PL 端内部的AXI interconnect IP 核进行传输。
4.1 资源消耗与时延评估
在双缓存流水机制下,数据缓存单元中切割因子设置为Si =12、So =12、Sr =26、Sc =26,输入输出接口Nin=Nout=4,步距S=2,卷积核尺寸K=3,数据位宽bitwidth 为16 位定点数。以上参数确定后结合表1,预估需消耗184 个BRAM。
Bottelneck 模块内有PW 卷积和DW 卷积,需设置不同的卷积计算单元。PW 卷积计算单元的并行度参数Pi=Po=12,DW 卷积计算单元的并行度参数Po=12。FPGA 内部两个16 位数的乘法运算消耗NDSP=1,依据式(4),PW 和DW 卷积预估需消耗共156 个DSP48e1。
Vivado 系统综合后消耗的实际资源如表3 所示,实际消耗BRAM 比预估多消耗19 个,可能用于PL 端输入输出接口缓存。实际消耗的DSP48e1 比预估多消耗16 个,可能用于其他计算单元的消耗。

表3 PL 端资源消耗
给定数据缓存单元的配置以及优化方法,PL 端的时钟频率为150 MHz,根据各模块延时表达式(3)和式(12),展示部分模块时延预估,选择图1 中Id =3 的Bottleneck 和shortcut 模块、SPP 中三个Max pooling 以及Upsample,如表4 所示,实际时延与预估时延的误差可能来自各模块的初始化延时以及BRAM 中数据读取和存储的延时。

表4 PL 端加速器部分模块时延 单位:ms
4.2 不同平台性能对比
将本文在不同的平台对同一目标检测网络YOLO-FASTEST 进行推理,对功耗、检测精度、计算性能、能耗比和单帧延时进行评估。在服务器端的CPU(I5-8300H)以及GPU(GTX1050ti) 上使用Darknet 框架进行模型推理,数据类型为浮点数。在嵌入式端分为仅ARM-A9 推理以及ARM-A9+FPGA联合推理,数据类型为16 位定点数。
结果如表5 所示,检测精度方面,在PSCAL VOC 2017 的数据集上,嵌入式端数据量化后的检测精度相比服务器端的检测精度仅降低1.3%。在性能表现方面,嵌入式端的功耗要远低于服务器端,但是仅ARM9 推理模型的单帧延时较高,无法满足目标检测实时性的需要。本文设计的ARM-A9+FPGA的推理框架,能耗比达到5.27 GFLOPS/W,约为嵌入式端ARM-A9 的48 倍,服务器端CPU 的55 倍,GPU 的20 倍。单帧延时为163 ms,满足目标检测的实时性。

表5 不同平台的参数对比
将本文的设计与前人的工作进行对比,如表6 所示,文献[12]提出的体系结构侧重于最大限度地提高系统的吞吐量,因此,网络的每一层都映射到一个专用的硬件块。特征图、权重、偏置都存储在片上缓存中,以尽量减少片外的数据传输延时,取得了极高计算性能。但其对片上存储资源的要求较高且可重构性较差。文献[14]使用了通用矩阵乘法来加速卷积层,需将输入特征图转换为通用矩阵的形式,此过程需消耗较多的BRAM 与DSP 资源。文献[15]使用层间流水的方式,内部硬件控制器使卷积层的数据流直接与池化层进行连接,可降低数据与片外存储传输的次数。这种方法的卷积计算使用的是滑动窗口的方式,且仅适合卷积层后紧跟池化层的情况。
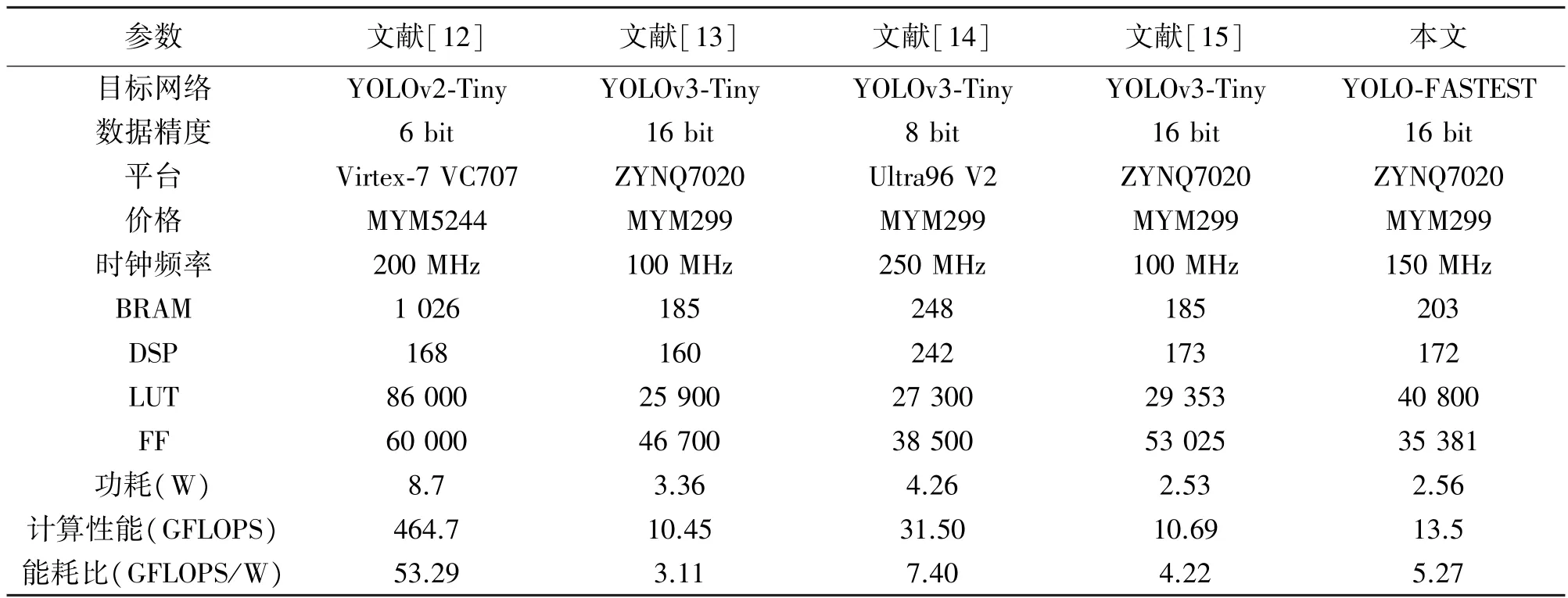
表6 与文献设计的系统对比
5 总结
本文提出一种将目标检测网络YOLO-FASTEST在低成本的异构计算平台上运行推理的方法。针对网络结构中的Bottleneck 模块,本文使用特征图复用的运算模式,降低多层片上流水延时。同时本文建立数据单元和计算单元与PL 端的资源约束关系式,使设计方案满足低成本计算平台的资源约束。设计的系统根据参数调节可移植至任意资源的FPGA 计算平台。未来的改进工作将集中在算法加速方面,例如使用Winograd 快速矩阵乘法对3×3 大小的卷积层进行加速。
猜你喜欢
意林(2023年7期)2023-06-13
昆钢科技(2022年4期)2022-12-30
北京航空航天大学学报(2021年9期)2021-11-02
昆钢科技(2021年6期)2021-03-09
自动化仪表(2020年10期)2020-11-13
电子制作(2019年11期)2019-07-04
小学科学(学生版)(2019年4期)2019-05-11
北京航空航天大学学报(2018年1期)2018-04-20
船舶力学(2015年6期)2015-12-12
电视技术(2014年19期)2014-03-11
