
基于多粒度标签扰动的文本分类研究
2024-01-27 13:40姚汝婧王芳
现代情报 2024年1期
姚汝婧 王芳






关键词: 文本分类; 深度学习; 标签扰动; 元学习; 多粒度
DOI:10.3969 / j.issn.1008-0821.2024.01.003
〔中图分类号〕TP391 〔文献标识码〕A 〔文章编号〕1008-0821 (2024) 01-0025-12
文本分类是信息组织和信息分析中的重要內容,其涉及的范围十分广泛, 不仅包括学术文献的分类任务, 如文献结构分类、引文情感分类、引文意图分类等, 也包含社交媒体信息分类、突发事件的识别与分类、政策文本分类等。随着文献数量的飞速增长, 对于学术文献相关内容的分类能够帮助学者在面对浩如烟海的文献资料时, 快速地识别出所需信息, 了解目标文献的研究内容与研究价值[1-2] 。政策文本分类能够帮助政府、高校、企业等高效地获取自身所需的科技政策[3] 。社交媒体信息分类能够帮助决策者快速了解公众的情感和观点, 并利用这些有价值的分类信息优化和改进现有的解决方案[4] 。突发事件的自动识别与分类能够从海量信息中快速获取有效信息, 并为应急管理机构提供帮助[5] 。
深度学习算法因其良好的特征表示能力, 逐渐成为了解决上述问题的首选方案。然而, 有监督的深度学习算法的训练依赖于训练数据, 一个大型高质量的训练样本集对能否有效训练深度学习算法几乎起着决定性作用。但是, 由于标注经验、主观性以及责任心等因素的影响, 人工标注的数据集不可避免地存在着噪声。如有研究表明图像分类中最为知名的大型数据集ImageNet 约包含了6%的噪声标签[6] , 而NER 领域应用最为广泛的数据集CoNLL-2003 也被发现约5%的标签错误存在于测试句中[7] 。可想而知, 对于深度学习任务所采用的非基准数据集, 其噪声标签比例极可能更高, 而这些噪声标签会对深度学习的模型训练造成负面影响。因此, 在文本分类研究中, 寻求有效的噪声标签学习方法也已经成为一个热点问题。
迄今为止, 研究者们已经提出了各种各样的噪声标签学习算法[8] , 通过降低噪声标签对模型训练的负面影响进而提升模型的性能, 基于标签扰动的算法就是其中一类典型的学习策略。顾名思义,标签扰动的目标是训练样本的标签, 即通过对一部分训练样本的标签添加扰动来减少噪声标签对模型造成的负面影响, 增强模型的鲁棒性。按照扰动粒度的不同, 标签扰动算法可以分为样本级粒度的扰动、类别级粒度的扰动、数据集级粒度的扰动。目前, 有3 种具有代表性的单一粒度的标签扰动算法:Label Smoothing(标签平滑)算法[9] 、Bootstrapping 算法[10] 、Online Label Smoothing(在线标签平滑) 算法[11] 。Label Smoothing 和Online Label Smoothing 为类别级粒度的标签扰动算法, Bootstrapping 为样本级粒度的标签扰动算法。
多项研究表明, 不同粒度的标签扰动算法都能有效地提升模型性能, 然而, 现有的算法大多是从同一粒度下的深入探索, 缺乏对不同粒度信息的有效利用, 而不同级别的粒度信息能够进行互补从而提高模型的性能。基于此, 本文首先分析了LabelSmoothing、Bootstrapping、Online Label Smoothing 3种单粒度的标签扰动算法如何具体地对学习过程起着调节作用。然后, 提出了一种多粒度的标签扰动算法(Multi-granularity Label Perturbation, MGLP),该算法通过加权的方式将前述的3 种单粒度的标签扰动算法融合在一起。随着融合权重取值的不同,本文提出的MGLP 算法可以简化为3 种扰动方式中的任意一种或者两种的组合。对于融合权重, 本文采用元学习的思想对其进行学习, 使之能够根据不同的数据特点自适应地进行调整, 减轻了人工调参的负担, 并减少了主观性偏差对结果造成的负面影响。最后, 本文将提出的MGLP 算法应用在推文情感分类、电影评论情感分类、引文意图分类3 个文本分类数据集上, 通过施加不同类型噪声的方式验证算法的性能, 实验结果表明本文提出的MGLP算法有效地提升了深度学习算法在文本分类任务上的准确性, 对于深度学习算法更准确地在信息组织和信息分析领域的应用具有十分重要的价值和意义。
1 相关研究
1.1 文本分类
文本分类在信息组织和信息分析中发挥着日益重要的作用。早期的文本分类利用信息增益[12] 、互信息[13] 或者主题模型[14] 等提取特征, 然后利用浅层分类器进行分类。近年来, 以词向量为基础的分布表示和以LSTM[15] 、Transformer[16] 等为代表的深度学习算法逐步取代了早期文本分类的方法。如BERT、ERNIE 等模型被用来对文献的学科进行分类[17] 。基于SciBert 的模型被用于学术文献致谢的识别[18] 。融合多种特征的深度学习模型可以较好地实现对评论中的用户意见的分类[19] 。除了在上述文本分类任务上以外, 深度学习算法也广泛地应用在突发事件的识别与分类任务以及政策文本分类方面。吴雪华等[5] 提出了一个两阶段的突发事件应急行动支撑信息的识别与分类框架, 且利用SVM、LR、TextCNN 以及BERT 等算法进行实验来验证其性能。一种BERT 与多尺度CNN 融合的算法被提出且用来捕获科技政策文本的特征信息, 对政策文本的主题进行分类[20] 。深度学习算法具有较强的特征表示能力, 被广泛应用于各种文本分类任务,且使得文本分类任务的准确性有了进一步的提高。
除了词汇的分布表示、更为有效的深度学习网络架构等研究之外, 针对训练数据的不完美特点设计有效的学习策略, 如噪声标签、类别不平衡等问题, 也是文本分类领域的研究重点。针对类别不平衡问题, 研究者们提出了多种解决方案。Zong D等[21] 设计了一个双通道的学习策略来解决文本分类中的长尾分布问题。卢小宾等[22] 提出了综合数据、算法、评估3 个层面的优化框架以解决新兴技术识别中的数据类别不平衡问题。为了更好地处理虚假评论识别任务, 一种基于类别可分性计算的代价敏感学习方法被提出[23] 。基于类别先验Mixup数据增强策略被用来解决罪名分类任务中的不平衡问题[24] 。此外, 元学习和小样本学习等方法也被引入来处理数据中存在问题。一种在不平衡少样本情况下基于元学习的文本分类模型被提出[25] 。小样本数据增强技术被用于对科技文档的不平衡分类问题进行解决[26] 。通过对上述研究的总结和分析发现, 文本分类在信息组织和信息分析中发挥着越来越重要的作用。此外, 针对数据的不完美特点探讨有效的学习策略逐步成为研究的热点。
1.2 噪声标签学习
在文本分类任务中, 基于浅层机器学习和深度学习的算法逐渐成为主要方法, 而在算法的训练过程中, 训练数据中存在的噪声标签会对算法的训练造成负面影响, 比如容易导致所学习到的模型产生过拟合等问题, 因此, 噪声标签学习逐渐成为一个重点的研究方向。在浅层机器学习时代, 噪聲标签学习就是一个极受关注的研究问题。如经典的支持向量机算法[27] , 所引入的松弛变量的一大动机就是抑制噪声标签的不利影响。相对于浅层学习时代相对规模较小的训练数据, 深度学习的训练对人工标注的数据集规模有着更高的要求, 不可避免地会进一步带来噪声标签问题。
目前解决噪声标签问题的途径主要有两种, 一种是对噪声标签样本进行离线检测, 另一种是基于噪声标签样本进行在线检测。离线检测的方法主要利用损失[28] 、交叉验证错误率[7] 、几何边界距离[29]等量化指标来区分正常标签样本与噪声标签样本。如置信学习被用来对样本集进行清洗, 降低噪声数据对模型的负面影响, 进而有效地提升了模型的性能[30] 。为了检测命名实体识别任务中的噪声样本,一种基于交叉验证的方式被提出来计算每个样本的预测正确率[7] 。该正确率越小那么该样本更可能是噪声样本, 然后将正确率作为样本权重重新进行训练。此外, 汪敏等[31] 提出了一种噪声识别与纠正算法, 通过筛选可信样本对样本标签的置信度进行预测, 然后识别噪声标签, 对噪声标签进行纠正。Huang J 等[32] 提出了一个基于过拟合—欠拟合过程的策略来识别噪声样本。对噪声标签样本的离线检测方法的主要缺陷在于通常需要增加大量的训练时间, 为此, 研究者们开发出了基于噪声标签样本的在线检测途径。
基于噪声标签样本的在线检测方法隐式地降低噪声标签的不利影响, 基于标签扰动的方法就是其中一类典型的学习策略。许多基于噪声标签学习的深度学习算法, 甚至其一些研究分支, 本质上都可以归结为对训练数据的扰动。如当前深度学习中的热点研究方向: 对抗攻击[33] 以及基于对抗攻击的对抗训练[34] 。对抗攻击的根本性问题就是寻求一个满足特定目标的样本扰动并叠加到输入样本上。从数据对象上看, 现有的方法可以分为特征扰动、逻辑向量扰动以及标签扰动等几大类别。对抗攻击可以看作是特征扰动。此外, 近期一些代表性的研究从不同角度来提升算法的泛化性能, 如IS⁃DA[35] 、Logit Adjustment[36] 等在数学上都可以归结为逻辑向量扰动。Label Smoothing、Bootstrapping、Online Label Smoothing 可以归结为标签扰动。从扰动粒度上, 现有的方法可以分为训练集级别、类别级别以及样本级别。Label Smoothing 和Online LabelSmoothing 是类别级粒度的扰动, Bootstrapping 是样本级粒度的扰动。然而, 目前大多数研究通常在同一粒度下进行探索和创新, 极少有研究综合考虑利用不同粒度的有效信息, 而多种粒度信息的有效利用能够帮助模型更好地学习特征表示, 有利于提升模型的性能。基于此, 本文针对单一粒度的不足,探讨多种粒度级别下的标签扰动, 以期通过多粒度信息的有效利用提升模型的性能。
2 研究方法
本节首先对3 种单粒度的经典标签扰动算法进行了分析, 然后针对单粒度算法没有有效地利用不同粒度级别信息的缺陷, 提出了一种多粒度标签扰动算法。该算法综合考虑了样本级粒度和类别级粒度信息, 弥补了单粒度算法的不足。对于不同粒度信息的融合权重, 本文采用了元学习的思想对其进行学习, 使本文提出的方法能够根据不同的数据特点自适应地调整融合权重, 减少了人工调参的负担, 降低了主观因素对结果产生的不利影响。
2.2 多粒度标签扰动算法( Multi-granularity LabelPerturbation, MGLP)
2.2.1 MGLP算法设计
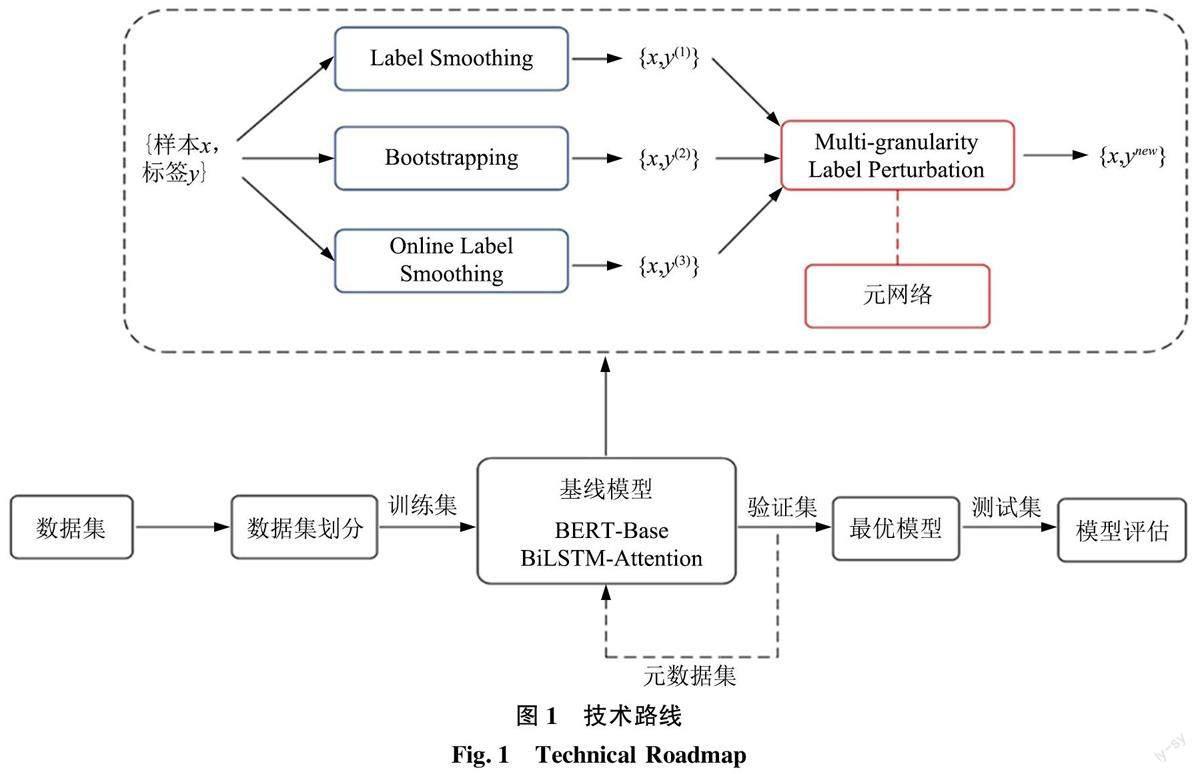
大量的理论和实验已经证明, 类别级的标签扰动和样本级的标签扰动对于解决噪声标签问题非常有效和高效。然而, 当前大部分研究都是在同一粒度下对算法的深入探索, 鲜有研究综合考虑利用这些不同粒度的标签扰动策略提升模型的性能, 而不同粒度的扰动能够从不同的角度对算法性能进行补充。基于此, 本文提出了一种多粒度标签扰动算法(Multi-granularity Label Perturbation, MGLP), 该算法对Label Smoothing、Bootstrapping、Online La⁃bel Smoothing 3 种单粒度的标签扰动策略进行了集成, 综合考虑了样本级粒度和类别级粒度的扰动。同时, 利用元学习的思想对3 种标签扰动策略的融合系数进行学习, 技术路线如图1 所示。由于在文本分类任务中, BERT 和BiLSTM 具有良好的特征表示能力[37,17] , 因此, 为了全面地验证本文所提出的算法的性能, 本研究分别利用BERT-Base 和BiLSTM-Attention 作为基线模型进行实验。
3 实验
3.1数据
为了充分地验证本文所提出的MGLP 算法的性能, 选择3 个知名的国际公开的英文文本分类数据集进行实验: SemEval-2016 Task 4 Subtask A[40] 、Movie Reviews(MR)[41] 和SciCite[42] 。第一个数据集来自于SemEval-2016 的任务4 的子任务A, 是推文情感分类数据集, 包含正面情感、中性情感、负面情感3 种类型, 本文采用官方给定的训练集、验证集和测试集的划分。第二个数据集是MR 数据集, 其为一个电影评论情感分类数据集, 包含正面情感和负面情感两种类型的标签, 由于官方数据未划分训练集、验证集和测试集, 因此, 本文按照7 ∶1∶2 的比例将MR 数据集划分为训练集、验证集、测试集。SciCite 是一个引文意图分类数据集, 包含背景、方法和结果3 种类型, 本文采用该数据集官方给定的训练集、验证集和测试集的划分。
3.2 对比算法及参数设置
为了有效地验证本文提出的MGLP 算法的性能, 采用以下几种经典的以及最先进的噪声标签处理算法进行对比: Label Smoothing[9] 、Soft/ HardBootstrapping[10] 、Online Label Smoothing[11] 、Self-Distillation from Last Mini-Batch(DLB)[43] 、MarginbasedLabel Smoothing(MbLS)[44] 。本文在原始数据集的基础上施加了两种类型的噪声, 一种是对称噪声, 一种是非对称噪声[8] 。对称噪声指的是样本的真实标签以相同的概率随机翻转成其他类别标签, 非对称噪声指的是样本的真实标签被翻转成某类特定的标签, 本文设置的样本的真实标签翻转比例(即噪声比例)为10%、20%、30%。
对于本文采用的BERT-Base, 其有12 层Trans⁃former 结构, 隐藏层维度为768, 学习率设为2e-5, epoch 设为10。对于BiLSTM-Attention, 本文采用300 维的Glove 词向量, 隐藏层维度设为300,epoch 设为50。对于Label Smoothing、Soft Bootstrap⁃ping、Hard Bootstrapping、Online Label Smoothing、DLB、MbLS 等对比算法, 按照其对应的原论文的设置进行实验。在MGLP 算法中, 本文随机选取验证集中的每类样本100 个作为元数据集。
3.3 实验结果
表1 为基线模型为BERT-Base 时不同噪声标签处理算法在3 种不同数据集上的实验结果, 表2为基线模型为BiLSTM-Attention 时不同噪声标签处理算法在3 种不同数据集上的实验结果。采用分类任务中常用的准确率作为评价指标, 每个实验进行3 次取其平均值作为最终结果。
通过表1 的实验结果, 可以看出本文提出的MGLP 算法以BERT-Base 为基线模型时, 在3 种数据集上都取得了最佳结果。
具体来说, 在SemEval-2016 数据集上, 不添加噪声的情况下, MGLP 算法相比于基线模型BERTBase提高了2.02%。相比于单粒度的Label Smoot⁃hing、Soft Bootstrapping、Hard Bootstrapping、On⁃line Label Smoothing 算法, MGLP 算法分别提升了1.35%、1.97%、0.92%、1.40%。说明MGLP 算法充分利用了样本级粒度和类别级粒度的信息, 结合了Label Smoothing、Bootstrapping、Online Label Smoot⁃hing 3 种经典的单粒度噪声标签算法的优势。在施加噪声的情况下, 相比于近年来的MbLS 算法, 本文提出的MGLP 算法平均提升了1.57%, 并且在施加20%對称噪声的情况下, 准确率高于MbLS 算法2.35%。在施加30%对称噪声时, 对比算法中准确率最高的为MbLS 算法, 而本文提出的MGLP算法的准确率相比于MbLS 算法提升了2.08%, 且相比于基线模型BERT-Base 算法提升了6.37%,具有明显的性能优势。在MR 数据集上, 在不添加噪声的情况下, MGLP 相对于基线模型BERT-Base提升了1.05%。在施加噪声的情况下, 相比于经典的Label Smoothing、Soft Bootstrapping、Hard Boot⁃strapping、Online Label Smoothing 算法, MGLP 算法分别平均提升了1.11%、1.39%、1.16%、1.12%。施加30%对称噪声和30%非对称噪声时, MGLP 算法相比于对比算法中准确率最高的MbLS 算法分别提升了1.66%和1.11%, 取得了最佳结果。在SciC⁃ite 数据集上, 不添加噪声的情况下, MGLP 相对于基线模型BERT-Base 提升了1.06%, 相比于对比算法中准确率最高的Online Label Smoothing 提升了0.70%。在施加噪声20%对称噪声的情况下,相比于对比算法中准确率最高的MbLS 算法提升了0.86%, 实现了最优性能。以上结果表明MGLP 算法能够充分利用不同粒度的数据信息, 减少噪声标签对模型性能产生的负面影响, 使模型的性能具有明显的提升。
通过表2 可知, 以BiLSTM-Attention 为基线模型时, MGLP 算法在3 个数据集上也都实现了最优的性能。
在SemEval-2016 数据集上, MGLP 算法在不施加噪声的情况下相比于基线模型提升了1.10%,相比于准确率最高的MbLS 算法提升了0.73%。在SemEval- 2016 数据集施加对称噪声的情况下,MGLP 算法相比于基线模型平均提升了1.75%; 在施加非对称噪声的情况下, MGLP 算法相比于基线模型平均提升了2.04%, 相比于近年来的DLB 算法和MbLS 算法, MGLP 算法分别平均提升了1.18%、1.08%。在施加20%对称噪声时, MGLP 算法相比于对比算法中准确率最高的MbLS 算法提升了1.46%。在MR 数据集上, 相比于经典的Label Smoot⁃hing、Soft Bootstrapping、Hard Bootstrapping、OnlineLabel Smoothing 算法, MGLP 算法平均提升了1.45%、1.02%、1.19%、1.37%。在施加10%对称噪声的情况下, MGLP 算法相比于对比算法中准确率最高的Soft Bootstrapping 算法提升了1.02%, 实现了最佳性能。此外, 在MR 数据集施加30%非对称噪声的情况下, MGLP 算法相比于基线模型提升了4.48%。在SciCite 数据集上, MGLP 算法准确率也是最高的, 相比于BiLSTM-Attention 基线模型平均提升了1.40%。在SciCite 上施加30%对称噪声的情况下, MGLP 算法相比于Label Smoothing、Soft Bootstrapping、Hard Bootstrapping、Online LabelSmoothing、DLB、MbLS 算法分别提升了1.47%、1.56%、1.32%、1.28%、1.34%、1.21%。此外,在施加20%非对称噪声时, 对比算法中准确率最高的为MbLS 算法, 本文提出的MGLP 算法相比于MbLS 算法提升了1.07%, 取得了最优结果。以上实验结果均表明, MGLP 算法充分利用了3 种经典的单粒度的噪声标签算法的优势, 融合了样本级粒度和类别级粒度的数据信息, 提升了深度学习模型的性能。在模型进行学习的过程中, MGLP 算法能够根据不同数据的特点, 自适应地选取不同的比例对样本级粒度和类别级粒度的数据信息进行融合,从而减少噪声样本对模型训练产生的负面影响。实验结果表明, 不管是在原始数据集上还是在施加噪声的情况下, MGLP 算法均有效且明显地提升了深度学习模型的性能。
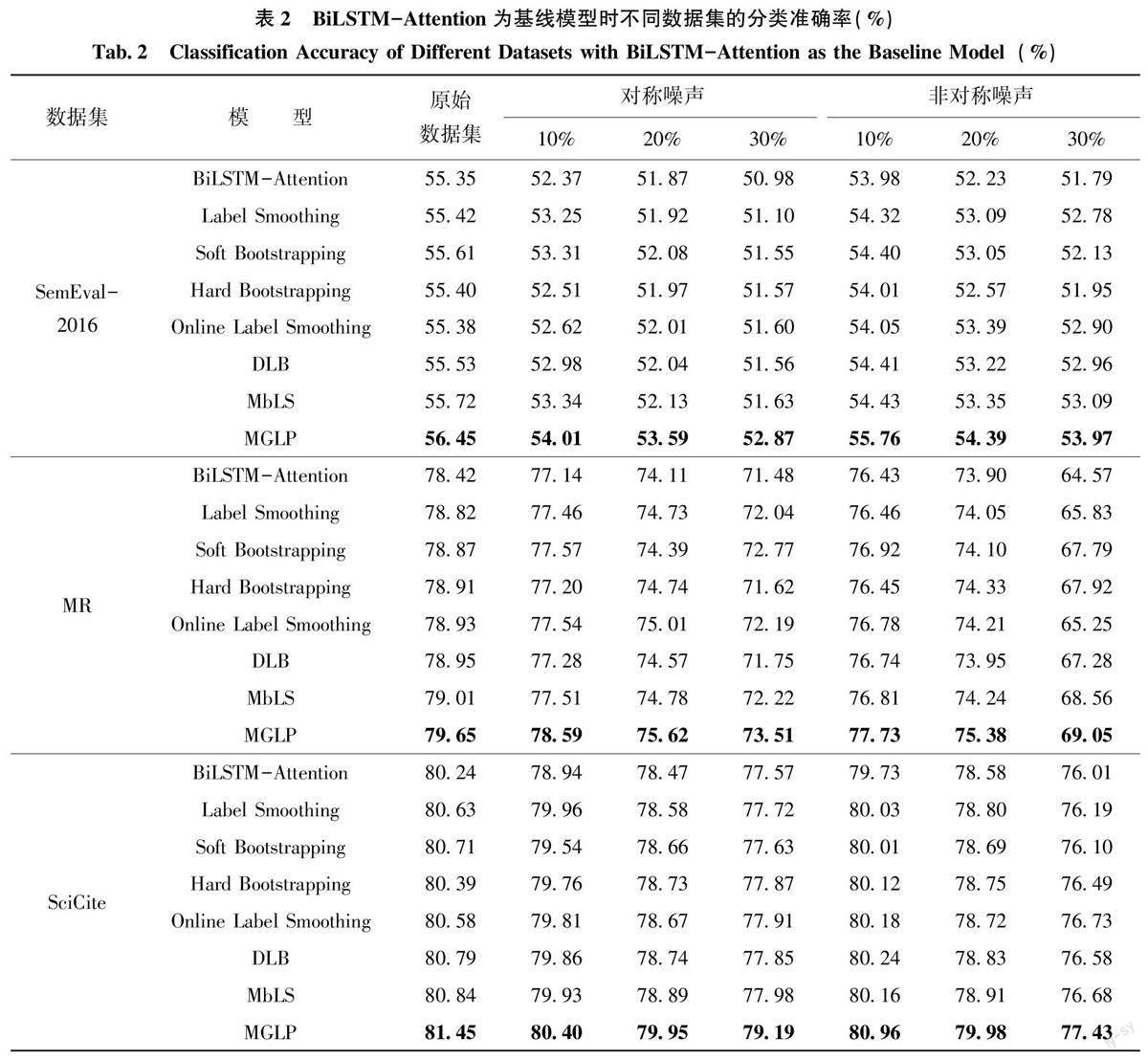
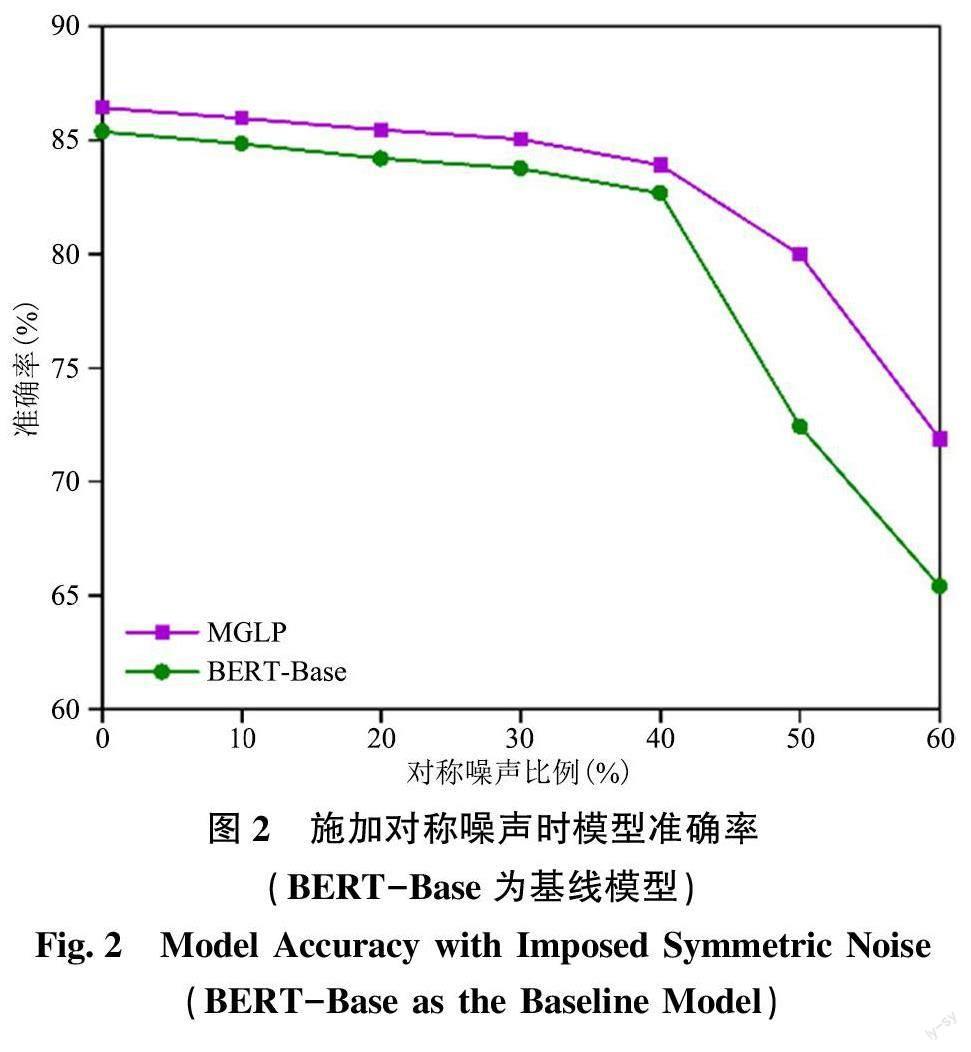
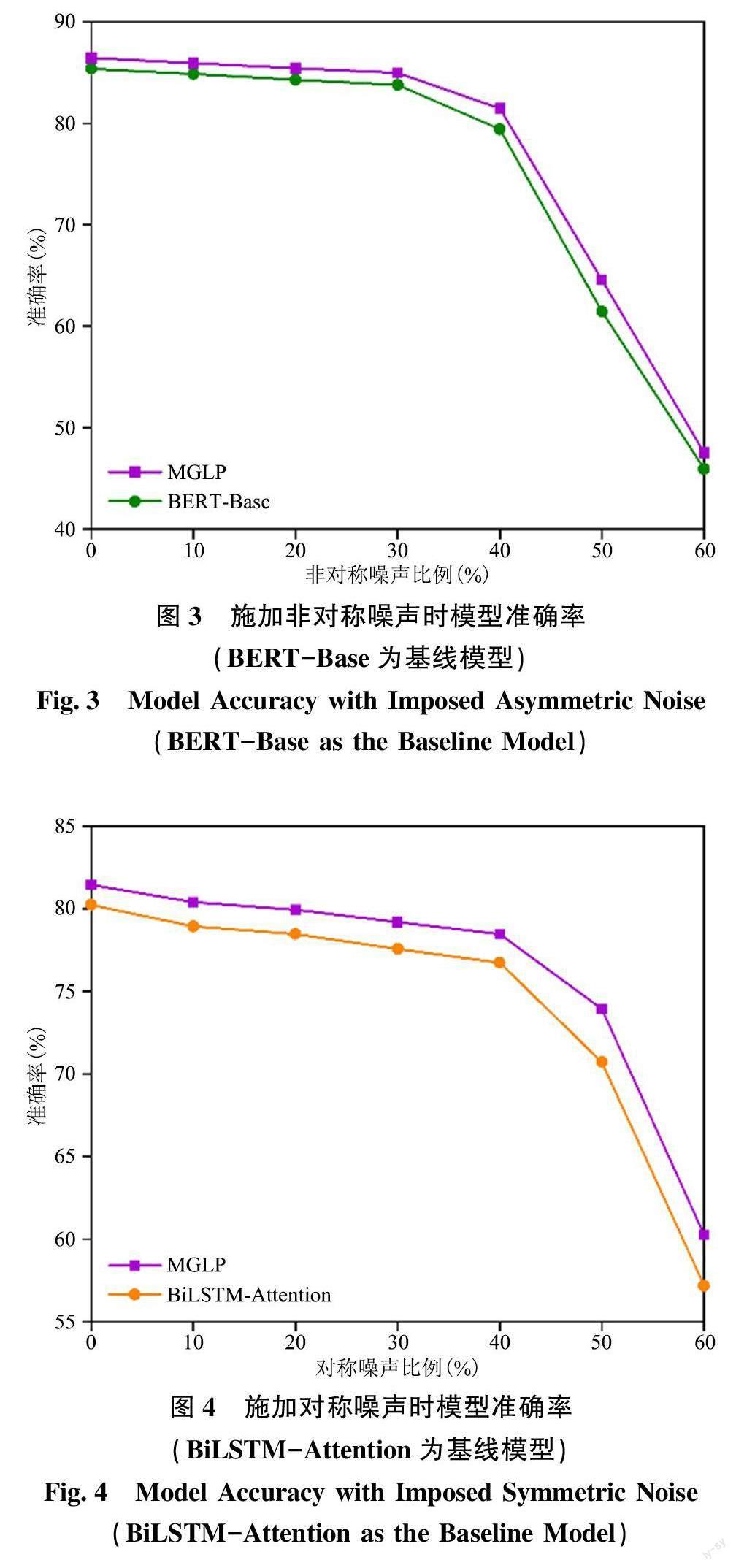
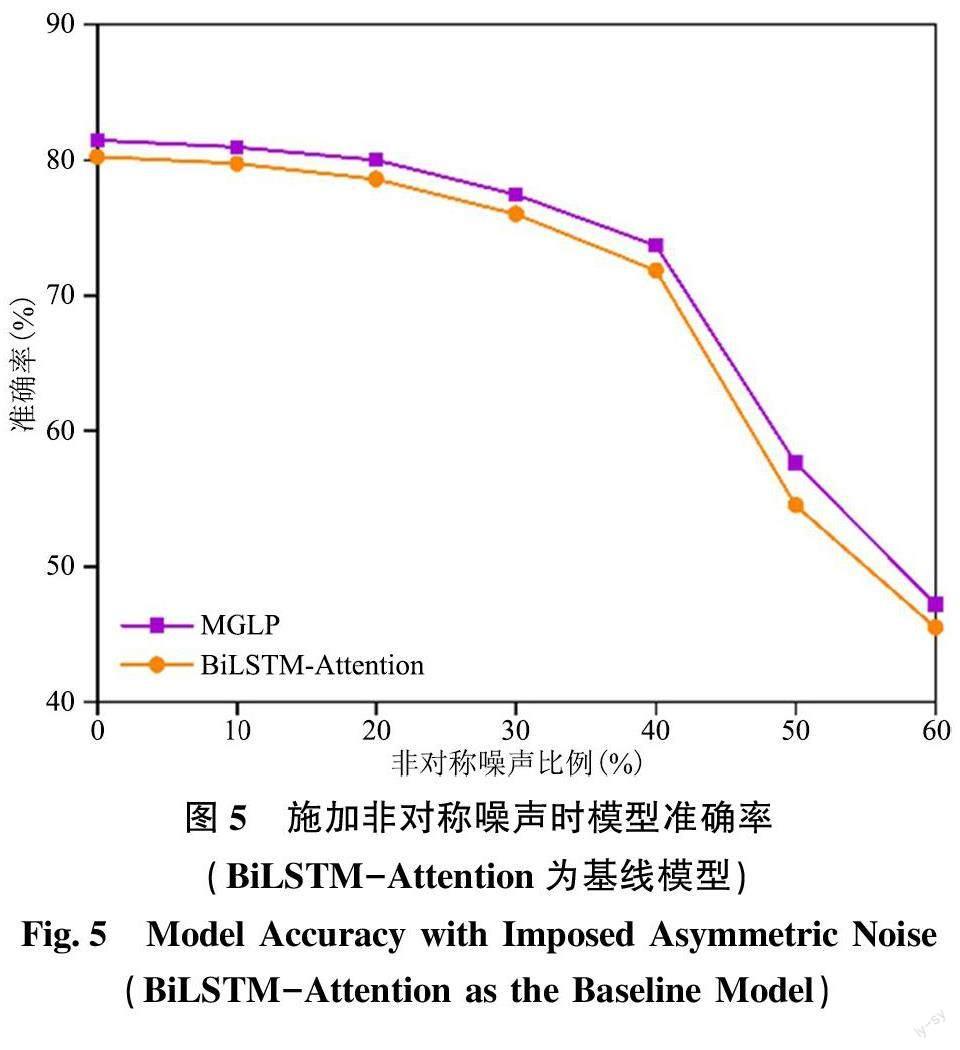
为了探究MGLP 算法的鲁棒性, 本文以SciCite数据集为例, 对更高比例噪声标签下算法的性能进行了评估, 结果如图2 ~ 图5 所示。在施加40%、50%、60%比例的对称噪声情况下, 本文提出的MGLP 算法相比于BERT-Base 和BiLSTM-Attention基线模型分别平均提升了5.09%、2.68%。在施加40%、50%、60%比例的非对称噪声情况下, MGLP算法相比于BERT-Base 和BiLSTM-Attention 基线模型分别平均提升了2.24%、2.22%。实验结果表明, 即使在施加更高比例噪声的情况下, 本文提出的MGLP 算法仍保持较高的准确率, 具有良好的鲁棒性。
4结语
本文针对现有的标签扰动算法大都只在单一粒度层级下进行深入探索, 而未有效利用多种粒度信息, 从而限制了算法的性能这一不足之处, 首先分析了Label Smoothing、Bootstrapping 和Online LabelSmoothing 3 种经典的单一粒度的标签扰动算法的原理, 然后提出了一种融合了样本级粒度和类别级粒度的多粒度标签扰动算法(MGLP)。该算法通过加权的方式将类别级的Label Smoothing 和Online La⁃bel Smoothing、样本级的Bootstrapping 3 种单粒度的标签扰动算法融合在一起, 集成了类别级粒度和样本级粒度的标签扰动算法的特点, 通过融合系数来控制不同粒度扰动的比例, 并利用元学习的思想对融合系数进行学习, 使其能够根据不同的数据特点自适应地对融合系数进行调整, 避免了人工调参所造成的主观性误差, 提高了模型的性能。本文在推文情感分类数据集、电影评论情感分类数据集、引文意图分类数据集3 个公开的文本数据集上进行了实验, 结果表明本文提出的MGLP 算法与其他算法相比性能有明显的提升, 能够有效地减轻噪声标签对深度学习模型训练的负面影响, 对于深度学习模型在信息组织和信息分析领域更准确地应用具有十分重要的价值和前景。
本文也存在一些局限性。首先, 只考虑了利用样本级粒度和类别级粒度的數据信息, 还未研究与数据集级粒度信息的结合; 其次, 本文只在英文文本分类数据集上对算法的性能进行了验证。在未来研究中, 将探究如何将样本级、类别级以及数据集级粒度的信息进行融合, 以期进一步提高对多粒度信息的有效利用, 进一步提升深度学习模型的性能, 并将在中文数据集上对多粒度标签扰动算法的性能进行探究。此外, 还将探究利用更多的信息对融合系数进行求解。在算法未来的应用层面, 除了将本文提出的算法应用于文本分类领域之外, 还将探究其在更多领域中的应用, 如计算机视觉领域,以期在多个领域中发挥该算法的应用价值。
猜你喜欢
计算机应用(2016年12期)2017-01-13
江苏教育·中学教学版(2016年11期)2016-12-21
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
