
一种区分极化码编码的PDCCH帧和噪声帧的算法*
2024-01-24 07:44:24汪奕汝管鹏鑫王夏怡赵玉萍
电讯技术 2024年1期
汪奕汝,管鹏鑫,王夏怡,赵玉萍
(北京大学 电子学院,北京 100871)
0 引 言
2008年,Arikan[1]首次提出信道极化的概念,并在2009年提出了极化码的概念以及编码和解码方式。极化码是第一种在理论上被证明可以达到信道容量的码型,并且不存在错误平层现象。极化码不仅能在多种码长和码率下表现出优异的误码性能,还具有较低的编码和解码复杂度,从而得到了学术界和工业界的广泛关注和研究。得益于优异的性能,在第三代合作伙伴项目(The 3rd Generation Partnership Project,3GPP)标准化的进程中,极化码已经用作5G新空口标准增强型移动宽带场景控制信道的编码方案。极化码编码的主要思想是使用信道极化的方式使各子信道在编码后具有不同的可靠性。经过编码后,信道可靠性会趋于两极化,一些信道的容量趋向于1,而另一些信道的容量会趋向于0。在发送信息比特时,就可以选择在容量接近完美的信道上直接传输以逼近信道容量。目前,极化码的研究方向包括速率匹配、基于神经网络的译码算法等。
为了支持下行信道的数据传输,5G系统中使用极化码编码的物理下行控制信道(Physical Download Control Channel,PDCCH)来承载下行链路控制信息(Downlink-Control Information,DCI),如下行资源分配、上行授权、随机接入响应、上行功率控制命令、信令消息(如系统消息、寻呼消息等)的公共调度指令等[2]。由于用户设备(User Equipment,UE)端无法预先获得DCI的长度或位置,因此需要使用盲检的方法对接收的帧进行解码,从而识别发送到该特定UE的目标DCI[2]。目前已有的盲检技术分为单阶段盲检和两阶段盲检。
在接收端进行盲检测后,可以根据该UE段是否获得属于自己的控制信息帧来判断盲检的算法的性能。此时,接收端可能会发生两种情况:第一种是漏检的情况,相应的概率称为漏检率(Missed Detection Rate,MDR),即基站发送了针对该UE的控制信息,但是该UE没有检测到;第二种是虚警的情况,相应的概率称为虚警率(False Alarm Rate,FAR),即基站在当前阶段没有发送给该UE的控制指令帧,但是却出现该UE检测到任一控制指令的情况。
在实际场景中,由于时钟不同步和发送端复杂度限制等问题,UE由于无法预先判断接收帧是极化码字帧或是噪声帧,所以会采取将全部接收帧都进行极化码盲检的方法,从而使接收端开销过大[3]。
目前,为了区分噪声帧和极化码字帧,文献[4]基于传统的置信度传播(Belief-propagation,BP)极化码译码算法[5],提出了固定比特集检查的方法和判决向量重编码的方法,文献[6]提出了一种奇偶校验符合性的方法。由于都具有复杂度高的特性,不仅会使收端盲检能耗增加,也会使实际场景中的数据传输速率受到限制,无法适用于低时延系统。文献[7]提出了一种基于深度学习的解决方案,能够识别多种编码方案并在多径衰落等信道损耗仍具有鲁棒性。然而,该方案需要大量的数据进行训练,由于不同方案的码字具备不同的特性,训练过程难以收敛。文献[8]指出由于无线网络临时标识符引起的虚警更有可能会在高信噪比范围内发生,并导致网络状态异常,因此提出了一种基于汉明距离度量的新型虚警缓解方案。为了降低FAR,文献[9]通过研究接收信号的能量来预筛选误报,并检测出合法码字。然而,如何降低MDR仍然需要进一步研究。
针对上述文献研究存在的问题,本文提出了一种区分极化编码的PDCCH帧和噪声帧的算法,能够在盲检前排除一定数量的噪声帧,从而降低UE端的盲检译码能耗。
1 传统的区分极化码字帧和噪声帧的方法
由于时钟不同步和发送端复杂度限制等问题,UE由于无法预先判断接收帧是极化码字帧或是无数据发送的噪声帧,所以会采取将全部接收帧都进行译码盲检的方法,从而使接收端开销过大。若在盲检前能剔除一定数量的噪声帧,会降低后续的译码开销。
基于BP的极化码译码算法,目前有两类方法可以实现噪声帧和极化码编码的PDCCH帧的区分[4]。
1.1 固定比特集检查的方法
在极化码的编码过程中,通常将固定比特集设定为全0向量。在此基础上,当BP译码算法收敛时,更多的固定比特对应的节点在译码时,对数似然比(Log-Likelihood Ratio,LLR)值应趋向非负。根据这种特性,传统的固定比特集检查的方法定义如下指标对极化码字帧和噪声帧进行区分:
(1)
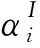
1.2 判决向量重编码的方法
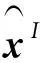
(2)
式中:G为极化编码矩阵。因此,判决向量重编码的方法提出了如下的指标以区分极化码字帧和噪声帧:
(3)
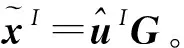
2 基于阈值检验区分极化码字帧和噪声帧的方法
传统的基于BP解码算法在区分噪声帧和PDCCH帧时需要多次解码迭代,第1节中两种算法的译码复杂度与迭代次数成正比。为保证要实现相同的误帧率,那么BP解码的算法复杂度和译码时延远高于连续消除(Successive Cancellation,SC)译码[1]。
在实际场景中,若接收端要求达到较低的误帧率,以上两种基于BP译码的区分噪声帧和极化编码的PDCCH帧的方法就需要较高的复杂度,这样会增加收端译码能耗,且限制实际场景中的数据传输速率,无法适用于低时延系统的需要。
本文提出的基于阈值检验区分极化码字帧和噪声帧的方法是基于节点在进行SC译码表现出的数值特性,因此,本节首先简要介绍SC译码流程,在此基础上介绍本文提出的阈值检验方法。
2.1 SC译码流程概述
SC译码算法的复杂度与编码复杂度相同,为O(NlbN),N为码长。
在极化码编码后,极化子信道的转移概率可以表示为
(4)
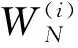
用N表示码字长度,K表示信息比特的长度,A表示信息比特对应的子信道集合,AC表示传输固定比特对应的子信道集合,uAC表示固定比特的取值,编码后的码字可以由(N,K,A,uAC)决定。译码器在比特判决时遵循以下判决准则:
(5)
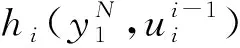
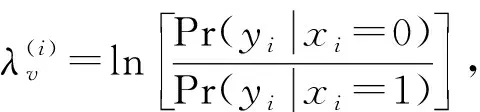
(6)

(7)
(8)
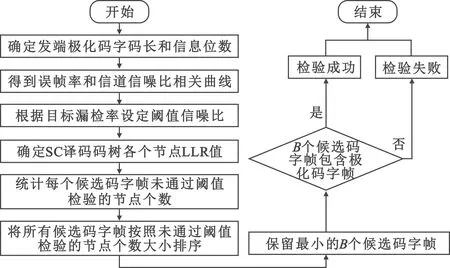
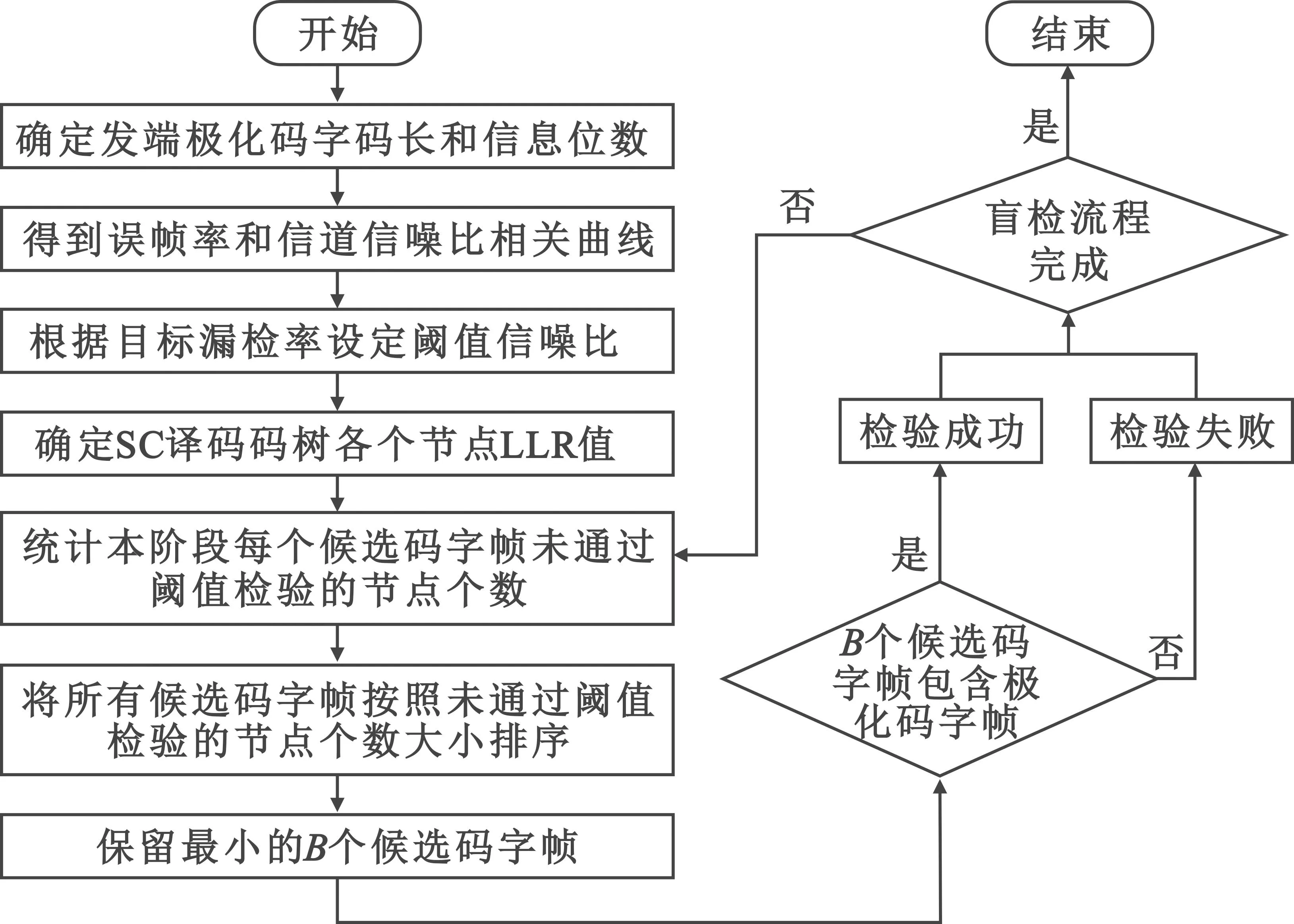
2.2 阈值检验的区分方法
由于发端信号经过了信道极化和噪声的作用,收端接收到的极化码字各个节点呈现出不同的硬判可靠度。当收端采用SC译码时,根据LLR的定义,各个节点的硬判错误概率与节点LLR的绝对值成反比,可以表示为
(9)

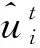
P(λvi<-Ti)P(βvi=0)+P(λvi>-Ti)P(βvi=1)
(10)
P(λvi<-Ti)
(11)
如果将硬判错误率限制在一定的数值内,即
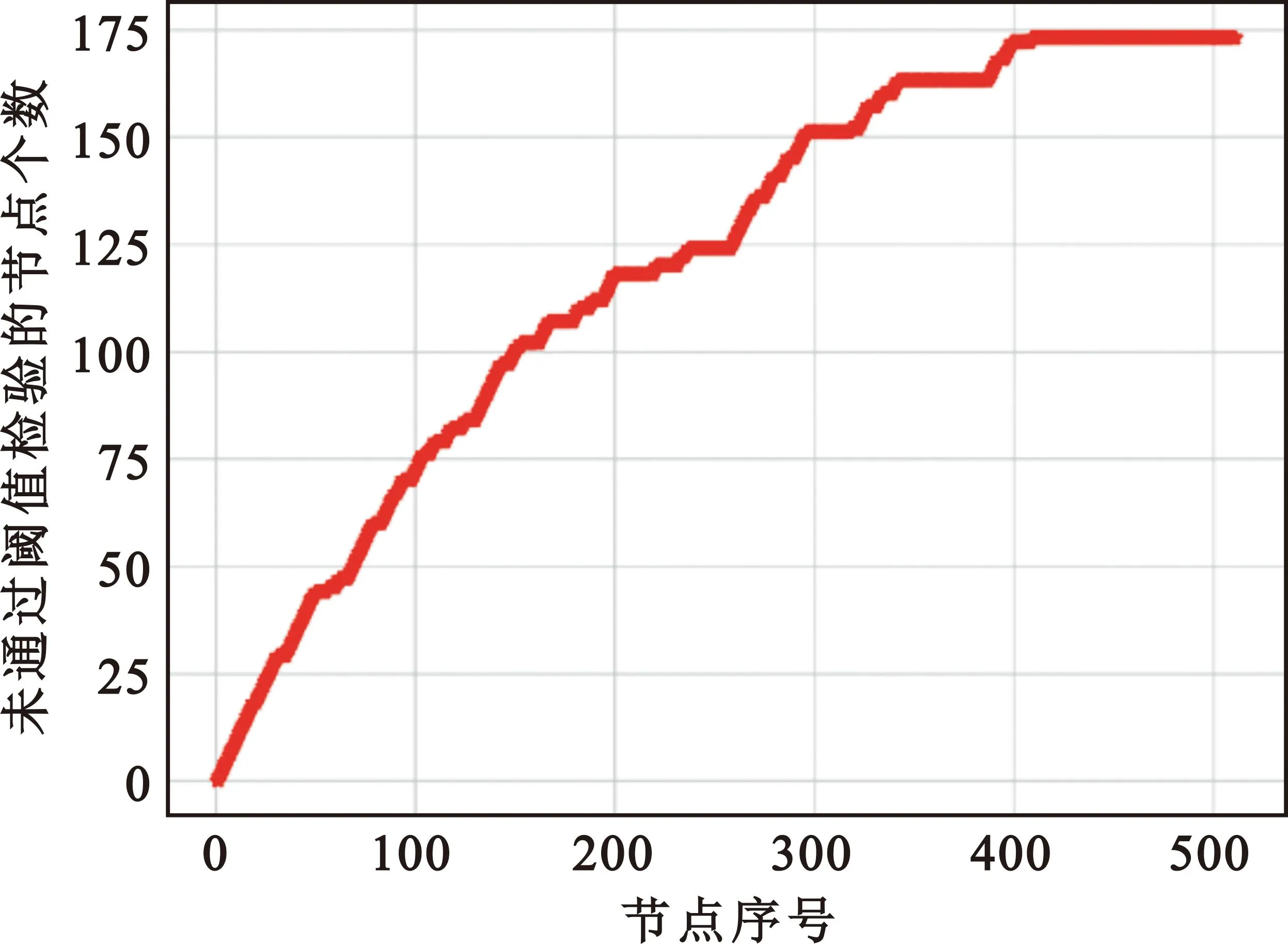
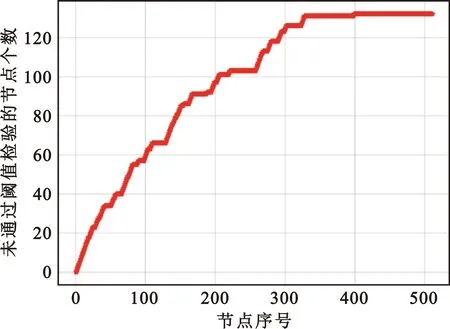
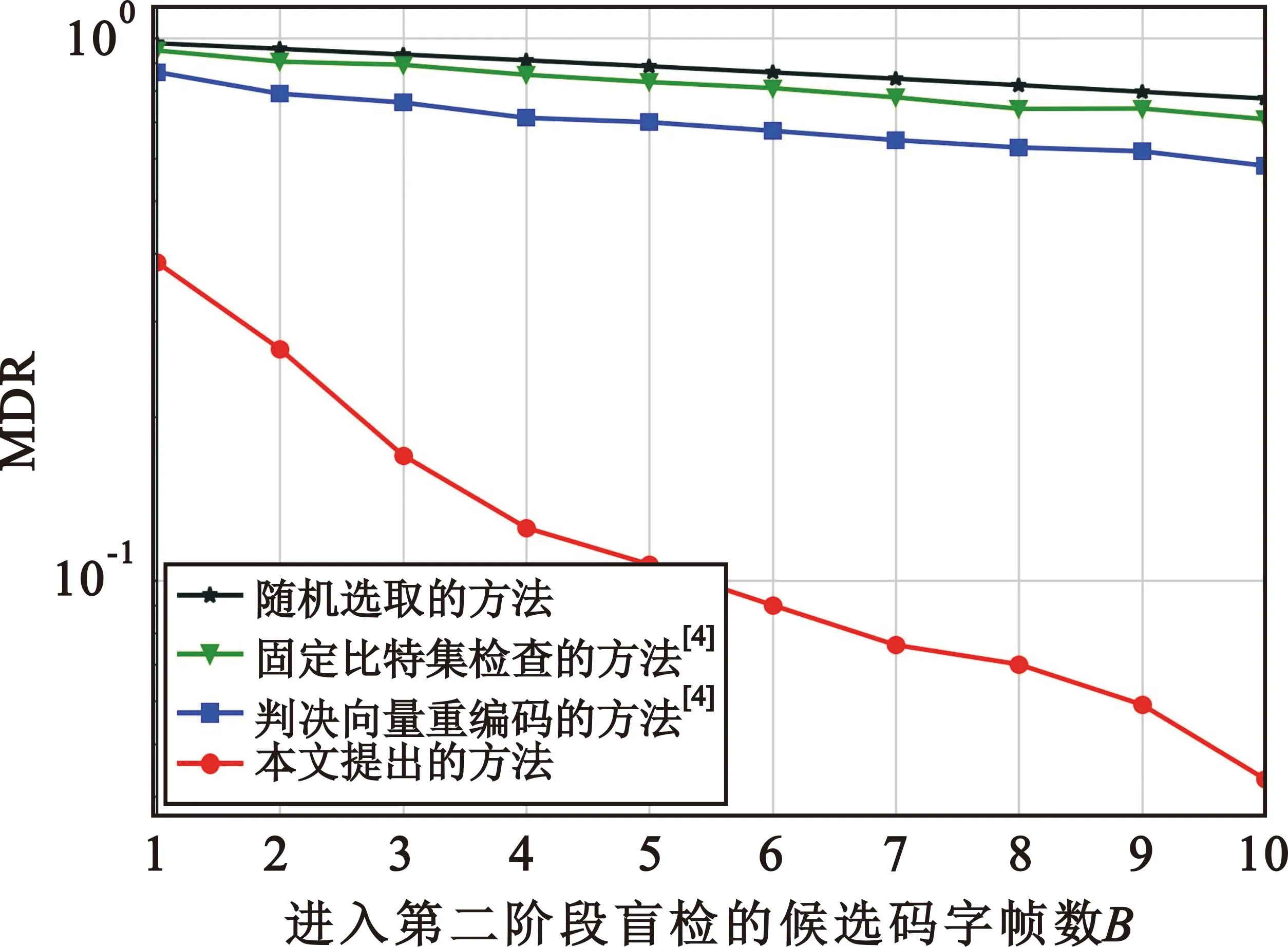
P(λvi<-Ti)=P(zi (12) (13) 因此,可得此时的阈值应设定为 (14) 这样,在UE端盲检之前,阈值检验的区分方法就能实现在SC译码算法同时统计每个候选码字帧在译码时未通过阈值检验的节点个数。与文献[4]类似,本方法能够实现在统计特征上区分极化码编码的PDCCH帧和噪声帧。根据实际UE端的算法复杂度和盲检精度的需求,当译码结束后,对所有帧未通过阈值检验的节点个数由小到大进行排序,选取最小的B个帧进入后续的译码盲检。B值越大,则剔除的噪声帧越少,漏检率越低,但会导致UE端后续盲检复杂度越大。若UE端要求较低的漏检率并可容忍较高的算法复杂度,则将B设为较大值;反之,将B设为较小值。 本文提出的阈值检验流程如图1所示。 图1 阈值盲检流程Fig.1 Flowchart of threshold blind test 图1为无反馈的阈值检验流程,此时UE端的检验性能完全由固定设置的B值决定,无法根据实时的需求进行调整,对应的阈值检验算法所需的时间复杂度近似可表示为O(NlbN)[10]。 若考虑实时的性能需求调整,可以在图1的阈值检验流程中引入反馈的环节,如图2所示。 图2 具有反馈的阈值盲检流程Fig.2 Flowchart of threshold blind test with feedback 实验设置发端发送10 000次,每次发送44个帧,其中只有一个是极化码码字帧,剩余43个帧都是纯噪声帧。信息比特经过极化码编码后进行二进制相移键控调制,送入高斯白噪声信道。为了充分验证本文所提算法的可行性,实验中分别采取码长N=512和N=256的极化码字帧进行测试。 实验基于图1的检验流程,收端UE采用本文所提出的阈值检验方法,之后选取B个候选码字帧。在进行后续盲检时,对所有的接收帧全部进行连续消除列表(Successive Cancellation List,SCL)译码[11],列表长度L=2。在每一个帧的SCL译码结束后,UE通过自己的无线网络临时识别符编码,可以实现循环冗余校验(Cyclic Redundancy Check,CRC)。一旦发现有一个帧的CRC校验通过,则认为此帧属于本UE,此时盲检结束;如果没有一个帧能够通过CRC,则该UE认为该时刻基站没有发送给自己的控制指令,该UE端盲检结束。 仿真时不考虑后续阶段的译码方式,仅度量算法挑选B个候选码字帧后MDR与B的变化情况。 为了展示本文提出的区分极化码编码的PDCCH帧和噪声帧算法的性能,下面将从译码过程中未通过阈值检验的节点个数的变化趋势和系统MDR两个方面进行分析。 图3和图4分别展示了在检验过程中噪声帧和经过极化码编码的PDCCH帧不通过本文提出的阈值检验节点的统计结果。本图对应的仿真设置中,极化码码长N=512,信息比特长度K=80。解调对应误块率值为10-2,即对应信噪比近似取为2.5 dB。根据对比可以看出,在统计结果上,噪声帧相较于极化码字帧具有更多不通过校验的节点个数,从而验证了本文提出的阈值检验方法的可行性。 图3 统计结果下噪声帧中未通过阈值检验的节点个数随节点序号增加的变化趋势Fig.3 Statistical trend of the count of nodes in noise frames failing the threshold test with increasing node numbers 图4 统计结果下极化码字帧中未通过阈值检验的节点个数随节点序号增加的变化趋势Fig.4 Statistical trend of the number of nodes in polar code frames failing the threshold test with increasing node indices 由于系统FAR主要由UE端译码能力决定,近似等于系统误块率[12],与能否在前期实现噪声帧的剔除关联较弱。但是系统的MDR与算法能否成功保留极化码编码的PDCCH帧有密切关系,若算法将PDCCH帧误判为噪声帧,导致该帧被错误剔除,则会显著影响UE端任务执行效率。因此,本节选取MDR作为衡量本算法与其他基准算法的指标。 本文的对比算法选取固定比特集检查的方法以及判决向量重编码的方法[4]。同时,本文考虑到公平性,限制两个对比算法与本算法复杂度保持相同,因此BP译码仅进行一次迭代。同时为了衡量三种算法的有效性,以随机选取的方法作为对照,该方法每次随机在接收帧中选取B个。 图5给出了MDR性能与选取的帧个数B之间的关系。本图对应的仿真设置中,极化码码长N=256,信息比特长度K=40,CRC比特长度m=16,对应净荷长度k=K-m=24。解调对应误块率值为10-2,即对应信噪比为4.25 dB。由图5可知,当B设置为1时,本文所提出的阈值盲检算法实现的MDR为38.6%,对比基于BP的两种传统的机制,可以将MDR减低约60%。此外,随着B的增加,精确限制放松,本文提出的算法使得MDR快速单调递减,这说明本文算法能够减轻LLR值重叠的影响,从而实现良好的区分极化码字帧和噪声帧的性能。当B取10时,本文提出的算法能达到MDR 4.3%的效果,相较于基于BP的固定比特集检查的方法,可以将MDR减低约94%,相较于基于BP的判决向量重编码的方法,可以将MDR减低约92%。 图5 MDR随进入第二阶段盲检的候选码字帧数B的变化趋势Fig.5 Trend of MDR with the variation in the number of candidate codeword frames B entering the second phase of blind testing 进一步分析图5可知,本文所提出的方法能在相同的复杂度限制下实现更低的MDR性能。此外,在保证低MDR的要求下,本文提出的算法可以显著减少进入后续盲检的候选码字帧数量,从而进一步降低后续盲检译码的复杂度。 在PDCCH盲检过程中,噪声帧的存在使得系统的译码时延和能耗均会增大。为了解决这个问题,本文提出了一种区分噪声帧和极化码编码的PDCCH帧的方案。数值仿真结果表明,在相同的MDR要求下,相比于现有的基于BP译码的固定比特集检查的方法和判决向量重编码的方法,本文所提出的方案能显著减少进入后续盲检译码的帧数量,从而降低盲检的复杂度。 在未来研究中,可以设计自适应的算法,根据信道条件和噪声水平来调整PDCCH盲检参数,从而满足不同条件下的应用场景。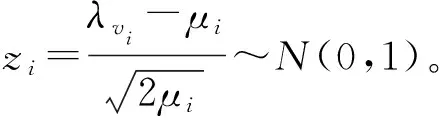
3 盲检流程概述
3.1 参数及流程设置
3.2 仿真结果与分析
4 结束语
猜你喜欢
现代计算机(2021年36期)2021-03-14 00:50:38
中国惯性技术学报(2019年6期)2019-03-04 09:50:10
扬子江诗刊(2018年1期)2018-11-13 12:23:04
舰船电子对抗(2018年3期)2018-08-28 02:02:56
扬子江(2018年1期)2018-01-26 02:04:06
中央民族大学学报(自然科学版)(2017年2期)2017-06-11 07:14:54
新闻传播(2016年3期)2016-07-12 12:55:27
火控雷达技术(2016年3期)2016-02-06 02:30:28
遥测遥控(2015年2期)2015-04-23 08:15:19
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01 02:54:43
