
基于深度强化学习的有源配电网实时电压控制策略
2024-01-22 11:43:34陈潇潇周云海张泰源郑培城
三峡大学学报(自然科学版) 2024年1期
陈潇潇 周云海 张泰源 郑培城
(三峡大学 电气与新能源学院, 湖北 宜昌 443002)
整县(市、区)屋顶分布式光伏政策和双碳战略使得我国能源体系结构逐步改变[1].国家能源局最新发布的数据显示,截至2023年上半年,全国光伏发电新增并网容量为78.423 GW,其中分布式光伏(distributed photovoltaic,DPV)新增并网容量为40.963 GW,同比增长108%[2].分布式光伏大规模接入配电网是发展趋势,但其接入改变了传统配电网潮流单向的模式[3],分布式光伏出力的随机性和波动性,会导致系统产生潮流倒送、电压波动及越限等电能质量问题,这严重影响配电网的安全稳定运行.
现有的配电网电压控制策略可分两类:无功控制和有功控制.无功电压控制中,有载调压器(on-line tap changer,OLTC)、投切电容器(switching capacitor,SC)等离散调节设备响应速度慢,且频繁动作会影响其使用寿命[4].静止无功补偿器(static var compensator,SVC)、静止无功发生器(static var generator,SVG)等连续调节设备响应速度快,但安装成本较高[5-6].有功电压控制中,削减光伏有功出力不利于新能源的消纳,而储能的运维费用较高[7].基于光伏逆变器的无功调节是一种关注最为广泛的调压方式[8],该方式能高效利用光伏逆变器的容量,响应速度快,且无需投资额外的设备.因此,本文选取光伏逆变器为电压控制设备,利用深度强化学习算法对配电网中的各光伏逆变器进行协同控制,实现对系统电压的实时控制.
下垂控制未考虑各逆变器的协同配合,难以实现全局优化控制;传统基于优化的方法[9],由于配电网精确的线路参数和拓扑结构难以获取,无法建立精确的数学模型,且存在求解速度慢、难以实时控制等问题[10].强化学习(reinforcement learning,RL)通过与环境的交互过程中学习最优策略,采用马尔科夫决策过程(Markov decision process,MDP)进行建模.深度强化学习(deep reinforcement learning,DRL)进一步融合深度学习的特征表示能力[11],具有更优秀的决策能力.
DRL 作为一种数据驱动的技术,近年在配电网电压控制领域得到广泛应用.文献[12]利用深度Q网络(deep Q network,DQN)算法控制系统中的SC,但该算法只能用于离散动作.文献[13]提出一种基于近端策略优化(proximal policy optimization,PPO)的配电网控制策略,该算法可用于连续动作,实验表明PPO 相较于DQN 有更好的控制效果,但传统策略梯度的算法数据利用率较低,为此有研究人员将动作-评论(actor-critic,AC)框架扩展到深度策略梯度的方法中,形成深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法.文献[14]提出一种双时间尺度配电网无功优化方法,采用DQN算法和DDPG 算法分别对SC、SVG 进行控制,但从控制架构来说依然属于单智能体结构,仍是将多个调节设备视作单个智能体,依然无法实现各个调节设备之间的协同控制.为此,文献[15]利用多智能体深度确定性策略梯度(multi-agent deep deterministic policy gradient,MADDPG)算法协同控制各调压设备,取得良好效果.但DDPG 和MADDPG 算法都存在Q值过估计的问题,文献[16]在DDPG 的基础上提出双延迟深度确定性策略梯度(twin delayed deep deterministic policy gradient,TD3PG)算法,引入3 种技术手段,提升算法的训练效果.文献[17]采用TD3PG 算法进行配电网电压控制,实验证明在无精确模型的情况下,该方法相比于传统基于优化的方法,控制效果更好、控制周期更短、鲁棒性更强,但该文采用的算法依然是单智能体结构.因此本文提出一种基于多智能体双延迟深度确定性策略梯度(multiagent twin delayed deep deterministic policy gradient,MATD3PG) 的有源配电网实时电压控制策略,其可以赋予各光伏逆变器独立决策的能力,提升系统的灵活性.首先,阐述MATD3PG 算法的框架及原理;其次,构建有源配电网实时电压控制物理模型,并将该物理模型转变为分散部分可观测的马尔科夫决策过程(decentralized partially observable Markov decision process,Dec-POMDP),通过MATD3PG 算法训练各智能体;最后,通过改进的IEEE-33节点算例验证本文所提控制策略的有效性,并证明MATD3PG 相较于下垂控制和MADDPG,在配电网电压控制问题上更有优势.
1 MATD3PG 算法的框架及原理
1.1 多智能体深度强化学习
RL 通过训练智能体(agent)与环境(environment)交互,强化学习模型中最关键的3个部分为:状态(state),动作(action),奖励(reward).一个经典的RL过程可以视为:智能体观察达到一个环境状态s t,执行一个动作a t后,环境反馈给它一个奖励r t与新的状态s t+1,然后智能体根据这个状态执行动作a t+1,获得r t+1与新的状态s t+2……以此类推,最终形成一个轨迹e t=(s t,a t,r t,s t+1),也称为马尔科夫链(Markov Chain)[18].DRL 在RL 的基础上又融合了深度学习,具有更强的的特征表示能力、更好的高维度空间处理能力.
多智能体深度强化学习(multi-agent deep reinforcement learning,MADRL)是指在DRL 框架下,多个智能体同时学习和交互的方法[19],其算法框架如图1所示.MADRL用于训练多个智能体在环境中进行协作或竞争的任务,每个智能体都具有自主决策能力,智能体之间通过共享经验、协同行动来提高整个系统的性能.
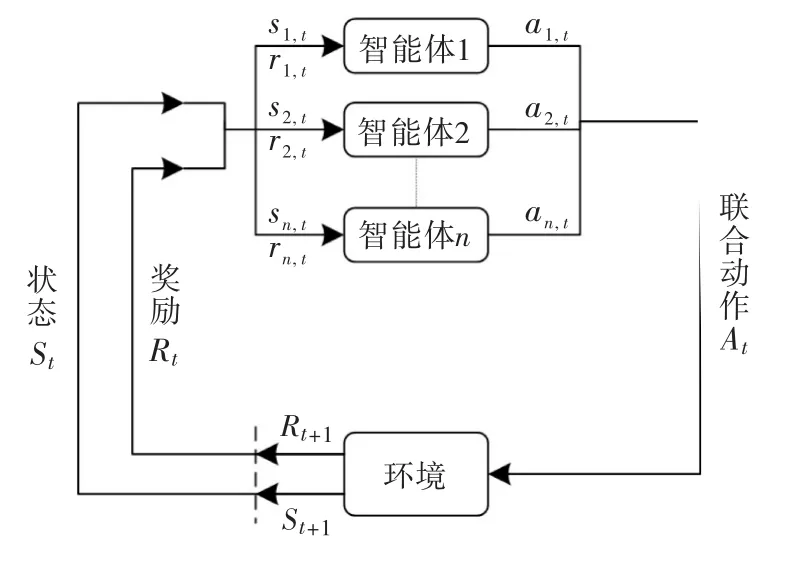
图1 多智能体深度强化学习框架
目前,多智能体深度强化学习方法可分为4类:独立学习、奖励分配、学习交流和集中式训练-分散式执行[20].本文的多智能体深度强化学习算法采用集中式训练-分散式执行机制,该机制将actor网络和critic网络中的信息差异化,actor网络仅有单个智能体的信息,而critic网络包含全部智能体的信息.集中式训练时,actor网络和critic相互辅助学习,训练得到集中式的critic网络;分散式执行时,利用训练好的critic网络,智能体仅需根据自身的局部观测信息就能完成决策.这种设计避免随智能体数量增长而导致的维度灾问题,保证每个智能体环境的平稳性,降低训练过程中的复杂度,从而提升训练效果.
1.2 双延迟深度确定性策略梯度算法
TD3PG 和DDPG 都是采用AC 结构、用于连续动作空间的DRL算法,此类算法包含动作网络actor和评论网络critic,actor负责根据当前策略选择动作,而critic则负责评估当前动作策略的价值,两个网络相互协作,通过正反馈过程进行更新,以优化动作策略和值函数.critic网络参数更新的方法为minLθ,Lθ见式(1);actor网络参数更新的方法为式(2),采用策略梯度更新.随着critic通过值函数评估的Q值越来越逼近目标值,actor的动作策略也趋于最优.
式中:θ为critic网络参数;φ为actor网络参数;r t为t时刻的奖励值;γ为折扣因子,通常为0.95~0.99;πφ(s t)为在状态s t下actor采取的动作;Qθ为价值函数;r t+γQθ[s t+1,πφ(s t+1)]为t时刻的目标Q值;Qθ(s t,a t)为t时刻的估计Q值;E为期望收益;E s~pπ为pπ状态分布下的期望收益.
TD3PG 是对DDPG 进行优化的算法,主要包括以下3个优化:
1)剪切双Q 学习(Clipped Double Q-Learning)
原始的双Q 学习,使用一对actor和critic,即(πφ1,πφ2)和(Qθ1,Qθ2),其 中πφ1利 用Qθ1进 行 优化,πφ2利用Qθ2进行优化.由于πφ1相对于Qθ1是最优的,因此在Qθ1的更新中使用独立的估计Q值可以避免actor动作策略更新带来的偏差.然而,由于它们在训练过程中使用了相同的经验池,critic并非完全独立.因此,对于某些状态s,会出现Qθ1[s,πφ(s)]>Qθ2[s,πφ(s)]的情况,因为Qθ1[s,πφ(s)]通常会高估真实值,并且在某些状态下,这种高估会进一步加大.因此,TD3PG 算法采用同一状态下Qθ1,Qθ2中较小的进行目标更新,其更新公式如下:
式中:y t为目标值函数;θ'n为目标critic网络参数;Qθ'为目标价值函数.n
2)目标网络及延迟策略更新(Target Networks and Delayed Policy Updates)
目标网络的引入提升了智能体训练过程中的稳定性,但当critic对Q值估计不精确时,actor会产生错误的动作,该动作会存放至经验池,由于是从经验池中随机采取一批样本用于critic网络更新,导致critic可能又产生错误的Q值,形成恶性循环.为此,TD3PG 算法延迟了actor的更新,令actor在critic估值偏差较低时再进行更新,提高了训练的稳定性.同时改进了目标critic网络更新,引入了软更新因子τ,因此也称为软更新,其更新公式如下:
3)目标策略平滑正则化(Target Policy Smoothing Regularization)
确定性策略的一个问题是,它们可能会过度拟合Q值估计中的峰值,在更新critic时,使用确定性策略的训练目标极易受到函数近似误差的影响,从而增加目标的方差.为此,TD3PG 算法通过在目标动作加入小批量高斯噪音求平均值来减少目标值的方差,即在式(3)基础上加入噪音:
综上,TD3PG 算法解决了DDPG 算法训练过程中Q值过估计的问题,提高了训练效率,提升了训练稳定性,大大提升了DDPG 在连续动作空间进行控制的性能,TD3PG 算法训练流程如图2所示.本文所提的MATD3PG 算法是TD3PG 在多智能体深度强化学习框架下的扩展算法,相对于MADDPG 可以更有效地解决环境中多个智能体交互的问题.
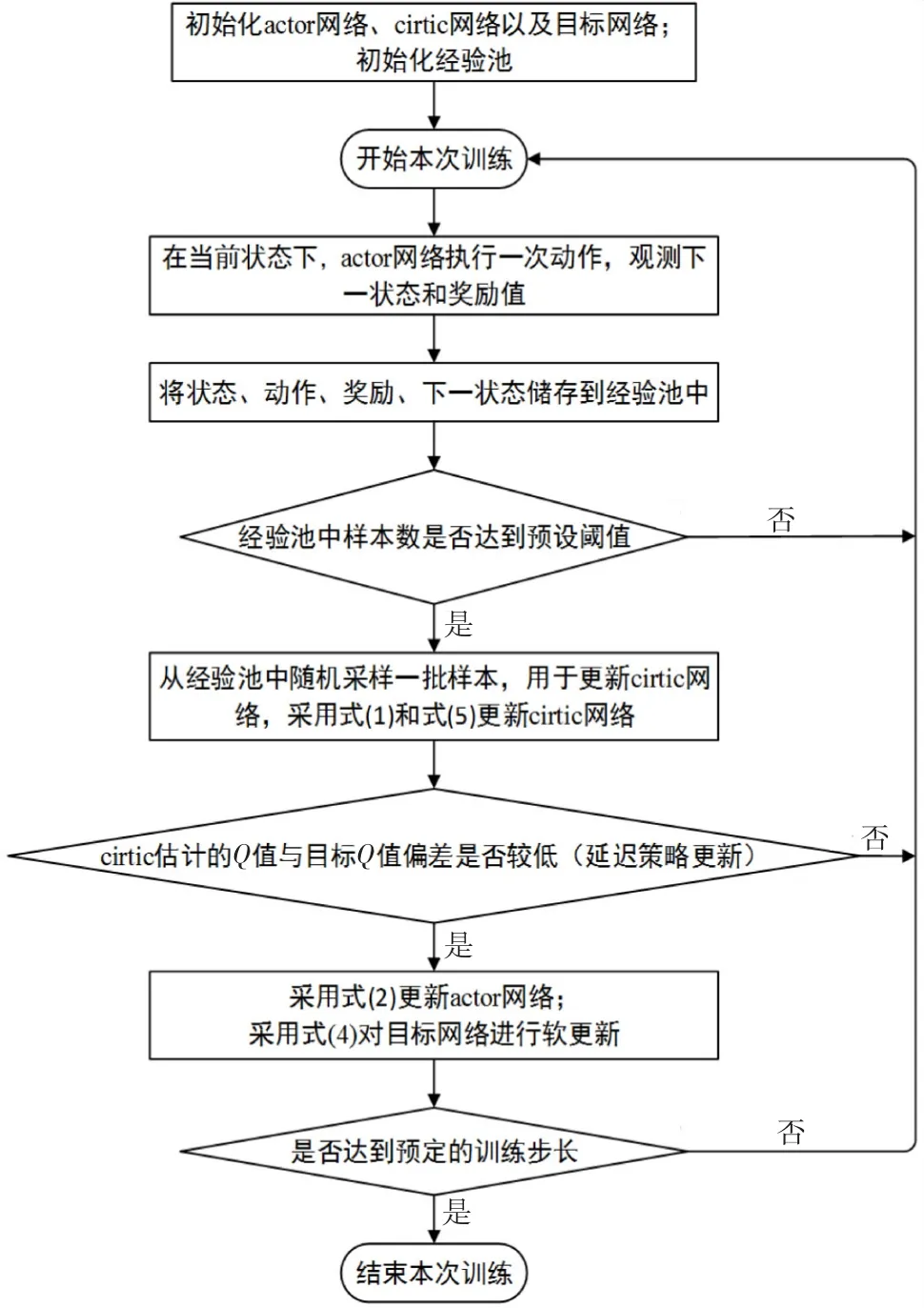
图2 TD3PG 算法训练流程
2 基于MATD3PG 的有源配电网实时电压控制
2.1 光伏逆变器无功调节原理
因为削减光伏有功出力,会影响新能源的消纳,这与我国整县(市、区)屋顶分布式光伏政策不相符,所以本文仅调节其无功出力,光伏有功仍以最大功率发电.光伏逆变器可调无功功率与光伏有功出力、光伏逆变器容量的关系为:
光伏逆变器额定容量通常为额定有功的1.0~1.1倍[21],这意味着当并网有功输出达到额定值时,光伏逆变器仍然具有可调无功容量,并且其无功可调功率会随着光伏有功出力动态变化.光伏逆变器有功-无功容量变化关系如图3所示.

图3 光伏逆变器有功-无功容量变化关系
A点为t1时刻逆变器有功功率输出值,此时逆变器无功调节范围为[-,];当逆变器有功功率输出值减少至B点时,逆变器无功调节范围增加至[-,];夜间光伏有功输出为0,可调无功容量数值就等于逆变器容量数值,可见其无功调节能力极为可观.
2.2 有源配电网实时电压控制物理模型
有源配电网实时电压控制通过协调控制各光伏逆变器,以抑制系统电压波动并降低网损,达到改善电能质量的目的,目标函数如下:
式中:T为一日的控制周期数;C u为电压偏差附加成本系数;Udev,t为第t个控制周期内系统平均节点电压偏差量;Closs为网损附加成本系数;Ploss,t为第t个控制周期的系统网损;U i为节点i的电压;Uref为基准电压;n为配电网节点数.
约束条件如下:
2.3 分散部分可观测的马尔科夫决策过程建模
由于配电网的精确模型参数难以获取,且光伏出力的快速波动性对控制的实时性提出了较高要求,传统基于优化的方法已无法适用于当前控制场景.而MADRL能够有效满足上述要求,能做到无模型数据驱动和实时控制.由于现实配电网环境受通讯条件限制,智能体只能观测到局部的环境状态,不再适合采用MDP进行建模[22],因此本文将有源配电网电压实时电压控制问题建模为Dec-POMDP,将各光伏逆变器当作MADRL 中的智能体,智能体联合动作的环境为现实配电网.
本文的Dec-POMDP 由元组{S,A,O,r,T,γ}组成,其中,S为状态集,A为联合动作集,O为联合观测集,r为奖励函数,T为状态转移概率函数,γ为折扣因子.具体含义如下.
1)状态集S
状态集S为环境内所有智能体状态的集合,S t∈T∈S,S t由各个智能体t时刻所处的状态s n,t组成,本文中s n,t是指包括t时刻智能体n所在区域的所有节点特征量,如负荷的有功和无功出力、光伏有功出力以及(t-1)时刻光伏逆变器的无功功率、关联节点电压.
2)联合动作集A
联合动作集A为全部智能体动作的集合,A t∈T∈A,联合动作A t由各智能体t时刻的个体动作a n,t组成,本文中a n,t为t时刻该光伏逆变器的无功出力.
3)联合观测集O
联合观测集O为所有智能体局部观测的集合,O t∈T∈O,联合观测O t由各智能体t时刻的局部观测o n,t组成,本文中o n,t为t时刻智能体n所在区域内的所有节点特征量.
4)奖励函数r
本文中各智能体为完全合作关系,通过协同动作最小化系统电压偏移和网损,每个智能体的学习目标是全局最优控制策略以获得最大奖励,因此采用全局奖励,根据式(8)设定实时奖励函数:
5)状态转移概率函数T
T(S t+1,S t,A t)表示在状态S t下,多智能体采取联合动作A t后,系统转移到S t+1的概率.状态转移概率函数考虑了有源配电网环境中光伏出力的不确定性,通过了解状态转移的概率分布,可以更有效地评估不同动作对于下一状态的影响,从而为智能体的决策提供指导,以寻找最优的动作策略.
基于MATD3PG 的有源配电网实时电压控制策略示意图如图4所示.

图4 基于MATD3PG 的有源配电网实时电压控制策略
本文通过潮流环境模拟实际配电网的运行环境.离线训练阶段,各智能体在仿真环境学习集中式的critic网络即最优控制策略;由于采用了集中式训练-分散式执行机制,在线实时控制阶段,各智能体仅需通过局部的观测信息和已经训练完成的critic网络进行决策,并且此时critic网络依然能接受配电网环境反馈的状态和奖励信息,可以在训练好的critic网络基础上继续实时更新.该控制策略既能使各智能体协同动作,提升系统的灵活性,又可以保证控制的鲁棒性和全局最优,取得良好的控制效果.
3 算例分析
3.1 算例设置
本文算例仿真测试于硬件平台Intel(R)Core(TM)i5-12500H CPU,Intel(R)Iris(R)Xe Graphics GPU;软件系统为Win10;强化学习算法均基于Python 3.9.0的Pytorch 1.8.1神经网络框架实现.算例基于IEEE-33 节点配电网系统进行改进,网络参数来自于Matpower7.1数据库[23],在节点13、18、22、25、29、33上安装逆变器容量为1.5 MW 的分布
式光伏,改进后的系统拓扑结构如图5所示.

图5 改进后的IEEE-33节点系统拓扑结构
设置根节点电压标幺值为1.00 p.u.,安全运行电压为0.95~1.05 p.u.,配电网实时电压控制间隔为3 min,控制周期数为480.光伏和负荷数据均来源于Elia集团(比利时电网运营商)公开历史数据[24],数据集为2022年整年数据,原始数据的时间分辨率为15 min(96个点),将数据按与配电网实时电压控制间隔(3 min)一致的时间分辨率(480个点)进行插值,其中每个季节选取7 d(共28 d)为测试集,其余则作为训练集.
强化学习算法中,实时奖励函数式(13)中电压偏差附加成本系数C u设为10$/p.u.,网损附加成本系数Closs设为0.05$/MW;在目标动作加入的小批量高斯噪音式(6)的标准差σ为0.1,截断区间参数c为1.强化学习环境中,将每个光伏逆变器都单独作为智能体,智能体动作时间间隔与配电网实时电压控制间隔一致,智能体训练步长为240,即每次不重复截取240个点(半天)的数据进行训练,240个点的数据训练完成即为一个训练回合,本文训练回合数为400.为了模拟现实配电网的不确定性,在每个训练回合开始时都会对系统初始化状态进行随机处理,其余算法参数设置见表1.

表1 强化学习算法参数设置
为了验证本文所提MATD3PG 算法的进步性和有效性,将该算法与以下3种方案进行对比:
1)无控制,即系统内所有光伏逆变器的无功出力为0;
2)传统Q(V)下垂控制策略[7];
3)MADRL中的经典算法MADDPG[15].
3.2 训练结果分析
由于方案1和方案2不存在离线训练过程,所以只进行方案3和本文所提MATD3PG 算法的对比分析.在相同的改进后IEEE-33 节点系统仿真环境下进行训练,上述两种算法训练的平均累积奖励如图6所示,实线为平滑后的曲线,背影部分为原始的振荡曲线.
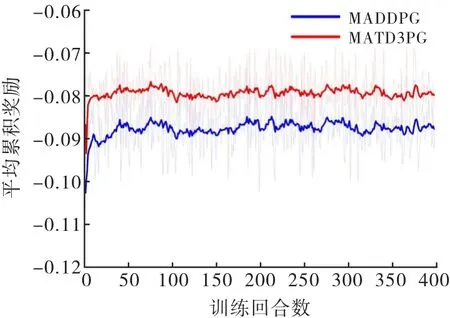
图6 MADDPG 和MATD3PG 算法的训练结果
从图6可以看出,在训练初期,由于智能体采取随机动作探索环境,其奖励变化幅度较大,但随着经验的积累,各智能体逐渐学得最优策略,体现出的就是图像开始收敛,后期奖励值在小幅度变化,MADDPG 算法和MATD3PG 算法的最终奖励值分别为-0.087 9、-0.079 7.本文提出的MATD3PG 算法训练过程中的平均累积奖励相比MADDPG 提升了9.33%,且波动性更小.这是由于MATD3PG 采用3种技术手段解决训练过程中Q值过估计的问题,提升算法的训练效率,取得了更好的训练效果.
3.3 测试集结果分析
将上述训练好的模型用于测试集进行对比分析,控制指标有电压偏差、网损、平均求解时间.不同控制策略的性能参数见表2.

表2 测试集下不同控制策略的性能参数
由表2可知,相较于下垂控制、MADDPG,本文所提MATD3PG 算法具有最佳的稳压降损性能.可以看到,无控制时的系统平均电压偏差较大,经下垂控制、MADDPG、MATD3PG 控制后,电压波动得到抑制,平均电压偏差分别降低了58.22%、62.91%、65.26%,这证明仅利用光伏逆变器也能有效控制电压波动;同时MATD3PG 算法的标准差最小,说明其能更稳定地抑制电压.由于无控制时光伏逆变器无功出力为0,节点间的无功流动较少,导致网损较低,在光伏逆变器调节无功后,会增加系统的网损,但MATD3PG 算法可以在更为有效稳定电压的同时,具备较低的网损,其网损平均值相比下垂控制和MADDPG,分别降低了15.55%、6.73%,其网损标准差也小于二者.由于下垂控制需要通过传统物理模型求解,其求解时间较慢,而强化学习算法仅需通过训练好的神经网络就能完成决策,因此其求解时间较短,且MATD3PG 相比于MADDPG 平均求解时间更短,能够满足在线电压控制的要求.
3.4 典型日结果分析
典型日系统PV 出力和负荷曲线如图7所示,该典型日的光伏渗透率为240.68%,渗透率采用功率渗透率的计算方法[25](即给定区域内,所有分布式光伏发电功率与同一时刻该区域负荷之比的最大值),可以看出9:00~16:00为光伏出力的高峰期,该段的光伏出力明显高于负荷需求,系统极易发生功率倒流、电压越限.
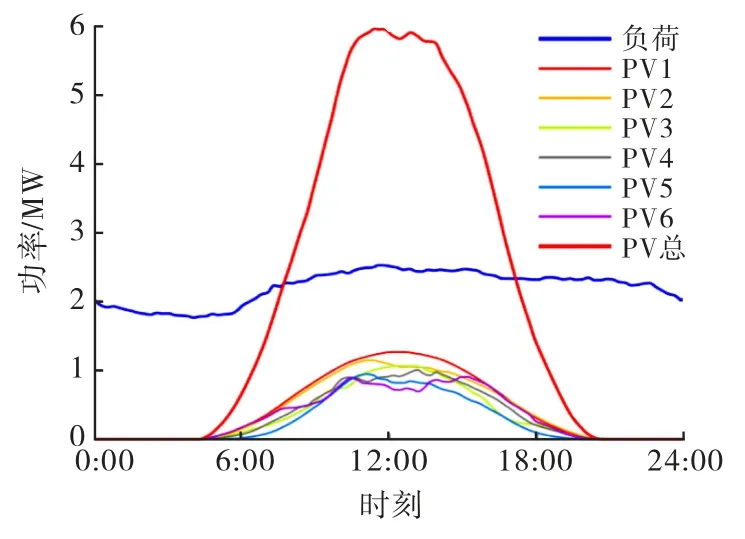
图7 典型日系统的PV 出力和负荷曲线
未经控制的典型日各节点电压分布箱线图如图8所示,可以看出在高渗透率分布式光伏接入的配电网中,众多节点都出现了电压越限,这严重影响了配电网的安全稳定运行.MATD3PG 控制策略下的典型日各节点电压分布箱线图如图9 所示.图中表明MATD3PG 控制策略取得了良好的电压控制效果,经此策略控制后全天各节点电压均处于安全范围内.

图8 未经控制的典型日各节点电压分布
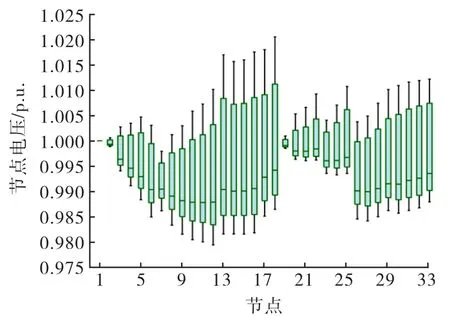
图9 MATD3PG 控制策略下的典型日各节点电压分布
图8表明,当日系统出现电压越限最为严重的节点为节点18,因此选择节点18作为典型节点进行本文所提方案与方案1~3的对比分析.典型日下不同控制策略下的节点18电压分布如图10所示,其中虚线表示基准电压和安全运行电压上下限.图中表明节点18在10:00~15:00均处于电压越上限状态;在夜间均处于电压越下限状态,整体波动较大.虽然方案2和方案3也能将节点电压控制在安全范围内,但从控制效果来看,基于MATD3PG 的控制策略相较于方案2和方案3,能更为有效地抑制电压波动,更好地改善电能质量.

图10 典型日不同控制策略的节点18电压分布
典型日不同控制策略的系统总网损如图11 所示.图中表明本文所提MATD3PG 相比于下垂控制和MADDPG,网损分别减少了20.10%、8.39%,本文所提方法网损最低.这是因为MATD3PG 能更高效地协调各光伏逆变器进行电压控制,减少系统中的无功流动,从而最大限度降低了系统网损.

图11 典型日不同控制策略的系统总网损
4 结 论
本文提出一种基于MATD3PG 的有源配电网实时电压控制策略,能够实现各光伏逆变器的协同控制,有效解决有源配电网的电压越限问题,提升配电网运行的稳定性.主要结论如下:
1)相比传统的优化算法,所提策略无需精确的配电网模型,仅采用光伏逆变器就能够将电压控制在安全范围内,且不会影响光伏消纳,具有较好的经济性.
2)强化学习算法采用基于集中式训练-分散式执行机制,解决传统强化学习算法训练过程中出现收敛困难的问题,降低训练的复杂度,提升训练效果,并显著提高在线实时决策的效率.
3)将有源配电网实时电压控制物理模型转化为Dec-POMDP,将各光伏逆变器作为强化学习环境中的智能体,与环境交互的过程中学习最优控制策略,能更好地应对实际配电网中的不确定性,可以在系统不具备完善通信设备的条件下,根据系统最新状态进行实时电压控制,具有良好的控制时效性.
4)经改进的IEEE-33 节点算例验证,相较于下垂控制和MADDPG,MATD3PG 能够更有效地抑制电压波动、降低系统网损.同时MATD3PG 算法的求解速度更快,具备良好的实时电压控制性能.
猜你喜欢
能源工程(2020年6期)2021-01-26 00:55:22
山东冶金(2019年3期)2019-07-10 00:54:04
经济技术协作信息(2018年32期)2018-11-30 01:43:16
消费导刊(2018年10期)2018-08-20 02:57:02
小学生作文(低年级适用)(2018年3期)2018-04-17 00:58:35
少年博览·小学低年级(2017年4期)2017-06-09 16:22:28
作文评点报·低幼版(2017年7期)2017-03-11 20:49:41
电测与仪表(2016年5期)2016-04-22 01:14:14
通信电源技术(2016年1期)2016-04-16 04:57:26
河南电力(2016年5期)2016-02-06 02:11:24
