
3D-SPRNet: 一种基于并行解码器和双注意力机制的胆囊癌分割模型
2024-01-21 15:14:10张浩洋尹梓名乐珺怡沈达聪束翌俊杨自逸孔祥勇
计算机与现代化 2023年12期
张浩洋,尹梓名,乐珺怡,沈达聪,束翌俊,杨自逸,孔祥勇,龚 伟
(1.上海理工大学健康科学与工程学院,上海 200093; 2.上海交通大学医学院附属新华医院普外科,上海 200092)
0 引 言
胆囊癌[1]是一种由恶性肿瘤引起的、病变于胆囊黏膜上皮细胞的癌症,其癌变部位[2]无明显临床表现,易恶变转移。患者就医时往往因发现较晚而失去手术机会,即使手术,大部分预后情况也较差,5 年生存率仅占比5%左右[3]。
胆囊癌的诊断需要依赖于增强计算机断层扫描(Computed Tomography,CT)影像,但是由于胆囊本身体积较小、易发生严重的形变,且胆囊的癌变部分形态具有多样性[4](1、胆囊壁增厚在CT 中主要表现为胆囊壁在不同切片上不规则增厚;2、腔内单发或多发结节表现为胆囊内部的灰色凸起结节;3、肿块充满整个胆囊,CT 中表现为白色结石或灰色质充满;4、癌变部位侵袭到临近肝脏组织),因此,依靠人工分析耗时耗力,难度较大,易出现误、漏诊的情况。
近年来,随着深度学习技术不断深化应用于医学图像语义分割,取得了一系列重要的新进展和成就。Maji 等[5]在Res-UNet 基础上提出了带有引导解码器的网络ARU-GD,在脑肿瘤分割中表现良好;Lee等[6]提出了一种具有多尺度网格平均池化的通道注意力模块用于乳腺癌分割;Fan 等[7]提出了PraNet 网络基于并行反向注意力机制对结肠镜中的息肉进行分割等。如果将这些不同模型中的新技术,尤其是以编码-解码结构为基础的深度学习模型架构,应用于胆囊癌分割,预期可有效提高胆囊癌的分割精度。因此,本文旨在研究一种适用于胆囊癌分割的深度学习网络模型。
1 相关工作
胆囊在图像中的分割是胆囊癌分割的基础。已有部分学者对胆囊分割方法进行了研究,例如,Huang 等[8]提出了基于解剖学先验知识的胆囊自动定位及分割的方法,有效结合了解剖学先验知识来定位胆囊大概位置,并利用水平集方法对其进行分割,但当胆囊本身存在病变时如胆囊侵袭肝脏组织等情况时其分割效果不佳。Lian 等[9]采用基于区域生长的方法来分割超声图像中的胆囊,该方法经实验验证可提供胆囊和胆结石的轮廓信息并帮助医生准确判断胆囊区域和胆囊结石区域之间的相对位置,但同时易受噪声和灰度不均的影响导致过分割。随着深度学习的不断发展,其在医学影像分割中的效果逐渐取代传统分割方法。近年来,以编码-解码结构为基础的分割模型已成为胆囊分割的主流架构。例如,Shen等[10]提出了基于UNet 的多腹腔器官分割模型,其主要利用器官之间的位置和形状结构减少复杂背景的干扰,使用可变形卷积块提取多尺度特征、改进跳跃连接结构并利用空间注意力机制突出分割区域。该方法分割胆囊达到了较高的80.46%平均Dice 系数,但其依赖于多器官之间结构的相互关系,且二维分割导致深度方向失去空间上下文信息。
相比于胆囊分割,胆囊癌变部位的精准语义分割对临床诊治更具重要意义。虽然国内外研究较少,但已有部分学者进行了初步的研究,如金哲川等[11]基于自适应框架nn-UNet的分割模型,对西安交通大学第一附属医院收集的168 例胆囊癌CT 检查门静脉期图像进行分割,在其测试集上的Dice 相似系数为0.74±0.15。尹梓名等[12]基于深度神经网络Mask RCNN 模型对胆囊癌、慢性胆囊炎胆结石以及正常胆囊CT 进行识别,其平均检测精度和平均召回率分别达到了0.794 和0.774。Basu 等[13]基于超声图像提出了基于ROI区域选择和多尺度二阶池化的GBGNet胆囊癌分割网络,从超声切片中检测胆囊癌,其检测精度高达0.91。虽然以上这些工作可以有效地结合多种模型和算法对胆囊癌区域进行分割,但这些网络结构仅专注于对胆囊癌标注所在的区域进行特征学习,没有将胆囊癌变部位的特征和约束纳入考量;同时以上研究均采用二维图像作为模型的输入进行训练,忽略了三维体数据空间中包含的大量空间上下文信息,而这些上下文信息对于医学影像分割具有很强的指导意义。因此上述研究存在无法细化癌变边界区域、分割边界不够精确等问题。
2 方 法
本文提出一种结合并行解码器和双注意力机制对胆囊癌分割的网络模型3D-SPRNet,模型结构如图1所示。设网络输入CT为I,将预处理后的胆囊CT输入到网络之中,经过残差连接三维卷积模块得到初始特征图f1,再多次利用通道注意力机制和残差连接三维卷积,得到特征图fi(i=2,3,4,5)。利用并行解码器聚合并解码多尺度高级特征图fi(i=3,4,5)得到与I尺寸相同的全局映射图Sg。对Sg先进行下采样将尺寸缩小至与高级特征f5相同,在此基础上通过反向注意力机制得到强调了未被预测区域特征的权重特征图R5,与Sg下采样后的特征图相加来补充细节得到输出特征图S5。同样地,使用反向注意力机制将S5上采样后的特征图与高级特征f4经反向注意力模块得到权重特征图R4,再与S5上采样后的特征图相加得到输出特征图S4,同理可得权重特征图R3和输出特征图S3,对S3进行激活操作即可得到预测标签Prediction。

图1 3D-SPRNet网络结构
本文提出的网络模型主要特点如下:
1)提出一种对三维增强CT影像进行分割的网络模型,将CT影像Z轴深度方向病灶区域的连续上下文特征信息纳入考量,保证预测结果中空间信息的连续性。
2)在特征提取过程中,将残差连接与通道注意力机制相结合,增强网络表征能力,在缓解梯度消失和网络退化问题的同时引导网络更多地关注癌变区域。
3)利用并行解码器获得多尺度感受野,帮助网络对胆囊癌中丰富的高级特征进行提取并聚合这些高级特征得到全局映射图,摒弃低级特征的同时降低模型的复杂性。
4)通过反向注意力机制,在全局映射图的基础上引导网络关注未被预测的区域,逐步推理挖掘边界信息,迭代校正预测结果,提升分割准确性。
2.1 残差连接三维卷积模块
为了能够有效地学习胆囊CT 影像中的空间特征,保留不同切片之间上下文的关系,相比于常规的二维卷积操作,本文使用卷积核大小为3×3×3的三维卷积来对特征进行学习。此外,残差连接通过对上层网络和下层网络的跳跃连接,让网络保留梯度信息,有助于反向传播。目前,残差连接已被证明能够显著改善梯度消失和网络退化等问题[14],有助于深度学习的训练,为此在特征提取过程中加入残差连接。由于网络中输入数据变化差异较大,为将特征值大小限定到一定范围内,在模块中加入归一化操作。而实例归一化能够不受通道数和批处理大小(Batchsize)的影响,对每个单独样本分别进行归一化[15],更适用于影像表现多样且数据数量较少的医学影像。激活函数为网络增加非线性因素,强化网络的学习能力。本文使用的Leaky ReLU 激活函数相比于传统ReLU 激活函数,一定程度上保留了负值输入[16],防止出现ReLU激活函数中负值神经元不学习的问题。
具体模块信息如图2 所示。对于一个输入x,首先对输入数据进行实例归一化(InstanceNorm)将特征值大小调整到限定范围,有助于模型收敛。随后使用Leaky ReLU 激活函数对其激活后再进行3×3×3 的三维卷积操作,最后将所得结果与初始输入值求和完成残差连接。
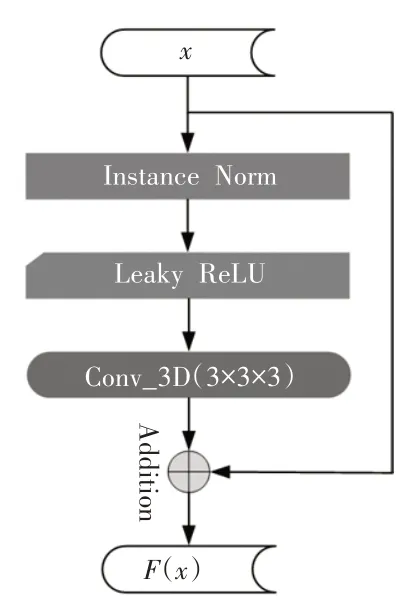
图2 残差连接局部模块
设实例归一化操作为fIN,Leaky ReLU 激活函数表示为σLR,三维卷积操作表示为Conv3D3×3×3,则输出结果如公式(1)所示:
2.2 通道注意力模块
在医学影像中,复杂的背景信息会对分割造成干扰,尤其是像正负样本像素分布极不平衡的胆囊癌分割等其他部位癌变分割。此外,特征提取得到的各个特征图的不同通道也有着不同的作用,不应赋予相同权重。注意力机制为图像分割等方向的精度提升做出了贡献[17-18],在抑制输入图像中冗余信息的同时突出了特定区域的显著特征,解决了数据不平衡问题和性能问题,取得了优异的效果。
为了增强模型的分割效果,本文设计三维通道注意力机制,其原理是基于网络中不同通道之间的联系,通过建模网络特征通道之间的相互依赖关系,让网络执行特征重新校准,学习全局信息来选择性地强调特征信息,抑制非特征信息。
模块主要包含压缩(Squeeze)和激活(Excitation)2 个部分[19]。假设输入端为X且X∈RC×D×H×W,C、D、H、W分别代表通道数、深度、高度和宽度。经过残差模块卷积输出为Res_X,且Res_X∈RC×D×H×W。首先将空间上的特征压缩,ZC=RC是对特征Res_X在空间维度D×H×W中每一个元素执行三维平均池化的结果,如公式(2)所示:
只保留通道信息,将C×D×H×W的特征图压缩到C×1×1×1 的实数数列。为了利用压缩得到的聚合信息,随后利用激活操作来学习通道之间非线性非互斥的关系,如公式(3)所示:
其中,S表示C个特征图的权重,σ表示Sigmoid 激活函数,δ表示ReLU 激活函数,,r代表降维率。
将压缩后的通道特征通过使用2 个FC 层对机制进行参数化。第1 个是具有降维率r的降维层后接ReLU 激活函数,第2 个是维度升高层,2 个层先后完成对学习通道先压缩后扩展的过程即完成了注意力的过程,最后对每个通道1×1×1 的特征维度进行Sigmoid 归一化即可得到通道注意力的矩阵S,权重即为特征选择后的每个特征通道的重要性,用该矩阵乘上输入的特征即可得到赋以不同通道特征权重的特征图SE_X。具体模块实现如图3所示。
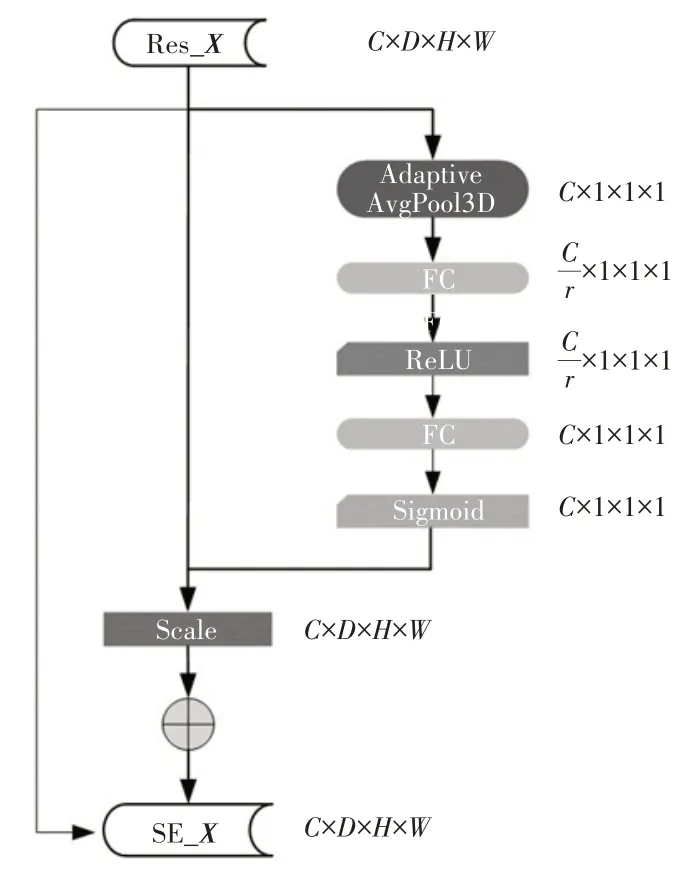
图3 三维通道注意力模块SE_3D
2.3 并行解码器模块
在UNet及3D-UNet、Res-UNet等衍生网络中,其解码方式通常为反卷积或线性插值。反卷积虽然可以将图片还原到原始尺寸并细化粗略特征图[20],但在还原过程中会产生棋盘效应导致图像不均匀重叠,影响预测效果。线性插值虽然可以通过扩大图片后卷积等操作来解决上述问题,但在三维图像中应用三线性插值时,由于计算量过大将导致速度较慢。
为此,Wu 等[21]指出在卷积神经网络得到的多级特征中,低级特征相比于高级特征贡献较小,且高级特征需要较大的空间分辨率和一定的硬件支持,计算成本较高,为此提出了一种双分支级联的部分解码器框架。Liu 等[22]受人类视觉中的群感受野启发,设计了新的特征提取模块RFB(Receptive Field Block),利用不同大小的卷积核和空洞卷积来获得多尺度感受野,其原理如图4所示。
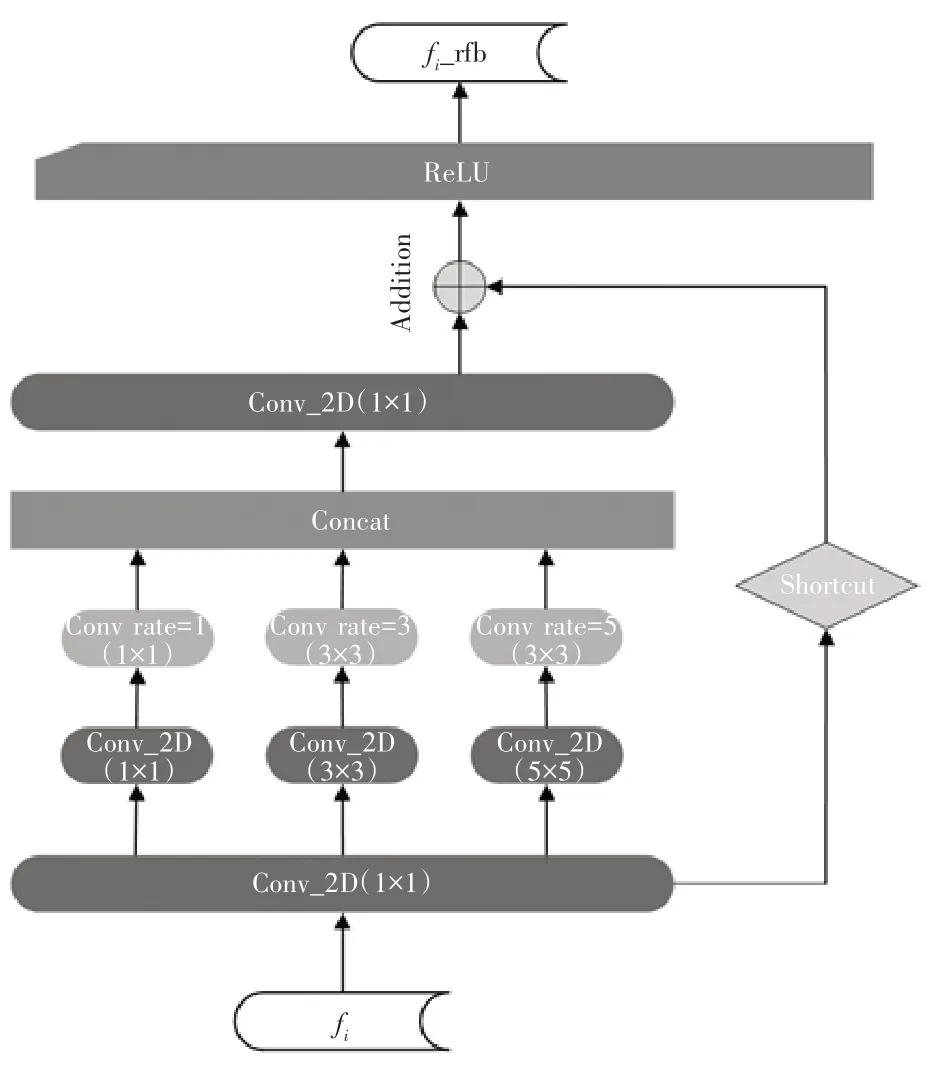
图4 特征提取模块RFB
相比于图4 的原始结构,本文引用其思想并加以改进为应用于三维数据的模块,将卷积的分支数增加为4 个,调整空洞卷积核大小分别为3×3×3、5×5×5 和7×7×7,rate 值分别为3、5 和7。为减少三维卷积和拼接时的运算量,在每个分支的空洞卷积前进行卷积分解,用1×3×1 和1×1×3 的卷积近似代替一个3×3×3的卷积。将其应用于三维特征图的并行解码器,对高级特征进行聚合后解码得到全局映射图。
具体而言,当输入一个尺寸为D×H×W的胆囊CT时,可在主干网络上提取到5个层次的特征fi,其中i=1,2,3,4,5。将特征fi分为低级特征fi(i=1,2)和高级特征fi(i=3,4,5)。利用并行解码器将3 个高级特征f3、f4和f5并行连接后聚合高级特征,解码后得到全局映射图Sg。
并行解码器由特征提取模块RFB 和高级特征聚合模块Aggregation 组成。具体模块实现分别如图5、图6 所示。RFB 结构由4 个分支构成,将高级特征f3、f4和f4并行输入到并行解码器中。为了减少卷积核参数、加速训练,先对跨通道信息进行整合:每个分支中均使用1×1×1的三维卷积统一将通道数减少至32。在分支b1,b2,b3中,分别添加3 个卷积层,并使用空洞卷积增加感受野。最后将分支b0,b1,b2,b3的输出在通道维度上拼接,随后再次进行卷积。将拼接后的结果与初始输入的高级特征相加后使用ReLU 对结果进行激活后输出。简言之,对输入特征先进行特征整合减少参数,在空洞卷积前加入2个卷积分解,保证提取特征的同时控制参数。再进行多尺度空洞卷积提取多尺度特征,最终残差连接对拼接后的特征进行完善补充。
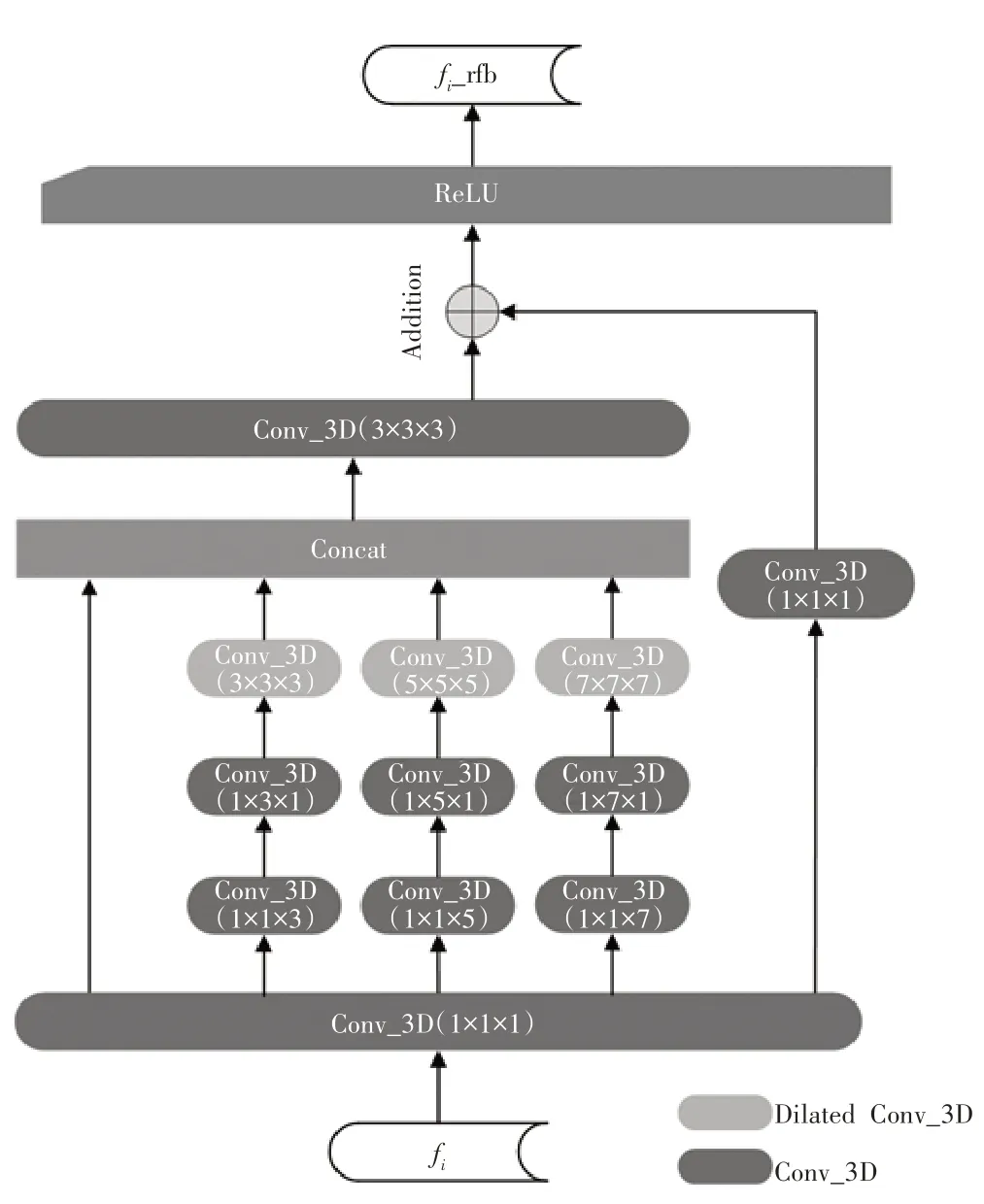
图5 改进的特征提取模块RFB
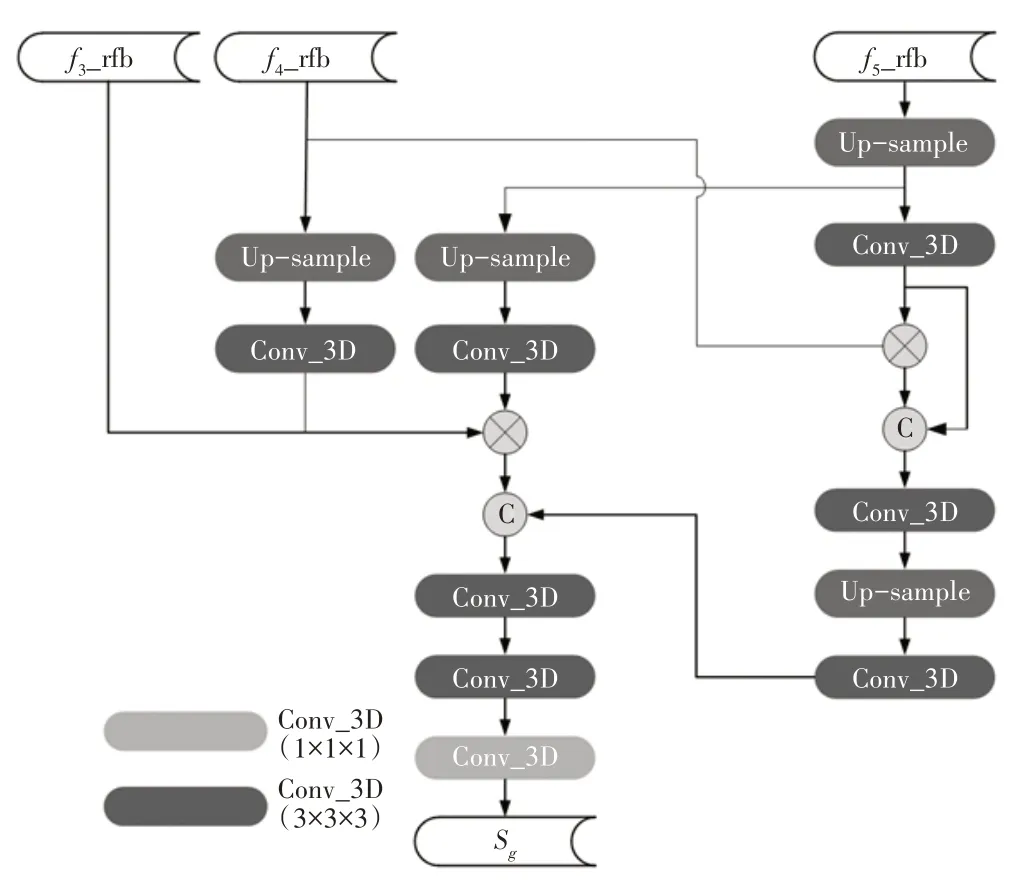
图6 高级特征聚合模块Aggregation
Aggregation 结构用于聚合高级特征,将RFB提取得到的3 个多尺度高级特征f3_rfb、f4_rfb、f5_rfb 通过上采样和卷积操作聚合为一个全局映射图Sg。具体而言,本文将最深层的高级特征f5_rfb 进行一次上采样操作和一次卷积核大小为3×3×3 的三维卷积操作将特征图尺寸放大1 倍后与f4_rfb 直接相乘用于初步融合带有最深层特征权重的特征图,再将其与上采样后的f5_rfb 进行拼接完善通道特征。随后将其进行2次三维卷积和1 次上采样操作将尺寸还原到与f3_rfb相同的特征图。对高级特征f4_rfb 进行1 次上采样操作放大到相同尺寸后再次卷积,与经过2 次上采样和1 次卷积后的f5_rfb 和初始高级特征f3_rfb 相乘,用来融合3 个层次的高级特征f3_rfb、f4_rfb 和f5_rfb。此处相乘而非拼接或相加的目的在于所提取到的3 个高级特征来自于不同深度层次,需要将各层权重通过乘法表现到融合的特征图之中。最终,将上述2 个已经还原到初始尺寸的融合的高级特征在通道上进行再次拼接,以补充语义信息。经2次卷积核大小为3×3×3 的三维卷积和1 次1×1×1 的三维卷积将通道数降为1得到全局映射图Sg,至此完成融合高级特征的解码。
2.4 反向注意力模块
如图1 所示,聚合后的高级特征经并行解码器解码后,通过三线性插值得到全局映射图Sg。但由于其聚合的特征只是来自主干网络提取的深层特征,因此只能关注到胆囊癌变部位特征的粗略部分,对于细节信息仍然需要进一步完善。为此,Chen 等[23]在目标检测过程中先对最深层的粗略特征进行预测,提出了反向注意这一思想,即自上而下地删除现有预测区域,逐步探索其余丢失的细节部分。本文将其思想应用于此:由于在预测过程中未被预测的区域极有可能包含癌变部位,但网络对于非预测区域的学习不充分一定程度上会影响分割精度。为此,引导网络关注现有的背景区域有助于发掘原始预测和反向预测之间的差异,进而减少对背景和前景的错误分割。此外,本文中所分割的前景癌变部位的大致全局信息在网络的深层可以大致获得,对于边缘外的细节信息需要引导网络主动关注,才能保证最终分割结果的精准度。
具体而言,主干网络所输出的3 个高级特征fi(i=3,4,5)可自适应地学习反向注意力机制,通过对高级特征区域取反再加1 的方法来擦除高级特征中现有网络所预测的癌变区域(即从最深层上采样得到的特征),进而按次序关注并学习与癌变部位互补的区域上的细节。
在反向注意力机制中,将全局映射图Sg进行上采样(up)后的(i=1,2,3)激活得到矩阵,则权值为全1 的三维矩阵减去该矩阵得到的差值,表示为当前未被预测区域的权重。设权重为Ai,上采样得到的为,则其计算方式如公式(4)所示:
最后,将下采样过程中所输出的3 个高级特征fi(i=3,4,5)乘以反向注意力权重Ai,可以得到反向注意力特征Ri,即可引导网络关注未被预测的背景区域,如公式(5)所示:
具体细节如图7 中所展示的那样,最终由反向注意力机制可以将粗略的估计逐步细化定位为更加准确的边缘信息。
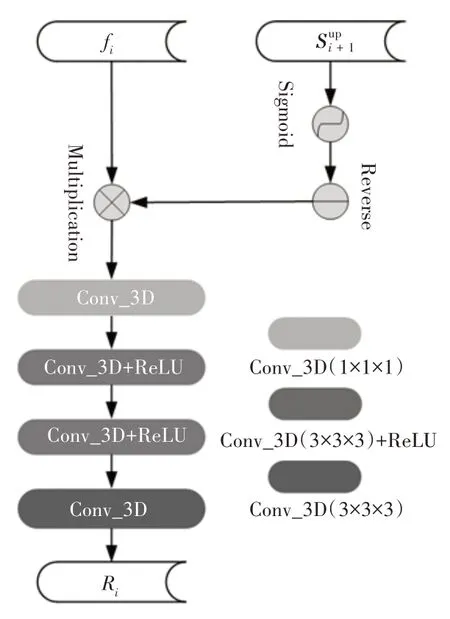
图7 反向注意力模块RA
3 实 验
3.1 数据集预处理
本文所用到的数据集是来自上海交通大学医学院附属新华医院的胆囊癌患者的CT 图像,共计315份数据。在对影像逐一检查并结合医生的临床判断后,发现有11 例数据存在标注区域错误、胆道梗阻非胆囊癌、癌变区域过小的问题。考虑到以上问题,选择删除这11例数据记录。在剩余304例患者的CT影像中,本文将数据集以8:1:1的比例划分为训练集、验证集和测试集,并使用5折交叉验证来验证网络性能。
为了提高特征占比、消除背景冗余信息的干扰,本文对原始CT 的横断面进行裁剪。原始CT 如图8所示。
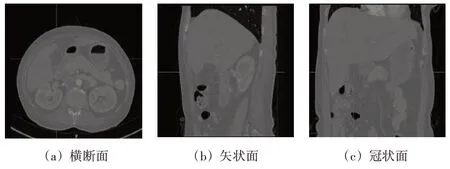
图8 原始CT图像
本文对原始CT 图像进行区域切割,在保证胆囊及其癌变部位完整的情况下,裁取横断面左上1/4 部分。具体操作为:在垂直于矢状面的X轴方向上取存有胆囊的左半部分、在垂直于冠状面的Y轴方向上取包含完整胆囊的部分(第64至第336像素)、在垂直于横断面的Z 轴方向上找出医生标注的癌变存在区域,再从该癌变存在区域切片的开始和结束各向外扩展20 层以确保胆囊完整存在。标签同CT 进行相同的切割处理。此外,为了使原始CT 影像中能够清晰地分辨胆囊、癌变以及周围软组织区域,本文将CT阈值限定为-200~200 之间,将CT 灰度值在阈值范围外的部分截断,最终处理后的CT如图9所示。
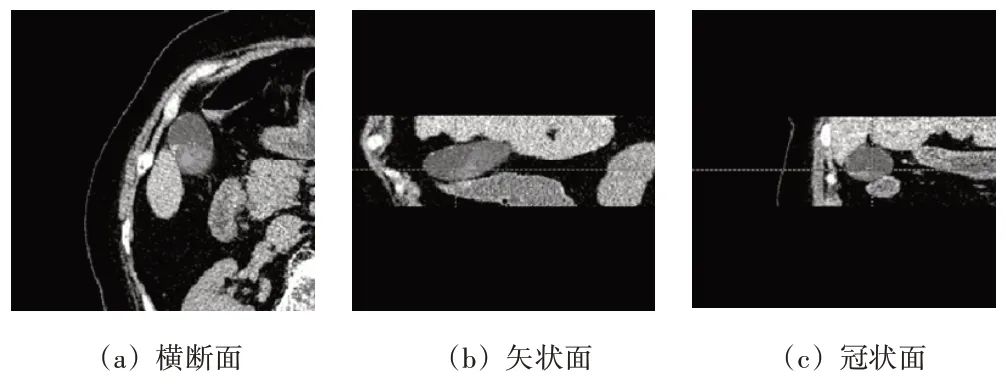
图9 预处理后CT图像
3.2 损失函数和评价指标
3.2.1 BCELoss交叉熵损失函数
交叉熵主要描述为实际输出(概率)与期望输出(概率)的距离。交叉熵的值越小,则证明模型实际输出与期望输出的概率分布越接近。假设概率分布p为期望输出,概率分布q为实际输出,H(p,q)为交叉熵,则交叉熵损失函数如公式(6)所示:
实验中用到的交叉熵损失函数BCELoss 是图像分割中常用的逐像素交叉熵损失函数。在医学分割领域尤其是本数据集样本的背景下,CT 影像经常出现类别不均衡的问题,如无关部分(如背景或其他软组织)占据CT 大部分内容,而真正要分割的胆囊癌变部分体积较小,这导致训练时会被像素较多的类主导,难以学习到胆囊癌变部位的特征,降低了网络的有效性。虽然交叉熵损失函数在梯度传播方向效果较好,但却忽略了医学图像样本中不同类别占总空间的比例,因此本文又引入DiceLoss 损失函数与之结合。
3.2.2 Dice系数与DiceLoss损失函数
Dice系数是一种集合相似度度量函数,用来计算2 个样本之间的相似度,取值在(0,1)之间,Dice 系数越大表明2 个样本越相似。若X代表真实结果,Y代表预测结果,X⋂Y代表预测图和分割图的交集,则Dice系数s如公式(7)所示:
在Dice系数的基础上,可将DiceLoss损失函数表示为公式(8)所示:
虽然DiceLoss 适用于样本不均衡的情况,但不利于反向传播,容易使训练不稳定。因此,本文实验中使用BCELoss 和DiceLoss 这2 个损失函数,分别赋以2 个合适的权重α、β,求和为一个整体损失函数Total_Loss。使用整体损失函数对训练效果进行评判,可以有效结合2 个损失函数的优点。整体损失函数如公式(9)所示:
在训练过程中,本文对编码过程中输出的3 个高级特征图fi(i=3,4,5)和全局映射图Sg进行深监督,经上采样后与标签G进行比较。因此整体损失函数可进而表示为公式(10)所示:
3.2.3 IoU和MIoU
交并比IoU 常作为语义分割的标准度量,通过计算分割后所有类别的预测结果和金标准的交集和并集之比的平均值来评价预测结果好坏。假设A和B分别为预测区域和真实区域,则交并比IoU 如公式(11)所示:
均交并比MIoU 是在交并比IoU 的基础上计算所有分割类别的预测结果和金标准的交集和并集之比的平均值。用pij表示将类别i错误预测为类别j,MIoU如公式(12)所示:
3.3 实验平台及超参数
本文使用Pytorch 框架实现网络,在Linux Ubuntu 16.04系统环境下运行,并在具有24 GB 显存的Nvidia TITAN RTX GPU 上进行实验,CUDA 版本为10.1。CT影像输入大小为32×160×160,使用Monai医学深度学习框架中的翻转、平移、拉伸操作以30%的概率对训练数据进行在线数据增强。超参数设置如表1所示。
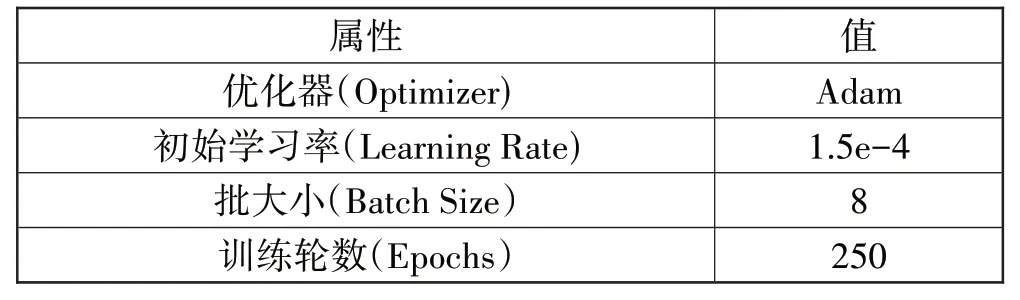
表1 超参数设置
4 结果分析
4.1 胆囊癌分割对比实验
为了验证本文所提出的胆囊癌分割模型的有效性,在采取相同的训练方法和参数设置的基础上,将本文提出的3D-SPRNet 网络模型同经典的3D-UNet网络模型[24]、3D-Res-UNet 网络模型[25]、3DDenseNet 网络模型[26]在本文数据集上的表现进行对比,经5折交叉验证后实验结果如表2所示。
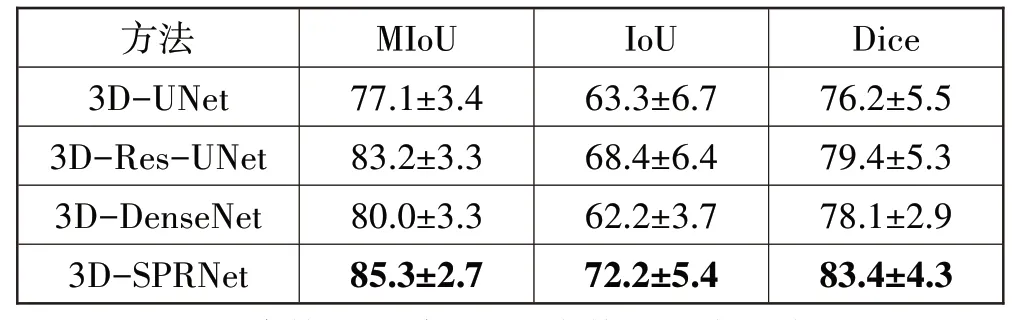
表2 评价指标结果(95%置信区间)
相比于其他3 种常用网络模型,本文提出的3DSPRNet 网络在胆囊癌分割中表现出较好的性能,其均交并比、交并比和Dice 系数分别达到了85.3%、72.2%和83.4%。其中,与3D-UNet 相比,3D-Res-UNet 中残差连接的加入会一定程度改善网络的分割精度,在Dice 系数上提高了3.2 个百分点,这表明残差连接对于胆囊癌分割精度的提升会有不可忽略的作用,为此本文也在下采样过程中采用残差连接来解决反向传播中梯度消失的问题进而优化分割效果。3D-DenseNet 网络在测试集上的平均Dice 系数均在78.1%附近波动,但在交并比和均交并比方面要明显低于3D-Res-UNet 网络。这说明,密集卷积模块在胆囊癌分割方面并未起到精度提升的作用。预测结果如图10所示。

图10 胆囊癌分割对比实验结果
4.2 消融实验
为验证本文中各模块对于提升模型分割精度的必要性,本文通过消融实验来说明通道注意力机制、并行解码器和反向注意力机制可以有效改善分割效果并提高分割精度。其中:A1 表示本文3D-SPRNet网络;A2 表示在A1 的基础上去掉三维通道注意力模块的网络;A3 表示在A1 的基础上去掉并行解码器模块的网络;A4 表示在A1 的基础上去掉反向注意力模块的网络。实验结果如表3所示。
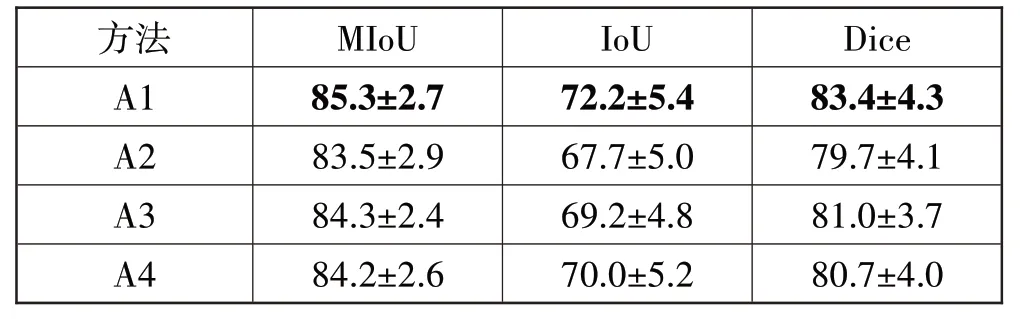
表3 消融实验结果(95%置信区间)
由表3消融实验结果和图11预测结果可得,在本文所提出的3D-SPRNet 模型中,三维通道注意力模块、并行解码器模块和反向注意力模块均能有效提升分割精度、细化分割边界并减小背景干扰信息对预测结果的影响。其中,三维通道注意力模块对分割精度的影响最大,Dice 系数较3D-SPRNet 降低约4.5%左右,癌变部分交并比降低约6%左右。结合预测结果而言,三维通道注意力的加入能够有效帮助网络对全局信息中非特征信息进行抑制,对特征信息进行重点关注。综上,本文提出的3D-SPRNet 模型能够实现胆囊癌变部位较为精确的分割。
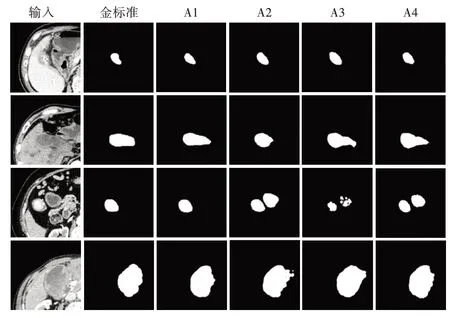
图11 消融实验结果
4.3 损失函数超参数对比实验
为了确定不同损失函数的权重,本文进行了超参数对比实验,α分别取0.0、0.2、0.4、0.6、0.8 和1.0,β取1-α。不同超参数取值下测试集的预测表现如表4所示。
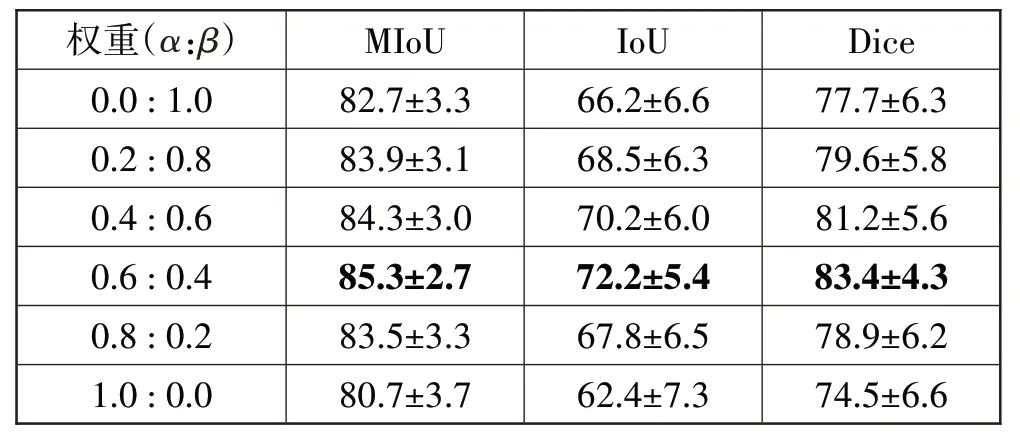
表4 超参数对比实验结果(95%置信区间)
从实验结果可知,当BCELoss 和DiceLoss 这2 个损失函数的权重α、β分别为0.6和0.4时,相比于其他5组权重,该组在测试集上的分割精度达到最高、表现最好。
4.4 讨论
在胆囊癌分割对比实验的预测结果中:当胆囊癌变区域明显且周围背景干扰因素较少时(图10第1行和第2行对应数据),这4种网络模型都能大致实现癌变部位的基本分割。但相比于本文提出的3DSPRNet,前3种基本网络模型在边界预测中或多或少受比邻组织器官的影响,无法保证边界区域的平滑和准确。当输入CT 中背景信息复杂、周围组织多变区域界限模糊,尤其是属于胆囊癌侵袭周围肝脏组织的癌变类型(图10第3行对应数据)或腔内结节类型(图10 第4 行对应数据)时,3D-UNet 和3D-Res-UNet 网络模型极易受到癌变周围干扰背景的影响,出现过分割情况。而3D-DenseNet 相比于前2 种网络可以不受周围干扰特征的影响,基本实现癌变区域较为准确的定位和分割,但其预测形态和边界平滑度都不如本文提出的3D-SPRNet网络模型。
具体而言,3D-UNet网络对输入的全局特征给予了相同的关注度和惩罚,这导致网络无法更多地关注目标区域,易受到背景部分冗余信息的干扰从而出现边界粗糙、标注区域离散的问题。在3D-Res-UNet网络中,虽然残差连接通过浅层特征到深层特征的恒等映射可以帮助网络定位癌变区域,但是对于边缘信息的处理仍然容易受到比邻组织器官的影响,出现过分割的情况。而3D-DenseNet 在通道维度上对特征图进行拼接从而实现特征重用,在牺牲了一定的内存的基础上保证了预测区域的范围,但其预测边界区域粗糙,且容易出现欠分割的情况。
针对以上3 种基本网络模型存在的问题,本文提出的3D-SPRNet 网络在结合并行解码器、通道注意力机制和反向注意力机制的基础上,一定程度地解决了上述问题。由3D-SPRNet 预测得到的结果可看出,对于癌变区域形态较为完整、边界较为清晰且与周围背景信息对比度强时,3D-SPRNet能够实现癌变区域较为精准的分割,网络在保证预测区域匹配的前提下进一步通过反向注意力机制挖掘边界线索,使预测边缘平滑清晰。当背景信息复杂、且癌变区域模糊不易识别时,本文网络通过并行解码器能够提取并融合癌变的高级特征,反向注意力则以此为初始关注区域,挖掘外围区域线索最终完成相对精确的预测。综上所述,3D-SPRNet网络模型在胆囊癌分割中的表现要明显优于3D-UNet、3D-Res-UNet 和3D-DenseNet网络模型,在癌变边界区域的细化和预测方面有更好的效果。
5 结束语
本文基于并行解码器和双注意力机制,提出一种胆囊癌分割模型3D-SPRNet,实验结果显示,本文提出的3D-SPRNet 相比于经典的3D-UNet 网络、3DRes-UNet网络和3D-DenseNet网络,具有更好的预测精度,能够为临床医师诊断提供一定意义的辅助决策。
但同时本文也存在一定的局限性:由于胆囊癌种类多样,对于侵袭临近肝脏组织的胆囊癌的病变,现有方法很难将癌变区域从肝脏中分离出来。此外,对于损失函数的设置,简单地利用权重将2 个损失函数相结合的方法并非最优解,对于结合方法的改进或提出针对于胆囊癌数据集特点的损失函数也将是后续努力的方向。因此,如何利用其它深度学习方法如集成学习等,将不同模型的对于不同类别的胆囊癌的分割优势进行结合,亦或是加入解剖学先验知识来对不同类别的胆囊癌进行更具特点的分割是接下来研究的方向所在。
猜你喜欢
昆明医科大学学报(2022年2期)2022-03-29 00:51:36
中国医学影像学杂志(2018年9期)2018-10-17 01:27:12
癌症进展(2016年9期)2016-08-22 11:33:04
中国卫生标准管理(2015年25期)2016-01-14 09:29:18
中国现代医学杂志(2015年26期)2015-12-23 11:04:22
医学研究杂志(2015年9期)2015-07-01 17:27:52
卫生职业教育(2014年16期)2014-05-16 03:48:30
西南医科大学学报(2014年6期)2014-03-20 15:43:45
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:39
癌变·畸变·突变(2014年6期)2014-02-27 06:15:03
