
基于AOA-MSVM的控制集群故障检测方法
2024-01-21 15:14:20杨博,庄毅
计算机与现代化 2023年12期
杨 博,庄 毅
(南京航空航天大学计算机科学与技术学院,江苏 南京 211106)
0 引 言
计算机和通信系统已经变成当今社会的关键组成部分,并对当前的经济、社会、政治和文化等方面产生了深刻的影响。大多数当前的软件系统都可以被视为集群系统,集群系统是由大量独立的计算机组成的并行或分布式系统[1],多用于高性能计算和高可用应用服务。由于计算机技术的发展,集群系统已经广泛应用于大型互联网企业,例如:Google 搜索引擎[2]、Facebook[3]及高性能计算集群等。集群系统中节点数量不断增加,网络架构日益复杂,使得集群系统功能逐渐复杂,但同时也对集群系统的可用性提出了更高的要求[4]。集群系统中节点或网络出现故障和异常的情况越来越频繁,这些故障发生后可能会进一步传播最终导致系统级的服务失效。据相关数据统计,Google 搜索引擎每季度至少宕机一次;亚马逊公司出现过大规模的宕机事件,导致大量相关的应用服务中断;Google 集群分析报告指出其每36 个小时就可能会有一个节点发生故障,每年的节点故障大约为2%,频繁的故障严重影响用户的正常使用[5]。
集群系统中发生于某节点的故障可能会由于任务的协作和节点之间的通信导致其他节点相继发生故障,即产生更大范围内的系统故障。由于控制集群系统的复杂性和动态性,且监控系统需要从节点、程序、网络和性能等方面搜集大量资源数据,集群系统分析大量的数据将会导致故障检测效率和准确度低。因此,必须结合真实集群系统的运行特性,获取更多不同类型故障的特征,设计出能够准确检测集群故障类型的方法。
现有研究工作在集群系统的故障检测方面已经取得了较好的效果,但是检测效率和检测准确度方面还需进一步提高。因此,本文提出一种基于AOAMSVM 的控制集群故障检测方法,不仅可提高故障检测准确率,而且可大大缩短故障检测时间,进而提高控制集群的可用性。具体的工作如下:
1)在集群系统中收集大量系统监控数据,运用局部线性嵌入算法提取故障特征,在保持原始数据性质不变的情况下,对数据进行降维。
2)由于集群系统易发生的故障类型众多,使得标准的单类支持向量机的检测效率和检测准确度较低。为此,本文提出一种多类支持向量机的故障检测方法,以提升集群系统的故障检测能力并降低时间开销。
3)使用改进的自适应算术优化算法求出故障检测模型参数最优解,以提高故障检测模型的准确度。
4)搭建高可用控制集群系统,模拟多种故障类型进行检测,对比实验结果表明,本文提出的故障检测方法具有检测准确度高、检测效率快并可有效识别故障类型的优点。
1 相关研究
集群系统故障检测大致可以分为节点故障检测、程序故障检测[6]、网络故障检测和性能异常检测[7]。节点故障检测通常分为基于规则检测[8]和异常检测2类。Guan 等[9]提出了一种使用贝叶斯模型集成的无监督故障检测方法,同时提出了一种有监督的决策树分类器,用于预测系统中发生的故障;Arefin 等[10]提出了一种检测数据中心运行问题的整体方法,该方法能够检测到许多操作问题;王开放[11]提出了一种基于长短期记忆网络和支持向量机相结合的故障预测模型,通过训练得到SVM 故障判断模型对预测数据进行故障分类;Adamu 等[12]使用从计算机故障数据存储库收集的实时数据信息,通过机器学习算法预测实时云环境中的节点故障以提高系统可用性。程序故障检测指在程序跟踪或执行日志中发现非法控制流和故障,Shu等[13]提出了一种使用聚类和单类支持向量机检测系统调用序列中共现和频率异常的方法;Shu等[14]提出了一个程序故障检测框架,该框架使用上下文敏感模型对程序故障进行检测;另一个例子是DeepLog[15],这是一个框架,它使用一系列长短期记忆网络来发现长序列日志条目中的异常。网络故障检测主要是通过被动式和主动式2 种方法进行网络故障检测,Lu等[16]提出了自适应探测算法,通过少量的哨兵来监测所有网路组件中的状态;张开延等[17]提出了一种网络故障分类算法,使得分类更加精确、高效;董海强[18]研究了一种基于贝叶斯网络的网络故障检测算法,该算法可以更好地对抗噪声;周畅[19]提出了一种用于网络故障检测的改进的高效蚁群算法。性能异常检测包括寻找以时间数据表示的系统性能指标中的异常偏差,Yu 等[20]提出了一种针对大规模基础设施的异常检测框架,该框架能够检测到以前未发现的异常;王涛等[21]提出了一种基于自适应监测的云计算系统故障检测方法,该方法建立可靠性模型以预测系统可能出现故障的时间;Guan 等[22]提出了一种识别云基础设施异常的方法,该方法采用主成分分析来选择与故障相关性更大的系统指标;CloudPD[23]是为云基础设施设计的异常检测和修复框架,它能够检测以前未见过的异常,并能够适应正常行为的变化。
综上所述,尽管近年来集群系统的故障检测取得了重大进展,但现有的大规模集群系统故障检测方法依然存在以下3个问题:
1)现有的故障检测方法大都仅针对集群系统单一故障类型进行检测,无法同时对多类故障进行检测,这导致集群系统无法有效识别故障类型。
2)在集群系统中,部分故障只有在经过一段时间才能被检测到,而不是在瞬时,现有方法无法快速检测到更复杂的故障。
3)在实际的集群系统中,通常信息数据量巨大,导致现有故障检测方法可能会造成较长的检测时间和较高的检测错误率。
2 基于AOA-MSVM 的故障检测方法
基于AOA-MSVM 的控制集群故障检测方法分为2 个部分,分别为模型训练阶段与检测阶段。在模型训练阶段中,将集群系统收集的各类信息组成信息数据集,对信息进行分析,寻找易导致集群故障的关键信息,对数据进行预处理,运用一种数据降维方法,使数据保持局部线性特征不变;然后,使用一对多支持向量机构建故障检测模型并使用改进的自适应算术优化算法对模型参数求最优解得到多类故障检测分类器。在检测阶段,收集系统实时动态数据,对数据中的关键信息进行提取;然后,通过多类分类器进行故障检测,给出故障检测结果和故障类型。本文所提出的集群故障检测方法流程如图1所示。

图1 基于AOA-MSVM的故障检测方法流程
2.1 故障特征提取
在高可用控制集群系统中,需要实时从集群收集大量的节点信息、网络信息和系统资源信息等,以持续不断监测控制集群中心节点和计算节点的运行状态。若故障检测模型需要分析所有的监测信息,则会造成巨大的时间消耗。因此,为了同时满足故障检测准确性和时间开销小的需求,需要从大量信息中收集关键信息,并提取故障特征。
LLE(Locally Linear Embedding)算法是一种数据降维方法,此方法将高维数据映射到低维空间,并使数据保持局部线性特征不变[24]。给定一个样本集X={X1,X2,…,XN},X的低维特征映射结果为Y,LLE算法的实现需要3个步骤:
步骤1邻域选择。对于样本集X中的每个样本点Xi,采用欧氏距离确定每个样本点的k个近邻点。
步骤2计算重建权重矩阵W,并通过最小化重建损失函数E(W)得到该点,如式(1)所示:
其中,为Xi的k个近邻点,是Xi与之间的权重值,且满足条件;如果不是Xi的近邻,则其对应的=0。
步骤3计算降维后的矩阵Y。通过步骤2 求出的权重矩阵W使损失函数E(W)最小,损失函数与约束条件如式(2)所示[25]:
其中,I是N×N的单位矩阵。可进一步求解式(2)得到式(3):
其中,M=(I-W)T(I-W)是N×N的对称矩阵。
要使得损失函数最小,则取Y为M的m个最小非零特征值所对应的特征向量。在处理过程中,将M的特征值从小到大排序,通常取2~m+1 间m个特征值对应特征向量的输出结果。
2.2 故障检测模型
对于多分类问题,可以利用二分类SVM 构建多类分类器。其中,“一对多”支持向量机[26]是在一类样本与剩余样本之间构造决策平面,从而达到多类识别的目的。该方法不必在两两之间都进行分类,大大缩短了分类时间。
本文用Fi(x)表示第i类集群故障检测分类器的决策函数。 若故障类型被划分为M类,则Fi∈{1,2,…,M}。Fi(x)计算方法如式(4)所示:
其中,ωi和ρi为超平面参数。对于每一个类,将其作为+1 类,而其余M-1 个类的所有样本作为-1 类。构造一个二分类SVM 将第i类与其他M-1类分开,即求解如式(5)所示的二次规划问题:
其中,t表示样本的索引,i∈{1,2,…,M}表示共需要训练M个二分类SVM,ηi为第i个分类器的故障检测时间为松弛变量,v∈(0,1]是一个正则化参数。
对于新样本x̂,M个决策函数一共有M个输出,选择决策函数中最大的类i作为对x̂的检测,即对x̂进行分类的决策函数如式(6)所示:
核函数的选择对构造一个具有良好性能的模型来说至关重要。径向基核函数(Radial Basis Function,RBF)的优点是参数少并且具有良好的泛化能力,且由于其与高斯分布的相似性而成为使用最广泛的核函数之一。因此,本文使用RBF 函数作为核函数,用K(x,x̂)表示,如式(7)所示:
其中,σ>0为高斯核函数的带宽。
2.3 改进的自适应算术优化算法
算术优化算法(Arithmetic Optimization Algorithm,AOA)是2021年提出的元启发式优化算法,它的灵感来自算术运算符在解决算术问题中的应用[27],使用简单的算术运算符,如加减乘除作为数学优化,从一组候选解中搜索出符合标准的最优解。AOA 提高了位置更新的全局分散性和在局部区域的精确性。
步骤1设置目标参数和的取值范围;随机生成种群,其初始位置代表参数(,)的初始值;求解初始个体的适应度值,计算方法如式(8)所示:
其中,numi表示被错误检测为第i类故障的个数,C为故障总数,sum为训练样本总数。
步骤2初始化种群后,算法内设置了一个加速函数(Math Optimizer Accelerated,MOA)来控制算法的搜索策略(进行探索阶段或开发阶段),根据随机数r1∈(0,1)进行判断,当r1> MOA 时,进入探索阶段;当r1≤MOA 时,进入开发阶段。加速函数的计算方法如式(9)所示:
其中,C_t和M_t分别为当前迭代次数和最大迭代次数,Max和Min分别为加速函数的最大值和最小值。
与MOA 类似,算法内设置了一个概率函数MOP(Math Optimizer Probability),计算方法如式(10)所示:
其中,α为一个敏感参数,代表了迭代过程中的开发精度,用于控制AOA 在迭代过程中的变化幅度。Abualigah 等[27]的研究表明,不同的α值会影响MOP,从而影响算法的性能。通过实验对比可知,当α<1时,MOP 是一个凸函数,有利于算法前期的充分探索,而不是快速收敛到局部区域。α值较小可能导致算法陷入局部最优,α值较大可能导致搜索不足,甚至找不到最优解,影响算法的效率。因此,本文引入自适应变化的α值,有助于提高算法在探索阶段和开发阶段搜索能力之间的平衡。自适应α值的计算方式如式(11)和式(12)所示:
其中,α(C_t)为第C_t次迭代的α值,αmin和αavg分别表示α的最小值和平均值,f、fmin、favg、fmax分别表示当前迭代时的适应度值、最小适应度值、平均适应度值和最大适应度值,ε表示一个较小的正数。
步骤3探索阶段。根据随机数r2进行判断,当r2<0.5 时,执行除法探索策略,当r2≥0.5 时,执行乘法探索策略,位置更新方程如式(13)所示:
其中:best(Pj)表示当前迭代的最优解的第j个位置;ε表示一个较小的正数,其作用是防止分母为0;UBj和LBj分别表示第j个位置的上界值和下界值;μ是调整搜索过程的控制参数,取值固定为0.5。
步骤4开发阶段。根据随机数r3进行判断,当r3<0.5 时,执行减法开发策略,当r3≥0.5 时,执行加法开发策略,位置更新方程如式(14)所示:
步骤5判断适应度函数值是否在误差允许范围内或已达到迭代上限。若满足条件,则停止迭代,输出故障检测模型的最佳参数组合,记为ν和σ;若不满足,则跳转到步骤2继续执行。
3 实验与结果分析
3.1 实验环境
本文搭建的高可用控制集群系统共有21 个节点,包括1个中心节点和20个计算节点。实验环境配置如下:CPU 为Intel Core i7-10700;内存为16 GB以上;硬盘为512 GB 以上;使用的操作系统为Ubuntu 16.04。
3.2 实验结果分析
根据3.1 节的实验环境配置,本文将提出的基于AOA-MSVM 的控制集群故障检测方法分别与MSVM[28]、PSO-MSVM[29]和GWO-MSVM[30]的故障检测方法进行对比实验。
实验从搭建的集群系统中采集2000 条包含节点信息、网络信息和系统性能等正常数据作为训练数据集。本文分别模拟节点故障、程序故障(如内存泄露)、网络故障和性能异常来获取故障数据。实验将收集的数据和阿里巴巴集群跟踪数据作为训练集。
本文使用准确率、精确率、召回率、F1Micro和检测时间来评估4 种方法的故障检测结果,实验结果如图2~图6所示。
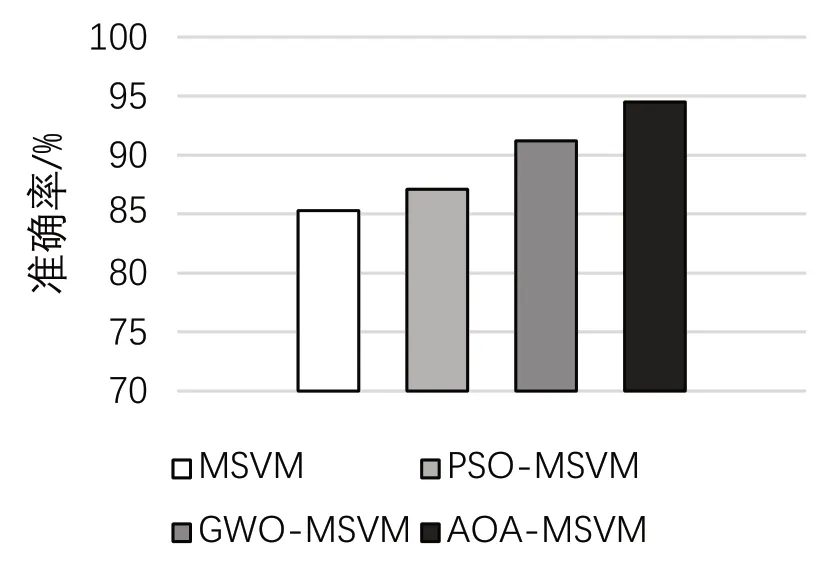
图2 准确率对比
图2 给出了4 种方法的准确率对比。由图2 可知,4 种检测方法的检测准确率都相对较高,且本文提出的方法明显优于其他方法,故障检测准确率可达94%以上。
图3 与图4分别给出了精确率和召回率对比。由图3可知,4种方法精确率较为接近,本文所提故障检测方法精确率稍优于其它方法。由图4 可知,本文所提故障检测方法的召回率达到97.2%,明显优于其它方法。

图3 精确率对比

图4 召回率对比
图5 给出了4种方法检测结果的F1Micro,其是综合考虑了模型精确率和召回率的计算结果。由图5 可知,本文提出的故障检测方法均优于同类方法,表明了本文所提方法的优越性。

图5 F1Micro对比
图6 对4种方法的故障检测时间进行了对比。由图6 可知,本文所提故障检测方法检测时间约为2.47 s,均明显少于其它3 种故障检测方法,缩短了故障检测时间。

图6 检测时间对比
4 结束语
本文针对控制集群系统故障检测问题,提出了一种基于AOA-MSVM 的控制集群故障检测方法。使用LLE 算法对数据进行降维处理,并保持了原始数据性质不变,采用一对多支持向量机来检测集群系统故障,并使用改进的自适应算术优化算法对模型参数求最优解,提升故障检测能力。与同类方法的对比实验结果表明,本文提出的故障检测方法具有更高的检测准确率和效率,并可有效识别故障类型。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
国际眼科杂志(2021年9期)2021-09-15 03:24:42
装备制造技术(2020年2期)2020-12-14 03:09:16
汽车维修与保养(2019年7期)2020-01-06 03:30:42
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
电子制作(2018年11期)2018-08-04 03:25:40
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
汽车维护与修理(2016年10期)2016-07-10 08:17:41
中国卫生(2015年12期)2015-11-10 05:13:34
