
基于累积置信规则库推理的台风灾害直接经济损失预测*
2024-01-18 06:41杨隆浩高建清
灾害学 2024年1期
张 恺,杨隆浩,高建清,郑 晶
(1. 福建船政交通职业学院 信息与智慧交通学院,福建 福州 350007;2. 福州大学 经济与管理学院,福建 福州 350116;3. 福建江夏学院 电子信息科学学院,福建 福州 350108)
台风灾害是全球发生频率最高、影响最严重的灾害[1]。我国的沿海地区频频受到台风灾害的侵袭,且伴随着巨大的经济损失和人员伤亡。据《中国气象公报》统计,2011-2020年,我国台风累计直接损失已达到6 651.8亿元人民币[2]。台风灾害直接经济损失的统计具有滞后的特点,这给应急响应工作带来一定的难度。因此,深入研究台风灾害与直接经济损失之间的关系,并对台风灾害直接经济损失进行预测,更好地评估台风灾害带来的损失,进而完善应急减灾救灾体系,这对台风灾害应急管理具有重要的研究意义[3- 4]。
为了有效评估台风灾害损失,国内外学者已经提出了若干的台风灾害评估模型。例如,TAN等[5]提出了基于单值中智集的熵,并将其应用于台风灾害评估中。随后,TAN等[6]又提出基于博弈理论和灰色理论的决策支持方法对台风灾害进行评估;陈莉婷等[7]探究了台风灾害的模糊性,应用模糊证据推理对台风灾害风险进行评估;潘金兰等[8]应用层级分析法和TOPSIS方法构建了台风灾害风险评估模型;卢耀健等[9]运用组合权重和模糊随机方法建立了台风灾害风险评估模型。但是需要指出的是,随着台风灾害损失的预测对于准确性要求的提高,基于数据驱动的预测模型逐渐成为台风灾害评估的主要研究方向。例如,李博等[4]提出改进的神经网络模型对广东省台风灾害经济损失进行预测;于小兵等[10]应用可计算一般均衡模型对广东省台风“山竹”带来的损失进行评估;林江豪等[11]提出神经网络和支持向量机模型相集结的台风灾害经济损失评估模型;周纳等[12]提出模糊神经网络算法对台风灾害损失进行预测;DU等[13]应用极度梯度提升树和随机森林相结合的机器学习方法对台风灾害损失进行评估;WANG等[14]通过案例推理方法预测台风灾害经济损失的空间分布;ZHENG等[15]应用案例检索方法对台风灾害进行评估以便于快速做出应急响应。
上述研究成果为基于数据驱动的台风灾害评估与预测奠定了一定的基础,但是仍存在以下几个问题:首先,基于决策模型的评估方法缺少对历史数据的合理利用,导致预测与评估的准确性不够高;其次,基于数据驱动的台风灾害评估与预测通过历史数据提升了评估与预测的准确性,但是忽略了决策者对模型可解释性的需求。
扩展置信规则库(Extended Belief Rule Base,EBRB)推理模型[16]采用IF-THEN规则存储信息,不仅对模糊性和不确定信息具有较强的表达能力,训练过程简单,而且在可解释性上具有独特的优势[17,18]。EBRB被广泛地应用于评估和预测问题中,如,环境治理成本预测[19]、桥梁风险评估[20]、交通事故预测[21]。台风灾害直接经济损失与台风灾害相关属性息息相关,并具有大量的数据,然而已有的预测模型鲜有考虑到直接经济损失与台风灾害信息之间的关系,以及数据驱动为导向的模型。此外,台风灾害直接经济损失对于模型的低复杂性和可解释性具有较高的要求。鉴于此,本文将引入EBRB对台风灾害进行预测。但是考虑到台风灾害可能存在大量数据的情形,有可能造成EBRB中过量的规则和组合爆炸。因此,需要针对基于EBRB的台风灾害直接经济损失预测进一步深入研究。
针对上述的问题,本文提出基于累积置信规则库(Cumulative Belief Rule Base,C-BRB)的台风灾害直接经济损失评估模型。首先,引入聚类方法和证据推理(Evidence reasoning,ER)方法构建C-BRB,提升了案例的可解释性并克服了组合爆炸问题;其次,基于EBRB和ER提出累积推理过程,克服了规则的不一致性,从而提升推理结果的精确度;最后,通过台风灾害直接经济损失预测进行实例研究,验证本文提出模型的可行性和有效性。
1 基于EBRB的台风灾害直接经济损失预测模型
1.1 台风灾害直接经济损失预测中EBRB的表示
EBRB是由扩展置信度规则构成的,则第k(k=1,…,L)条扩展置信规则库表示为:
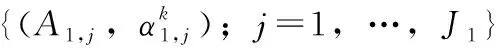
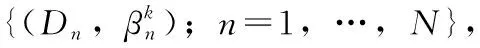
(1)

在台风灾害直接经济损失预测中,当前置属性房屋损坏和死亡人口的评价等级为低,中和高,输出指标直接经济损失指数的结果等级为低和中时,则关于台风灾害直接经济损失指数的扩展置信规则表示为:
Rk:IF房屋损坏 is{(低,0.3),(高,0.6)} and 死亡人口 is {(低,0.7),(中,0.3)},THEN 直接经济损失指数 is {(低,0.5),(中,0.5)}.
(2)
1.2 台风灾害直接经济损失预测中EBRB的建模
为了确保台风灾害直接经济损失预测的准确性,需要依据历史数据和专家知识构建EBRB。构建流程(图1)和步骤如下:
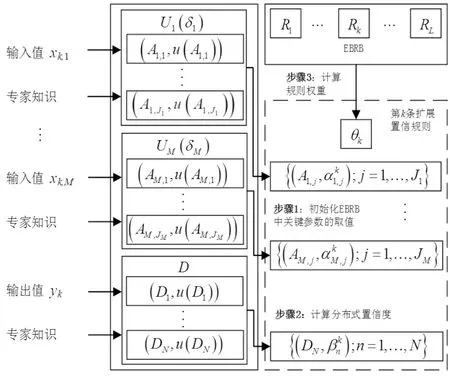
图1 EBRB的构建流程
步骤 1:通过参数优化模型确定EBRB中关键参数的取值。在构建EBRB时,根据专家知识可以确定前置属性Ui(i=1,…,M)中评价等级的效用值u(Ai,j),输出属性D中评价等级Dn(n=1,…,N)的效用值u(Dn)和所有前置属性的属性权重δi。
步骤 2:将数值转化为置信度分布。首先,收集台风灾害直接经济损失预测问题的数据
(3)
基于此,得到第i个前置属性式置信度分布:
(4)
同理,根据式(2)得到输出数据的置信度分布:
(5)
步骤3:计算每条扩展置信规则的规则权重θk。通过计算两两规则之间的前置相似性(SRA)和输出相似性(SRC),来确定规则权重:
(6)
(7)
然后,计算第t条扩展置信规则库的不一致度,其计算公式如下:
(8)
最后,根据不一致度,计算规则权重:
(9)
1.3 台风灾害直接经济损失预测中基于EBRB的规则推理
在EBRB构建的基础上,通过EBRB规则推理,从而进行台风灾害直接经济损失预测,其基本流程如图2所示。

图2 基于EBRB的预测基本流程
EBRB规则推理的基本流程如下:
步骤1:计算个体匹配度。假设台风灾害直接经济损失指数预测问题的输入值为x=(x1,…,xM,根据式(2)将其转换为置信度分布形式:
S(xi)={(Ai,j,αi,j);j=1,…,Ji},
(10)
然后,计算第k条扩展置信规则中第i个前置属性的个体匹配度,公式为:
(11)
步骤2:计算刺激权重。在步骤1的基础上,第k条规则的刺激权重计算公式如下:
(12)

wk是评估规则是否需要被激活的凭证,即wk>0意味着第k条规则可以被激活,否则意味着该条规则不能被激活。
步骤3:集结激活规则。根据ER算法[23]对被激活规则的输出属性集结为新的置信度分布形式:
βn=
(13)
之后,根据输出属性评价等级Dn上的效用值u(Dn),计算台风灾害直接经济损失指数的预测值:
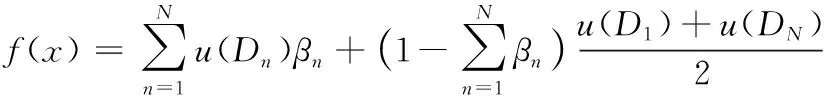
(14)
2 基于C-BRB的台风灾害直接经济损失预测新模型
本节在EBRB预测模型的基础上,通过聚类方法,提出C-BRB模型。同时,针对台风灾害中存在大数据量问题,说明基于C-BRB的台风灾害直接经济损失预测新模型。本节将围绕置信库生成、规则生成和规则合成三个部分介绍台风灾害直接经济损失预测过程,其中主要研究框架如图3所示。

图3 基于C-BRB对台风灾害直接经济损失进行预测
2.1 基于C-BRB的置信库生成
步骤1:规则聚类。根据每个扩展置信分布的最大置信度,可以确定多个相似置信度的规则集合。假设RCj1…jM为与前置属性的M个参考值Ai,ji(ji∈{1,…,Ji};i=1,…,M)相关的规则集合,则相应的扩展置信规则集合可以表示为:
(15)
步骤2:累积置信库生成。针对每个规则集合RCj1…jM,将所有属于RCj1…jM的扩展置信规则通过证据推理方法进行集结,生成新的扩展置信规则如下:
(16)
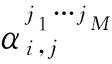
2.2 基于C-BRB的扩展置信规则生成
步骤1:计算累积扩展置信规则的刺激优先级。假设累积置信库R有M个参考值集合{Ai,j;j=1,…,Ji}用来评价第i个前置属性,那么,第i个前置属性的刺激优先级定义为:
(17)
在此基础上,计算累积规则Rj1…jM(Rj1…jM∈R)的刺激优先级:
(18)
步骤2:确定刺激扩展置信规则集合。当累积置信规则的优先级等于最小的所有累积置信规则的刺激优先级时,该累积置信规则将被认定为输出数据 的刺激规则,那么,得到如下的刺激规则集合:
(19)
根据2.1节中的累积EBRB置信规则库的构建和2.2节中的置信规则生成过程,可以为台风灾害直接经济损失预测问题构建基于C-BRB的预测模型。接下来,对台风灾害直接经济损失预测过程做进一步介绍。
2.3 基于累积EBRB的台风灾害直接经济损失预测
步骤1:计算刺激权重。当台风灾害直接经济损失预测的新数据为x=(x1,…,xM)时,依据1.2中的步骤2转换为置信度分布形式;再根据1.2中的步骤1确定输入数据的刺激规则集合AR(x);接着,计算每个刺激规则Rj1…jM(Rj1…jM∈AR(x))的刺激权重:
(20)
步骤2:集结刺激规则预测台风灾害直接经济损失成本。当所有刺激规则的刺激权重确定后,选取刺激权重大于0的扩展置信规则作为刺激规则,根据1.3中的步骤3集结刺激规则获取置信度βn。随后,根据设置的输出属性在每个评价等级上的效用值u(D1)≤u(D2)≤…≤u(DN),得到台风灾害直接经济损失预测值:
(21)
3 实例分析
3.1 台风灾害数据来源与属性确定
台风灾害数据采用2005-2018年的中国气象灾害年鉴中的热带气旋灾情表中的数据,每个台风只选取登陆点的灾害数据,从中选取直接经济损失值大于0 的记录,一共有113条。灾害信息属性包括:失踪人口A1(人)、死亡人口A2(人)、受灾人口A3(人)和转移安置人口A4(人),房屋损坏A5(万间),损害面积A6(万hm2),登陆时风速大小A7(m/s)和登陆时风速级别(A8),直接经济损失A9(亿元),GDPA10(亿元),人口密度A11(人/km2)。
台风灾害所在年份的社会环境会影响灾情数据,因此需要对灾害信息数据进行调整。通过将A1、A2、A3和A4除以该台风当年人口密度进行调整,指标简称分别为B1,B2,B3和B4;将A9除以该台风当年GDP进行调整,指标简称为B9。因此,预测模型中的问题属性包括调整后的B1,B2,B3和B4,以及A5,A6,A7和A8;预测属性为调整后的属性B9。表1显示了所有输入输出指标的描述性统计分析。

表1 输入输出指标的描述性统计分析
3.2 台风灾害直接经济损失指数预测过程
首先,根据1.2节的步骤1,得到C-BRB直接经济损失预测模型参数的初始取值(表2)。所有前置属性的初始权重均设为1,前置属性和输出属性的评价等级均分为3个等级。进而根据步骤2,转换为置信度分布形式,以规则1为例,其置信度分布如表3所示。
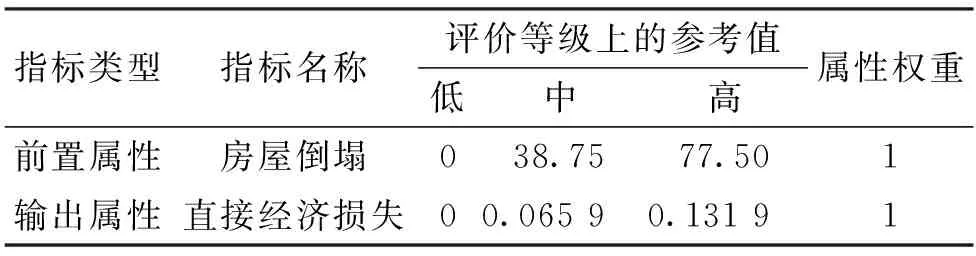
表2 直接经济损失指数预测参数的初始取值
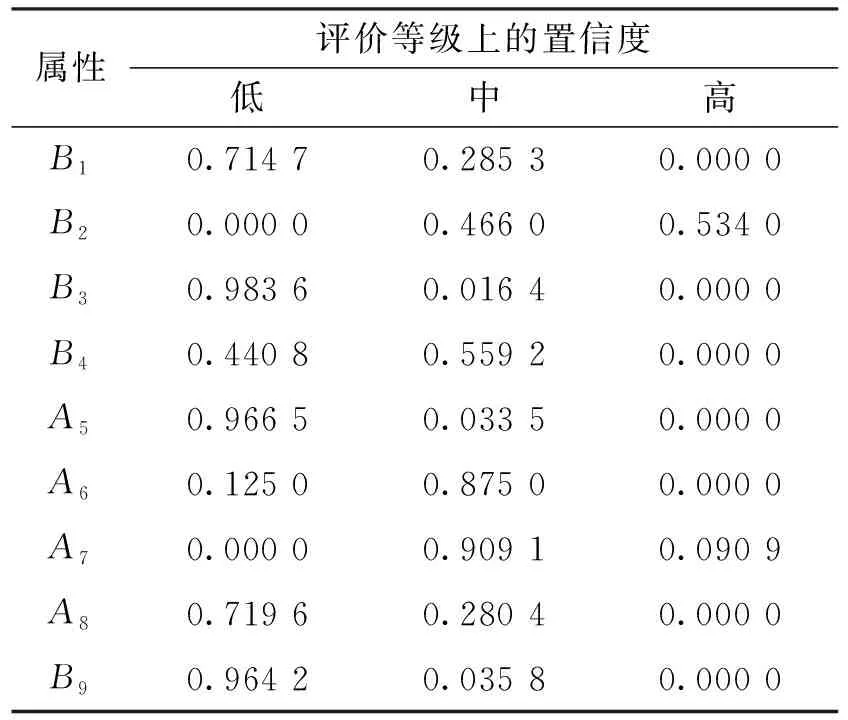
表3 规则1前置属性和输出属性的置信度分布
然后,数据集按照8∶2的比例分为训练集和测试集,通过2.1小节构建C-BRB,进而应用2.2小节计算刺激权重,并根据2.3小节合成激活规则,从而得到结果,训练集的预测结果与真实结果比对如图4所示。
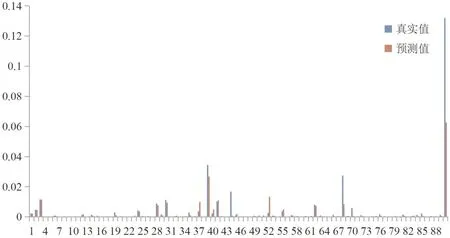
图4 训练集的预测结果与真实结果的比对
在训练的基础上,测试集数据的预测结果,得到预测结果与真实结果的比对(图5)。从图5可知,大部分的测试集的预测结果与真实结果的拟合度较好,除了个别规则存在一定差异,这是因为不同台风灾害,其数据的统计可能存在一定的差异,对直接经济损失评估等采用的策略不同。
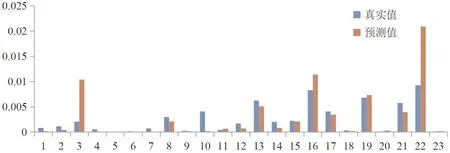
图5 测试集的预测结果与真实结果的比对
最后,根据运行状态得到运行参数指标(表4)可知,基于C-BRB的台风灾害直接经济损失模型的精确度较高,运行速度较快,能够快速为相关部门专家提供决策参考,尽快做出应急响应,降低台风灾害带来的直接经济损失。
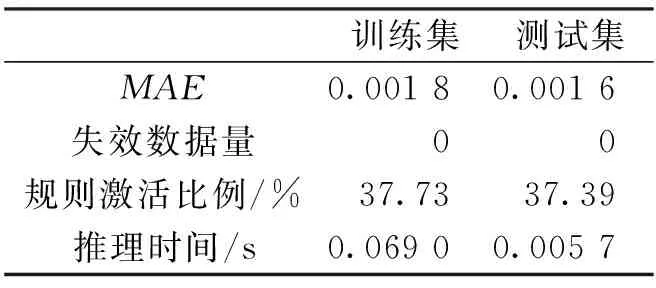
表4 基于C-BRB的直接经济损失指数预测模型运行参数
3.3 预测模型的准确性与有效性分析
为了进一步说明C-BRB在台风灾害直接经济损失指数预测中的优越性,本节将EBRB和案例推理(Case-Based Reasoning,CBR)[24]模型与C-BRB进行性能比较。同时,将转准确率作为评价指标。用平均绝对误差(MAE)和对称平均绝对百分比误差(SMAPE)进行比较。三种不同预测方法的准确性对比结果如表5所示,其预测值与真实值的对比如图6所示。从表5可知,基于C-EBRB模型的运行结果不管在MAE还是在SMAPE指标上都高于EBRB和CBR方法。为了进一步说明本文方法的精确性,进一步比对三种方法的预测值和真实值,结果如图6所示。
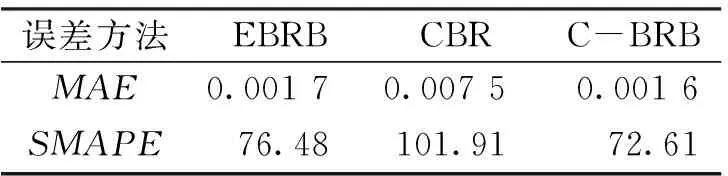
表5 不同方法预测准确性对比分析

图6 三种方法预测结果与真实数据的比较
从图6中可以明显发现,C-BRB方法预测的结果有更多的案例更加贴近真实值,除个别点与真实值比较偏离,大部分与真实值的差距较小。因此,基于C-BRB的台风灾害直接经济损失指数预测模型具有较高的准确性。
此外,为了更进一步比较本文模型的优越性,从三种方法的技术层面进行研究分析。基于C-BRB的预测模型在面对大数据量时,首先通过聚类方法生成置信规则库,不仅降低了模型运行时间,同时也提高了模型的精确度。此外,C-BRB模型通过扩展置信度规则对案例进行表示,且其是一个白箱算法,具有较好的可解释性能,这对于应急决策专家快速做出有效的应急响应起到了至关重要的作用。因此,良好的可解释性可以辅助决策专家更好地了解模型及其给出的决策支持。三种方法的性能比较结果如表6所示。

表6 三种方法的性能比较
4 结论与讨论
为了解决台风灾害直接经济损失预测中精确性和可解释性问题,本文在EBRB的构建与推理的基础上,通过聚类方法和ER方法对扩展置信规则进行累积,进而构建基于C-BRB的台风灾害直接经济损失预测模型。最后以收集并整理后的我国2005-2018年的台风灾害数据为例,说明本文提出模型的预测过程和结论。本文的主要研究结论有:
1)现有的台风灾害损失评估模型往往忽视了历史数据对于预测模型构建的效用。因此,本文提出了基于C-BRB的台风灾害直接经济损失预测模型,克服了以往模型在数据驱动情形下的局限性。
2)针对预测模型的可解释性对于决策者做出准确决策的重要性,通过EBRB模型的IF-THEN规则表示提高模型的可解释性,避免决策者的认知不足而做出不够精确的决策。
3)大量的台风灾害数据可能造成过量的扩展置信规则及集结爆炸问题,通过聚类方法和ER方法构建累积扩展置信规则,进而进行累积扩展置信规则的推理,提升了EBRB模型在台风灾害预测中的性能。
4)在实例分析中,以收集并整理后的我国2005-2018年的台风灾害数据为例,验证本文提出方法的可行性、准确性和优越性。此外,本文提出的预测模型也为其他灾害损失预测提供有效的预测工具。
5)台风灾害具有动态性,累积置信规则库推理在此情形下的应用有待进一步探索,今后将深入研究考虑台风灾害演变的直接经济损失预测,并拓展置信规则库推理使其适用于时间序列的预测,进一步提高直接经济损失预测的精确度。
猜你喜欢
交通财会(2023年9期)2023-10-29
水利水电快报(2022年8期)2022-11-23
核科学与工程(2021年4期)2022-01-12
中国毕业后医学教育(2021年3期)2021-12-02
中国毕业后医学教育(2021年3期)2021-12-02
陶瓷学报(2021年2期)2021-07-21
计算机应用(2018年5期)2018-07-25
中华老年多器官疾病杂志(2016年9期)2016-04-28
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
轴承(2015年2期)2015-07-25
