
基于spark平台的跨境电商产品混合式协同推荐
2024-01-17 09:57李佳颖
贵阳学院学报(自然科学版) 2023年4期
李佳颖,刘 静
(1.广州南洋理工职业学院 经济管理学院,广东 广州 510900;2.喀什大学 计算机科学与技术学院,新疆 喀什 844000)
跨境电商作为进出口贸易的重要组成部分,该行业的持续发展直接影响我国整体经济增速。[1]近年来,关于跨境电商产品采购预测、用户分析、产品推荐等成为研究热点,跨境电商产品推荐作为促进跨境电商产业高效发展的重要手段,在跨境电商研究中占据重要地位。[2]跨境电商平台由于用户文化差异、语言文本多样化、用户需求变化速度快等特点,要实现电商产品的高效精准推荐单靠一种策略很难完成,混合式协同推荐具备更稳定的电商产品推荐性能。[3]
当前,关于电商产品推荐的研究较多,杨单等借助大数据分析技术进行用户和商品的特征分析,以找到用户和商品特征,从而为用户定制化推荐产品;[4]张瑾等将异质图运用于用户和产品的关联分析,挖掘两者共有特征然后实现产品推荐,两者均采用单一策略对跨境电商产品推荐,其推荐性能均有一定提升空间。[5]本文将LFM与K-means算法结合,实现混合式协同推荐,有效提升推荐准确度,并借助Spark运算优势,保证混合式系统推荐的高效执行。
1 电商产品的混合式系统推荐
1.1 电商产品推荐
电商产品推荐的实质是找到用户和商品属性的内在相似度,根据用户和商品多维特征间的差异,搜索与用户特征差异较小的商品,并推荐给用户。
在电商产品推荐过程中,有两个因素直接影响推荐的精准度,一方面,参与比较的用户和商品特征,另一方面,特征比较算法。根据跨境电商平台的用户浏览及购买历史,得到用户和商品次数矩阵,通过矩阵可以为用户推荐曾经购买过的历史产品。但若要为用户推荐新产品,还需要根据用户和商品的特征差异值,设参与特征对比的组数为N,每组特征差异函数为Si,则商品推荐的优化函数为:
(1)
式(1)中ωi为权重。根据商品推荐优化函数,采用合适算法不断求解特征差异最小值,选择与用户差异最小的商品作为候选推荐。
1.2 用户—商品评分
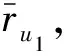
(2)
式(2)中ru1,p和ru2,p分别为u1和u2对第p个商品的评分。
假设跨境电商平台的m个用户为U={u1,u2,u3,…um},n个商品为I={i1,i2,i3,…in},根据u1和u2用户相似度,则可以计算任意用户对商品的评分。其中用户j对商品k的评分为:
(3)
遍历该用户对所有资源的评分值,选择较高评分值作为候选推荐商品。
2 混合式商品推荐
2.1 基于隐语义模型(LFM)
设用户u对隐含特征k的关注度为Puk,商品i在隐含特征k的重要程度为Qki,那么用户u对商品i的评分为[6]:
(4)
式(4)中K为参与运算的所有特征。Pu和Qi分别为用户u和商品i针对于所有隐含特征的关注度和重要度矩阵集合。
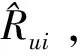
(5)
损失函数为[7]:
(6)
对上式加入正则项:
(7)
分别对关注度和重要程度求导得:
(8)
(9)
根据求得结果,不断更新关注度和重要程度,更新方法为[8]:
(10)
(11)
当获得稳定的Pu和Qi,则可以确定LFM模型。
2.2 K-means聚类算法
设空间中两点i和j之间距离Sij为[9]:
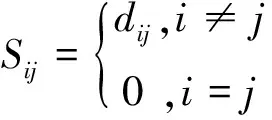
(12)
设包含n维属性的中心点为xi(xi1,xi2,xi3,…,xin),那么某个非中心点xj(xj1,xj2,xj3,…,xjn)和xi距离为[10]:
(13)
对比dij与距离阈值,当dij小于阈值表示xj与xi属于相同类别。ε表示xi与该类中其他点的误差。
(14)
N(xi)的含义为N个点中去除了xi的其他点,限制条件是∑j,xj∈N(xi)Sijxj=1,Sij≥0 。
化简公式(14)得[11]:
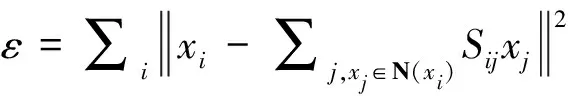
(15)
那么K-means的聚类转化为求解公式(16)[12]:
minε
(16)
2.3 K-means初始簇中心的鲸群优化
鲸群优化算法(WOA)通过鲸鱼在捕食过程中的位置变化来搜寻规定范围内的最优解,通过不同鲸鱼角色的运动特点来完成最佳适应度个体的选择。WOA个体的位置更新方法是[13]:
(17)
(18)

(19)
(20)
鲸鱼螺旋攻击方法为:
(21)
其中b为常量,l为rand[-1,1]。
鲸群获得食物坐标后,采用概率p决定是采用包围捕食还是螺旋攻击:
(22)
每次更新位置后,都计算当前个体的适应度值,输出适应度最优个体。
2.4 基于LFM和WOA-K-means混合式系统推荐
将LFM和WOA-K-means算法相结合,通过LFM评分函数获得候选商品推荐序列,然后通过WOA-K-means聚类获得与用户同类别的商品。最后综合两种策略获得的商品序列,则作为混合式协同推荐的商品。
3 基于Spark平台的混合式推荐部署和流程
Spark作为大规模并行运算的常用处理方式,能够有效提高电商产品的推荐效率。在混合式系统推荐过程中,LFM的关注度矩阵和重要度矩阵运算,K-means的类别误差最小化求解,以及WOA的运动位置迭代更新,都需要强大的运算能力和运算效率的支持。通过多机并行及RDD运算,[15]可以有效增强跨境电商产品的混合式协同推荐。同时Spark MLlib库[16]集成了多种深度学习库,这也为混合式协同推荐提供了便利。LFM和WOA-K-means运算的Spark部署方法如图1所示。

图1 基于Spark平台的混合式推荐部署
4 实例仿真
为验证LFM和WOA-K-means混合式协同商品推荐算法的性能,分别对四家跨境电商平台进行仿真分析,数据集如表1所示。首先,验证LFM算法、K-means算法、LFM和K-means算法、LFM和WOA-K-means算法分别对四个跨境电商平台的商品推荐性能,然后分别验证单机和Spark平台下的商品推荐效率。

表1 跨境电商平台集
4.1 LFM与WOA-K-means的协同推荐性能
采用LFM和WOA-K-means 2种算法进行跨境电商产品的协同推荐,分别选择不同的TOP推荐数,统计其推荐指标如表2所示。

表2 LFM与WOA-K-means的协同推荐性能
从表2可知,采用LFM与WOA-K-means的协同跨境电商产品推荐中,三个推荐指标值随着推荐商品数量的增多而增加。在推荐商品数量为TOP2时,其推荐的准确率等指标均在0.3左右,而当推荐数量上升至TOP10后,其跨境电商产品的推荐准确率均达到了0.83以上,而到达TOP15后,其产品推荐准确率达到了0.9以上。对于相同推荐商品数,平台C的推荐性能更优,这表明LFM与WOA-K-means协同推荐算法对平台C的适用度最高。
采用单机进行LFM与WOA-K-means的混合式协同推荐,测试样本数为2000,分别统计不同产品推荐数量下的推荐时间。

表3 LFM与WOA-K-means协同推荐时间
从表3可知,对相同平台,其推荐TOP数量的改变对推荐时间影响较小,基本维持在90 s左右,这说明采用LFM与WOA-K-means的协同推荐,其算法稳定时得到的推荐序列数与计算时间没有较强的关联。同时对比不同平台发现,在相同数量样本的协同推荐中,电商平台A和B的完成推荐耗时更少。
4.2 独立推荐和混合协同推荐性能对比
分别采用LFM算法、K-means算法、LFM和K-means算法、LFM和WOA-K-means算法进行跨境电商产品推荐,对比单一推荐和混合式协同推荐的性能差异。

图2 LFM与WOA-K-means协同推荐准确率(TOP2)

图3 LFM与WOA-K-means协同推荐准确率(TOP10)
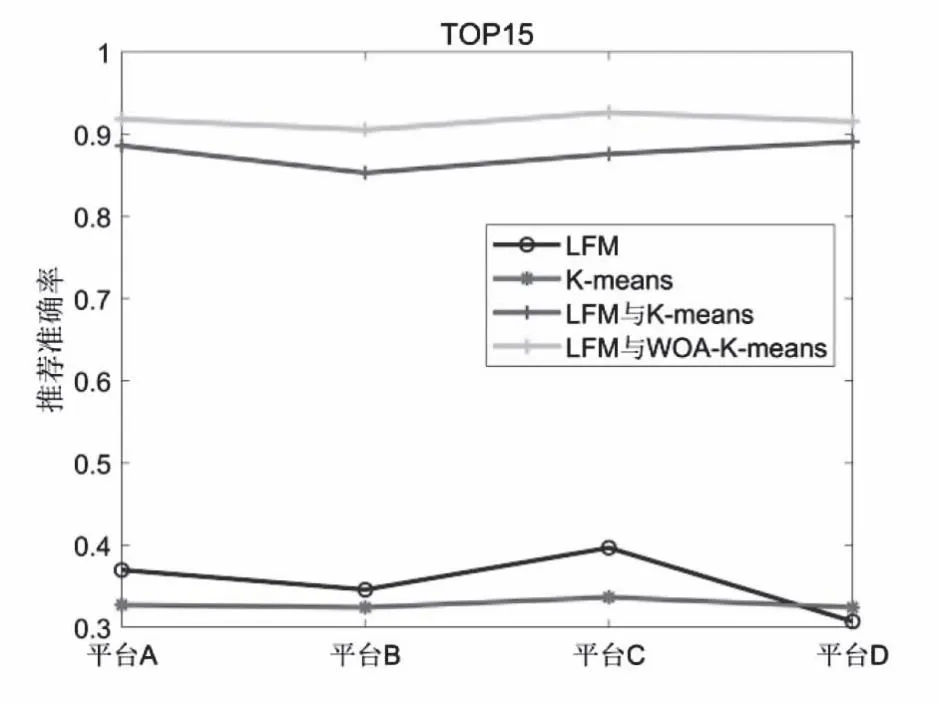
图4 LFM与WOA-K-means协同推荐准确率(TOP15)
从图4可知,对相同的商品推荐数量,不同模型的推荐准确率存在较大差异。相比较而言,通过K-means的用户和商品特征聚类得到的候选推荐序列并不是用户期望得到推荐的商品,其推荐准确率均在0.35以下,而LFM挖掘用户和商品特征语义得到的相似推荐准确率也不超过0.4,说明采用这两种方法的独立推荐其效果并不理想。而通过LFM和K-means协同完成推荐,其准确率均提升100%以上,再加入WOA算法对K-means优化后,其推荐准确率值有了进一步提升。
对比不同推荐序列数量,在TOP2时,四种算法的电商产品推荐准确率均较低,这说明四种算法均不能实现电商产品的精准推荐。而当推荐序列达到TOP10以上后,协同推荐准确率上升明显。
4.3 Spark平台的推荐效率
从四个跨境电商平台中分别选择不同数量的样本构成六个容量不同的数据集,分别是[S-100K,S-400K,S-1M,S-10M,S-100M,S-1G]。采用LFM与WOA-K-means协同推荐,计算单机和Spark模式下的推荐效率,Spark平台包含三个节点,单机仅包含1节点。

图5 单机和Spark的协同推荐效率
从图5可知,对不同容量电商集,LFM与WOA-K-means协同推荐算法部署至单机与Spark平台的推荐效率呈现不同结果。对于容量为100K和400K的样本集,Spark的并行计算优势体现并不明显,而当容量超过100MB时,Spark平台的协同推荐相比于单机,其效率得到明显提升。在容量为1GB时,单机需要400秒以上才能实现推荐序列生成,而Spark平台仅需50多秒。
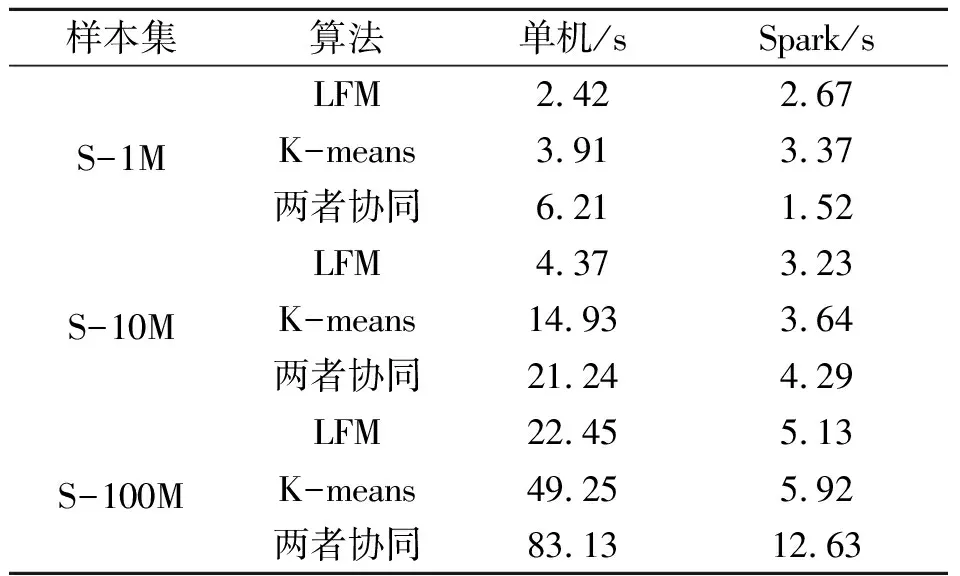
表4 不同算法的推荐效率
从表4可知,在样本容量较小时,对于LFM算法,其单机推荐效率更高。因为采用Spark平台节点间任务通信需要耗费时间,其他情况下,三种算法均在Spark平台相比于单机更节省推荐时间。
5 结论
采用LFM与WOA-K-means算法用于跨境电商产品的混合式协同推荐,可获得较高跨境电商产品推荐准确度。并将LFM与WOA-K-means均部署至Spark平台,提高了大规模混合式协同推荐效率。
猜你喜欢
新疆钢铁(2021年1期)2021-10-14
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国外汇(2019年20期)2019-11-25
中国外汇(2019年14期)2019-10-14
中国外汇(2019年21期)2019-05-21
航天工业管理(2019年11期)2019-04-20
中国交通信息化(2018年5期)2018-08-21
能源(2017年9期)2017-10-18
