
基于机器学习构建住院患者深静脉血栓风险预测模型的系统评价
2024-01-16 11:30杨楠楠蒋慧萍史婷奇
护理学报 2023年23期
杨楠楠,蒋慧萍,史婷奇,
(1.南京中医药大学鼓楼临床医学院,江苏 南京 210008;2.南京大学医学院附属鼓楼医院 护理部,江苏 南京 210008)
深静脉血栓形成(deep venous thrombosis, DVT)是住院患者常见的并发症[1],不同疾病患者在住院期间DVT 的发生率为0.2%~85.0%[2], 因DVT 引起肺动脉栓塞(pulmonary embolism, PE)而死亡的住院患者占比为5%~10%[3]。 因此,早期识别住院患者发生DVT 的可能高危因素,及时制定针对性的预防或干预措施尤为重要[4]。 当前,静脉血栓栓塞的风险预测仍以纸质量表(如Caprini、Autar 等)为主,但对于术后、肿瘤患者等不同情况的住院患者来说,传统量表预测或评估结果特异性偏低[5,17]。 且量表中纳入的部分血液指标等数据难以直接获取, 导致预测准确率并不理想,难以客观反映不同人群DVT 的潜在风险。当前基于机器学习构建的DVT 风险预测模型在国外率先引起研究热潮[6]。 机器学习,作为计算机科学更广泛领域中人工智能的一个子集。 其原理是基于算法从海量数据中学习内在规律, 实现对未知样本的预测[7]。 现已成为医学领域常用的研究方法之一。 基于机器学习技术对住院患者电子病历进行患者特征提取来构建DVT 风险预测模型的相关研究日益广泛[8]。 本研究对该研究领域相关文献进行全面检索、整理与质量评价,旨在推动高质量预测模型在住院患者DVT 领域的应用,为未来相关研究的改进与实践提供参考依据。
1 资料与方法
1.1 方法 本研究依据系统评价和荟萃分析优选报告项目 (Preferred Reporting Items for Systematic Reviews and Meta-Analyses,PRISMA)进行报告[9]。
1.2 纳入与排除标准 纳入标准: (1)研究对象为年龄≥18 岁的住院患者; (2)研究内容为基于机器学习算法构建住院患者深静脉血栓风险预测模型,且模型经过内部和(或)外部验证;(3)以中文或英文发表。
排除标准:(1)因静脉血栓栓塞相关并发症而住院的住院患者;(2)未描述模型构建过程或方法的文献;(3)不能获取原文或数据不完整;(4)会议摘要、学位论文、重复文献。
1.3 文献检索策略 检索中国知网(CNKI)、万方数据知 识 服 务 平 台、PubMed、Embase、Cochrane Library、CINAHL、Web of Science, 时限为建库至2023 年3月。中文检索词为深静脉血栓、DVT、机器学习、深度学习、支持向量机、人工神经网络、极限梯度提升、随机森林、人工智能、预测模型。 以主题词+自由词检索。 语言限制为中文或英文。PubMed 数据库检索策略见图1。

图1 PubMed 数据库检索策略
1.4 文献筛选与资料提取 2 名研究者根据纳入与排除标准独立完成文献筛选和数据提取工作, 出现分歧时, 由第3 名研究者协助决策。 提取文献信息为:作者、发表年份、研究对象、数据来源、DVT 发生率、建模模型、模型预测性能、验模方法、主要预测因子等。
1.5 纳入文献的质量学评价 使用预测模型构建数据提取和质量评价清单 (Checklist for Critical Appraisal and Data Extraction for Systematic Reviews of Prediction Modelling Studies, CHARMS[10])对 纳 入研究进行偏倚风险与适用性评价。 CHARMS 包括数据来源、参与者、预测结局、预测因子筛选、样本量、缺失数据处理、模型建立、模型性能、模型评价、性能结果、讨论共11 项条目。 2 名研究者分别使用上述工具对纳入文献作数据提取与质量评价, 意见不一致时可讨论, 若仍有分歧则由第3 名研究者作最终决策。
1.6 统计学分析 本研究从偏倚风险与适用性2个方面评价纳入文献。综合方法学质量较高的文献,描述性分析预测模型的特征与性能。
2 结果
2.1 文献筛选流程及结果 数据库检索共获得859篇文献,经过查重、多次复筛后,最终纳入文献13篇[11-23],其 中3 篇[11-12,23]中 文 文 献,10 篇[13-22]英 文 文献。 文献筛选流程见图2。
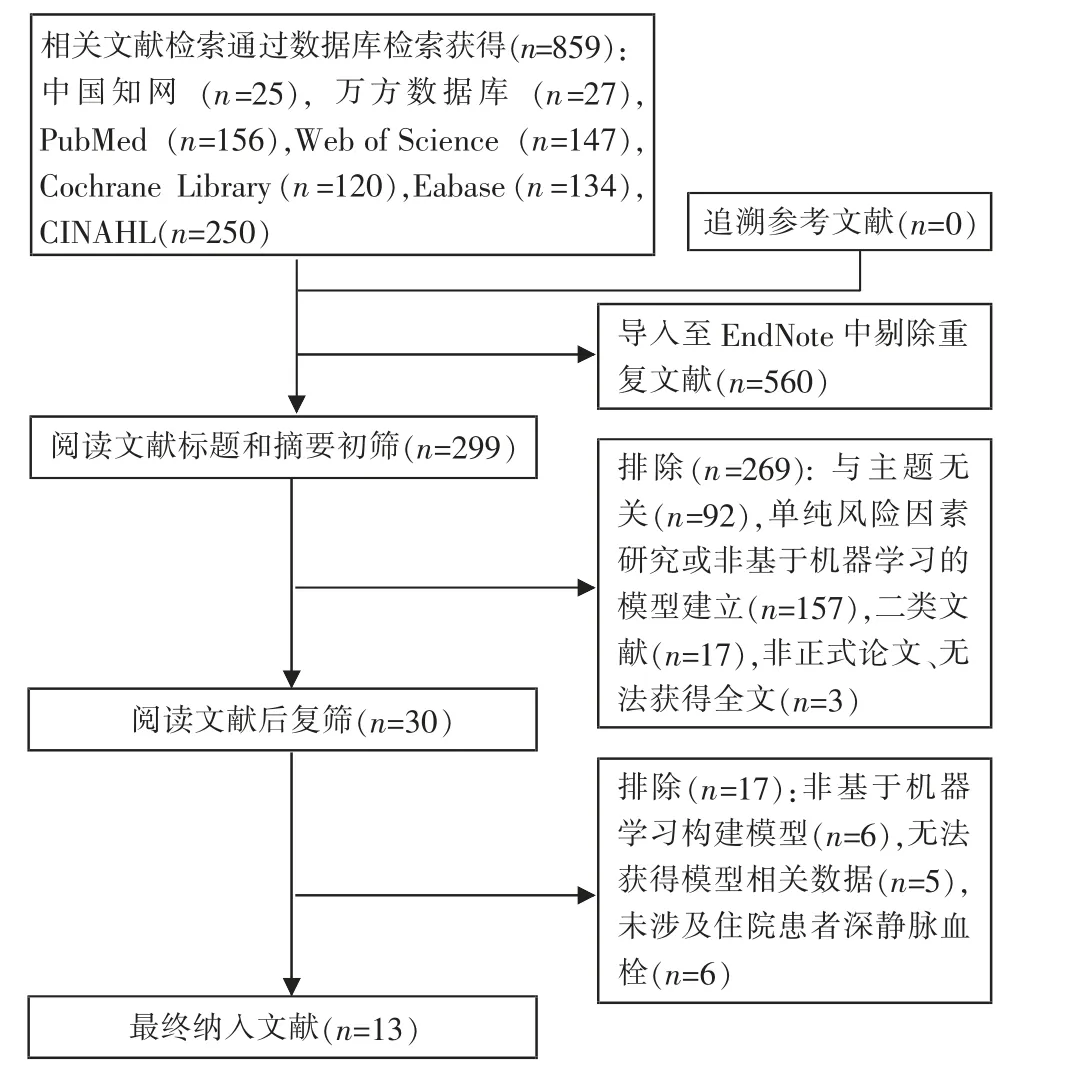
图2 文献检索流程图
2.2 纳入文献基本特征 纳入研究的基本特征见表1。 纳入研究的发表时间集中于2021—2023 年。其中,7 项研究[11-13,17,20,21-23]在国内开展,6 篇[14-16,18-19,21]文献在国外开展;研究类型方面,13 篇文献均为回顾性研究;研究对象分布方面,术后住院患者6 篇[11-16]、常规住院患者3 篇[17-19]、肿瘤住院患者3 篇[21-22]、妊娠住院患者1 篇[23]。 DVT 发生率为0.95%~50%。

表1 纳入文献的基本特征
2.3 纳入文献偏倚风险与适用性评价 使用CHARMS 对13 篇文献作偏倚风险与适用性评价,在全部11 项评价项目中,有2 篇文献[12,23]“不清楚”与“高风险”结果数量﹥5,即整体方法学质量较低,因此在本环节舍弃,不进入下一环节的数据提取、分析与讨论。 13 篇文献偏倚风险与适用性评价见表2。
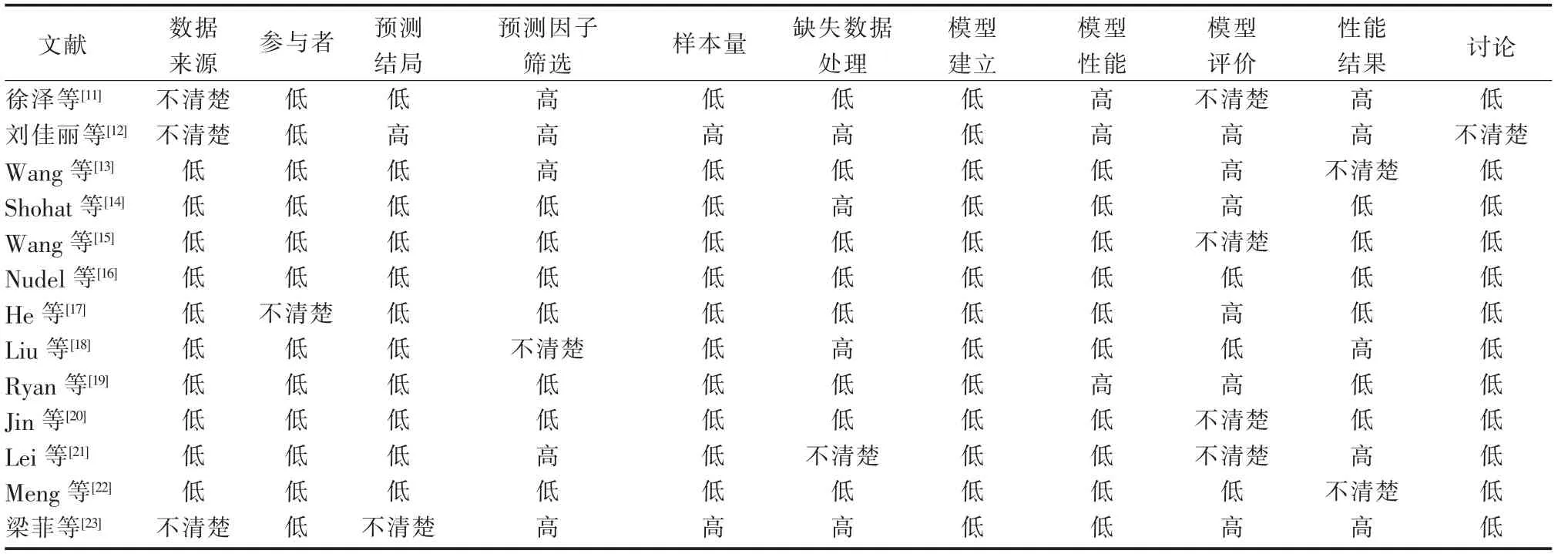
表2 纳入文献偏倚风险与适用性评价
对余下11 篇[11,13-22]文献进行偏倚风险与适用性评价。在纳入研究模型偏倚风险评价中,“模型评价”与“结果”项目偏倚较大:“模型评价”项目中所有文献均未采用外部验证,仅部分文献[16,18,22]明确汇报了验证数据的调整与校准过程。“结果”项目中,多数文献未明确汇报训练集与验证集的预测变量以及缺失数据的分布情况。 “数据来源”、“样本量”、“模型建立”项目偏倚风险低:“数据来源”项目中11 篇文献均为病例对照类研究或队列研究。 因此整体获得低偏倚风险评价。 “样本量”中11 篇文献均达到CHARMS建议,因此整体获得低偏倚风险评价。“模型建立”项目中所有文献均明确汇报了模型开发过程中的数据分配情况与建模工具的选择等, 因此整体获得低偏倚风险评价。
在纳入研究模型适用性评价领域中。 “数据来源”项目中:多数文献[11-14,17-23]采用的是研究医院的内部数据库,易丢失数据或缺少重要预测因子,使得预测模型的适用性受到影响, 因此整体适用性水平较低。 “预测因子筛选”中部分文献[11,13,18,21]未明确汇报是否盲筛预测因子或未体现筛选过程, 因此获得“高风险”或“不清楚”评价。 其他项目中多数文献表述规范,符合CHARMS 中模型适用性建议,但由于所有文献均未进行外部验证, 因此本次描述性分析中涉及的11 篇文献整体模型适用性水平一般。
综上,本次研究最终筛选出的11 篇较高质量文献的整体偏倚风险较低,预测模型适用性水平一般。
2.4 模型构建情况 最终纳入的11 篇[11,13-22]文献。患者特征提取数为14~108 个, 样本量为573~94 657例;随机森林模型(Random Forest, RF)7 次、逻辑回归(Logistic Regression, LR)7 次、决 策 树(Decision Tree, DT)1 次、 极限梯度提升 (Extreme Gradient Boosting, XGBoost)7 次、支持向量机(Support Vector Machine, SVM)5 次、人工神经网络(Neural Network,NNET)1 次。多篇研究[11,13-14,16-18,20,22]构建了2 种及2 种以上的机器学习模型作性能对比;11 篇文献均明确汇报了数据库与数据来源, 数据类型均为文本型数据。 其中,2 篇文献[15-16]使用了国家级开源数据库; 建模工具方面,11 篇文献均明确汇报了 建 模 工 具 与 软 件 包;9 篇 文 献[11,13,15-18,20-22]明 确汇报了数据缺失现象及插补方法,使用均值填充、中位数填充或KNN 插值等方法作数据处理。详情见表3。
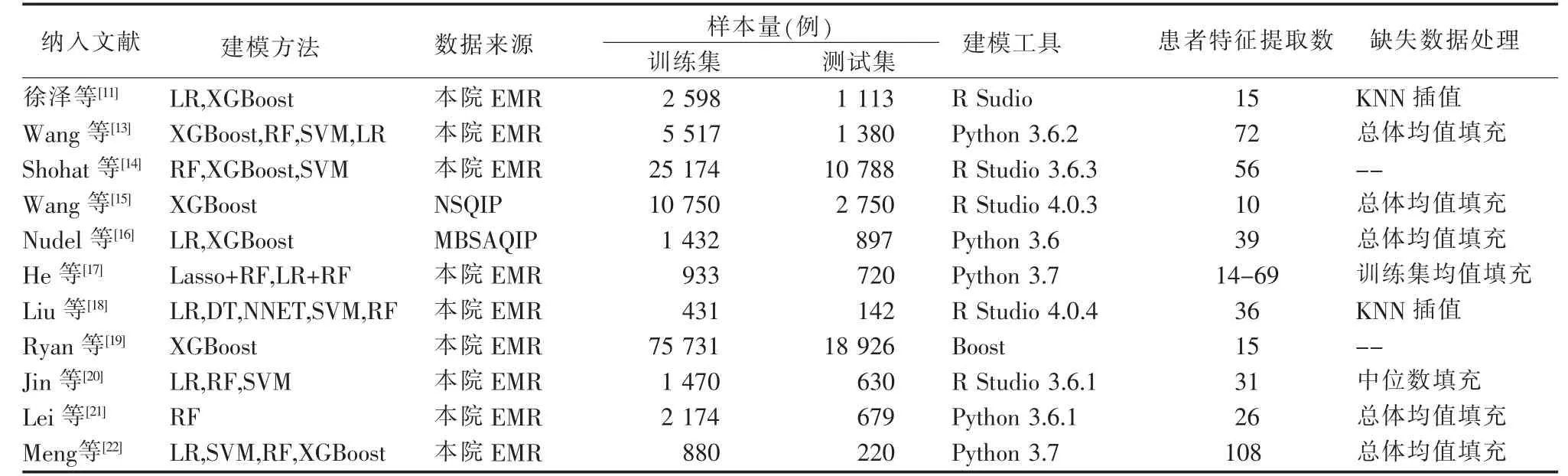
表3 11 篇较高质量文献的模型特征
2.5 模型性能和预测因子 该环节筛选了上述11篇文献中的推荐模型, 详情见表4。 从分布趋势上看,共7 篇文献[11,13-16,19,22]认为XGBoost 为推荐模型。其中在术后住院患者这一亚群体中, 5 篇[11,13-16]文献均认为XGBoost 可作为术后住院患者深静脉血栓风险预测模型的推荐模型; 其他亚群体深静脉血栓风险预测推荐模型的分布相对分散。
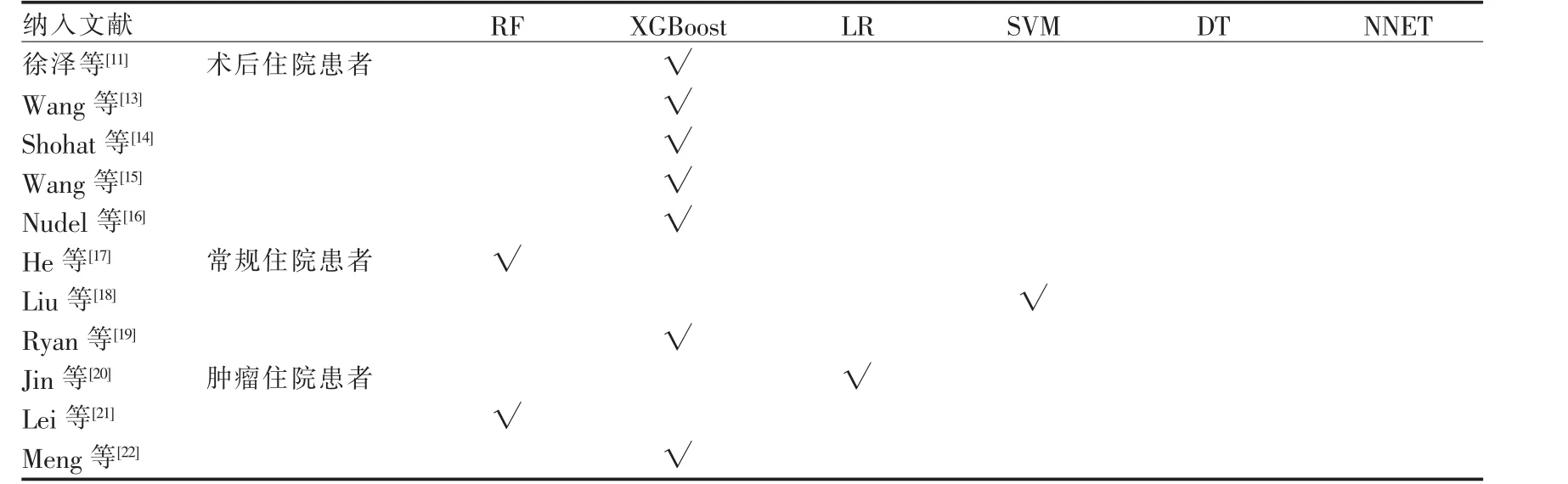
表4 纳入文献推荐模型
该环节提取了上述推荐模型的性能特征,详情见表5。 11 篇文献均详细报告了模型性能指标与效果评价。 11 个代表模型曲线下面积(Receiver Operating Characteristic,ROC) 得分为0.710~0.976, 准确率(Accuracy,AC)为71.0%~95.7%;8 篇文献[13,15,17-22]明确汇报了过度拟合问题的处理; 纳入的主要预测因子共74 个,Wang 等[13]的研究结果与结论侧重于模型性能报告,文中未见主要预测因子的总结与排序。对于住院患者整体而言,主要预测因子集中于年龄、血栓史、D-二聚体、住院时间、肿瘤史等因子。 术后住院患者、常规住院患者、肿瘤住院患者、妊娠住院患者等4 类亚群体相较于住院患者整体而言, 预测因子具有一定的特异性。

表5 纳入文献推荐模型性能特征
3 讨论
3.1 纳入文献整体偏倚风险较低,预测模型适用性水平一般 本研究纳入的11 篇文献在研究设计与模型开发过程中设计较为规范, 但在模型评价偏倚风险层面,纳入文献均为单中心的内部验证研究,缺乏外部验证的数据支持。 整体方法学质量较高:(1)纳入文献均为队列研究或病例对照研究, 纳排标准明确、规范,最大程度的减少了选择性偏倚,预测模型的适用性水平得以提高。 (2)纳入文献的28 个模型中,所有推荐模型ROC 得分≥0.7,说明基于机器学习构建的风险预测模型可以准确地预测住院患者深静脉血栓的潜在风险。部分文献[11,13-14,16-18,20,22]构建了多种模型,对预测性能进行横向对比,从而得出推荐模型和重要程度更高的主要预测因子。如He 等[17]研究团队将随机森林模型结合Caprini 量表对创伤后住院患者深静脉血栓形成作模型建构并内部验证,将其与随机森林、Caprini 量表的预测性能分别对比。 结果显示随机森林与Caprini 量表的结合预测性能表现突出,预测性能在三者中表现最佳。(3)纳入文献的研究对象足够细化具体,对亚群体的模型个性化构建,如术后住院患者、肿瘤住院患者等深静脉血栓风险预测模型的构建,极大提高了各预测模型的准确性和普适性。(4)然而,纳入文献中部分模型构建过程也存在数据来源非开源、 预测因子筛选非盲法的情况,这可能会引起模型的过度拟合,一定程度上加大了研究的偏倚风险[23],且降低了模型的适用性。
3.2 相关预测模型发展迅速,研究对象有进一步细化分层的趋势 本研究系统检索了国内外机器学习模型在住院患者深静脉血栓风险预测模型的相关研究,发现多数文献的发表年份集中,发展迅速。且多数已有研究对于住院患者这一群体有更进一步的细化分层,如术后患者、常规住院、肿瘤患者、妊娠患者等。这一趋势直接或间接地提高了预测模型的准确性,对于后续研究有着重要的参考意义。 另外,由于不同国家或地区的医疗护理标准、文化背景等诸多方面的差异,且多数研究并没有进行外部验证,因此,部分高质量模型的适用性与可推广性仍有待进一步验证[24]。 未来研究者可以考虑多中心、大样本研究,加强前瞻性研究,同时重视外部验证,开发出可同时满足标准化、个性化、实用性与适用性的预测模型,弥补传统量表机械、普适性不强等方面的不足[25],发挥人工智能、数据挖掘在医疗领域“治未病”的巨大潜力。
3.3 XGBoost 模型在术后住院患者中的预测性能突出 本研究通过对住院患者的进一步划分, 发现XGBoost 模型在术后住院患者这一亚群体中的预测模型性能表现突出。 Ryan 等[19]在文献中指出XGBoost模型是一种集合学习技术, 它结合了多个决策树的结果来创建预测分数。 当该模型遇到数据更为庞大的电子病历系统时, 通过电子病历系统自动输入变量,纳入更多的数据点,其预测性能往往比普通模型更佳[26]。 术后住院患者的电子病历不仅包含术后的医疗护理和生理数据,还包括术前、术中的评估与生化检查等庞大数据量[27],这些数据在传统量表或普通预测模型中往往被忽略[5],具备集合学习技术的XGBoost 模型恰好符合了大数据时代对于高处理速度、高处理能力与识别复杂关联能力的严苛要求。这也与Lu[28]和Kumar[29]等的观点一致。 上述研究团队分别证明了XGBoost 在前交叉韧带重建术后患者过夜入院和肩关节置换术后患者临床结局风险等级划分的积极作用。其他预测模型如LR,RF 等在肿瘤住院患者的深静脉血栓风险预测中也表现了不俗的预测能力,其预测性能均优于传统预测方法[17,20]。
3.4 年龄、VTE 史、住院时间、用药史、D- 二聚体凝血酶原活动度是预测住院患者深静脉血栓风险的重要因素,生化指标发挥重要作用 本研究结果显示,高龄、D-二聚体阳性、具有VTE 史、住院时间长、凝血酶原活动度低等因素是引起深静脉血栓形成的高危因素,在术后住院患者、常规住院患者或是肿瘤住院患者群体中均有不同程度的影响。这与目前临床常用预测工具Caprini 预测指标有重叠部分[30],也反映了交叉预测因子的可验证性。 但重点有所转移,基于机器学习的预测模型多采用自动输入的方式导入了电子医疗记录的数据, 更多的生化、实验室指标被纳入,且在预测性能中发挥重要作用,提高了预测模型的准确率。 如凝血酶原活动度、血细胞比容等。
3.5 基于机器学习算法构建住院患者深静脉血栓风险预测模型的应用建议 深静脉血栓风险预测模型作为发现并识别住院患者静脉栓塞的有效工具,可以早期筛查和识别高危人群、高危因素,从而预测目标人群发生深静脉血栓栓塞的潜在风险[6]。 这对于患者身心健康、医院医疗护理质量、社会资源均有较高的研究价值与意义。如利用机器学习算法模型对患者病情进行分类和预测[31]、为医师制定治疗方案、护士发现潜在健康问题,制定相应护理措施提供有力依据。 但不可否认的是,本次研究所纳入的研究在模型构建与模型验证等方面仍存在局限性。如缺乏外部验证、样本量不足、缺少多中心研究等。后续研究应尽量开展成熟模型外部验证的普适性研究,从而建立完善、全面的风险预测信息平台,充分发挥人工智能与数据挖掘技术对医疗卫生行业的正向促进作用。
3.6 本研究局限性 本研究纳入文献在患者住院原因、模型算法、结局评价指标等存在差异,数据异质性较大,文献数量相对较少,因此未对提取到的数据资料进行量性整合分析。此外,本研究纳入文献以中等质量为主,且多为回顾性研究,无法验证纳入模型的实际预测效果。 未来研究可聚焦于某一特定群体与算法进行量化分析, 如本文中XGBoost 预测模型对术后住院患者深静脉血栓形成的预测作用。
4 结论
本研究纳入11 篇文献,包含28 个住院患者深静脉血栓风险预测的机器学习模型。 研究显示,该领域相关文献整体方法学质量较好,文献偏倚风险评价较低,预测模型适用性水平一般。 不同亚群体住院患者所采用的机器学习模型有所侧重。传统预测工具中所忽视的生化、实验室指标在机器学习模型的预测性能中发挥了重要作用。但多数模型在验证过程中缺少外部验证与多中心研究,这在一定程度上影响了模型的稳定性和外推性。 未来研究中,相关研究人员可结合临床实际, 进一步利用成熟的机器学习算法开发、整合、应用、优化住院患者深静脉血栓风险预测模型,来有效预防深静脉血栓及相关并发症的发生。
猜你喜欢
新作文·小学低年级版(2022年6期)2022-08-30
中老年保健(2021年8期)2021-12-02
家庭影院技术(2021年2期)2021-03-29
基层中医药(2020年10期)2020-11-27
建材发展导向(2019年10期)2019-08-24
淄博师专论丛(2019年1期)2019-04-04
基层中医药(2018年4期)2018-08-29
哈尔滨医药(2016年1期)2017-01-15
中国卫生(2016年7期)2016-11-13
铁道通信信号(2016年1期)2016-06-01
