
基于多模态投影的激光雷达点云实时语义分割网络
2024-01-15 07:49:16唐彬洪
汽车工程师 2024年1期
唐彬洪
(重庆交通大学,重庆 400074)
1 前言
在自动驾驶领域,激光雷达传感器因可提供丰富的场景信息和具有极强的抗干扰能力而获得广泛应用。激光雷达点云语义分割可为三维点云分配语义标签,并为地图增加语义信息,从而提高驾驶的准确性和安全性。
在以往的研究中,研究人员提出了各种深度学习模型来处理激光雷达三维点云,如基于点的方法、基于稀疏体素的方法和基于二维投影的方法。基于点的方法包括PointNet[1]、PointNet++[2]。PointNet 使用点云逐点多层感知机(Point-wise Multi-Layer Perceptron,Point-wise MLP)对每个输入点逐点计算。PointNet++在其基础上提出了采样(Sampling)和分组(Grouping)模块整合局部邻域。PointCNN[3]使用点云卷积(Point Convolutions)方法,引入X 变换(Χ-Transformation)使点云经卷积变换后的输出不变。RandLA-Net[4]同样使用点云逐点多层感知机,引入轻量级神经网络结构,依赖随机采样和本地特征聚合器考虑空间关系和点的特征,获得更大的邻域。这些基于点的方法直接应用于无序三维点云,不会造成任何信息损失,但采用的邻域搜索方式等相对耗时。
激光雷达三维点云具有稀疏性,因此,可基于体素(Voxel)的方法将三维点云量化为三维网格。VoxelNet[5]利用三维卷积配合图像语义分割中的全卷积网络(Fully Convolutional Network,FCN)结构来处理三维体素数据。黄润辉等[6]提出三维锥形栅格解决了激光点云的稀疏性和密度不一致性问题。基于体素的方法可使点云数据规则化,但体素化本身会带来离散伪影和信息丢失,在选择较高分辨率时会出现计算效率低与占用内存大的问题。
基于二维投影的方法将成熟的二维卷积神经网络(Convolutional Neural Networks,CNN)应用于三维点云投影的二维网格特征图。FCN[7]将原网络中的全连接层替换为卷积层。RangeNet++[8]尝试使用K 近邻算法(K-Nearest Neighbor,KNN)作为后处理方法,而SANet[9]将空间相关性与空间注意力结合作为预处理方法。
综合基于点的方法能保存完整点云信息与基于二维投影的方法能保证实时性的优势,本文提出基于多模态投影的激光雷达点云实时语义分割网络架构,分别使用点到网络(Point to Grid,P2G)和网格到点(Grid to Point,G2P)模块同时在鸟瞰图和距离视图的二维网格上投影并提取语义特征,通过空间注意力模块聚合特征,再输入到特征融合金字塔模块,结合初步处理的三维点云输出分割预测结果。然后,利用提出的多模态投影增强点云特征信息,通过空间注意力模块处理投影后的二维网格特征图,并在二维全卷积网络中加入三重下采样模块提升下采样性能。最后,利用SemanticKITTI 数据集对网络的速度和精度进行测试。
2 多模态投影点云分割
要实现准确、快速的激光雷达点云语义分割,不仅需要高效提取语义特征,还需要保留完整的点云信息。基于二维投影的方法可以有效降低算法的计算量,并通过鸟瞰图和距离视图保留完整的点云信息。本文提出的点网格融合模块如图1 所示,融合步骤为:点到网格模块将输入的点特征投影到鸟瞰图和距离视图上;空间注意力模块由注意力模块和上下文模块组成,经过空间注意力模块提取的特征输入二维全卷积网络提取语义特征,注意力模块使用较大的感受野获取空间分布信息,学习较为重要的特征,上下文模块使用不同感受野聚合上下文信息,融合大小不同的感受野;使用二维全卷积网络处理二维特征图有效提取语义特征;网格到点模块将二维网格特征传输到三维点上;点融合模块将初步处理的三维点、鸟瞰图和距离视图分支的特征融合,以确保点云信息完整。
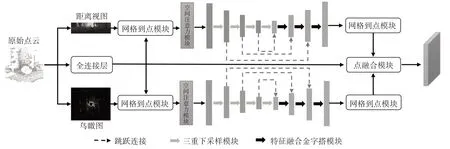
图1 点网格融合模块
2.1 点到网格模型
点到网格模型旨在将三维点特征转换为二维网格特征图。如图2 所示,首先需要选择合适的网格大小,然后将第k个三维点投射到二维网格获取相应的二维坐标集合Rh,w包含落在同一二维网格(h,w)中的点的索引,即,其中分别为uk、vk的整数部分,通常将uk和vk坐标四舍五入到最接近的整数,并将点储存在相应的网格单元中。三维特征通过每个通道c取最大三维特征点的特征值形成相应的二维网格特征,计算公式为:
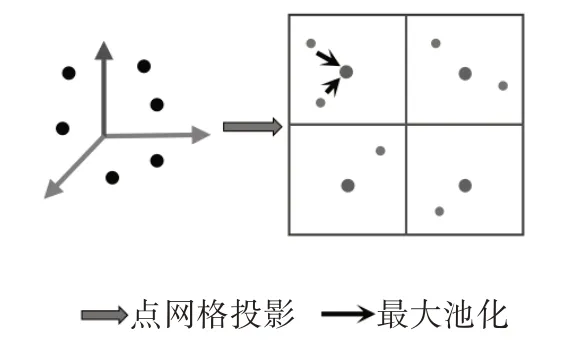
图2 点到网格操作
鸟瞰图省略了高度维度,即z维度,而距离视图则省略了距离r维度。因此,将这两种视图互补可减少二维投影的信息损失。它们所使用的点到网络模型类似,只是在二维投影方式上有所不同。鸟瞰图使用矩形二维网格离散化,通过矩形二维网格(xmin,ymin,xmax,ymax)将三维点云投影到x-y平面上,该平面的离散度为宽度Wbev和高度Hbev:
式中,rk、θk、φk分别为距离、垂直角、方位角。
然后将θk和φk离散化,忽略rk,获取距离视图的宽度Wrv和高度Hrv:
式中,f=fup+fdown为激光雷达的垂直视角;fup、fdown分别为垂直视角的上、下部分。
鸟瞰图分支接收形状为(Wbev=600,Hbev=600)的二维特征图,范围为(xmin=-50,ymin=-50,xmax=50,ymax=50)。范围视图分支接收形状为(Wrv=1 024,Hrv=16)的二维特征图。对于每个网格单元,根据其内部点的特征值通过最大池化操作计算聚合的特征。
2.2 空间注意力模块
空间注意力模块分为注意力模块和上下文模块。在鸟瞰图和距离视图中,上下文相关性主要体现在车辆和行人对道路有很强的依附性,即车辆和行人周围的像素极大概率属于道路的类别标签。空间分布规律体现在物体类别在空间分布中的相关性和一般规律,即行人和植被的旁侧像素大概率属于道路。此外,基于激光雷达生成点云的方法可以看出,在距离视图中道路一般处于图像中轴与底线位置。
如图3 所示,分别将点到网格模型处理后的二维网格特征图输入注意力模块和上下文模块。
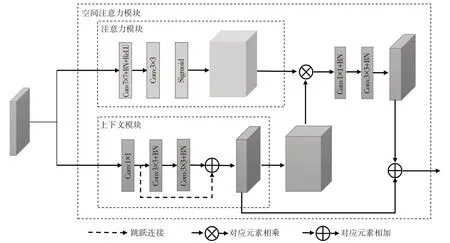
图3 空间注意力模块
注意力模块通过大尺寸卷积获取较大感受野并使用Sigmoid 函数将权重归一化到0~1 范围内,对每个通道进行缩放。上下文模块使用1×1卷积和空洞卷积改变通道数量并增大感受野,通过融合不同尺度的特征图获得更准确的上下文信息,最后,将两分支输出结果对应元素相乘获得空间注意力特征。此外,将上下文模块分支的输出结果与空间注意力输出结果相加,以进一步更新空间注意力特征。
2.3 二维特征金字塔融合模块
采用编码器和解码器架构的二维全卷积网络分别应用于鸟瞰图和距离视图提取语义特征。编码器以ResNet[10]为基础,采用4个编码器和3个解码器,即9 层的轻量级骨干网络。两视图采用类似的二维全卷积网络,但视图范围没有沿高度维度进行下采样。特征通道数分别设置为64、32、64、128、128、96、64 和64。高分辨率特征图可显示更多细节,如轮廓、边缘、纹理等,而低分辨率特征图包含更多的语义信息,如表征道路、大型建筑物等,解码器使用特征金字塔进行上采样并融合高层和低层特征图。
在下采样阶段,为保留更多的信息,基于丰富块(Inception Block),本文提出三重下采样模块。使用3个包含二维卷积和二维最大池化的分支分别进行特征提取,最后将通道数相加,经过线性整流函数(Rectified Linear Unit,ReLU)层输出结果。三重下采样模块使用1×1 卷积可以减少参数的积累,在提高网络深度的同时提高宽度且减少了模型参数,保留了更多信息,如图4所示。
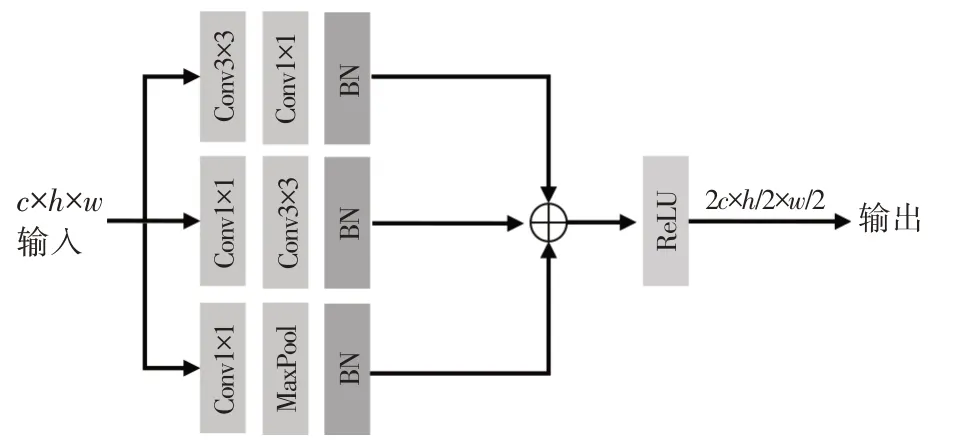
图4 三重下采样模块
2.4 网格到点模型
与点到网格操作相反,网格到点模型从二维网格中每个单元格提取特征重新映射到三维点。如图5 所示,它在4 个相邻网格内应用双线性插值,即确定与点相关的4 个相邻网格单元,它们是最接近点的单元格。为进行插值,计算点与这4 个相邻单元格的距离权重。对于每个特征,根据权重和这4个单元格的特征值进行插值操作。计算公式为:
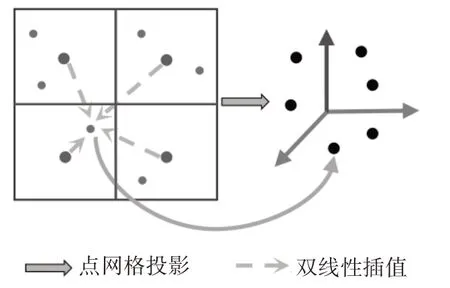
图5 网格到点操作
式(5)考虑了点云位置(uk,vk)到目标网格位置(i,j)的距离。对于边缘点,超出视图范围的相邻网格视为无效网格。
2.5 点融合模块
点融合模块融合来自原始点云、鸟瞰图和距离视图的点特征。通过向量拼接(Concatenate)操作合并特征通道,使融合模块同时考虑鸟瞰图和距离视图的语义信息。与SuMa++[11]中的分割网格不同,本文不采用后处理模块,只通过点融合模块使用特征联合和多层感知机层作为最后的输出结果,实现端到端框架。
鸟瞰图和距离视图的分辨率不同,导致投影到二维网格的点范围不同。虽然在某个视图中,被投影到二维网格范围外的点的特征被视为无效,但它可以传递另一个视图的信息。本文设置超出鸟瞰图视图范围,但在距离视图范围内的点被视为有效点并传递相应距离视图点的特征信息。
2.6 损失函数
分割预测通过一个全连接层对上一层点融合模块的输出特征进行处理,获得分割预测结果。受激光雷达点云数据的特点,以及激光雷达点云语义分割数据集各类标签的数据量不平衡的影响,语义分割网络在学习训练中对小类别语义分割存在困难。在同帧数据中,例如道路、汽车、植被、建筑等的环境要素的像素占比明显高于摩托车、行人等类别。而对比整个数据集数据量中的类别,道路、人行道和建筑物在数据集中的比例是行人和骑行者的数百倍。数据的极不平衡使语义分割网络在训练中更加倾向高占比类别,而难以提取和预测低占比类别。为减少由数据不平衡导致的语义分割网络的性能损失,本文采用加权交叉熵损失来强调低占比类别:
式中,yc为真实标签为预测概率;Fc为类别c在整个数据集中的频率;αc为类别c的权重;ε为一个很小的正数,防止除零错误;C为数据集的类别数量。
3 验证分析
为评估本文算法的性能,选用SemanticKITTI 数据集进行训练和测试。该数据集包含43 552 帧360°雷达扫描点云数据,划分为22 个序列。序列00~序列07与序列09~序列10共19 130帧点云数据作为训练数据集,序列08 共4 071 帧数据作为验证数据集,序列11~序列21 共20 351 帧点云数据作为测试数据集。选用Velodyne VLP-16 激光雷达,具有垂直方向16 线光束,每帧扫描约3.2×104个点。采用平均交并比(mean Intersection Over Union,mIoU)评估算法的表现:
式中,S为类别数;Ti为类别i的真正值数量,即模型正确预测为类别i的数量;Fi为类别i的假正值数量,即模型错误预测为类别i的数量;Ni为类别i的假负值数量,即模型未能正确预测为类别i的数量。
所有测试均使用GeForce RTX 4090 图形处理器(Graphics Processing Unit,GPU)硬件平台完成。
3.1 消融试验
为验证本文算法各模块的有效性,在数据集上进行消融试验,各模块配置情况和试验结果如表1所示。
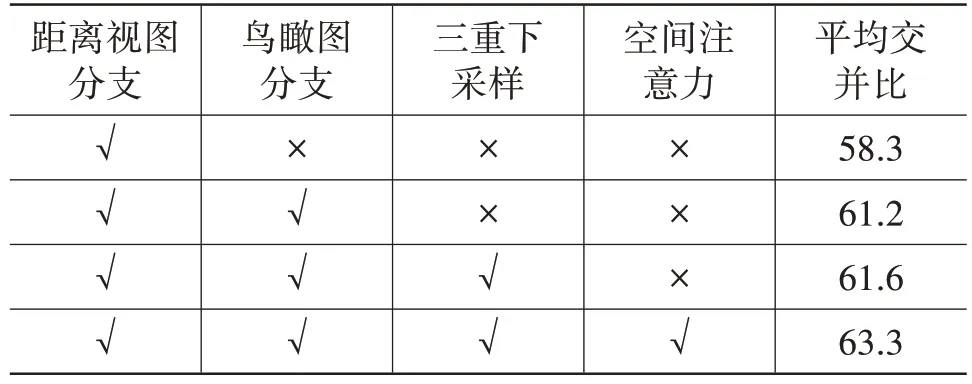
表1 特定融合块分析 %
3.2 性能分析
在SemanticKITTI 测试集上与其他先进算法进行对比,结果如表2 所示。由表2 可以看出:对比RangeNet++,本文算法在精度和速度方面都有所提升,特别是精度明显优于RangeNet++ ;对比SqueezeSegV3,本文算法在精度提升的同时,单帧速度也大幅提升;对比SalsaNext 和MPF,本文算法在速度上略显不及,但在精度上相比MPF 至少提高了7.8百分点,证明了本文提出的多模态投影语义分割网络的高效性。
此外,本文算法与其他算法在序列21上的可视化对比结果如图6 所示。由图6 可以看出,本文算法对于物体的预测在保持高精度的前提下具有很好的稳定性。对于小物体预测,本文算法正确分割了“行人”这一对象,而其他算法精度较差,甚至忽略了该对象。

图6 序列21数据集定性分割结果
4 结束语
本文提出了一种基于多模态投影的实时激光雷达点云分割算法,通过点和网格模块实现二维和三维特征图的转换,将空间注意力模块和特征金字塔融合模块有机结合并加入三重下采样模块高效提取重要位置信息,整合了丰富的语义特征信息,结合三维点云、鸟瞰图和距离视图对点云信息进行互补。
通过与RangeNet++、SqueezeSegV3、SalsaNext和MPF 等先进算法进行比较,验证了本文算法在精度和速度方面的优势。可视化结果表明,本文算法在小物体预测方面表现优异,展现出了较高的精度和稳定性。
猜你喜欢
北京测绘(2022年5期)2022-11-22 06:57:43
汽车观察(2021年8期)2021-09-01 10:12:41
数学物理学报(2021年1期)2021-03-29 03:14:42
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25 01:40:34
学生天地·小学低年级版(2019年5期)2019-06-05 01:15:11
学生天地(2019年15期)2019-05-05 06:28:28
中国交通信息化(2019年1期)2019-03-26 06:43:46
电子制作(2018年16期)2018-09-26 03:27:00
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
