
基于深度模型的汉字拼写检查方法
2024-01-15 09:35陈哲,曹阳
南通大学学报(自然科学版) 2023年4期
陈 哲,曹 阳
(东南大学 网络空间安全学院,江苏 南京 211102)
随着中国经济的发展和国际地位的不断提高,汉语在全世界得到了极大程度的普及,越来越多的人们开始学习汉语,并通过使用汉字进行书面交流。汉语是一门复杂的表意语言,在使用的过程中难免会出现拼写错误,影响使用者的正常表达。与英文这类拼音文字相比,拼音文字的拼写错误更多集中于个别字母的增减或错用;而汉字这类象形文字除了由语音相似引起的拼写错误之外,还会因为外形的形状相似而造成使用者的拼写错误。根据Liu 等[1]人的研究,约83%的汉语拼写错误与语音相似性有关,48%的错误与视觉相似性有关。这些汉语中语音或视觉上很相似的汉字,语义却大不相同,使用者的拼写错误将极大改变原本想要表达的句子含义。另外,除了人类书写会造成拼写错误,现如今应用越来越普遍的自动语音识别、光学字符识别也会造成汉字的拼写错误。因此,对汉语的拼写进行检查是有意义的。
汉语拼写检查(Chinese spelling check,CSC)是自然语言处理(natural language processing,NLP)中一项检测和纠正汉语拼写错误的任务,旨在通过使用统计或者深度学习的方法来解决汉语书写错误的问题。尽管最近研究人员在汉语拼写检查领域取得了一些进展,但汉语拼写检查依旧是一项具有挑战性的任务。另外,相比英文的拼写纠错,汉语拼写检查更加注重利用上下文信息之间的关系来进行错字的识别与修改。
以往的汉语拼写检查方法倾向于使用混淆集来查找和过滤候选词。混淆集由不正确的统计数据构成,它在视觉相似对和语音相似对之间有一个映射。Yu 等[2]建议通过检索混淆集,然后利用语言模型对其进行过滤,从而产生多个候选;Wang 等[3]使用指针网络从混淆集中复制类似字符。然而,这些模型只从混淆集中学习一个浅映射,其性能在很大程度上取决于混淆集的质量。而如今随着汉语在各个领域内的使用,很难找到一个最新的混淆集。另外,以往的研究倾向于使用单种模型来进行拼写检查任务,而实际上使用模型组合的方式分别完成检测和纠正能得到更好的效果。
为解决上述问题,本文提出了一个汉语拼写检查模型。该模型由检测网络和纠正网络构成。其中,由双向长短期记忆网络(bidirectional long shortterm memory,BiLSTM)结合条件随机场(conditional random field,CRF)构成的检测网络用于检测视觉错误词与语音错误词。LSTM 是一种循环神经网络模型,相比普通的循环神经网络(recurrent neural network,RNN)模型,LSTM 独特的门机制可以更有效地保存有用信息。利用双向LSTM 则可以同时从前文和后文获取信息。CRF 是一种用来捕获序列潜在特征的机器学习方法,在序列标注问题中有较多应用。将检测出的拼写错误词进行掩盖,输入到基于BERT(bidirectional encoder representations from transformer)模型构成的纠正网络中,纠正网络将结合上下文对掩盖的词进行预测,达到纠正拼写错误词的目的。其中BERT 模型是近些年来最为火热的NLP预训练模型,它及各种演变模型在许多NLP 任务中都大放异彩。在测试集上的实验表明,本文提出的模型得到了先进的结果。
本文的主要贡献如下:
1)提出一个汉语拼写检查模型,该模型能够不依赖于混淆集,并且利用模型组合的优势,对句子中的视觉错误词及语音错误词通过检测模型进行检测,然后利用纠正模型进行纠正;
2)本文所提出的模型在SIGHAN-2015 测试数据集上的评价指标结果比现有的汉语拼写检查方法表现更好。
论文结构安排如下:第1 节介绍汉语拼写检查的相关工作;第2 节介绍本文所提出的汉语拼写检查模型结构;第3 节介绍实验相关设置;第4 节介绍实验的结果和分析;第5 部分对全文工作进行总结。
1 相关工作
许多研究者对汉语拼写检查任务已进行了大量研究。早些年研究者利用N 元语言模型来做汉语拼写检查任务。Xie 等[4]提出一种基于二元和三元语言模型,以及汉语分词的方法;Jin 等[5]使用了一种混合方法来进行汉语拼写纠正。他们集成了3 种模型,包括N 元语言模型、基于拼音的语言模型和基于声调的语言模型,用来提高汉语拼写错误检查系统的性能。
还有的方法将汉语拼写检查视为序列生成问题或序列标记问题。Wang 等[3]引入复制机制以生成纠正序列;Bao 等[6]通过基于块的生成模型统一了单字符和多字符纠正。
随着预训练模型(pre-trained models,PTM)在机器翻译领域大放异彩,研究者们开始将预训练模型引入到CSC 任务中。具体做法为引入掩蔽语言模型(masked language model,MLM)作 为预训 练任务,根据上下文条件预测拼写错误的词并对其进行纠正。基于MLM 可以将混淆集应用于狭窄的搜索空间,以预测正确的字。Cheng 等[7]通过混淆集构建了一个图表,以帮助最终预测;Nguyen 等[8]提出了一个适应性混淆集,但其训练过程不是端到端的;Li等[9]采用一种混淆集引导的掩蔽策略来对掩蔽语言模型进行训练。
最近,一些拼写检查方法还利用了语音特征和视觉特征。Liu 等[10]使用门控循环单位(gated recurrent unit,GRU)[11]将拼音序列和汉字笔画序列编码为额外特征;Xu 等[12]对字符的图片进行编码以获得视觉特征;Li 等[13]利用图卷积神经网络引入拼音和部首信息作为语音和视觉特征;Yin 等[14]采用K 近邻模型结合语音、图形、上下文信息进行拼写纠错。
不同于以往研究者只使用序列标注模型或者预训练模型,本文在总结前人工作经验的基础上,同时使用了这两种模型,并结合模型特点分配检测和纠正任务,从而发挥出不同模型各自的优势,以得到更好的效果。具体来说,本文使用BiLSTM +CRF 的结构构成检测模型,来检测句子中的拼写错误,并对错误词做特殊处理;使用预训练模型BERT作为纠正模型,来纠正检测出的错误词。
另外,本文还在模型中结合了汉字的语音和视觉特征来提升效果。下文将在第2 节介绍提出的模型。
2 拼写检查模型
本文将在这一部分介绍提出的汉语拼写检测模型。模型由检测网络和纠正网络组成,并融入了汉字的视觉特征和语音特征。
2.1 整体模型结构
整体的拼写检查模型结构如图1 所示。不同于只利用序列标注模型或者预训练模型的现有方法,本文提出的方法同时使用了两种模型:1)利用序列标注模型进行错词检测;2)使用BERT[15]模型进行错词纠正。这种方式可以更大程度发挥模型优势,以达到更好的效果。

图1 本文提出的拼写检查模型结构示意图Fig.1 Structure of spell checking model
模型工作流程如下:
1)将待检查句子输入模型进行输入嵌入(input embedding);
2)输入嵌入通过检测网络进行检测,若未检测出错误词,则直接输出结果,否则对错误词进行掩盖嵌入处理;
3)将经过掩盖处理的嵌入输入到纠正网络中进行修改,将得到的输出与输入嵌入进行残差连接作为模型的输出。使用残差连接可以缓解深度模型由于层数过多而导致的梯度消失问题。
2.2 输入表示
在将汉字的表示输进模型之前需要对输入的汉字做嵌入。本文采用类似BERT 模型的嵌入方式对输入的汉字进行嵌入,如图2 所示。具体来说,字符嵌入包含了每个汉字的信息;段嵌入用以记录段落信息;位置嵌入记录不同汉字的位置。除此之外,本文在嵌入中增加了笔画嵌入及语音嵌入。笔画嵌入包含了每个汉字的笔画信息,用以记录视觉特征;而语音嵌入包含了每个汉字的拼音信息,用以记录语音特征。
2.3 检测网络
检测网络旨在检测出句子中拼写错误的字。本文提出使用BiLSTM[16]结合CRF 的方式构成检测网络。条件随机场CRF 是一种无向图模型,它结合了最大熵模型和隐马尔科夫模型的特点,常用于标注或分析序列资料。由于CRF 可以弥补循环神经网络无法捕获序列潜在转移关系的不足,使得BiLSTM +CRF 的结构在命名实体识别、语法检错等领域中有较多应用。鉴于任务的相似性,本文使用类似语法检错的方式对拼写错误的字进行检测。分别给句子中的正常字、语音错误字、视觉错误字赋予不同的标签,如图3 所示。通过检测网络可以给不同的字打上不同的标签:图中达(挞)为视觉错误字,标签为R;高(糕)为语音错误字,标签为V;其他正确字标签为O。
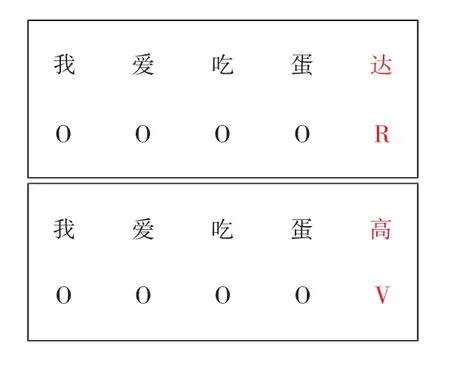
图3 汉字标签示例Fig.3 Chinese character label example
训练检测网络模型能够找到句子中不同类别的拼写错误。检测网络模型如图4 所示。具体来说,将经过嵌入后的字符Ei(i=1,2,…,n)输入到BiLSTM 网络中,将前向输出与后向输出拼接后得到的结果Ti(i=1,2,…,n)输入到CRF 层中,CRF 层将根据Ti的特征及不同Ti之间的转移关系计算出最佳的组合标签序列,以此作为检测模型的输出。

图4 检测网络Fig.4 Detection network
在送入纠正网络之前,需要对找出的错误字进行掩盖(mask)处理。由于错字在视觉上或者语音上与正确字相似,因此,它与正确字之间存在一定的联系。为此本文对找出的错字进行软掩盖(soft mask)[17]处理
其中:θ 为软掩盖参数;Ei表示错误字的嵌入表示,i=1,2,…,n;EM表示掩盖标志的嵌入表示。本文中θ取0.5。对于正确的字,不对其做掩盖处理。
2.4 纠正网络
纠正网络旨在结合全局上下文对掩盖后的字进行预测,以达到纠错的目的。纠正网络主体为BERT 模型,模型架构如图5 所示,图中Ei(i=1,2,…,N)表示嵌入表示,Trm 表 示transformeer 模型。BERT 由双向transformer[18]的编码器构成,基于注意力机制的架构使得BERT 摆脱传统语言模型的束缚,可以同时利用上下文的信息进行预测。另外,纠正网络利用上下文预测掩盖词的任务与BERT 的MLM(mask language model)预训练任务是契合的,因此选用BERT 模型作为纠正网络是合理的。纠正网络接收经过掩盖处理后的嵌入,输出经模型修改后的结果。

图5 BERT 模型架构图Fig.5 BERT model architecture
2.5 预训练任务与损失函数
为了使模型能够达到拼写检查的目的,本文设计了错误词检测-修改预训练任务。错误词检测-修改任务旨在预测句子中错误词的位置,并将该词进行纠正,以此来训练模型的检查效果。对训练集中的错词按照视觉错误与语音错误进行分类。本文将正确的句子表示为
包含错误汉字的句子表示为
其中:rj表示视觉错误词;vi表示语音错误词。记录错误词位置信息为p=[j,i],sc对应的标签信息为
其中,R,V 分别表示视觉错误标签与语音错误标签。检测-修改任务通过训练模型,得到错句sc的正确标签序列pos,并利用pos 纠正rj,vi为tj,ti。
最后,分别计算检测网络和纠正网络的损失,如式(2)与式(3)所示。
检测网络的损失函数为
其中:xi表示CRF 中第i 条路径状态分数与转移分数之和,共有mn条路径;n 为序列长度;m 为标签种类数。检测网络损失函数Lossd表示为真实路径分数占总路径分数的比重的负数,即真实路径分数占比越高,损失函数越小。
纠正网络的损失函数为
其中:S 表示正确句子样本;Sc表示错误句子样本表示被掩盖的词经过纠正网络纠正后得到的结果;Θ 表示模型参数。修改网络损失函数为句子中所有字的交叉熵损失和。计算得到最终的损失函数
其中,0 <λ <1。
3 实验设置
本节将介绍实验使用的训练数据集与测试数据集,以及汉语拼写检查的评价标准。同时对所使用模型的超参数进行介绍。
3.1 数据集与基线
采用CLP-2014 数 据集[19],SIGHAN-2013 数 据集[20]和SIGHAN-2015 训练数据集[21]作为本文的训练数据。训练数据中一共有8 538 个句子,其中有897 个句子没有错误,7 641 个句子有一处或多处错误。
采用SIGHAN-2015CSC 测试数据集作为测试数据。测试数据中一共有1 100 个句子,其中有550个句子没有错误,550 个句子有一处或多处错误。CLP 和SIGHAN 等数据集是汉语拼写检查任务常用的数据集,在许多研究中都得到了使用[7-10,12-14,22]。
选取Han 等[23]的模型作为本文的基线模型(baseline model)。Han 等人基于双向LSTM 构造拼写检查模型,同时将汉字的视觉特征和语音特征与模型相结合。他们的模型是汉字拼写检查任务中具有代表性的结构,并在SIGHAN-2015 测试集上取得了较好的效果。我们采用文献[23]所给的参数重建了他们的模型,并采用了本文所用的训练集数据,获得了在个别指标上超过原文实验数据的结果。
为了证明提出模型结构的有效性,本文选用BERT 做为消融实验的模型。BERT 作为近些年最火热的预训练模型,在许多自然语言处理任务中都取得了突出的结果。其使用的MLM 语言模型非常适用于汉字拼写检查任务。我们同样在BERT 中加入了汉字的视觉特征和语音特征。
3.2 评价标准
本文将用于判断拼写检查正确性的标准分为两个部分:一个检测正确度;另一个纠正正确度。对于检测正确度,给定句子中所有错误字符的位置都应与标准完全相同;对于纠正正确度,错误字符更改后的结果应与正确句子中的字符完全相同。两个正确度都将从假阳性率(false positive rate,FPR)、准确率(accurate rate)、精确率(precision rate)、召回率(recall rate)和F1 分数(F1-score)的角度进行评判。5 种标准计算方式如下:
其中,TP、FP、FN、TN 分别表示真正例、假正例、假负例和真负例。本文从句子级维度进行正负例的定义,即正例表示不含错误汉字的句子,负例表示包含错误汉字的句子。假阳性率表示所有判定为负例样本中假正例的比例;准确率表示所有判定正确的样本占总样本的比例;精确率表示真正例的样本占判定为正例的样本的比例;召回率表示真正例占实际正例样本的比例;F1 分数则同时兼顾了精确率和召回率。这些评价指标将从不同的角度对模型的检测和纠正性能进行评估,从而得到一个全面的评价结果。
3.3 模型超参数设置
在检测模型中,输入嵌入的维度为512 维,并使用隐藏层为256 维的两层双向LSTM 模型;在纠正模型中,使用隐藏层维度为512,层数为12 的BERT 模型。另外,用作消融实验的BERT 模型使用了同样的超参数。本文使用Adam 算法[24]作为优化算法来训练模型,学习率为0.000 1,批次大小设置为32。
4 实验结果分析
实验结果如表1 和表2 所示。其中表1 表示检测正确度的结果,表2 表示纠正正确度的结果。表中基线模型(baseline model)表示Han 等人提出的模型;model 表示不添加额外特征的本文提出的拼写检查模型;model+strokes 表示模型只添加视觉特征;model+voice 表示模型只添加语音特征;model+strokes+voice 表示模型同时添加视觉特征和语音特征。实验结果表明:在模型不额外添加特征及只添加视觉特征的情况下,本文提出的模型在测试集上的表现相比基线并无明显优势;在模型只添加语音特征的情况下,检测正确度与纠正正确度上的表现均优于基线;在模型同时添加了语音和形状特征的情况下,检测与纠正正确度上的各项评价均优于基线;且相比模型只添加语音特征的情况,同时添加语音和视觉特征可以小幅提高模型在测试集上检测与纠正正确度的表现。在本实验中,视觉特征对模型检测和纠正能力的提升效果有限,我们认为这与视觉特征的表示方式有关,将笔画顺序作为嵌入的方式并不能很好地反映汉字的视觉特征。另外,本文在训练过程中采用较小规模的训练集,相比基线模型获得了一定程度的性能提升。在提升训练集规模的前提下,本文提出的模型凭借结构优势及大参数量能够展现出更大的潜力和更好的效果。
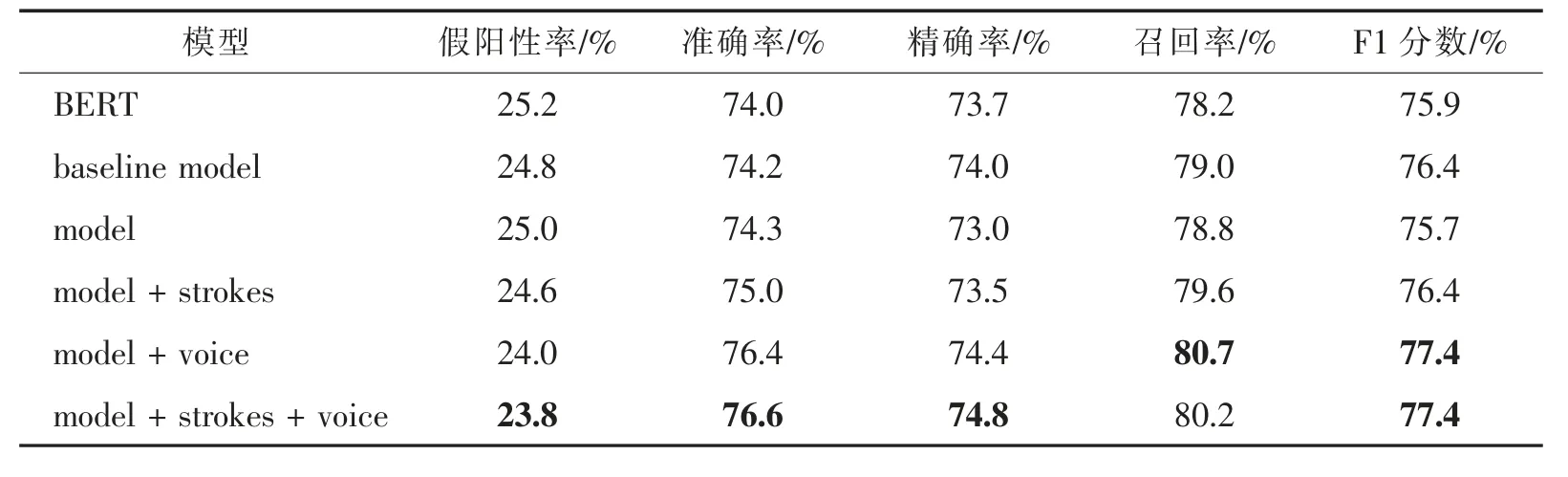
表1 检测正确度的实验结果Tab.1 Experimental results for detecting correctness
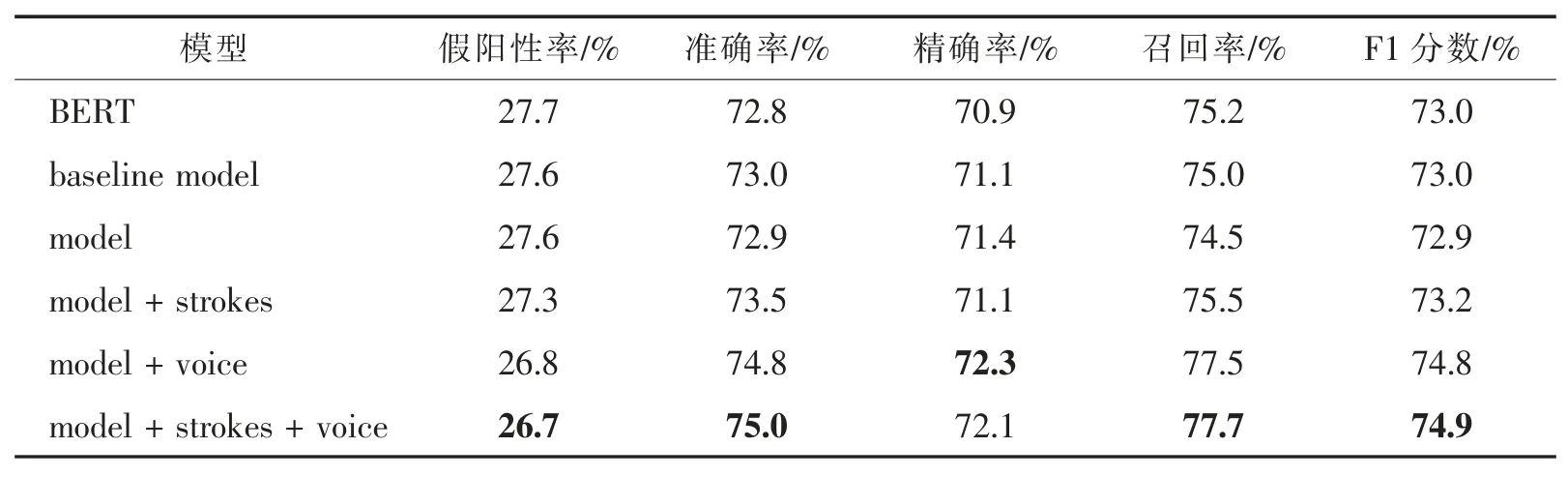
表2 纠正正确度的实验结果Tab.2 Experimental results for correcting correctness
实验还通过与BERT 模型的对比展现本文方法的有效性。与同样添加了语音特征和视觉特征的BERT 模型相比,本文的方法在检测正确度和纠正正确度上的表现都更为出色,证明了本文模型在结构上的优越性。
表3 给出了一些实验中模型预测的结果示例。这些具体的例子也说明了本文方法的有效性和实用性。

表3 模型预测结果示例Tab.3 Examples of model predictions
5 结论
本文提出了一种汉语拼写检查模型。文中提出的模型结合了汉字的视觉特征和语音特征,并利用BiLSTM+CRF 模型构成检测网络进行错误词检测,利用BERT 模型构成纠正网络对检测到的错误字进行修改。在SIGHAN-2015 CSC 测试集上,本文提出的方法相比现有的方法和BERT 模型在评价指标上得到了更好的结果。另外,相比视觉特征,语音特征对拼写检查效果的提升在本文实验中更为有效。
对于未来的工作可在以下两方面进行深入的研究:1)视觉特征的提升效果有限或许与视觉特征的表示方式有关,改进表示方式可以进一步提升拼写检查任务的效果。2)迁移学习在汉语拼写检查中使用。通过使用迁移学习可以提高原始语料库和人工语料库的接近度,从而提高模型的可用性。
猜你喜欢
小天使·一年级语数英综合(2022年2期)2022-03-30
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
读天下(2018年10期)2018-07-24
赢未来(2018年1期)2018-04-20
考试周刊(2017年92期)2018-02-03
校园英语·下旬(2016年3期)2016-04-18
人生十六七(2015年29期)2015-02-28
