
面向高校图书馆的智慧搜索模式研究
2024-01-12 04:39赵航康丽娟
微型电脑应用 2023年12期
赵航, 康丽娟
(1. 西安工程大学, 图书馆, 陕西, 西安 710048; 2. 西安职业技术学院,现代商学院, 陕西, 西安 710077)
0 引言
随着时代发展,人们对计算机技术的应用扩展到生活的方方面面,图书馆资源管理的方式也在发生转变,从传统的纸质媒介资源图书管理到线上的电子图书馆,之后到了现在的智慧图书馆。信息化技术的发展,使得信息数据成为优势导向资源,科学数据是维持社会稳定和支持科学技术及经济发展的重要资源。为了获取高利益的科学数据,诸如知网、万方、ResearchGate等资源建设平台不断改进、发展智慧化搜索模式以提高用户占比,获取更大市场效益[1]。在这样复杂的信息技术环境下,图书馆为了应对各行各业的跨界挑战不被边缘化,探索电子图书馆和智慧图书馆建设模式。智慧图书馆是指把智能技术运用到图书馆建设中而形成的一种智能化建筑,是智能建筑与高度自动化管理的数字图书馆的有机结合和创新。智慧图书馆是一个不受空间限制的、能够被切实感知的一种概念。其通过使用云计算、智慧化等技术,对传统图书馆进行改造,使其能够为读者提供更贴心的服务[2-3]。智慧图书馆发展的一个重要方面便是搜索模式的智能化。随着信息化图书资源及智慧图书馆用户的持续增长,高效能的检索模式对于用户目标资源导航及访问重点数据库变得愈加重要。其中,高校因其以科学研究作为主要目的,图书馆需要对科学研究进行全面且智能化的管理。为了满足多元化、个性化的用户需求,高校图书馆开始探索动态化、智能化、全面化的智慧搜索模式。基于此,本文为了优化高校图书馆检索服务体验,提高高校图书馆竞争力,借助大数据对高校图书馆智慧搜索模式建设进行探索。
1 高校图书馆智能搜索模式设计
1.1 以移动视觉搜索为主要检索方法的高校图书馆智能系统构建
图书馆智能化搜索服务模式构成要素包括提供服务的主体、内容、目标对象、设施和环境[4-5]。在高校图书馆中,智慧搜索服务的服务主体为各高校图书馆单位,即单位内部馆员和相关部门;服务的目标对象为图书馆资源的使用者,除了校内师生,还有其他经学校认证的校外人员;服务内容因图书馆资源及目标而有所变化,是高校图书馆为满足多样化用户需求所具备的图书智慧检索服务和延伸服务;环境则包括客观存在的物理环境和社会环境,包括智能化搜索环境、管理人员服务环境、资金环境和学校及政府的文件支持环境;智慧搜索服务的服务设施主要为图书馆资源大数据管理平台和构建智慧搜索服务所需要的相关技术。通过对各大高校建设的智慧搜索服务五大要素进行分析可知,智慧搜索服务除了包含其主要的服务本体,即基于大数据构建的图书馆资源智能搜索平台,还包含延伸的图书馆藏资源智慧推荐、智慧互动和基于用户需求的智慧引导服务。本文以适用于图书馆资源搜索的大数据搜索模式为主要研究对象,构建的高校图书馆智慧搜索模式如图1所示。
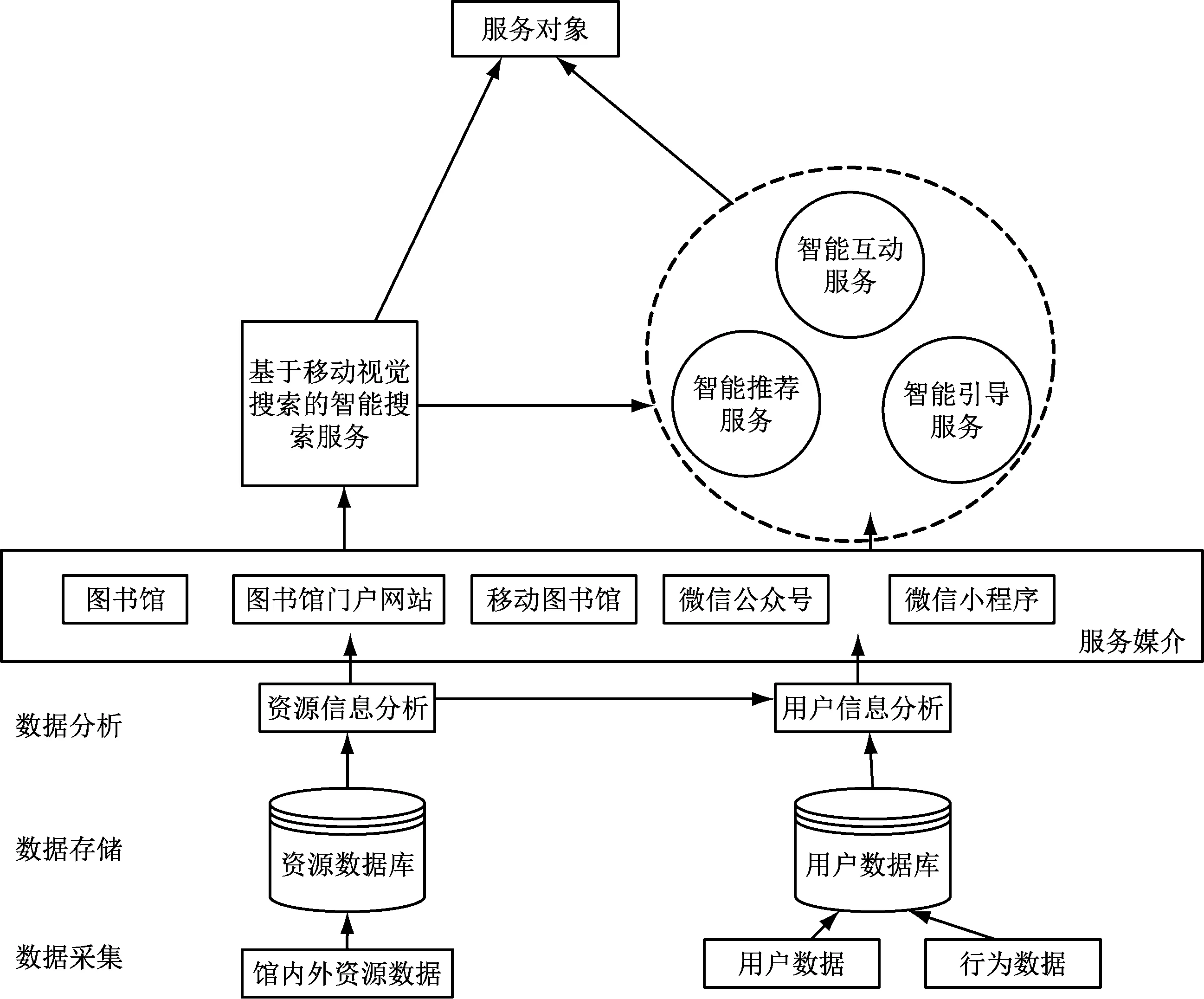
图1 高校图书馆智慧搜索模式
为了追求更高效的高校图书馆智慧搜索模式和满足服务对象的个性化搜索需求,本文在传统的基于文本分析的图书馆藏资源大数据检索模式上进行创新,设计了基于移动视觉搜索的高校图书馆搜索模式。考虑到用户对图书馆资源搜索的便携性及灵活性需求,高校图书馆智慧搜索系统提供多样化的服务媒介,包括图书馆内检索、图书馆门户网站检索、手机移动图书馆软件检索、微信公众号及微信小程序检索方法。除了作为主要功能的智慧搜索功能,智慧图书馆搜索系统还提供基于用户数据库进行行为分析和信息分析的推荐服务及互动服务。移动视觉搜索(MVS)可根据用户提供的多样化信息进行识别,不仅可以用于以图片进行视觉化图像检索,还可实现对多种内容的搜索,包括文本、视频、地图、三维模型、图像等,其构建流程包括图像识别、描述提取、匹配数据和返回结果[6]。高校图书馆移动视觉搜索系统构建见图2。

图2 高校图书馆移动视觉搜索系统
用户发送图像及检索需求到图书馆藏资源检索系统,移动视觉搜索系统对用户需求进行特征提取,并建立用户需求库,通过使用视觉对象匹配技术将用户需求视觉特征与馆藏文献进行匹配,匹配成功后,构建相应的检索内容列表,将匹配结果分类返回给用户。馆藏资源知识库中存储着图书馆内的书籍及图像的电子资源和引导文本,同时还包含关联数据库中的电子资源。根据用户不同类型的搜寻需求,高校图书馆移动视觉搜索系统可提供不同的检索内容。首先为了满足用户对资源的全面性和完整性需求,移动视觉搜索系统适配不同的智能移动端,可对多平台进行跨平台检索,以提供全面的检索资源。其次为了满足用户个性化需求,利用云数据计算技术为用户提供针对化和独立的检索推荐服务。根据用户偏好提高搜索准确率和全面性,同时还可与移动端口连接,方便用户及时获取各项服务。
1.2 移动视觉目标搜寻算法构建
本文为设计出能够对图书馆多种形式馆藏资源进行搜寻的资源搜寻系统,使用YOLOv5(You Only Look Once第五代)作为基线网络,相较于传统移动视觉搜寻算法,其加入更多提升精度和速度的技巧,从而取得精度与速度的平衡[7-8]。本文选用YOLO系列中较为轻量化的YOLOv5作为图书馆藏资源检索系统的基础网络,其结构见图3。

图3 YOLOv5网络
如图3所示,YOLOv5主要分为输入端、主干网络、颈部网络和头部网络。输入端输入的数据进入Focus对图片进行切片处理,将图片中的像素值每隔一个值进行抽取,将1张图片切分为4张图片,从而做到提高感受野,减少图片信息丢失。以上数据经过卷积操作后进入CSP层。CSP层避免了传统深度学习模型梯度信息丢失和网络计算消耗大的问题,并有效提高了卷积神经网络学习能力。YOLOv5的CSP结构是将原始输入分为2个分支进行卷积运算,将通道数减半,然后在1个分支上进行Bottleneck×N运算,再将2个分支并联,使Bottleneck CSP的输入和输出大小相同。CBL层封装了3个模块,分别是BN、Convolution层以及Leaky ReLu激活函数。BN是YOLO系列独创单元。CSP1结构主要应用于Backbone中,CSP2结构主要应用于Neck中。CSP2x表示在Neck Network中使用的CSP模块。它与在Backbone Network中使用的CSP模块的主要区别在于使用了2X个CBL模块代替了残差模块。此后,通过再一次卷积进入Neck Network结构。大多数纳入神经网络模型的注意力机制都能提供一些性能上的提升,但它们在轻量级网络中并不像在大型网络模型中那样有效。因此,本文将使用能够在轻量化网络特征信息提取性能上表现优异,且计算量级小的坐标注意力机制(CA),其具体结构见图4。

图4 注意力机制结构
如图4所示,坐标注意力机制可看作增强移动网络特征表达能力的计算单元,使用坐标信息嵌入和协调注意力生成2个模块来编码通道和长距离关系。首先对输入特征数据的每个二维图像进行平均操作,利用全局池化模块,建立二维坐标轴,沿着X和Y方向聚合成相对独立的平面感知特征图示[9-10]。之后根据空间构成原理,在三维上进行投射,进行卷积操作以整合特征图。最后,通过使用具有归一化权重的Sigmoid函数的加权乘法,将2个注意力权重应用于输入数据中,以强化算法对目标区域的重视。将坐标注意力机制引入YOLOv5时,首先将坐标注意力机制嵌入到YOLOv5的主干网络中,通过对已有研究的调查可知,在基线网络中,底层的特征提取通道数量最多,使得其能够对与目标无关的信息进行有效加工,对提取结果造成影响,可能会降低对算法识别的准确性,所以在最后一层加入了坐标通道关注模块,试图让检测算法能够关注与当前任务相关的特征信息。
2 基于移动视觉搜索的高校图书馆智能系统性能测试
本文构建图书馆智慧搜索系统,以图书馆智能搜索服务构成要素为基础,通过融合注意力机制的YOLOv5算法,进行用户需求视觉特征与馆藏文献资源的匹配,并提供延伸服务。因此评估系统的性能测试中,先对融合注意力机制改进后的YOLOv5算法进行训练,使用某高校图书馆藏数据集进行测试。该数据集包括图书封面的图像和文字标注,对模型进行训练后得出α-CloU损失函数曲线定位损失曲线,分类损失曲线和置信度损失曲线如图5所示。
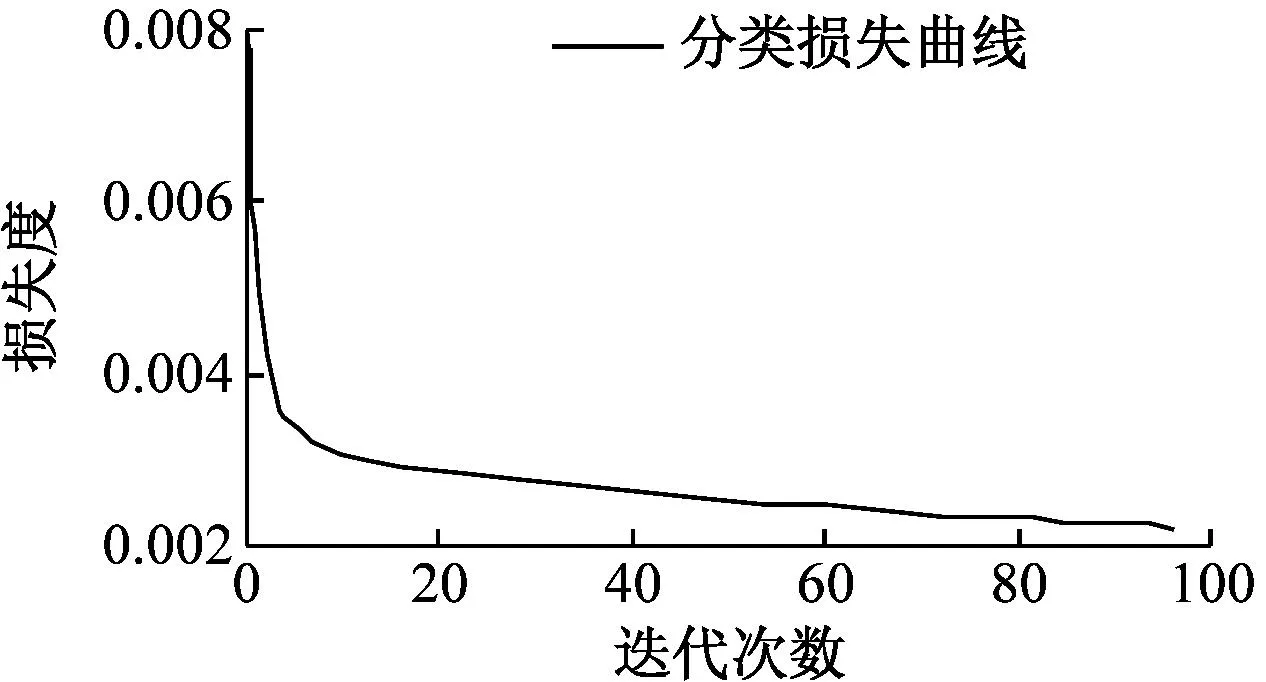
(a) 分类损失曲线
图5为YOLOv5模型训练过程中的损失函数统计分析结果。在训练过程中,未出现过异常情况,在模型训练到第100轮次时,所有的损失函数曲线都趋向于稳定。从图5可以看出:定位损失和置信度损失逐步稳定在0.002和0.028;分类损失逐步稳定在0.017。在此基础上,为提高系统对目标区域特征的识别精度,在基线网络模型中加入能够同时考虑通道间关系以及长距离的位置信息,且具有轻量化特点的坐标注意力机制进行调整。训练之前,先将超参数batch size设置成16,共训练100个epoch。从开始训练到训练结束,使用warm-up原则,也就是从0开始学习3个 epoch。选择带有动量的随机梯度下降法(Random Gradient Descent)作为优化器。该方法的优点是在很小的空间内计算梯度的平方,所以不需要存储梯度。在全部训练图片开启马赛克数据增强后,关闭mixup数据增强。加入坐标注意力机制的网络模型训练结果损失函数曲线如图6所示。

(a) 分类损失曲线
图6(a)、图6(b)、图6(c)分别表示融合注意力机制改进后的YOLOv5算法的分类损失曲线、定位损失曲线、置信度损失曲线。模型在训练过程表现与预期相符,各损失函数曲线皆随着epoch增加逐步达到稳定态,在前20个epoch损失下降得较快,之后稳定缓慢下降,直到达到稳定态。最终定位损失和分类损失的稳定态结果在0.001 18左右,置信度损失则最终稳定在0.028左右。为了验证坐标注意力机制对YOLOv5测算精度提高的有效性,分别将通道注意力(SE)、卷积注意力(CBAM)和坐标注意力机制加入YOLOv5算法中,训练模型并进行比较。SE通道注意力机制加入的位置与坐标注意力机制一样,因CBAM注意力机制有优秀的空间信息提取能力则用来替代卷积层执行空间特征信息提取任务。为了达到轻量化和高精度的目标,使用CBAM注意力模块替换YOLOv5模型第五层的卷积层。同时选取普通YOLOv5模型作为比较,4种模型准确度比较曲线如图7所示。

(a) YOLOv5
图7(a)、图7(b)、图7(c)、图7(d)分别为基线网络模型YOLOv5、YOLOv5+SE、YOLOv5+CBAM、YOLOv5+CA的测试结果。从图7可以看出,4种网络模型整体趋势相似,皆在0~1的置信区间快速上升后逐渐趋于稳定。进一步对图7(a)和图7(b)分析可知,2个模型的所有类别都在置信度为0.946时,准确率可以近似为1.0,但是插入SE的YOLOv5模型对others类别,相较于YOLOv5基线模型的准确度曲线更为平滑,效度更高。对图7(c)与图7(d)比较可知,插入CA的YOLOv5模型对书、3D模型和艺术字类别识别正确的置信度更高,在0.4的置信度时就有良好的准确率表现。对准确率曲线进行横向对比可知,融合坐标注意力机制的YOLOv5网络模型在图书识别上性能更优。融合坐标注意力机制YOLOv5网络模型旨在高精度地对图书馆藏资源进行移动视觉搜索且占用较小的运行内存,以方便其可以搭载在图书馆的多功能计算机中,并通过多种媒介为用户提供服务,为了验证融合坐标注意力机制YOLOv5网络模型相较于主流模型有更好的识别精度、计算时间的平衡及更小的内存占比,对其进行多次比较实验,结果见表1。

表1 多网络性能比较实验
如表1所示,其清晰地体现了6种移动视觉搜索算法的检测精度、运行时间和内存占比比较。从表1可以看出,相较于其他YOLO网络,YOLOv5网络计算精度更高,运行时间也更长,但内存占比最小,仅为0.9%。而YOLOv5+CA算法沿袭了YOLOv5网络在内存占比上的优点,以较小的内存实现了最高的计算精度,运行时间相较于YOLOv5网络有所降低。其识别精度为0.904,运行时间为42.5 ms,内存占比为1.2%,有较好的性能表现,可以适配于图书馆中的数据智能检索服务。
3 结论
为了应对图书馆多元化的用户需求,优化高校图书馆检索服务体验和增强高校图书馆竞争力,本文借助大数据深度学习模型,使用移动视觉搜索技术对高校图书馆智慧搜索模式建设进行探索,构建了融合注意力机制的YOLOv5算法的高校图书馆智慧搜索服务。性能测试结果表明,模型训练在前20个epoch损失下降得较快,之后稳定缓慢下降,直到达到稳定态。最终定位损失和分类损失的稳定态结果在0.001 18左右,置信度损失则最终稳定在0.028左右。基线网络模型YOLOv5、YOLOv5+SE、YOLOv5+CBAM、YOLOv5+CA比较测试结果表明,插入CA的YOLOv5模型对书、3D模型和艺术字类别识别正确的置信度更高,在0.4的置信度时就有良好的准确率表现。YOLOv5+CA识别精度为0.904,运行时间为42.5 ms,内存占比为1.2%,有较好的性能表现。实验结果表明,本文提出的YOLOv5+CA搜索算法有较好的计算效能和较小的内存占用,可以适配于图书馆中的数据智能检索服务。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通·3-4年级(2021年5期)2021-07-16
今日农业(2019年15期)2019-01-03
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
小天使·一年级语数英综合(2014年6期)2014-07-22
智慧与创想(2013年7期)2013-11-18
网球俱乐部(2009年9期)2009-07-16
