
基于多注意力机制的多粒度读者画像分析
2024-01-12 04:39贺海玉
微型电脑应用 2023年12期
贺海玉
(山东大众报业(集团)有限公司, 山东, 济南 250014)
0 引言
高校图书馆是高校教育工作建设的重要组成部分,发挥着提供课后学习场所与保障阅读需求供给的职能作用。随着计算机技术的发展,数字时代背景之下,大学生的阅读需求总体上呈现出阅读多样化、高质量化、个性化的倾向[1]。由于未及时精准系统地了解读者需求,高校图书馆提供的资源、服务与读者需求之间的矛盾日益凸显,高校图书馆的使用率越来越低。为了提升图书馆的服务能力,满足读者多元化阅读需求,各大高校图书馆加大投入推行了个性化服务。但个性化服务造成了大量的人力物力消耗,对图书馆管理工作要求较高,且工作效率较低。用户画像是建立在真实数据信息之上的用户模型,能够借助对数据的分析判断用户属性,将用户分类并赋予特定描述构成用户画像[2-4]。高校图书借阅会保留大量具有研究价值的阅读数据,基于阅读数据可分析读者阅读行为,精准预测读者行为进而实现图书馆的精准服务,促进高校教学文化建设。鉴于此,研究首先利用卷积神经网络进行用户内部特征抽取,并使用图卷积网络进行读者间特征抽取,最后使用注意力机制将内部特征与读者之间的特征联合在一起构建基于多注意力机制的多粒度读者画像分析模型,帮助高校图书馆挖掘读者阅读需求,有望提高高校图书馆服务质量。
1 多粒度读者画像分析模型搭建
1.1 基于卷积神经网络的内部特征抽取算法设计
研究利用卷积和图卷积神经网络学习表征读者借阅频率、阅读兴趣等阅读行为的特征,利用自注意力机制对数据信息的噪声进行处理,使用多层注意力机制融合所有特征学习用户的最终标签,构建基于多层注意力网络的联合读者评测模型。用户画像的核心工作是根据用户信息赋予用户特定标签,电子商务、教育、医疗以及众多服务行业都根据用户画像了解用户需求,挖掘用户价值。图书馆的借阅系统会保留大量的日志数据,日志数据覆盖了机器大部分的执行操作,通过日志能够实现运维监控、业务分析等多种统计分析的需求[5]。读者画像数据包括静态和动态2个部分,静态数据包括用户姓名、年龄、专业以及学历等基本信息;动态数据包括读者在阅读过程中产生的行为数据,包括借阅行为、进出馆时间、检索关键词等。
读者行为通常包含多种类型的信息,将读者不同数据来源构成n个行为信息包A,用户信息定义为{A0,A1,…,An};每个信息包A包含m个行为信息,行为信息定义为句子a,Ai={a0,a1,…,am};每个句子a包含k个单词w,句子ai={w0,w1,…,wk}。首先每个单词w进行词嵌入,将每个句子长度固定为b,长度不够或超出部分需进行填充或截断处理。将单词w通过词嵌入映射成低维向量E⊂RV×d,词向量定义为wi⊂RV×d,d表示词嵌入维度,V表示词汇量大小。词模块的框架如图1所示。

图1 词模块框架

(1)

(2)
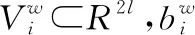
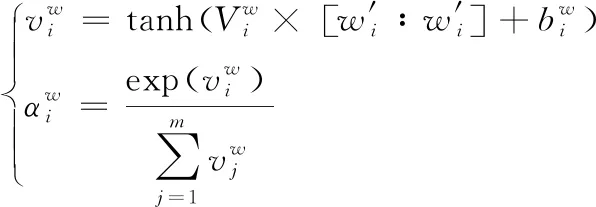
(3)
对于预测画像起重要作用的行为信息,权重较大;对于噪声较大的数据则削弱权重,句子a的表达式见式(4),a⊂Rl。
(4)

图2 句子模块框架
内部特征计算见式(5)。
(5)

1.2 基于多层注意力网络的读者画像模型搭建


(6)
GCNN通常包括3个步骤:首先将每个节点的自身特征信息转变后发射给邻居节点;将节点信息融合后接收并聚集邻居节点的节点特征信息;最后把信息聚集作非线性变换,增加模型预测画像能力。经过GCNN算法训练,即可得到读者之间的特征uinner。读者数据来源类型较多,有时存在用户内部特征数据无法描述完整用户画像的情况,算法学习时应将所有类型数据加以考虑,提高用户属性预测的准确度,因此需要将得到的读者内部特征与读者间的特征进行融合。基于多层注意力网络的联合读者预测模型框架如图3所示。
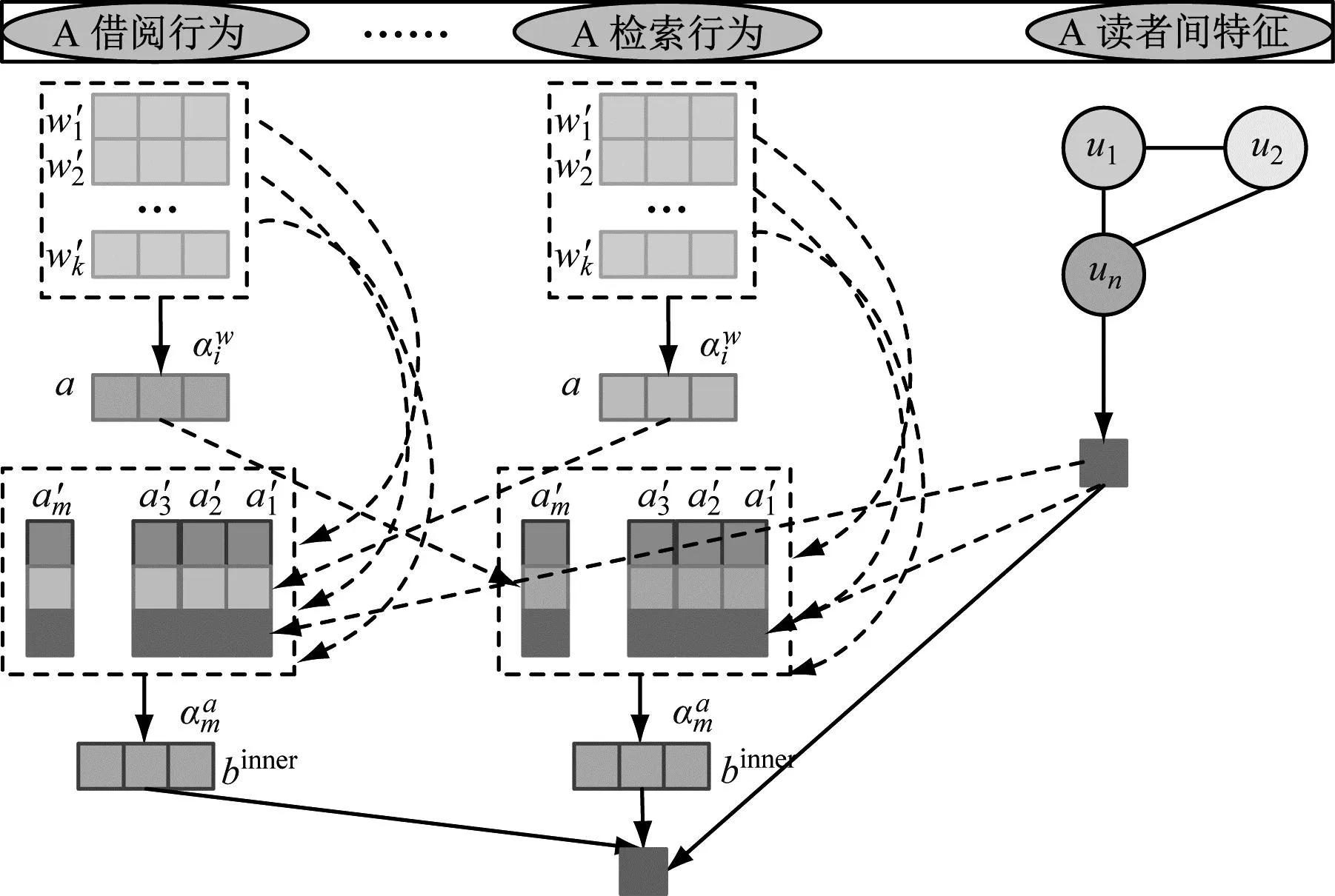
图3 基于多层注意力网络的联合读者预测模型框架
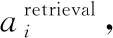

(7)
尽管所有读者数据来源均用于模型分析,但为了区分不同类型数据对读者特征分析的贡献度,且读者间特征数据噪声较多,影响读者画像描述准确性。研究是根据读者相似行为的发生而将读者与读者连在一起,这种联系有时存在判断误差。为了解决这一问题,研究在基于多层注意力网络的联合读者预测模型中加入信息包级别的注意力机制。通过注意力网络计算不同特征权重大小,得到联合读者的属性特征,计算过程见式(8)。

(8)
最后,将用户画像分类,使用线性函数将读者特征映射到目标空间,用Softmax分类器计算读者为当前属性的概率值,计算过程见式(9)。式(9)中,W、b表示参数,|y|表示类别数[13]。
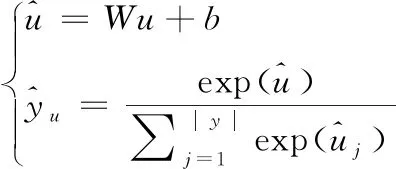
(9)
(10)
2 基于多层注意力网络的读者画像模型效果分析
为了评估算法的有效性,研究将某高校图书馆20 467名读者作为一个大群体进行读者画像分析,以读者活跃度、读者借阅率、电子资源使用率以及进馆率四个指标将所有读者群体分为4类小群体。指标定级分别为高、较高、较低、低,均值范围≥1.000为高;均值范围[0.600,1.000)为较高,均值范围[0.300,0.600)为较低,均值范围[0.000,0.300)为较低,算法读者画像群体分类情况见表1。

表1 读者画像群体分类结果
对四个群体的读者画像进行分析,根据算法输出结果,结合读者基本信息得出读者群体画像,据此制定精准个性化图书服务。由表1可知,第一类群体共9267人,占比45.28%,这类读者群体画像为活跃度、借阅率以及电子资源使用率均处于低频次的范围,但进馆率处于较高水平,该类读者对图书馆的需求多为使用公共场所自习,占图书馆读者比例较大,因此可增加图书馆的座位以及自习空间。第二类群体的活跃度、进馆率较低,但借阅率高、电子资源使用率较高。这类群体占比23.14%,对图书馆电子、纸质资源比较感兴趣。图书馆可对该类群体加大资源推送力度。第三类群体的活跃度、进馆低,借阅率较高、电子资源使用率较低,占比较少,仅15.09%。这类群体常在图书馆借阅书籍,但电子资源使用较少,可根据借阅书籍类型增添书籍收藏数量。第四类群体的四个指标均表现较高,该类型应属于图书馆的忠实读者,兴趣浓厚。对于这类读者可向其推荐图书馆新设福利,获取更大吸引力。
将基于多层注意力网络的联合读者画像预测模型分别与GCNN、CNN-GCNN算法的性能进行比较。3种算法的运行时间结果如图4所示。由图4可见,CNN-GCNN-SA的耗时最短,完成所有读者画像预测及分类仅用时71.06 s。GCNN、CNN-GCNN算法耗时明显较长,与CNN-GCNN-SA联合算法相比,耗时分别增长101.65%,97.02%。在学习效率方面基于多注意力机制的多粒度读者画像算法更满足高校图书馆的需求。
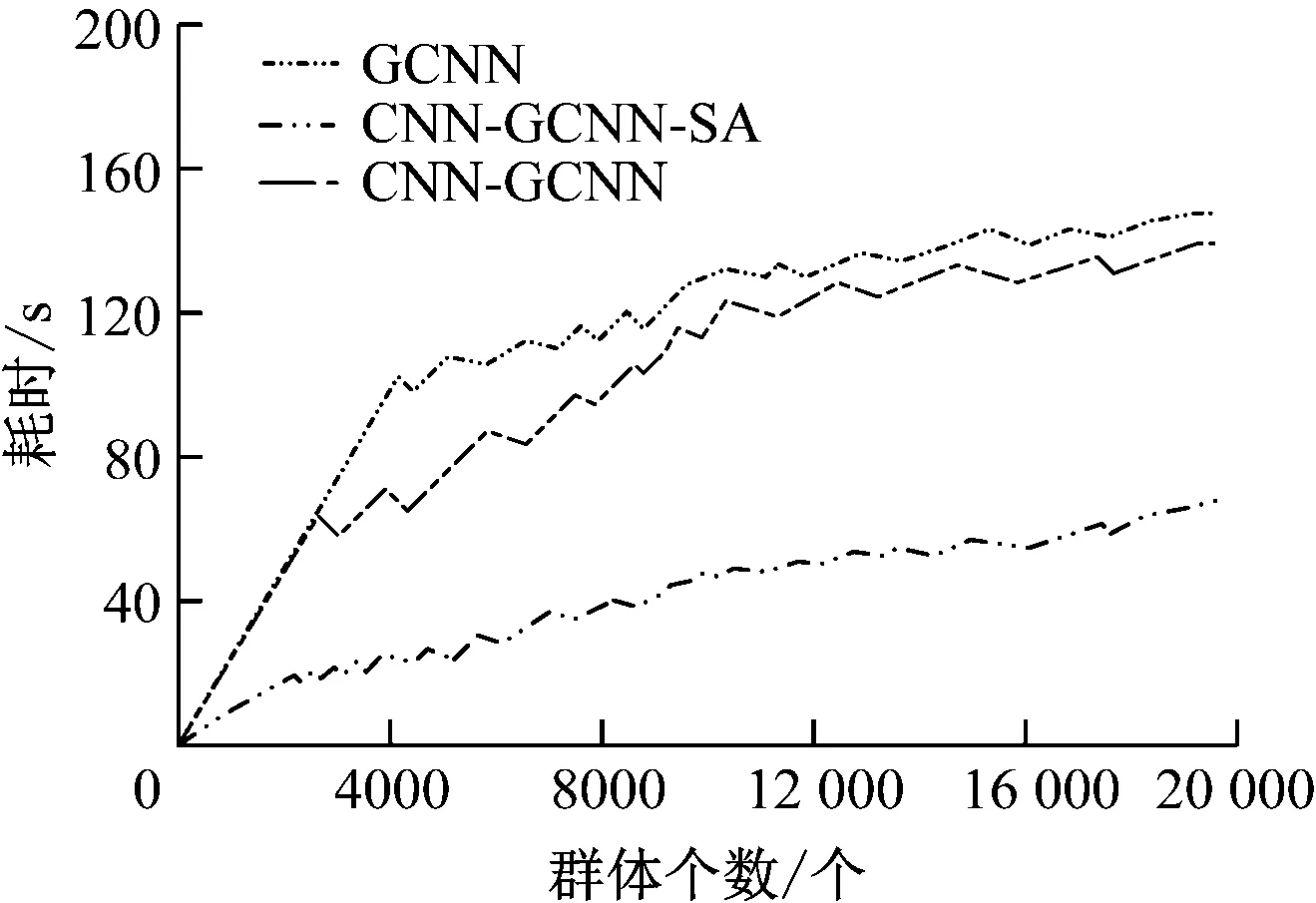
图4 不同算法的耗时变化比较
为了评估算法的有效性,研究使用准确率与F1值作为评价指标,对模型在读者的活跃度和借阅率上的预测结果进行评价。比较GCNN、CNN-GCNN、多层图结构读者画像模型(HGAT)和融合文本特征与图像特征的Text-image cooperation framework(COOP)模型。在同样的数据集下迭代40次进行算法学习训练,实验结果如图5所示。由图5可见,CNN-GCNN-SA模型的准确率最高,最大准确率值为91.09%,画像分类较为准确。GCNN、CNN-GCNN算法的最大准确率分别为67.24%、55.27%,分别低23.85、35.85个百分点。F1值是精确率与召回率的加权平均,因为精确率与召回率有时存在矛盾情况,因此用F1值综合考虑算法性能。综合分析来看,CNN-GCNN-SA模型的F1值曲线最高,最大值达到了89.23%,没有存在精确率与召回率牺牲的现象。综合而言,研究提出的CNN-GCNN-SA模型的综合性能更优,与其他两种模型相比,在活跃度和借阅率上的特征预测结果取得的结果最好。表明多层注意力机制参与的复杂语义特征学习体现了读者画像预测的优势。词模块中注意力机制的引入增强了关键信息,句子模块的注意力机制则减少了数据的噪音干扰问题,能够表征读者属性的数据赋予了更大的权重读者间特征数据噪声的排除增加了模型对读者画像分析的准确性。

(a) F1
较HGAT、COOP模型,CNN-GCNN-SA模型的两种评价指标仍表现较优,体现了多源特征数据抽取对读者画像分析的有效性。HGAT、COOP模型尽管也使用了多类型数据,但对于内部特征的抽取并不充分,读者间特征没有得到利用意义,准确率最高值分比为78.45%、81.47%;CNN-GCNN-SA则充分利用了读者间与读者内部特征的作用,使得读者间的关联性得到充分挖掘。
3 总结
在数据信息时代背景下,为了改善图书馆资源享有情况以及提高图书馆教育文化服务水平,研究设计了基于多注意力机制的多粒度读者画像分析模型。首先利用卷积和图卷积网络提取读者内部与读者之间的特征,利用自注意力机制对计算特征权重大小,并融合所有特征。实验结果表明,算法可对读者群体进行画像分析并分类为4种类型,分别占比45.28%、23.14%、15.09%、16.49%,第一类群体占比最大,依据画像分析结果可对读者群体提供精准服务。算法耗时较少,仅用时71.06 s。GCNN、CNN-GCNN算法耗时较长,耗时分别增长101.65%、97.02%。CNN-GCNN-SA模型的准确率最高,最大准确率为91.09%,较GCNN、CNN-GCNN算法高23.85、35.85个百分点;算法的F1值曲线最高,最大值为89.23%。算法预测分类效果较好,综合性能较优,但模型分析的读者特征体系还不够完善,绘制的画像还可以更加全面。
猜你喜欢
小哥白尼(神奇星球)(2022年3期)2022-06-06
小雪花·成长指南(2022年1期)2022-04-09
新世纪智能(高一语文)(2020年9期)2021-01-04
非公有制企业党建(2020年10期)2020-10-27
科学大众(2020年10期)2020-07-24
当代陕西(2019年6期)2019-04-17
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
延河(下半月)(2014年1期)2014-02-28
中国火炬(2012年8期)2012-07-25
