
基于改进属性加密的多源大数据安全访问控制
2024-01-11 03:01:16胡燕
黑龙江工业学院学报(综合版) 2023年10期
胡 燕
(罗定开放大学 教务处,广东 罗定 527200)
数据规模大幅度增长,促进了互联网大数据时代的到来。大数据指的是规模庞大,不能被轻易存储、计算的数据集合;多源大数据指的是不同来源的数据,数据类型繁多、信息量庞大、可靠度较高[1]。人们在享受多源大数据提供便利服务的同时,也存在隐藏的安全问题,比如用户个人隐私保护以及多维大数据安全共享等问题[2-3]。若用户个人隐私遭到泄漏,可能遭受不法分子的恶意骚扰甚至诈骗,被不法分子恶意盗取,损害国家以及个人的利益。因此,多维大数据安全问题是重中之重[4]。多维大数据安全访问控制能够保障数据安全共享。所谓访问控制是指通过判断用户的身份信息,给予正常用户访问权限,且正常用户只能访问已授权的数据,拒绝恶意用户访问请求,从而保障数据的安全[5]。然而如何实现多源大数据安全访问控制,保护数据隐私的同时,又能实现数据安全共享,是目前亟需解决的问题。
王嘉龙等[6]结合访问用户的数量,研究一种基于访问用户属性的大数据访问控制方法,在原始的Ranger访问控制模型中引用密文策略属性加密方法,运用该方法的加密、解密为大数据访问控制策略中增加访问控制树;实现多源大数据的安全访问控制。黄美蓉等[7]结合过去经验学习,提出一种基于角色的多源大数据安全访问控制方法,该方法能够代替人工审查访问用户是否授权,实现自动化审查;通过提取正确授权、错误授权等特征,进行访问控制刻画,面对不同的访问用户均能给出正确判断,实现大数据的安全访问控制。但是前者在加密、解密的过程中占用了大量时间,增加了存储空间的开销;后者存在授权过度或者是授权不足的问题,导致正常用户无法访问数据,数据信息易被恶意用户盗取。Qin等[8]提出了一种基于ABE和区块链技术的轻量级解密访问控制方案。使用区块链技术进行代理计算,在该过程中实施加密操作。通过区块链获得授权,并记录访问行为,以此建立一种用户信誉激励机制。根据用户的访问行为计算用户的信誉,给出信誉评分,从而动态调整访问方案。Banerjee等[9]提出了区块链设想的细粒度用户访问控制方案。支持多个属性权限以及固定的密钥和密文。基于密码策略属性对IoT智能设备收集的数据进行加密,并发送到附近的网关节点。网关节点根据加密数据形成交易,以形成部分区块。将部分区块转发到对等网络中的云服务器转换为完整区块,使用拜占庭容错机制将完整区块添加到区块链中共识算法中,实现用户访问控制。王金威[10]为了降低网络安全访问延时,提高网络利用率,设计了基于IPv6环境的安全访问控制模型,利用ReliefF算法获取特征子集,采用PCA方法对网络信息进行降维处理,基于上下文约束概念建立访问控制模型,实现安全访问控制。赵男男[11]基于联合特征辨识方法设计信息编码,建立模糊信道编码模型提取特征值,通过优化BP神经网络进行数据聚类,结合自适应滤波方法检测网络攻击,保证信息安全性。但是上述方法在加密、解密的过程中占用了大量时间,增加了存储空间的开销,同时数据信息易被恶意用户盗取。
属性加密(Attribute-based encryption,ABE)把访问用户身份视为一种属性,当用户的属性超过多源大数据加密者设置的阈值时,用户可进行解密[12]。属性加密分为密文、密钥两种策略属性。属性加密能够起到很好的多源大数据安全访问控制效果,实现多源大数据安全共享[13]。但是,属性加密比较复杂,直接用其加密多源大数据,会形成大量的计算开销;且需要庞大的属性集才能够管理全部的属性,如何高效运用属性加密是多源大数据安全访问控制面临的一个难题。为此,本文提出基于改进属性加密的多源大数据安全访问控制方法,维护大数据实现安全共享。
1 多源大数据安全访问控制方法
1.1 多源大数据安全访问控制模型
1.1.1 安全访问控制机制
由于数据规模较大,多源大数据拥有者通常将大数据存储在云端,无法像管理本地数据一样去管理云端中的大数据。云服务提供商为获取自身利益,存在非法访问用户的私密数据信息现象,因此用户的隐私遭到泄露。
为保护数据安全,多源大数据拥有者先加密大数据,再将加密后的大数据上传到云端,访问用户获取到访问权限,才能够得到访问该大数据的解密密钥。目前,运用比较多的是基于属性加密的多源大数据安全访问控制模型[14-15],分为密文策略属性加密(Ciphertext Policy Atteribute Based Encryption,CP-ABE)和密钥策略属性加密两种方法。
密钥策略属性加密中,每个多源大数据密文具有相应的属性,所有访问用户的密钥都有相应的访问控制结构[16]。若该访问用户密钥的访问控制结构和已经加密的多源大数据密文属性相匹配,则该访问用户的密钥能够解密多源大数据密文,拥有访问权限;若两者不能够匹配,则该访问用户的密钥不能解密多源大数据密文,说明该访问用户没有访问权限。如果访问用户想要访问多个大数据文件,就需要多个密钥,才能够解密多个大数据文件。
CP-ABE中,每个访问用户都有相应的属性,根据用户的属性生成该访问用户的私钥,每个多源大数据文件中都有一个访问控制结构[17]。如果访问用户的属性能够达到访问多源大数据文件的要求,则该访问用户的私钥能够解开多源大数据密文;如果不能满足要求,则不能解开该密文。
CP-ABE的优点为:多源大数据拥有者可以根据访问用户的属性,给自身拥有的每个大数据文件赋予不同的访问控制策略。每个访问用户只有一个密钥。多源大数据拥有者在不改变公钥、私钥的情况下,可以直接修改多源大数据文件的访问控制策略。因此,本文提出一种基于CP-ABE的多源大数据安全访问控制模型。
1.1.2 基于CP-ABE的安全访问控制模型
基于CP-ABE的多源大数据安全访问控制模型由用户、数据拥有者、认证颁发机构和属性管理机构组成[18],多源大数据安全访问控制模型如图1所示。
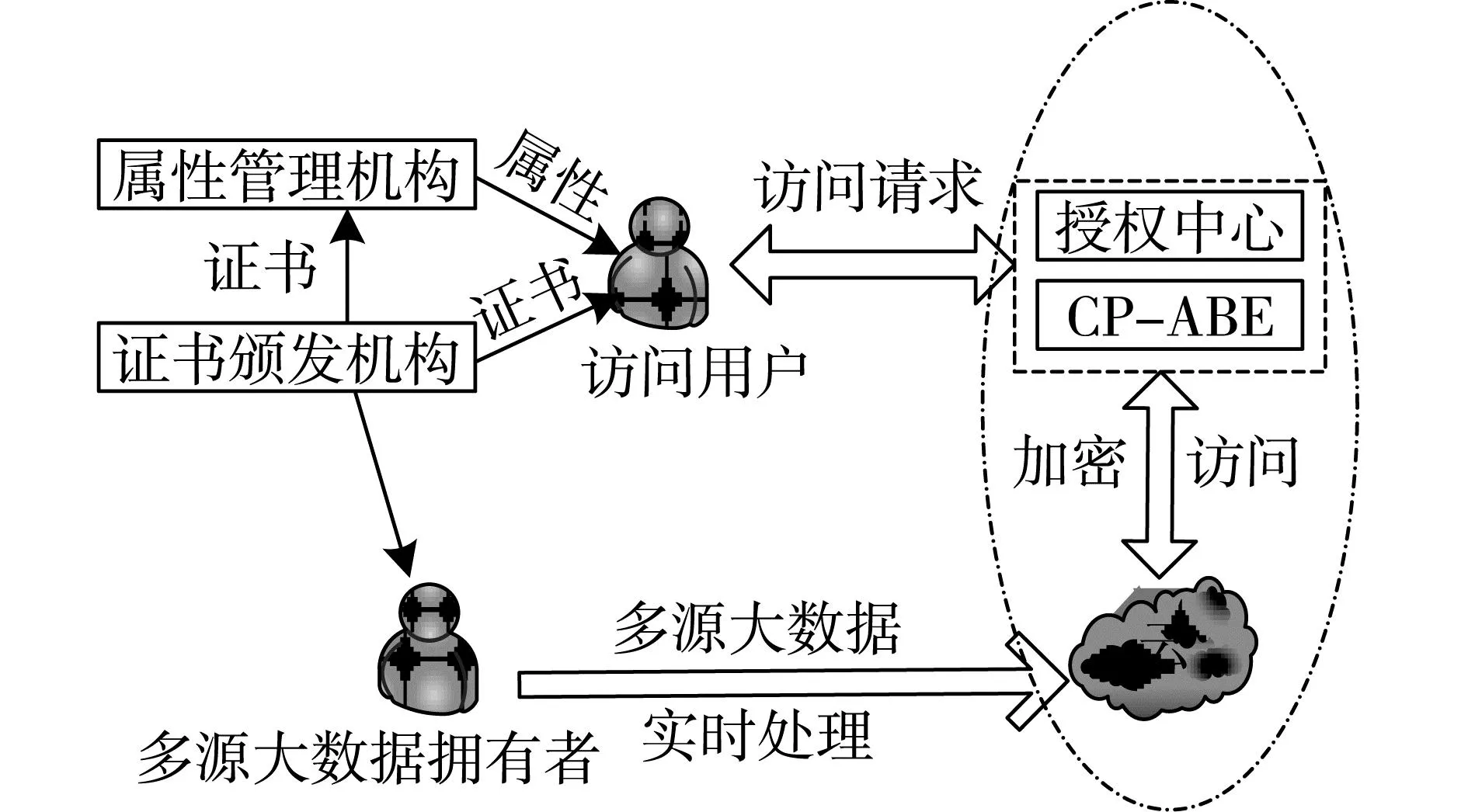
图1 多源大数据安全访问控制模型
证书颁发机构能够为访问用户、多源大数据拥有者、属性管理机构等颁发公钥证书。访问用户的公钥证书在多源大数据拥有者的访问用户权限列表中,该访问用户即可访问多源大数据。
属性管理机构根据不同用户更新、发布以及撤销用户属性,该机构主要负责生成公共属性密钥,将密钥颁发给具有访问权限的用户。
多源大数据拥有者将多源大数据加密后再上传至云中,结合CP-ABE设置访问控制策略管理访问用户怎样访问特定的多源大数据资源,管理数据资源的访问权限。本文只有多源大数据拥有者才能够更新访问控制策略[19]。
访问用户想要访问(读或者写)多源大数据时,属性管理机构将会给该访问用户颁发属性。访问用户将访问多源大数据的请求发送到控制模型的授权中心,经过授权中心的检验,给予该用户访问多源大数据的权限。
1.2 基于CP-ABE的多源大数据安全访问控制方法
本文提取出基于CP-ABE的多源大数据安全访问控制方法。CP-ABE由属性、访问结构以及访问树三部分组成[20]。
设集合P={P1,P2,…,Pn}代表多源大数据全部属性,访问用户的属性用C表示,访问用户属性是多源大数据属性集合中的非空子集,C⊂{P1,P2,…,Pn},说明根据属性N能够辨别2N个用户。
设u表示访问结构,且u⊂2{P1,P2,…,Pn}∉φ。访问结构能够辨别访问用户的属性,若访问用户的属性集合在访问结构中,则表示该集合已被授予访问权限;若访问用户的属性集合不在访问结构中,则表示该集合没有获取访问权限。
访问树用于描述一个访问结构,多源大数据的加密密钥隐藏在其中,访问树的叶节点象征着访问用户的属性。该树中的所有节点均为一个多项式,采用前序遍历的方式,按照从左至右的顺序进行访问[21-22]。
CP-ABE由以下四个步骤构成。
Setup:多源大数据拥有者生成主密钥和公钥。
Encypt:多源大数据拥有者运用公钥、访问结构加密多源大数据文件,得到多源大数据密文。
KeyGen:访问用户结合其属性和主密钥得到属于该访问用户的私钥。
Decrypt:利用访问用户的私钥将已经加密的多源大数据密文解密,得到多源大数据明文。
将CP-ABE用于多源大数据安全访问控制机制中,虽然增加多源大数据访问控制的安全性能,但CP-ABE并没有和多源大数据安全访问控制模型相结合,无法提高该访问控制模型的效率。因此,本文提出基于改进属性加密的多源大数据安全访问控制方法,更加全面的定义多源大数据的安全访问控制过程。
1.3 改进属性加密
以往的属性加密算法通常基于访问策略控制访问权限,在只有满足特定属性或属性组合的用户才能解密和访问加密数据。而改进属性加密算法引入了访问树这种更加灵活的控制方式,能够适应不同场景和需求的变化。
1.3.1 计算主密钥和公钥
在集合P={P1,P2,…,Pn}中共有n个元素,设p表示元素的素数阶,p的乘法循环群用G和GT表示,设g表示G的生成元。设M个群元素h1,h2,…,hM∈G和属性集合P相关联,从中任意选取指数a、b。
多源大数据所有者的主密钥为K,其计算公式为:
K=ga
(1)
多源大数据所有者的公钥为K′,其计算公式为:
K′={g,K(g,g)a,gb,h1,…,hM}
(2)
1.3.2 文件加密
多源大数据拥有者设定待加密存储的多源大数据在云存储中心有且仅有一个ID,为了提高属性加密算法的灵活性,使其可以适应不同属性用户的需求,将访问树机制引入文件加密中,任意选取一个对称密钥S加密多源大数据文件,得到密文用C(t)表示,具体表达式为:
C(t)=Encypt(K′,{S,Ksi,Kve},u,t)
(3)
式(3)中,签名密钥的读、写权限分别为Kve、Ksi,其中Ksi主要表示用户进行写的步骤后,签名该多源大数据文件;Kve也被称为验证密钥,主要用于验证签名结果。多源大数据访问树的访问结构为u,加密多源大数据过程的时间戳为t。
访问用户权限列表中所有访问用户的属性集合用Pu表示,计算出访问用户的私钥用Kpru表示,具体表达式为:
Kpru=keyGen(K,Pu)
(4)
对访问用户的私钥后加密,将加密后的私钥发送给该访问用户。
多源大数据拥有者将多源大数据文件加密后储存在云中,将具有访问多源大数据文件权限的用户ID,已经访问多源大数据文件的用户名单以及删除访问多源大数据文件权限的用户名单等访问用户权限列表储存在云中。
1.3.3 获取用户授权和读写数据文件
在多源大数据安全访问控制模型中,所有访问用户都有一个公钥、一个私钥,用户证书中存储访问用户的公钥,并公开验证消息来源的真实性;多源大数据拥有者在建立多源大数据文件时将私钥发送给访问用户,访问用户通过客户端储存私钥,为保证多源大数据的可靠性,需要对消息签名。
如果访问用户想要读取加密的多源大数据文件,那么访问用户应当查找多源大数据密文,从中找到想要读取的加密文件、访问结构以及签名。
通过上述计算,得到访问多源大数据文件的两种密钥,分别为S、Kve。访问用户将含有上述两种密钥的访问请求发送到访问模型的授权中心,授权中心接收到访问请求后,将访问请求中的S、Kve和云端中存储的访问用户权限列表中的对称、验证密钥对比,若两者成功匹配,说明该访问用户得到访问多源大数据的权限。
与此同时,访问用户运用密钥验证签名的准确性,若该签名是准确的,运用对称密钥解密加密文件,得到多源大数据明文。
1.3.4 控制访问用户权限
1.3.4.1 授予访问用户权限
授予访问用户权限指的是将访问用户的属性集添加到访问结构中。多源大数据拥有者在多源大数据文件的密钥体中得到密文,多源大数据拥有者运用私钥和访问结构,解密密文得到签名、验证、对称三种密钥,将访问用户的属性集添加到访问结构中,得到新的访问结构,其表达式为:
u′=u∨Pu
(5)
此时,根据u′得到新的多源大数据密文C′(t)的表达式为:
C′(t)=Encypt(K′,{S,Ksi,Kve},u′,t)
(6)
此时,多源大数据拥有者将多源大数据文件的密钥体中的密文更新为C′。
1.3.4.2 访问用户权限扩展与删除
访问用户权限的扩展就是在访问结构中添加访问用户的属性,多源大数据拥有者依据访问用户的属性和式(4)得到访问用户的私钥;按照该用户的访问请求增加新的访问权限,将该权限的属性添加到原始多源大数据信息中,根据式(5)和式(6)得到新的访问结构以及数据项,最后将数据项写入多源大数据文件密钥体中。
访问用户权限的删除就是从多源大数据文件密钥体的访问结构中删除访问用户的属性集。当多源大数据拥有者按照访问用户属性集和式(4)得到访问用户的私钥,在多源大数据文件密钥体数据项中查找出其访问结构,从原访问结构中删除该访问用户的属性集,即u′=u-Au,多源大数据拥有者得到新的验证密钥用Kve′表示,S′表示新的对称密钥、Ksi′表示新的签名密钥。新的多源大数据密文的表达式为:
C′(t)=Encypt(K′,{S′,Ksi′,Kve′},u′,t)
(7)
访问用户运用新签名密钥对多源大数据文件重新签名,用C′(t)代替C。
通过以上流程,完成改进属性加密,高效率实现多源大数据安全访问控制,维护大数据安全共享。
2 实验分析
以SQL Server数据库作为本次实验对象,Python为实验的开发语言。本次实验外部环境为:酷睿i9-12900处理器,5.1GHZ,30M的三级缓存。操作系统为UNIX,在VMware Workstation 6.5.2虚拟机上安装Ubuntu 16.04。客户端云服务器为8核16G。
本文方法是在CP-ABE的基础上进行改进,为验证本文方法改进效果,在属性数量和访问用户不同的情况下,将CP-ABE改进前后的多源大数据拥有者根据访问用户属性的主密钥生成私钥的时间进行比较,比较结果如图2所示。
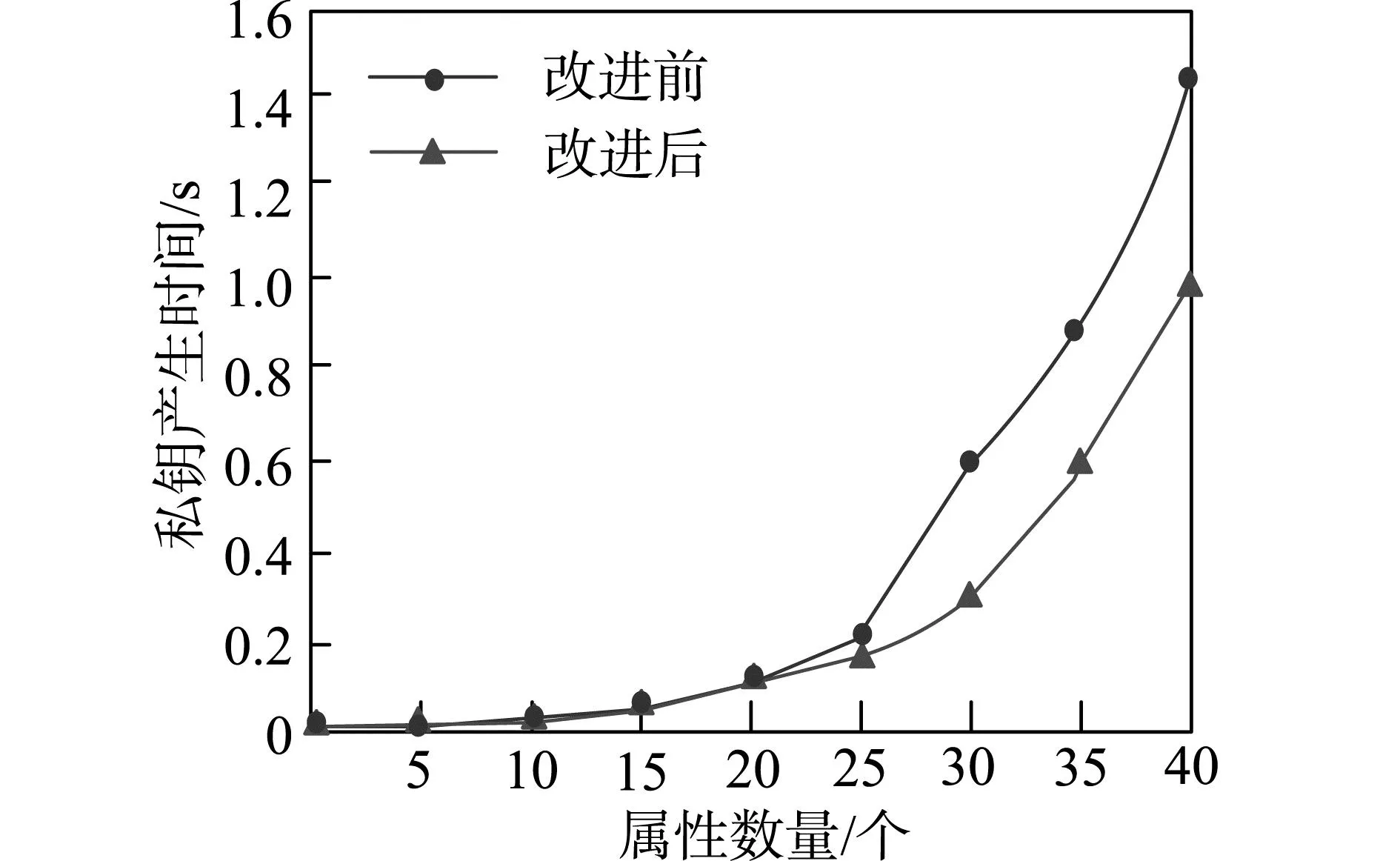
(a)属性数量不同
由图2(a)可知,随着访问用户以及属性数量的增长,多源大数据私钥产生的时间也逐渐增加。属性数量在20以内时,CP-ABE改进前后,访问用户的私钥产生时间几乎一致;属性数量超过20时,改进后访问用户私钥产生时间较短,且始终低于1s。由图2(b)可知,当访问用户数量超过100时,改进后访问用户私钥产生时间相比改进前显著降低,且私钥产生时间始终低于2s。实验结果表明,改进后CP-ABE的私钥产生时间较短,提高了私钥产生的效率。
在属性数量分别为15、30时,运用本文方法进行多源大数据安全访问控制,统计所占用存储空间情况,如图3所示。
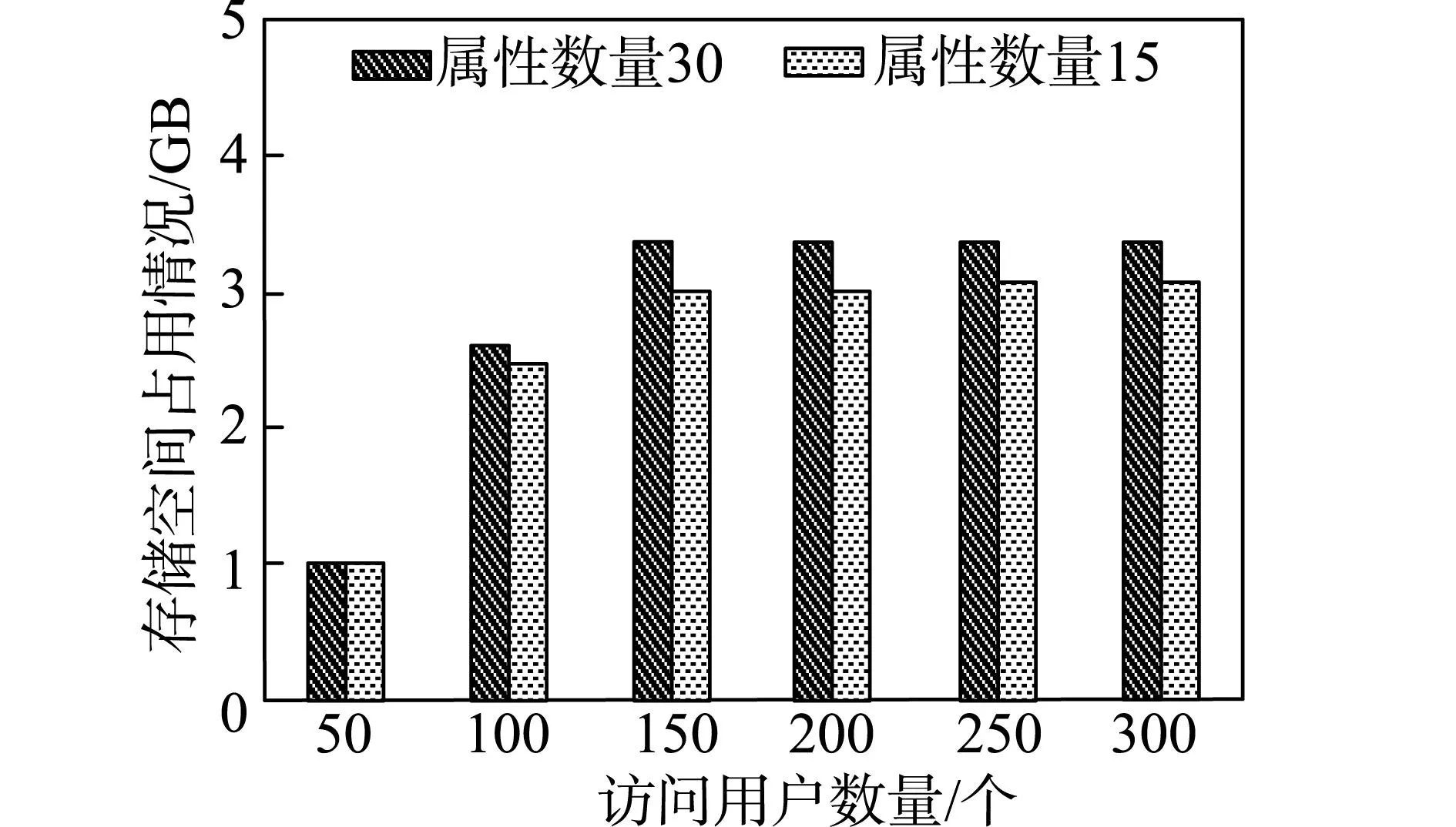
图3 存储空间占用情况
由图3可知,随着访问用户的数量增加,占用的存储空间也逐渐增大,属性数量的增加也会导致占用的存储空间增加。但当访问用户数量超过150时,在本文方法的控制下存储空间基本趋于稳定,不会因为用户数据量及属性数量的增加导致占用的存储空间剧增。实验结果表明,在访问用户及属性数量增加时,本文方法仍能够储存大量多源大数据文件的密钥体数据,极大的减少了存储空间开销。
通过验证本文方法加密效果,衡量本文方法的安全访问控制性能。从数据库中任意选取一个多源大数据文件,运用本文方法进行加密,加密前后多源大数据文件中的字符变化如图4所示。
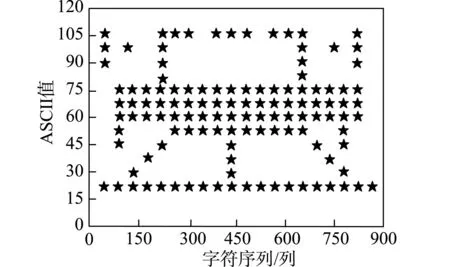
(a)加密前的数据ASCII值的分布
由图4(a)可知,加密前多源大数据文件中的字符按照某种次序工整的排列,ASCII值也具有相应的分布顺序。而图4(b)中加密存储后的多源大数据文件中的字符杂乱无章,毫无排列规律,且ASCII值分布比较均匀,完全隐藏原始多源大数据文件中的字符。实验结果表明,本文方法在加密多源大数据后,能够将多源大数据内容完全隐藏,避免没有权限的用户直接查看多源大数据文件,从而提高访问多源大数据的安全性。
为验证本文方法的实用性,运用本文方法管理访问用户的访问多源大数据的权限,并通过大数据安全控制访问系统呈现本文方法安全访问控制结果,如图5所示。

图5 本文方法访问控制结果
由图5可知,运用本文方法能够快速辨别访问用户是正常用户还是恶意用户。从大数据安全控制访问系统的安全访问控制日志中可查看某一时间段的访问用户,若访问用户在多源大数据安全控制访问系统的访问用户权限列表中,则说明该用户具有访问多源大数据文件权限,可以查看有访问权限的多源大数据文件。若访问用户不在该列表中,说明系统检测出该用户为恶意用户,阻止该用户访问多源大数据文件。实验结果表明,本文方法能够实现多源大数据安全访问控制,阻止恶意用户访问数据,维护多源大数据的安全,实用性较好。
结语
为了维护多源大数据的安全性,提出基于改进属性加密的多源大数据安全访问控制方法。通过实验验证本文方法生成私钥的效率、存储空间占用、数据加密效果以及实用性。实验结果表明,在属性数量和访问用户数量不同的情况下,改进后CP-ABE根据访问用户属性生成私钥的时间明显降低,提高了私钥生成效率。随着访问用户及属性数量的增加,本文方法有效储存多源大数据文件密钥体数据,节约存储空间,增加多源大数据的安全访问性能。能够辨别恶意用户访问,维护大数据安全共享。
猜你喜欢
计算机与网络(2022年2期)2022-03-17 22:48:16
网络安全技术与应用(2021年7期)2021-07-16 06:13:20
装甲兵工程学院学报(2018年1期)2018-06-19 09:57:06
网络安全和信息化(2018年9期)2018-03-03 18:11:15
信息安全研究(2018年1期)2018-02-07 01:44:46
网络安全和信息化(2017年12期)2017-11-08 10:39:14
中国公共安全(2017年11期)2017-02-06 05:28:08
通信学报(2016年11期)2016-08-16 03:20:32
现代工业经济和信息化(2016年19期)2016-05-17 05:38:20
信息安全研究(2016年10期)2016-02-28 20:18:36
