
基于生成对抗网络的图像修复研究
2024-01-11 03:01:14刘庆俞
黑龙江工业学院学报(综合版) 2023年10期
刘庆俞,刘 磊,陈 磊,肖 强
(1.淮南师范学院 计算机学院,安徽 淮南 232038;2.国家大学 计算机与信息技术学院,菲律宾 马尼拉 0900)
图像修复是指将一幅破损或有缺失的图像利用技术手段进行补全,使其语义连贯、纹理细节合理。图像修复的目标是通过重建破损区域像素来尽量恢复到原始图像。图像修复是计算机视觉领域的一个热点研究课题,在很多方面发挥着巨大作用,比如字画的破损修复、图像的超分辨率、图像去雾[1-2]、公安人员对口罩遮挡嫌疑人的人脸识别等。
图像修复技术主要有传统修复方法[3-5]和基于深度学习的修复方法[6-8]。扩散理论的传统修复算法是利用周边的像素来填补缺失区域,它只能修复小的缺失区域且很难生成语义丰富的图像结构。基于块的修复方法可以从源图像集中提取相似的像素块来快速填补图像。它的主要问题是假设缺失区域和其他图像具有相同或相似的像素信息。因此,对于简单结构的图像修复效果较好,但是对于复杂的缺失区域往往修复效果不佳,且计算量较大。近年来随着卷积神经网络的快速发展,尤其是生成对抗网络的出现,基于深度学习的图像修复算法为图像修复提供了新的解决思路。这类方法一个重要特点是可以从未遮挡的其他区域内提取到有意义的语义信息,进而生成新的内容重建缺失像素。
Context Encoder(CE)[9]是首个基于生成对抗网络[10]的图像修复方法,整体结构为编码-解码器结构。编码器将缺损图像映射到低维特征空间,解码器用于重构图像,编码后的特征通过基于通道的全连接层融合输入至解码各阶段。但由于在生成过程中未充分考虑到全局一致性与语义连贯性,导致重构部分存在较严重的视觉模糊现象。
为了提升图像修复效果,本方案在CE模型的基础上引入UNet[11-13]结构,利用其跳层连接融合低层纹理特征和高层语义特征。另外在生成器的下采样模块中引入改进的残差模块和自注意力模块[14],以保证在降低参数量的同时不降低图像特征提取能力。
1 相关理论
1.1 生成对抗网络
生成对抗网络(Generative Adversarial Network,简称GAN)最早是由Goodfellow等人提出的一种深度学习模型,一经提出就被认为是二十年来机器学习领域最酷的想法。GAN网络的原理结构框架如图1所示,其中G表示生成网络(Generator),它通过接收随机噪声数据z生成相应的图像。D是表示判别网络(Discriminator),用来判断输入的图像x是真实的图像还是G生成的“假”图像。判别器的输出表示x为真实图像的概率,0表示判定其是假的图片,1则代表判别器鉴定其为真实图像。
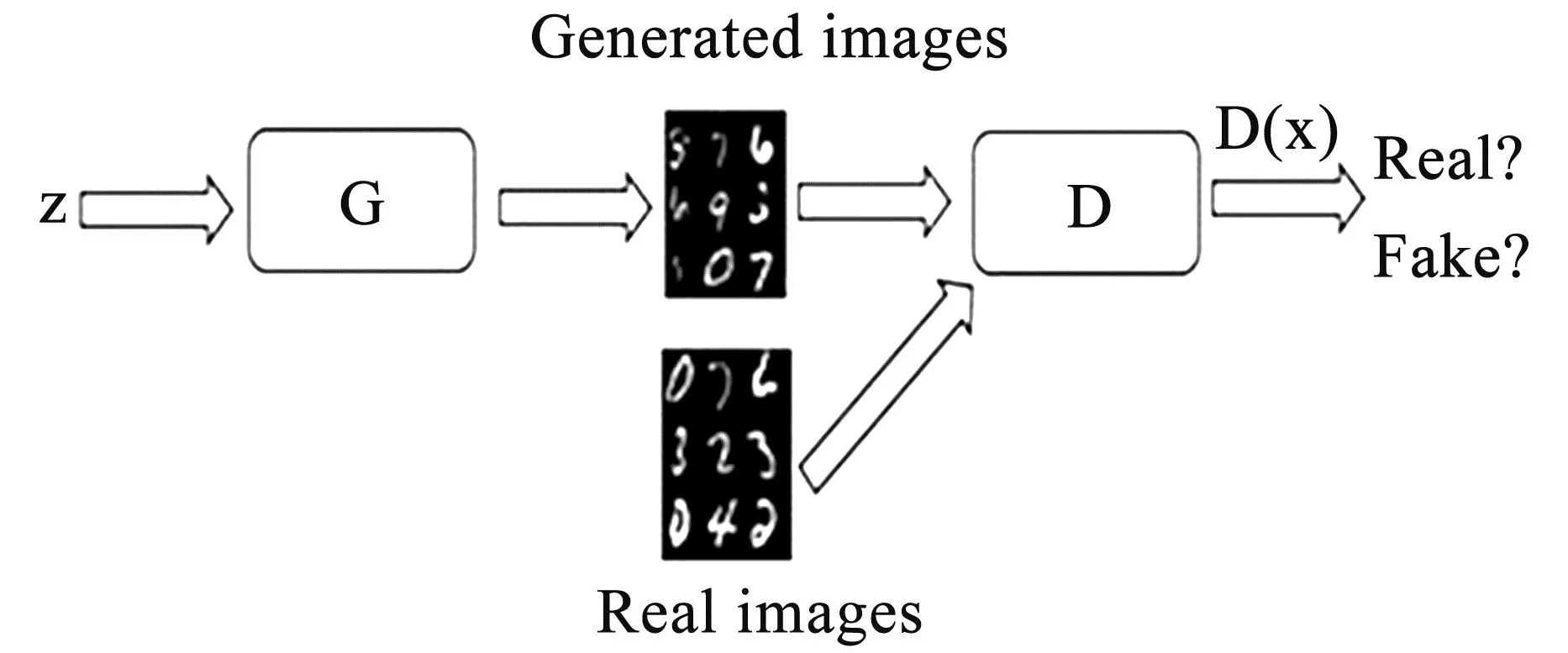
图1 GAN网络结构
GAN的思想主要来源于“零和博弈”理论。研究人员之所以将其引入到深度学习领域,就是利用生成器和判别器这两个前馈网络进行最小最大博弈的对抗训练。训练过程中鼓励生成器不断向真实数据的分布逼近,进而做到生成“以假乱真”的图像。由于具备这种灵巧的博弈对抗学习机制以及拟合数据分布的潜在能力,可以用来进行图像修复。因此,可进一步将这种博弈关系表示为:
MinGMaxD(D,G)=Ex~Pdata(x)[logD(x)]+
Ez~Pz(z)[log(1-D(G(z)))]
(1)
式(1)中,z和x分别表示随机噪声矢量和从真实数据分布Pdata(x)采样的真实图像。D(x)和D(G(z))分布表示对真实图像和生成图像的判别结果。式(1)也表示GAN是一种可以生成特定数据分布的模型。
正是因为GAN这种无监督且可产生新内容的博弈过程,使其在图像处理和图像修复领域得到更广泛的关注。在损失函数的作用下,通过判别器的不断优化,会促使生成器生成更接近于真实图像的优质图像。这对于图像修复技术尤为重要,因为修复结果主观上就是通过人眼视觉感知、判断算法的优劣。
1.2 自注意力机制
自注意力机制是注意力机制的一种,在图像处理方面,上下文信息对于局部特征的提取非常重要。自注意力机制通过(key、query、value)这种三元组提供了一种有效的捕捉图像全局上下文信息的建模方式。具体可以表示为:
(2)
式(2)中,f和g分别是一种查询变换,βi,j表示修复第j个像素时,模型对第i个像素点的关注程度。假设o是N个C维的向量组,配合另外一种变换h,可以得到自注意力层的输出特征图oj,具体如式(3)所示。
o=(o1,o2,…,oN)∈RC*N
=Whxi,v(xi)=Wvxi
(3)
于是最终特征输出为:
yi=μoi+xi
(4)
式(4)中,μ为可训练的影响因子,其初始值一般为0。xi为输入,yi即是自注意力机制处理后的输出特征。随着训练的进行,可以获得从局部到全局的信息。
2 模型设计
本文将UNet结构和CE模型相结合,在生成器中加入改进的残差模块和自注意力机制来提升图像修复效果,具体框架如图2所示。生成器经过连续的下采样提取特征并降低特征图大小,在上采样的过程中得出修复后的小图。最后将修复后的小图嵌入遮挡的原始图像中得到最后的修复图像。

图2 模型整体框架
2.1 生成器
本文假设原始遮挡图像大小为128×128,遮挡掩码居中为64×64。生成器由7个下采样模块和6个上采样模块组成,输出为修复后的遮挡区域。图3为下采样模块结构,包括2个改进后的残差模块,其中一个残差模块通过步长stride设置为2来降低特征图大小。
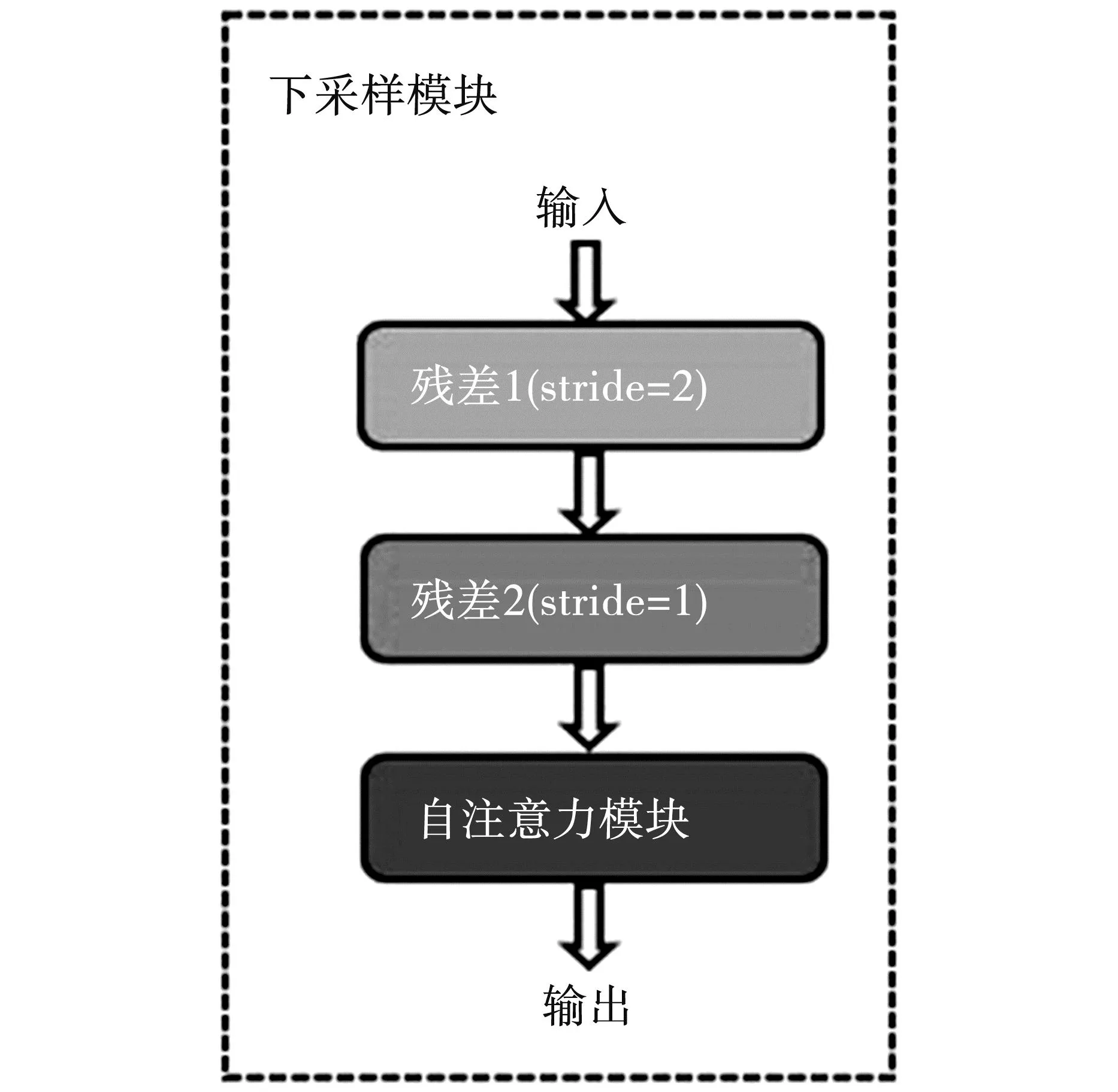
图3 下采样模块结构
残差网络的出现是深度学习领域的重要成果[15],它指出在神经网络中,较深的网络应该不会比较浅的网络效果差,通过输入的恒等映射即可实现深度神经网络。图4左图即为原始的残差模块,它可以解决网络退化问题。残差网络越深,特征提取能力越好。考虑到不同大小的卷积核能够提取不一样的特征,本研究在原始残差模块的基础上增加了多尺度卷积神经网络分支来进行特征融合,从而更好地在下采样过程中提取有效特征。改进后的残差模块包括3路卷积分支,分别是1×1、3×3和5×5的卷积分支,模块的输出为3路卷积结果的融合。根据实际需要来计算复杂度,可以调整分支数。卷积分支中,激活函数使用LeakyRelU,使用InstanceNorm2d替换BatchNorm2d。
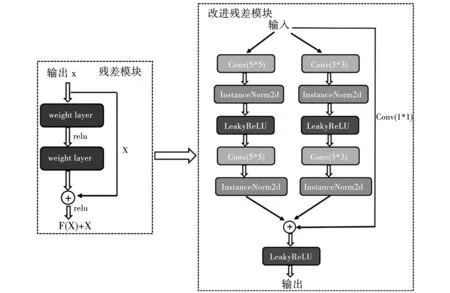
图4 多尺度残差模块
图5是上采样模块结构,也包括了一个改进后的残差模块,步长stride为1,即特征图大小不变。上采样模块中使用了“Concatenate”操作,将处理得到的特征图与对应大小的上采样特征图进行通道维度的叠加处理。这种操作的结构是结合了底层和高层的特征,尽量保持其他未遮挡区域像素的一致。
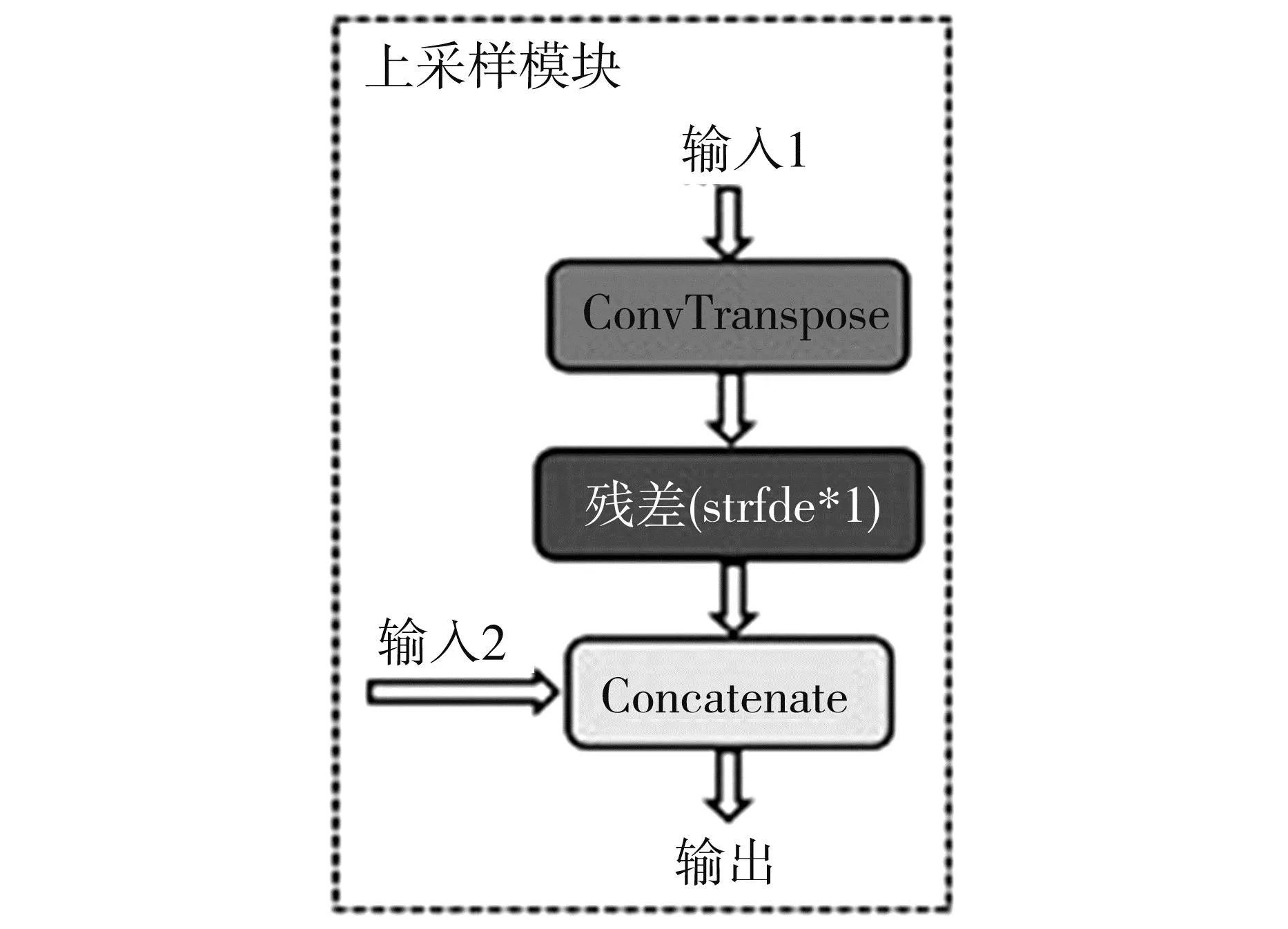
图5 上采样模块结构
2.2 判别器
判别器和生成器相辅相成,用于判断输入的图像是真实的“自然”图像,还是生成器生成的“假”图像。图6显示判别器共有三个卷积操作,分别将输入图像大小减半,输出为(1,8,8)的矩阵。矩阵中的每一个点代表了原始输入图像的一个区域。
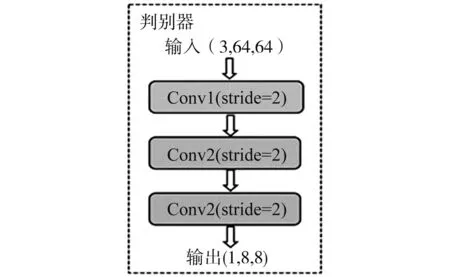
图6 判别器结构
2.3 损失函数
在生成对抗网络中,损失函数起着重要的作用,判别器和生成器分别对应自己的损失函数。生成器损失函数包括L1损失(LossL1)和对抗损失(Lossadv),两种损失的权重之和1(γL1+γadv=1),具体为:
LossG=γL1×LossL1+γadv×Lossadv
(5)
对于判别器,它接收2种输入图像,真实图像给予高判别值,生成图像则数值较低。损失函数只采用对抗损失,具体为:
LossD=Lossadv(D)
(6)
3 实验与分析
3.1 实验数据与环境设置
本文的图像修复模型训练和测试均在Celeb A数据集上进行。该图像数据集包括202599张各国名人的人脸图像,选取其中26000张用于模型训练,1000张用于测试。图像初始化为128*128,人脸遮挡区域居中且为64×64。
实验硬件环境为Intel Xeon处理器,128G内存和8块3090显卡。软件环境使用Red Hat 4.8.5,Python 3.7.1,Pytorch 1.10。实验超参数γadv为1,γL1为100,batch size为300,优化器为Adam。
3.2 定性分析
为了证明模型的有效性,将本文所提的图像修复算法与CE、CE-UNet(CE模型的生成器添加UNet结构)和GLGAN[16]在同一个图像数据集上进行对比。图7为四种修复算法在矩形遮挡的人脸图像上修复的效果图(模型训练到800epoch)。其中,第一列为遮挡人脸图像,最后一列为原始正常人脸。中间四列依次为不同修复算法的修复结果。显然,本文修复算法的效果优于其他三种算法。CE和CE-UNet算法修复后的图像存在明显的模糊和边界突出的问题,而GLGAN算法的整体修复效果略差于本文方法。本文修复效果和原始人脸具有较好的一致性,人脸的细节恢复较好,保证了视觉上的自然和纹理的连贯性。

图7 修复效果图(800epoch)
3.3 定量分析
为了更好地说明本文修复算法的有效性,使用PSNR(峰值信噪比)和SSIM(结构相似性)[17]两项参数进行定量数据分析。PSNR一般用于衡量最大值信号和噪音数据之间的图像质量参考值。PSNR值越大,图像失真越少。SSIM是一种衡量图像之间相似度的指标。一般来说,SSIM在评价图像质量上更能符合人类一般的视觉特性。SSIM使用的两张图像中,一张为原始的无失真图像,另一张为处理后的图像。显示本文所提算法的修复结果在PSNR和SSIM两项指标上也是优于前面3种算法,如表1所示。

表1 修复结果的定量分析表
结语
本文在原始CE模型的基础上改进了生成器和判别器网络结构。生成器采用UNet跳层连接,同时下采样模块使用了多尺度的残差模块和自注意力机制以提高模型的特征提取能力。在对抗损失和L1损失函数的作用下,实现了更好的图像修复效果。实验结果表明,本文修复算法在定量分析和定性分析方面都取得了明显的提升。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
自动化学报(2019年6期)2019-07-23 01:18:32
今日农业(2019年15期)2019-01-03 12:11:33
CHIP新电脑(2016年3期)2016-03-10 14:22:03
