
阅读研究中常用眼动控制模型的对比分析
2024-01-09 23:03:02陈松林陈新炜李璜夏药盼盼
心理科学进展 2024年1期
陈松林 陈新炜 李璜夏 药盼盼
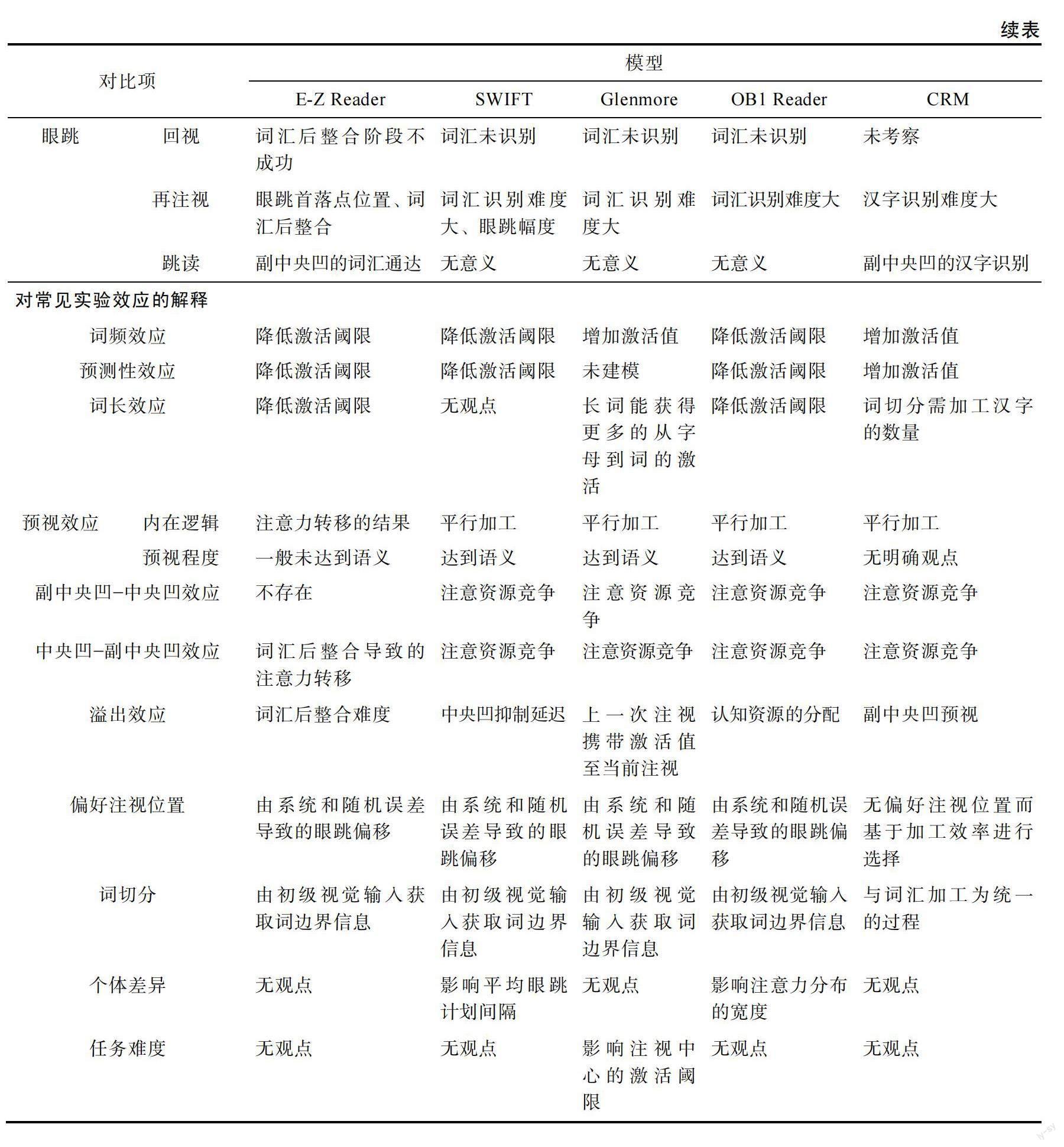

摘 要 建立于序列加工理论、平行加工理论和交互激活理论, 一些经典的眼动控制模型对阅读过程中常见的眼动行为、实验效应及其背后可能的信息加工认知机制进行了模拟和探究。阅读研究中的5种经典眼动控制模型——E-Z Reader 10th、SWIFT、Glenmore、OB1 Reader和CRM, 在模型结构、模型基本逻辑、解释常见眼动行为、解释常见实验效应上存在相似性亦有独特性。基于对上述模型的对比分析, 未来模型需要考察词汇后整合的问题、语序的问题、语言外因素的问题, 可尝试对偏好注视位置的最新实证研究结果进行一定程度的解释, 建立模型对比的统一标准, 探索各个模型的跨语言解释力。
关键词 E-Z Reader, SWIFT, Glenmore, OB1 Reader, CRM, 眼动控制
分类号 B842.5
1 引言
阅读是协同了一系列不同认知活动(如视觉信息加工、文字与词语识别、注意力的分配和转移、眼球运动控制等)的高级认知行为。探究阅读过程认知机制是心理语言学领域的核心课题, 而揭示阅读过程中的眼动控制规律则是当前热点话题。近年来, 基于大量眼动实验数据, 研究者们建立了不同的计算模型来模拟阅读过程中的信息加工(Li, Huang et al., 2022; Mézière et al., 2021; Yu et al., 2021; Zhang, Yao et al., 2022)。本文分析整理了经典的5种眼动控制计算模型, 并系统对比了各个模型的结构、逻辑及其对常见阅读眼动行为和实验效应的解释。对这些眼动控制模型系统深入的了解有助于我们认知真实的阅读过程。
基于知觉广度内视觉注意分配的差异, 眼动控制计算模型大致可分为两大类型, 即序列加工模型(sequential attention shift models)和平行加工模型(parallel graded processing models)。这两大派系从各自诞生之始至今, 仍存争议(Reichle, Liversedge et al., 2009; Snell & Grainger, 2019a; Snell & Grainger, 2019b; 综述见Murray et al., 2013; Rayner et al., 2003; 马国杰, 李兴珊, 2012; 隋雪 等, 2013; 吴俊, 莫雷, 2008)。序列加工模型的基本假设是:注意力一次只能被分配到一个词上, 且以严格序列的顺序从一个词转移到下一个词。其典型代表是E-Z Reader (Pollatsek et al., 2006; Rayner et al., 2005; Reichle et al., 1998, 1999, 2003, 2006; Reichle, Warren et al., 2009)。與之相对, 平行加工模型则假设可以同时加工多个词, 每个词的加工程度由视觉空间注意梯度进行调节。其典型代表是SWIFT (Engbert et al., 2002, 2005; Richter et al., 2006), Glenmore (Reilly & Radach, 2006)和OB1 Reader (Snell et al., 2018)。但上述模型都是基于拼音文字(英语和德语)的实证研究成果构建的。由于语言的特异性, 这些模型在非拼音文字(如中文)中是否也具有解释力则亟待证实。中文的书写系统由方块字组成, 且不存在词边界的标记。这就对已有模型模拟词切分和词识别提出了挑战。针对中文书写系统的特异性, Li和Pollatsek (2020)提出了中文阅读模型(Chinese Reading Model, 下文简称CRM)。该模型主张对知觉广度内的汉字进行平行加工, 而对词的加工也是平行的, 只是一般词n+1的激活强度较低, 因此加工较慢。
国内已刊发的文献对E-Z Reader、SWIFT、Glenmore都有过详细的介绍(陈庆荣, 邓铸, 2006; 胡笑羽 等, 2007; 刘丽萍 等, 2006; 沈模卫 等, 2002; 隋雪 等, 2018), 而缺少对更新版本的E-Z Reader (Reichle, Warren et al., 2009)、OB1 Reader以及CRM的介绍。同时, 已有介绍类文献的重点在于介绍模型, 而没有对相关模型进行系统的比较分析, 从而可能导致对相关模型的认识是孤立片面的。本文在对上述模型的最新版本进行介绍的基础上, 对相关模型进行了系统的比较分析, 并对眼动控制模型构建的未来发展进行了展望。为了更加系统直观地对比不同模型, 我们将各个模型的特点总结归纳在表1中。
2 模型概览
2.1 E-Z Reader
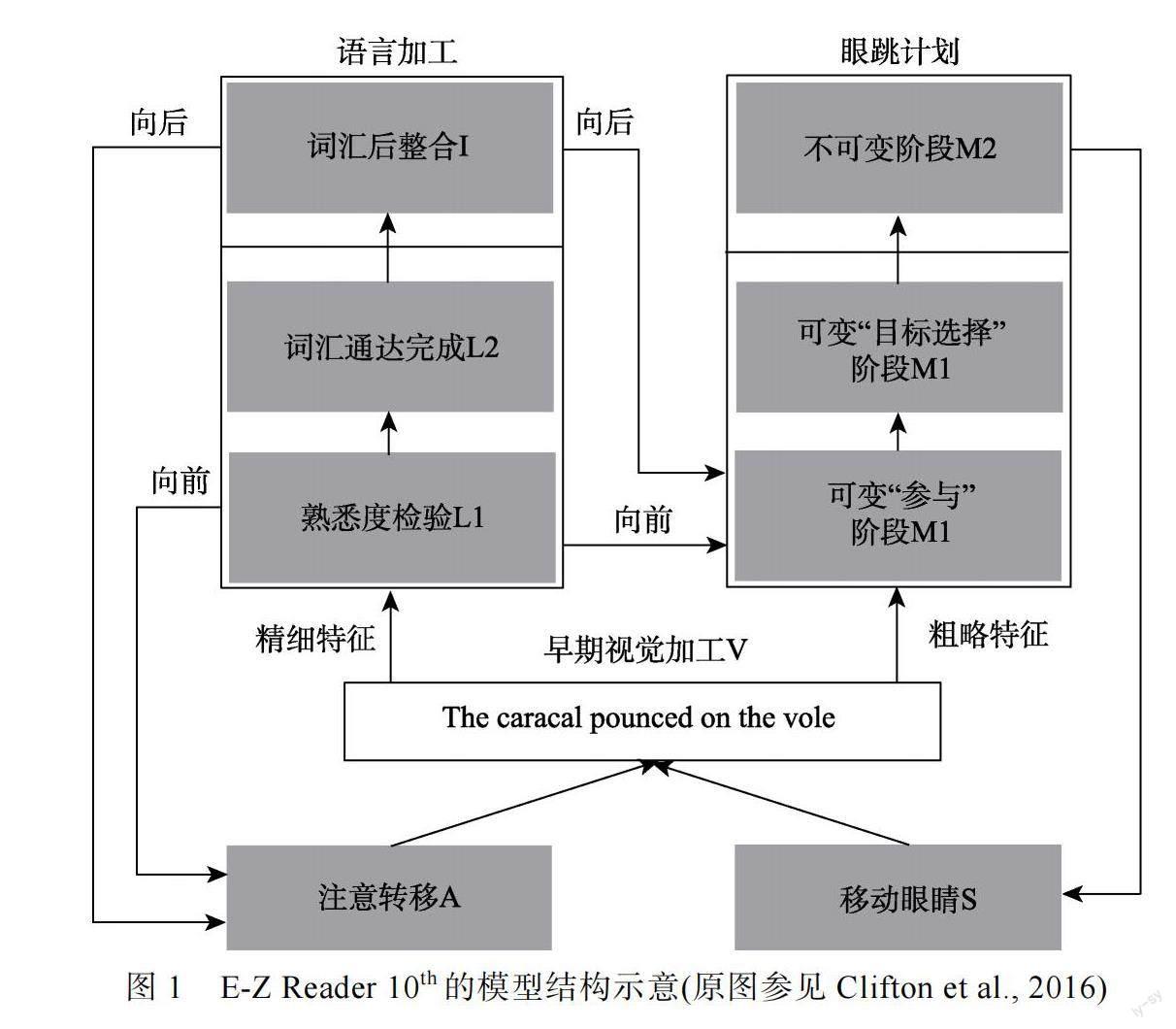
E-Z Reader是序列加工理论模型的典型代表, 是由Reichle、Pollatsek、Rayner等人基于英文阅读研究成果提出的模型(Pollatsek et al., 2006; Rayner et al., 2005; Reichle et al., 1998, 1999, 2003, 2006; Reichle, Warren et al., 2009)。自1998年提出以来, 为适应新的实验发现, 该模型已逐步发展至第10个版本, 该模型被广泛用来解释各种阅读过程中的眼动现象(Bordag & Opitz, 2022; Tschense & Wallot, 2022; Veldre et al., 2023; Yang et al., 2021)。E-Z Reader的发展经历了从简单到复杂的过程。具体而言, 模型1 (Reichle et al., 1998)考察了词频对词汇识别的影响。模型2 (Reichle et al., 1998)增加了可预测性因素的影响。模型3 (Reichle et al., 1998)增加了对一个单词可进行多次注视的机制。模型4 (Reichle et al., 1998)引入了离心率因素的影响。模型5 (Reichle et al., 1998)引入了离心率的不同作用机制, 假设离心率对词汇通达阶段的影响更大。模型6 (Reichle et al., 1999)在字符水平上阐明了各变量对阅读眼动控制的影响, 同时细化了再注视机制。模型7 (Reichle et al., 2003)增加了一个早期视觉加工过程, 并在新的实验和模拟数据的基础上改进了公式和相关参数。模型8 (Rayner et al., 2005)和模型9 (Pollatsek et al., 2006; Reichle et al., 2006)模拟了新实验范式的结果(如移动窗口范式、消失文本范式等)并调整了部分参数使模型更符合实际。模型10 (Reichle, Warren et al., 2009)新加入了词汇后整合阶段用于解释更高水平因素对阅读的影响, 其是本文所述的5个模型中唯一一个对词汇识别后的词汇后整合加工进行解释的理论模型。在这一系列模型中, 本文侧重介绍最新版本, 即E-Z Reader 10th (下文中简称E-Z Reader, 其模型结构如图1所示)。该模型包含了词汇加工和眼跳控制两个部分。词汇加工又包含熟悉度检验、词汇通达完成和词汇后整合三个阶段。眼跳控制则包含计划可变阶段、计划不可变阶段和眼跳执行三个阶段。这两部分是互相联系影响的:熟悉度检验阶段的完成会触发去往下一词的眼跳计划, 词汇通达完成会使注意力转移至下一词, 而词汇后整合则会调控眼跳控制。该模型很好地解释了诸如词频、词长、视敏度、预测性和词汇后整合对读者阅读过程眼动的影响。
2.2 SWIFT
SWIFT是平行加工理论模型的典型代表, 由Engbert、Nuthmann、Richter、Kliegl等人基于德语数据构建(Engbert et al., 2002, 2005; Richter et al., 2006), 目前已更新至第二版(模型结构如图2), 其中第二版模型是对第一版模型更详细的叙述。该模型也被用来模拟解释了很多实验效应(Antúnez et al., 2022; Gregg et al., 2023; Snell et al., 2023)。不同于E-Z Reader认为的注意力一次只能被分配到一个词上, 词汇加工以严格序列的顺序进行, SWIFT认为注意力是平行分布在知觉广度内(一般为4个词)的所有词上的, 即阅读广度内的多个单词同时被加工, 只不过其加工程度和速度存在差异(受到每个词视敏度、频率、预测性等因素的影响)。这些词互相竞争而胜者即为眼跳的目标。同E-Z Reader类似, SWIFT也包括了词汇加工和眼跳控制两个部分。其中词汇加工包括了词汇的前加工阶段和词汇通达阶段, 而眼跳控制包括了不稳定阶段和稳定阶段。词汇的前加工阶段主要对词汇的一些基本自然属性进行加工, 词汇的激活水平在这一阶段由0逐渐上升至最大值; 进入词汇通达阶段后, 词汇激活水平由最大值逐渐衰减, 直至词汇加工完成(词汇激活水平重新回到0), 注意资源此时开始根据知觉广度内多个词的激活程度进行重新分配。SWIFT认为所有眼跳都是随机产生的, 即在阅读过程中, 两次眼跳之间存在随机的时间间隔, 而眼跳的计划和执行会受到当前词汇加工的影响, 即当前加工词的词频、预测性等因素会在一定范围内影响眼跳计划(中央凹目标抑制机制)。该模型很好地解释了词频、预测性、视敏度等因素对阅读眼动的影响。
2.3 Glenmore
E-Z Reader和SWIFT都是从词汇识别开始建
模的, 并未涉及亚词汇信息(字母)的加工。基于此, 由Reilly和Radach構建的Glenmore (Reilly & Radach, 2006; 模型结构如图3)应运而生。该模型是基于德语数据提出的, 采用了平行加工的理论和交互激活的模型结构。该模型亦被用来模拟解释许多实验效应(Brossette et al., 2022; Gordon et al., 2020; Schwalm & Radach, 2023)。具体而言, Glenmore包括视觉输入层、字母层和词语层三个加工层, 并包含显著性地图(知觉广度内不同加工单元的激活值分布)、注视中心和眼跳发生器几个模块。词语识别方面, Glenmore认为, 词语的视觉信息会被传递到字母层和词语层, 从而完成对注视词字母和词语水平上的加工。字母层和词语层
之间是相互作用的, 字母层的信息传入词语层促进词语的识别, 而词语层又会对字母层进行反馈以保持字母的激活。同时, 词语层内多个激活的词之间会互相竞争, 每个词的激活强度和速度会受到其自身频率的影响。眼跳控制方面, 该模型认为, 眼跳目标选择是通过平行加工和显著性地图中的竞争来完成的。同SWIFT的逻辑类似, 当前注视词的视觉信息和字母信息会被转换为显著性地图, 进而影响眼跳目标选择。眼跳的实际触发是由一个注视中心模块控制的, 该模块可以接收来自多种认知加工途径的输入(字母层的激活、通过影响字母层而间接影响注视中心的词语层的激活、阅读任务、材料难度), 一旦注视中心模块的激活值超过某可调的阈值, 即触发眼跳。此外, 为解释溢出效应, 该模型还假设在一次注视完成后, 若该词得到通达则其激活值为零, 若未通达则该词的激活值可被携带至下一注视。
2.4 OB1 Reader
Glenmore虽加入了字母的加工, 但字母和词之间的连接是先验的, 即字母层的字母被先验地对应到了特定的词语, 而非传统的交互激活模型所述的字母层的字母能激活所有可能的词语。词语层到字母层的连接同理。这一操作并不符合心理认知现实。同时, 已有平行加工模型(SWIFT、Glenmore)并没有很好地解决词语激活顺序和句子语序之间的矛盾问题。为解决这些问题, Snell、Leipsig、Grainger、Meeter于2018年基于德语数据, 结合平行加工理论和交互激活模型构建了OB1 Reader (Snell et al., 2018; 模型结构如图4)。该模型创造性地加入了空间主题信息表征模块, 解决了激活顺序和语序矛盾的问题, 引发了大量对阅读机制中语序问题的探究(Brossette et al., 2022; Dufour et al., 2022; Mirault et al., 2022; Pegado & Grainger, 2020; Primativo et al., 2022; Zhang, Wang et al., 2022)。具体来讲, 模型认为, 视觉输入会激活开放双字母节点和包含词长信息的空间主题信息表征, 其中开放双字母节点的激活受视敏度、拥挤程度、注意权重等调节。开放双字母节点会激活多个词汇节点, 这些词汇节点相互竞争, 并被匹配到空间主题信息表征中。如匹配成功, 则词语得到通达, 如匹配失败, 则词语不通达。眼跳控制方面, 该模型认为眼跳触发是随机的, 而眼跳目标的选择视词语识别情况而定:当激活的词语与空间主题信息匹配成功, 则计划眼跳至视觉范围内显著性最高的词语(其显著性为组词字母的激活值之和); 若匹配失败, 则对左侧未识别的词语计划回视。同时, 该模型认为, 注意范围的大小取决于词语有没有得到通达:若通达则注意范围扩大, 若未通达则缩小。该模型解释了词长效应、正字法邻居大小效应等实验效应。
2.5 CRM
上述4个模型都是基于拼音文字的研究结果(英语和德语)构建的, 鉴于中文的特异性, 这些模型并不能直接用来解释中文阅读中的眼动现象。相较于拼音文字(如英语和德语), 中文不存在词间空格对词边界进行标记。词间空格的缺失使得读者不能利用词间空格完成词切分进而确定眼跳落点位置, 这就对上述4个模型解释中文阅读眼动现象提出了挑战。中文阅读中如何进行词切分成了构建中文阅读眼动控制模型必须首先解决的问题。另外, 中文以汉字作为书写符号, 这一表义的“方块字”由不同的笔画构成, 汉字之间的复杂度存在较大的差異, 且数量远多于拼音文字中的字母数量(李玉刚 等, 2017)。汉字的这些特点使得汉字层面的加工成为中文阅读的一个重点内容, 这就为上述模型解释中文阅读眼动现象提出另一挑战。曾有研究者尝试将E-Z Reader扩展到中文阅读中, 且模拟了中文阅读中的词频等效应(Rayner et al., 2007)。但这一尝试并未考虑中文阅读中没有明显的词间空格标记帮助进行眼跳落点位置选择的特异性, 这并不符合中文阅读的实际情况。同时, 这一尝试并未考虑汉字识别加工对中文阅读的影响。
Li和Pollatsek基于中文阅读眼动数据针对上述问题构建了中文阅读眼动模型(Li & Pollatsek, 2020; 模型结构如图5)。CRM的提出为中文阅读眼动机制的探究提供了理论基础(Li, Huang et al., 2022; Liao et al., 2022; Sui et al., 2022; Yao, Alkhammash et al., 2022; Yao, Slattery et al., 2022; Yao, Staub et al., 2022; Zhang, Bai et al., 2022; Zhang, Yao et al., 2022)。该模型采用交互激活的逻辑进行建模, 并包括两大模块:词汇加工和眼动控制。同Glenmore类似, 在CRM中, 词汇加工模块包括视觉层、汉字层和词汇层。汉字层和词汇层之间互相影响, 而每个层内被激活的节点之间互相竞争、彼此抑制。具体来讲, 知觉广度内所有的汉字平行激活, 所有这些汉字可能组成的词也都会被激活。所有被激活的词竞争出唯一的胜利者。当一个词胜出后, 它也就从所在字符串中被切分出来, 同时也就完成了对该词的词汇识别。因此, 该模型认为中文阅读过程中词切分和词识别是同时进行、不可分割的。眼动控制模块包括眼跳单元、注视词单元、汉字激活地图、眼跳目标选择四个部分, 其中前两个部分解决眼睛何时移动的问题, 而后两个部分解决眼睛向哪里移动的问题。CRM认为眼睛何时移动受到加工当前注视词所需时间的影响:注视词的激活强度越大(注视词单元的激活值越大)则眼跳单元的激活强度越大, 当达到一定阈限值时眼跳即被执行。而眼跳目标的选择则是基于汉字加工效率的策略进行的, 即眼动控制模块根据汉字激活地图, 从左到右序列选择激活值小于某阈值的汉字作为下一次眼跳目标。在平行加工还是序列加工这一基本问题上, CRM主张对汉字和词语的平行加工, 但一般词n+1的激活强度较低, 因此加工较慢。该模型解释了视敏度、词长、词频、预测性等因素对中文词切分和词汇识别的影响。
3 模型结构、逻辑的对比
3.1 模型结构
总体而言, 上述5个模型都包含词汇识别和眼动控制两个部分, 只是结构细节因假设不同而不同。词汇识别部分, E-Z Reader和SWIFT都包含了词汇的前加工(在E-Z Reader中称为熟悉度检验)和词汇通达完成两个阶段; 而基于交互激活模型构建的Glenmore、OB1 Reader和CRM则要复杂得多, 词汇识别是以不同的加工层之间的相互作用实现的, 大致包括视觉层、字母(汉字)层和词语层。眼动控制部分, 都包括眼跳目标选择和眼跳发生的结构。对于眼跳目标的选择, 基于平行加工理论构建的模型(SWIFT, Glenmore, OB1 Reader, CRM)都是通过显著性地图这一结构实现的, 而基于序列加工理论构建的E-Z Reader由于假设眼跳目标会默认选择当前注视词n的下一个词n+1, 故没有特定的结构用于眼跳目标选择。对于眼跳的发生, 与其他模型不同, Glenmore和CRM是通过独立的注视中心模块或眼跳单元模块控制眼跳的, 相应模块是否达到激活阈限决定眼跳是否执行。最后, 除了词汇识别和眼动控制, E-Z Reader还具有一个词汇后整合阶段用来解释词汇识别后的语义整合对眼动的影响。这一结构模拟了阅读过程中的语义整合, 相较于独立的词汇识别通达是较为高级和复杂的认知加工过程, 目前其他模型并未涉及。
3.2 注意分布
5个模型的核心逻辑差异是知觉广度内视觉注意分布是序列还是平行。从是否可以同时加工知觉广度内的多个词来看, E-Z Reader属于序列加工, 而SWIFT、Glenmore、OB1 Reader和CRM属于平行加工。另外, CRM在汉字加工上是主张平行加工的, 即知觉广度内所有的汉字同时激活, 他们所能构成的词语互相竞争直到有一个词的激活值超过阈限值进而完成词汇识别。而在词语加工上, CRM主张空间不重合的词没有竞争, 所以可以平行加工。但一般词n+1的激活强度较低, 因此加工较慢。另外, E-Z Reader虽然主张词语的序列加工, 但认为眼跳与注意力转移是可以分离的, 在完成词n的词汇通达以后, 注意力即可从词n转移到词n+1进而对词n+1开始预加工(熟悉度检验)。这就使得基于序列加工逻辑的E-Z Reader仍然可以解释预视效应。
3.3字母/汉字识别
E-Z Reader和SWIFT均从词语识别开始建模, 对字母识别没有明确主张。Glenmore、OB1 Reader和CRM都包含了字母/汉字的识别, 并认为视敏度影响其识别:在中央凹处的字母/汉字识别率最高, 随着距中央凹距离的增加, 识别率降低。同时, 这三个模型都采用了交互激活的建模逻辑, 都认为词汇层的激活也会对字母/汉字的激活产生影响:高激活水平的词汇可以促进其对应位置的字母/汉字的激活, 而抑制同一位置的其他字母/汉字的激活。
Glenmore基于实证研究结果(Inhoff et al., 2003), 认为词长信息会影响字母的平均激活水平:字母的平均激活水平随着词长增长而下降。OB1 Reader加入了注意力权重和拥挤程度对字母识别的影响。具体而言, 字母获得的注意力权重越高则越容易识别, 单独的字母以及位于词边缘的字母更容易识别。汉字的识别在CRM当中是通过输入汉字图像与先验的汉字模板之间的相似度匹配实现的, 同一位置上的汉字节点之间相互竞争, 最后胜出的那个汉字得到识别。
3.4词汇识别
不管是基于序列还是平行加工理论, 这5个模型都认为当某个词汇的激活值达到一定阈值后即可完成该词的识别, 并且都认为词频等因素影响识别过程。但是, 不同模型对这些因素如何影响词汇识别有不同的假设。E-Z Reader、SWIFT和OB1 Reader认为词汇识别的促进是通过降低阈限值实现的, 而Glenmore和CRM则认为词汇识别的促进是增加了该词激活值的结果。在影响词汇识别的因素上, 各模型也存在细微的差异。具体而言, 各模型都认为视敏度和词频影响词语识别。除Glenmore外, 其他模型都认为预测性影响词语识别。其中E-Z Reader和CRM都认为只有当前加工单元得到识别后, 预测性才能对下一单元的识别产生影响。而SWIFT则分离了词频和预测性的影响, 认为词语的激活难度可以单独用词频来衡量, 预测性被用来调整加工的效率。这样的结果是, 预测性对加工进程的影响可能早于词频。另外, E-Z Reader和OB1 Reader还认为词长也影响词语识别。Glenmore基于实证研究结果(Inhoff et al., 2003), 认为长词能从其组成字母中获得更好的激活而能更好地和短词竞争, 因此词长亦影响词语识别。同时, Glenmore允许任务难度通过“注视中心”模块实现对词语识别自上而下的调节。另外, 如前所述, 因为OB1 Reader和CRM都包含了字母/汉字的识别, 因此由相似字母/汉字构成的多个可能词语之间的竞争也会对词汇识别产生影响。Glenmore虽亦为平行加工模型, 但由于模型重在解释眼跳目标选择机制, 并未对词语识别中多个备选词的激活与竞争进行建模。最后, 由于中文没有词间空格对词边界进行标记, CRM中的词语识别过程同时包含了词切分的认知过程。其他基于拼音文字构建的模型都假设读者可以利用初级视觉输入信息(词间空格)获取词边界信息进而不需要词切分这一模块。
3.5词汇整合
在本文所述的5个模型中, 只有E-Z Reader包含了對已识别词语的语义整合过程。这一过程在该模型中被纳入了词汇加工的第三个阶段(词汇后整合阶段), 以用来反映读者在即时加工中将已识别词语整合到更高水平表征所需要的语义整合。例如, 将词整合进一个句法结构, 产生和语境匹配的语义表征, 将意义整合进话语模型中等。E-Z Reader对词语整合的即时性以及整合失败带来的回视和再注视等现象进行了详细的论述(详见下文4.2与4.3部分)。
3.6眼跳目标选择(Where to move the eyes)
在眼跳目标选择上, 平行加工模型和序列加工模型存在巨大差异。序列加工模型(E-Z Reader)认为下一次眼跳目标即为当前注视词后的第一个未识别的词, 因此不存在复杂的眼跳目标选择过程。值得注意的是, E-Z Reader认为阅读过程中可以对词n+1进行跳读(详见下文4.4部分)。平行加工模型(SWIFT、Glenmore、OB1 Reader)由于可以同时激活知觉广度内的多个词, 因此存在眼跳目标的选择问题。其基本逻辑是通过同时激活的多个词之间的竞争来完成眼跳目标的选择:Glenmore和OB1 Reader认为激活值最高的词即是下一次眼跳的目标, 而SWIFT认为激活值最高的词成为下一次眼跳目标的概率最高。而CRM的眼跳目标选择是基于汉字的, 具体而言, 模型采用基于加工效率的策略来决定眼睛移动的位置, 眼动控制模块从左到右序列搜索汉字激活地图, 找出激活值小于某个阈限值的第一个汉字作为下一次眼跳的落点位置。
3.7眼跳计划和执行(When to move the eyes)
各模型对如何进行眼跳计划和执行存在较大的差异, 可从两个角度予以说明。
第一, 从眼跳发生机制上来说, 根据Reingold等(2012), 可分为直接控制(direct control)和间接控制(indirect control), 其中直接控制又包含触发机制(triggering mechanism)和阻碍机制(interference mechanism)。直接控制是指对当前注视词的加工会影响到下一次眼跳启动, 这种影响是局部的、即时的。间接控制是指当前注视词的特征和属性不会直接影响到眼跳启动。间接控制涉及到对注视时间的延迟调整(即非实时), 该注视时间通常由读者遇到的阅读材料的平均加工难度等因素决定。直接控制的触发机制是指当注视词的加工达到一定程度时即触发眼跳计划, 而阻碍机制是指眼跳启动与特定加工阶段的完成无关, 是由注视词加工难度对眼跳潜伏期不同程度的抑制导致的。从词汇因素对眼跳发生的影响来看, 本文所述的5个模型可归为直接控制, 其中序列加工模型(E-Z Reader)为触发机制, 而平行加工模型(SWIFT、Glenmore、OB1 Reader和CRM)为阻碍机制。具体而言, 在序列加工模型中, 当读者完成词语的熟悉度检验后即触发眼跳计划。平行加工模型中, 眼跳的发生则是由词语的加工难度控制的, 不同难度的词语会对眼跳的发生产生不同的阻碍。从非词汇因素对眼跳发生的影响来看, E-Z Reader可归为直接控制, 其纠正错误注视位置时会触发新的眼跳至正确位置。而SWIFT、Glenmore和CRM则既可归为直接控制也可归为间接控制。三个模型认为在视觉编码出现困难时会触发对眼跳的抑制, 此时为直接控制; 同时, SWIFT和CRM中都引入了眼跳的自由参数来自动触发眼跳, 以模拟大脑没有知觉到任何信息或词汇加工为0时自主眼跳会在一段时间后自动触发的现象(time out), 此时则为间接控制。
第二, 从模型结构来说, 与其他模型不同, Glenmore和CRM是通过独立的注视中心模块或眼跳单元模块控制眼跳的, 相应模块是否达到激活阈限决定眼跳是否执行。但同时, 虽然Glenmore和CRM都通过眼跳控制单元来计划眼跳, 其控制单元所输入的信息却并不完全相同。CRM的眼跳单元只与词汇层连接, 进而使得注视词的激活强度成为眼睛移动的决定性因素。而Glenmore当中的注视中心模块不仅和词汇层连接, 其与字母层也有连接, 而且还能受到自上而下加工的影响(如任务难度), 其决定因素更多更复杂。而E-Z Reader、SWIFT、OB1 Reader则没有独立的眼跳模块, 眼跳计划和执行的触发由一个随机分布决定, 同时眼跳潜伏受到词语识别过程的影响。同时, E-Z Reader和SWIFT又都认为眼跳计划可以分为不稳定阶段和稳定阶段。其中, 不稳定阶段的眼跳是可以取消的, 而稳定阶段的眼跳则是不可取消的。两个模型对于两阶段的具体处理又有差异。E-Z Reader作为序列加工模型, 认为不稳定阶段开始于对当前注视词n的熟悉度检验(词汇加工的第一阶段)完成以后, 之后注意力开始转移到词n+1, 在词n完成词汇通达阶段(词汇加工的第二阶段)之后, 眼跳计划才进入稳定阶段然后执行眼跳。SWIFT则对词语识别过程和眼跳计划之间的先后关系没有明确假设。
4 对常见眼动行为的解释
4.1 注视
注视包含两个测量指标:注视位置和注视停留时间。注视位置与眼跳目标的选择紧密联系。注视停留时间受到词频、预测性等因素的影响。另外, 眼跳与注视时间也具有相关性, 眼跳的执行则意味着注视点的转移及上一次注视的结束。在这一机制上, 不同模型的处理方法有细微的差异。其中Glenmore和CRM认為上述各因素通过影响注视词的激活强度来调整眼跳单元激活的时间, 进而产生更长或更短的注视。而E-Z Reader、SWIFT和OB1 Reader认为眼跳计划产生于一个随机分布, 在无其他因素影响的情况下, 一定时间后会自动执行眼跳。而词频、预测性等因素就是通过改变随机分布的具体值促进或抑制眼跳, 进而产生更长或更短的注视。另外, 由于E-Z Reader加入了词汇后整合阶段, 该阶段的语义整合情况也会影响到注视时间的长短。例如, 当语义整合快速失败时, 读者会延长当前的眼跳潜伏或产生再注视, 导致当前注视词上的注视时间变长。
4.2 回视
回视是指读者在阅读中将眼睛向与正常阅读相反的方向移动以重新加工信息的现象。作为一种特殊的眼跳形式, 不同模型有不同的解释。平
行加工模型(SWIFT、Glenmore、OB1 Reader)认为, 如果在当前注视词之前仍然存在未识别的词语且其在眼跳目标选择竞争中获胜的话, 则会产生趋向这个词语的一次眼跳, 即回视。序列加工模型(E-Z Reader)则认为, 在阅读过程中, 会有一定的概率导致对词n的语义整合失败, 从而造成理解困难。此时如果已经完成到下一个词的眼跳或者该眼跳的眼跳计划已进入稳定阶段的话, 则会计划一次新的回视眼跳回到首先产生理解困难的地方(一般是词n)。序列加工模型对回视的解释稍显欠缺的表现是不能很好地解释长距离回视的情况, E-Z Reader中虽然也认为会有一定的概率回视到词n之前的内容, 但在实际模型中只模拟了回视到词n?1而不包含更前的位置。CRM则认为回视是受高级认知语言加工影响的, 而由于模型没有包含高级认知加工模块, 故而没有考察回视的问题。
4.3 再注视
再注视也是一种特殊的眼跳形式, 是在注视点向右移出当前加工单元前, 对加工单元进行第二次或更多次注视的现象。平行加工模型(SWIFT、Glenmore、OB1 Reader)主张, 如果当前词的识别难度较大, 对其进行再注视的概率就会较高。同时, SWIFT还主张眼跳幅度与再注视概率之间相关:较短幅度的眼跳会有更大的再注视概率。序列加工模型(E-Z Reader)中的再注视分两种情况:一种情况是词中心位置和该词首次落点位置之间的距离大小影响该词的再注视概率, 距离越远则再注视的概率越高; 另一种情况则来自词汇后整合, 在整合快速失败时(眼跳计划仍处于不稳定阶段), 读者可能会产生再注视以帮助当前注视词的语义整合。如前所述, CRM的眼跳目标选择是基于加工效率的策略实现的, 眼动控制模块从左到右序列搜索汉字激活地图, 找到激活小于某阈值的第一个汉字作为眼跳目标。按此逻辑, 如果当前注视汉字的激活值仍小于某阈值的话, 则会产生对该汉字的再注视。
4.4 跳读
跳读是指在阅读中对某一加工单位不进行注视的情况, 可细分为第一遍阅读当中的跳读和整个阅读过程当中的跳读, 一般指前者。跳读这一特殊的眼跳在一定程度上是序列加工模型的专利, 因为在平行加工模型(SWIFT、Glenmore、OB1 Reader)的空间显著性框架下, 词语跳读的概念是没有意义的, 因为没有默认的去往词n+1的眼跳。根据E-Z Reader, 当词n+1在副中央凹就完成词汇通达和整合时(如“the”, Angele & Rayner, 2013), 读者会将默认的去往词n+1的眼跳取消, 直接跳读到词n+2。
5 对常见实验效应的解释
5.1 词频效应
词频效应是指相较于低频词, 高频词更容易被跳读、其阅读时间更短(Kuperman et al., 2023; Li, Li et al., 2022; Liu et al., 2020)。作为一个非常稳健的实验效应所有眼动控制模型都对其进行了模拟。E-Z Reader、SWIFT、OB1 Reader认为高频词能降低词语激活的阈限值, 而Glenmore和CRM认为高频词可以增加词语的激活值。这两种不同的方式都可以使高频词较快地达到激活阈限进而被激活, 从而缩短加工时间。
5.2预测性效应
预测性效应是指相较于低预测性的词, 高预测性的词更容易被跳读、其阅读时间更短(Chang et al., 2020; Cui et al., 2022; Liu et al., 2020; Yao, Staub et al., 2022)。各模型对预测性效应的解释与词频相仿, 只有Glenmore没有对预测性效应进行模拟。其中, E-Z Reader还假设:当词语预测性高于读者依据前文语境猜测出词n的可能性时, 词语的熟悉度检验阶段加工时间为零, 继而对整个词的加工时间也为零。
5.3词长效应
词长效应是指相较于长词, 短词更容易被跳读、其阅读时间更短(Kuperman et al., 2023; Li, Li et al., 2022; Zang et al., 2018)。各模型对其的解释与词频效应类似。但由于中文没有词间空格, 因此在词汇识别之前, 词长信息和词边界信息是未知的, 词长对中文阅读的影响须在词切分完成之后。根据CRM, 词切分和词汇识别是统一的过程, 因此词切分后的词长效应可能是由词切分过程中长词的切分和识别需要激活更多汉字信息带来的。
5.4预视效应
预视效应是指读者可以对副中央凹区域的信息进行加工的现象(Chang et al., 2020; Cui et al., 2022; 综述见张慢慢, 臧传丽, 白学军, 2020)。由
于平行加工模型(SWIFT、Glenmore、OB1 Reader)认为视觉注意在知觉广度内是平行分布在各词上的, 那么预视效应就是这一平行加工的直接结果。而序列加工模型(E-Z Reader)则认为注意是序列转移的, 注意资源一次只能分配到一个词上, 其对预视效应的解释不同于平行加工模型。具体来說, E-Z Reader中的预视效应是注意力转移的结果。该模型认为, 词汇识别可以分为熟悉度检验和词汇通达完成两个阶段, 在完成词汇通达阶段以后, 读者的注意就转移至下一个词。而由于此时并没有发生实际的眼跳, 因此这一注意的转移会使读者通过副中央凹对下一个词进行熟悉度检验的加工。另外, 和预视效应相关的一个问题是预视加工的程度。平行加工模型(SWIFT、Glenmore、OB1 Reader)认为对词n+1的预视加工可以到语义程度, 而在序列加工模型(E-Z Reader)中, 对词n+1的预视加工只是针对其初级信息的加工, 并未达到语义。
5.5副中央凹?中央凹效应及中央凹?副中央凹效应
这两个效应是预视效应的进一步发展, 即读者不仅对副中央凹的信息进行加工, 且副中央凹的信息加工会和中央凹的信息加工相互影响(Zhang et al., 2019; 张慢慢, 臧传丽, 徐宇峰 等, 2020)。当考察副中央凹加工对中央凹加工的影响时, 就是副中央凹?中央凹效应, 反之则是中央凹?副中央凹效应。在副中央凹?中央凹效应上, 序列加工模型(E-Z Reader)和平行加工模型(SWIFT、Glenmore、OB1 Reader)有相反的主张。在序列加工模型中, 对词n+1的副中央凹加工发生在对词n的词汇通达以后, 二者具有清晰的时间先后顺序。因此序列加工模型认为不存在副中央凹?中央凹效应。而在平行加工模型中, 由于可以同时加工多个词语, 不同词语之间对注意资源的竞争就会导致副中央凹?中央凹效应。平行加工模型的这一机制同样可以用来解释中央凹?副中央凹效应。对于序列加工模型来说, 这一效应也是可以存在的:对词n的词汇后整合会影响到对词n+1的副中央凹加工。当词n发生词汇后整合的困难时, 读者会减少对词n+1的预加工, 而将注意力转移回当前注视词n。
5.6溢出效应
溢出效应是指对词n的加工效应会延迟表现到当注视点落到词n+1时的现象(Pollatsek et al.,
2008; Rayner & Duffy, 1986)。本文所述的5个模型均能对溢出效应提供一定的解释。E-Z Reader模型中, 读者在注视词n+1时可能同时存在对词n的词汇后整合, 且由于词n+1熟悉度检验阶段可预测性因素的作用与词n的词汇后整合密切相关, 进而导致词n的加工会影响到词n+1的加工。SWIFT认为眼跳是随机的, 但同时也会受到中央凹加工(词n)的抑制。某些情况下, 由于中央凹词语识别的过程要慢于眼跳产生单元, 词语识别影响眼跳系统就会有一个时间延迟, 即当词n的词语识别抑制效应起作用时, 眼睛已经随着眼跳转移到词n+1了。这种具有时间延迟的中央凹抑制的处理方案就可以很好地解释溢出效应。Glenmore对于该效应的解释是, 对字母或词语的激活值是可以从当前注视带到下一个注视的, 此逻辑下的溢出效应是顺理成章的。OB1 Reader和CRM对该效应的解释则立足于平行加工的逻辑, 即在注视词n+1时, 其加工时间会受到副中央凹的词n的影响, 若词n容易加工, 则读者可在词n+1的加工上分配更多认知资源进而使词n+1加工时间更短。
5.7偏好注视位置
偏好注视位置是指对某一个词首次落点最大分布值所在的位置。英语研究中, 这一位置一般是词中央偏左的位置(McConkie et al., 1988; Rayner, 1979), 但近年来也有研究者提出了注视位置灵活性的主张(Cutter et al., 2017, 2018)。基于前一主张, E-Z Reader、SWIFT、OB1 Reader认为眼跳计划指向眼跳目标的词中心, Glenmore认为眼跳计划指向显著性最高的词。在此基础上, 系统误差和随机误差导致偏好注视位置位于词中央偏左。由于中文没有词间空格, 在词边界不明的情况下确定词中心所在的位置本身就是一个较大的难题, 因此中文阅读中是否存在和英语一致的偏好注视位置效应一直存在争议(综述见: 李兴珊 等, 2011; 李玉刚 等, 2017)。针对中文特异性, 有研究者提出了基于加工效率的假设(Li et al., 2015; Ma et al., 2015; Wei et al., 2013), 即读者首先尝试在给定的注视点上加工尽可能多的信息, 当一个
注视位置的加工效率降低到一定程度时, 眼睛才移动到未处理信息的位置。也有研究者提出了副中央凹词切分的假设(Zhou et al., 2018; 白学军 等, 2012), 即若读者在副中央凹完成了词切分, 则会注视到词中心。近年来又有研究者提出了动态调整的假设(Li et al., 2015; Liu et al., 2019; Liu et al., 2019a, 2019b; Xia et al., 2023; 王永胜 等, 2018), 认为注视位置与中央凹和副中央凹的加工负荷有关, 会根据加工过程进行动态调节。具体而言, 读者从副中央凹获取的信息越多, 则眼跳越长。而中央凹加工负荷则是通过影响副中央凹加工进行的, 中央凹负荷越小, 则可通过副中央凹获得更多加工, 继而发生更长的眼跳。不过目前这一观点仍存争议。由此可见, 中文阅读中的偏好注视位置问题仍存争议, 需要进行更深入的探索。针对中文阅读构建的CRM模型对于这一问题的观点是, 读者在阅读中文时, 并不会把眼跳目标选择在一个词的固定位置上。中文阅读中的眼跳目标选择是基于汉字而非词语的, 其眼跳目标选择采用基于汉字加工效率的策略进行。
5.8词切分
词切分是指读者在阅读过程中借助一些线索将所要识别的词从连续字符串中切分出来并进一步加工的过程。基于拼音文字建立的眼动控制模型(E-Z Reader、SWIFT、Glenmore、OB1 Reader)认为读者可以通过初级视觉输入(词间空格)获取词边界信息, 无需进行特别的词切分过程。而由于中文没有词间空格, 因此需要额外的词切分过程(Huang et al., 2021; Li et al., 2009; Liu et al., 2019)。CRM认为词汇加工和词切分是一个统一的过程:知觉广度范围内的所有汉字同时被激活, 由这些汉字组成的所有可能的词进而被激活并相互竞争, 直到唯一胜出者完成词汇识别并同时从字符串中被切分出来。
5.9个体差异与任务难度
不同的读者群体或任务难度可能会导致不同的眼动行为(Mak & Willems, 2019; Staub, 2021)。本文所述的5个模型中, SWIFT、Glenmore和OB1 Reader对语言因素以外的读者差异或任务难度因素进行了讨论。但三个模型的侧重点并不一致。
其中OB1 Reader主要着眼于个体差异对注意力分布的影响, 而SWIFT和Glenmore则关注个体差异或任务难度对眼跳的影响。具体而言, OB1 Reader认为注意焦点是一个宽度可变的分布, 而读者的熟练度则可以调节这一分布:读者熟练度高则词语识别成功率高, 注意分布的宽度就会扩大, 反之则缩小。SWIFT认为眼跳计划间隔时间是随机的, 但具有预先定义的平均时间, 这一平均时间则与读者的个人阅读速率相关:高阅读速率的读者的眼跳平均时间更短。Glenmore则认为任务的难度会通过影响注视中心模块的激活阈限来影响眼跳的计划和执行:难度越高则激活阈限越高, 则更难进行眼跳。
6 对比总结
各模型的直观对比已总结归纳于表1。总体而言, 各模型存在诸多共性, 亦存在诸多差异。各模型都基于自己的逻辑对阅读中的眼动行为和实验效应进行了解释:如在字母/汉字识别和词汇识别中, 都引入了视敏度、词频等因素; 都解释了注视、回视、眼跳等常见眼动行为; 都模拟了词频效应、预视效应等常见实验效应。
5个模型的核心逻辑差异是知觉广度内视觉注意分布是序列的还是平行的。这一注意分布的差异会导致模型在字母/汉字识别、词汇识别上的主张存在差异:如序列加工模型主张不能同时加工多个词语, 而平行加工模型则相反。这一注意分布的差异还会引起对常见眼动行为解释的差异:如序列加工模型认为回視来自词汇后整合, 而平行加工模型则认为来自词汇识别。注意分布的差异同样会引起各模型对诸如预视效应、副中央凹?中央凹效应的解释出现差异:如序列加工模型认为不存在语义层面的预视效应, 也不存在副中央凹?中央凹效应, 而平行加工模型则相反。最后, 每个模型都可以解释其他模型无法解释的一些现象/效应:如CRM对中文阅读中词切分、偏好注视位置等问题进行了合理的解释; E-Z Reader对词语识别后的词汇后整合进行了一定的探索; 而SWIFT、Glenmore和OB1则对语言以外的部分因素进行了讨论。
7 展望
本文从序列加工和平行加工的理论争议出发, 系统对比了建立于这两大理论的5个模型(E-Z Reader、SWIFT、Glenmore、OB1 Reader和CRM)在模型结构、模型基本逻辑、对常见眼动行为的解释、对常见实验效应的解释上的异同。在系统了解这几个影响力较大的眼动控制模型后, 我们对未来的模型发展进行了如下展望:
(1)进一步考察词汇后整合的问题。目前只有E-Z Reader对词语识别后的语义整合进行了探讨, 且其对词汇后整合的探索仅是引入一个高水平的语义加工阶段, 用以解释第10版E-Z Reader之前的诸版本模型不能解释的一些问题。对于词汇后整合、句子框架整体语义搭建是怎么进行的并未进行深入的探讨。随着句法研究和语用研究的深入, 词语的语义整合问题会成为眼动控制模型完善发展的方向。
(2)对语序问题给予一定的关注。序列加工模型对语序问题的回答相对直观, 而平行加工模型则需要对这一问题进行详细回答。OB1 Reader通过引入空间主题信息表征模块在一定程度上解决了词语激活顺序和句子语序之间的矛盾问题。但这种基于词长信息的解决方案很显然不适于中文阅读。解释平行加工框架下中文语序现象是眼动控制模型需要关注的一个研究课题。
(3)加入更多语言因素以外的因素, 提高模型的解释力。SWIFT、Glenmore和OB1 Reader均对语言因素以外的读者因素或任务难度因素进行了讨论。未来还可以加入年龄、性别、智力、注意、语言水平等因素来提高模型的实际解释力和应用能力。
(4)对偏好注视位置的最新实证研究结果进行一定程度的解释。基于拼音文字构建的几个模型都主张眼跳指向词中心偏左, 因而无法解释前文所述的关于偏好注视位置灵活性的相关发现。中文阅读中的眼跳落点位置问题则更为复杂。目前CRM提供了基于汉字加工效率的解决方案, 但并不能解释近年来发现的诸如中央凹和副中央凹词语加工负荷的相关结果(Xia et al., 2023)。未来的阅读模型可在这一研究问题上给予更多关注, 以更全面了解阅读中眼跳落点位置的认知机制。
(5)建立计算模型的核心目的是为了模拟真实阅读过程中的眼动机制、加深对阅读这种高级认知行为的了解。在发展现有模型或开发构建新模型之外, 可尝试为模型对比制定系统全面的评判标准。目前各个模型基于各自特定的实证数据构建并模拟对应实验效应, 且一些关键参数在模拟不同效应时会发生一定的变化。这就为各个模型之间的定量对比造成了一定的困难。未来研究可尝试构建统一的大规模的实验效应数据库, 以便于基于统一的实验效应数据, 结合各模型的理论范围和基本假设, 分析各模型关键差异的可证伪性, 直观对比各模型对同一效应的不同解释力。
(6)探索各个模型的跨语言解释力。现有的各个模型的建立都是基于特定的某种语言(如E-Z Reader是基于英语, SWIFT是基于德语, 而CRM是基于中文)。关于各个模型对其他语言的解释力, 目前的研究比较有限, 且并未完全考虑语言特异性对模型解释可能造成的影响。未来研究中, 在充分了解分析不同语言之间的特异性和共性的基础上, 研究者或可尝试探索基于特定语言系统构建的模型是否可应用于其他语言。例如, CRM使用的基于汉字加工效率的眼跳目标选择机制是否可以扩展到拼音文字阅读中。
参考文献
白学军, 梁菲菲, 闫国利, 田瑾, 臧传丽, 孟红霞. (2012). 词边界信息在中文阅读眼跳目标选择中的作用:来自中文二语学习者的证据. 心理学报, 44(7), 853?867.
陈庆荣, 邓铸. (2006). 阅读中的眼动控制理论与SWIFT模型. 心理科学进展, 14(5), 675?681.
胡笑羽, 刘海健, 刘丽萍, 臧传丽, 白学军. (2007). E-Z阅读者模型的新进展. 心理學探新, (1), 24?29+40.
李兴珊, 刘萍萍, 马国杰. (2011). 中文阅读中词切分的认知机理述评. 心理科学进展, 19(4), 459?470.
李玉刚, 黄忍, 滑慧敏, 李兴珊. (2017). 阅读中的眼跳目标选择问题. 心理科学进展, 25(3), 404?412. https:// doi.org/10.3724/SP.J.1042.2017.00404
刘丽萍, 刘海健, 胡笑羽. (2006). SWIFT-Ⅱ:阅读中眼跳发生的动力学模型. 心理与行为研究, 4(3), 230?235.
马国杰, 李兴珊. (2012). 阅读中的注意分配:序列与平行之争. 心理科学进展, 20(11), 1755?1767.
沈模卫, 张光强, 符德江, 陶嵘. (2002). 阅读过程眼动控制理论模型: E-Z Reader. 心理科学, (2), 129?133+252. https://doi.org/doi:10.16719/j.cnki.1671-6981.2002.02.001
隋雪, 沈彤, 吴琼, 李莹. (2013). 阅读眼动控制模型的中文研究——串行和并行. 辽宁师范大学学报(社会科学版), 36(5), 672?679.
隋雪, 杨帆, 徐迩嘉. (2018). 交互激活眼动控制的Glenmore模型述评. 沈阳师范大学学报(社会科学版), 42(2), 118?124. https://doi.org/doi:10.19496/j.cnki.ssxb. 2018.02.022
王永胜, 赵冰洁, 陈茗静, 李馨, 闫国利, 白学军. (2018). 中央凹加工负荷与副中央凹信息在汉语阅读眼跳目标选择中的作用. 心理学报, 50(12), 1336?1345. https:// doi.org/10.3724/SP.J.1041.2018.01336
吴俊, 莫雷. (2008). 阅读中重要眼动控制模型的核心架构. 华南师范大学学报(社会科学版), (3), 115?121+160.
张慢慢, 臧传丽, 白学军. (2020). 中文阅读中副中央凹预加工的范围与程度. 心理科学进展, 28(6), 871?882.
张慢慢, 臧传丽, 徐宇峰, 白学军, 闫国利. (2020). 快速与慢速读者的中央凹加工对副中央凹预视的影响. 心理学报, 52(8), 933?945. https://doi.org/10.3724/SP.J.1041. 2020.00933
Angele, B., & Rayner, K. (2013). Processing the in the parafovea: Are articles skipped automatically? Journal of Experimental Psychology: Learning, Memory, and Cognition, 39(2), 649?662. https://doi.org/10.1037/a0029294
Antúnez, M., López-Pérez, P. J., Dampuré, J., & Barber, H. A. (2022). Frequency-based foveal load modulates semantic parafoveal-on-foveal effects. Journal of Neurolinguistics, 63, 101071. https://doi.org/10.1016/j.jneuroling.2022.101071
Bordag, D., & Opitz, A. (2022). Employing general linguistic knowledge in incidental acquisition of grammatical properties of new L1 and L2 lexical representations: Toward reducing fuzziness in the initial ontogenetic stage. Frontiers in Psychology, 12, 768362. https://doi.org/ 10.3389/fpsyg.2021.768362
Brossette, B., Grainger, J., Lété, B., & Dufau, S. (2022). On the relations between letter, word, and sentence-level processing during reading. Scientific Reports, 12(1), 17735. https://doi.org/10.1038/s41598-022-22587-1
Chang, M., Hao, L., Zhao, S., Li, L., Paterson, K. B., & Wang, J. (2020). Flexible parafoveal encoding of character order supports word predictability effects in Chinese reading: Evidence from eye movements. Attention, Perception, & Psychophysics, 82, 2793?2801. https://doi. org/10.3758/s13414-020-02050-x
Clifton, C., Ferreira, F., Henderson, J. M., Inhoff, A. W., Liversedge, S. P., Reichle, E. D., & Schotter, E. R. (2016). Eye movements in reading and information processing: Keith Rayners 40 year legacy. Journal of Memory and Language, 86, 1?19. https://doi.org/10.1016/j.jml.2015. 07.004
Cui, L., Zang, C., Xu, X., Zhang, W., Su, Y., & Liversedge, S. P. (2022). Predictability effects and parafoveal processing of compound words in natural Chinese reading. Quarterly Journal of Experimental Psychology, 75(1), 18?29. https://doi.org/10.1177/17470218211048193
Cutter, M. G., Drieghe, D., & Liversedge, S. P. (2017). Reading sentences of uniform word length: Evidence for the adaptation of the preferred saccade length during reading. Journal of Experimental Psychology: Human Perception and Performance, 43(11), 1895?1911. https:// doi.org/10.1037/xhp0000416
Cutter, M. G., Drieghe, D., & Liversedge, S. P. (2018). Reading sentences of uniform word length ? II: Very rapid adaptation of the preferred saccade length. Psychonomic Bulletin & Review, 25(4), 1435?1440. https://doi.org/ 10.3758/s13423-018-1473-2
Dufour, S., Mirault, J., & Grainger, J. (2022). Transposed- word effects in speeded grammatical decisions to sequences of spoken words. Scientific Reports, 12(1), 22035. https://doi.org/10.1038/s41598-022-26584-2
Engbert, R., Longtin, A., & Kliegl, R. (2002). A dynamical model of saccade generation in reading based on spatially distributed lexical processing. Vision Research, 42(5), 621?636. https://doi.org/10.1016/S0042-6989(01)00301-7
Engbert, R., Nuthmann, A., Richter, E. M., & Kliegl, R. (2005). SWIFT: A dynamical model of saccade generation during reading. Psychological Review, 112(4), 777?813. https://doi.org/10.1037/0033-295X.112.4.777
Gordon, P. C., Moore, M., Choi, W., Hoedemaker, R. S., & Lowder, M. W. (2020). Individual differences in reading: Separable effects of reading experience and processing skill. Memory & Cognition, 48(4), 553?565. https://doi. org/10.3758/s13421-019-00989-3
Gregg, J., Inhoff, A. W., & Li, X. (2023). Lexical competition influences correct and incorrect visual word recognition. Quarterly Journal of Experimental Psychology, 76(5), 1011?1025. https://doi.org/10.1177/ 17470218221102878
Huang, L., Staub, A., & Li, X. (2021). Prior context influences lexical competition when segmenting Chinese overlapping ambiguous strings. Journal of Memory and Language, 118, 104218. https://doi.org/10.1016/j.jml.2021. 104218
Inhoff, A. W., Radach, R., Eiter, B. M., & Juhasz, B. (2003). Distinct subsystems for the parafoveal processing of spatial and linguistic information during eye fixations in reading. Quarterly Journal of Experimental Psychology, 56(5), 803?827. https://doi.org/10.1080/02724980244000639
Kuperman, V., Schroeder, S., & Gnetov, D. (2023). Word length and frequency effects on text reading are highly similar in 12 alphabetic languages [Preprint]. PsyArXiv. https://doi.org/10.31234/osf.io/cbvjr
Li, X., Huang, L., Yao, P., & Hy?n?, J. (2022). Universal and specific reading mechanisms across different writing systems. Nature Reviews Psychology, 1(3), 133?144. https://doi.org/10.1038/s44159-022-00022-6
Li, X., Liu, P., & Rayner, K. (2015). Saccade target selection in Chinese reading. Psychonomic Bulletin & Review, 22(2), 524?530. https://doi.org/10.3758/s13423-014-0693-3
Li, X., & Pollatsek, A. (2020). An integrated model of word processing and eye-movement control during Chinese reading. Psychological Review, 127(6), 1139?1162. https://doi.org/10.1037/rev0000248
Li, X., Rayner, K., & Cave, K. R. (2009). On the segmentation of Chinese words during reading. Cognitive Psychology, 58(4), 525?552. https://doi.org/10.1016/j. cogpsych.2009.02.003
Li, X.-W., Li, S., Gao, L., Niu, Z.-B., Wang, D.-H., Zeng, M., ... Gao, X.-L. (2022). Eye movement control in Tibetan reading: The roles of word length and frequency. Brain Sciences, 12(9), 1205. https://doi.org/10.3390/ brainsci12091205
Liao, X., Loh, E. K. Y., & Cai, M. (2022). Lexical orthographic knowledge mediates the relationship between character reading and reading comprehension among learners with Chinese as a second language. Frontiers in Psychology, 13, 779905. https://doi.org/10.3389/fpsyg.2022. 779905
Liu, N., Wang, X., Yan, G., Paterson, K. B., & Pagán, A. (2020). Eye movements of developing Chinese readers: Effects of word frequency and predictability. Scientific Studies of Reading, 25(3), 234?250. https://doi.org/10. 1080/10888438.2020.1759074
Liu, Y., Yu, L., Fu, L., Li, W., Duan, Z., & Reichle, E. D. (2019). The effects of parafoveal word frequency and segmentation on saccade targeting during Chinese reading. Psychonomic Bulletin & Review, 26(4), 1367?1376. https://doi.org/10.3758/s13423-019-01577-x
Liu, Y., Yu, L., & Reichle, E. D. (2019a). The dynamic adjustment of saccades during Chinese reading: Evidence from eye movements and simulations. Journal of Experimental Psychology: Learning, Memory, and Cognition, 45(3), 535?543. https://doi.org/10.1037/xlm0000595
Liu, Y., Yu, L., & Reichle, E. D. (2019b). The influence of parafoveal preview, character transposition, and word frequency on saccadic targeting in Chinese reading. Journal of Experimental Psychology: Human Perception and Performance, 45(4), 537?552. https://doi.org/10. 1037/xhp0000630
Ma, G., Li, X., & Pollatsek, A. (2015). There is no relationship between preferred viewing location and word segmentation in Chinese reading. Visual Cognition, 23(3), 399?414. https://doi.org/10.1080/13506285.2014.1002554
Mak, M., & Willems, R. M. (2019). Mental simulation during literary reading: Individual differences revealed with eye-tracking. Language, Cognition and Neuroscience, 34(4), 511?535. https://doi.org/10.1080/23273798.2018. 1552007
McConkie, G. W., Kerr, P. W., Reddix, M. D., & Zola, D. (1988). Eye movement control during reading: I. the location of initial eye fixations on words. Vision Research, 28(10), 1107?1118. https://doi.org/10.1016/0042-6989(88) 90137-X
Mézière, D. C., Yu, L., Reichle, E., von der Malsburg, T., & McArthur, G. (2021). Using eye-tracking measures to predict reading comprehension [Preprint]. PsyArXiv. https://doi.org/10.31234/osf.io/v2rdp
Mirault, J., Vandendaele, A., Pegado, F., & Grainger, J. (2022). Transposed-word effects when reading serially. PLOS ONE, 17(11), e0277116. https://doi.org/10.1371/ journal.pone.0277116
Murray, W. S., Fischer, M. H., & Tatler, B. W. (2013). Serial and parallel processes in eye movement control: Current controversies and future directions. Quarterly Journal of Experimental Psychology, 66(3), 417?428. https://doi.org/ 10.1080/17470218.2012.759979
Pegado, F., & Grainger, J. (2020). A transposed-word effect in same-different judgments to sequences of words. Journal of Experimental Psychology: Learning, Memory, and Cognition, 46(7), 1364?1371. https://doi.org/10.1037/ xlm0000776
Pollatsek, A., Juhasz, B. J., Reichle, E. D., Machacek, D., & Rayner, K. (2008). Immediate and delayed effects of word frequency and word length on eye movements in reading: A reversed delayed effect of word length. Journal of Experimental Psychology: Human Perception and Performance, 34(3), 726?750. https://doi.org/10.1037/ 0096-1523.34.3.726
Pollatsek, A., Reichle, E. D., & Rayner, K. (2006). Tests of the E-Z Reader model: Exploring the interface between cognition and eye-movement control. Cognitive Psychology, 52(1), 1?56. https://doi.org/10.1016/j.cogpsych.2005.06. 001
Primativo, S., Rusich, D., Martelli, M., & Arduino, L. S. (2022). The timing of semantic processing in the parafovea: Evidence from a rapid parallel visual presentation study. Brain Sciences, 12(11), 1535. https://doi.org/10.3390/ brainsci12111535
Rayner, K. (1979). Eye guidance in reading: Fixation locations within words. Perception, 8(1), 21?30. https:// doi.org/10.1068/p080021
Rayner, K., & Duffy, S. A. (1986). Lexical complexity and fixation times in reading: Effects of word frequency, verb complexity, and lexical ambiguity. Memory & Cognition, 14(3), 191?201. https://doi.org/10.3758/BF03197692
Rayner, K., Li, X., & Pollatsek, A. (2007). Extending the E-Z Reader model of eye movement control to Chinese readers. Cognitive Science, 31(6), 1021?1033. https:// doi.org/10.1080/03640210701703824
Rayner, K., Pollatsek, A., & Reichle, E. D. (2003). Eye movements in reading: Models and data. Behavioral and Brain Sciences, 26(4), 507?526. https://doi.org/10.1017/ S0140525X03520106
Rayner, K., Reichle, E. D., & Pollatsek, A. (2005). Eye movement control in reading and the E-Z Reader model. In G. Underwood (Eds.), Cognitive processes in eye guidance (pp. 131?162). Oxford University Press.
Reichle, E. D., Liversedge, S. P., Pollatsek, A., & Rayner, K. (2009). Encoding multiple words simultaneously in reading is implausible. Trends in Cognitive Sciences, 13(3), 115?119. https://doi.org/10.1016/j.tics.2008.12.002
Reichle, E. D., Pollatsek, A., Fisher, D. L., & Rayner, K. (1998). Toward a model of eye movement control in reading. Psychological Review, 105(1), 125?157. https:// doi.org/10.1037/0033-295X.105.1.125
Reichle, E. D., Pollatsek, A., & Rayner, K. (2006). E?Z Reader: A cognitive-control, serial-attention model of eye-movement behavior during reading. Cognitive Systems Research, 7(1), 4?22. https://doi.org/10.1016/j.cogsys. 2005.07.002
Reichle, E. D., Rayner, K., & Pollatsek, A. (1999). Eye movement control in reading: Accounting for initial fixation locations and re?xations within the E-Z Reader model. Vision Research, 39(26), 4403?4411. https://doi. org/10.1016/S0042-6989(99)00152-2
Reichle, E. D., Rayner, K., & Pollatsek, A. (2003). The E-Z Reader model of eye-movement control in reading: Comparisons to other models. Behavioral and Brain Sciences, 26(4), 445?476. https://doi.org/10.1017/ S0140525X03000104
Reichle, E. D., Warren, T., & McConnell, K. (2009). Using E-Z Reader to model the effects of higher level language processing on eye movements during reading. Psychonomic Bulletin & Review, 16(1), 1?21. https://doi.org/10.3758/ PBR.16.1.1
Reilly, R. G., & Radach, R. (2006). Some empirical tests of an interactive activation model of eye movement control in reading. Cognitive Systems Research, 7(1), 34?55. https://doi.org/10.1016/j.cogsys.2005.07.006
Reingold, E. M., Reichle, E. D., Glaholt, M. G., & Sheridan, H. (2012). Direct lexical control of eye movements in reading: Evidence from a survival analysis of fixation durations. Cognitive Psychology, 65(2), 177?206.
Richter, E. M., Engbert, R., & Kliegl, R. (2006). Current advances in SWIFT. Cognitive Systems Research, 7(1), 23?33. https://doi.org/10.1016/j.cogsys.2005.07.003
Schwalm, L., & Radach, R. (2023). Parafoveal syntactic processing from word N+2 during reading: The case of gender-specific German articles [Preprint]. In Review. https://doi.org/10.21203/rs.3.rs-2642281/v1
Snell, J., & Grainger, J. (2019a). Readers are parallel processors. Trends in Cognitive Sciences, 23(7), 537?546. https://doi.org/10.1016/j.tics.2019.04.006
Snell, J., & Grainger, J. (2019b). Consciousness is not key in the serial-versus-parallel debate. Trends in Cognitive Sciences, 23(10), 814?815. https://doi.org/10.1016/j.tics. 2019.07.010
Snell, J., van Leipsig, S., Grainger, J., & Meeter, M. (2018). OB1-reader: A model of word recognition and eye movements in text reading. Psychological Review, 125(6), 969?984. https://doi.org/10.1037/rev0000119
Snell, J., Yeaton, J., Mirault, J., & Grainger, J. (2023). Parallel word reading revealed by fixation-related brain potentials. Cortex, 162, 1?11. https://doi.org/10.1016/j.cortex. 2023.02.004
Staub, A. (2021). How reliable are individual differences in eye movements in reading? Journal of Memory and Language, 116, 104190. https://doi.org/10.1016/j.jml.2020. 104190
Sui, L., Dirix, N., Woumans, E., & Duyck, W. (2022). GECO-CN: Ghent eye-tracking corpus of sentence reading for Chinese-English bilinguals. Behavior Research Methods. https://doi.org/10.3758/s13428-022-01931-3
Tschense, M., & Wallot, S. (2022). Using measures of reading time regularity (RTR) to quantify eye movement dynamics, and how they are shaped by linguistic information. Journal of Vision, 22(6), 9. https://doi. org/10.1167/jov.22.6.9
Veldre, A., Reichle, E. D., Yu, L., & Andrews, S. (2023). Understanding the visual constraints on lexical processing: New empirical and simulation results. Journal of Experimental Psychology: General, 152(3), 693?722. https://doi.org/10.1037/xge0001295
Wei, W., Li, X., & Pollatsek, A. (2013). Word properties of a fixated region affect outgoing saccade length in Chinese reading. Vision Research, 80, 1?6. https://doi.org/10.1016/ j.visres.2012.11.015
Xia, X., Liu, Y., Yu, L., & Reichle, E. D. (2023). Are there preferred viewing locations in Chinese reading? Evidence from eye-tracking and computer simulations. Journal of Experimental Psychology: Learning, Memory, and Cognition, 49(4), 607?625. https://doi.org/10.1037/xlm0001142
Yang, J., van den Bosch, A., & Frank, S. L. (2021). Unsupervised text segmentation predicts eye ?xations during reading [Preprint]. PsyArXiv. https://doi.org/ 10.31234/osf.io/eyvu7
Yao, P., Alkhammash, R., & Li, X. (2022). Plausibility and syntactic reanalysis in processing novel noun-noun combinations during Chinese reading: Evidence from native and non-native speakers. Scientific Studies of Reading, 26(5), 390?408. https://doi.org/10.1080/10888438. 2021.2020796
Yao, P., Slattery, T. J., & Li, X. (2022). Sentence context modulates the neighborhood frequency effect in Chinese reading: Evidence from eye movements. Journal of Experimental Psychology: Learning, Memory, and Cognition, 48(10), 1507?1517. https://doi.org/10.1037/ xlm0001030
Yao, P., Staub, A., & Li, X. (2022). Predictability eliminates neighborhood effects during Chinese sentence reading. Psychonomic Bulletin & Review, 29(1), 243?252. https:// doi.org/10.3758/s13423-021-01966-1
Yu, L., Liu, Y., & Reichle, E. D. (2021). A corpus-based versus experimental examination of word- and character- frequency effects in Chinese reading: Theoretical implications for models of reading. Journal of Experimental Psychology. General, 150(8), 1612?1641. https://doi.org/10.1037/xge0001014
Zang, C., Fu, Y., Bai, X., Yan, G., & Liversedge, S. P. (2018). Investigating word length effects in Chinese reading. Journal of Experimental Psychology: Human Perception and Performance, 44(12), 1831?1841. https://doi.org/ 10.1037/xhp0000589
Zhang, G., Yao, P., Ma, G., Wang, J., Zhou, J., Huang, L., Xu, P., Chen, L., Chen, S., Gu, J., Wei, W., Cheng, X., Hua, H., Liu, P., Lou, Y., Shen, W., Bao, Y., Liu, J., Lin, N., & Li, X. (2022). The database of eye-movement measures on words in Chinese reading. Scientific Data, 9(1), 411. https://doi.org/10.1038/s41597-022-01464-6
Zhang, M., Bai, X., & Li, S. (2022). Word complexity modulates the divided-word effect during Chinese reading. Frontiers in Psychology, 13, 921056. https://doi.org/10.3389/ fpsyg.2022.921056
Zhang, M., Liversedge, S. P., Bai, X., Yan, G., & Zang, C. (2019). The influence of foveal lexical processing load on parafoveal preview and saccadic targeting during Chinese reading. Journal of Experimental Psychology: Human Perception and Performance, 45(6), 812?825. https:// doi.org/10.1037/xhp0000644
Zhang, Y., Wang, M., & Wang, J. (2022). The sequence effect: Character position processing in Chinese words. Frontiers in Psychology, 13, 877627. https://doi.org/10.3389/ fpsyg.2022.877627
Zhou, W., Wang, A., Shu, H., Kliegl, R., & Yan, M. (2018). Word segmentation by alternating colors facilitates eye guidance in Chinese reading. Memory & Cognition, 46(5), 729?740. https://doi.org/10.3758/s13421-018-0797-5
Comparison of models of eye movement in reading
CHEN Songlin, CHEN Xinwei, LI Huangxia, YAO Panpan
(School of Psychology, Beijing Language and Culture University, Beijing 100083, China)
Abstract: Based on sequential processing theory, parallel processing theory and interactive activation theory, some classical models about eye movement control are constructed to simulate the eye movements, experimental effects, and to explore the possible cognitive mechanisms of information processing during reading. Among the five classic eye movement control models: E-Z Reader 10th, SWIFT, Glenmore, OB1 Reader and CRM, there are similarities and uniqueness in model structures, basic logic of model, explanations of common eye movement patterns and explanations of typical experimental effects. Future development of models needs to focus on the questions about post-lexical integration, word order, and extra-linguistic factors. New findings about PVL, and eye movement patterns in other languages are also need to be explained. In addition, general standards are needed for model comparation.
Keywords: E-Z Reader, SWIFT, Glenmore, OB1 Reader, CRM, eye movement control
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
汽车实用技术(2022年7期)2022-04-20 11:44:42
思维与智慧·上半月(2022年4期)2022-04-08 21:24:29
载人航天(2021年5期)2021-11-20 06:04:32
小哥白尼(神奇星球)(2021年4期)2021-07-22 03:17:22
现代装饰(2020年6期)2020-06-22 08:43:14
学苑创造·B版(2017年3期)2017-05-03 16:04:17
汽车观察(2016年3期)2016-02-28 13:16:36
外语学刊(2016年4期)2016-01-23 02:34:15
出版与印刷(2014年4期)2014-12-19 13:10:39
