
基于生成对抗网络反馈的社交网络差分隐私保护方法
2024-01-09 13:20陈旭林
兰州工业学院学报 2023年6期
陈旭林
(福建水利电力职业技术学院 信息工程学院, 福建 三明 366000)
社交网络的大规模应用,让越来越多的人参与到社交网络的活动当中,正因如此,社交网络中可以获得大量用户的隐私数据,且隐私数据涉及的领域非常广泛,一旦被窃取,将会给用户和社交平台带来极大的危险[1]。同时,对于个体而言,个人隐私被泄露,也会导致个体对社交网络失去信心,从而减少对社交网络的使用,阻碍社交网络的发展。因此,如何保护隐私信息成为一个炙手可热的话题[2]。刘晓娜等[3]利用GDK-means算法,对高校贫困生信息通过聚类处理的方式进行隐私保护。但该方法需要消耗大量的计算时间和资源。苏晨等[4]利用差分隐私对电力客户数据进行编码,并将编码后的数据进行聚类处理,通过计算数据的节点和连接点,保证数据的安全性。但GDK-means方法需要较多的迭代计算和参数调整,增加了计算和调试的复杂性。
在上述研究的基础上,本文设计了一种利用生成对抗网络反馈机制的社交网络差分隐私保护方法。通过构建社交网络隐私风险量化模型,对隐私数据进行聚类处理,从而实现对社交网络差分隐私数据的保护。试验结果表明该方法能够提高隐私数据的安全性,减少因数据泄露带来的安全问题。
1 社交网络差分隐私保护方法设计
1.1 构建差分隐私风险量化模型
影响社交网络数据隐私泄露的因素很多,为了实现对社交网络差分隐私的保护,构建差分隐私风险量化模型,利用隐私风险量化模型对数据隐私泄露的风险进行量化,实现对真实数据的保护[5]。在构建差分隐私风险量化模型时,首先要根据复杂的社交网络图数据,计算相对应的差分隐私预算参数[6],其具体计算过程如式(1)。
(1)
式中:εi表示差分隐私的预算参数;Q表示噪声添加参数。通过上述公式计算出差分隐私的预算参数,以此为基础,结合对隐私数据的精确风险量化,构建差分隐私风险量化模型,模型如图1所示。
在利用差分隐私风险量化模型量化隐私数据泄露风险的过程中,首先,将原始的社交网络数据集进行抽象处理,接着将抽象处理后的数据集发布到社交网络,再将发布后的数据集作为信息的接收方[7]。然后对社交网络中用户的数量进行统计,从而计算社交网络的接收方和发送方所拥有的信息量,其具体计算过程如式(2)。
(2)
式中:H(G)表示发送方发送的隐私数据包含的信息量;H′(G)表示接收方接收的数据信息量;pi表示传输数据的概率向量;H(pi)表示数据的不确定;Vj表示数据传输通道中数据节点的信息量;gj表示数据通道中数据节点泄露数据信息的概率;vol(G)表示数据节点的连接权重。通过上述公式,计算出社交网络中发送方和接收方的信息量,两者之间的差值即为数据的隐私泄露量[8]。至此,差分隐私风险量化模型的构建完成。
1.2 基于生成对抗网络反馈的隐私数据分类
在构建的差分隐私风险量化模型的基础上,考虑到社交网络中存在海量有价值且敏感的隐私信息,为了更好地实现对隐私数据的保护,利用生成对抗网络反馈对隐私数据进行分类和判断处理,减少数据出现泄露的可能,提高数据的安全性[9]。本文将分类过程划分为两个部分,一是数据分类的生成过程,二是数据分类的判别过程[10],其具体分类过程如图2所示。
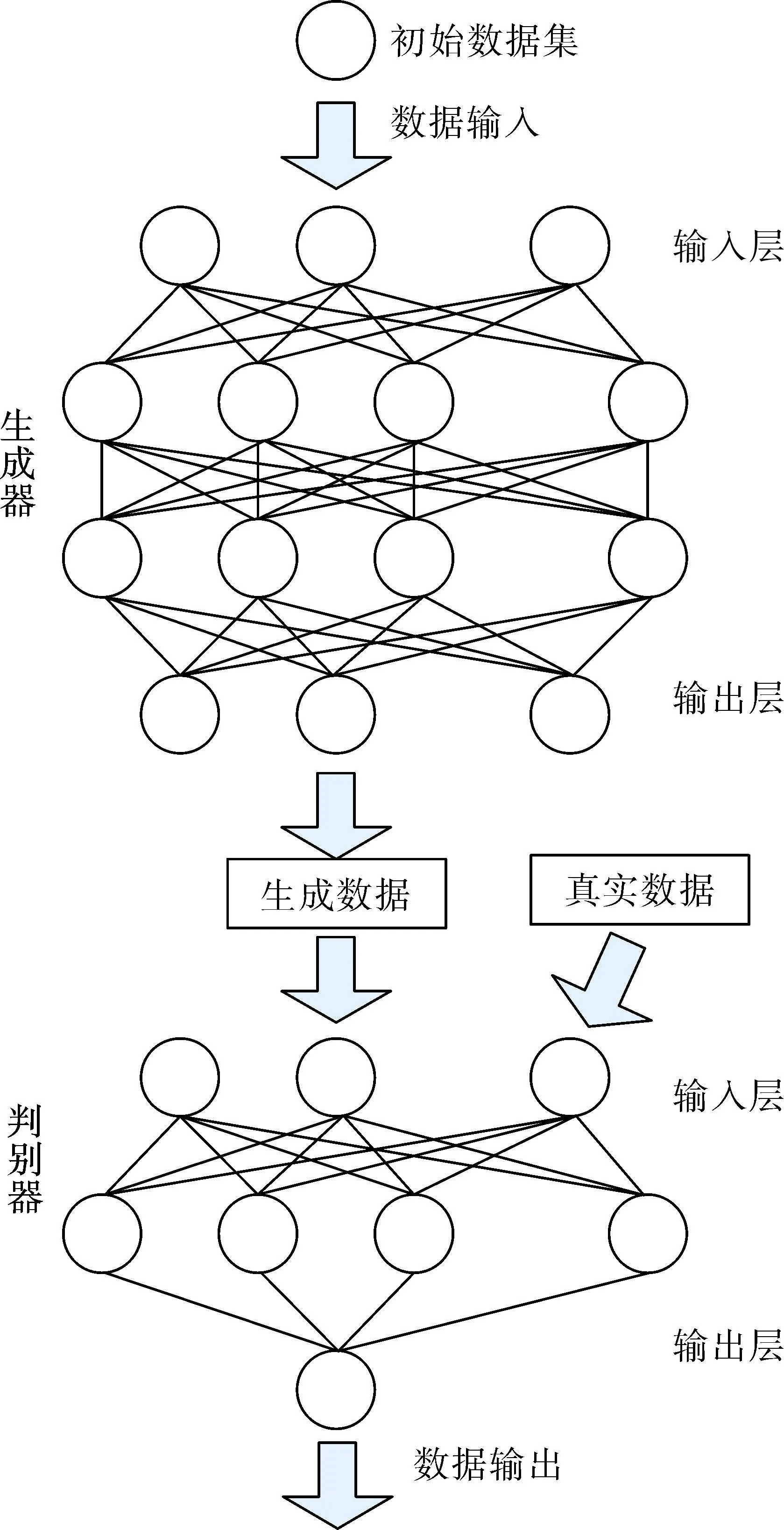
图2 基于生成对抗网络反馈的数据分类
由图2可知,生成器是对输入的初始数据集进行处理,得到生成数据集。判别器是将输入的生成数据和真实数据进行判别,并输出相应的判别结果[11]。在对数据进行分类时,需要对初始数据集进行计算,其具体计算过程如式(3)。
(3)
式中:H(D)表示初始社交网络数据集的信息熵;k′表示初始社交网络数据集在生成对抗网络反馈的作用下,数据集分类的类别数量;Ck表示不同类别的子数据集。在此基础上,将数据属性作为界定数据集类别的标准,根据不同的数据属性,计算出数据集的信息熵,其具体计算过程如式(4)。
(4)

(5)
式中:HA(D)表示隐私数据分类后的信息量;gR(D,A)表示数据信息的增益率。利用计算出的信息增益率对分类后的数据信息进行判断,如果信息增益率能平衡分类属性,则说明当前分类结果符合标准,如果无法平衡分类属性,则说明当前分类结果需要重新进行[13]。至此,对隐私数据的分类完成。
1.3 实现社交网络差分隐私保护
将GAN模型与差分隐私技术结合,通过在生成器和判别器中引入一定程度的噪声,可以增强对个体隐私的保护,并且保持生成数据样本的可用性,进而提高隐私保护效果,实现社交网络差分隐私保护。其具体的隐私保护过程如图3所示。

图3 差分隐私保护过程
由图3可知,在社交网络中,当从数据发送方接收到数据信息后,用户在传输数据的过程中,为保证数据的安全性,需在发送方发送数据后,对其进行加密处理,再将其传输到接收方。在本文中,利用差分隐私对其进行加密处理,通过在传输的数据中添加噪声使得数据信息发生改变[14]。差分隐私在数据中添加噪声后,数据的变化情况如图4所示。在传输的数据中注入随机噪声后,数据的波动情况发生了改变,且与原本的数据有一定的偏差。在上述情况下,即便出现数据被窃取的情况,被窃取的数据也很难被解密和识别,数据泄露的情况大幅度降低。此外,在传输隐私数据的过程中,单一的加密方法很难保证加密的效果,因此,本文除了差分隐私加密方法外,还结合了其他加密算法共同加密,保证数据的安全。同时,隐私数据的接收方想要接收发送方发送的隐私数据时,需要先进行身份验证,如果验证结果没有异常,接收方才能接收到解密后的信息。否则接收方将无法接收数据,且数据接收的异常信息也会很快反馈到发送方,提醒发送方注意信息安全。

图4 差分隐私在数据中添加噪声后的变化情况
2 试验测试
2.1 试验准备
在本次试验中,需要使用的试验环境和参数如表1所示。

表1 试验环境及参数设置
根据表1设置相应的试验参数,得到的试验环境如图5所示。利用数据采集仪采集相关试验数据信息,从中选取10个数据集作为试验对象开展本次试验,其数据集的具体情况如表2所示。

表2 试验数据集具体信息

图5 试验环境
在表2的数据集中,前5个数据集来源于twitter数据集,主要是利用twitter社交软件在社交圈中获得的数据资源,后5个数据集来源于Facebook数据集,包括Facebook在使用中,不同用户对于彼此的关注信息。上述10个数据集均来自于真实的社交网络,能够反映出社交网络的实际特点和状况。同时,在本次试验中,利用本文的方法对上述数据集进行分类处理,以数据集1为例的分类结果如图6所示。

图6 数据集1的分类结果
2.2 试验结果与讨论
数据集1被划分为3个不同的类别,根据数据集的分类结果,进行相关的数据保护。本文设计的方法为方法1,文献[5]提出的方法为方法2,文献[7]提出的方法为方法3。为对比3种方法在实际应用中的效果,本次试验以方法的执行时间作为评价指标,通过对比3种方法在不同数据集下的执行时间来体现该方法在进行隐私保护时的效率优劣,对比效果如图7所示。

图7 3种方法的执行时间对比
利用不同的方法对不同的试验数据集进行测试,执行时间均有不同。其中,方法2在数据集10中的执行时间最长,为599.5 ms;方法1在数据集3中的执行时间最短,仅为112.3 ms;同时,在10个试验数据集中,方法1的平均执行时间为123.2 ms,方法2的平均执行时间为498.5 ms,方法3的平均执行时间为501.2 ms,因此,本文设计的方法在实际应用中执行时间最短,在改善隐私保护性能的同时提高了数据的安全性。
3 结语
本文设计的方法在生成对抗网络反馈的支持下,将隐私数据集进行分类处理,为后续隐私数据的保护提供更好的数据支持。然而,对于任何新的隐私保护方法,用户的接受度是至关重要的。在推广差分隐私风险量化模型和生成对抗网络反馈方法时,需要考虑用户的参与意愿以及对数据隐私保护的关注程度。此外,在差分隐私预算参数的计算过程中,由于涉及到舍入操作或近似计算,可能会引入一定的误差。这些误差会对差分隐私预算的准确性产生影响,并导致计算结果不够精确。因此,在实际应用中,需要对这些误差进行充分的考虑,并在计算过程中寻求更准确和可靠的方法。
猜你喜欢
英语世界(2023年6期)2023-06-30
意林彩版(2022年2期)2022-05-03
新世纪智能(数学备考)(2021年5期)2021-07-28
数学小灵通(1-2年级)(2021年4期)2021-06-09
第一财经(2020年4期)2020-04-14
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
文苑(2018年17期)2018-11-09
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
信息安全研究(2015年3期)2015-02-28
