
基于元学习和神经架构搜索的半监督医学图像分割方法
2024-01-09 09:05:06于智洪李菲菲
电子科技 2024年1期
于智洪,李菲菲
(上海理工大学 光电信息与计算机工程学院,上海 200093)
随着深度学习的发展[1],尽管医学图像分割方法[2]已有较大进展,但当将训练好的模型用于未知数据集时可能引起性能骤降,这主要是由病人种群、扫描仪器和扫描采集设置不同而引起,该问题被称为“域偏移(Domain Shift,DS)”[3]。其中,性别、年龄、种族特征等因素导致潜在病理和解剖结构有所差异[4]。扫描仪器和扫描采集设置会影响医学图像的亮度、对比度等特征,这也给医学图像任务造成困扰。
解决“域偏移”问题的直接方法是通过获取大量多样的含标签数据集进行模型训练,但该方式耗时耗力并且需要大量资金。其次,域适应(Domain Adaptation,DA)[5]方法也被广泛用于解决“域偏移”问题。该方法主要通过训练源域(Source Domain)模型,并使用目标域(Target Domain)中的部分数据进行模型再训练,通过该方式将目标域中所涉及的特征信息用于目标域评估。但在医疗诊断现实应用中,任何未知的目标域数据集均可能遇到“域偏移”问题,因此域适应方法仍然无法直接应用于现实社会生活。考虑到医疗诊断在现实社会中的应用问题,一个更加具有挑战性的方法被提出——域泛化(Domain Generalization,DG)[6],该方法不使用目标域中的任何先验知识,而是通过对源域数据集的探索来更好地泛化到未知医疗任务中。因此,域泛化更具有现实应用意义和挑战性。
就域泛化问题而言,目前可实现该目标的方法分为:1)源域数据增强[7];2)表征学习(Representation Learning,RL)[8],即学习域不变(Domain-invariant)表示,或者是将特征分解为特定和公共两部分表达式;3)基于梯度的元学习方法[9]。本文采用基于梯度的元学习方法来获得域不变表示以达到更好的域泛化能力。该方法将源域分为元训练集和元测试集,通过这两个集合不断模拟域偏移过程学习提取域不变特征。先前方法大部分是在监督学习下完成,例如文献[10]利用了全局类对齐和局部样本聚类,文献[11]使用形状感知约束,但医学图像的像素级标注费时费力,所以在数据稀少的环境中可能无法获取准确的域不变特征。在上述基于元学习的分割方法[12-13]中,多数采用固定的U型结构网络进行分割,却并未考虑到针对不同源域任务利用更适合的分割结构可以获得更好的结果。
因此,本文采用了神经架构搜索(Neural Architecture Search,NAS)[14]对特定源域任务进行分割结构搜索,使其可以与元学习更好地配合,以探索出准确的域不变特征,实现良好的泛化能力。神经架构搜索由搜索空间、搜索策略和评估技巧3部分组成,由于设计一个性能良好的网络结构需要大量人力,神经架构搜索可以通过超参数的优化更新来自动获取较合适的针对特定任务的架构,但该过程需要大量标签数据。而元学习[15]致力于从经验中进行学习,该方法可以从少量数据进行学习,并应用到新的任务之后。将二者结合可产生一个利用少量训练数据和迭代次数并且可以自适应网络结构的方法。
本文在DGNet[13]基础上提出了更加灵活准确的域泛化网络。基于神经架构搜索的自适应性[16],本文设计了一个新训练策略,首先针对不同域的稀少数据进行架构搜索以找到较合适的分割网络,使分割结果更准确。其次利用基于梯度的半监督元学习方法,将源域分为元训练集和元测试集,利用上述分割结果不断探索合适的域不变表示。实验结果表明,与DGNet以及一些主流网络相比,本文方法有效提高了域泛化能力,拥有良好的性能。
1 本文方法
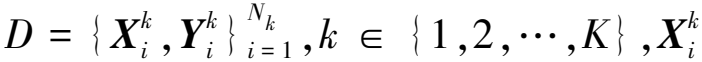
1.1 算法流程
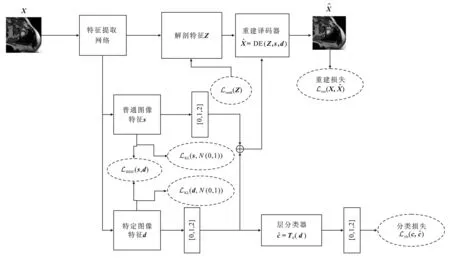
源域数据由标签数据和无标签数据两部分组成。本文选择所有无标签数据和m%(m=0,1,2,…,100)的标签数据作为源域训练集,选择一个新域作为目标域数据集以评估泛化能力。如图1所示,本文首先利用m%的标签数据和神经架构搜索进行分割网络架构的搜索与确定,在分割网络确定后使用半监督元学习训练[13]策略进一步探索域不变表示。首先,源域数据被分为元训练集tr和元测试集te,在每次迭代过程中,元训练集tr通过Dice损失函数meta-train对β和φ进行更新
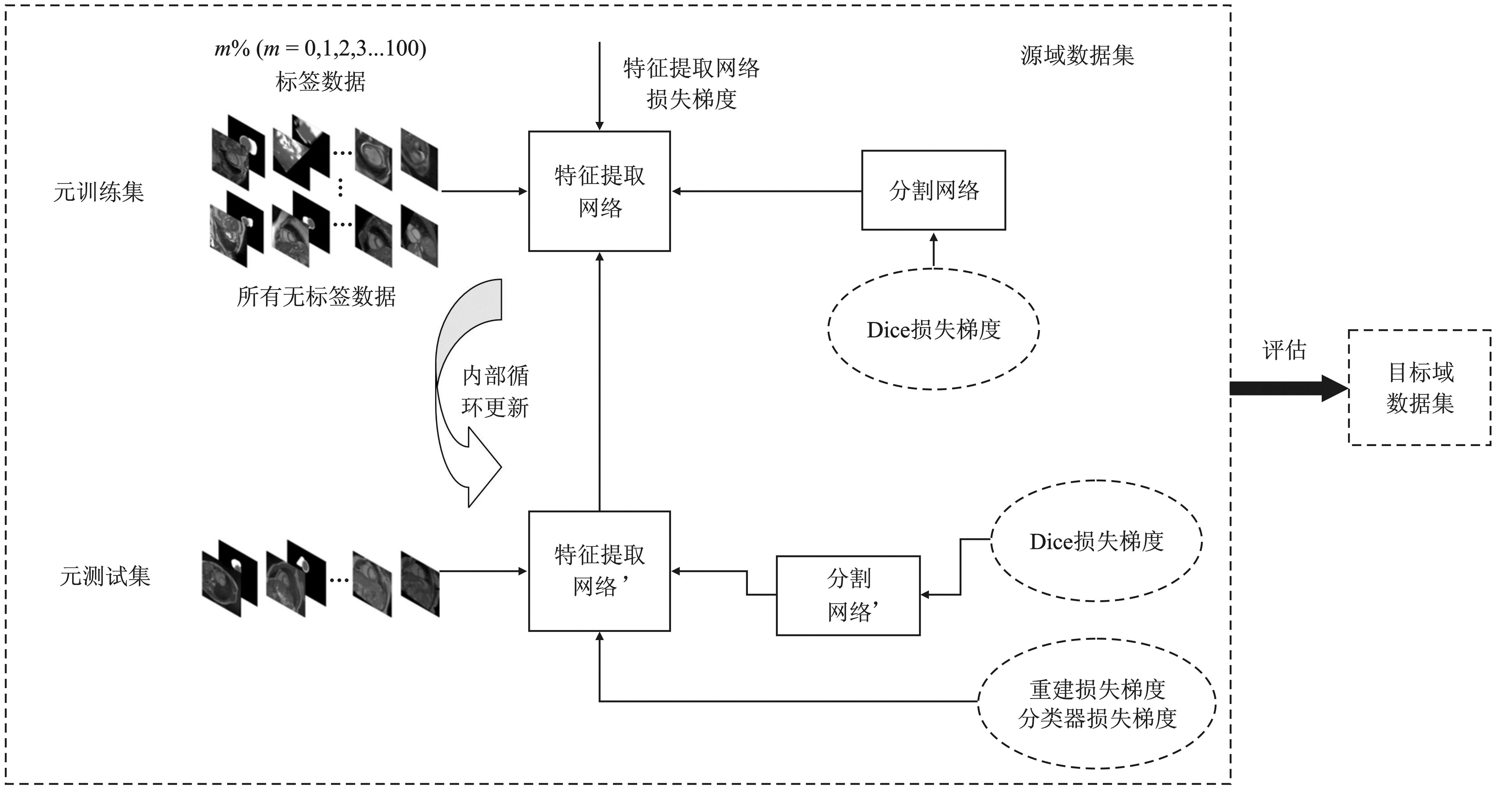
图1 本文算法整体框架Figure 1. Overall framework of the proposed algorithm

(1)
其中,λ代表元训练tr更新过程中的学习率。元测试te使用更新过后的(β′,φ′)进行再训练,使元训练tr和元测试te过程中的损失和最小[16]
(2)
无论是源域数据集还是未知数据集,通过该方法都可以拥有良好的泛化性能。最后,使用训练得到的最佳模型在新域数据集上进行评估。
1.2 分割网络架构搜索
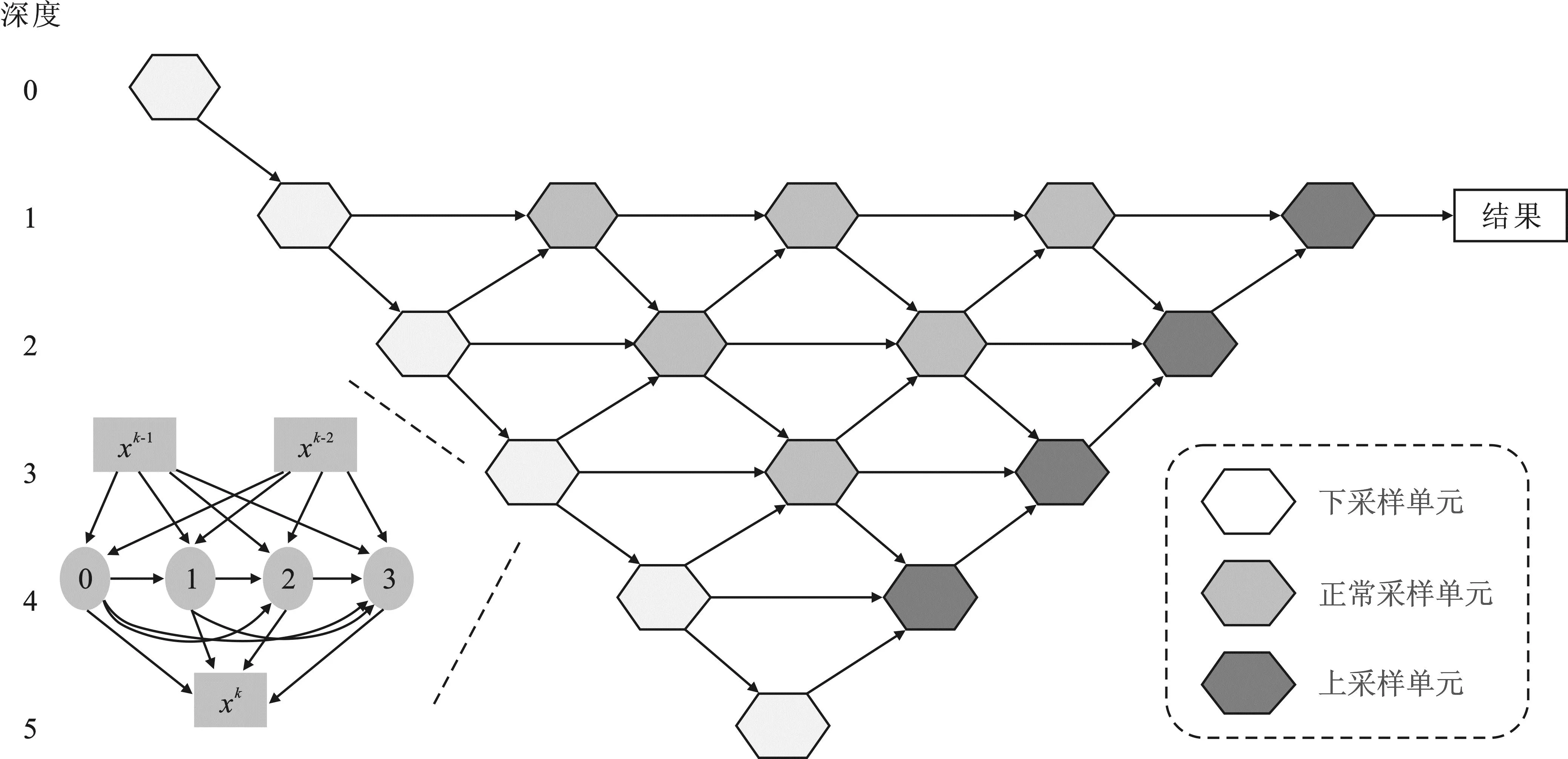
由于在医学图像分割中U型网络架构是较主流的方法,因此本文基于NAS-UNet[17]和UNet++[18]将搜索空间确定为U型结构,由上采样、下采样以及正常采样3种单元构成,从不同尺度中学习最优特征表示,获得较合适的子网络。
1.2.1 搜索空间
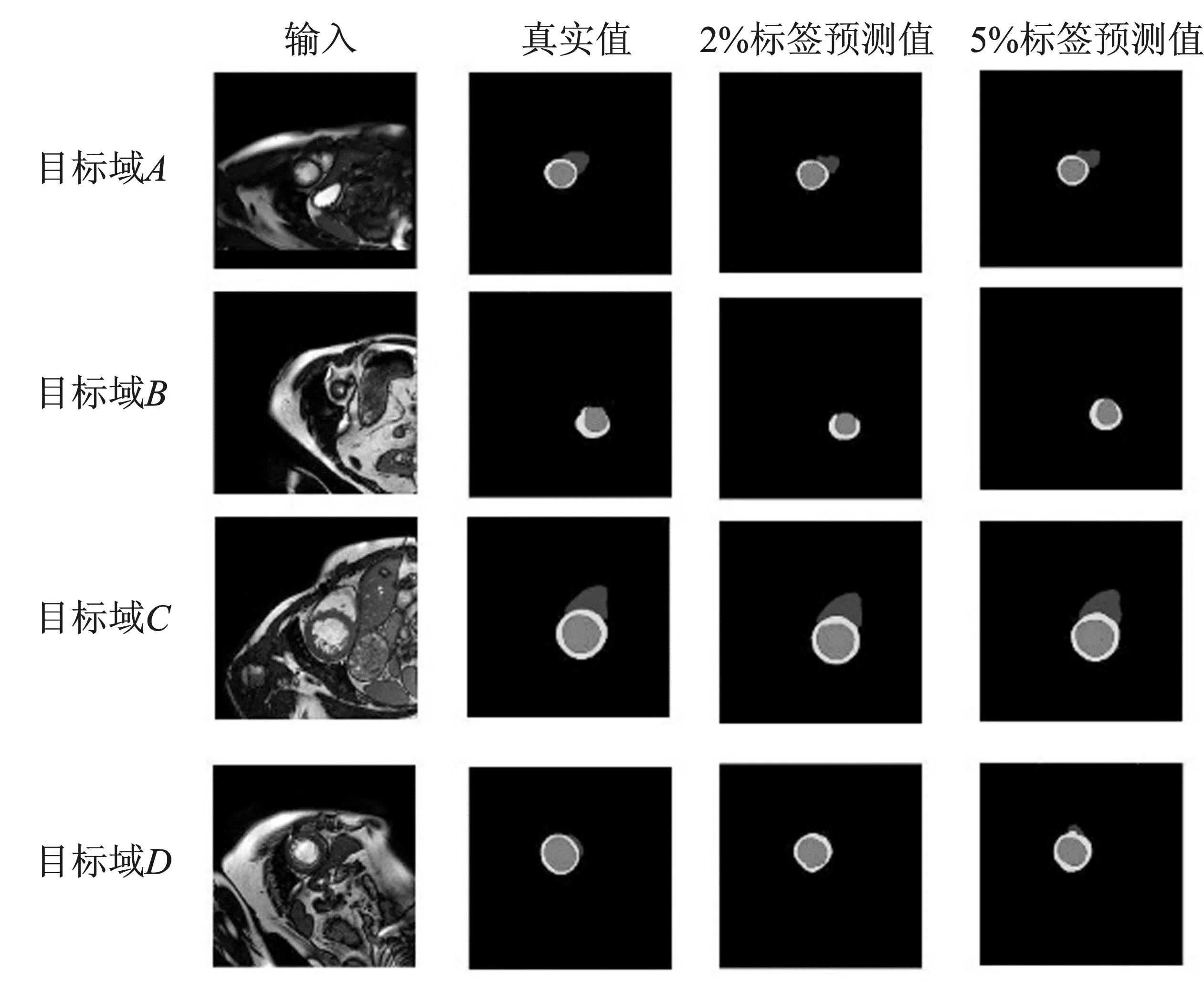
如图2所示,该搜索空间深度为5,不同尺度的特征映射通过跳跃连接进行信息融合。其内部搜索空间结构由先前的两个特征图作为输入,进行上采样、下采样、正常采样操作。具体下采样单元结构如图2左下所示,下采样与正常采样单元结构相同。图2可以用有向无环图(Directed Acyclic Graph,DAG)来解释,xk-2和xk-1为两个输入,0、1、2、3为中间4个潜在的节点,xk为输出。信息通过特征映射(i,j)(i 表1 候选操作总结 图2 分割网络的搜索空间Figure 2. The search space of segmentation network 与DARTS[19]相似,每条边都由超参数α(i,j)来权衡重要性,本文依据O的维度,针对3种单元设置了3个不同的权重矩阵,使其从离散空间变为连续空间,并通过对应的损失函数和梯度下降进行参数更新,最后使用Softmax函数对具体边应选取的操作进行计算 (3) 1.2.2 搜索策略 1.3.1 特征提取网络 图3 特征网络结构Figure 3. The structure of feature network (4) 其中,c是域标签,超参数λrank=0.1,λKL=0.1,λrec=1.0,λcls=1.0。 1.3.2 元训练与元测试目标函数 首先,元训练目标函数由两部分组成 (5) 当标签数据可获得时,λDice=5。在元测试阶段,本文致力于获得更加准确的分割掩码以及保持s、d和Z之间的纠缠关系。因此,元测试阶段的目标函数如式(6)所示。 (6) 本文实验使用多中心、多供应商和多疾病心脏图像分割(M&Ms)数据集[4]来验证泛化能力。该数据集包含320名受试者,他们在3个不同国家的6个临床中心接受扫描,并且使用了西门子、飞利浦、GE和佳能的核磁共振仪器,即A、B、C、D这4个不同域,其中域A包含95个受试者,域B包含125个受试者,域C和域D各包含50个受试者。 实验使用Pytorch[24]框架和一块NVidia 2080 Ti GPU,所有模型均使用Adam优化器,学习率为2×10-5,批尺寸为2,一共迭代150次,重采样率为1.2。在半监督设置中,本文使用特定百分比的受试者作为标签数据和所有无标签数据。本文使用Dice和Hausdorff Distance作为评价指标。 表2~表5展示了Dice和Hausdorff Distance以及它们的标准差结果,其训练数据集包含2%或者5%的标签数据和全部无标签数据,而基准模型仅使用2%或者5%的标签数据进行训练。粗体数字表示最佳性能。由表得知本文方法可以获得较好的泛化性能。就表2和表3而言,在Dice指标下,无论是5%还是2%的标签数据,本文方法有超过一半的精度均好于DGNet,并且高出约2%。虽然5%标签的精度平均值与DGNet持平,但是在2%标签数据下,相比DGNet以及其他主流方法,本文方法至少超出1.2%。就Hausdorff Distance指标而言,当其距离越小,表明效果越好。从表4~表5可以看出,本文方法无论目标域为何,与所有主流方法相比,均可以取得最佳效果,超出至少2%。 表2 M&Ms在含5%标签数据Dice上的结果 表3 M&Ms在含2%标签数据Dice上的结果 表4 M&Ms在含5%标签数据Hausdorff distance上的结果 表5 M&Ms在含2%标签数据Hausdorff distance上的结果 与自动分割网络nnUNet[25]相比,本方法使用NAS进行自动分割,使用元学习进行训练取得了更好的泛化效果,精度提升至少3%。针对使用了图像增强的半监督学习方法SDNet[26],采用rank损失的LDDG[23]以及基于梯度下降的元学习分割方法SAML[11],本文方法依然拥有2%以上的精度优势。以上实验进一步证明本文方法将元学习与神经架构搜索结合的有效性和良好的泛化能力。 当域A作为目标域时,图4为在5%和2%标签条件下的分割结果以及其真实值,可以看出本文方法具有良好的泛化能力。表6为其在5%标签下搜索出的最优单元结构。由图2可知,一共有4个节点,每个节点由前两个输出与操作卷积进行连接,然后再进行下一步输出。通过该结构可使网络拥有较好的分割结果,从而产生较好的泛化能力。 表6 M&Ms在含5%标签数据上的单元结构 图4 分割可视化结果Figure 4. The visualization results of segmentation 本文利用基于梯度下降的神经架构搜索和元学习来进行泛化医疗分割方法研究。首先利用U型搜索空间,针对不同源域进行上、下以及正常单元结构搜索,使其分割网络更适合本源域的分类,继而利用元学习进行泛化学习,使其更好地适应未知目标域数据以达到良好的泛化效果。目前,本文方法在M&Ms数据集上拥有良好性能,但该网络依然存在缺陷,例如当源域变化时,本文方法需要重新搜索网络结构,耗费较多时间。后续工作将研究利用元学习使分割结构也纳入具有快速泛化能力的新方法,从而节约时间和成本。
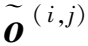
1.3 元学习训练策略
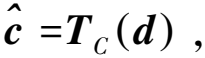
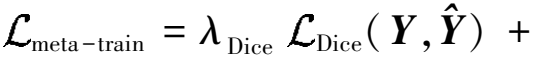
2 实验
2.1 实验数据集
2.2 实验配置
2.3 实验结果与讨论





3 结束语
猜你喜欢
计算机技术与发展(2024年3期)2024-03-25 02:10:02
成都信息工程大学学报(2022年4期)2022-11-18 07:31:10
汽车工程(2021年12期)2021-03-08 02:34:30
计算机技术与发展(2020年11期)2020-12-04 07:50:46
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
电信科学(2017年6期)2017-07-01 15:45:17
公民与法治(2016年10期)2016-05-17 04:12:58
电子与信息学报(2015年12期)2015-08-17 11:14:42
计算机工程(2015年8期)2015-07-03 12:20:27
